
Дизайн с помощью ИИ: протестировал 35 модели с сгенерировал 138 картинок
Я сгенерировал одну и ту же задачу 38 разными агентами/моделями, и показываю вам 150 итоговых картинок. Разница в стоимости между самым дорогим и дешевым вариантами — 410 раз.
У этого поста есть еще версия на английском: mikeozornin.ru/blog/all/llm-and-ui-design-en
Иногда коллеги, часто не дизайнеры, после анонсов всяких Клод-дизайнов, спрашивают каково оно. Как оно дизайнит, что это вообще. Насколько хороший дизайн можно ожидать, можно ли взять дизайн-систему и как потом довести до продакшена. Возможно, они хотят услышать, что нейросети заменят не только их, разработчиков, но и дизайнеров тоже, — тогда мы вместе выпиливать столы, жарить кофе или работать курьерами.
Я решил проверить, как дела с ИИ-дизайном обстоят на начало мая 2026 года. Ситуацию быстро меняется, через полгода всё это будет уже неактуально, но сейчас вот так.
1 План эксперимента
Я опишу план эксперимента: процедуру и ограничения, чтобы вы могли во-первых, понять, насколько можно верить результатам, во-вторых, могли провалидировать или повторить их самостоятельно.
TL;DR; Агенты рисовали три экрана: десктоп, мобильный и промостраницу через Paper MCP.
1.1 Процедура
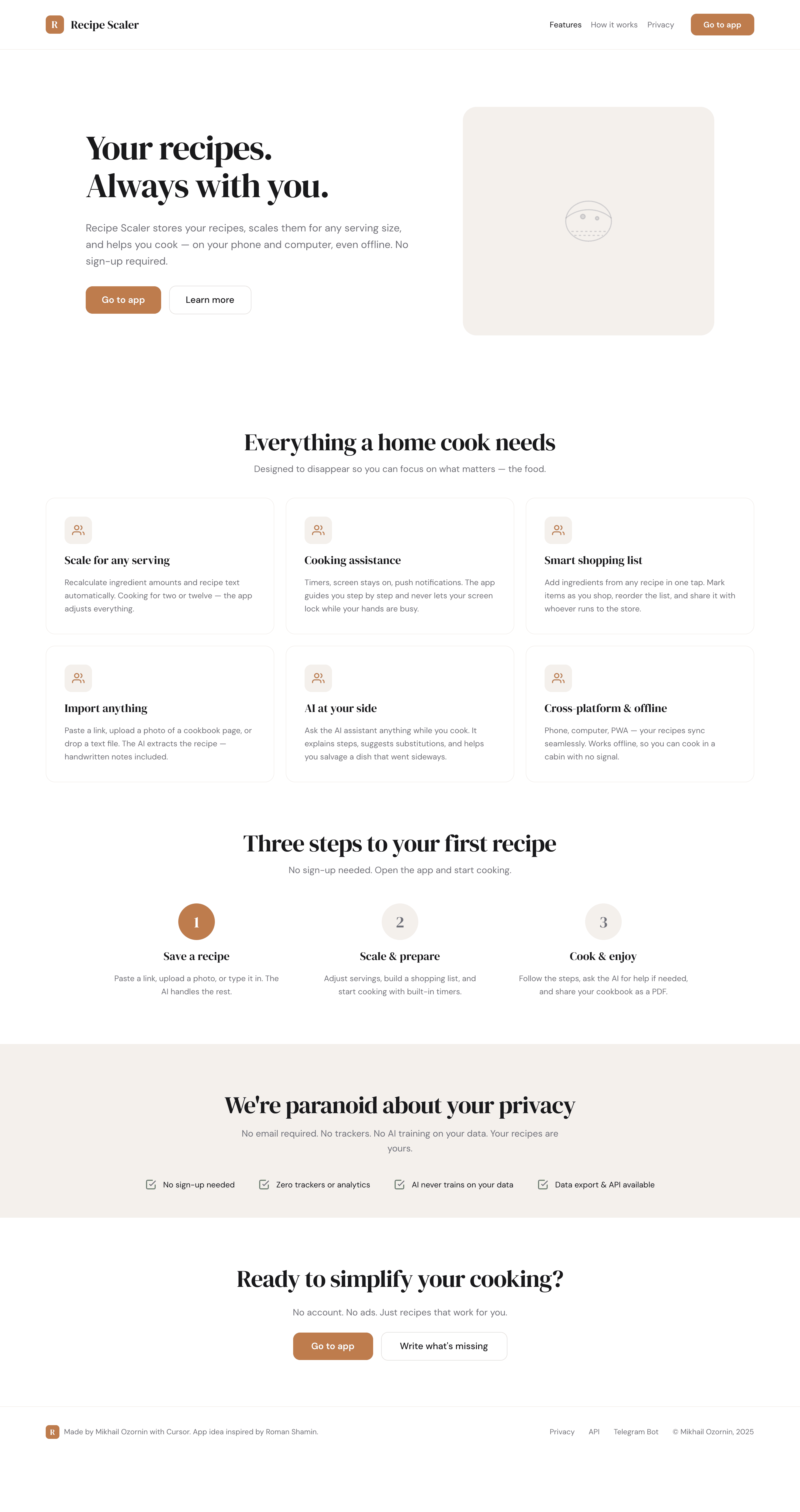
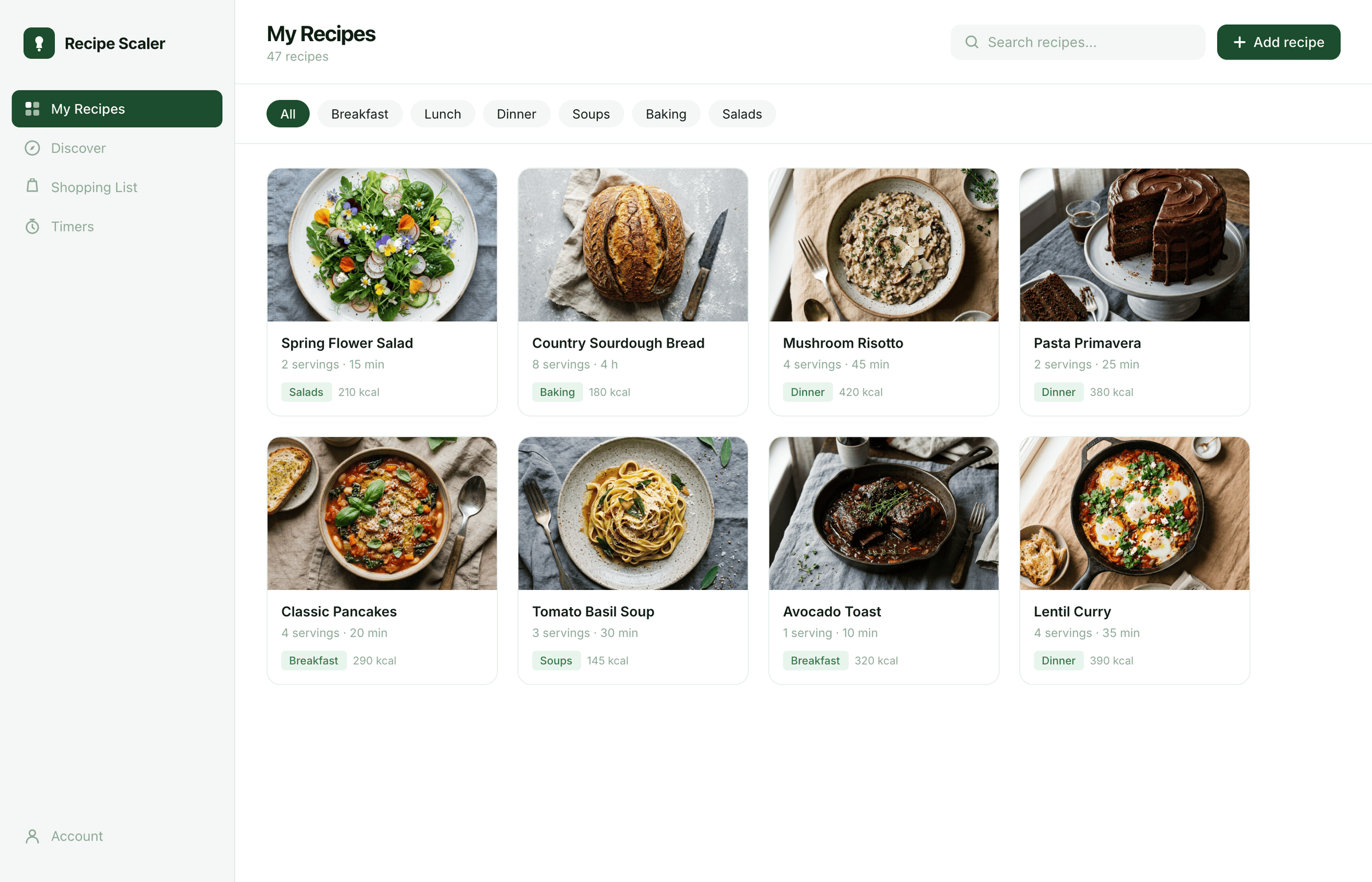
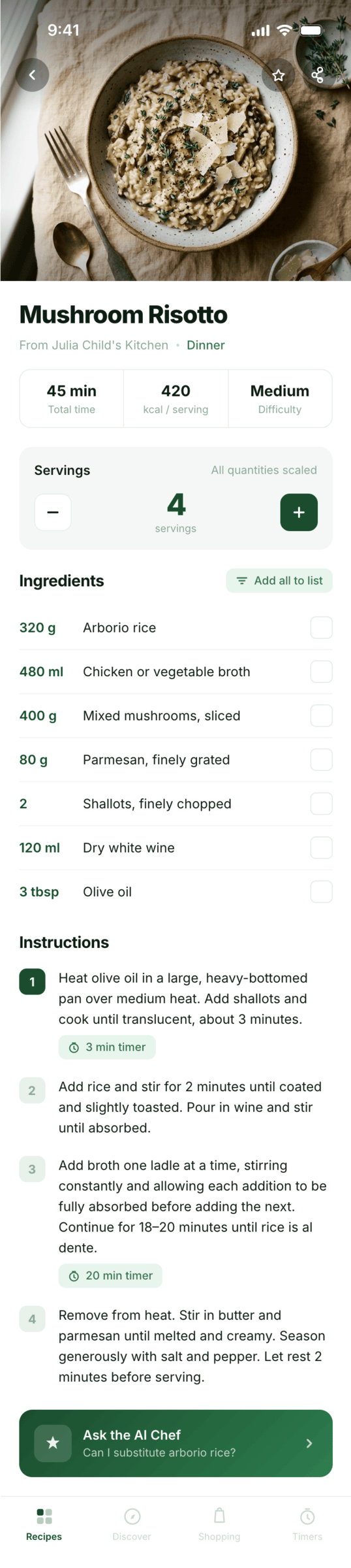
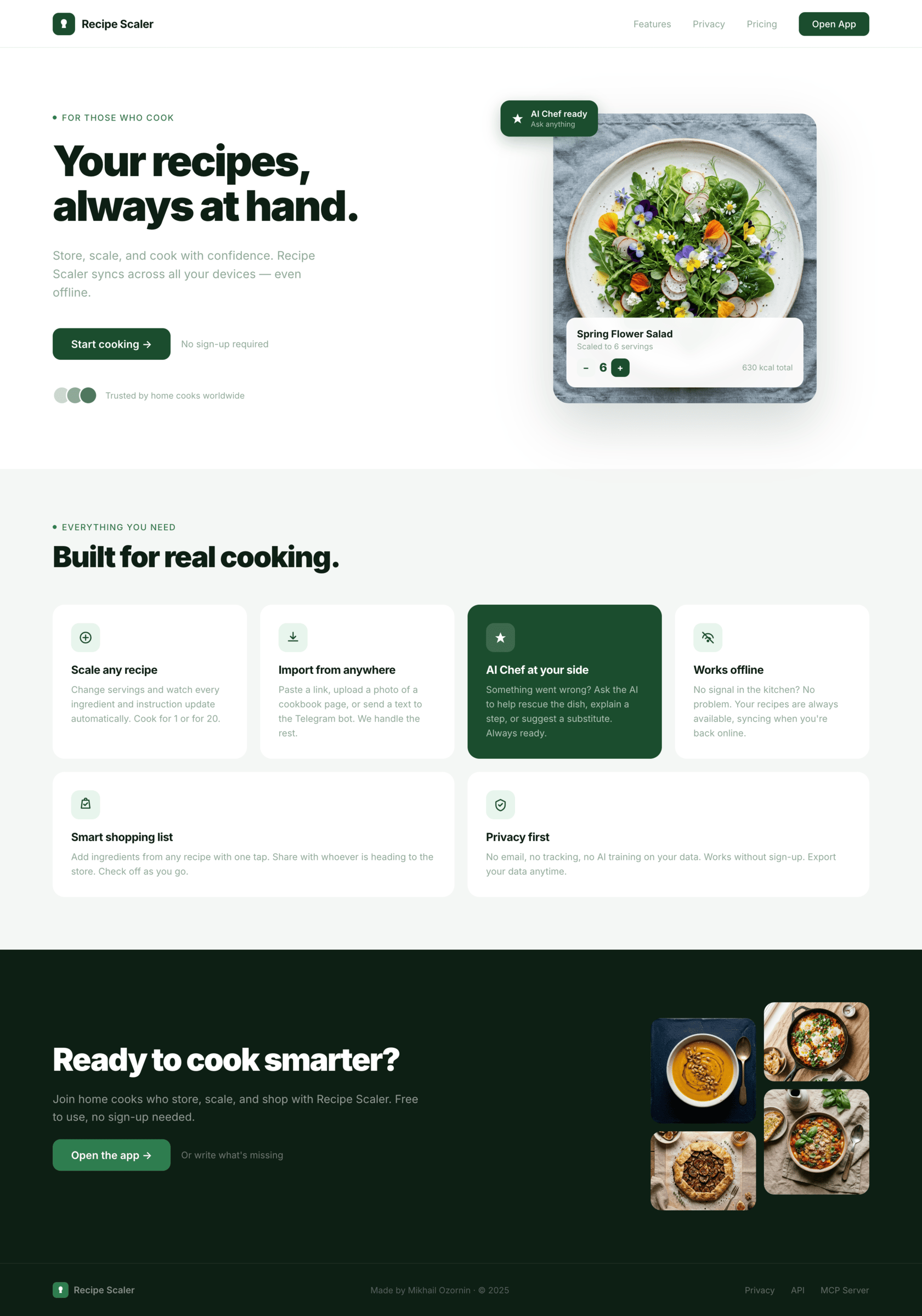
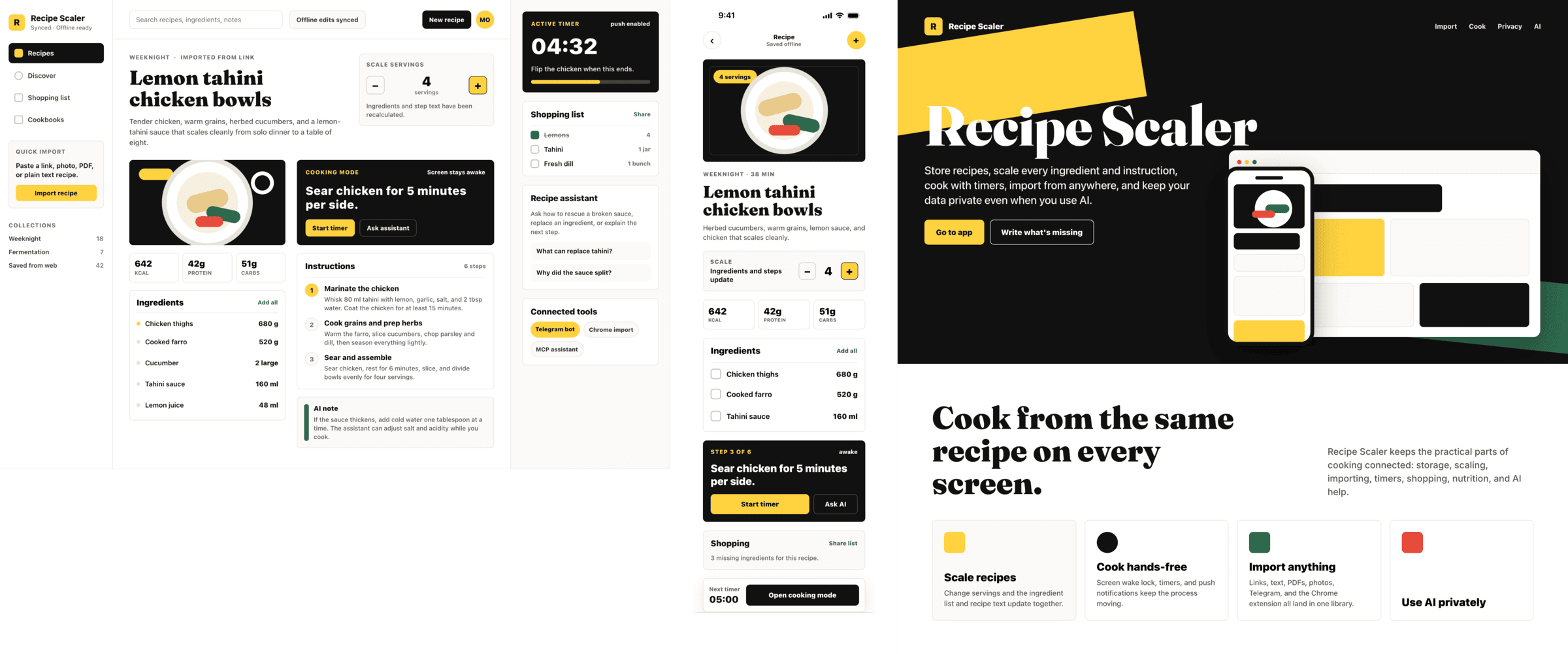
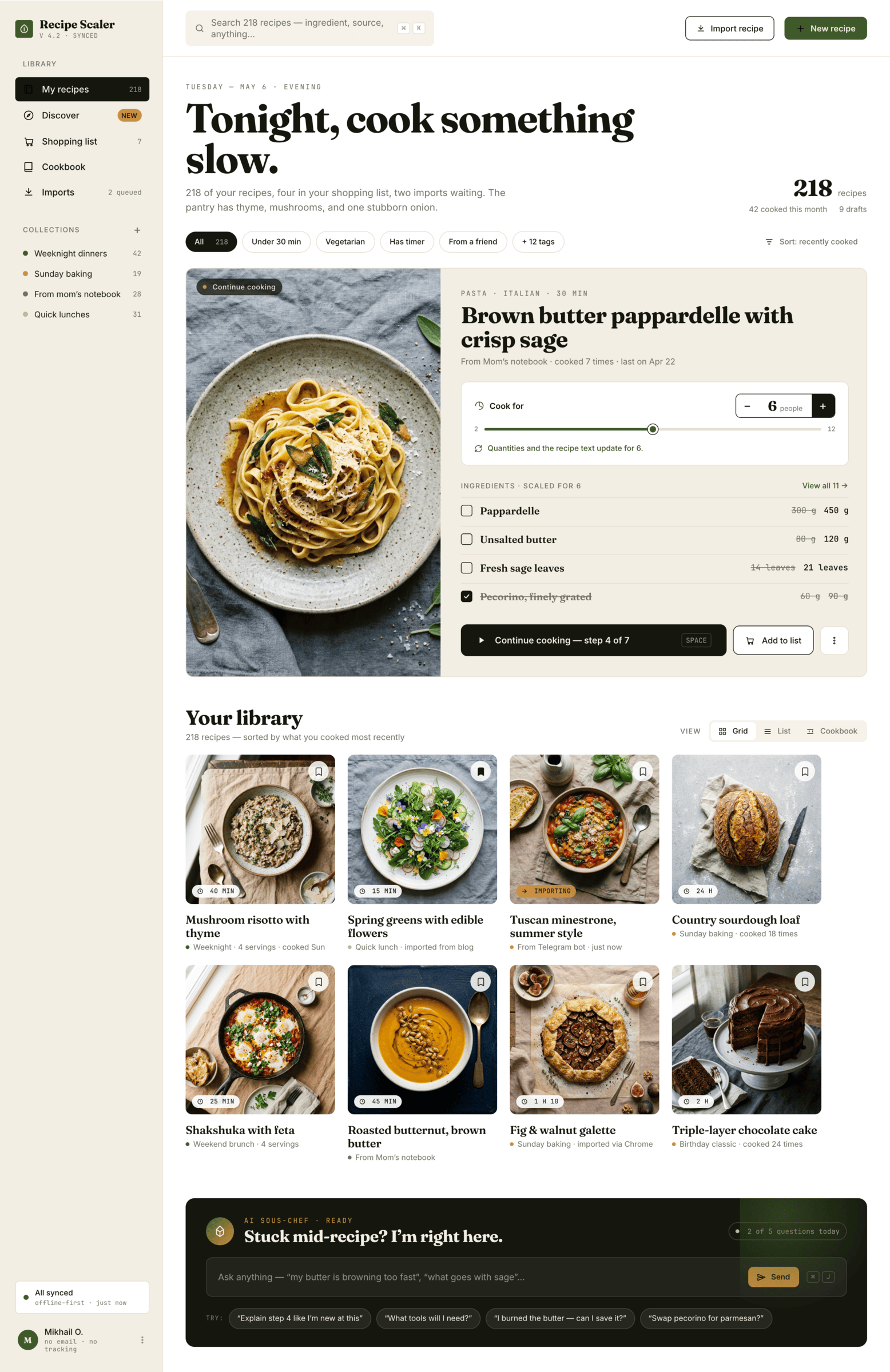
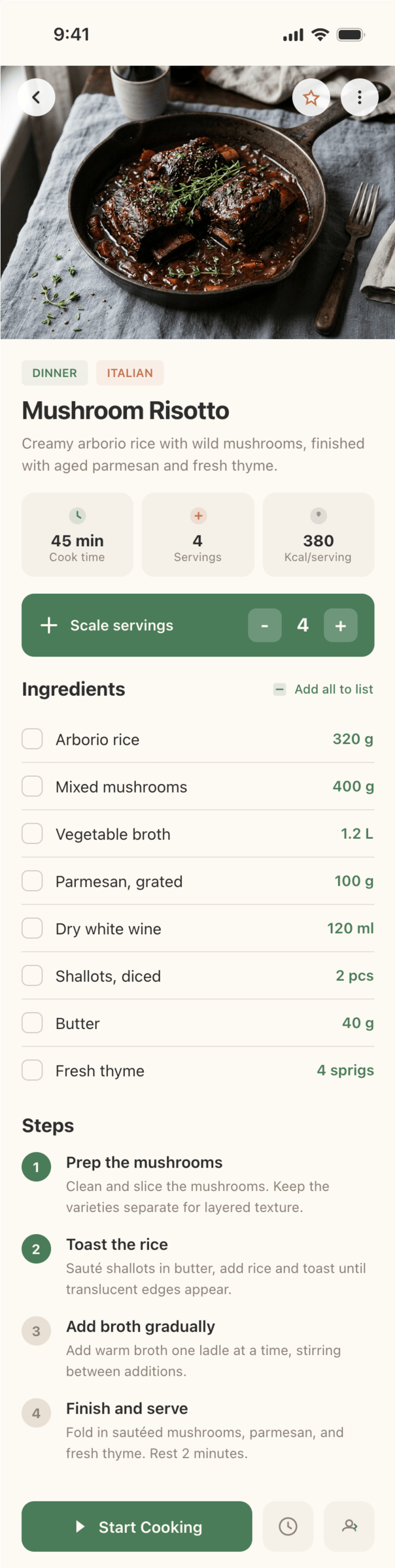
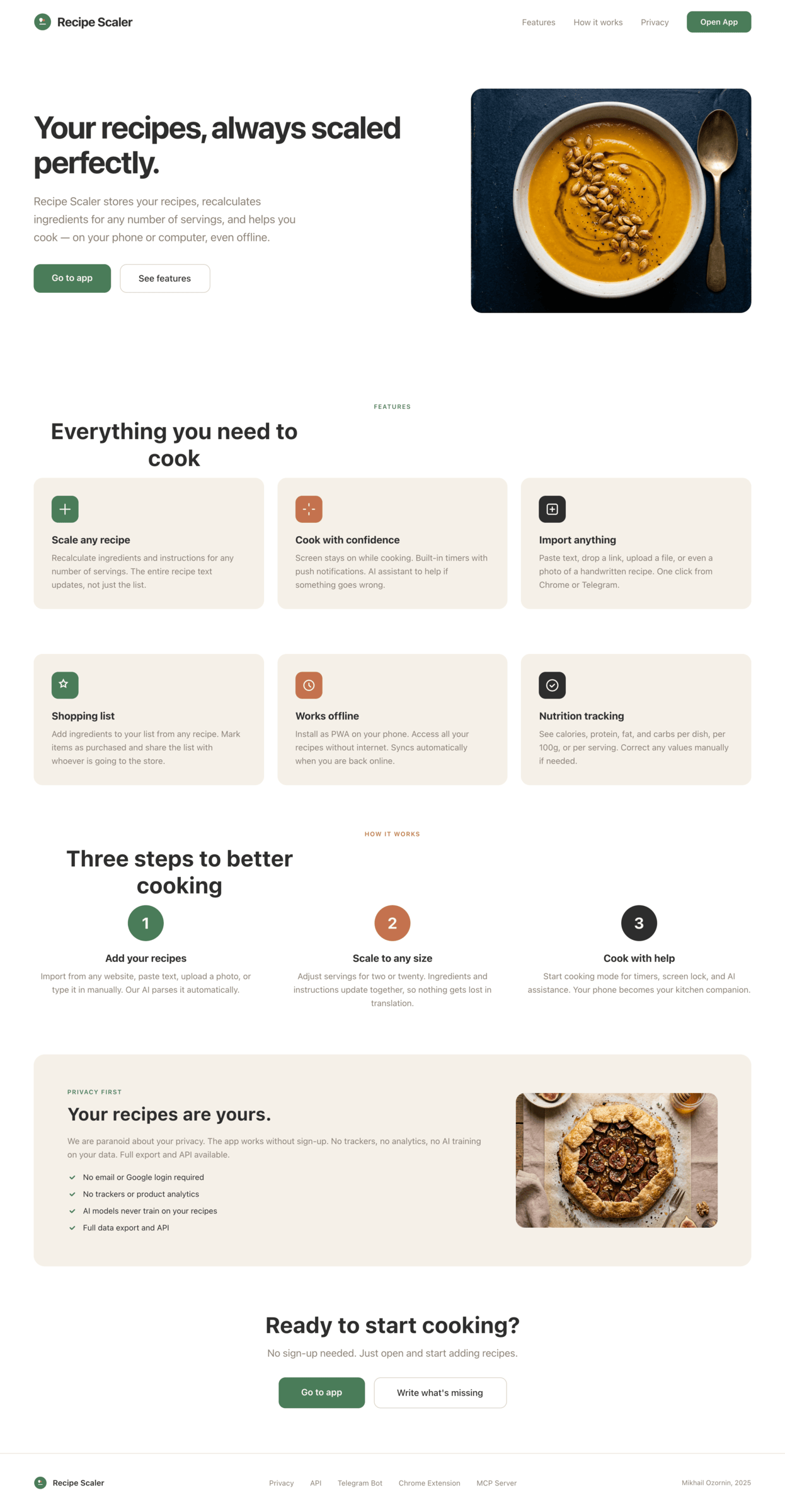
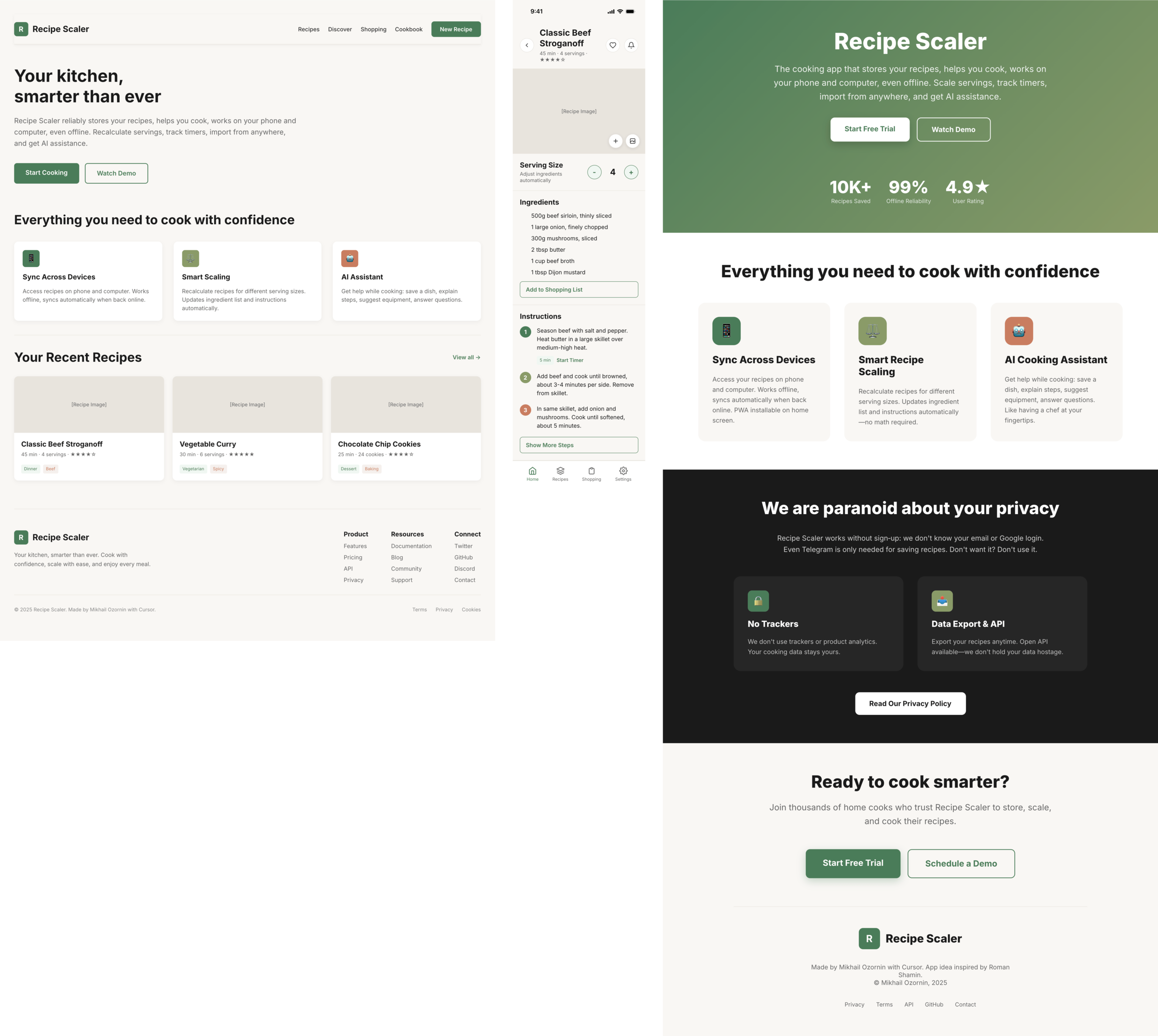
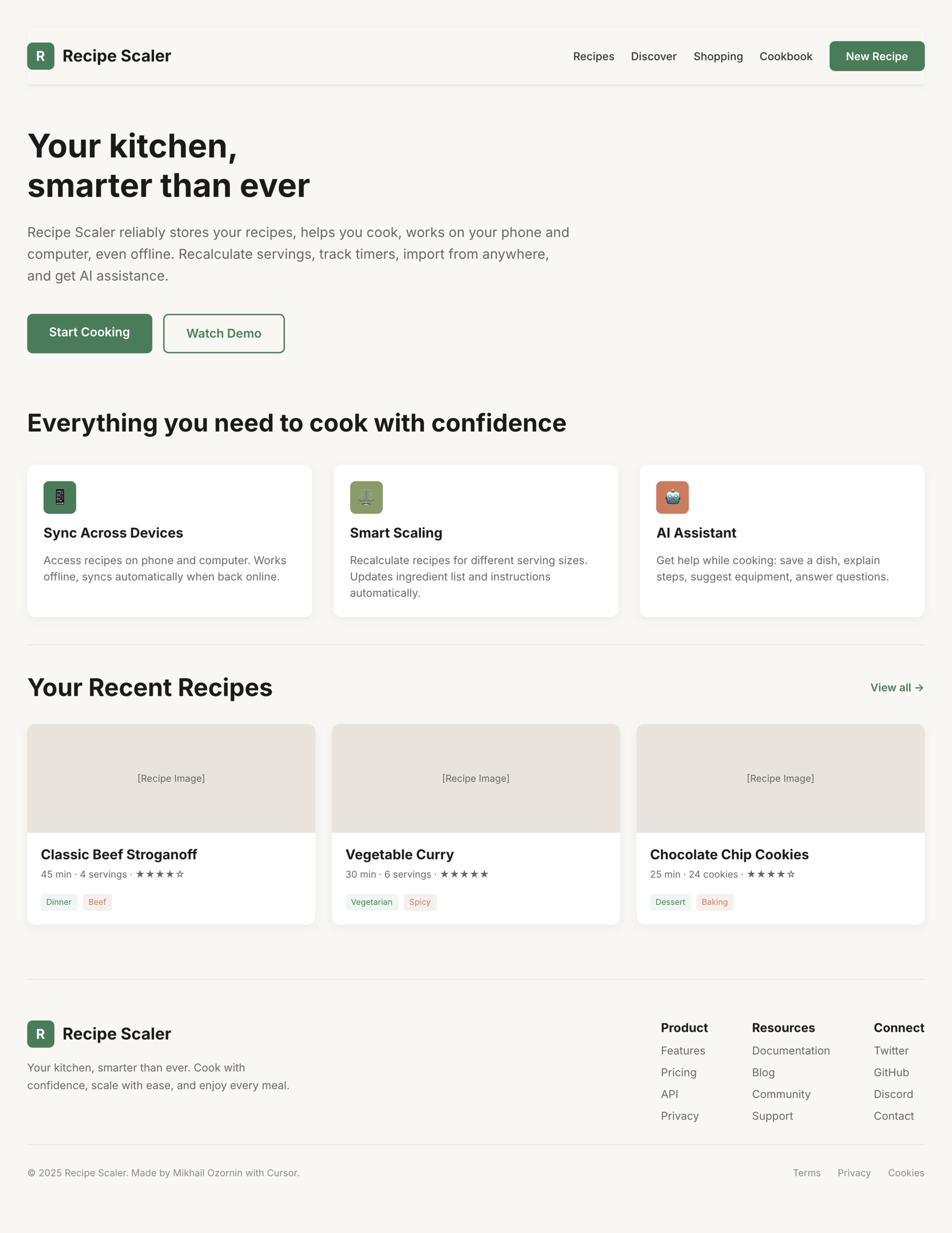
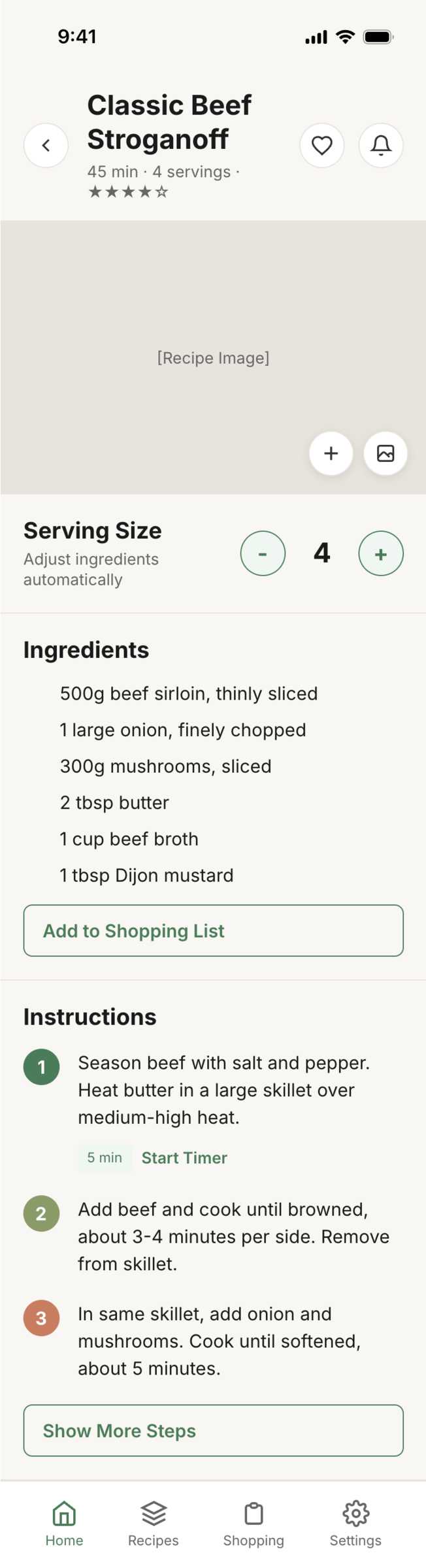
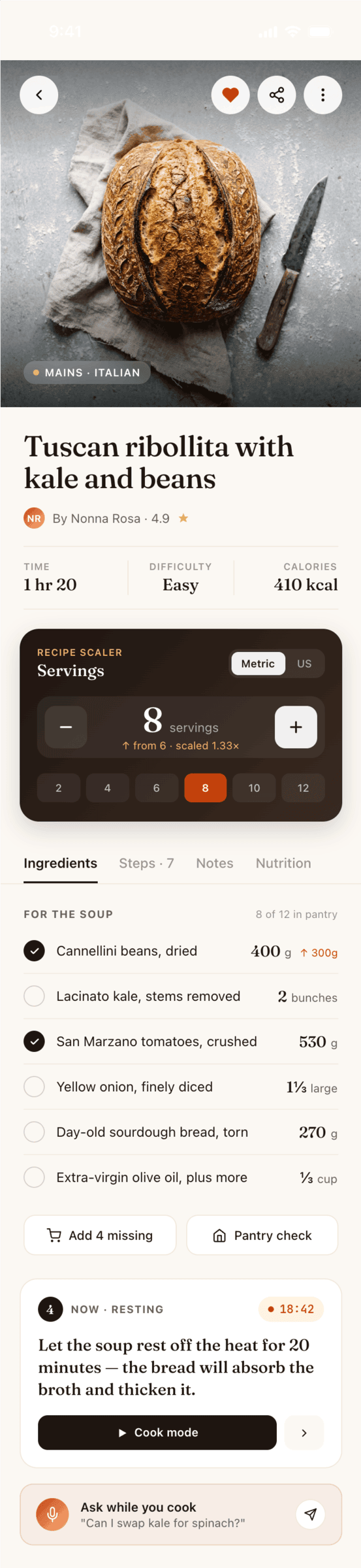
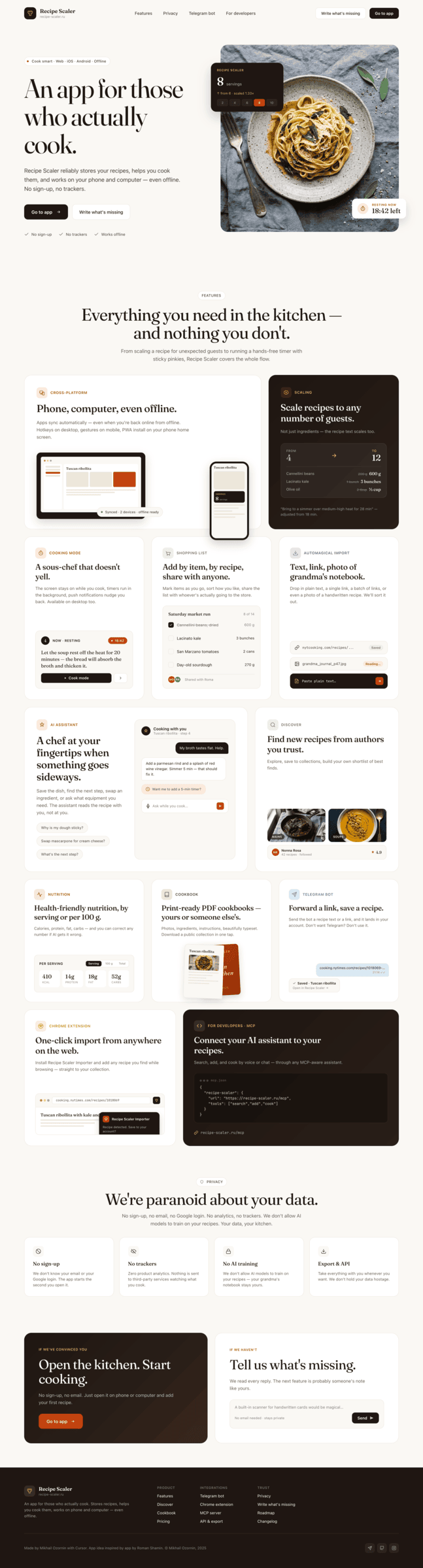
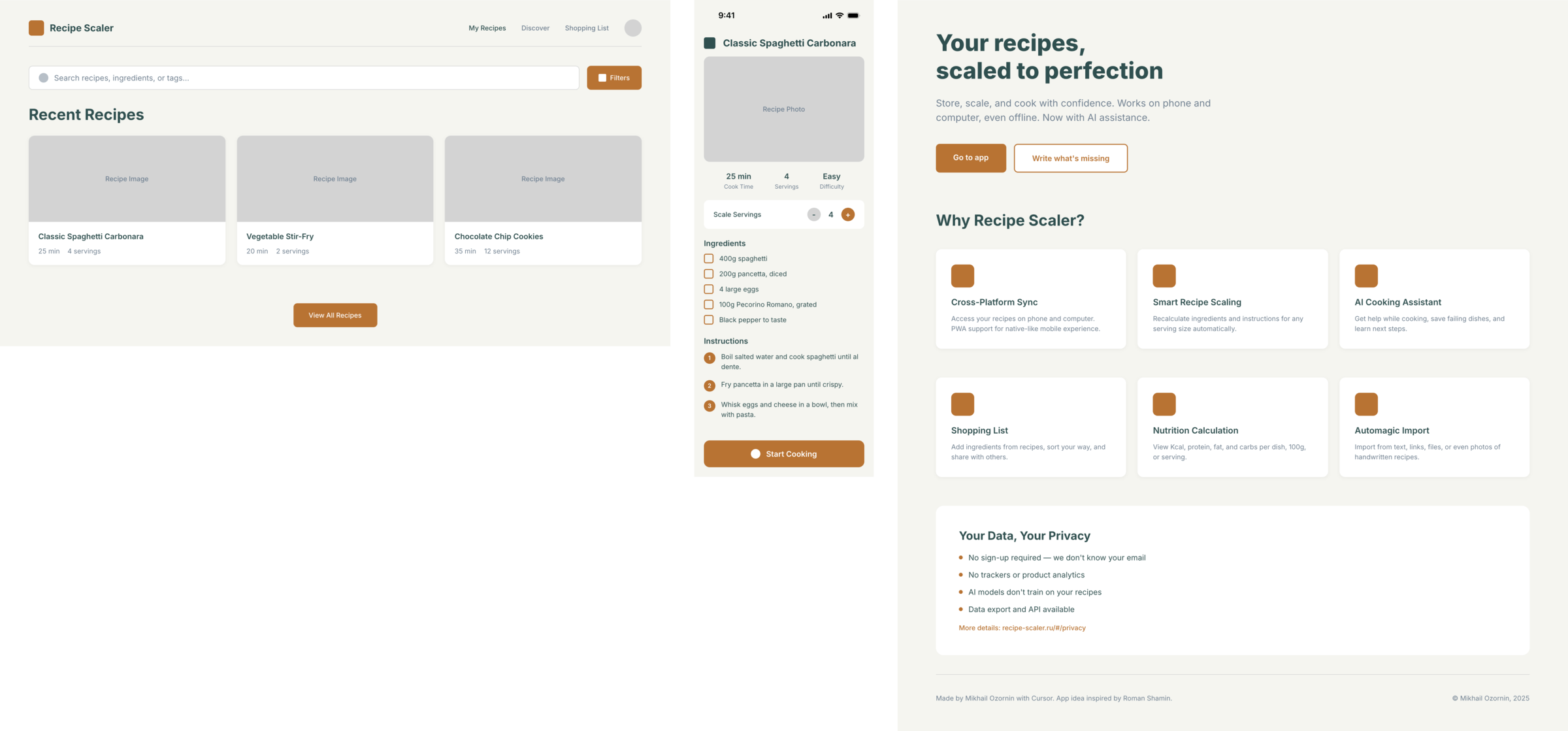
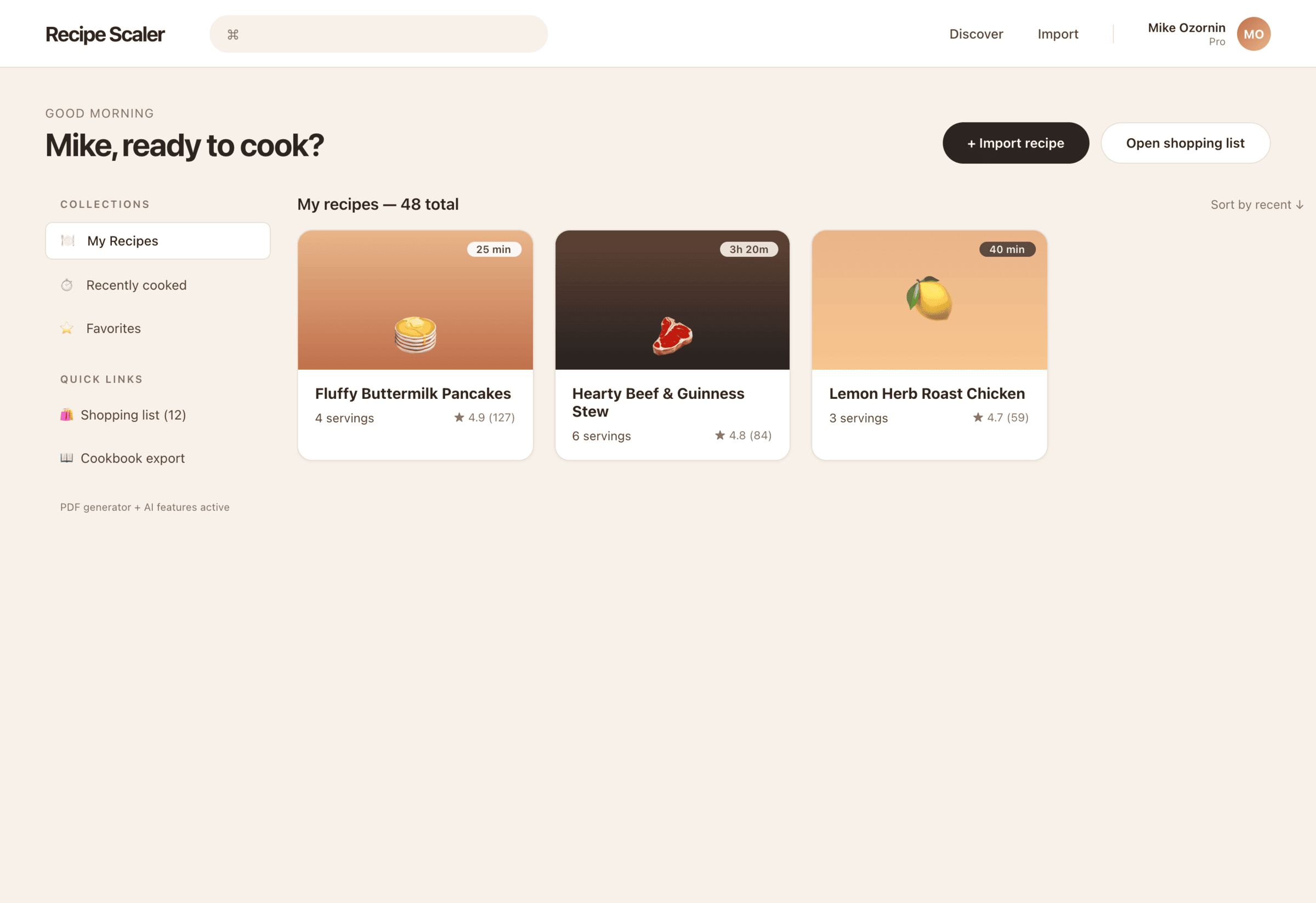
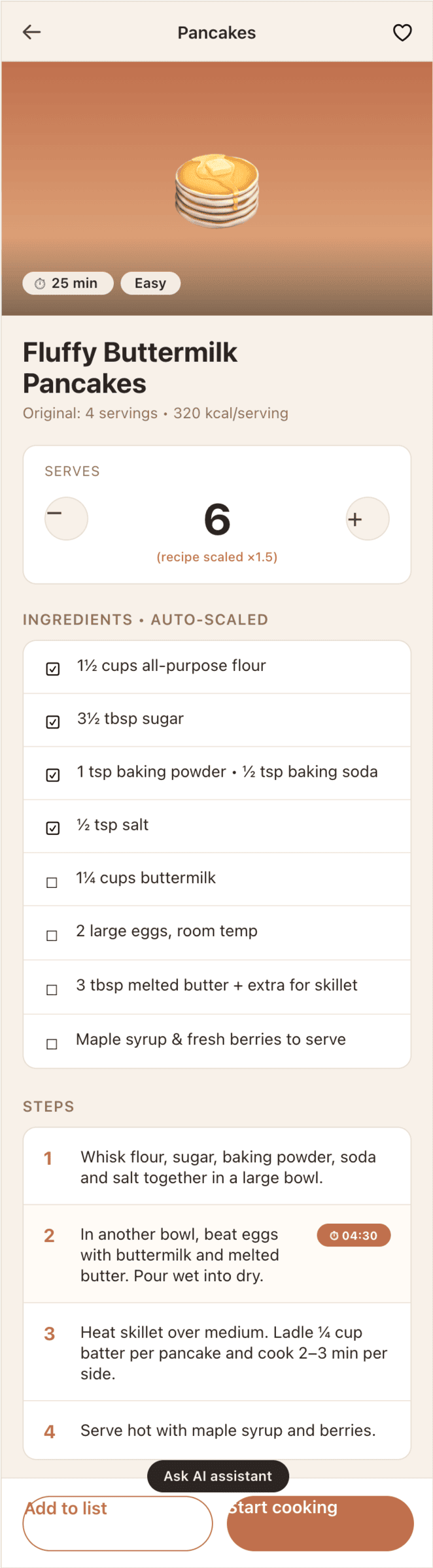
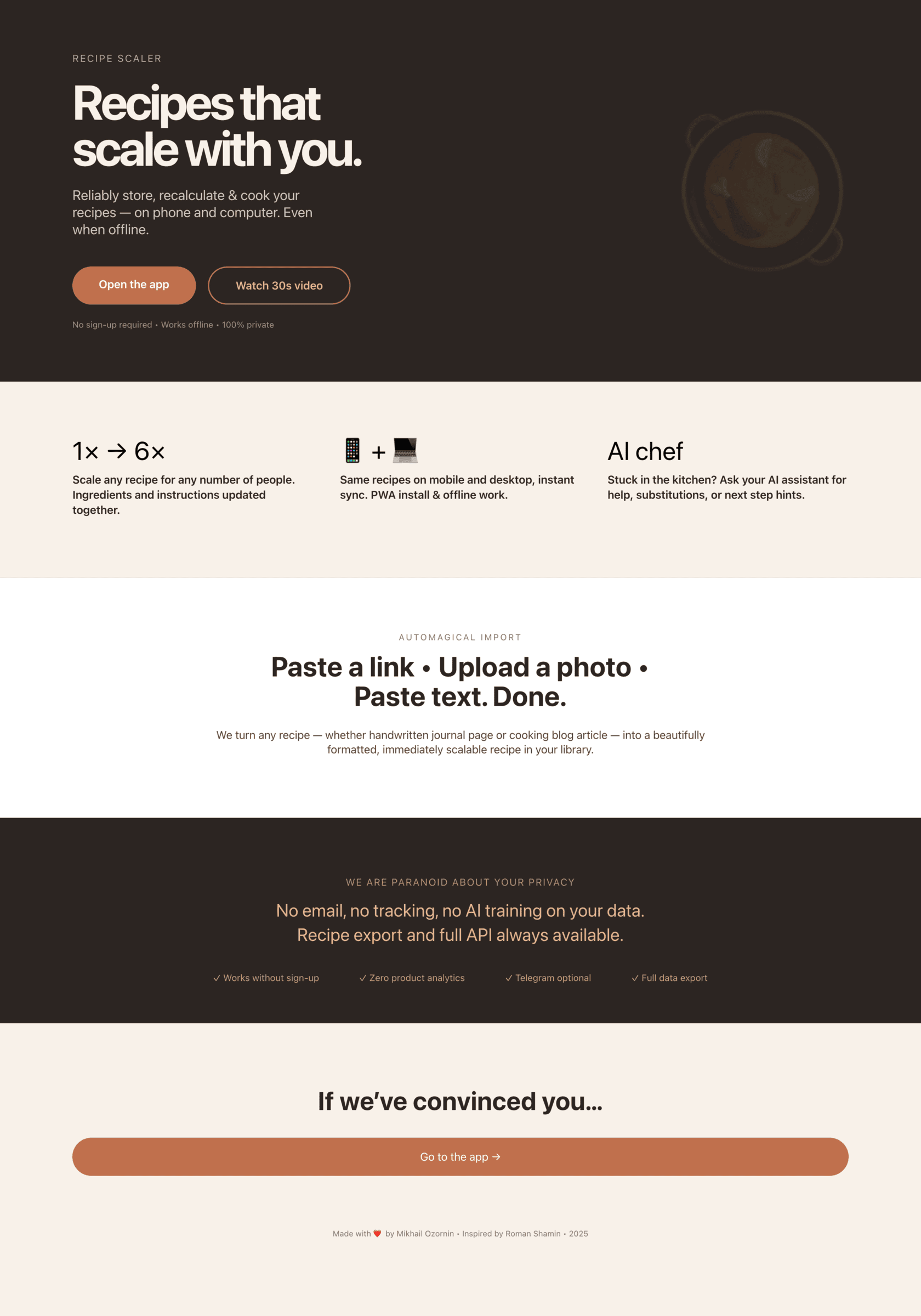
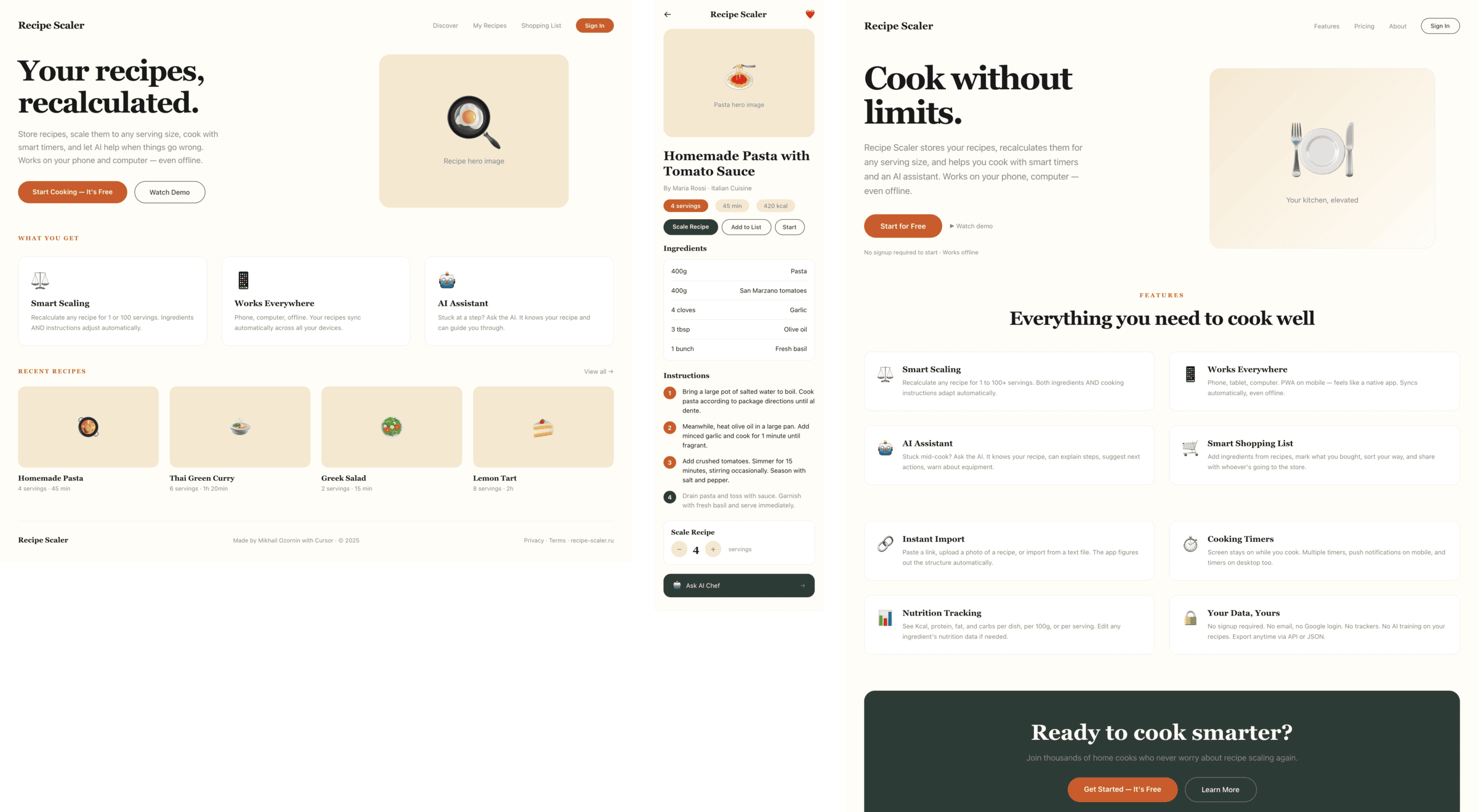
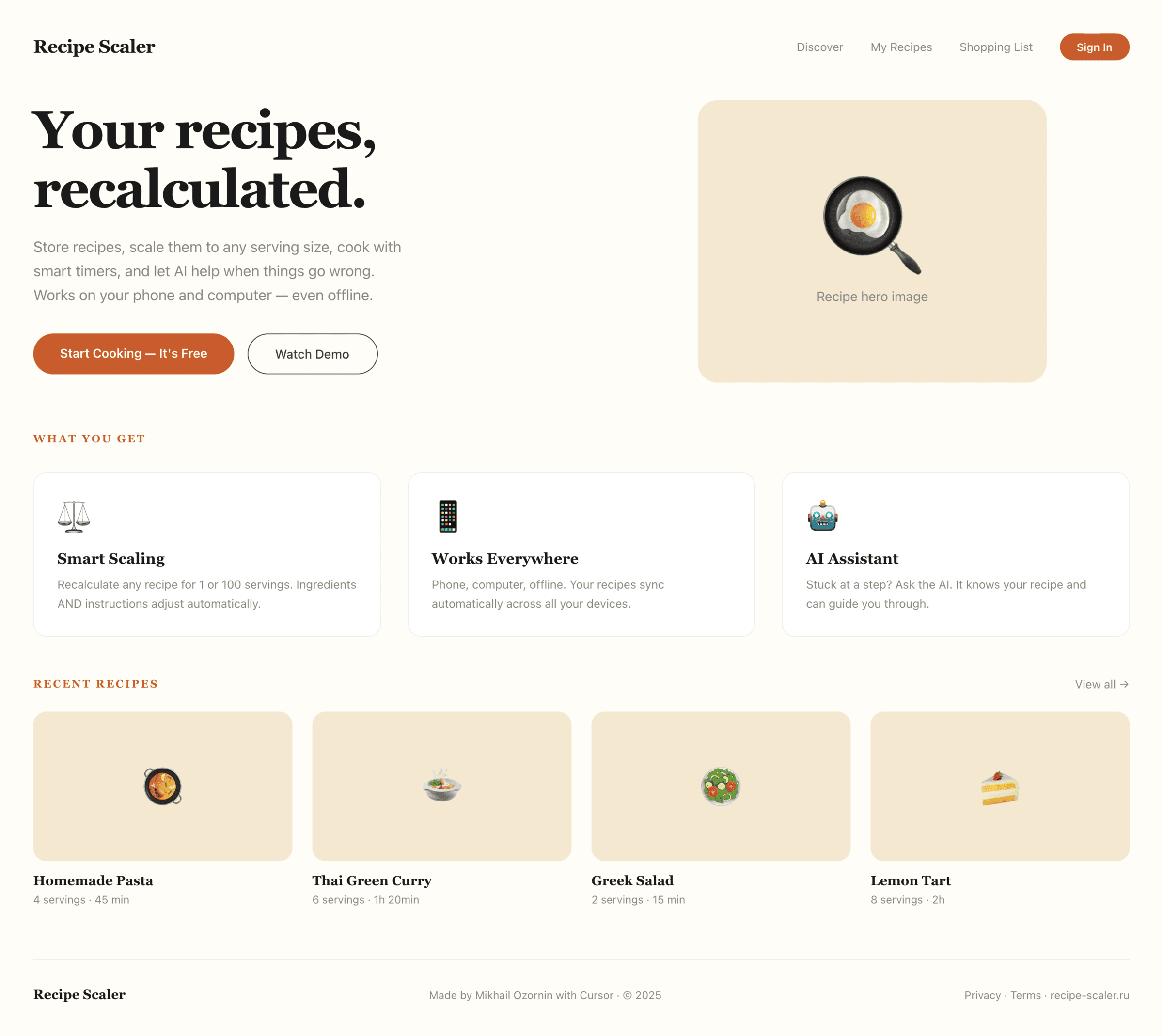
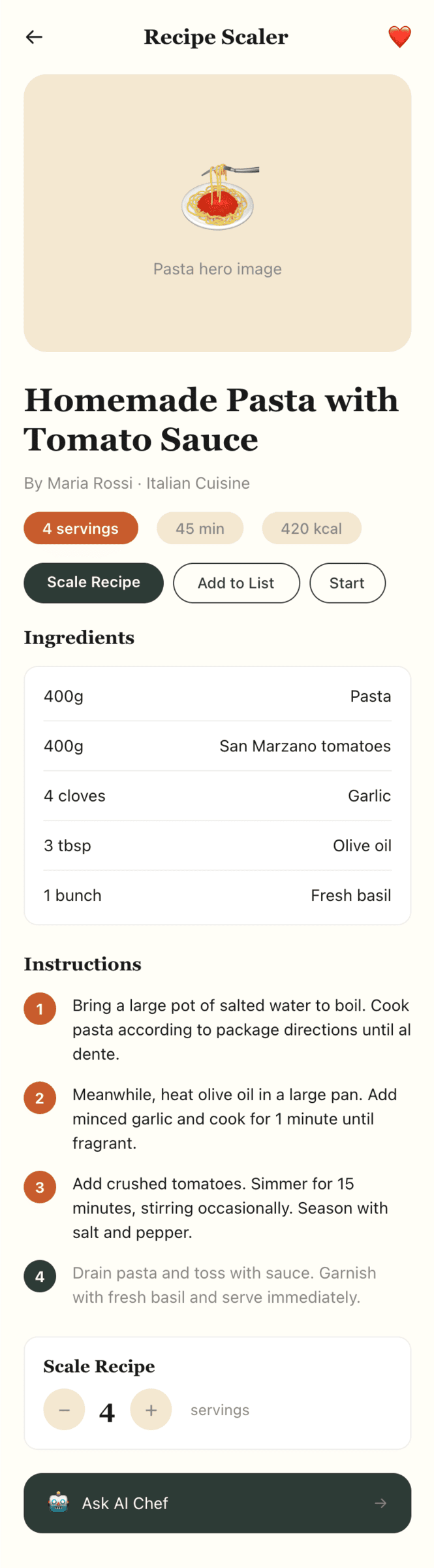
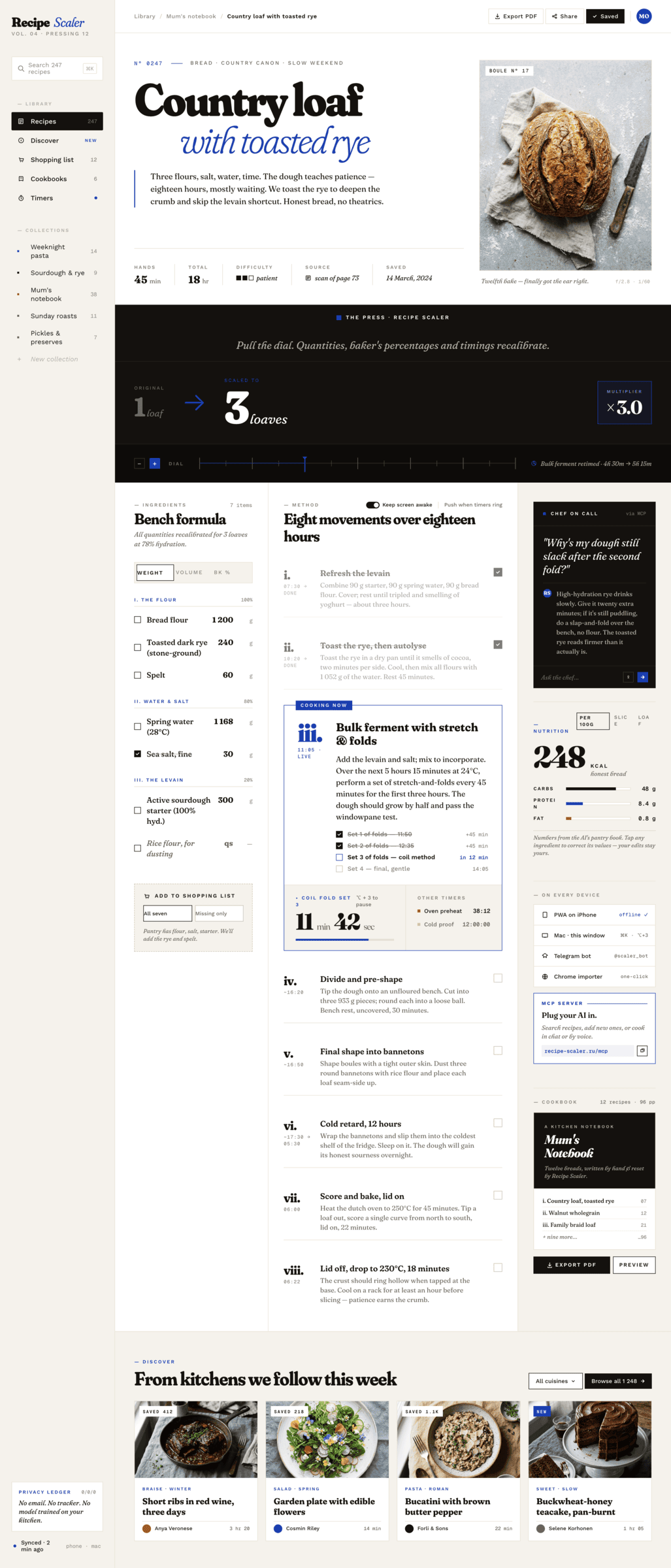
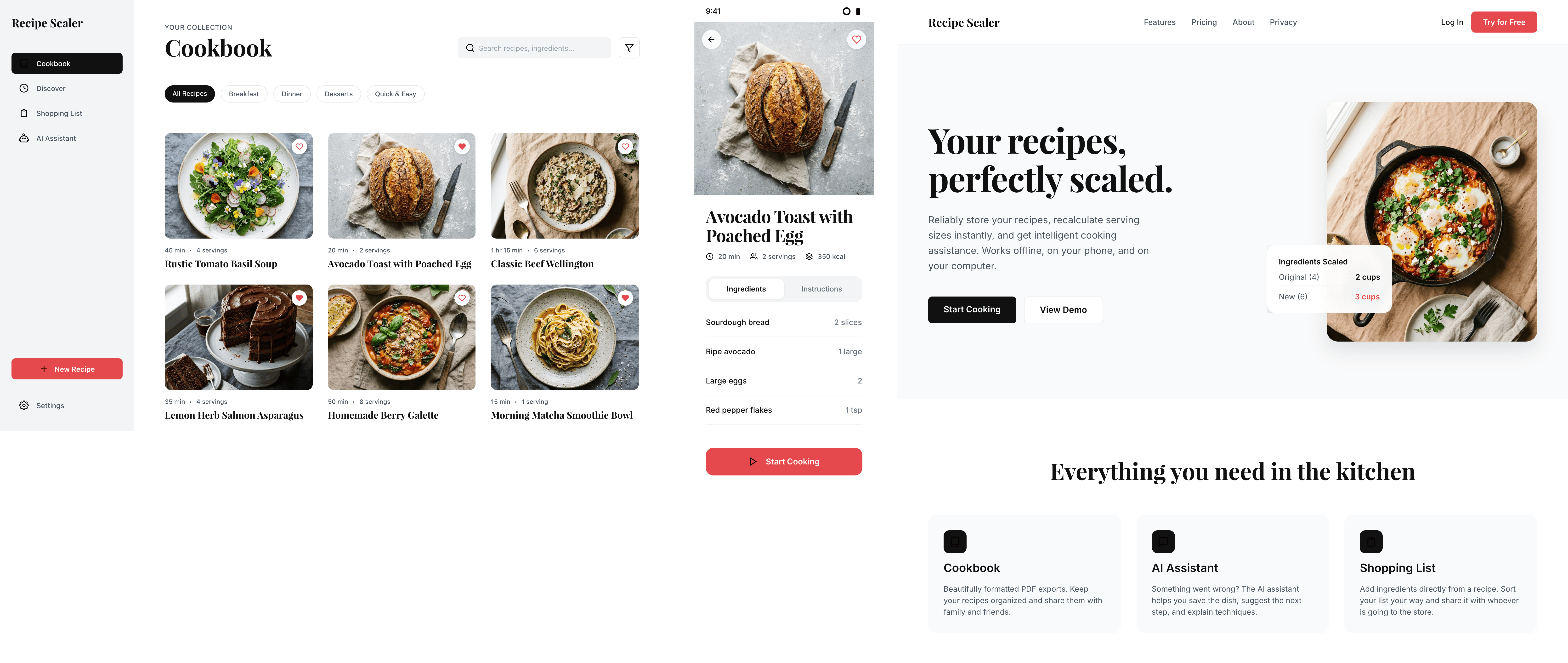
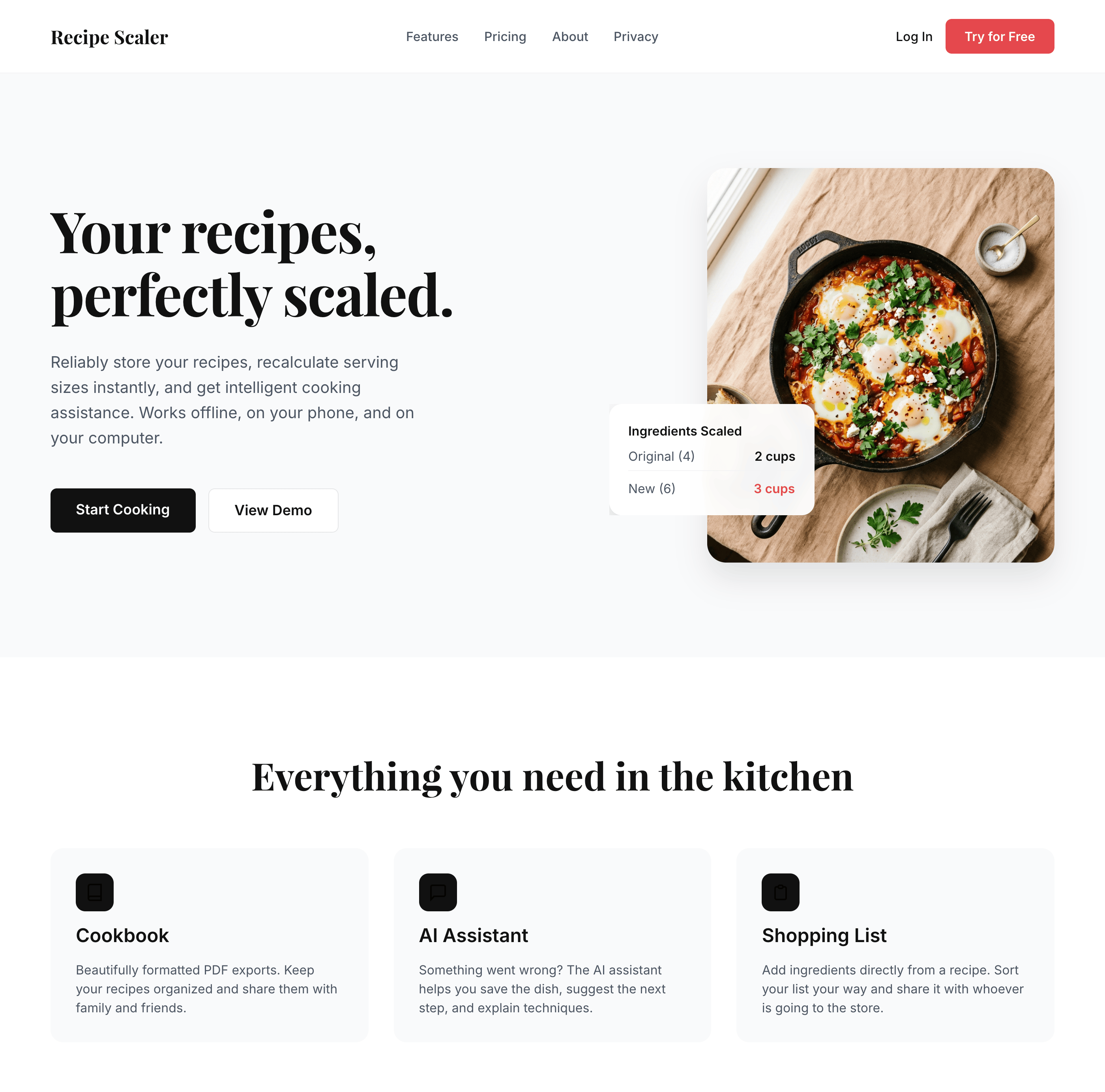
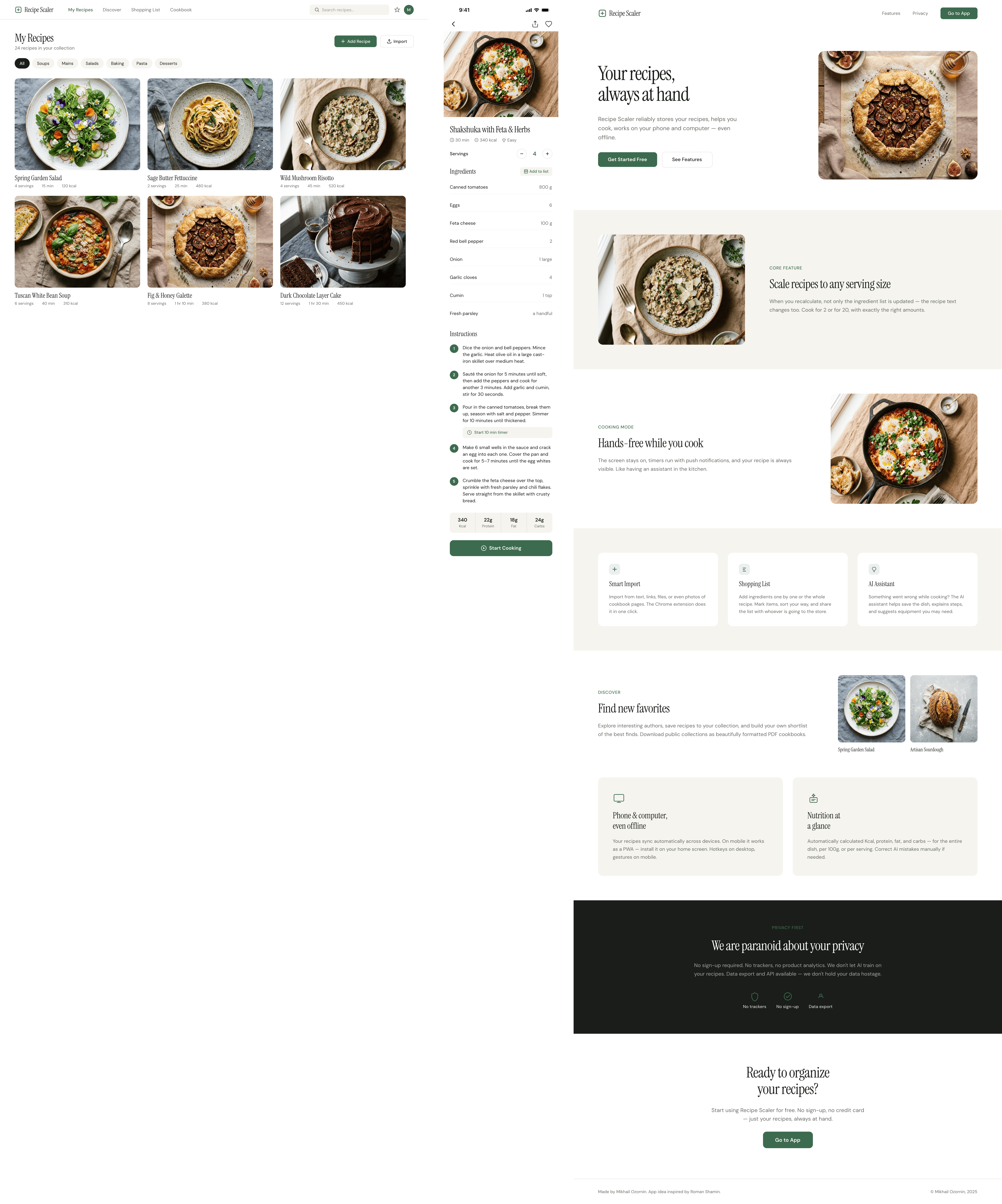
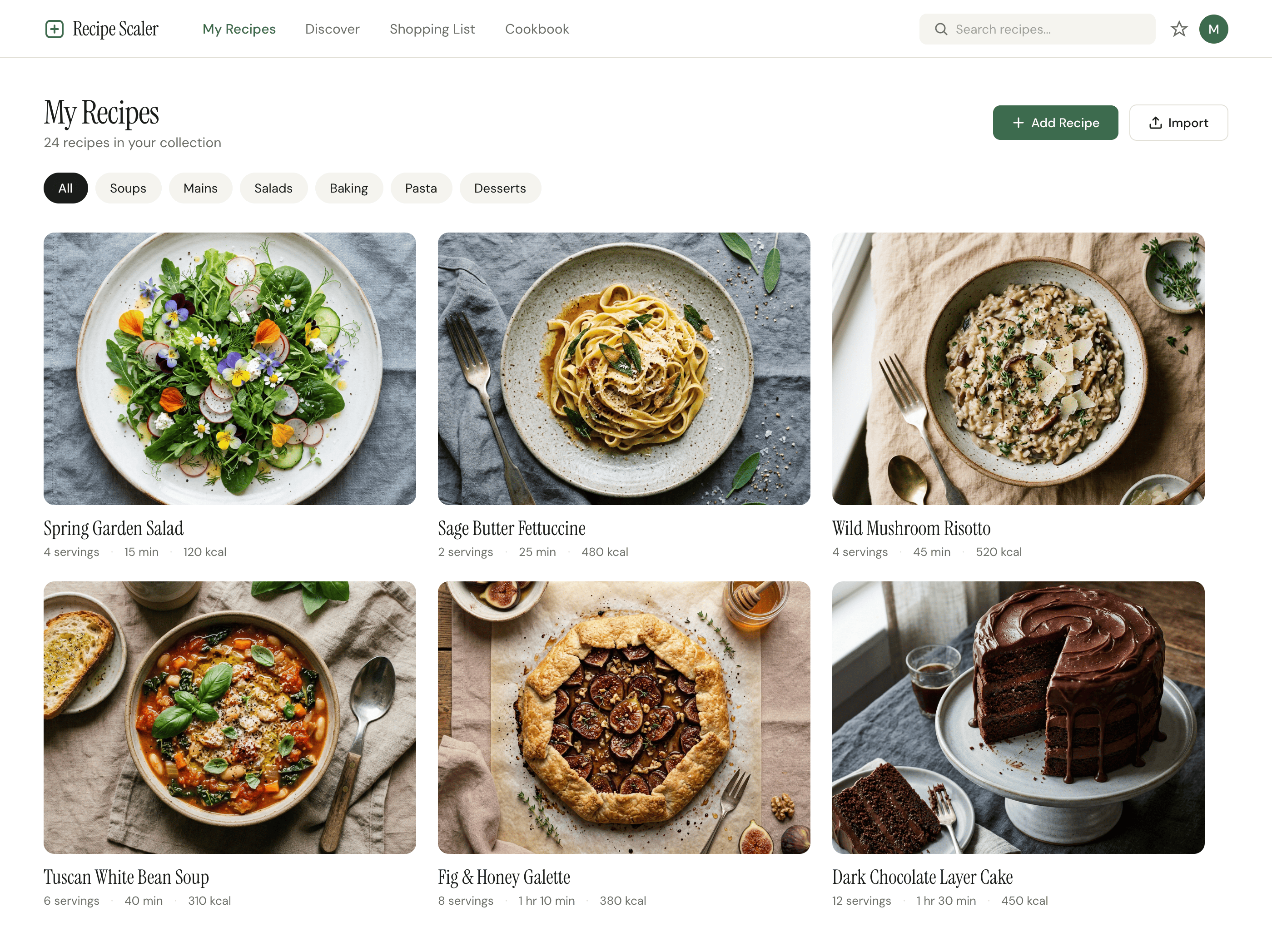
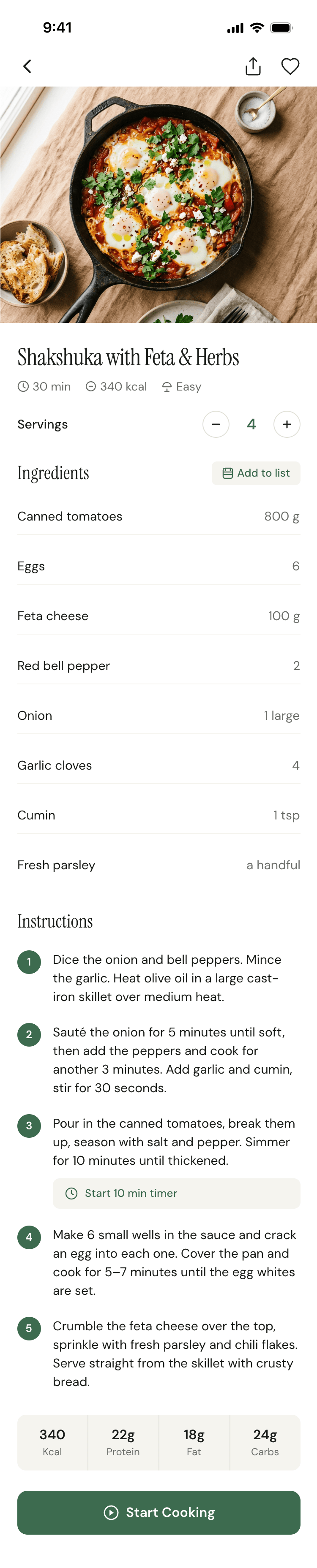
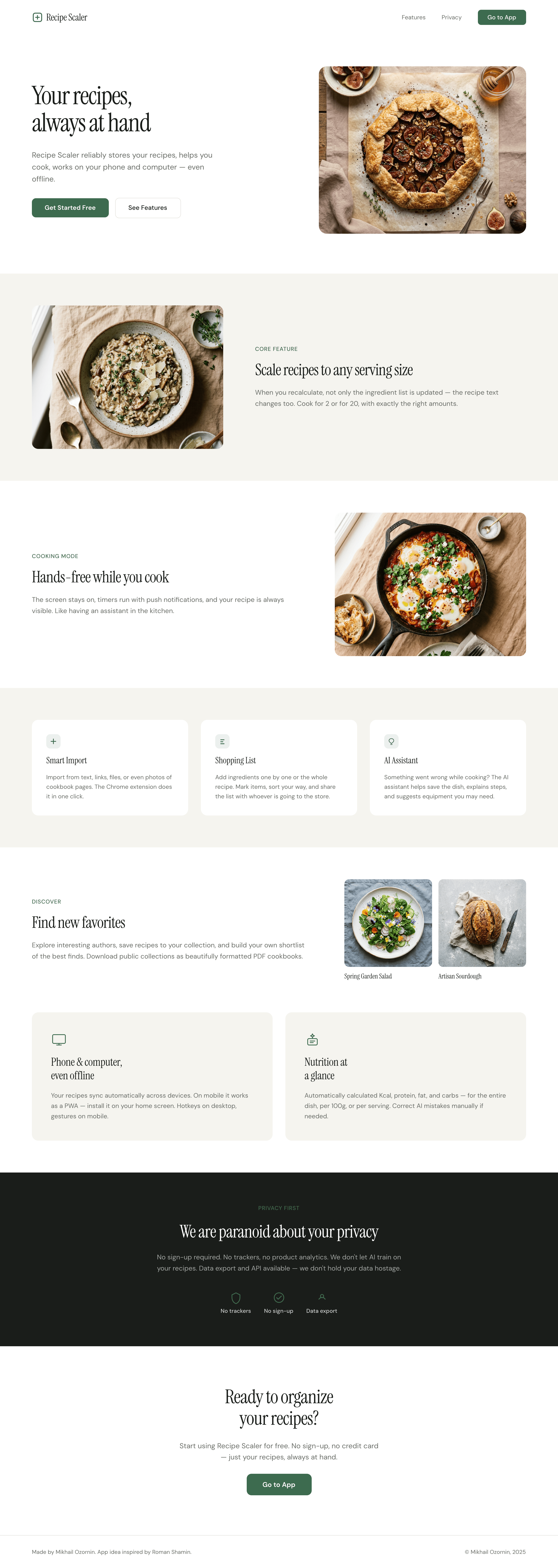
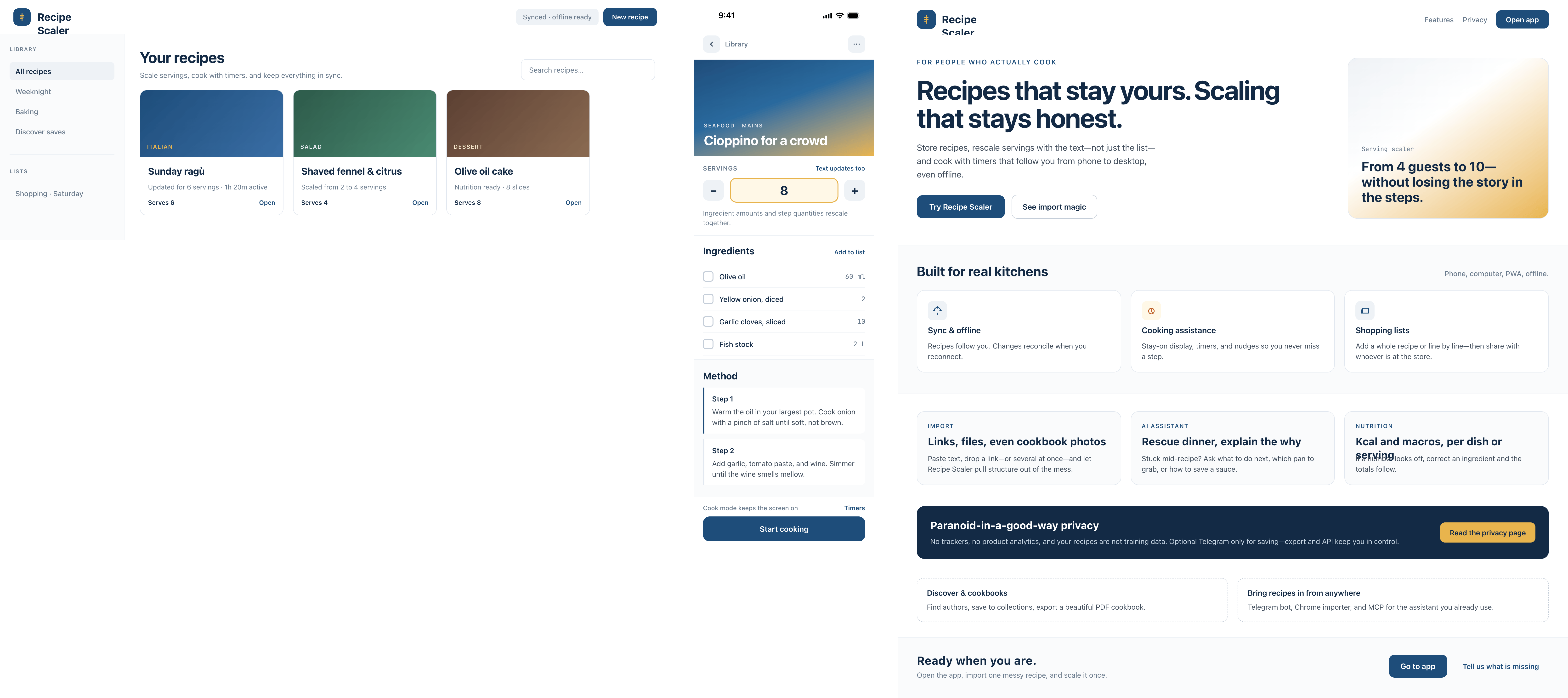
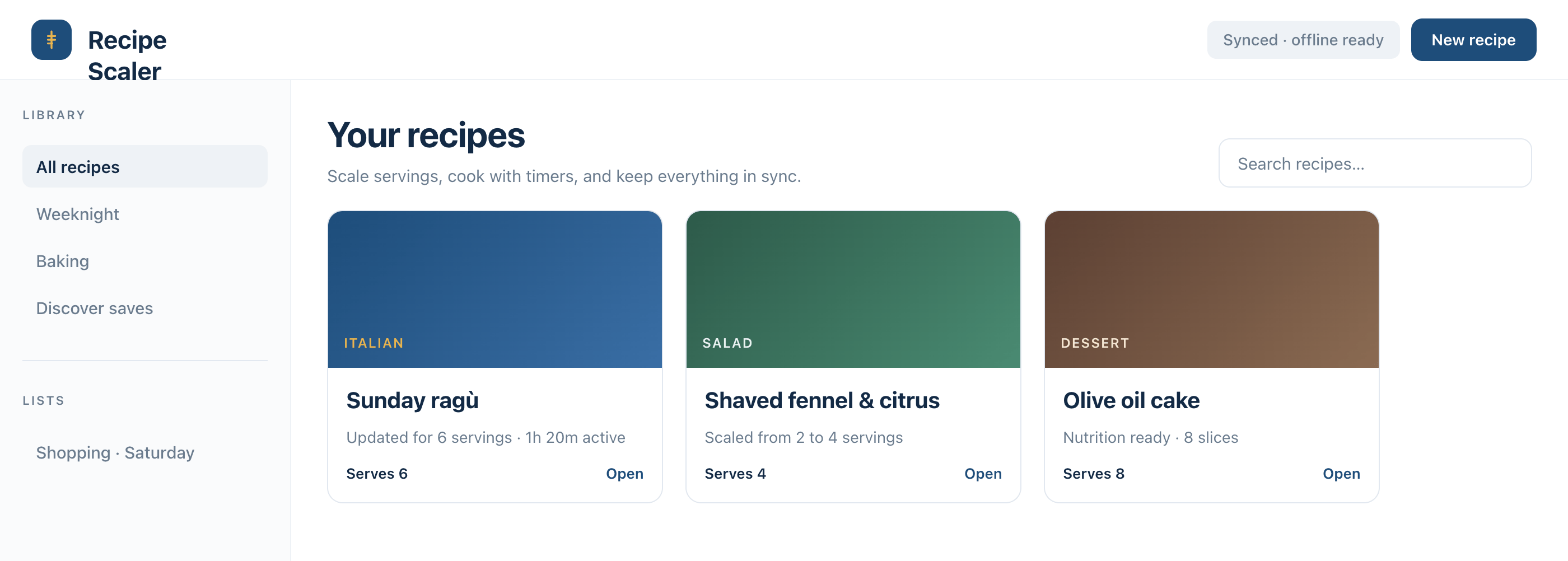
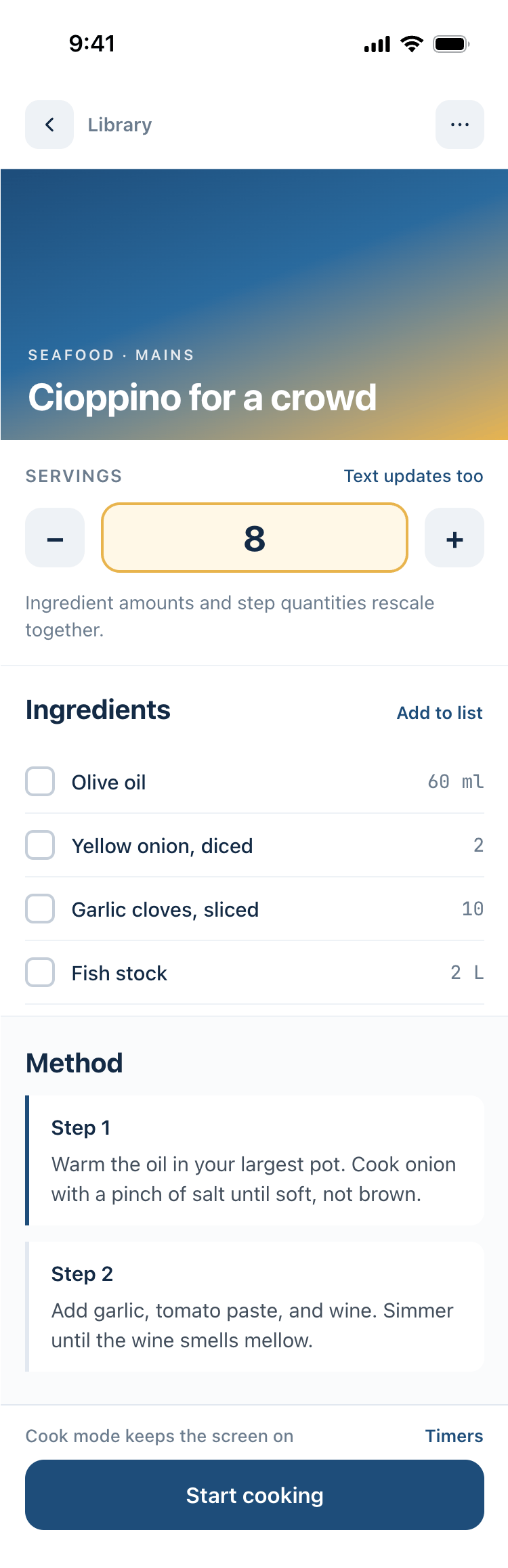
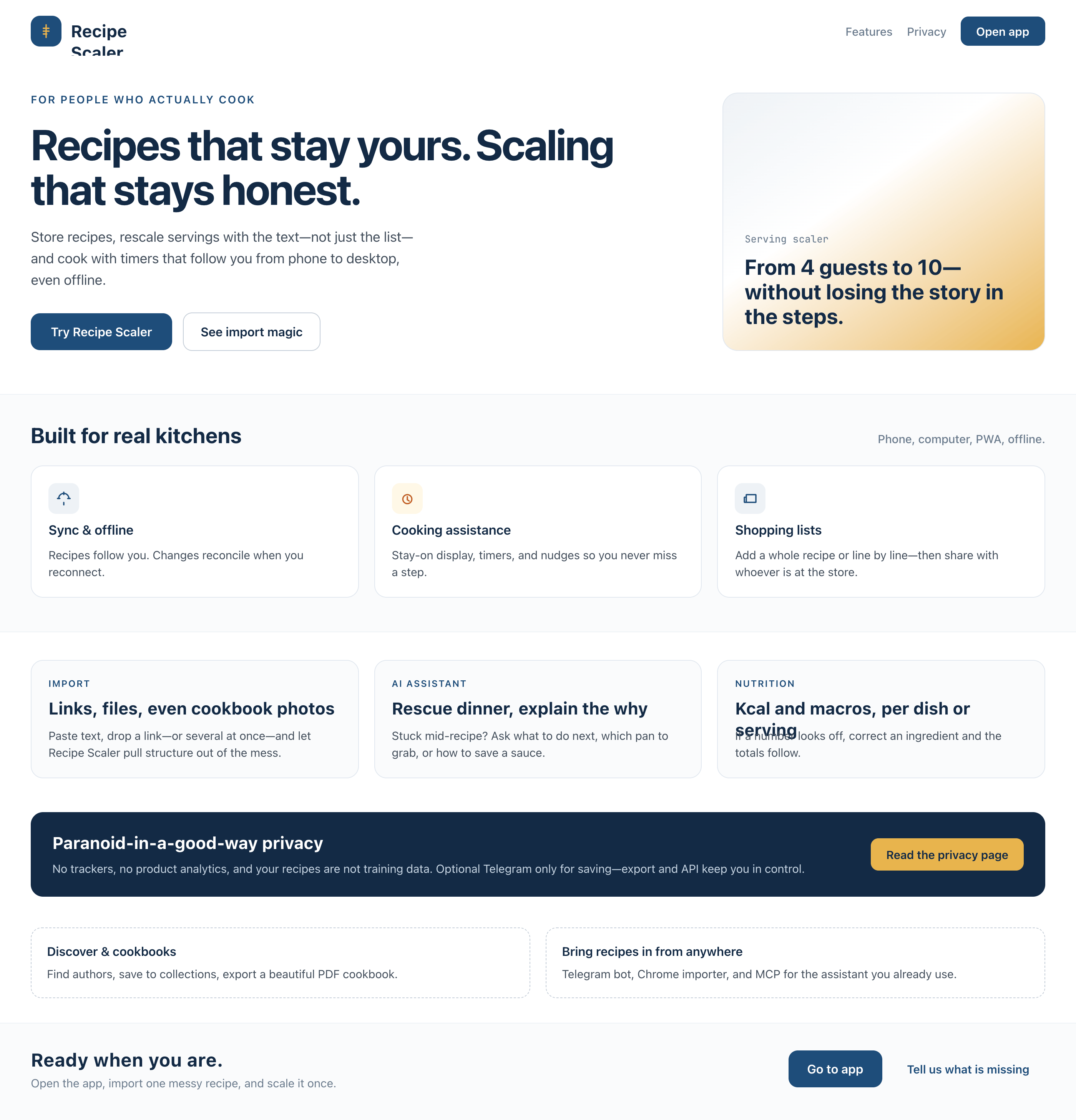
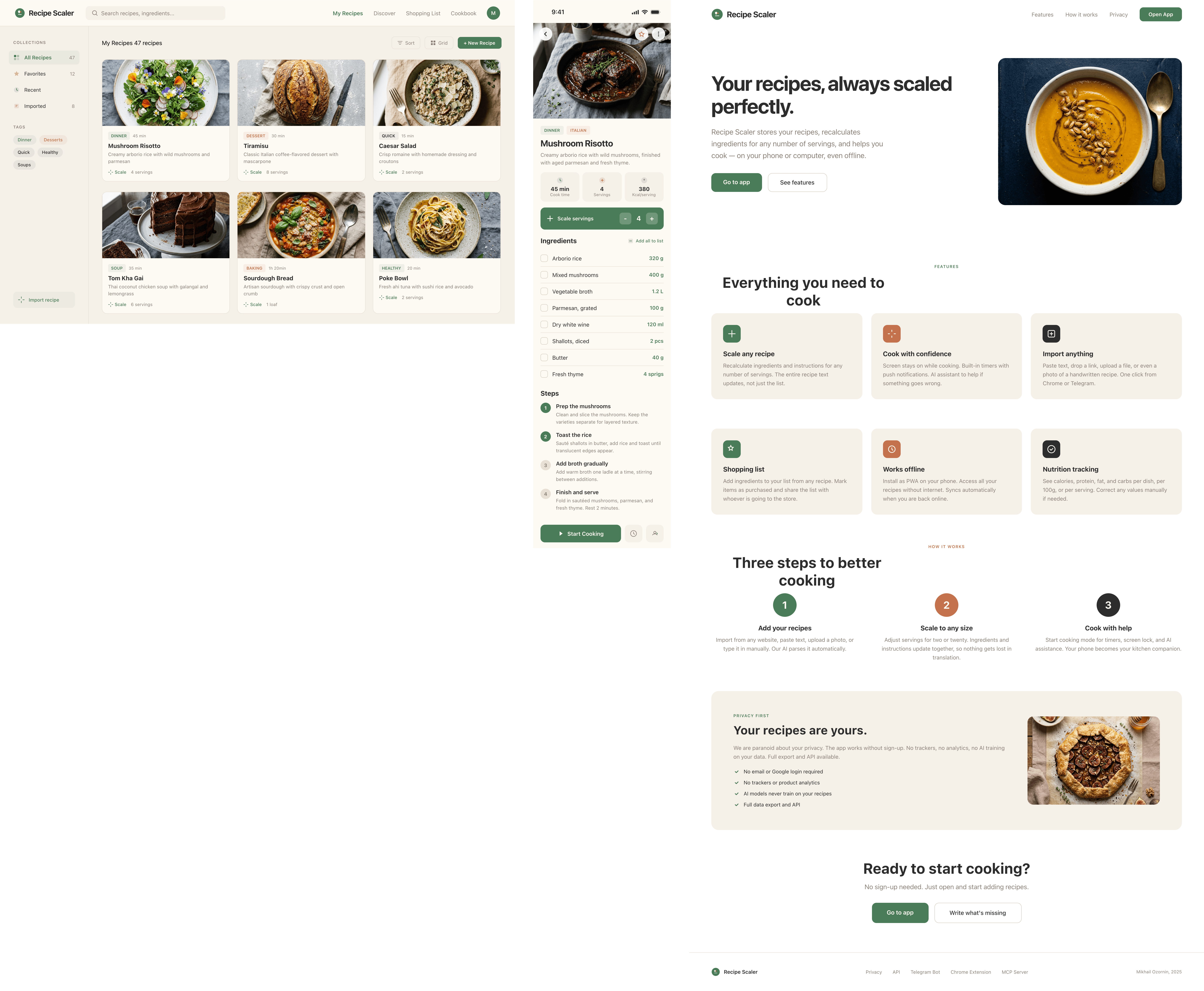
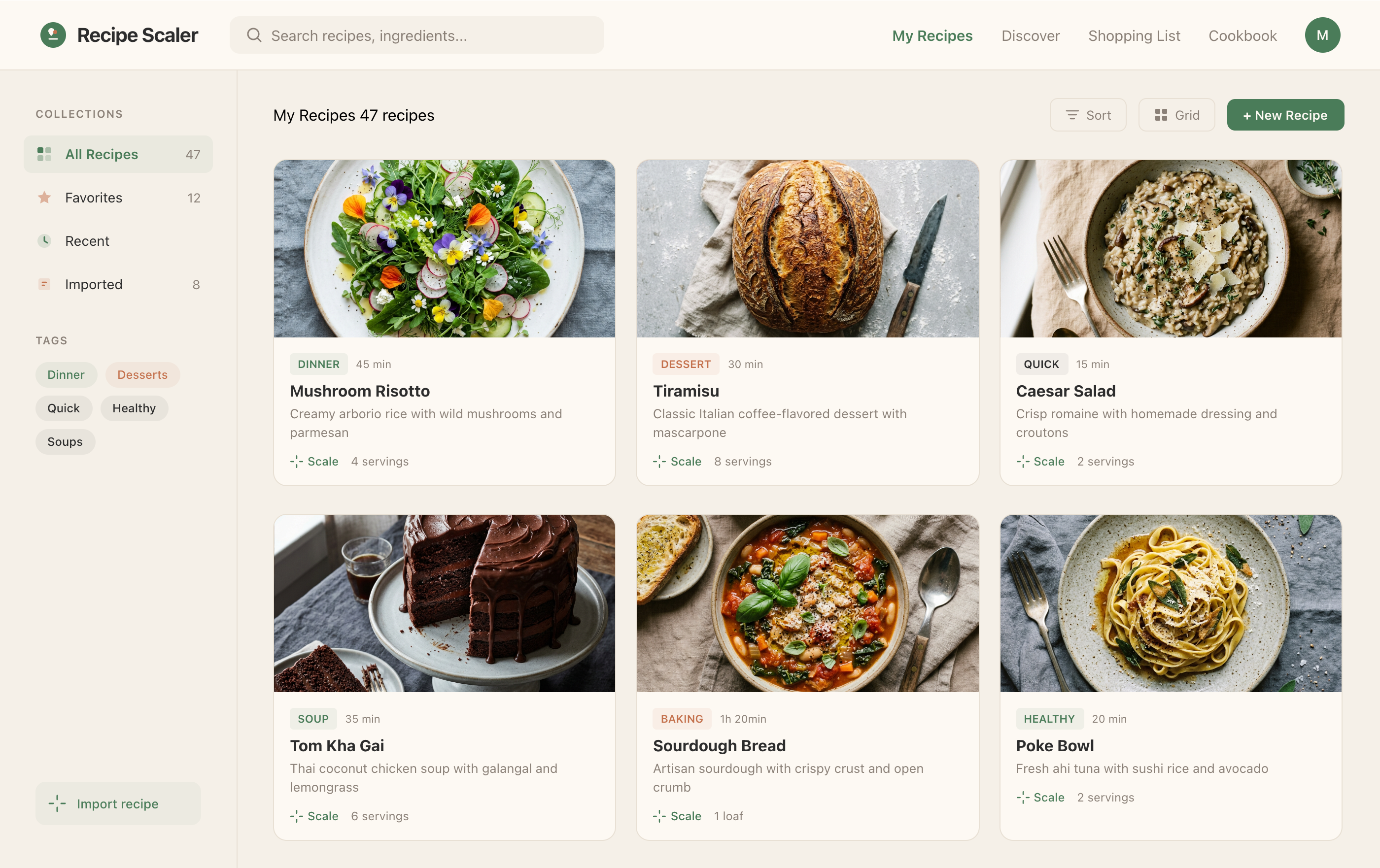
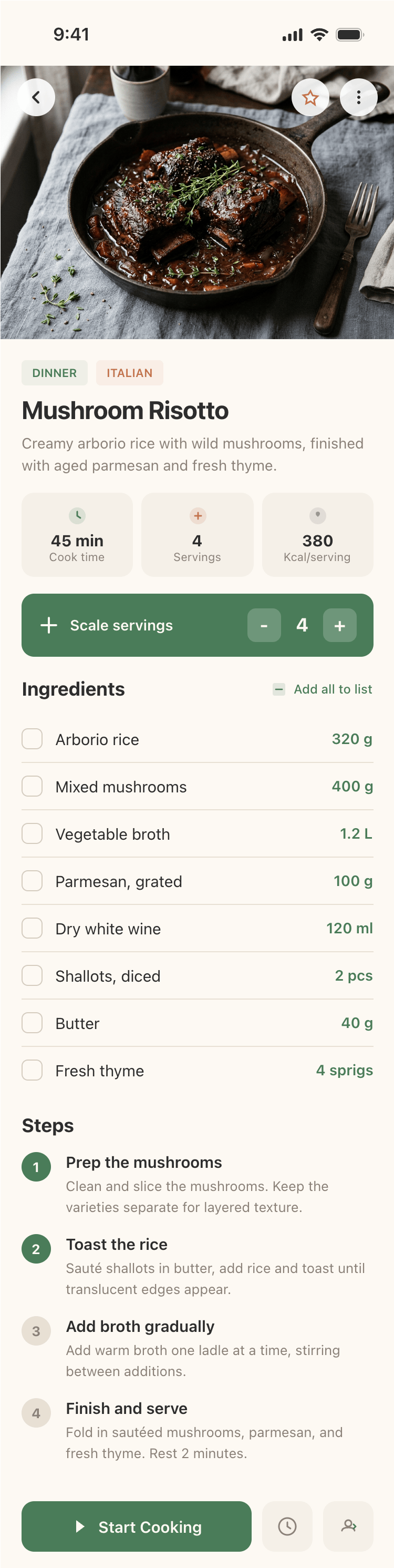
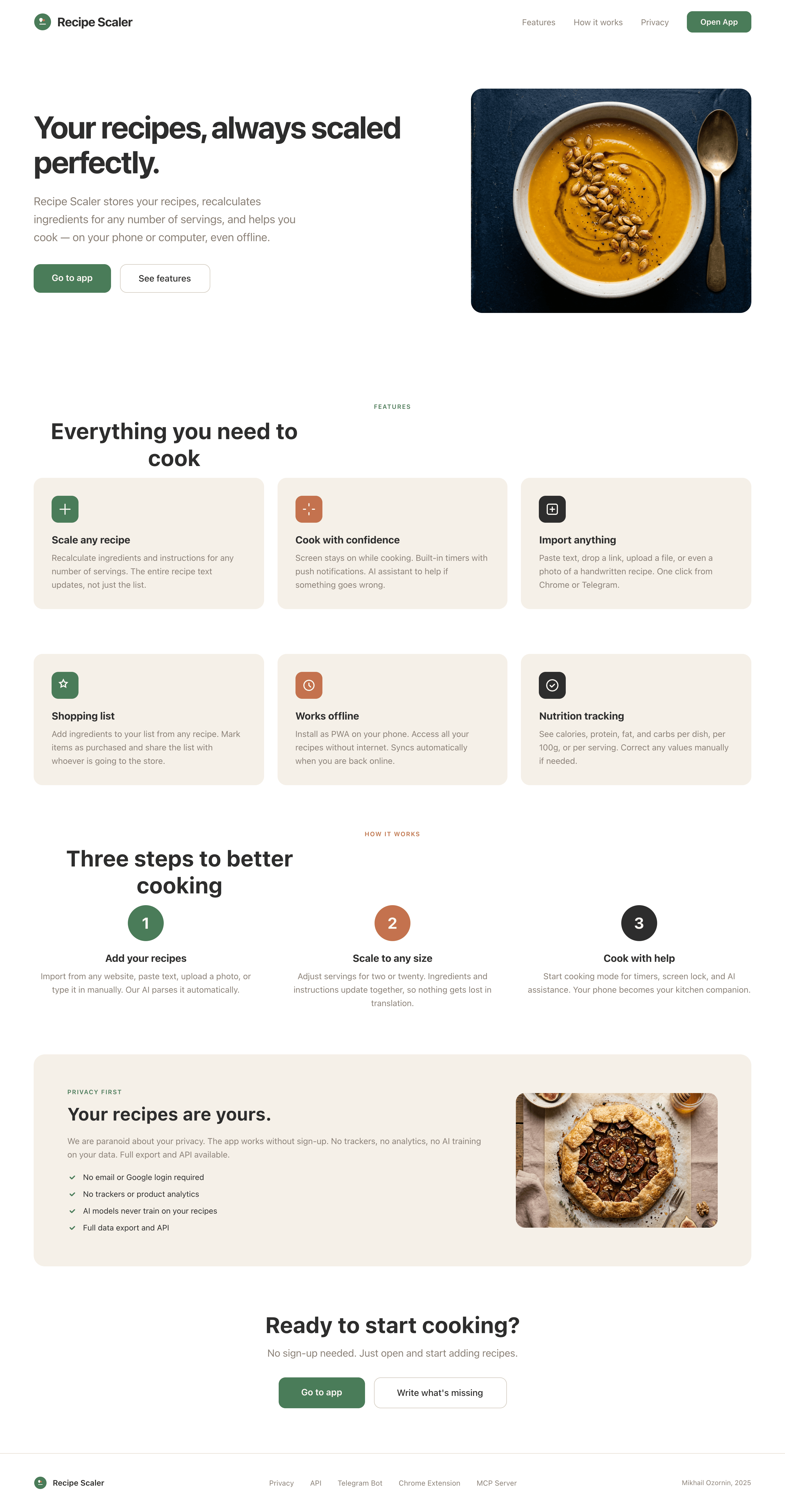
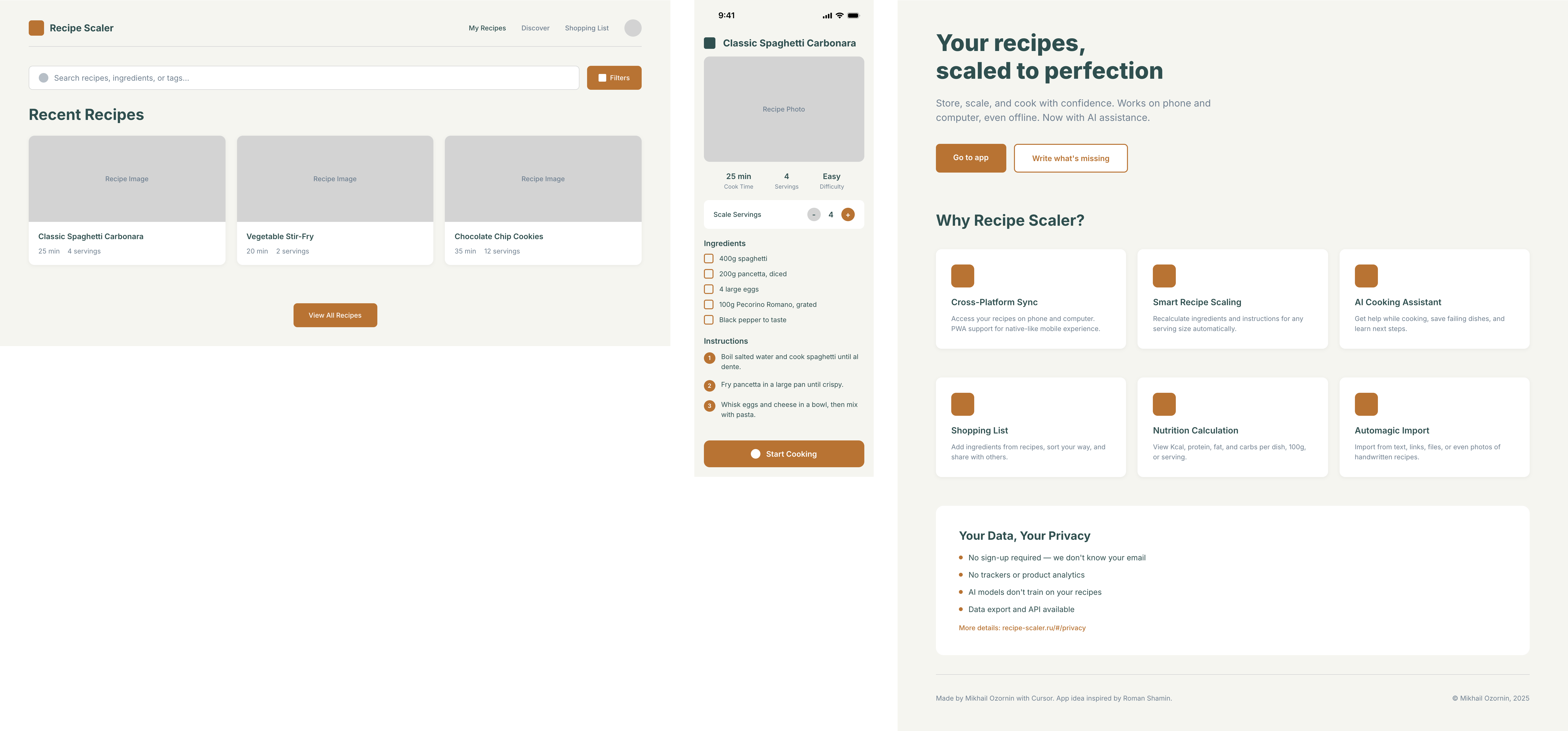
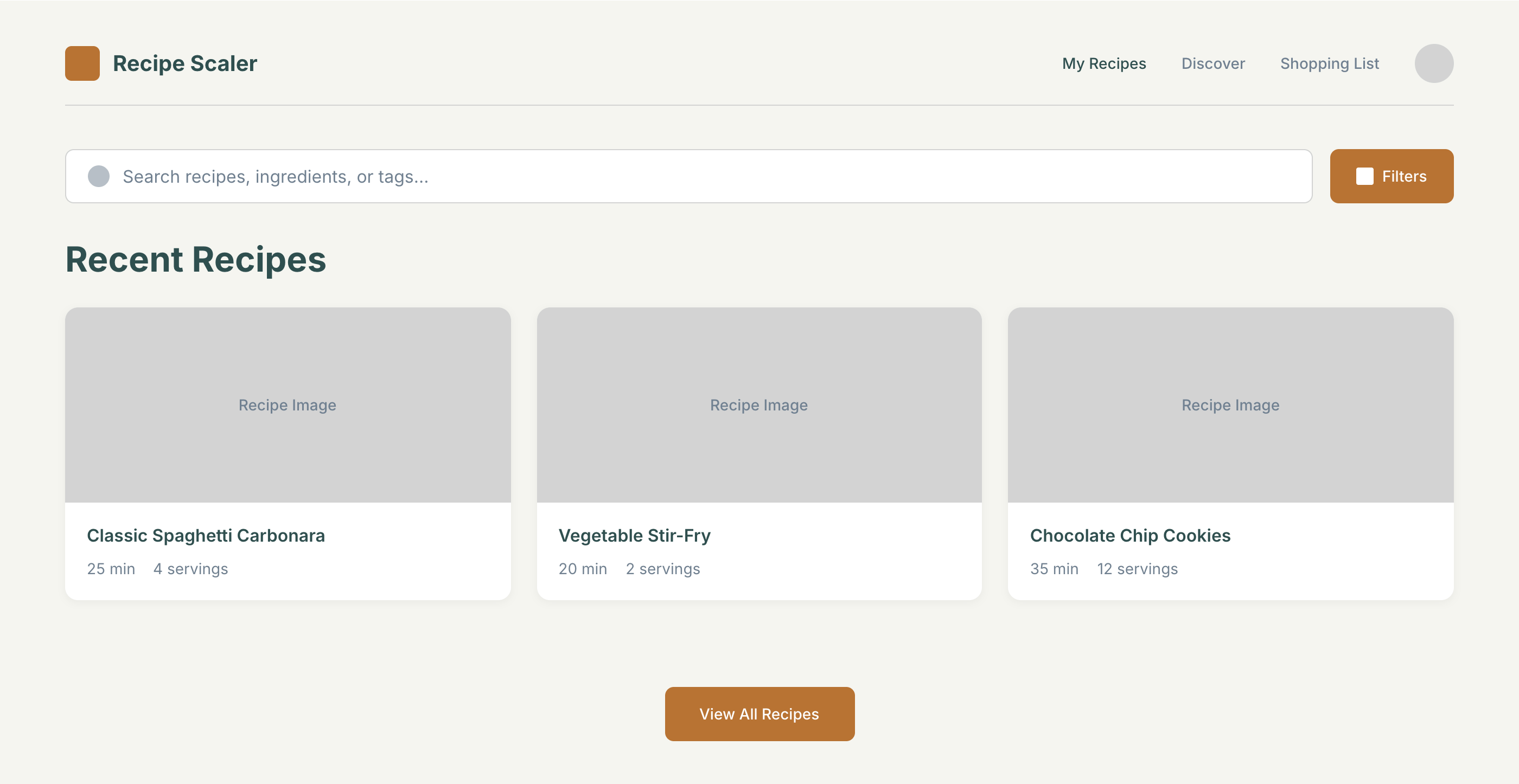
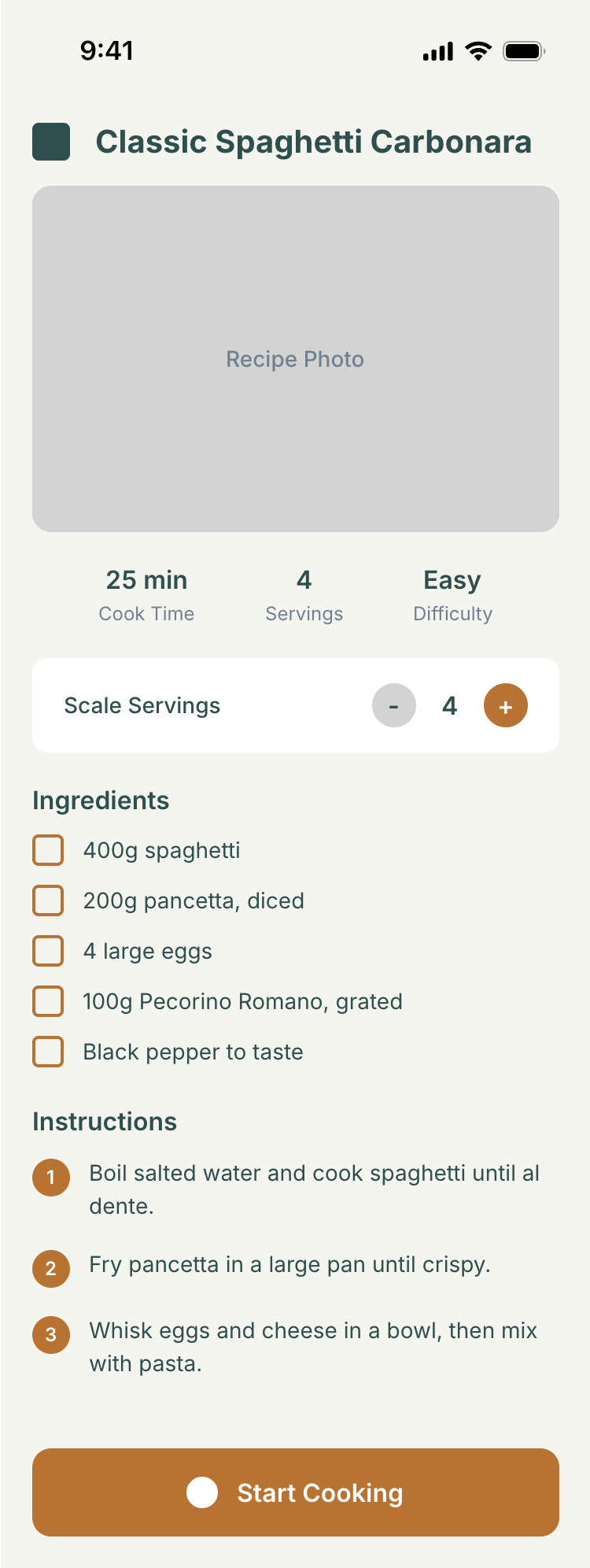
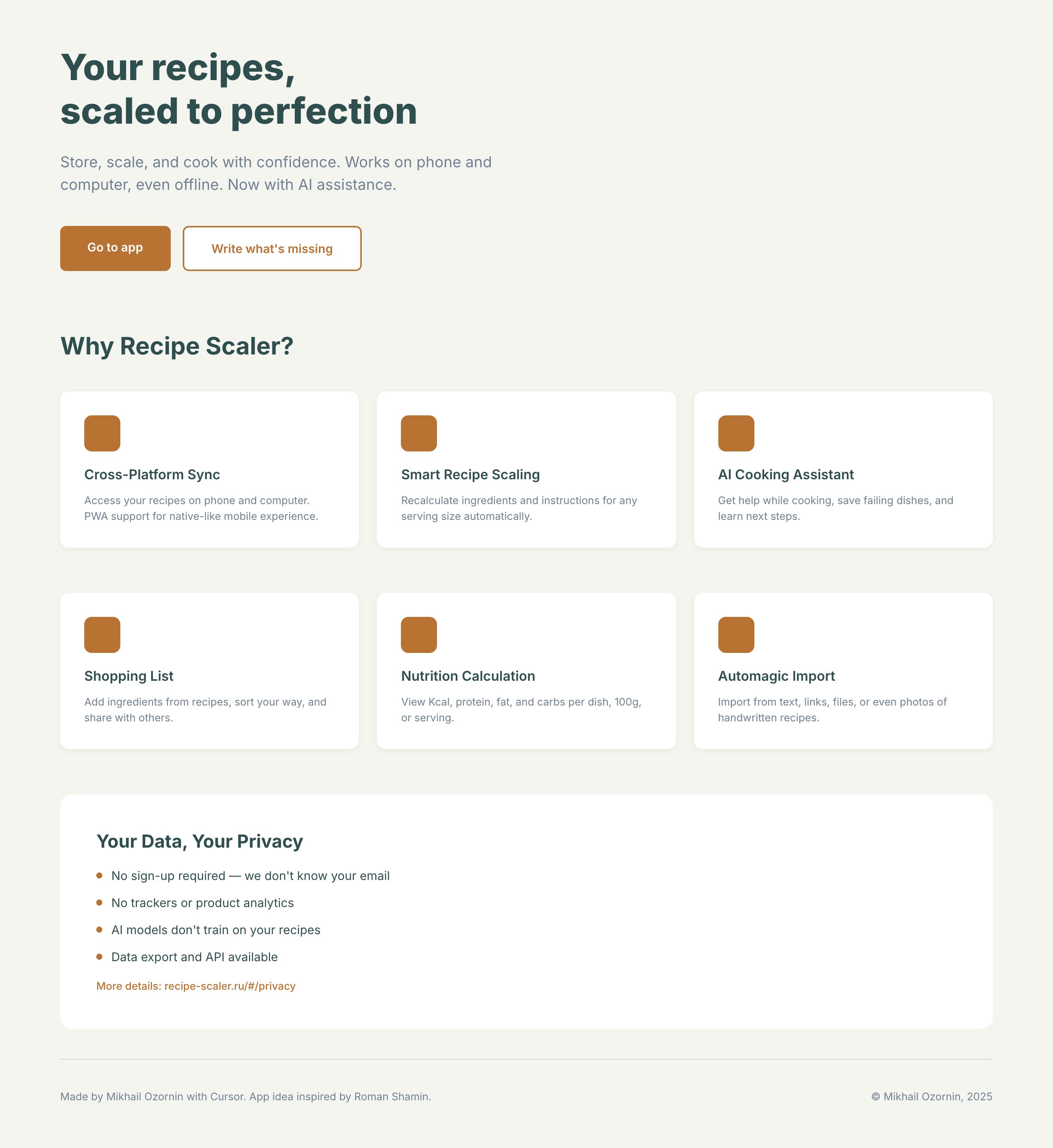
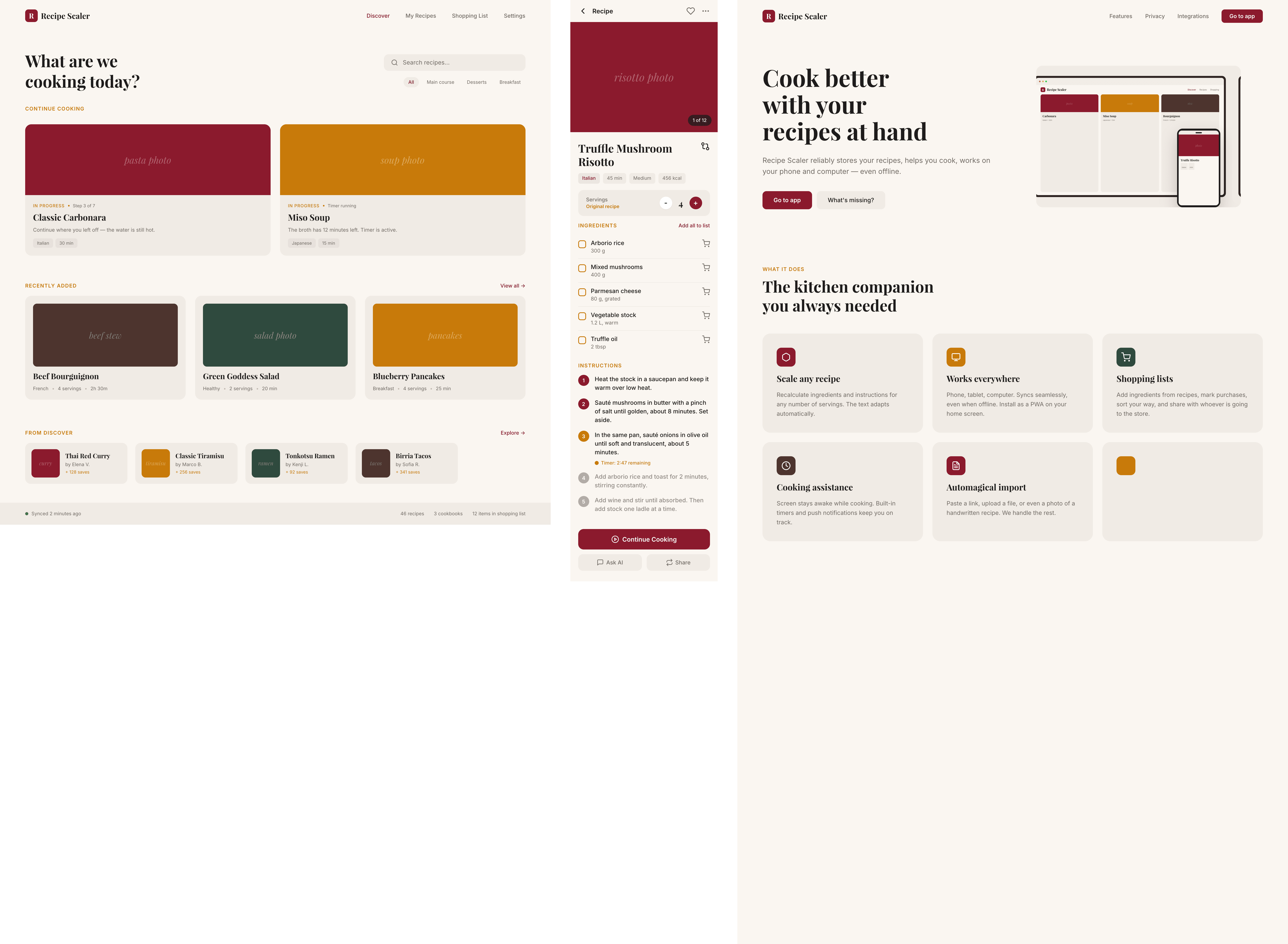
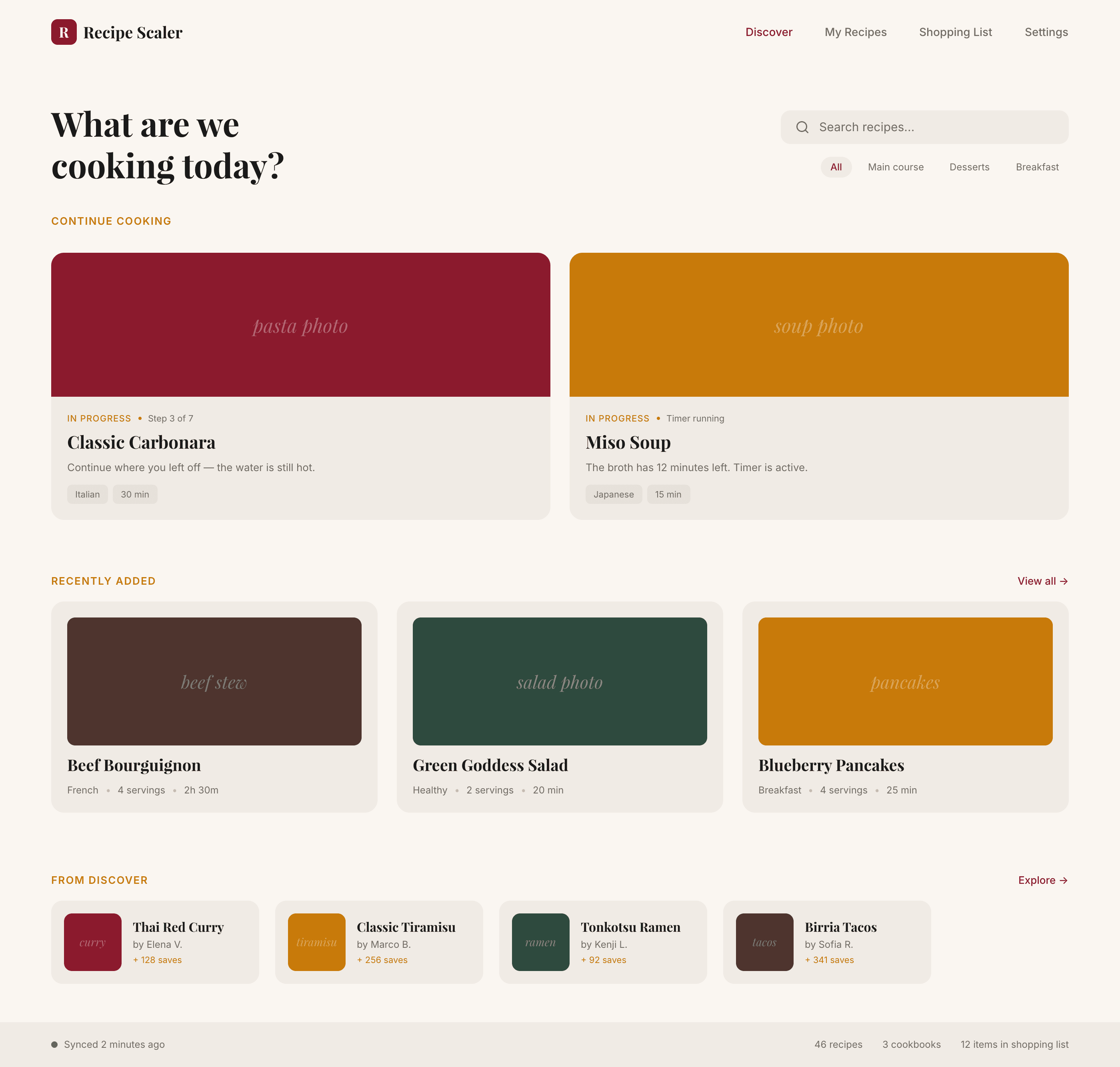
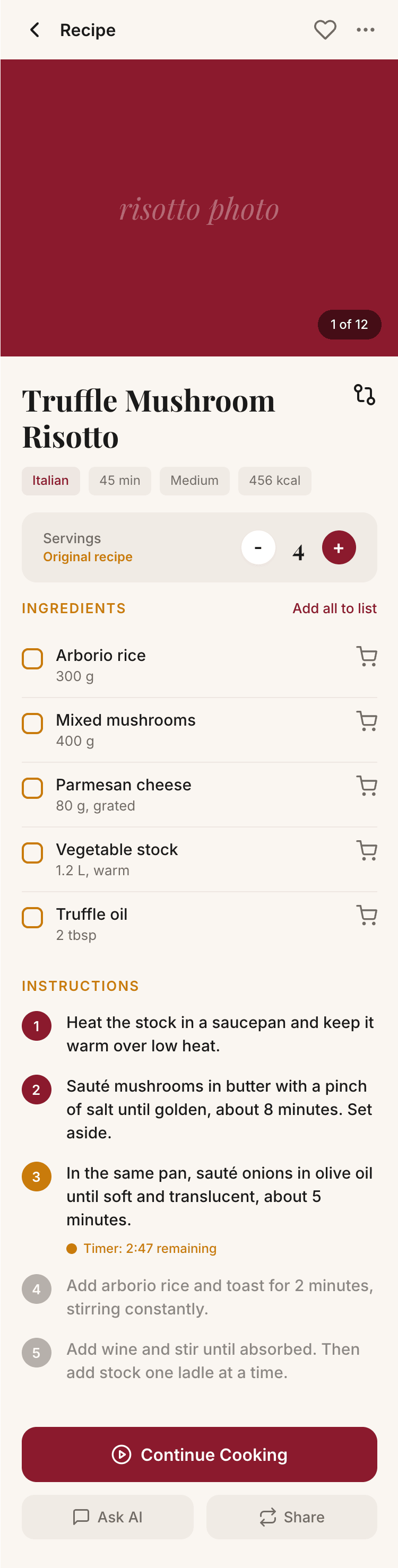
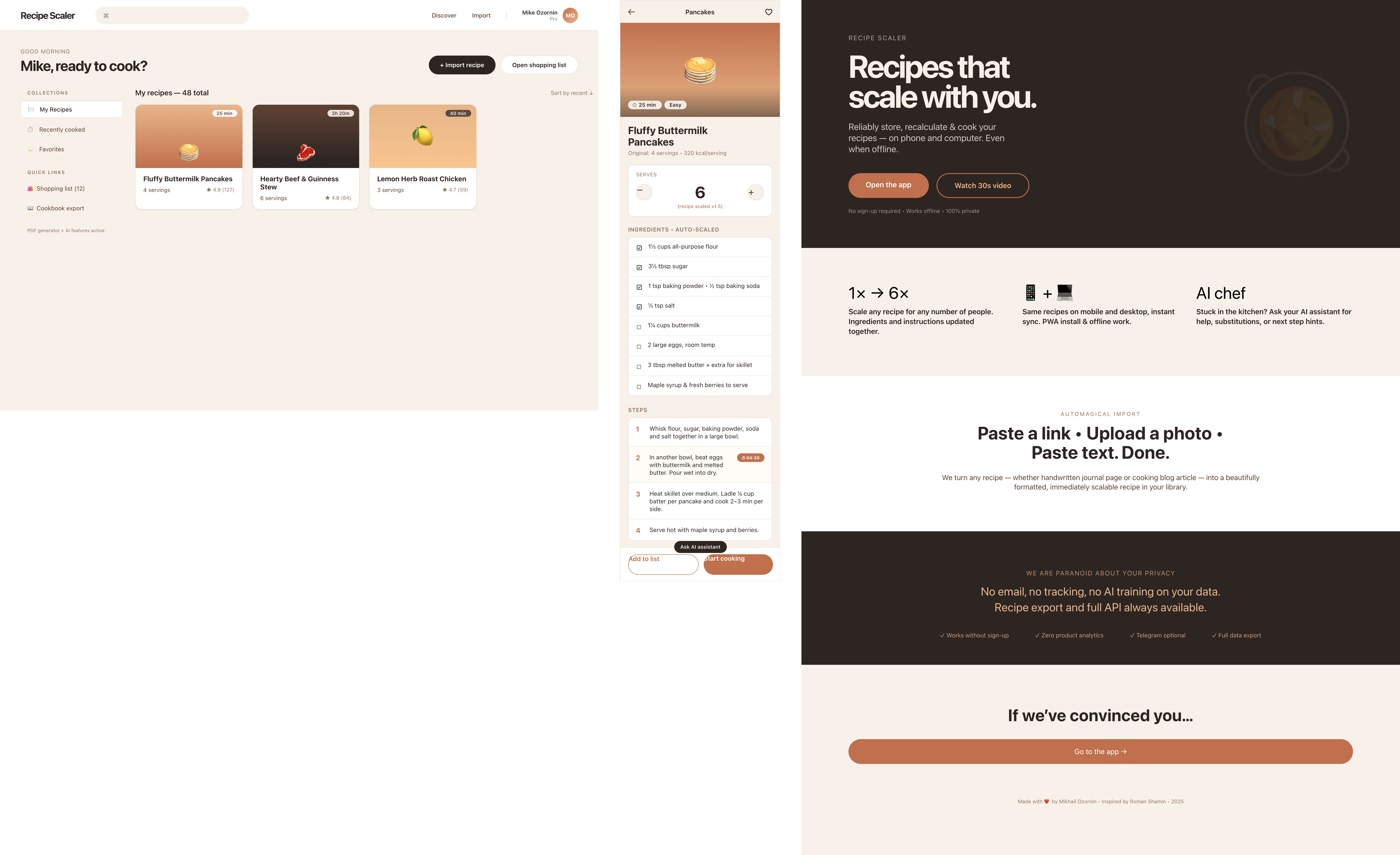
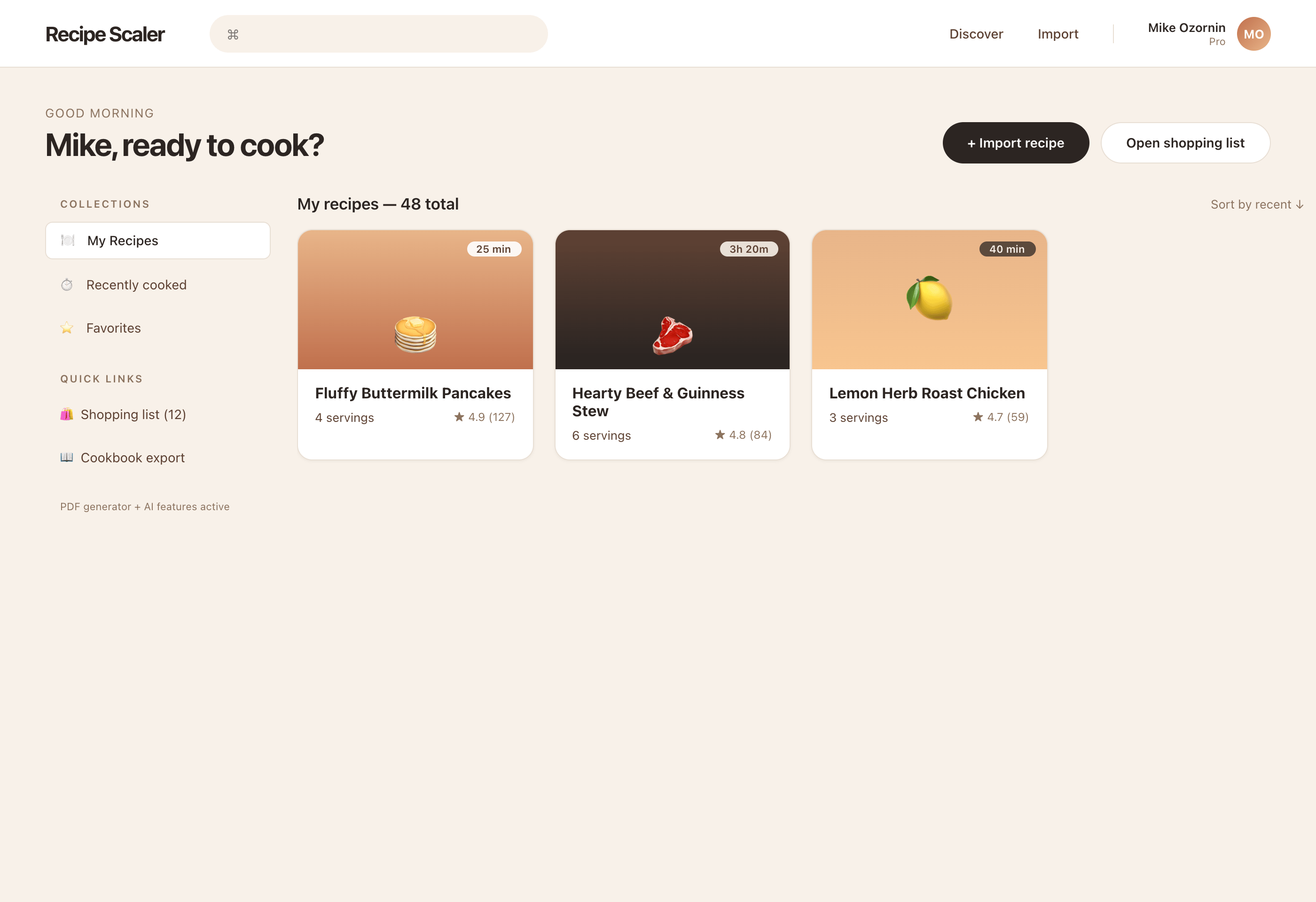
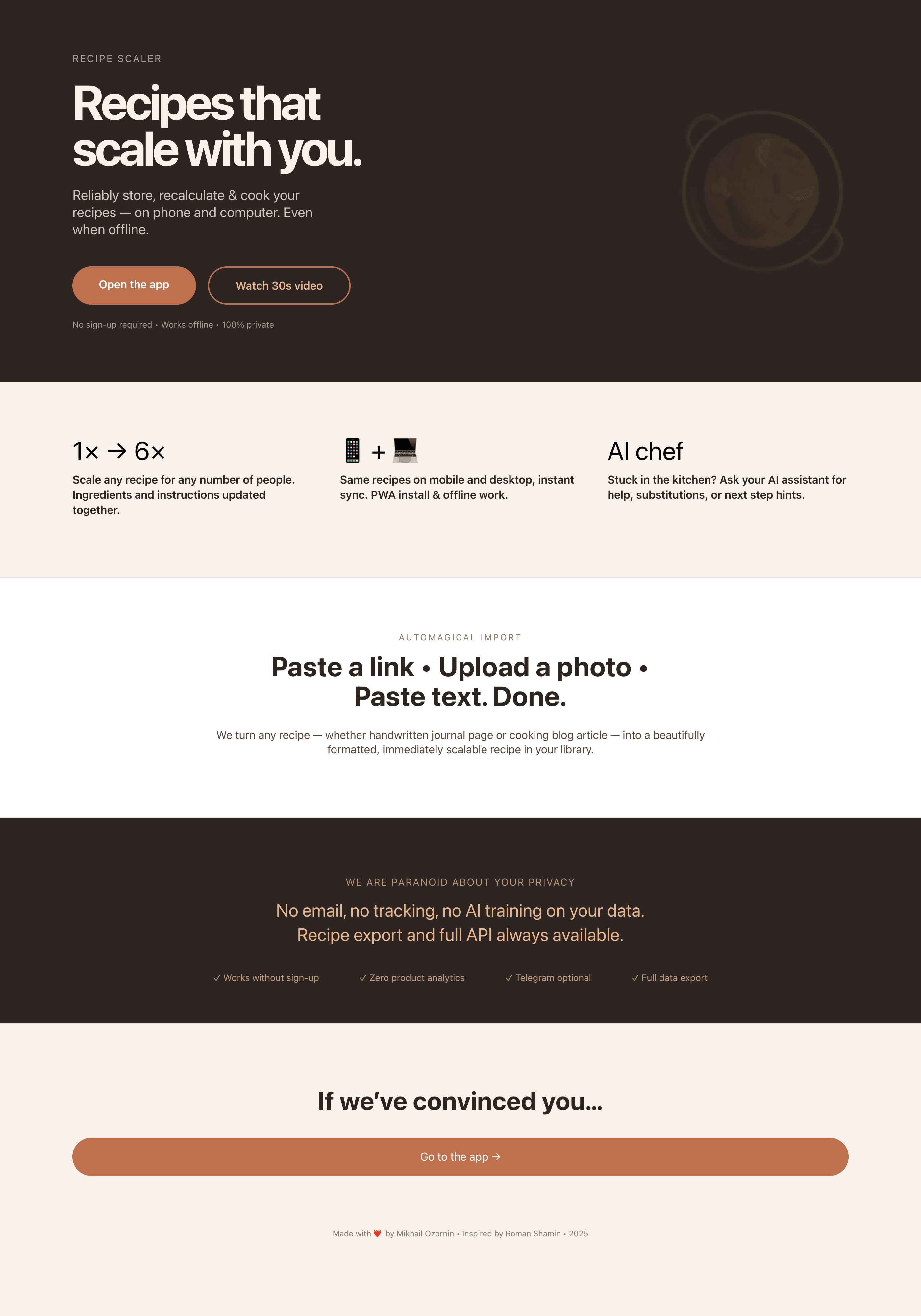
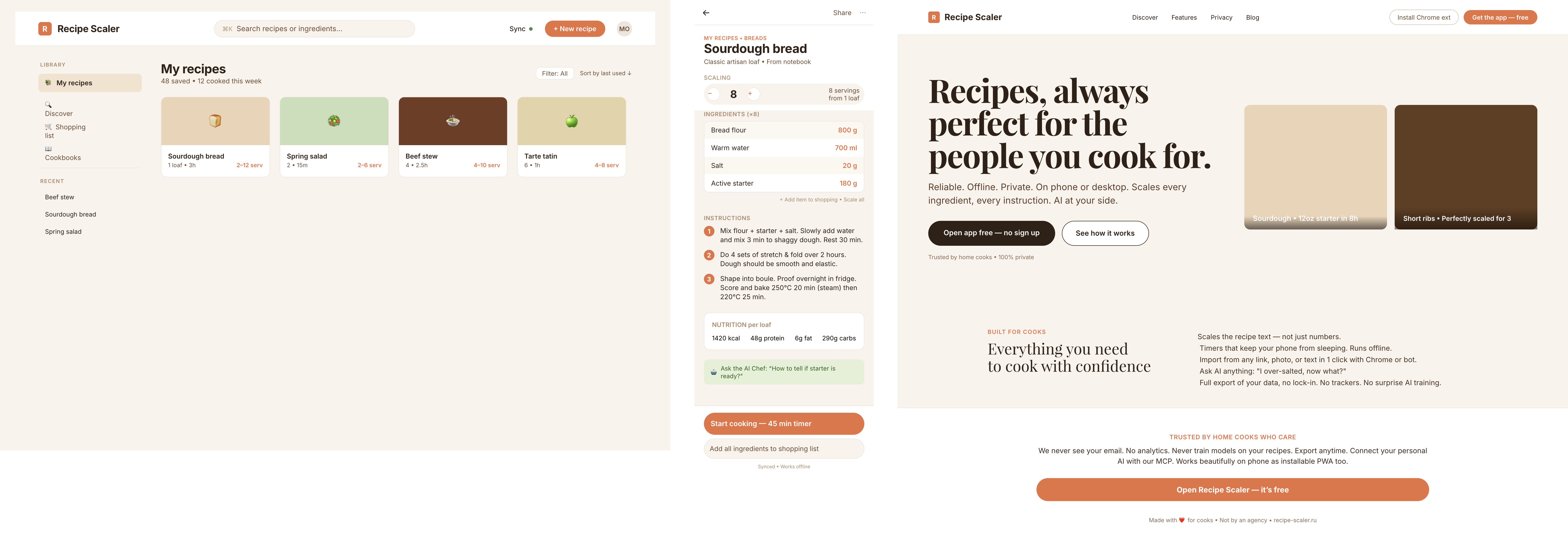
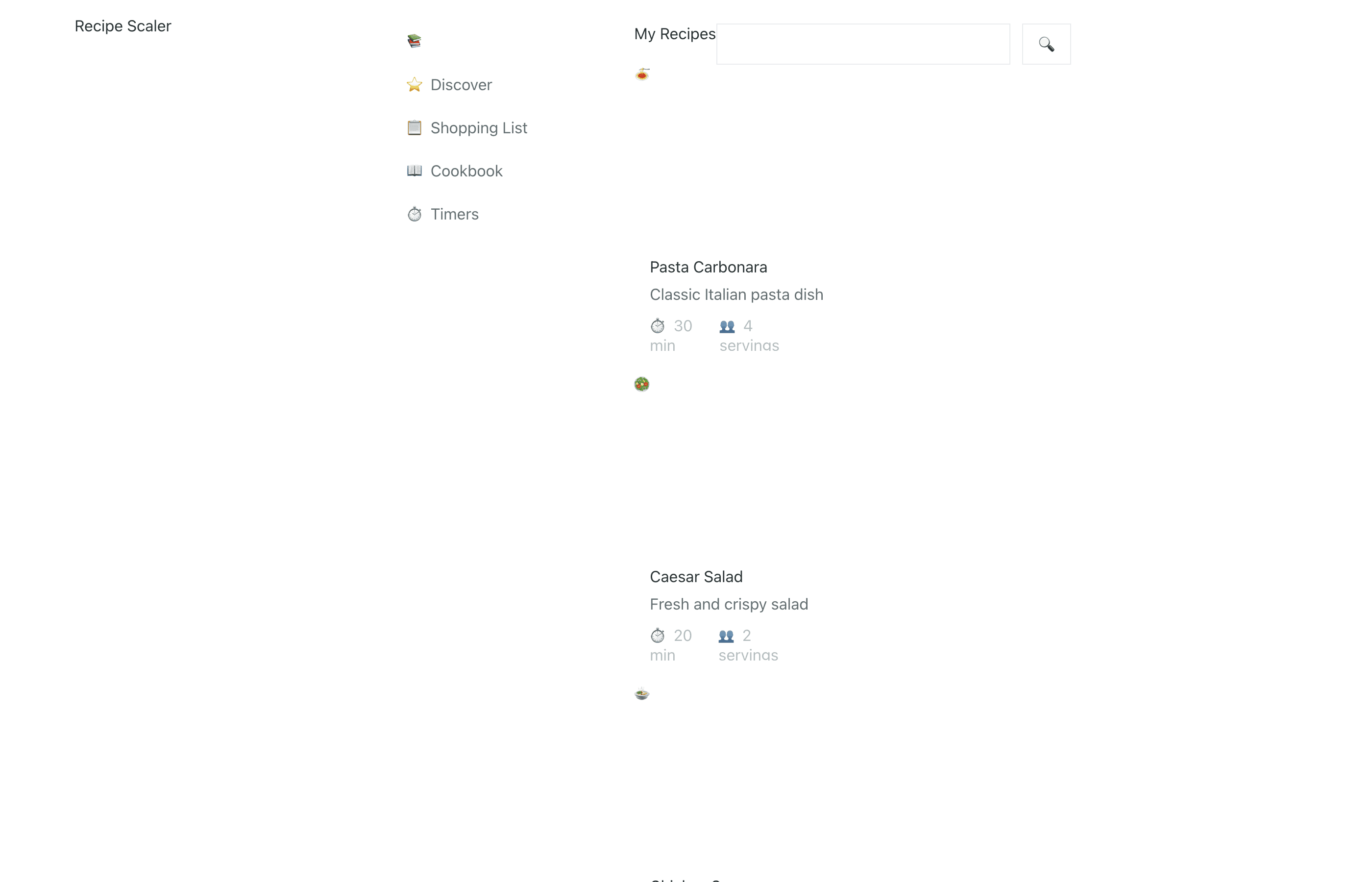
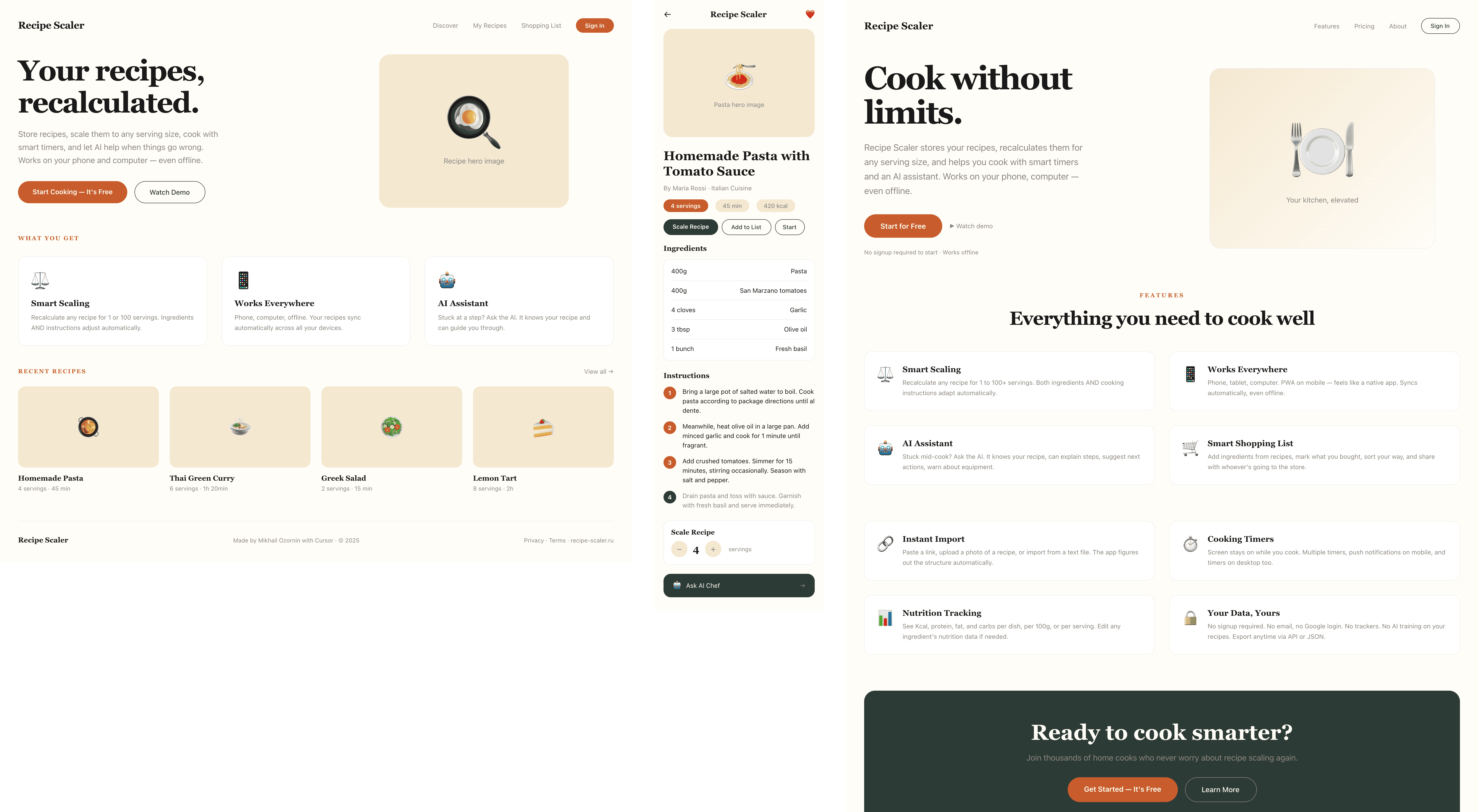
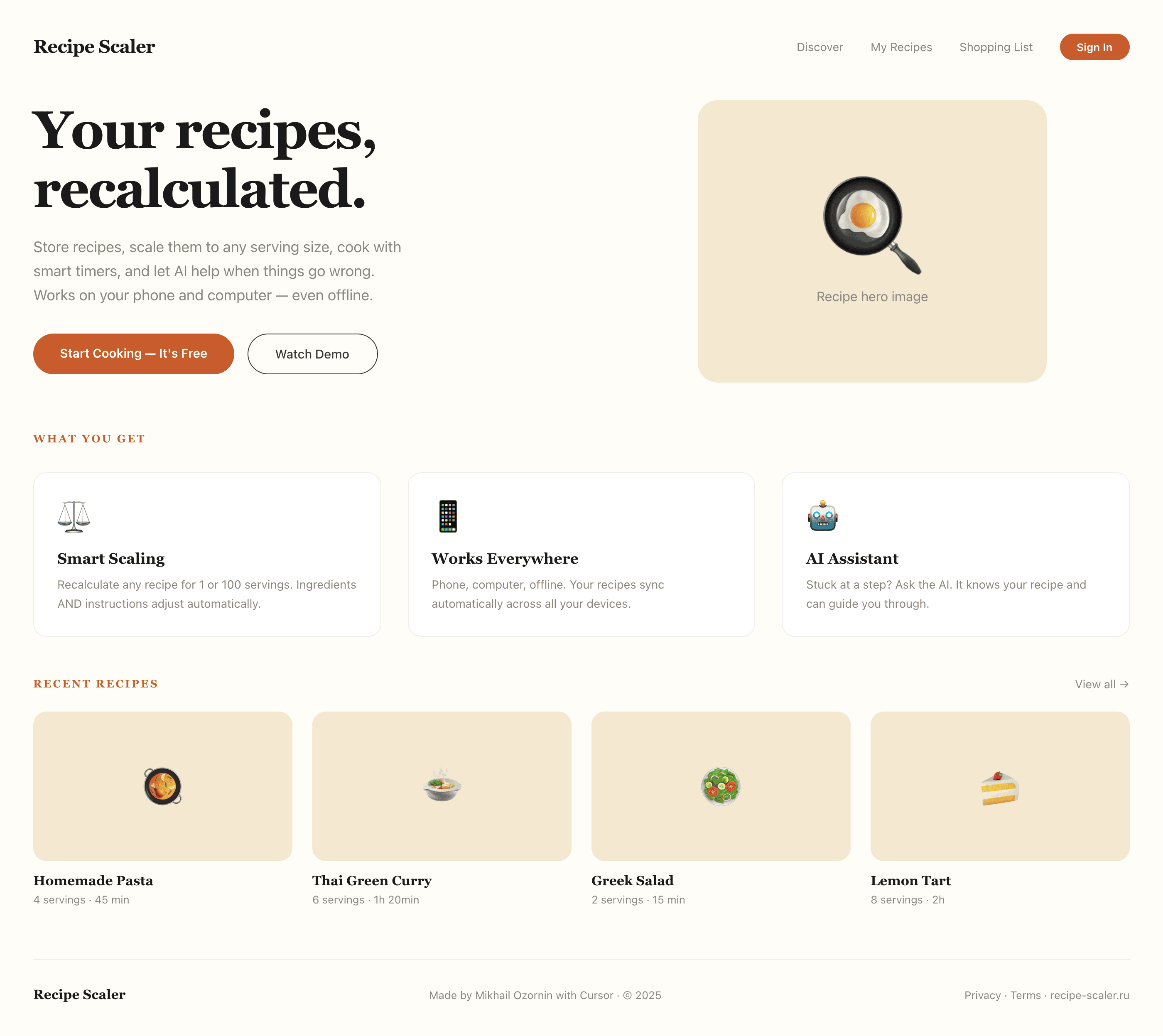
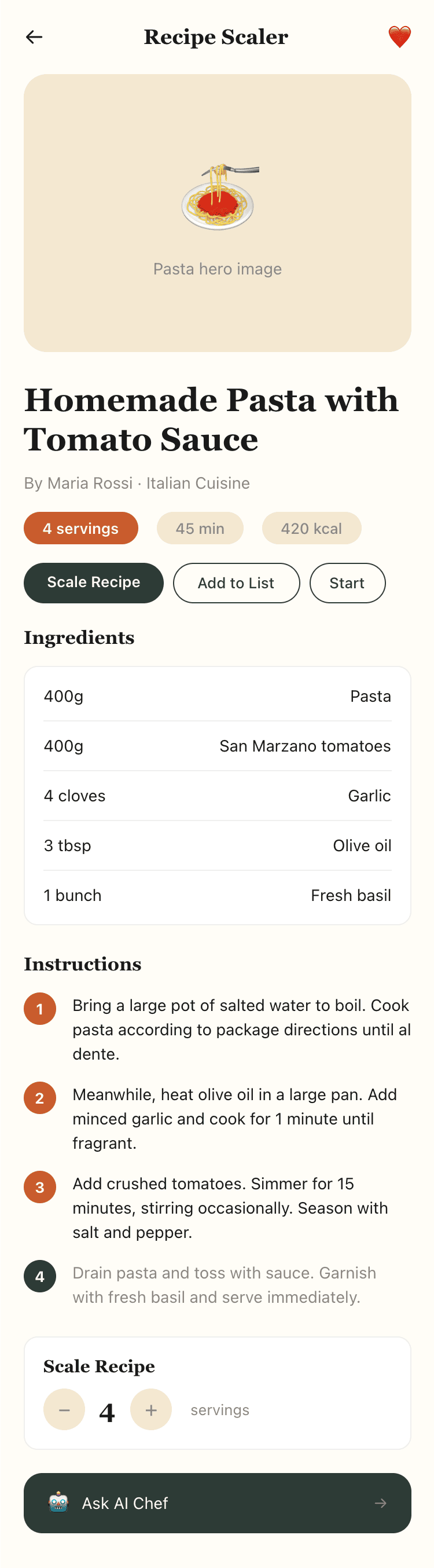
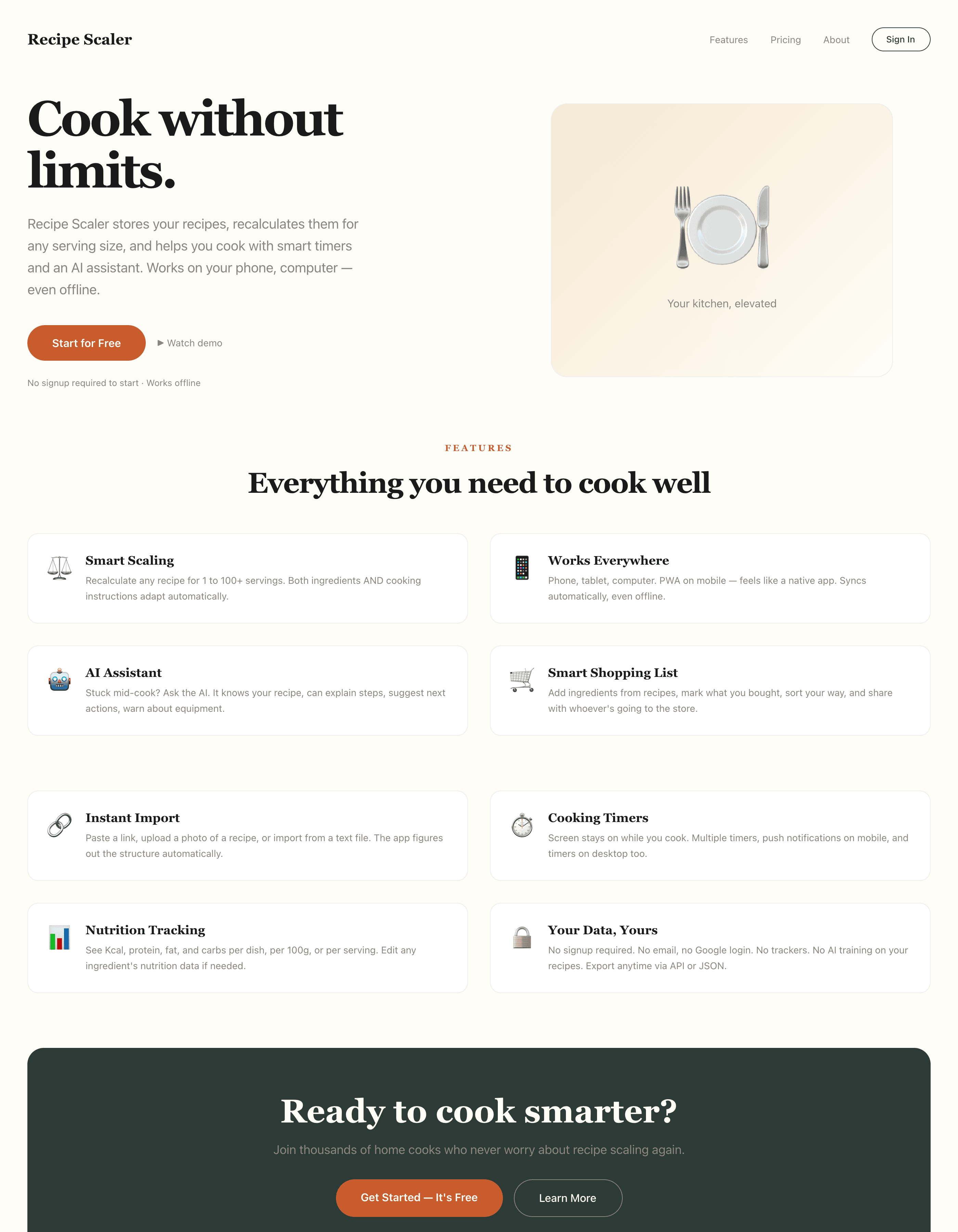
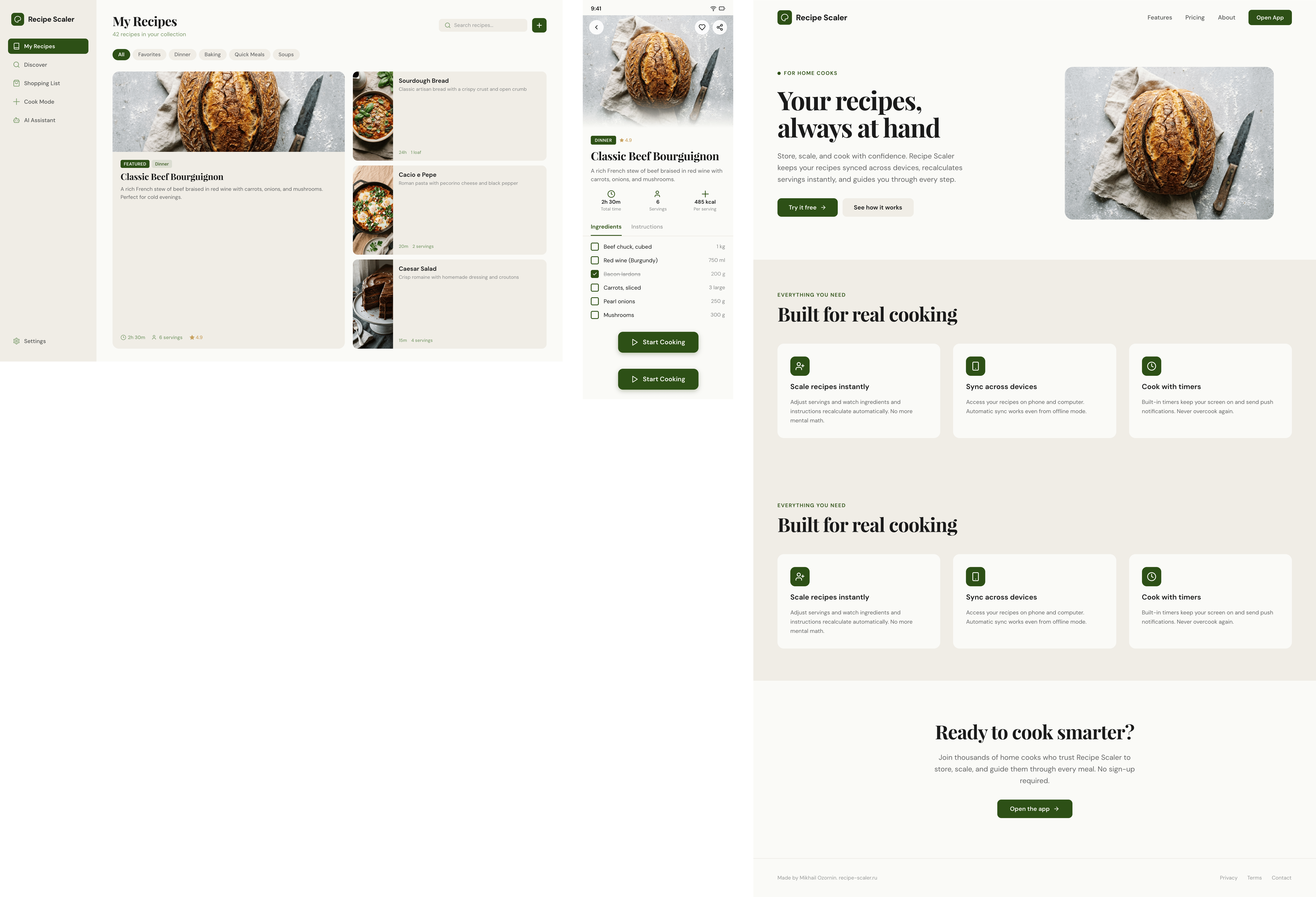
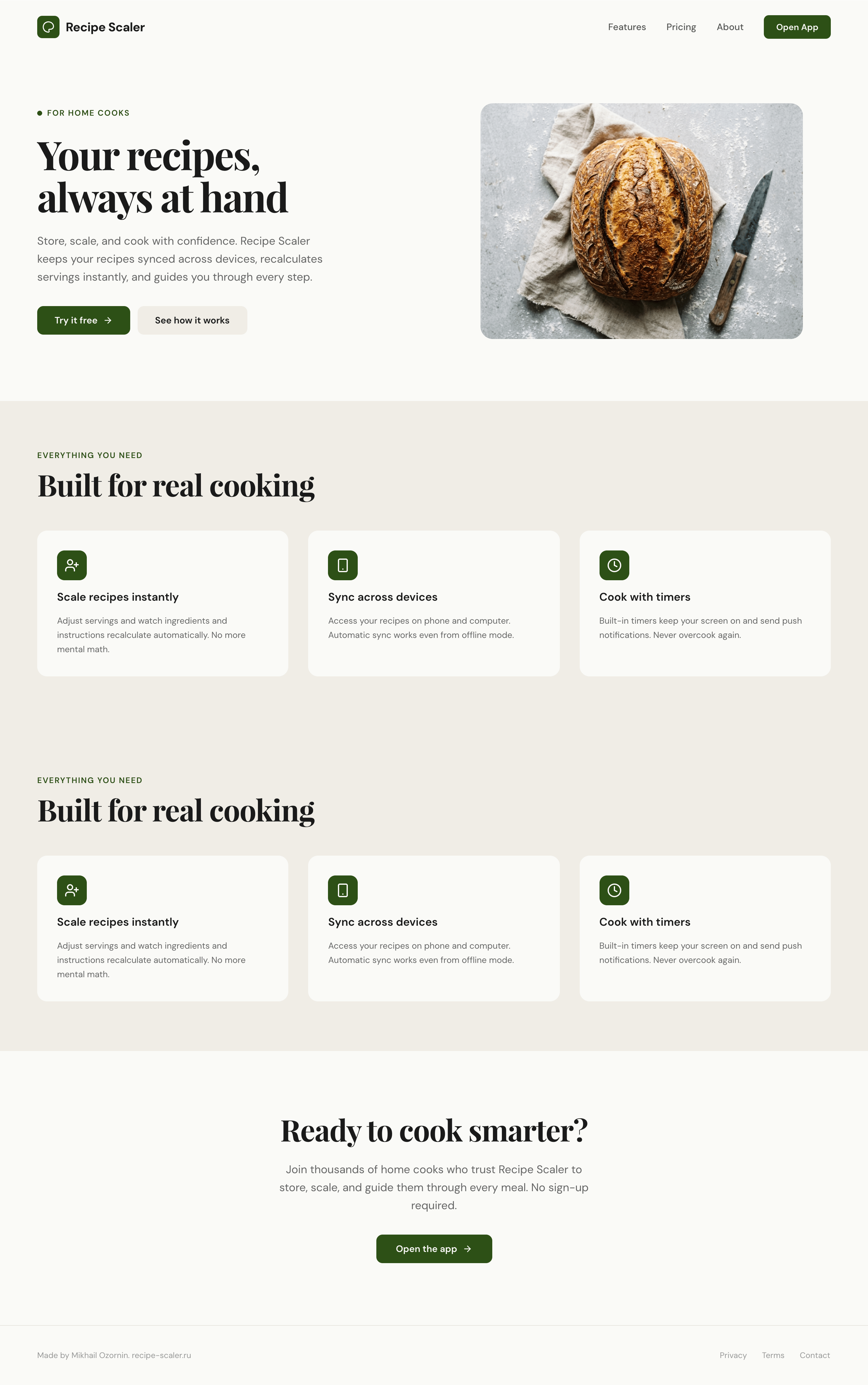
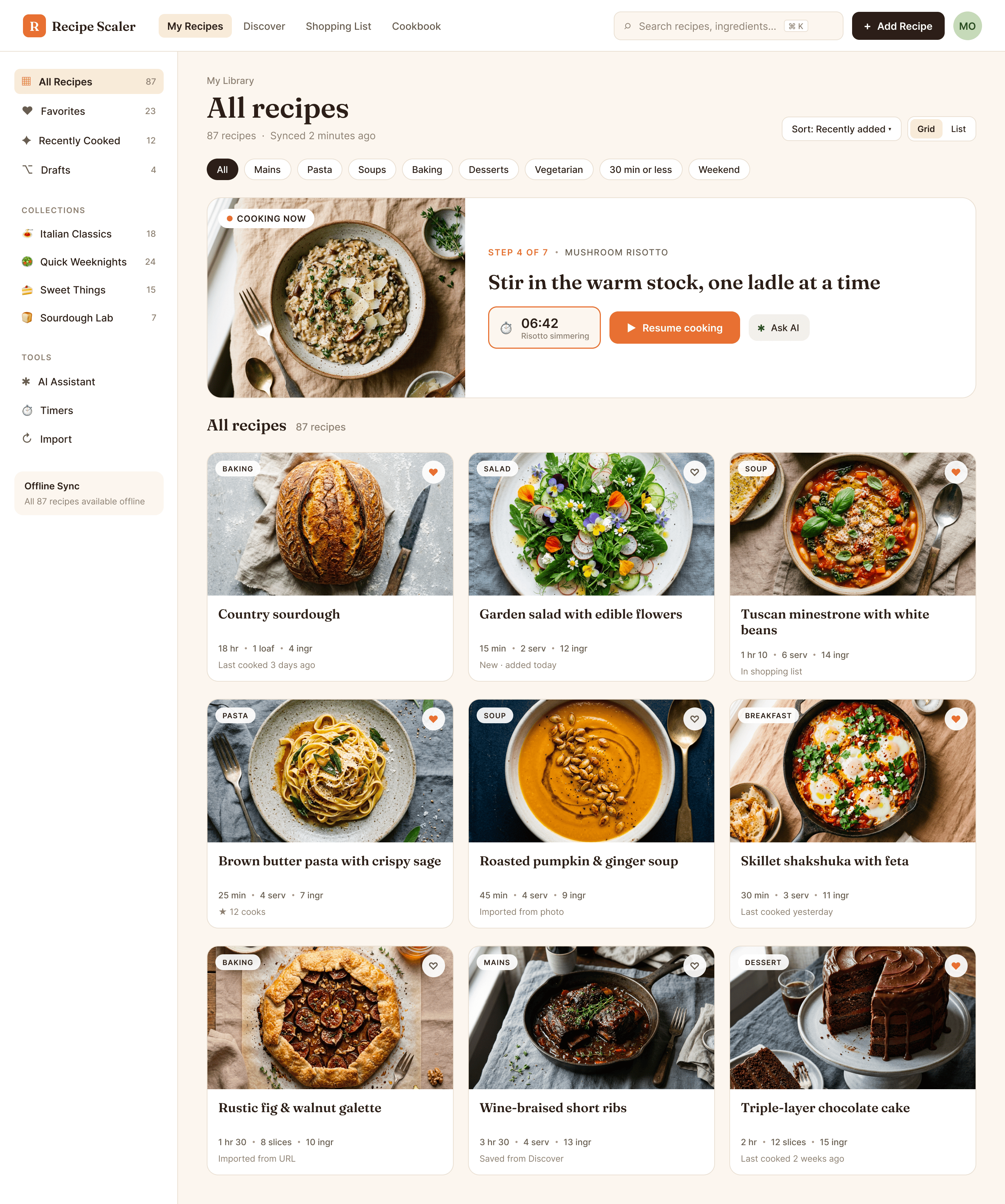
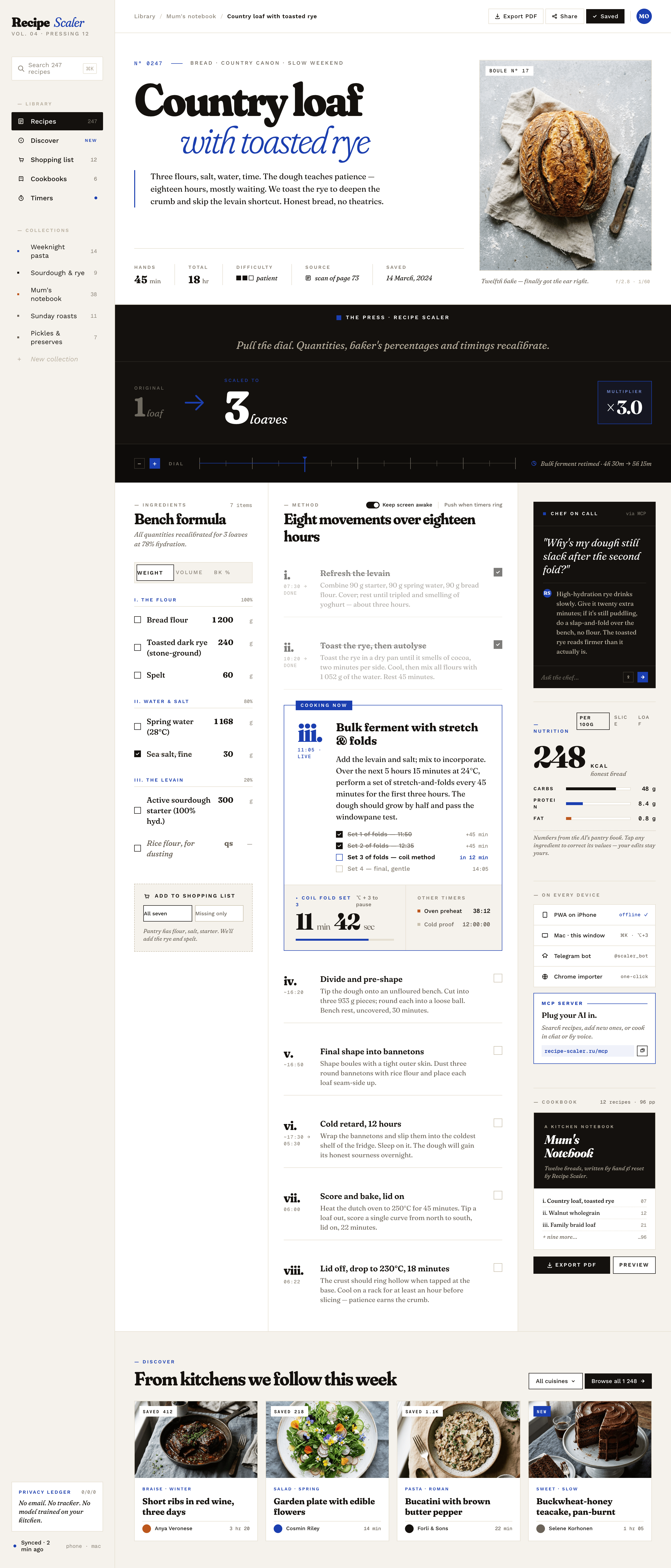
Я дал одну и ту же задачу 34-м разным агентами + моделями. Задача звучала как «сделай три экрана для одного и того же продукта»: десктопный экран, мобильный экран и промостраницу. В качестве продукта взял свою рецептилку и скормил агентам текст со страницы about.
Я взял все популярные агенты и модели, которые сейчас представляю интерес.
Агенты:
- Агенты основных вендоров моделей: Claude Code, Codex, даже Antigravity
- Самый популярный независимый закрытый агент рынке: Cursor
- Два самых популярных открытых агента (и единственные на сейчас, которые заслуживают внимания): Opencode и Kilo Code.
Забегая вперед скажу, что в этой задаче агент не был принципиально важен.
Модели использовались как в нативных провайдерах, так и сторонних через Openrouter. Модели:
- Флагманские модели американских лаб: Opus 4.7, Sonnet 4.6, Haiku 4.5, GPT 5.5 и 5.4, Gemini 3.1 Pro.
- Модели Cursor Auto, Composer 2 и Composer 2.5, а также нишевые игроки типа Grok 4.3,
- Все популярные китайские модели: Qwen 3.7, Qwen 3.6 Max Preview (и более старая Qwen3.5 397B A17B), GLM 5.1, MiniMax 2.7, DeepSeek V4 Pro, Kimi 2.6.
Всем моделям на входе передавалось задание в файле, оно было одинаковым,отличался только адрес файла — каждой модели выдавался свежий файл Paper, чтобы исключить любое влияние предыдущих запусков.
Полный промт для Пейпера ниже (вариант для фигмы отличался только сменой инструмента и ссылки).
I am creating a design for a product.
# Task
Create new pages:
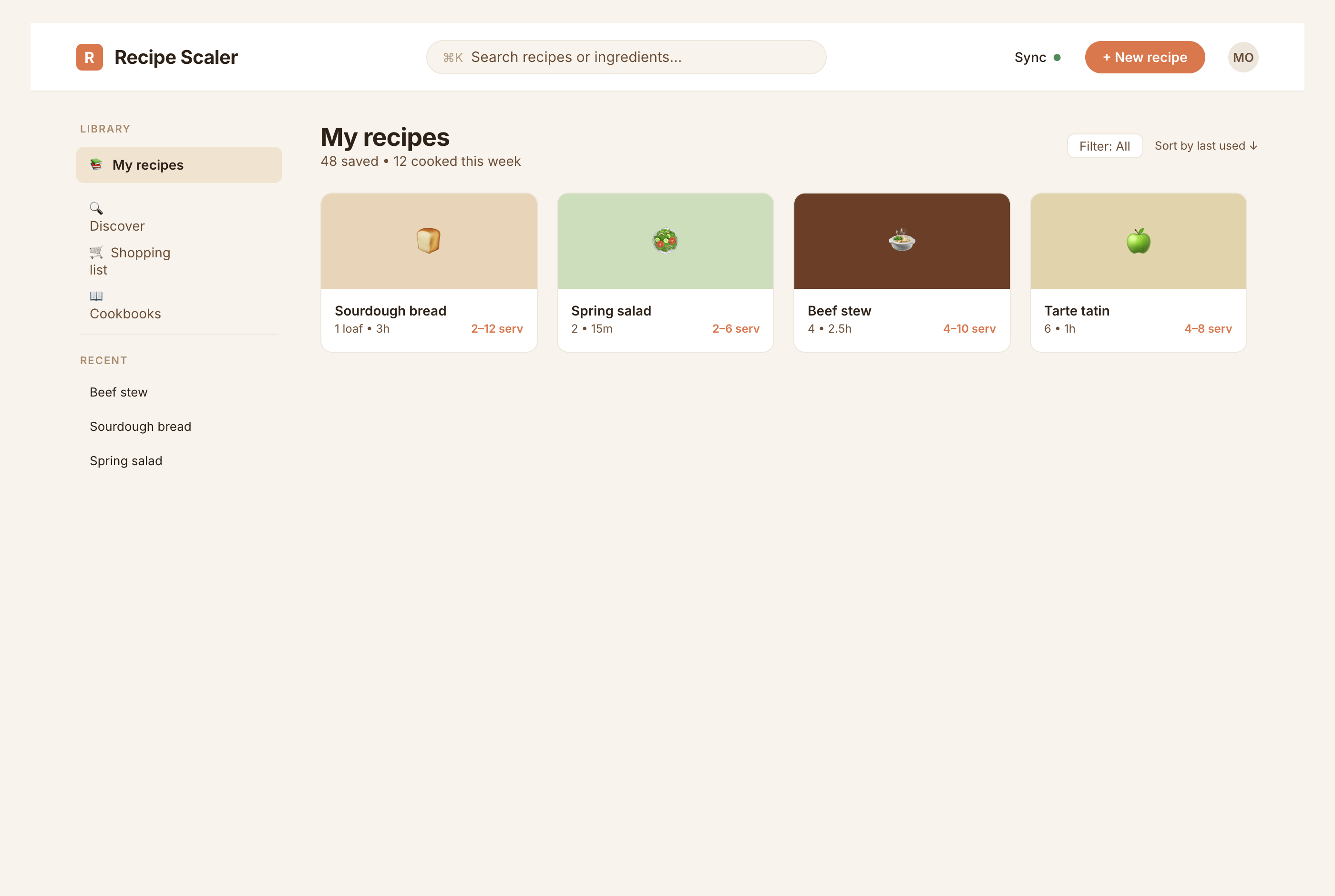
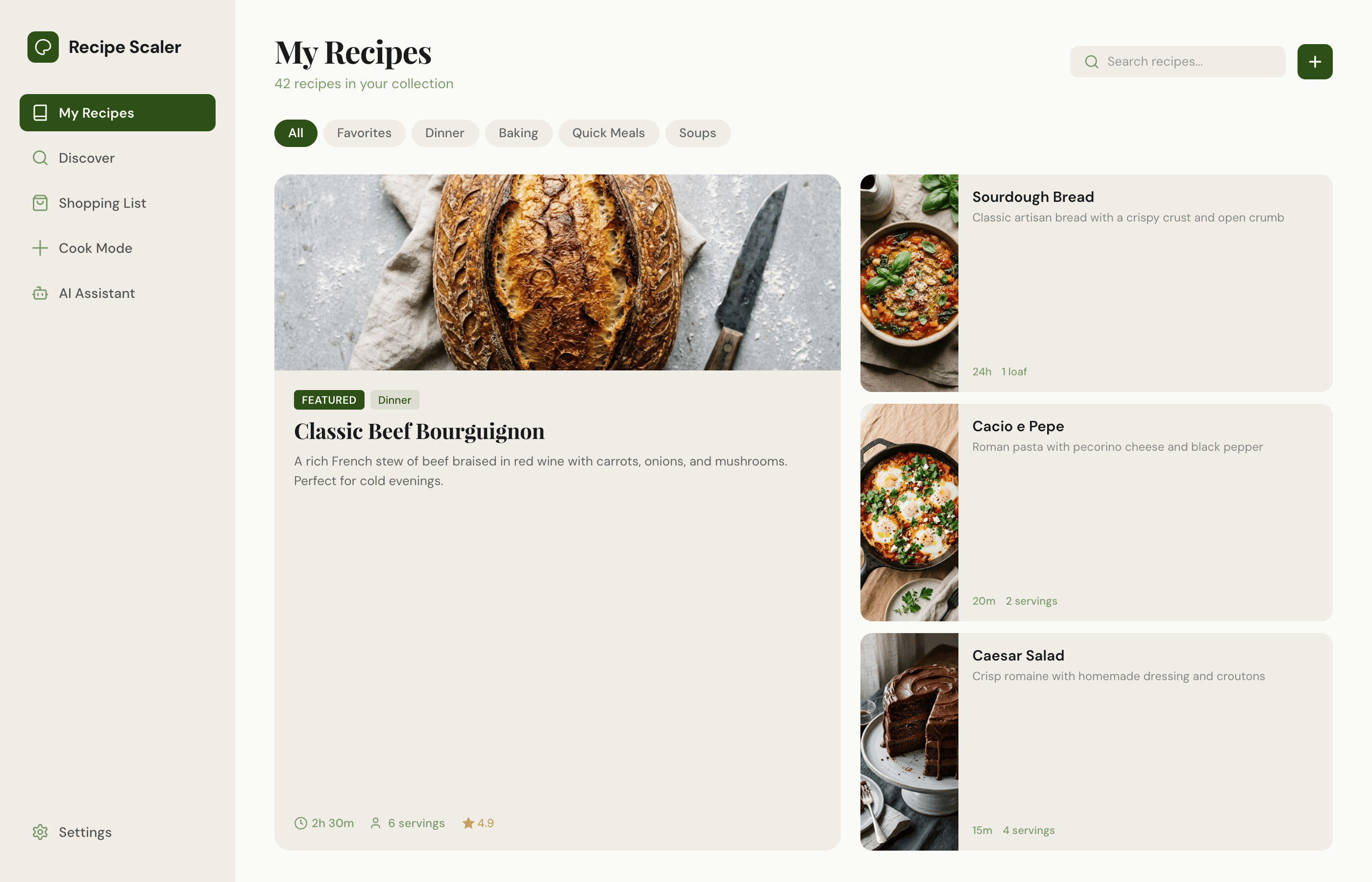
1. A desktop screen interface — choose the main screen and design it. Screen width: 1400px.
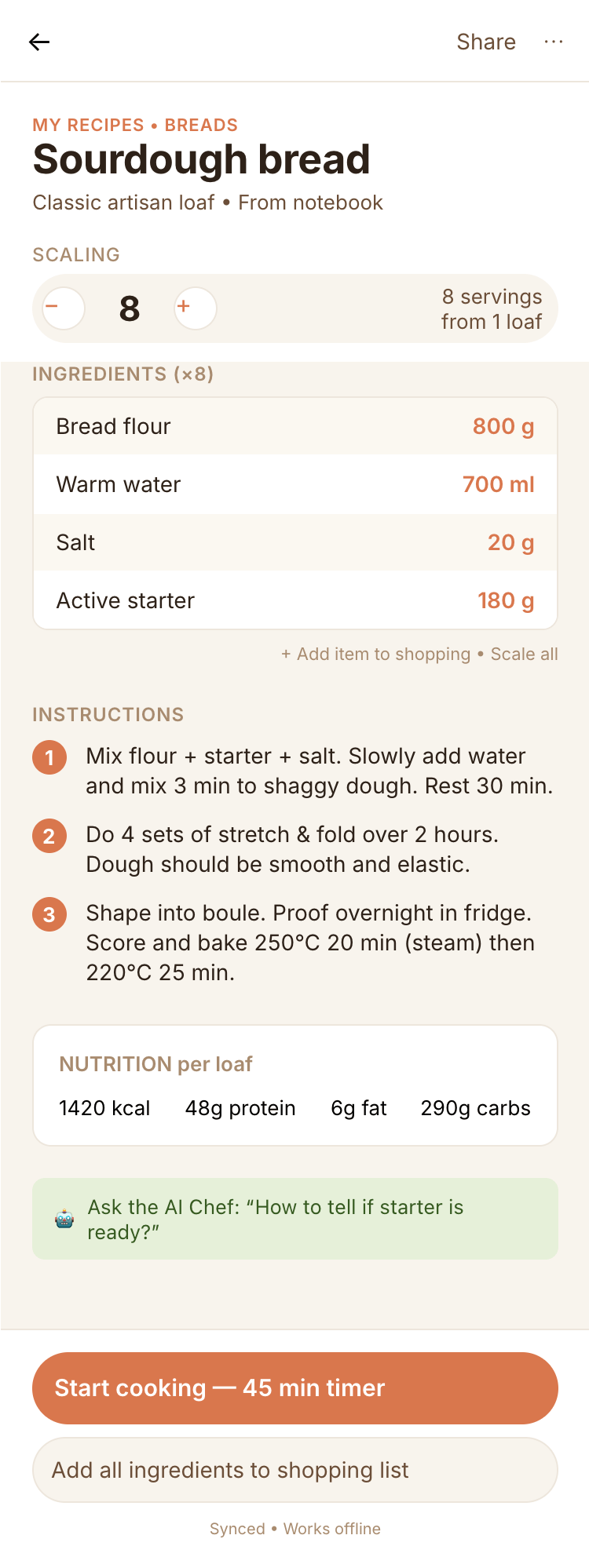
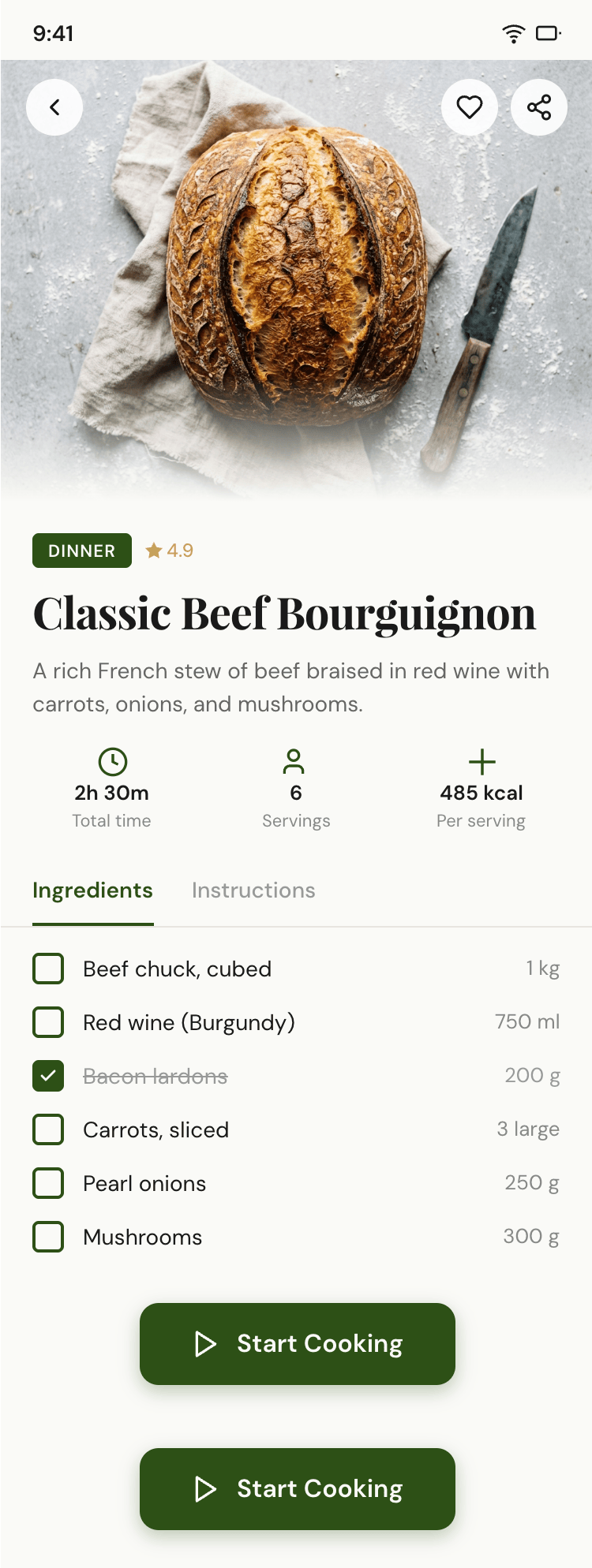
2. A recipe screen interface for mobile. You need to design a recipe screen. Screen width: 375px.
3. A promo page describing the product. Screen width: 1400px.
# Where to create it and expected result
Where to create: TODO
If the mockups are long, you can make a tall frame/artboard/layout. You do not have to fit standard screen proportions.
Use Paper MCP to create the design.
Use English for the content inside the mockups.
You can use pregenerated images for illustations: '/Users/mike/work/git-repos/projects/ai workshops/design with ai-tmp'. If you have built-in tools for drawing images, you can use them too.
Below is the product information, which also describes the product capabilities.
# Product information
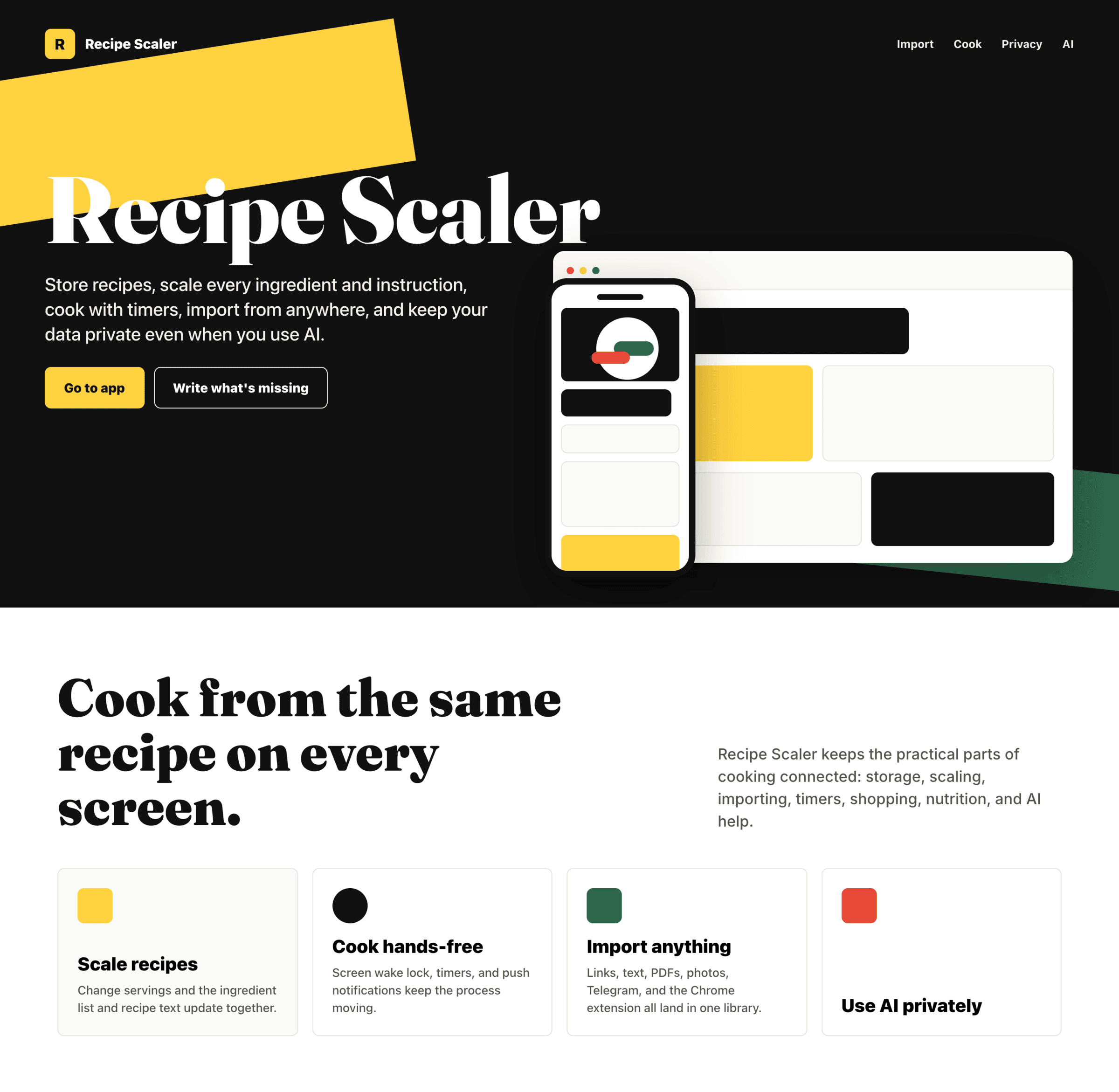
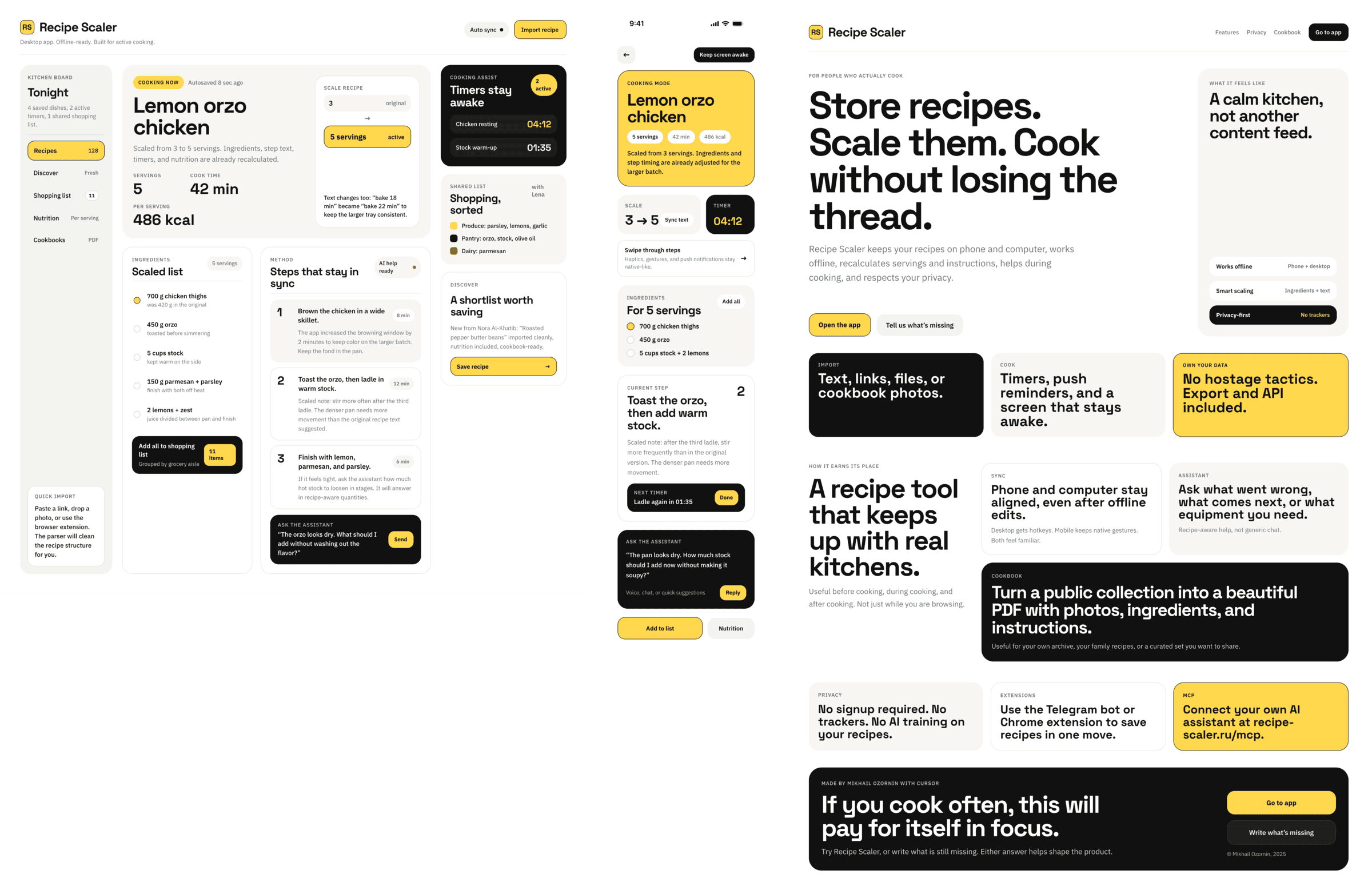
```
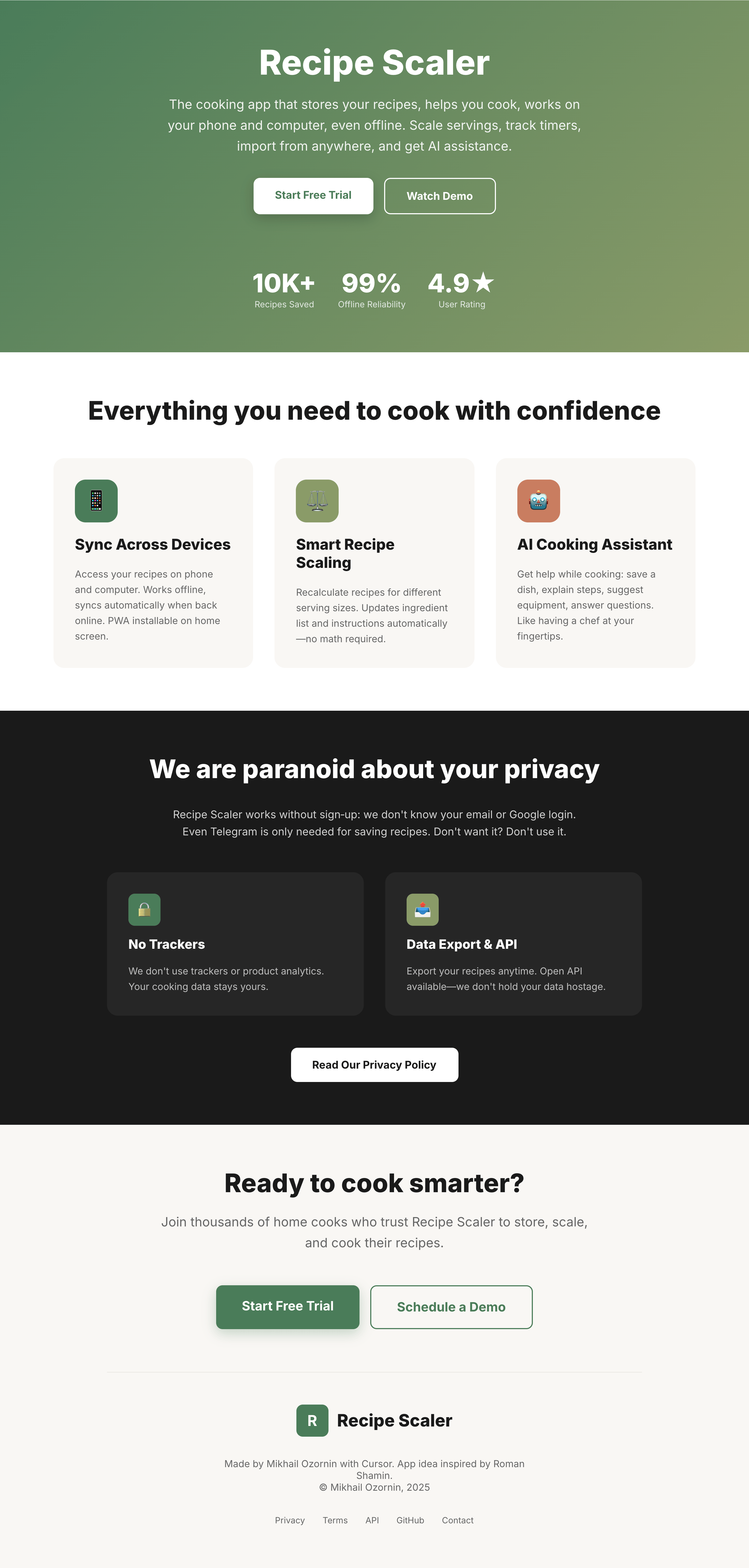
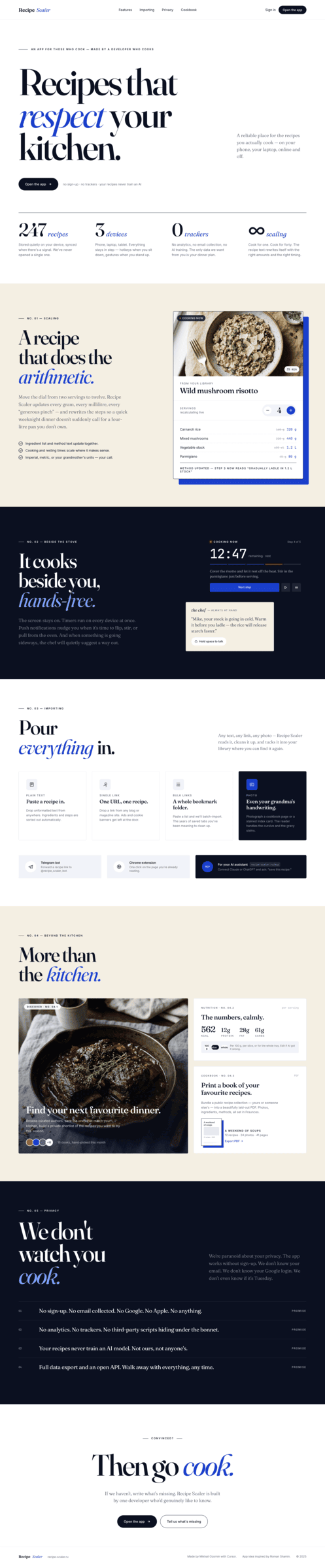
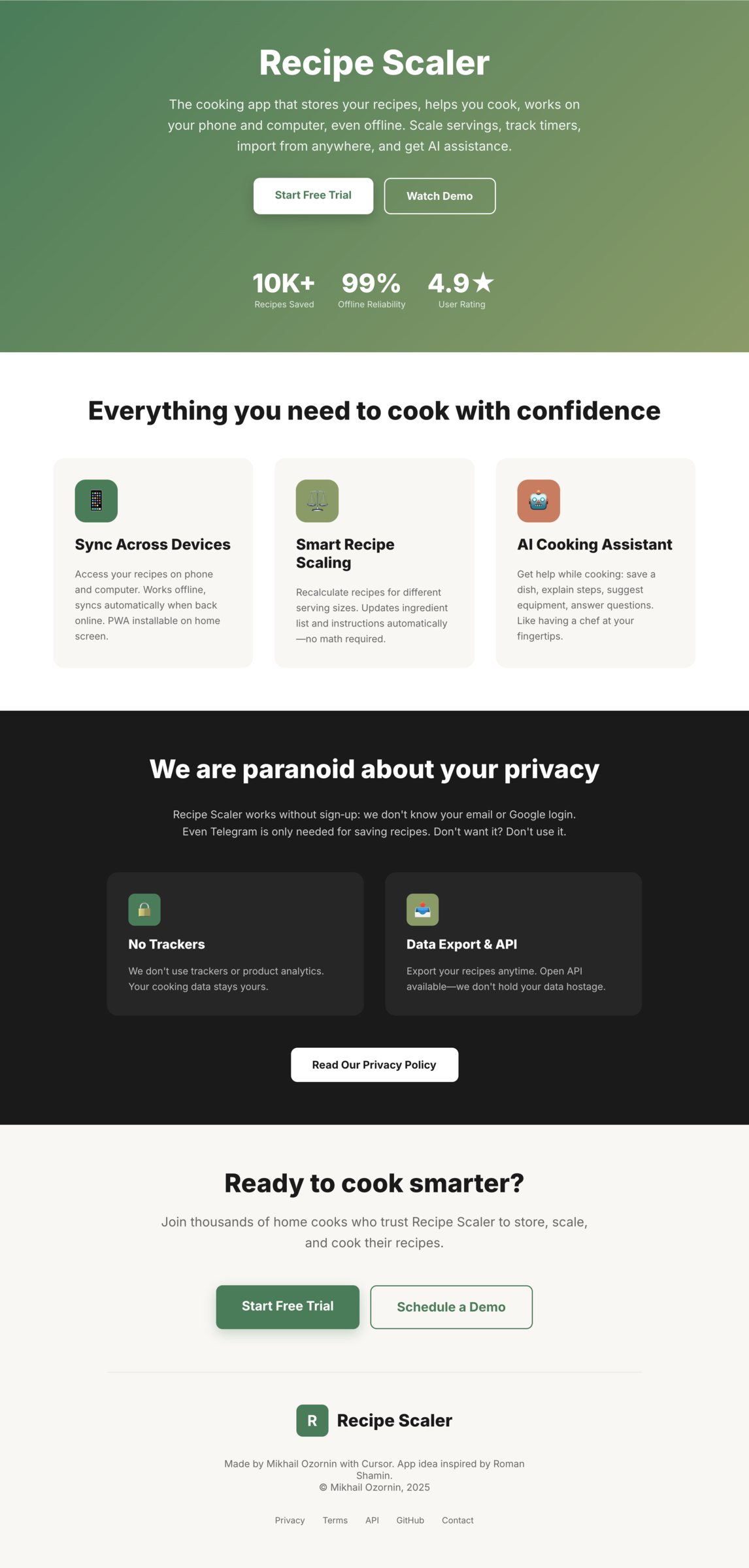
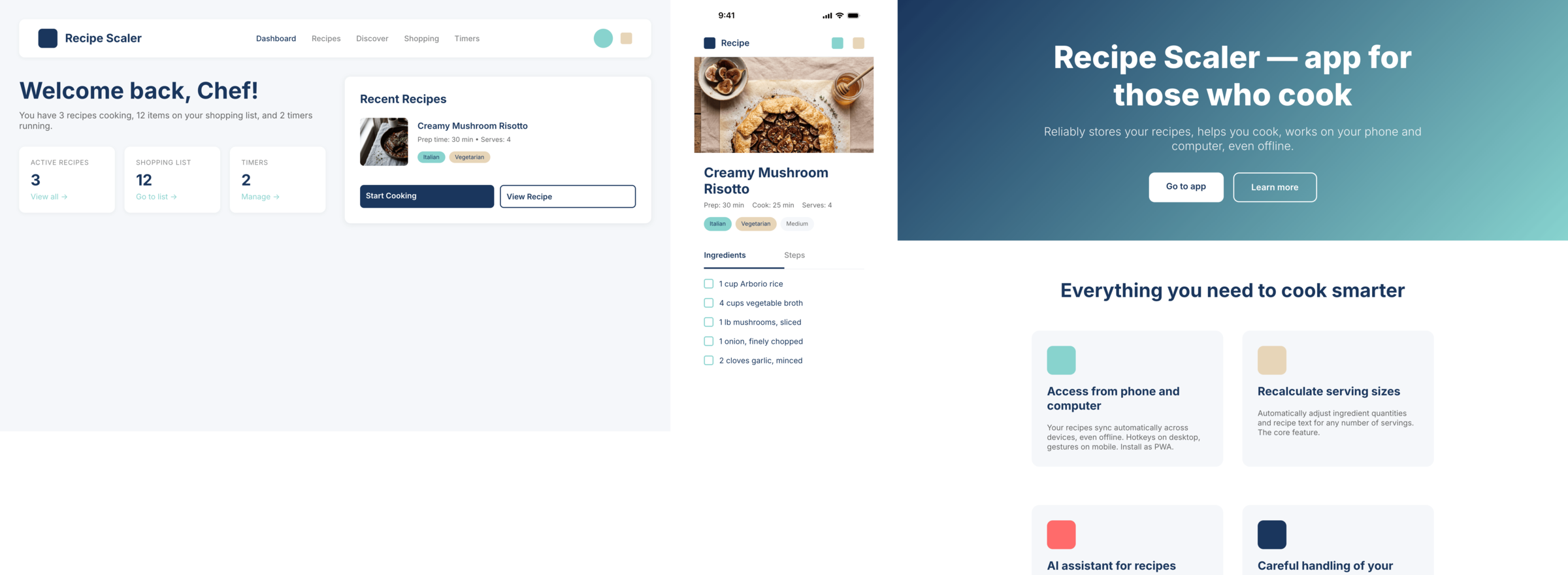
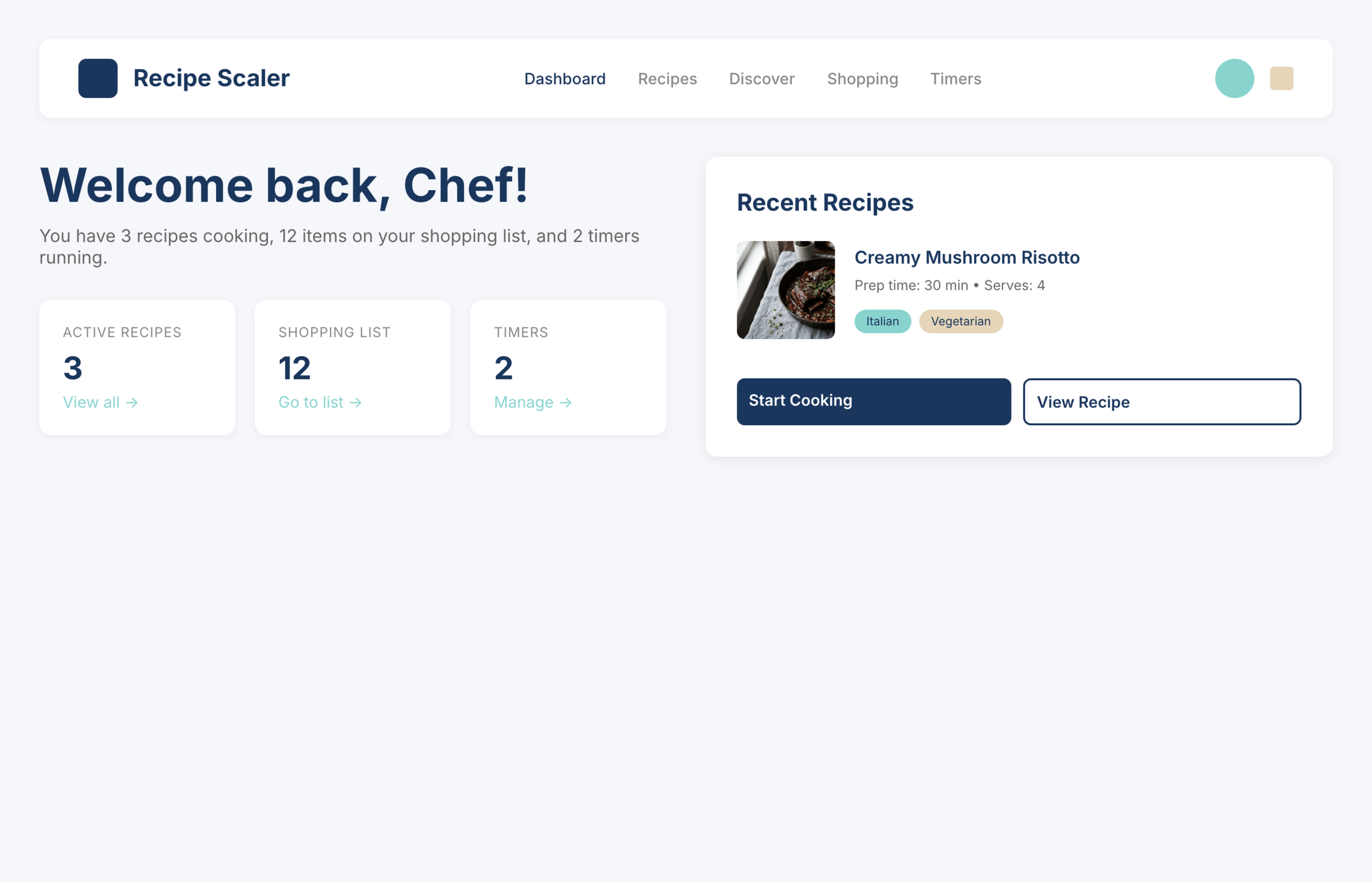
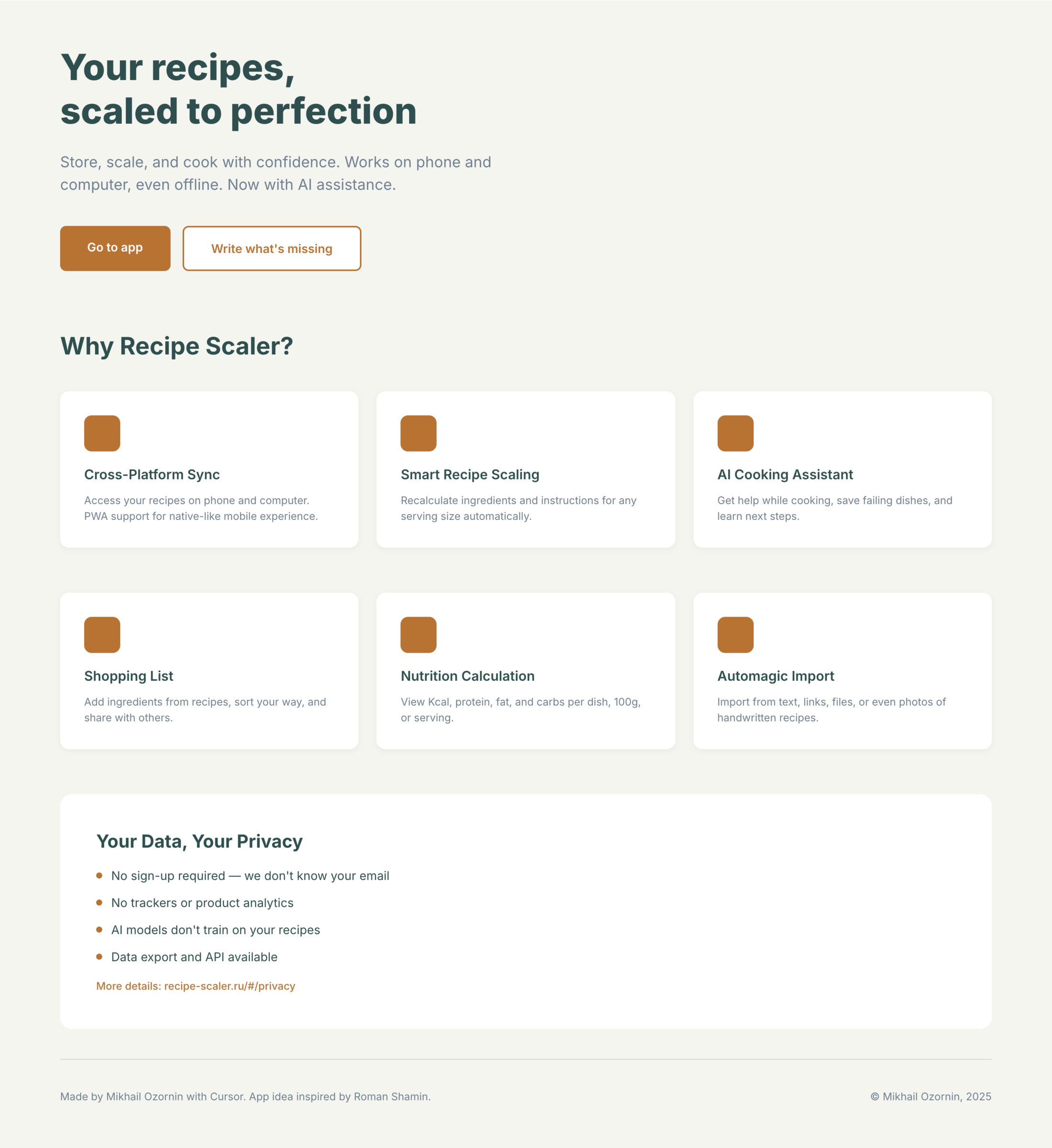
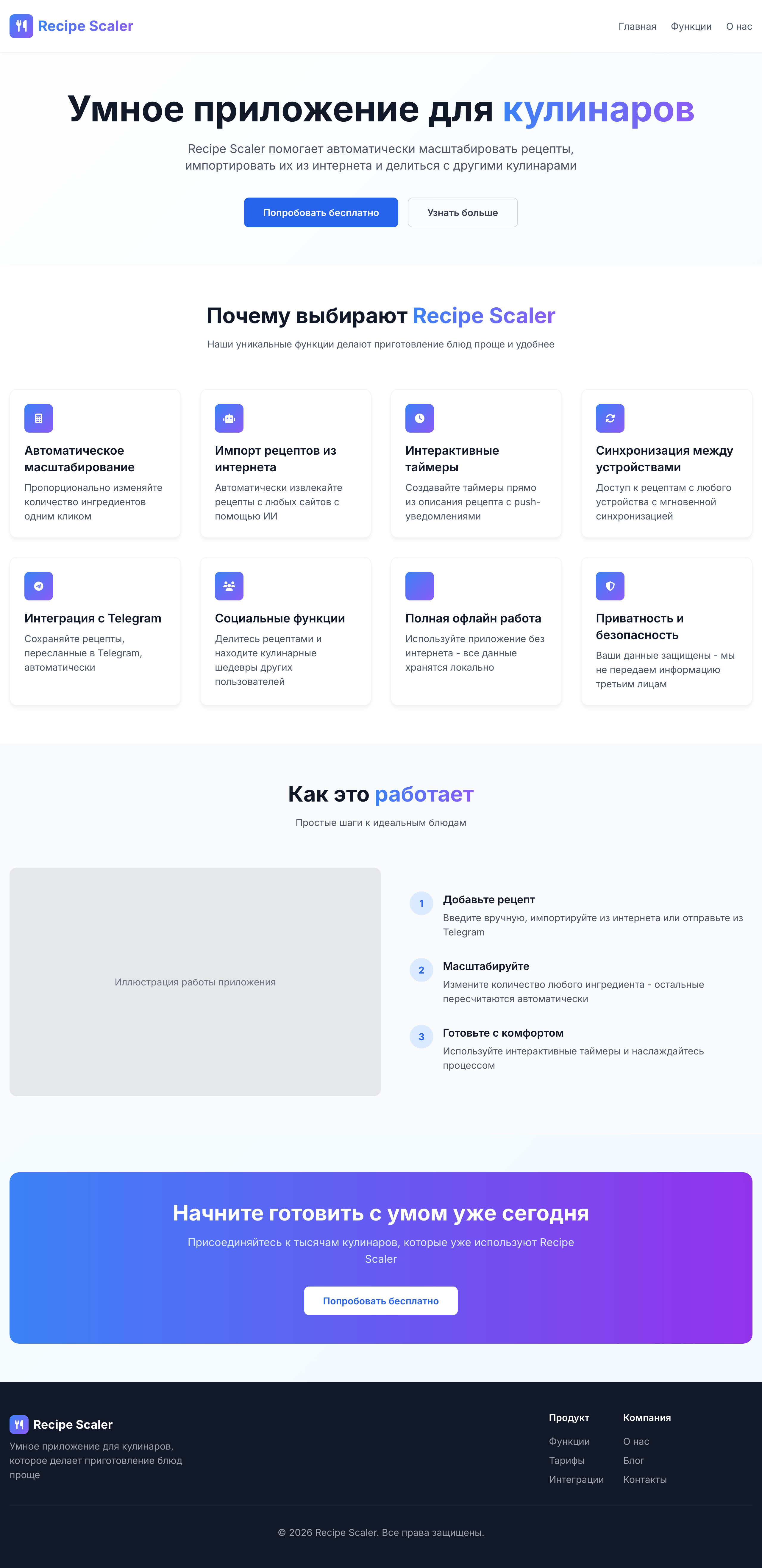
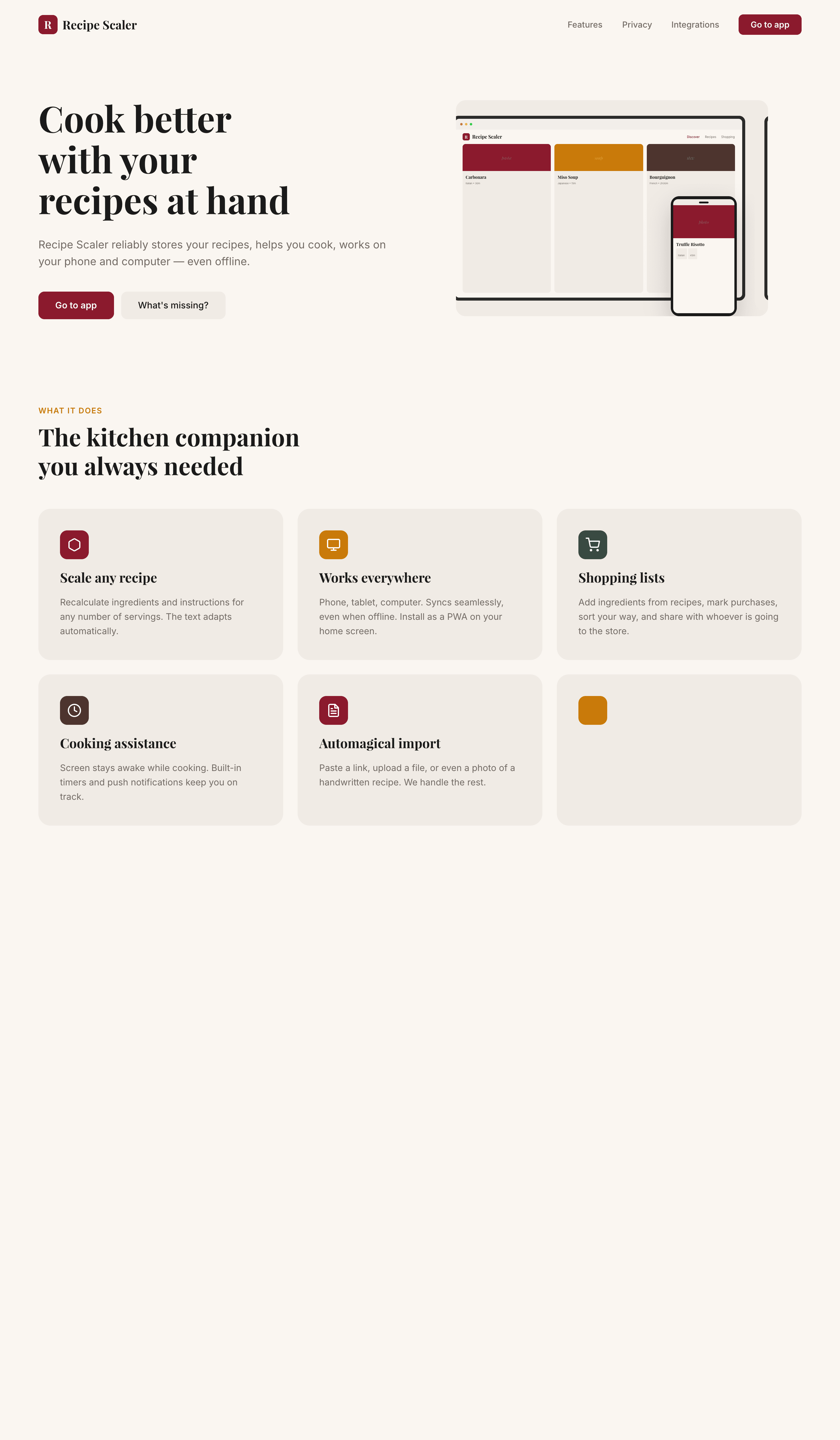
Recipe Scaler — app for those who cook
It reliably stores your recipes, helps you cook, works on your phone and computer, even offline.
Access from phone and computer
You will have access to your recipes both on your phone and computer. The apps will sync automatically, even from offline.
On each platform, the web application uses familiar ways of working: hotkeys on the computer, and standard gesture controls on the phone.
On the phone it works as PWA — install it on your home screen and you won't tell the difference from other apps.
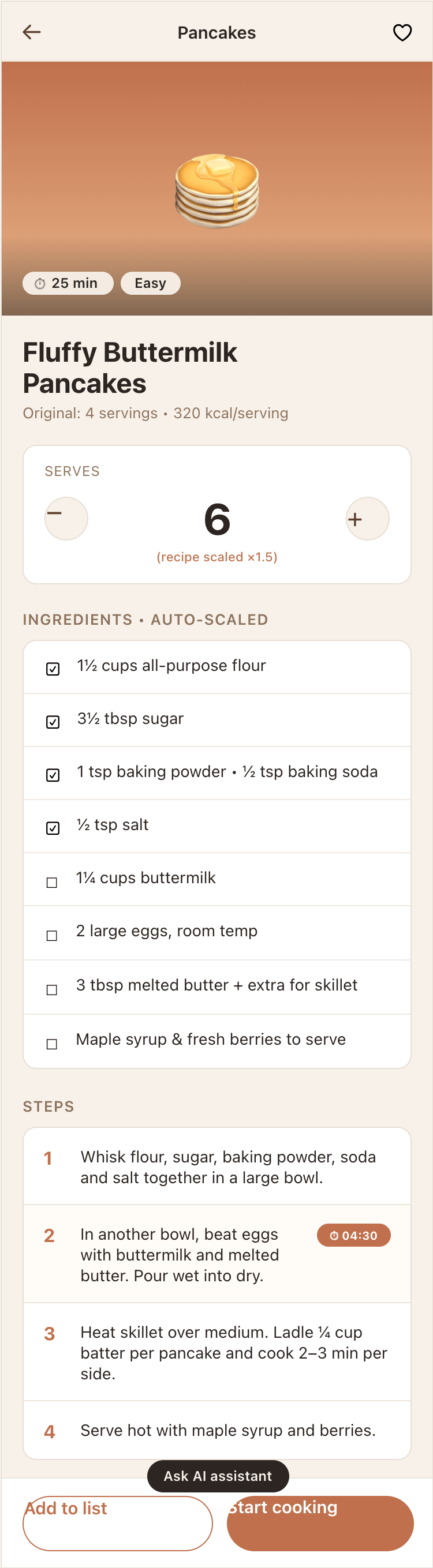
Recalculate recipes for different serving sizes
This is where the app started: recalculating recipes for different serving sizes.
When recalculating, not only the ingredient list is updated, but also the recipe text.
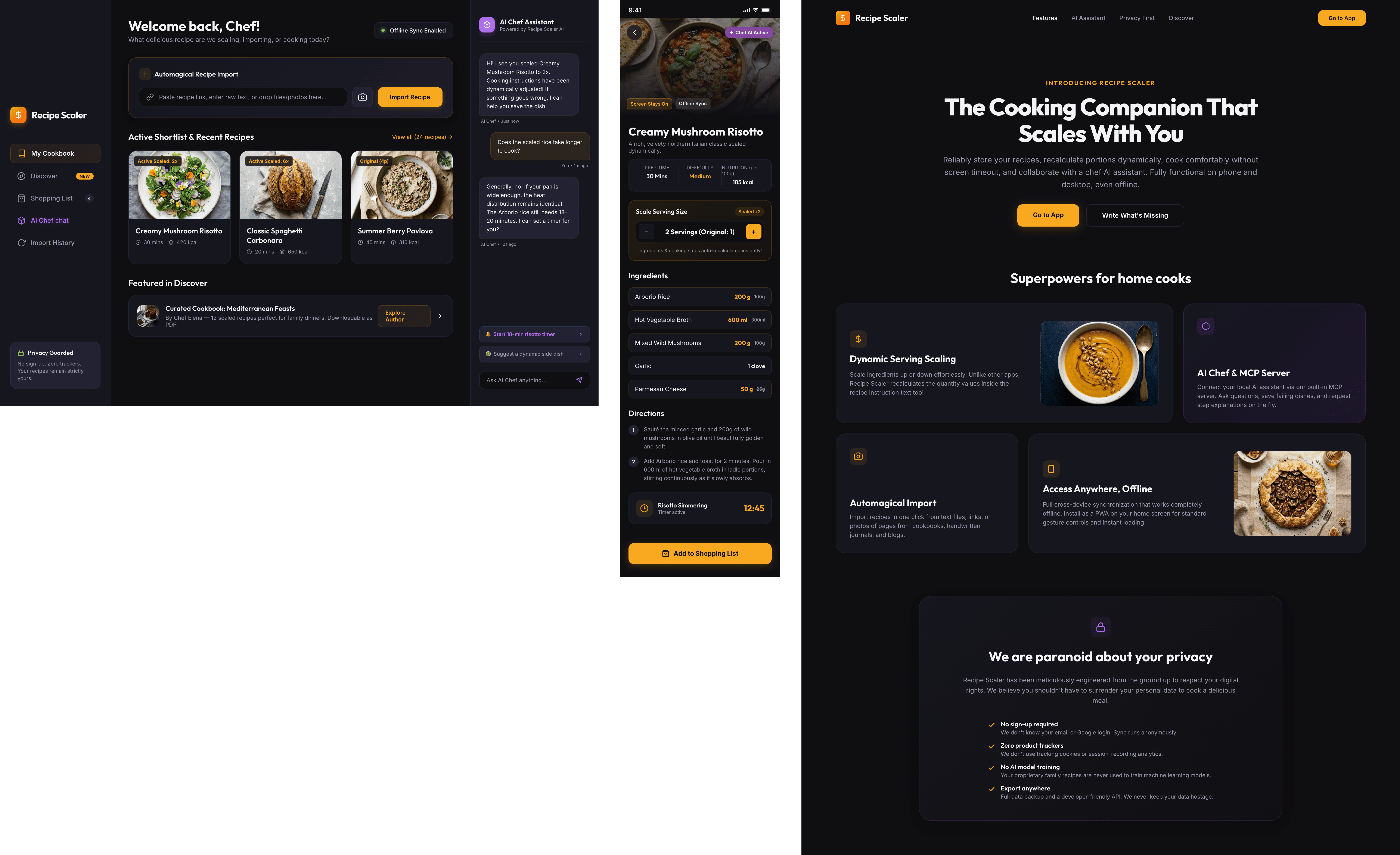
Cooking assistance
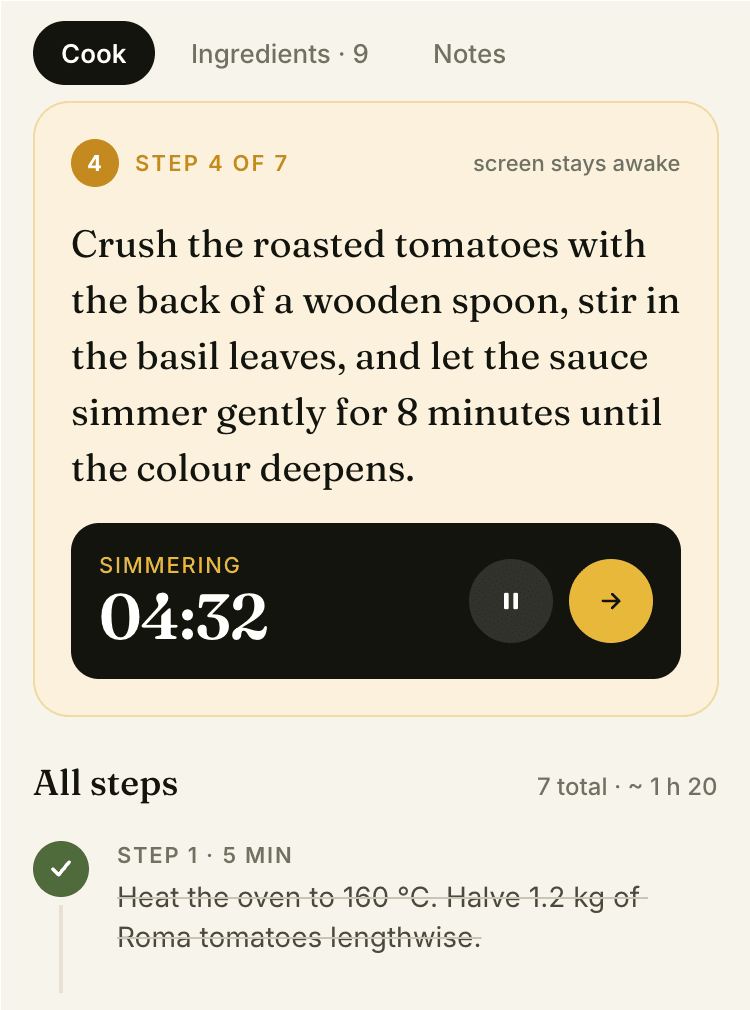
The app will help you cook: it won't turn off the screen while cooking, will track time and even send push notifications. Timers are, of course, available on the computer too.
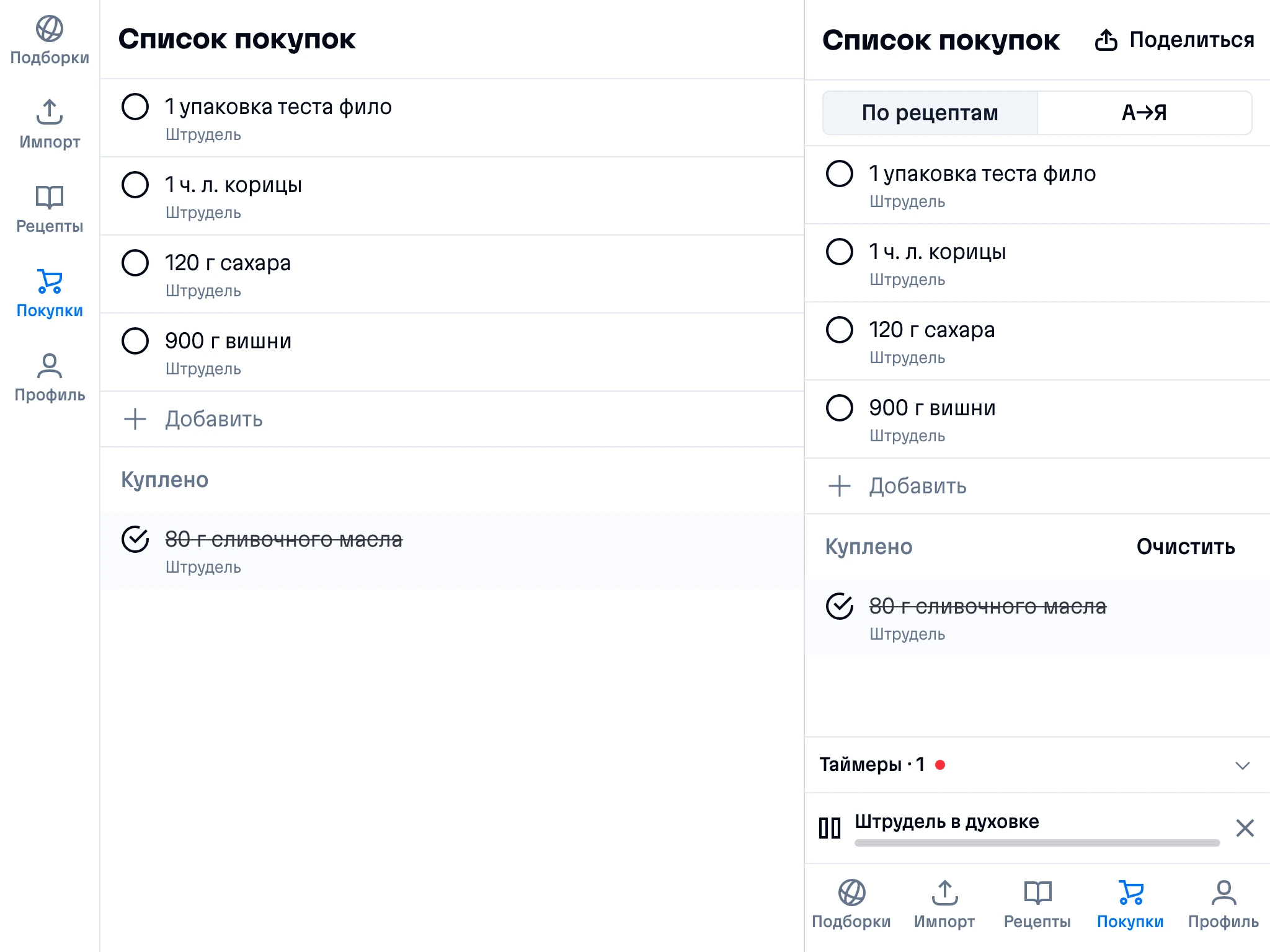
Shopping list
Add ingredients to your shopping list one by one from a recipe, or add the whole recipe at once.
Mark purchased items, sort the list the way you like, and share the list with the person going to the store.
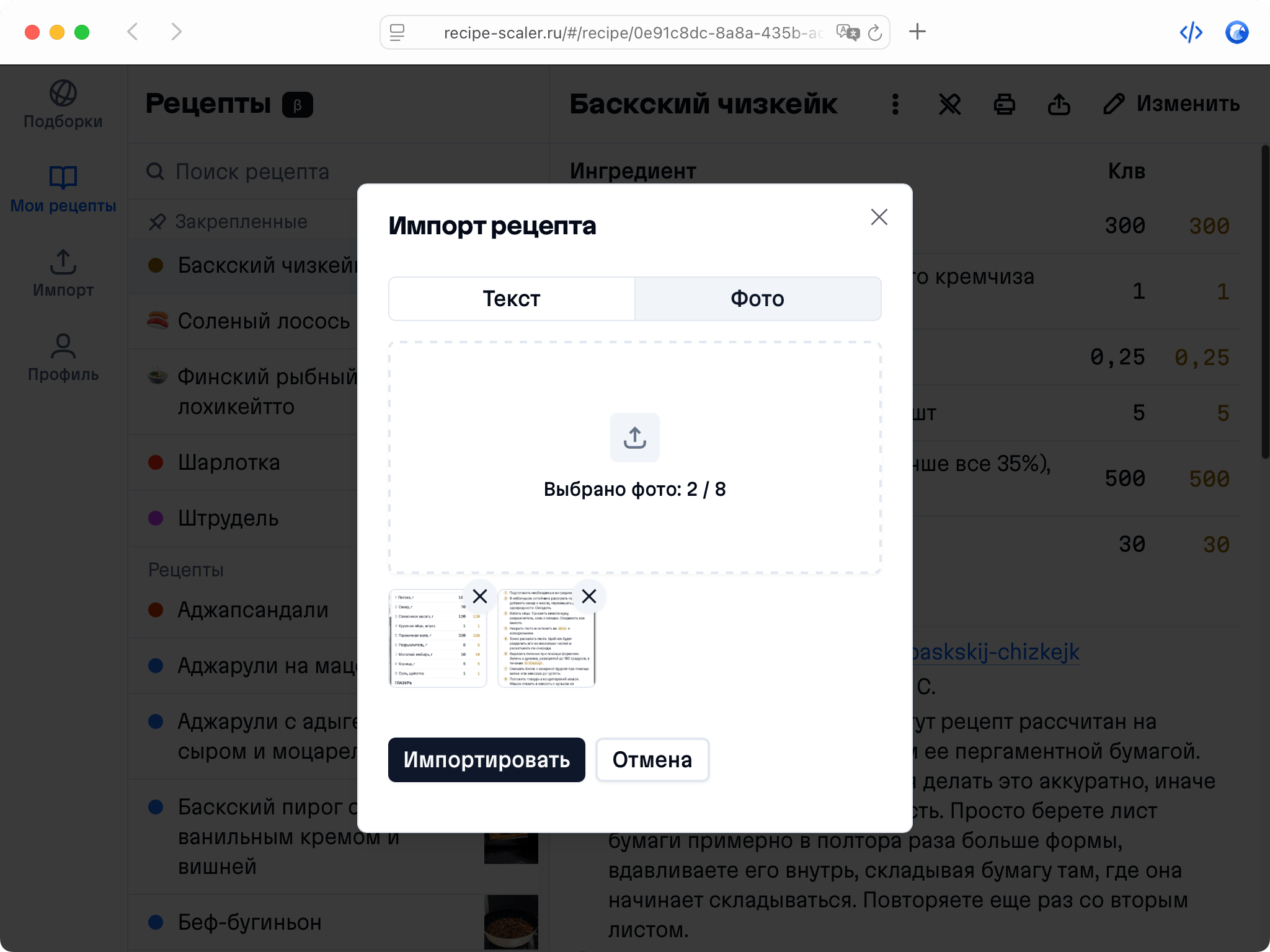
Automagical recipe import
Recipe Scaler can import a recipe from text, a single link, or multiple links at once.
You can also upload a file in almost any text format and even photos of pages from a cookbook, notebook, or handwritten recipe journal.
AI assistant for recipes
If something goes wrong while you cook, the AI assistant can help you save the dish and figure out what to do next.
It can also explain the recipe, suggest the next step, and point out the equipment you may need.
It's like having a chef always at your fingertips, ready to answer your questions.
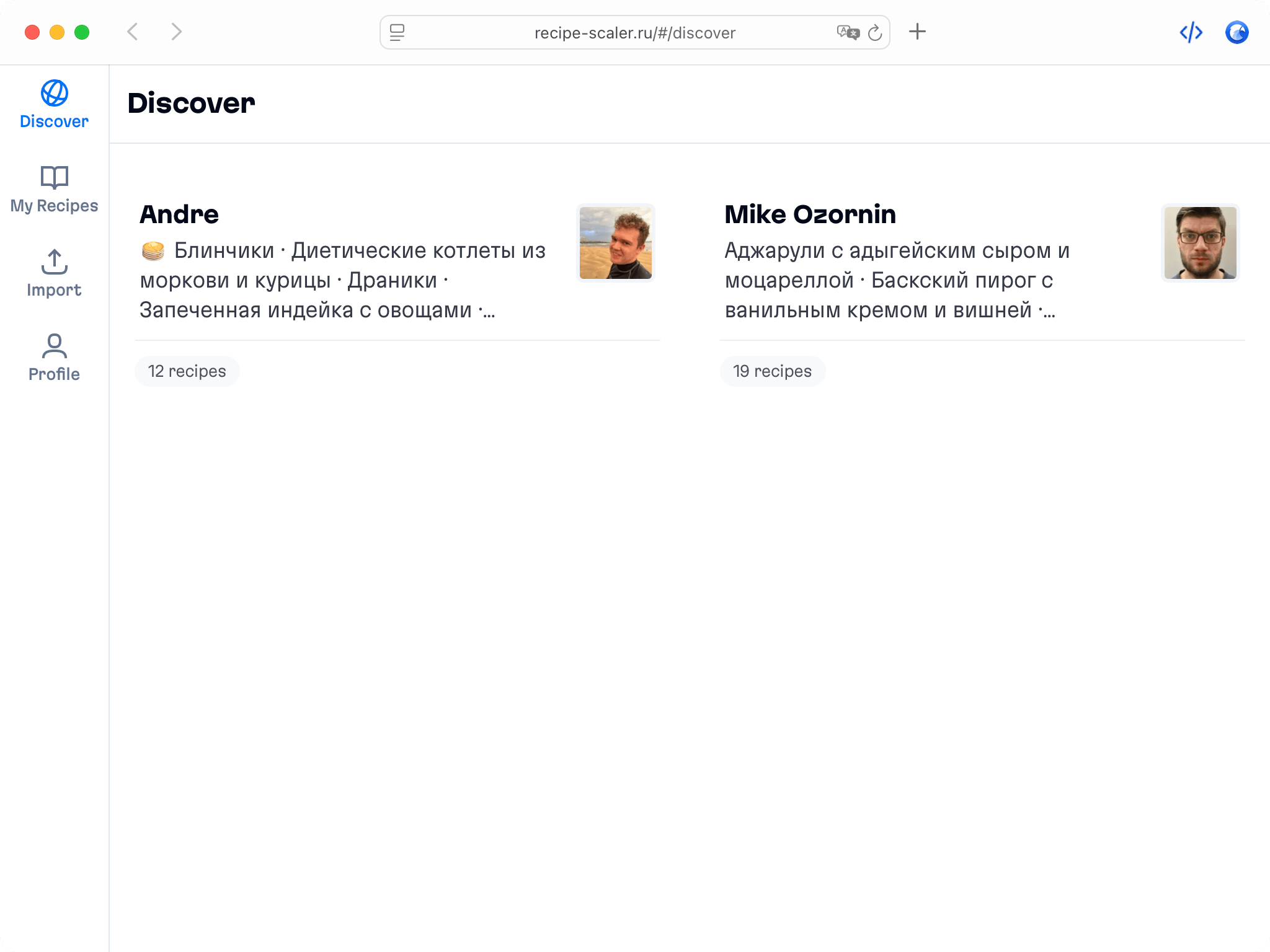
Discover section
Find new recipes in Discover.
Explore interesting authors, save recipes to your collection, and build your own shortlist of the best finds.
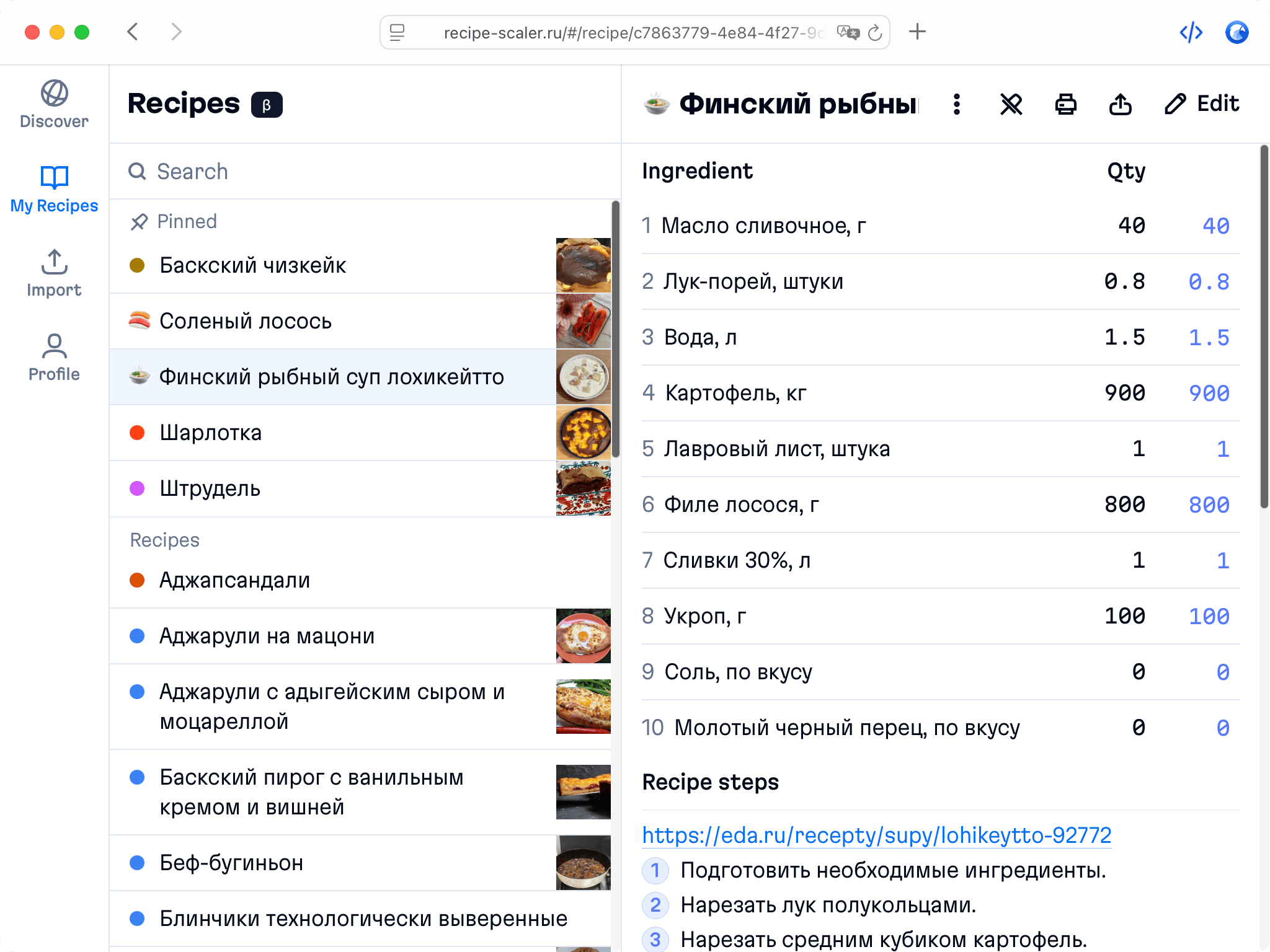
Health-friendly: nutrition calculation
Recipe Scaler will calculate the nutritional value (Kcal, protein, fat, carbs) for a dish and let you view it conveniently: for the entire dish, per 100 grams, or per serving.
If artificial intelligence makes a mistake in the numbers, you can always correct the nutritional value of the needed ingredient.
Cookbook
Download a public recipe collection (your own or someone else's) as a beautifully formatted PDF.
The cookbook includes recipes with photos, ingredients, and cooking instructions.
Telegram bot
Send the bot a recipe text or a link to it and the bot will save the recipe to your account.
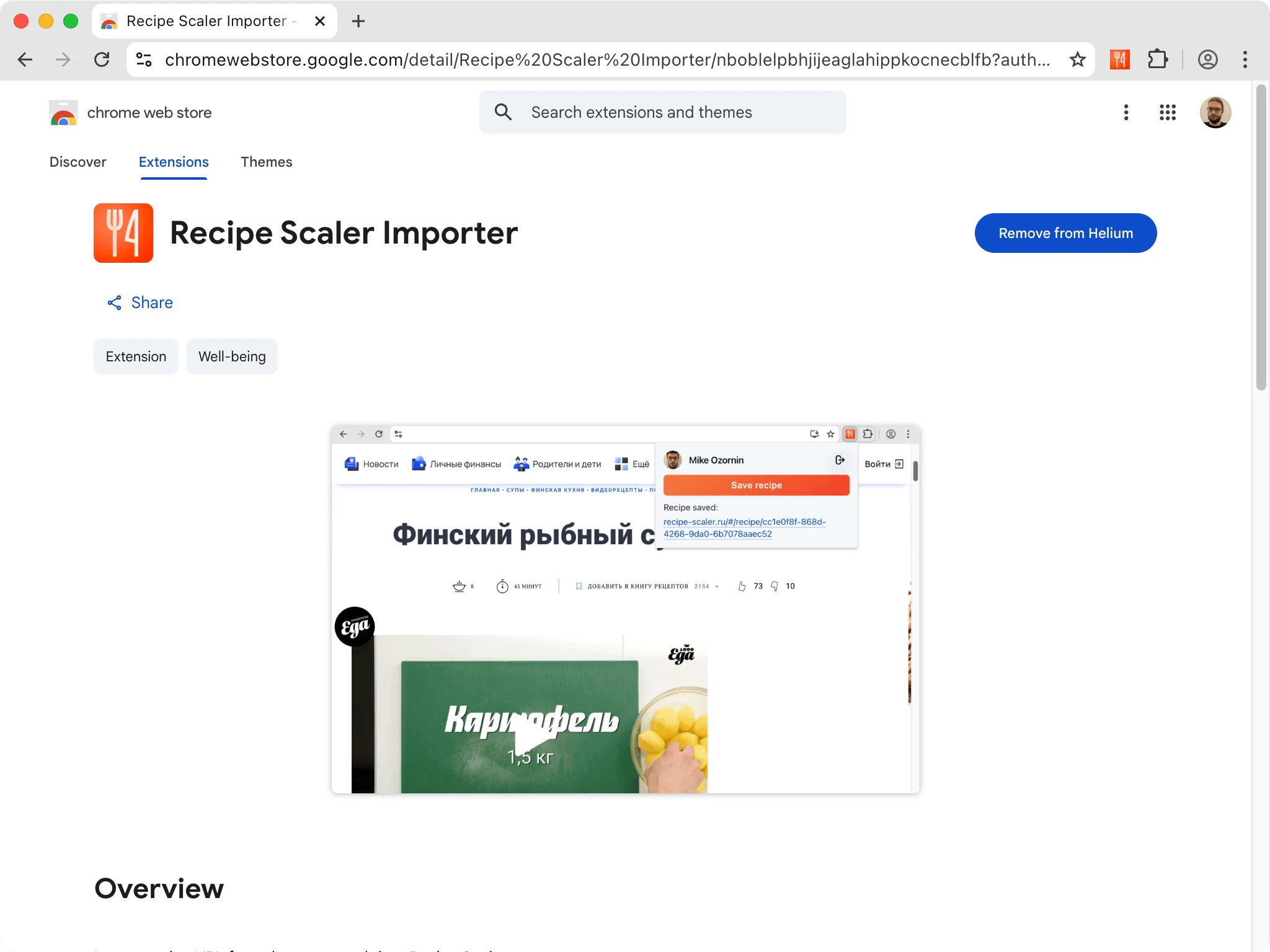
Chrome extension for quick import
Install the Recipe Scaler Importer extension and import the recipe into your account in one click.
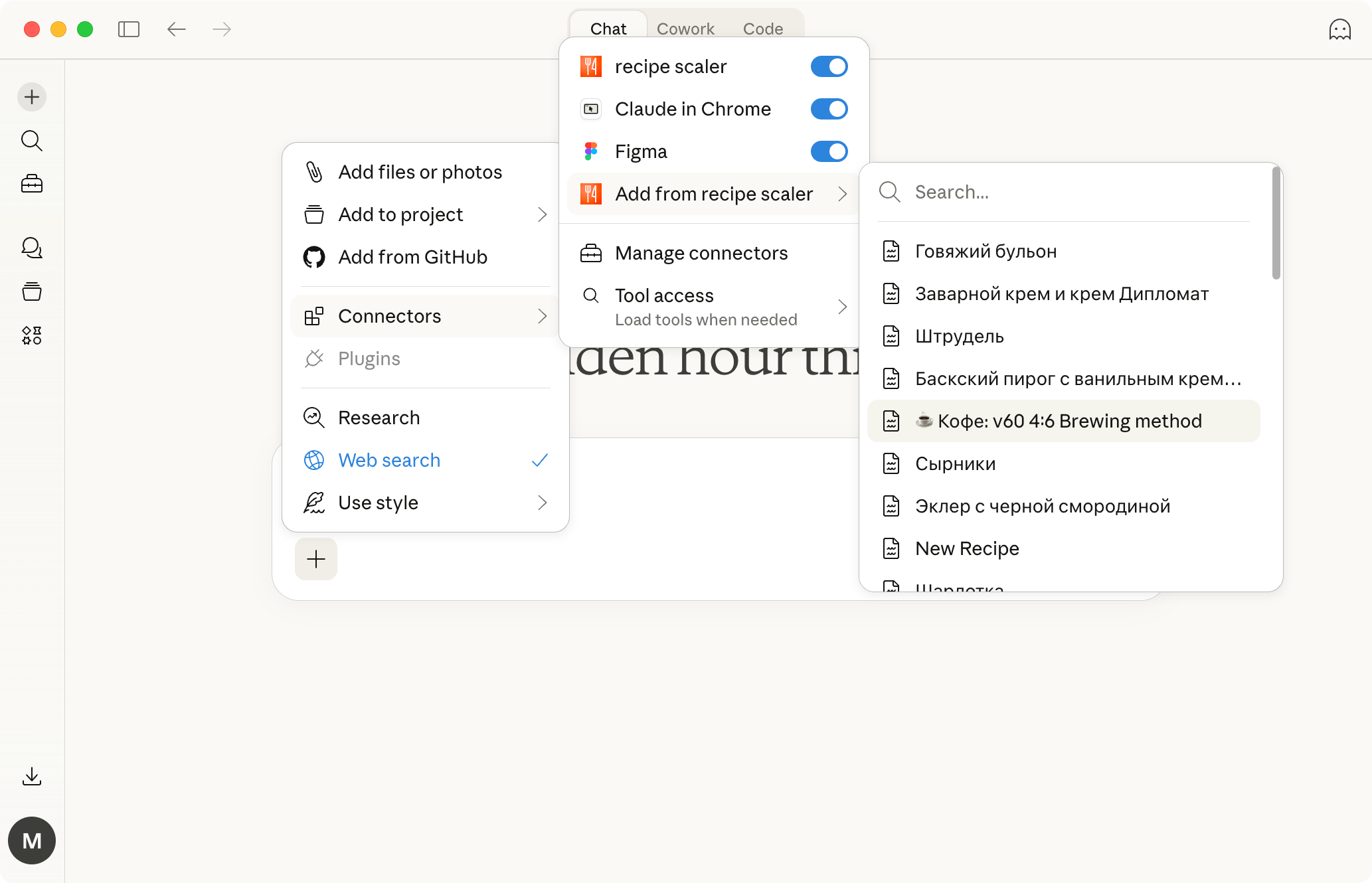
AI assistant integration
Connect your AI assistant to recipes. It can search recipes, add new ones, or help you cook the way you're used to: in chat, by voice. To connect, use the link: recipe-scaler.ru/mcp
For techies: yes, this is an MCP server.
Careful handling of your data
We are paranoid about your privacy.
The app works without sign-up: we don't know your email or your Google login. Even Telegram is only needed for saving recipes. Don't want it? Don't use it.
We don't use trackers or product analytics.
We don't allow AI models to train on your recipes.
Data export and an API are available, so we don't hold your data hostage.
More details: recipe-scaler.ru/#/privacy
If we've convinced you to try:
Go to app
If we haven't convinced you:
Write what's missing
Made by Mikhail Ozornin with Cursor. App idea inspired by app by Roman Shamin.
© Mikhail Ozornin, 20251.2 Особенности эксперимента
- Моделям были даны базовые ограничения и инструкции, не было никаких уточнений по стилю, дизайн-системе и прочему. На уточняющие вопросы я не отвечал, скипал их. Вмешательства в процессе не было, максимум — если агент чего-то ждал, я просил начать или продолжить.
- Все модели, кроме Опуса 4.7 работали на максимально возможной установке ризонинга или параметра его замещающего (эффорт для клод кода).
- Я специально не давал пожеланий по стилю, не прикладывал никакую дизайн-систему, не описывал более важные и менее важные сценарии. Мне хотелось проверить не что я смогу задизайнить с ллм, а что сможет сам агент.
- Все тексты были на английском. Это небольшой чит для моделей — хороших шрифтов для английского заметно больше, чем для кириллицы. С кириллицей было бы похуже, я думаю. И шрифтовой выбор был бы более примитивный, и вообще смело бы выбрали шрифты, в которых вообще не бывает кириллицы.
- Для дизайна использовался Paper MCP, в качестве резервного варианта — Figma MCP. Paper MCP работает лучше, быстрее и открыт к большему числу агентов. Фигма не позволяет открытым агентам Опенкод и Кило с ними работать. С Figma MCP я тоже проверил, просто запусти вариантов поменьше.
- Чтобы сравнение было честнее, я не чинил макеты руками, максимум — изредка растягивал фрейм, если агент сделал артборд меньше собственного контента. Обидно было видеть, что вот же оно.
1.3 Формальные цели
Что я хотел посмотреть и проверить:
- Результат: насколько сделанные макеты вообще похожи на решение задачи, насколько результат можно использовать в работе, насколько красиво, аккуратно и в целом хорошо.
- Внутренности: насколько чисто сверстано внутри, хочется ли помыть после этого руки.
- Что по стоимости решения.
- Насколько сильно результат зависит от агента.
- Насколько сильно результат зависит от уровня ризонинга.
В целом я хотел понять, какие модели и агенты имеет смысле для чего-то использовать, а какие не имеет.
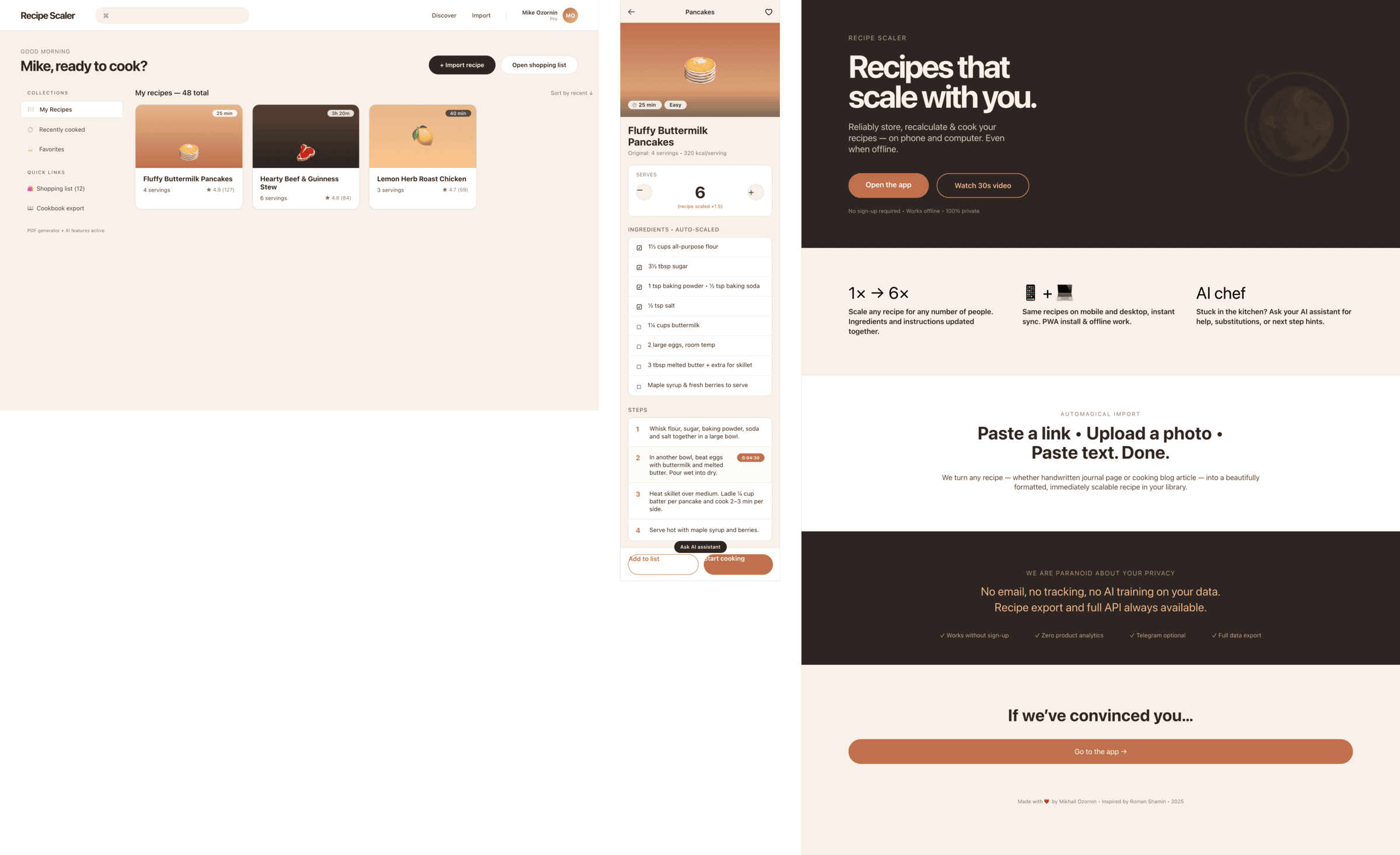
2 Результаты
Разрыв между моделями огромный — некоторые верстали интересно и красиво. Другие верстали нейрослоп в худшем его понимании, третьи — вообще не могли справиться с тулами и выдавали сломанный макет.
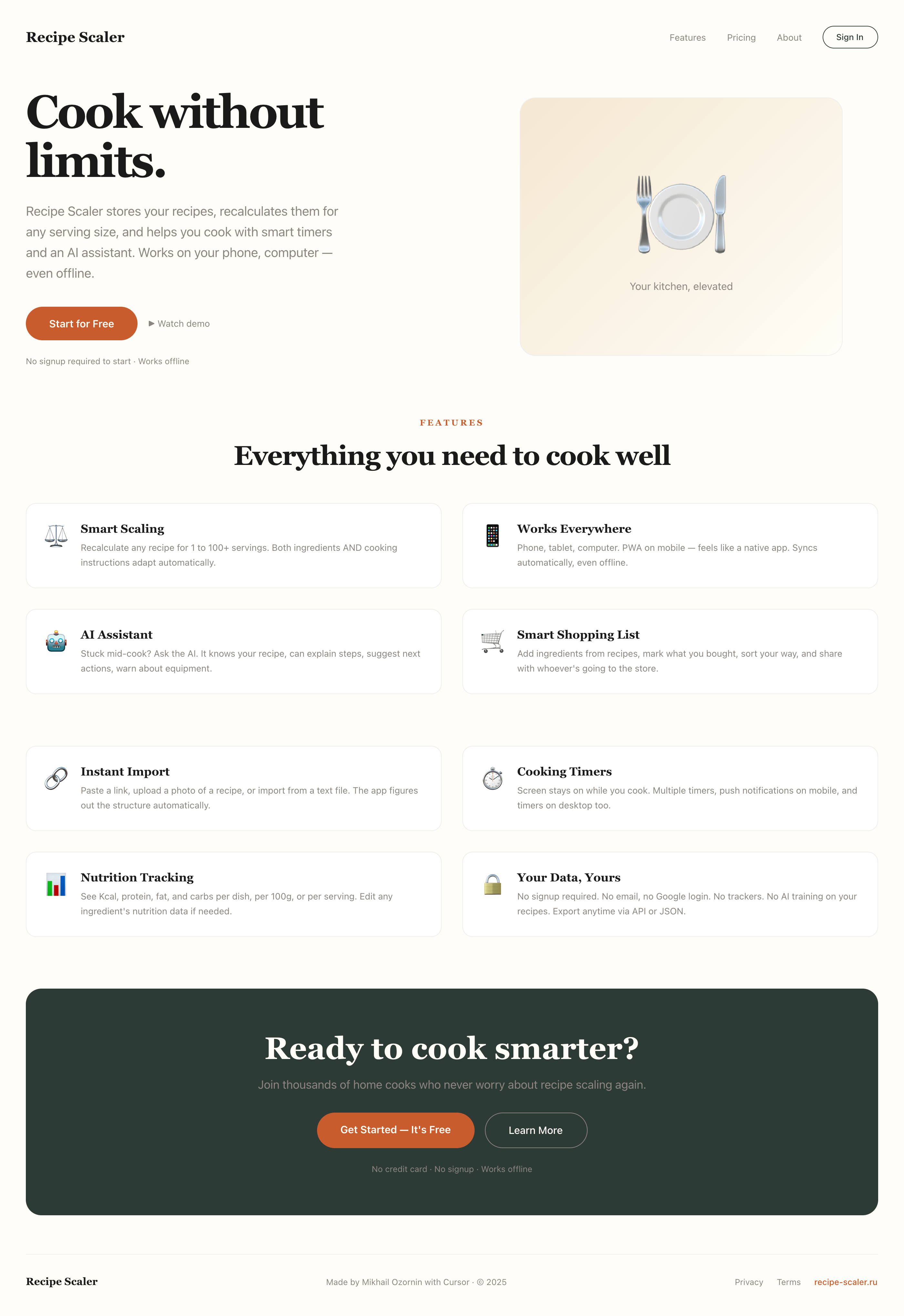
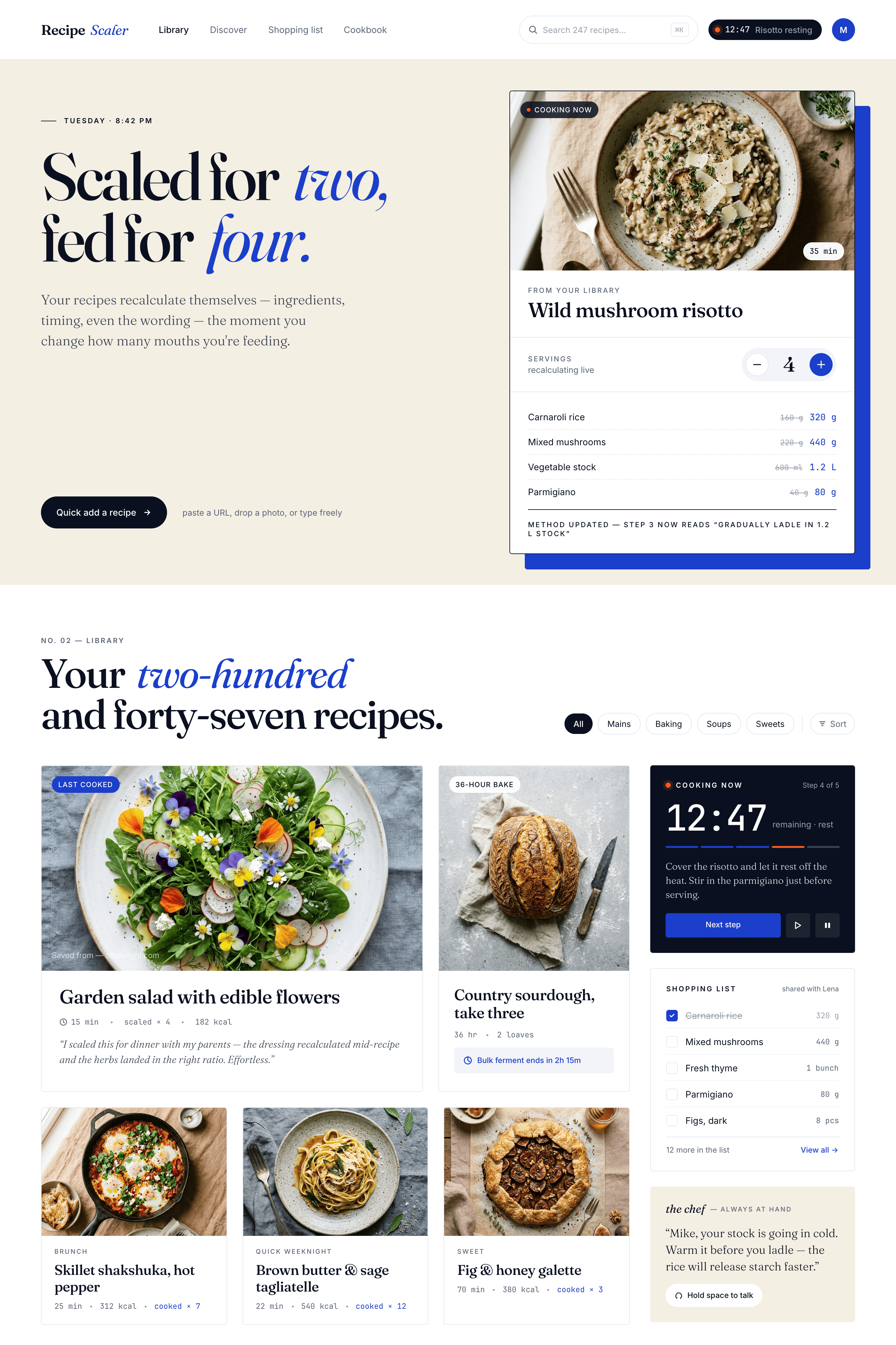
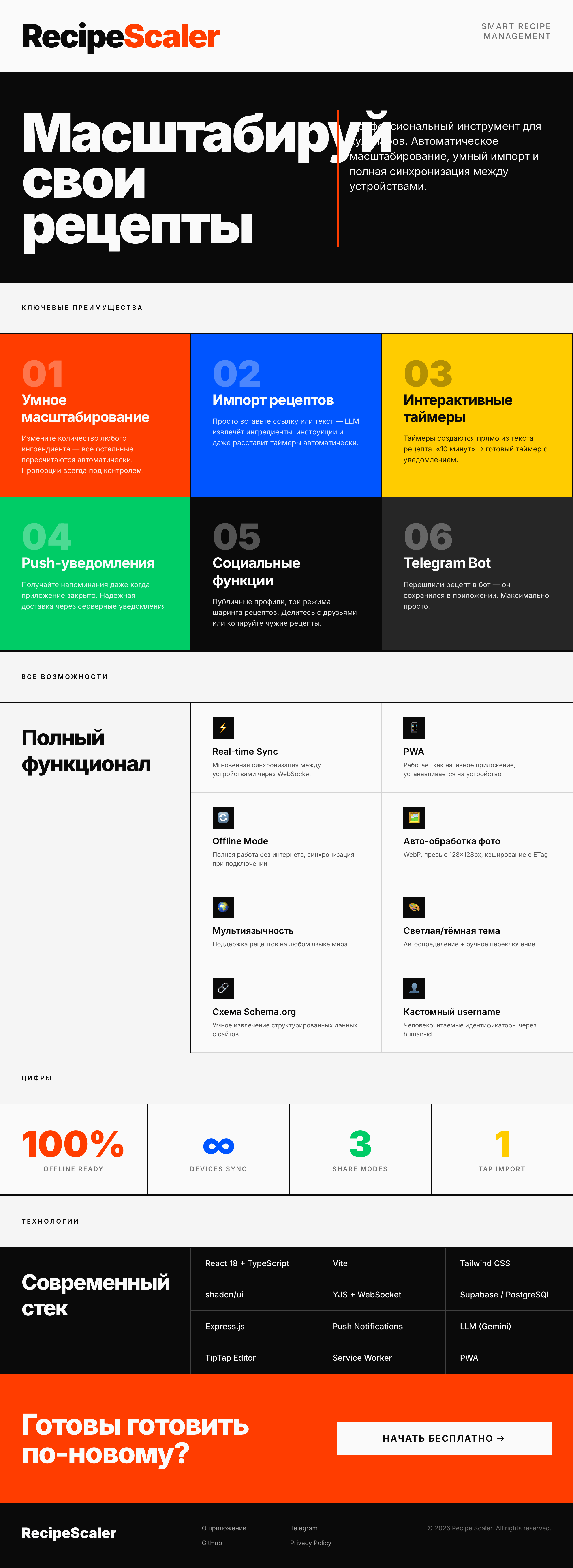
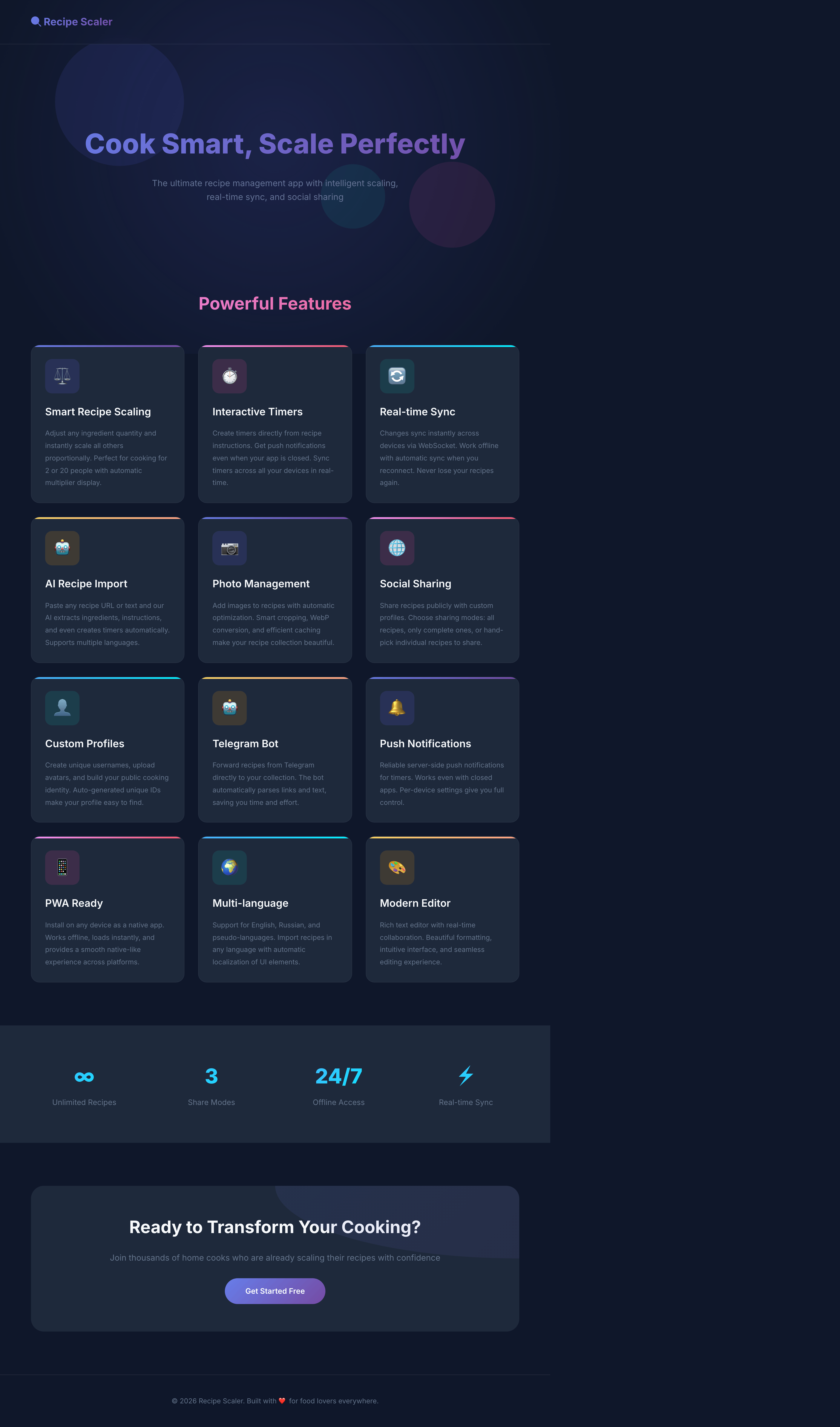
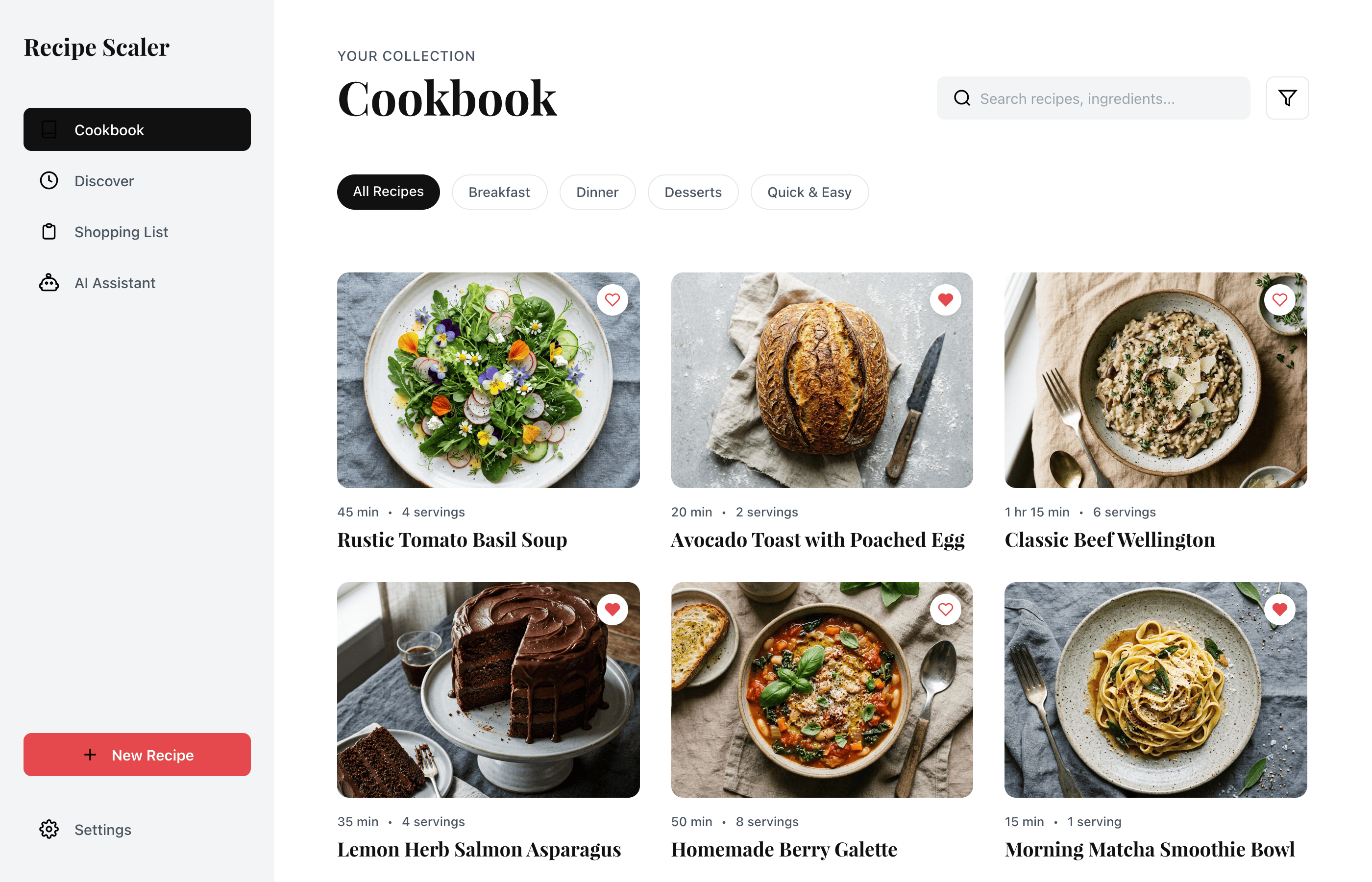
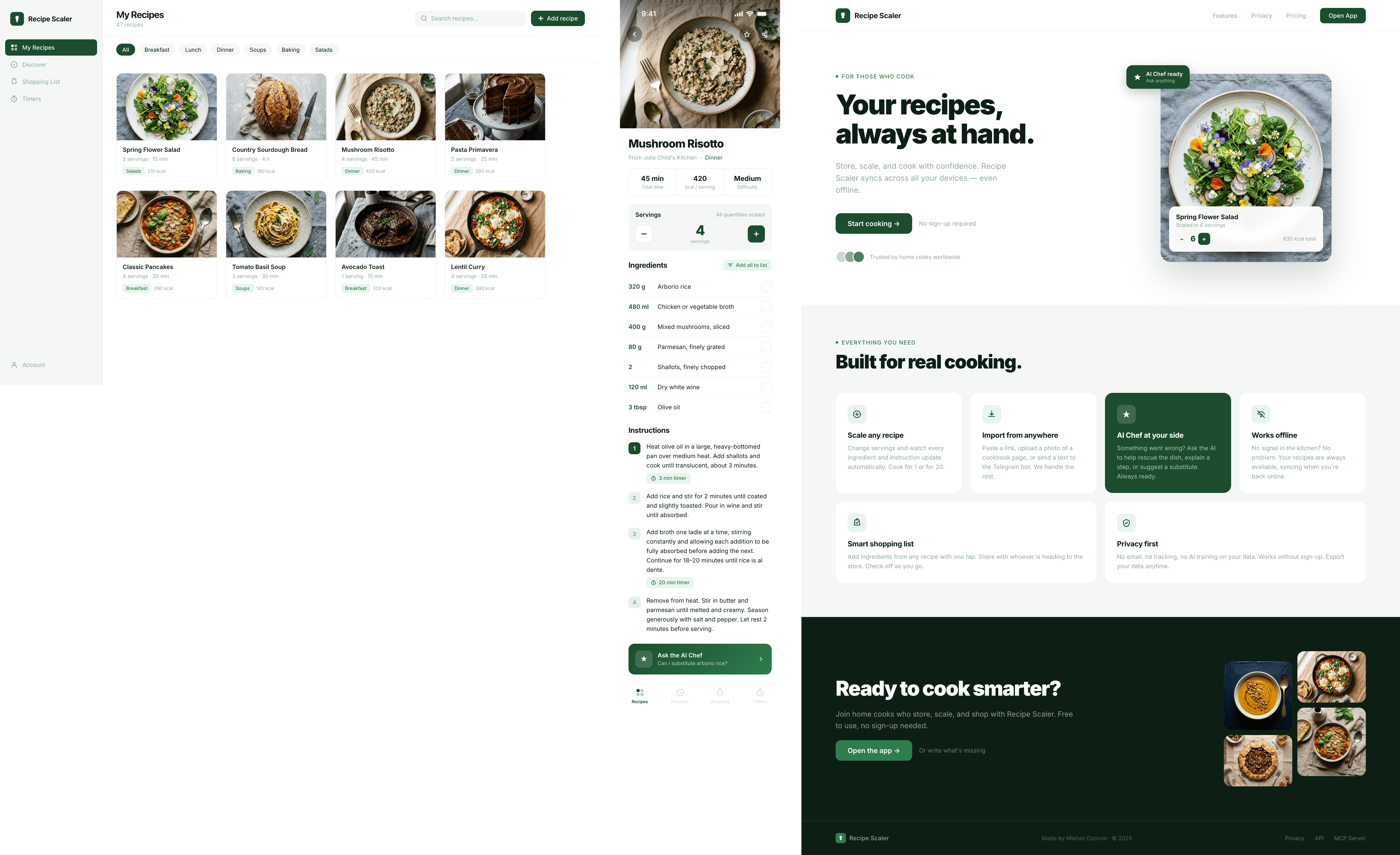
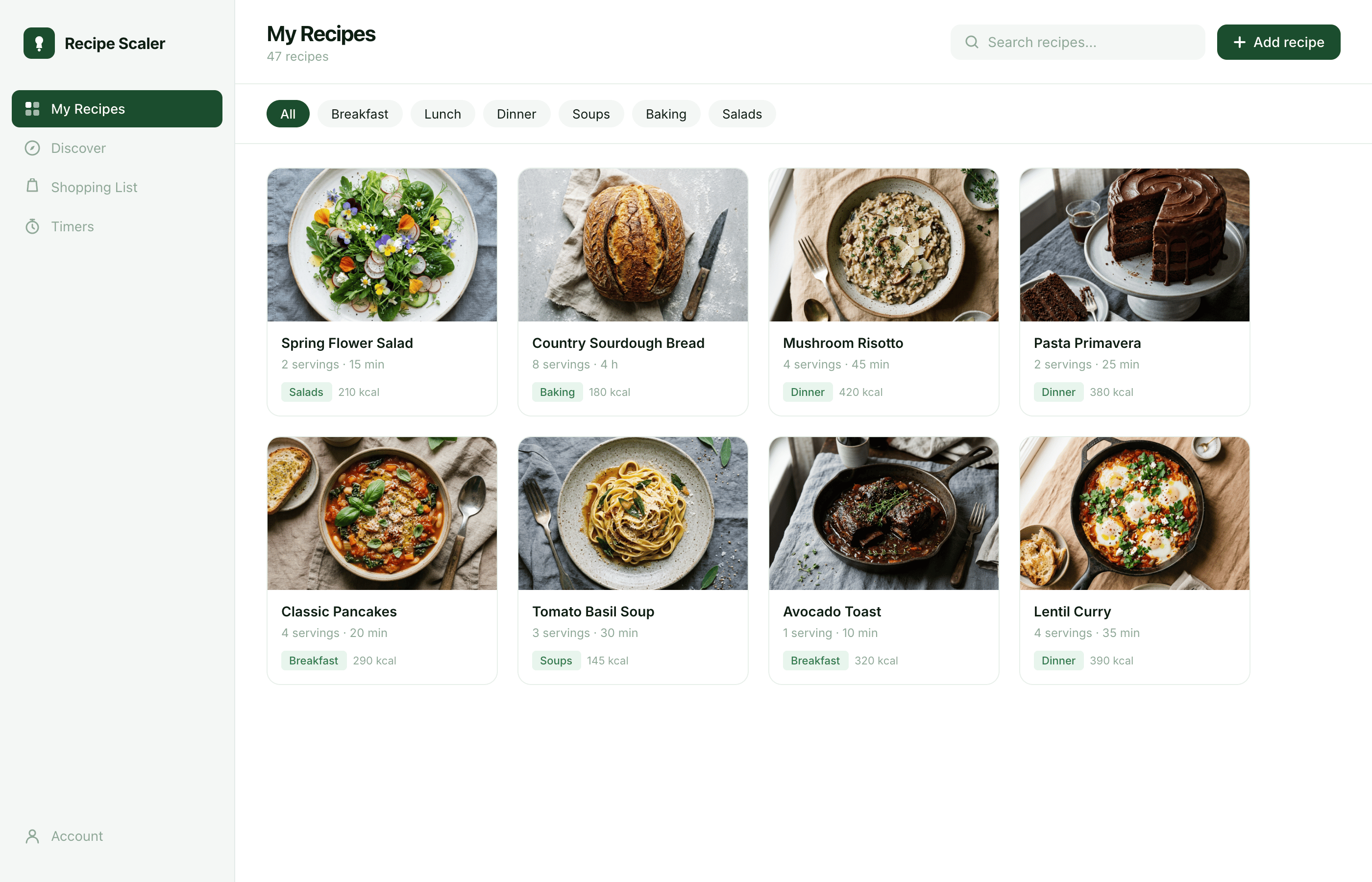
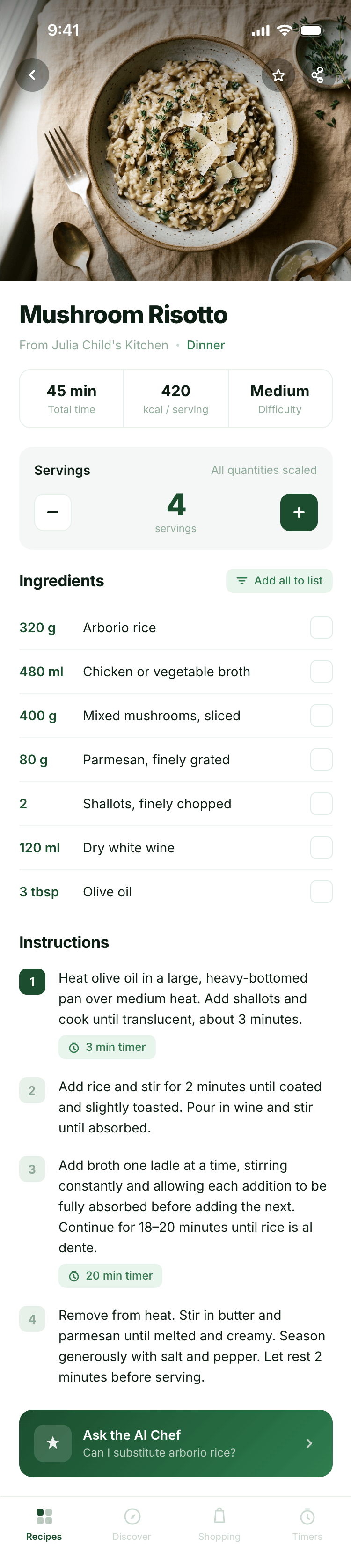
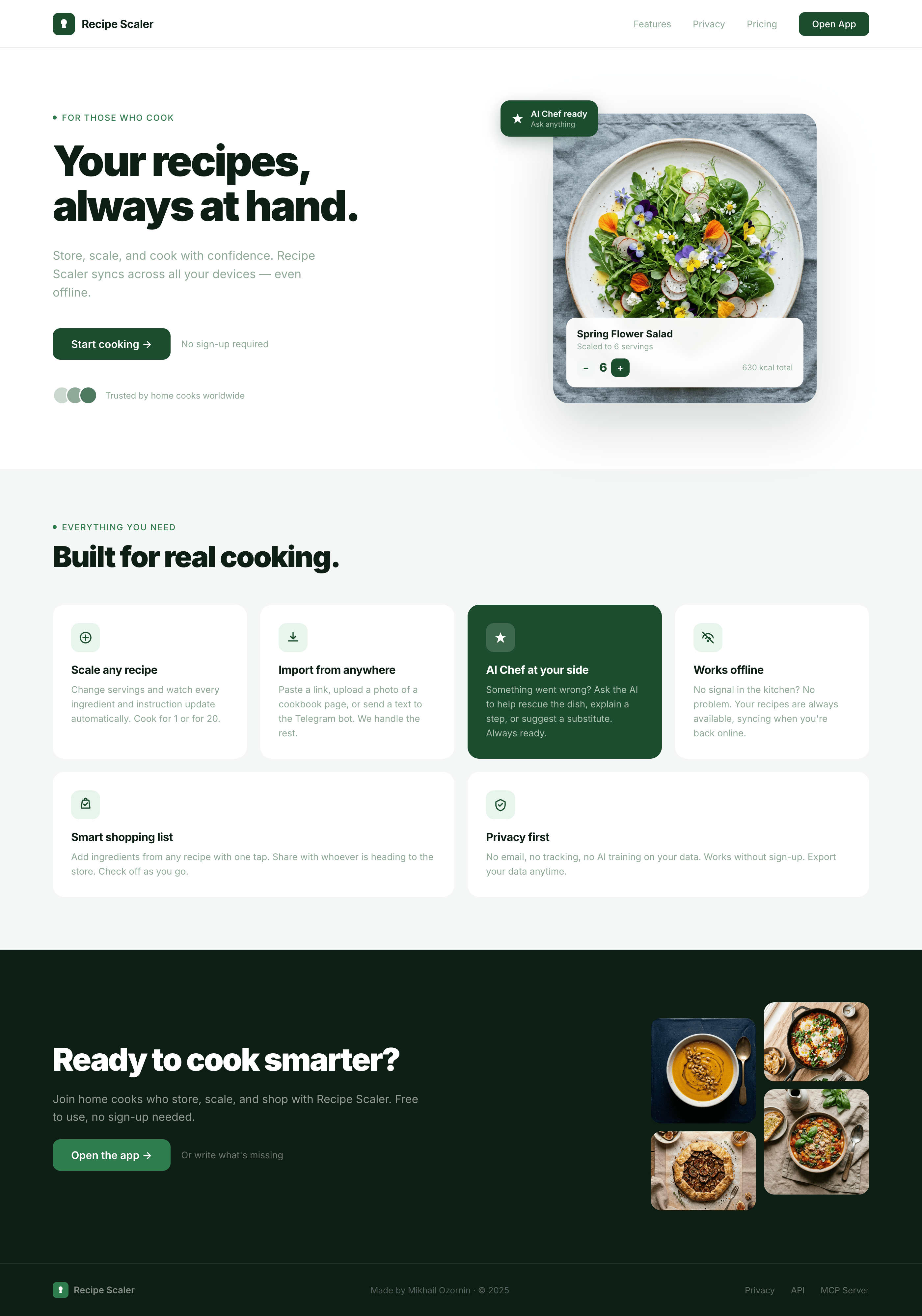
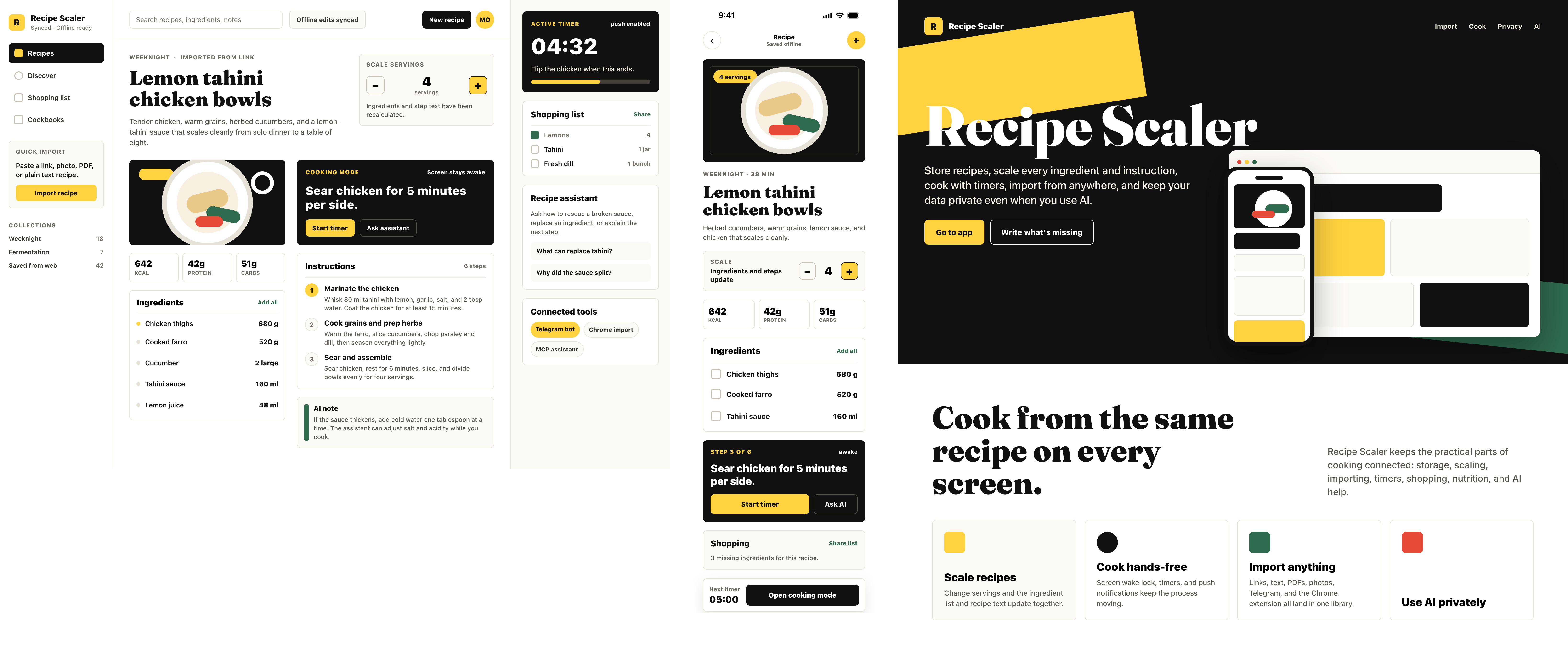
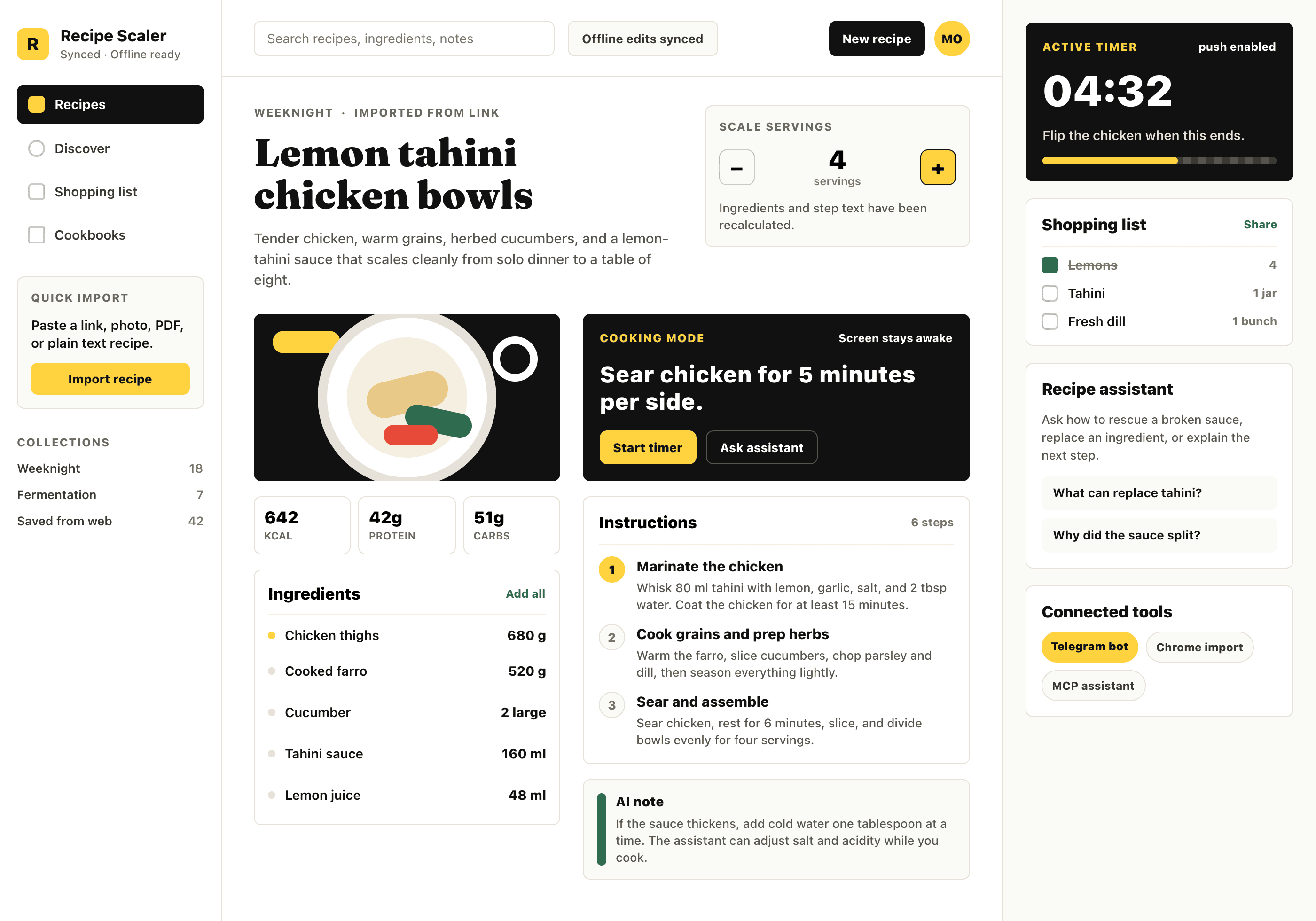
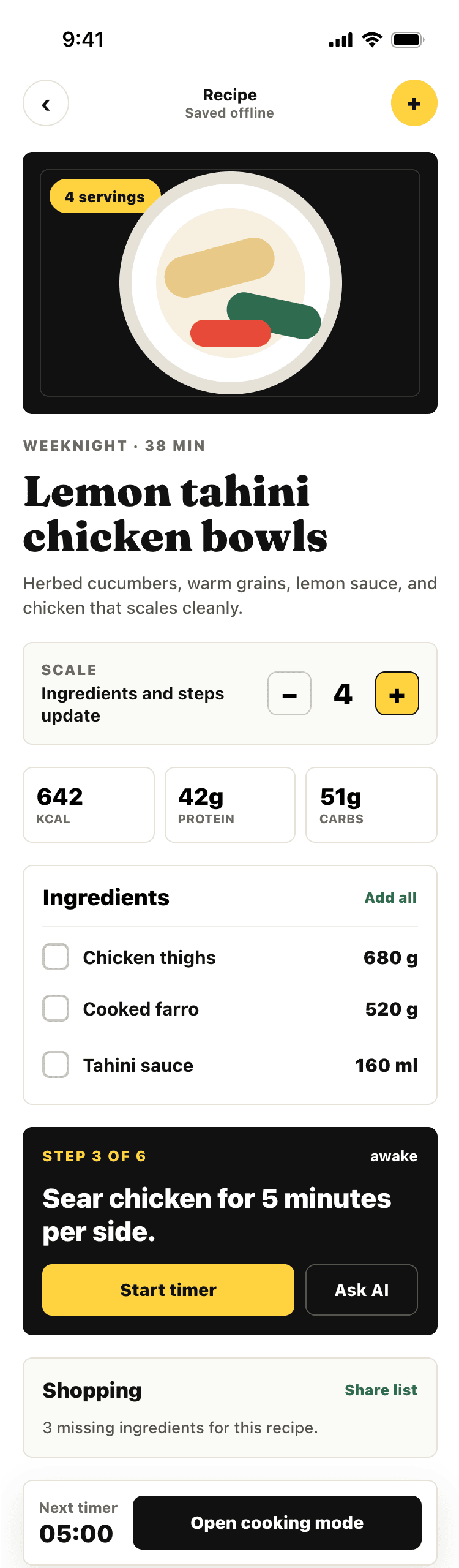
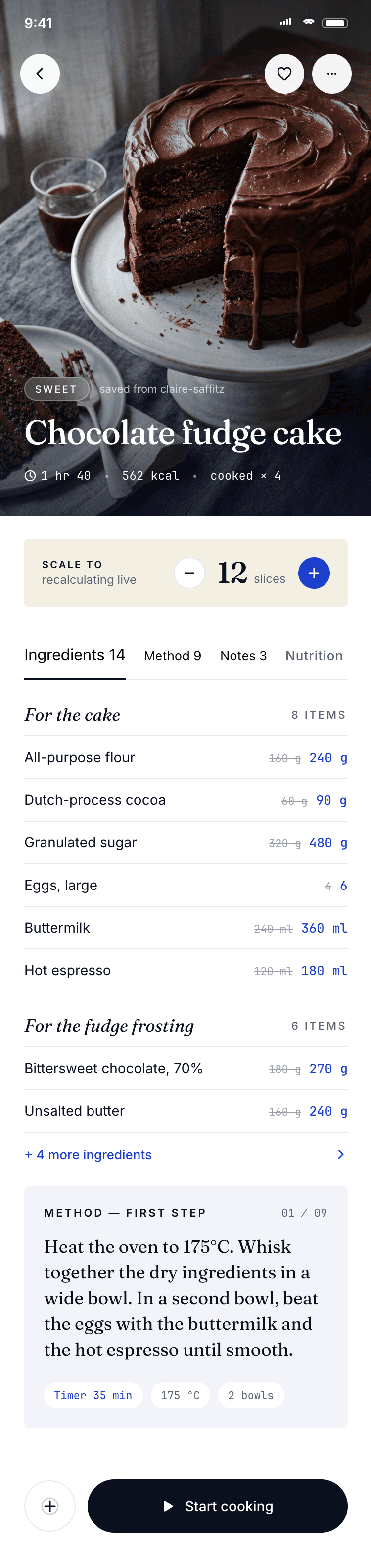
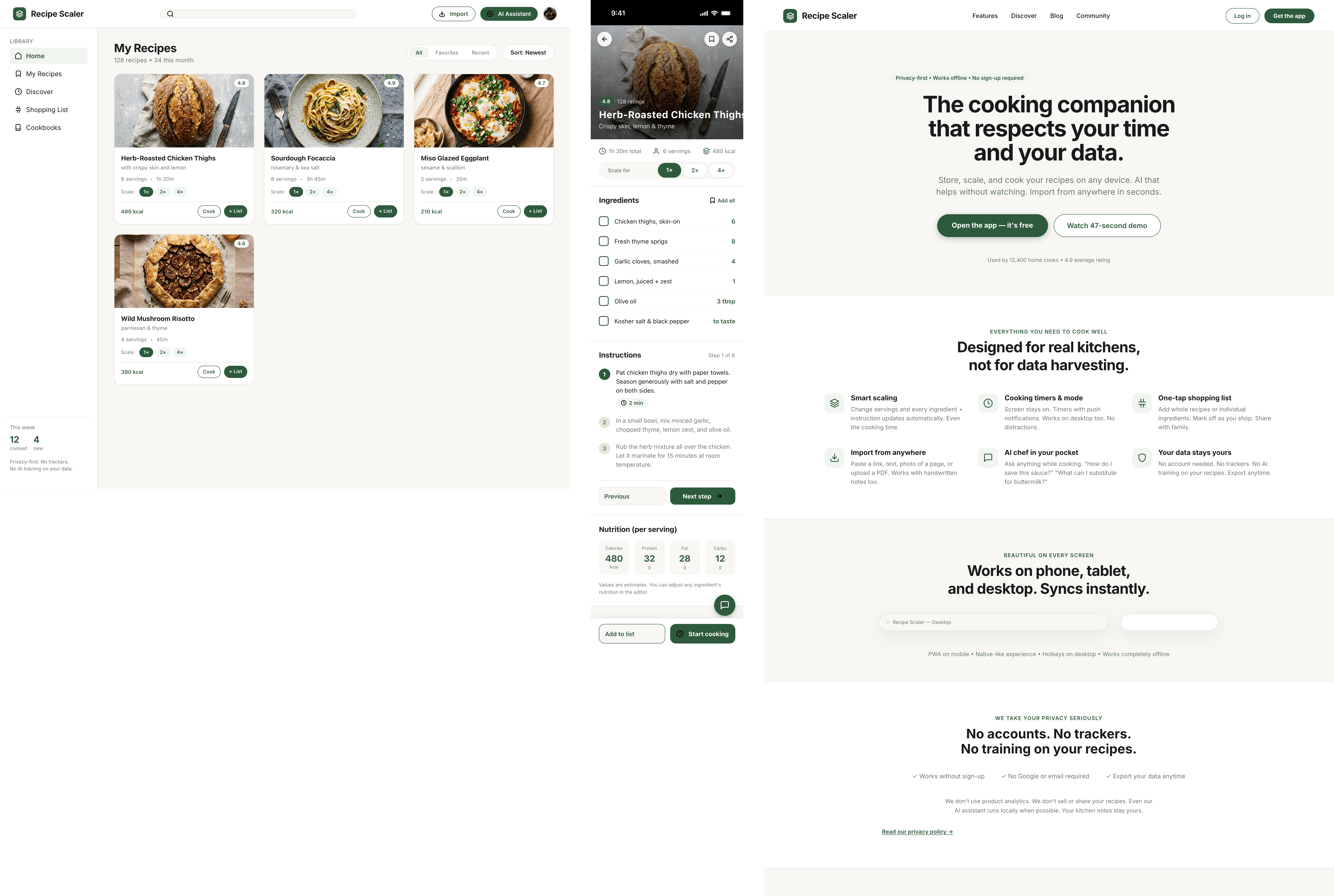
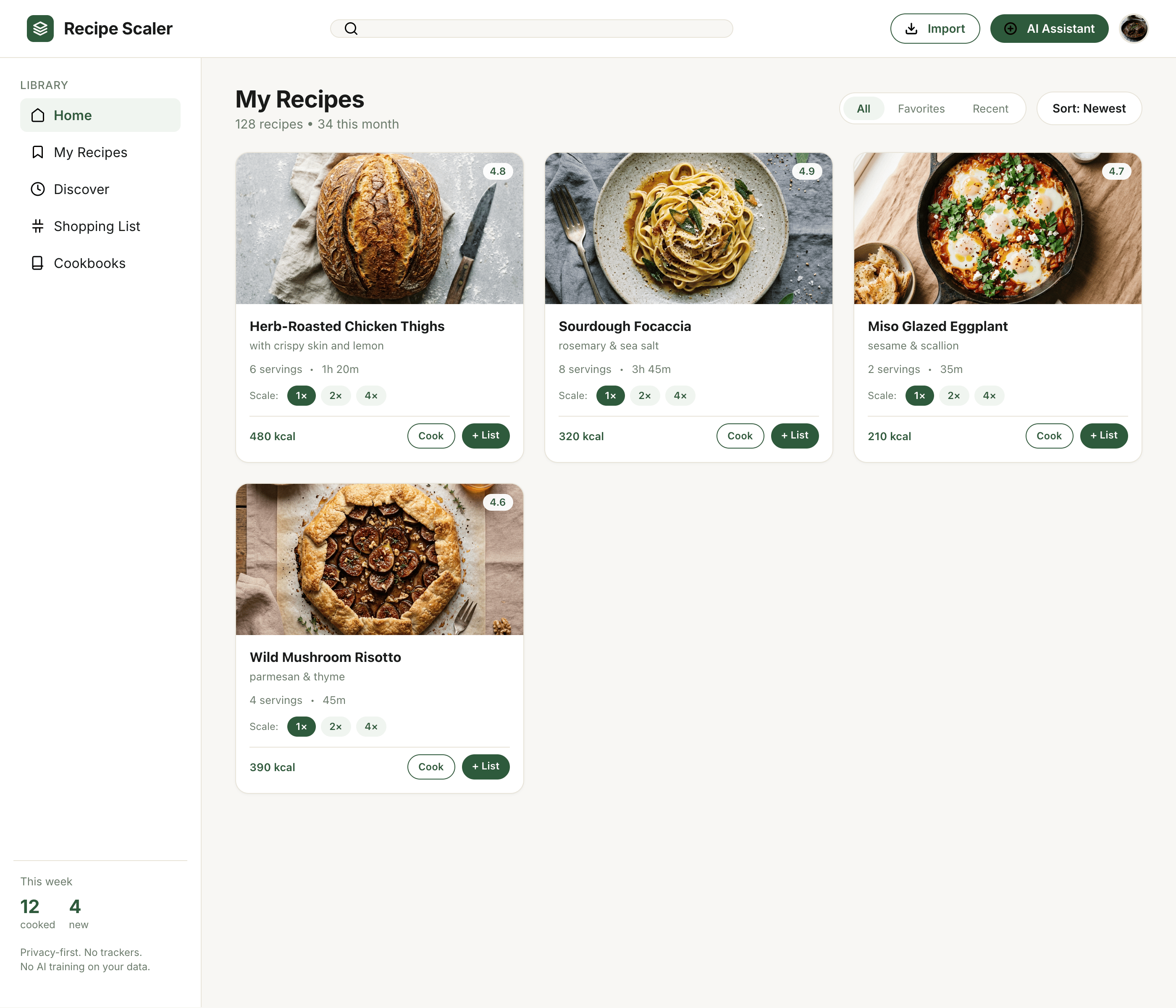
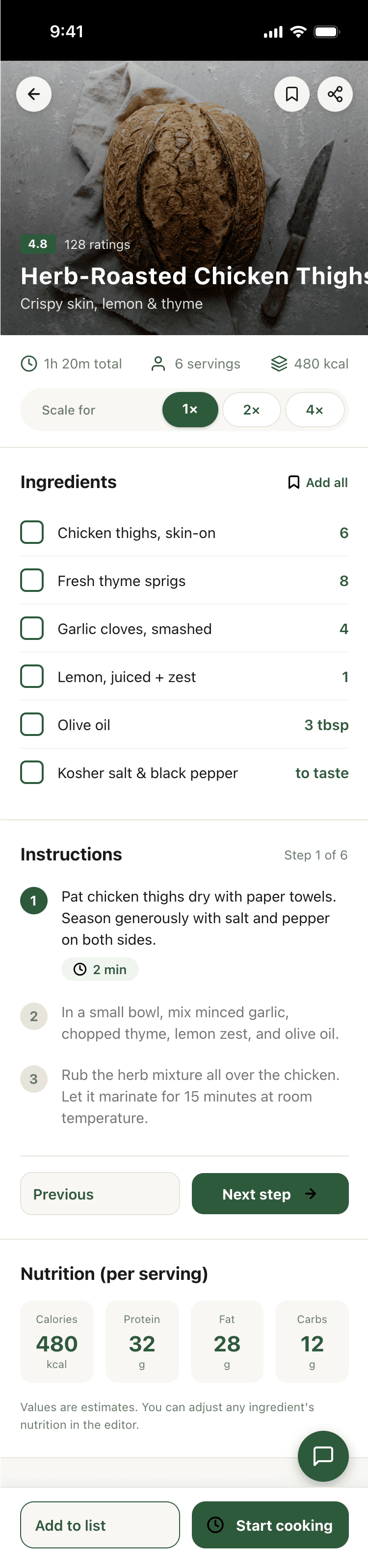
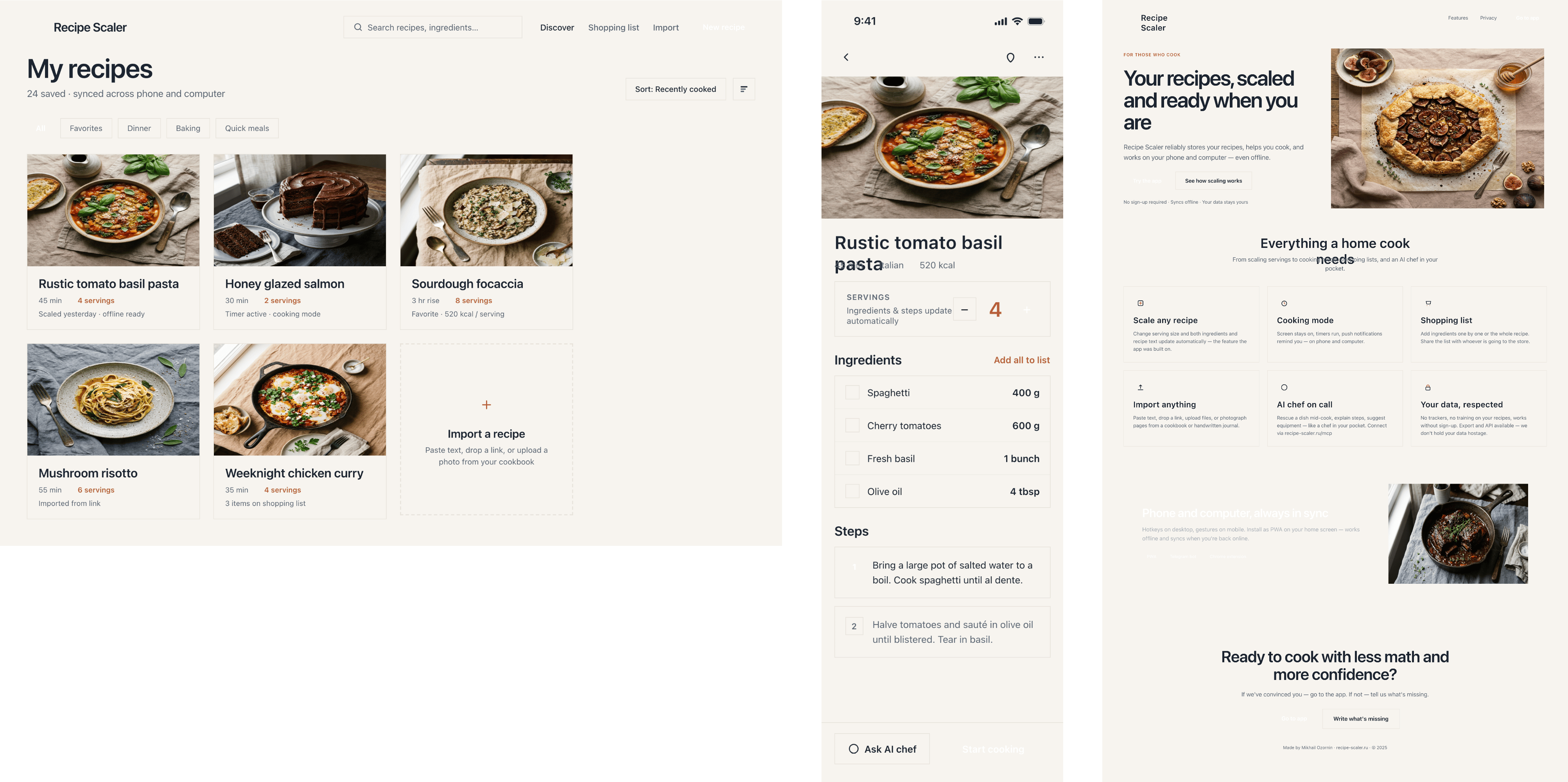
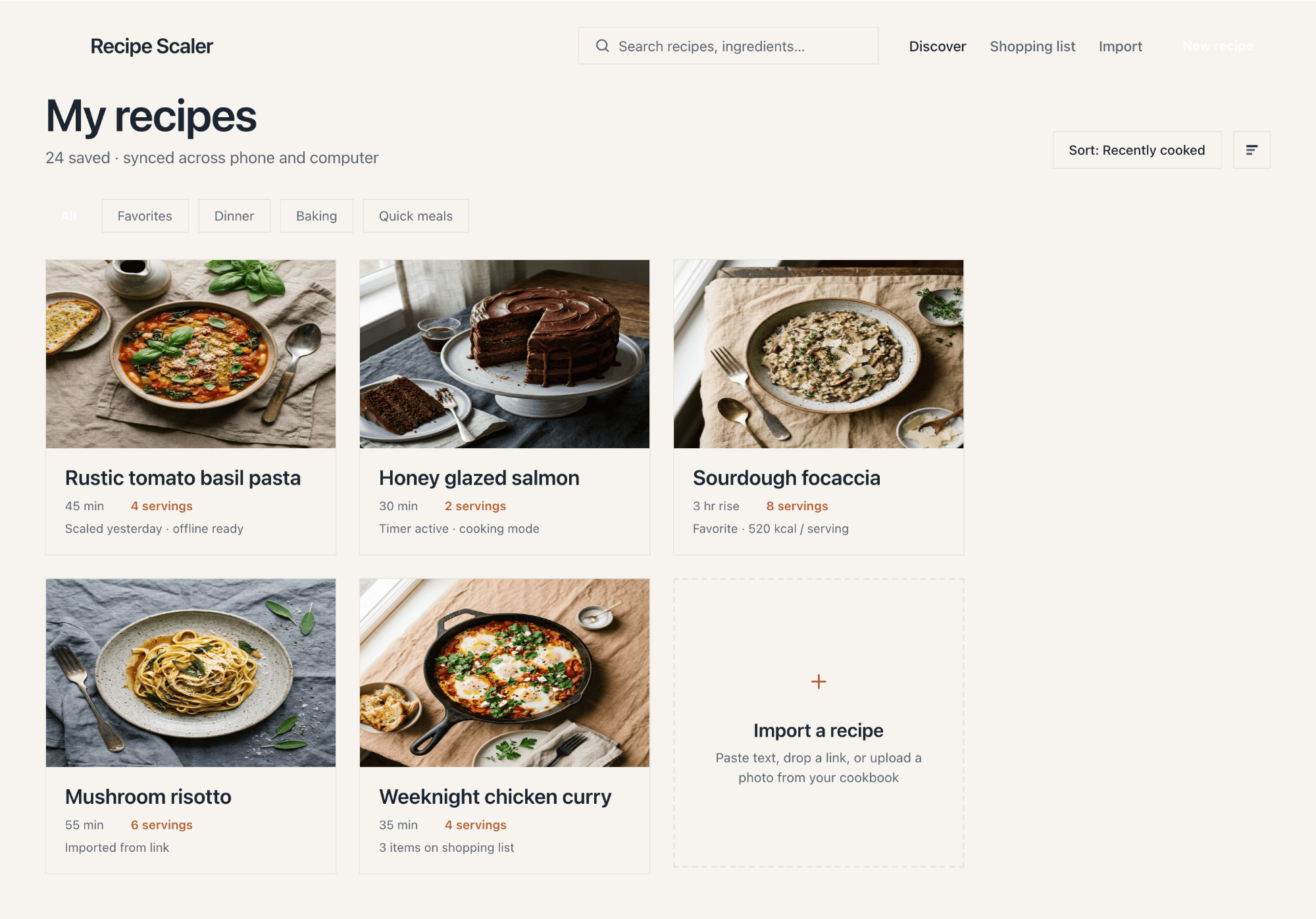
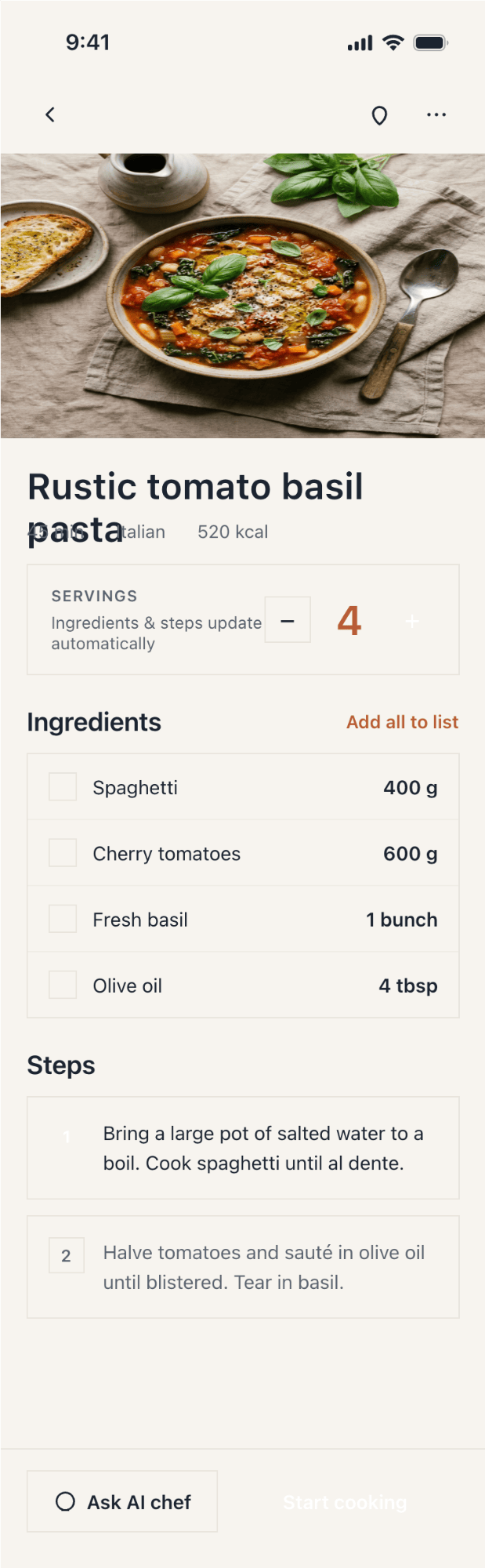
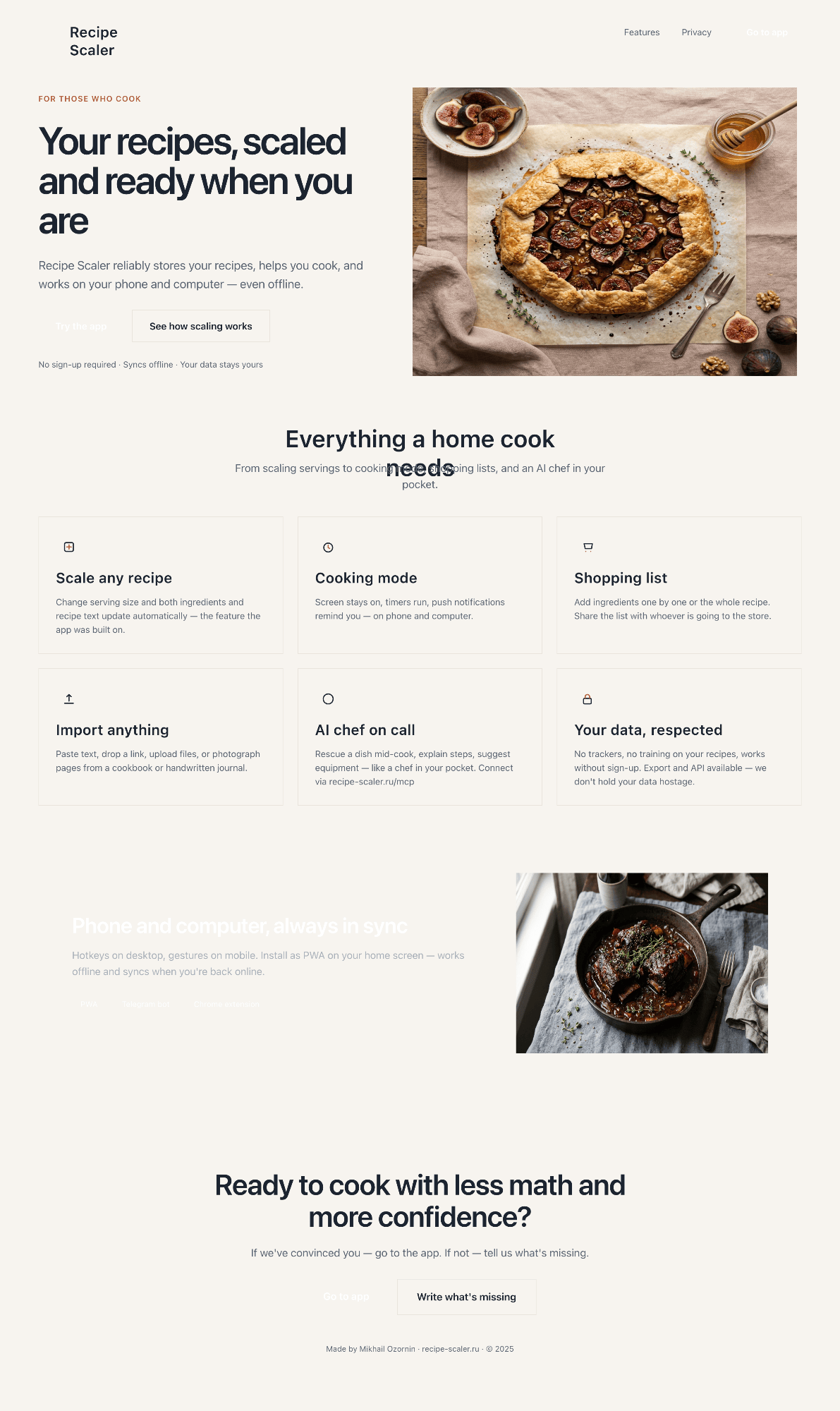
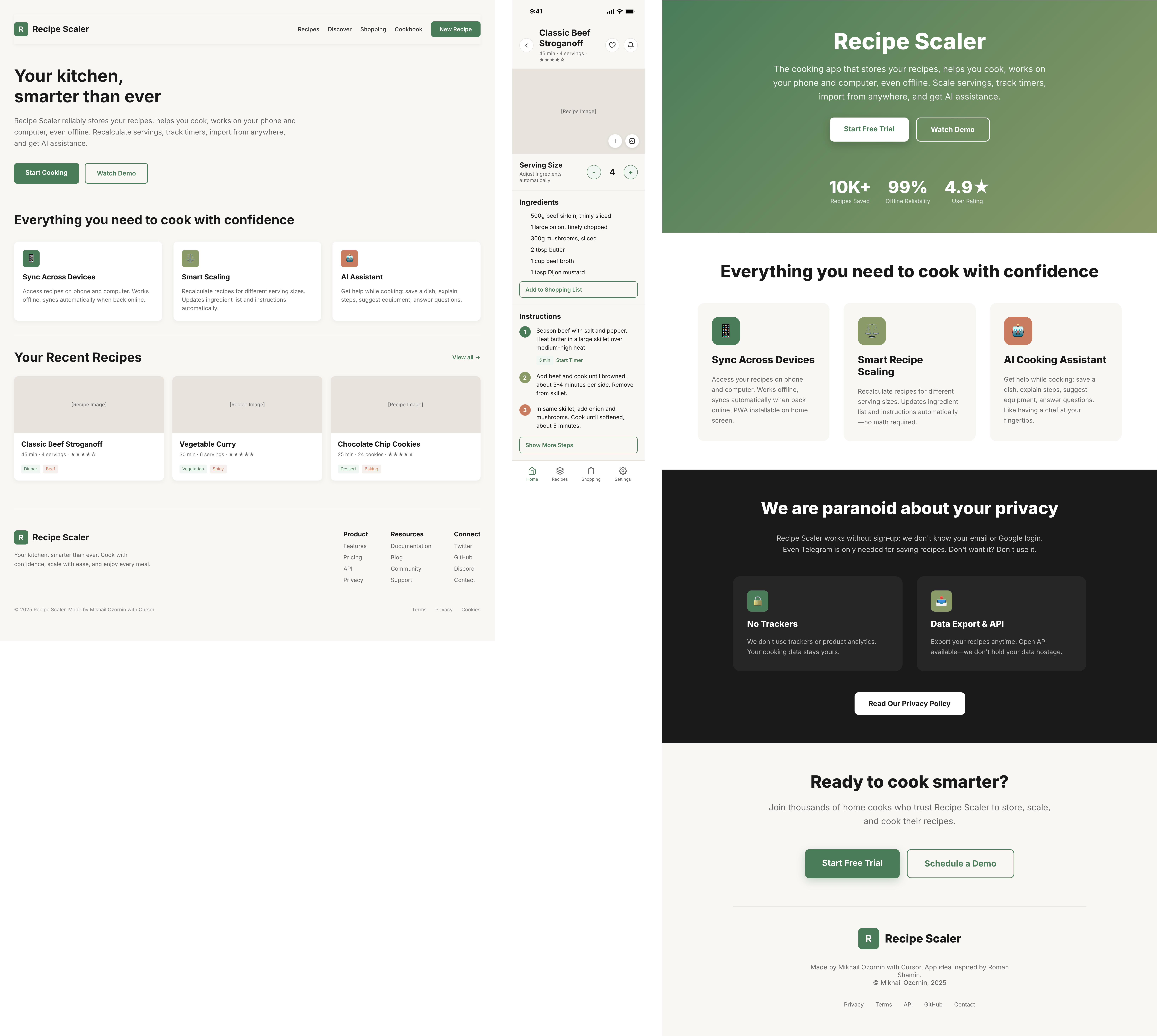
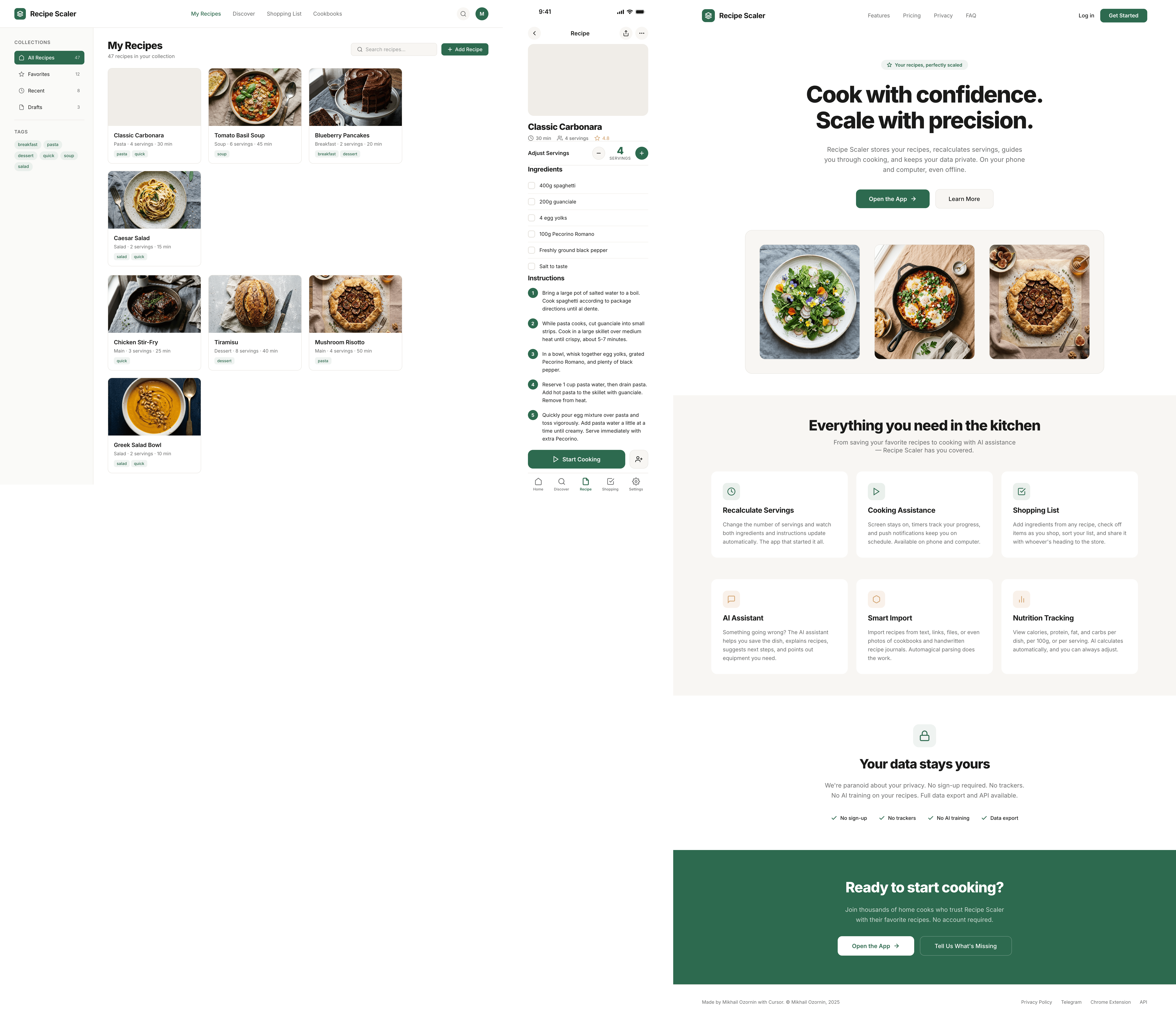
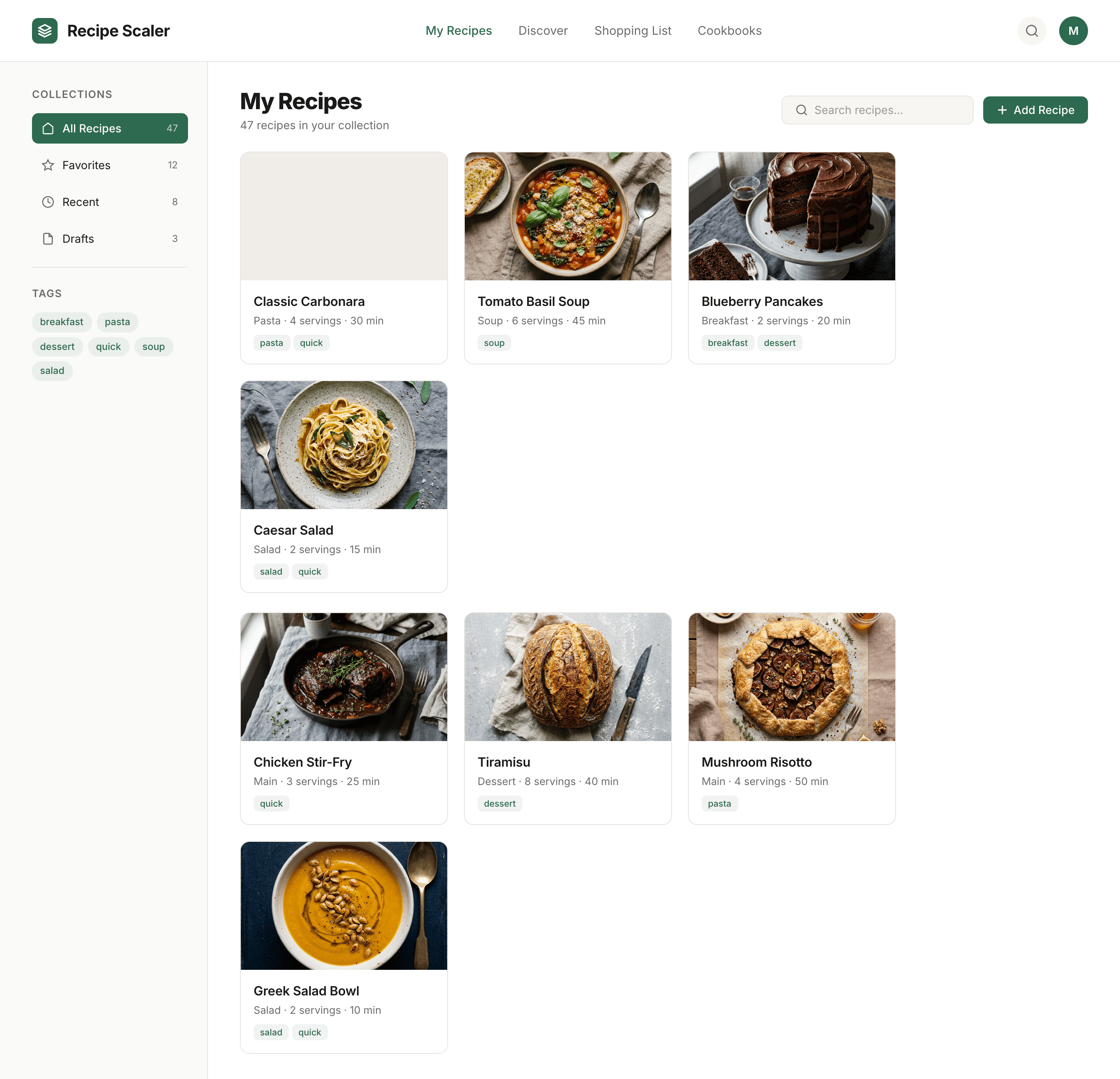
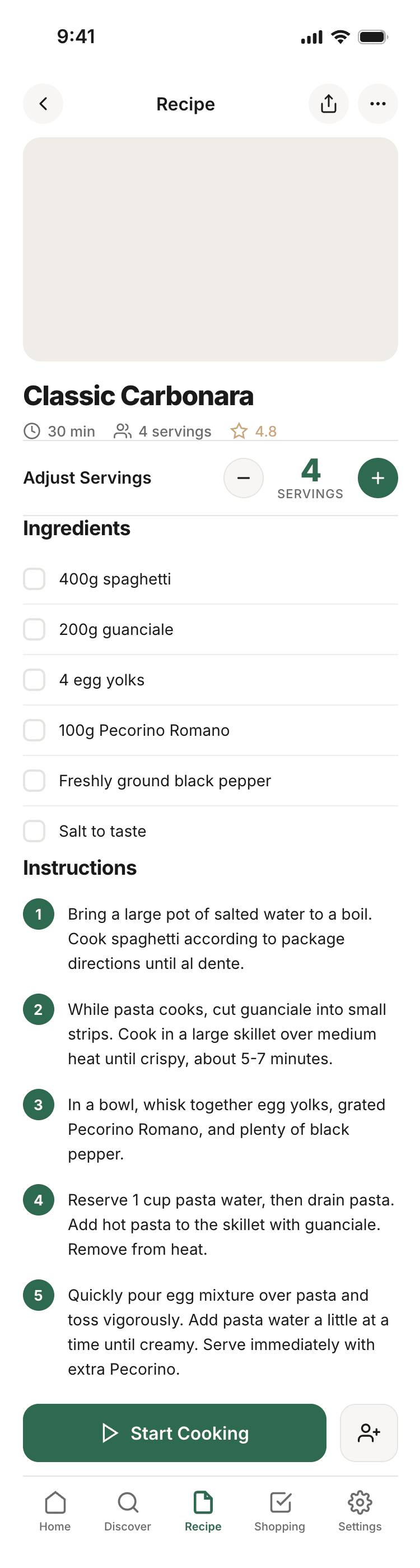
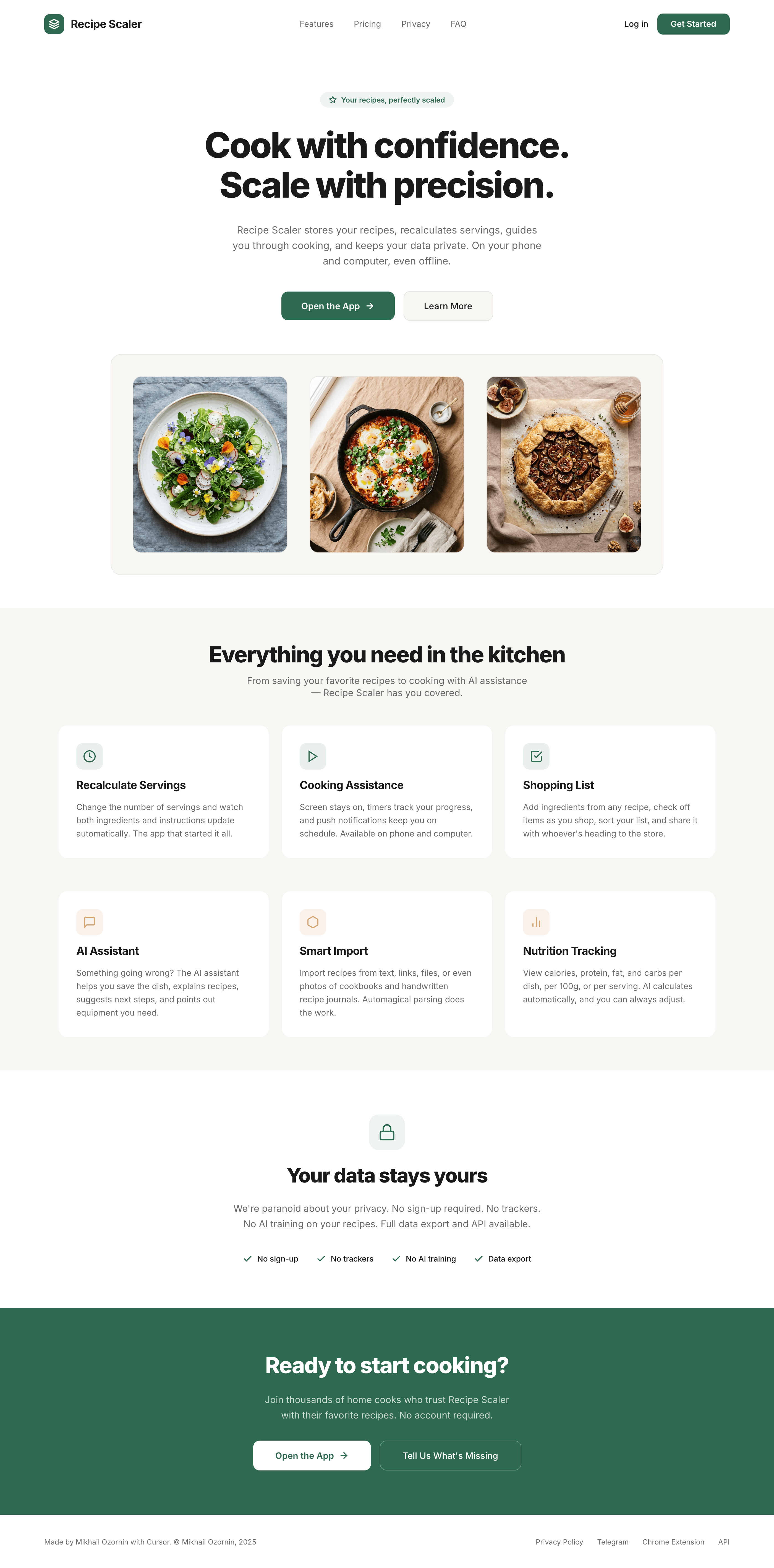
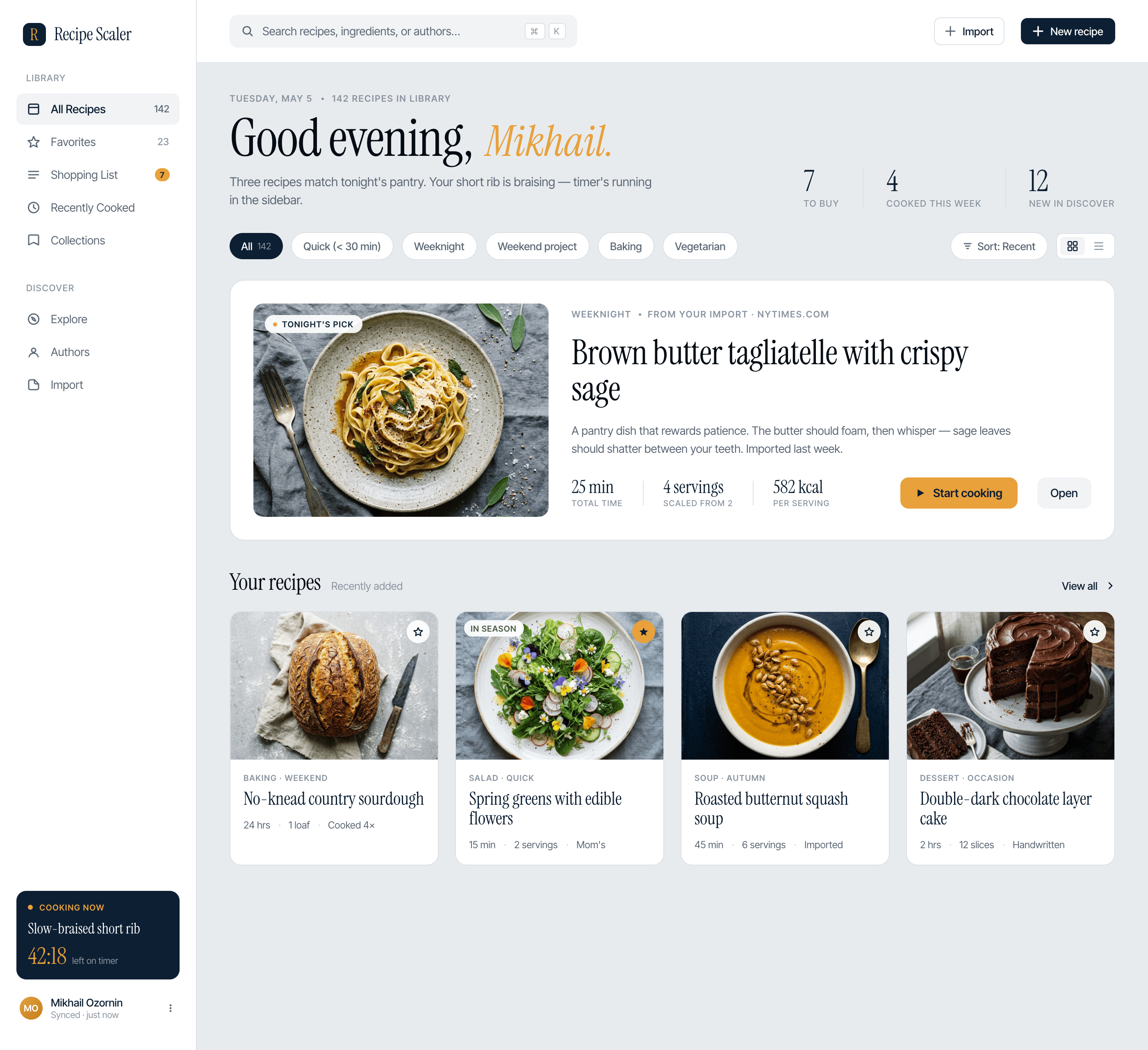
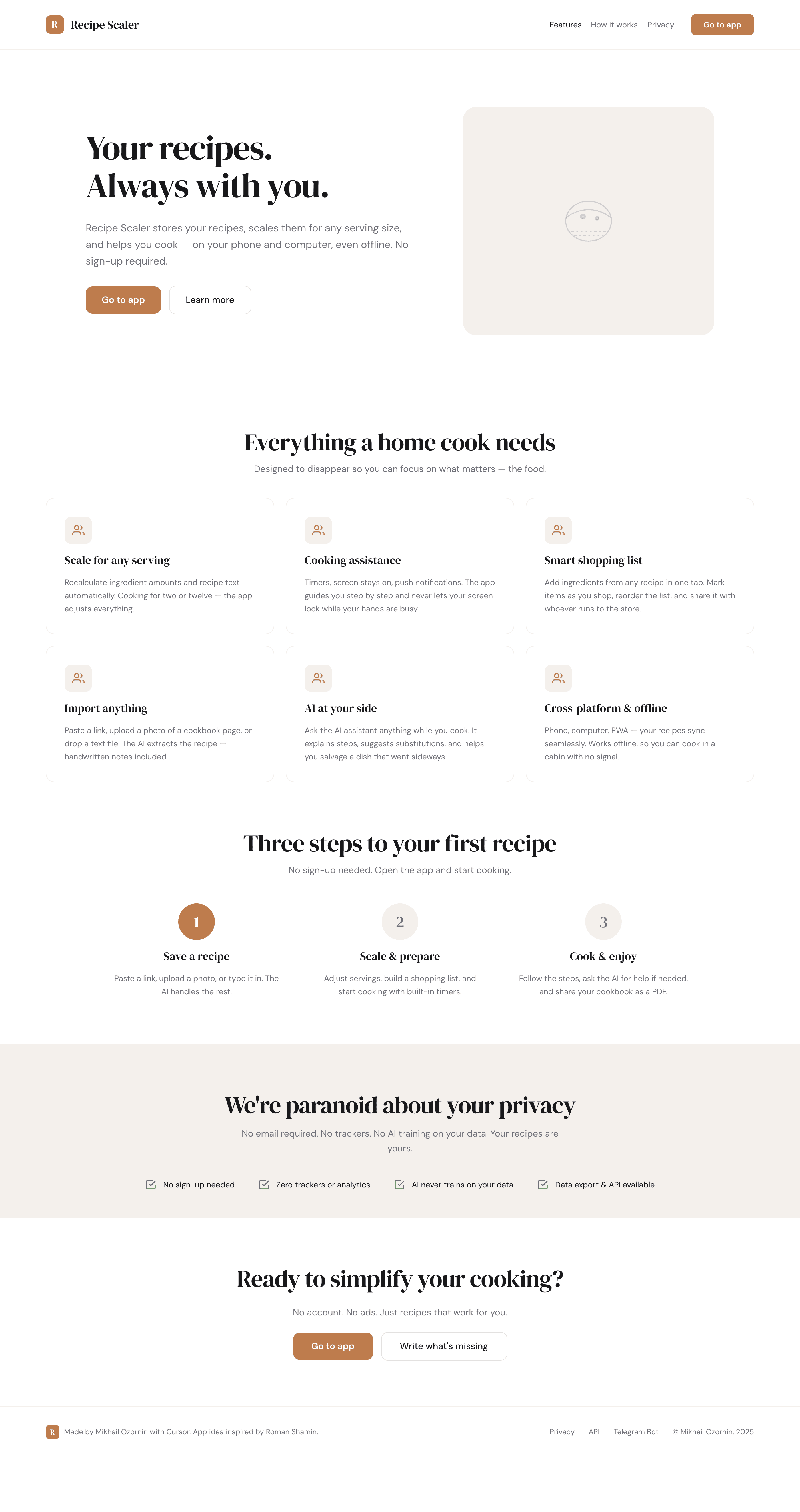
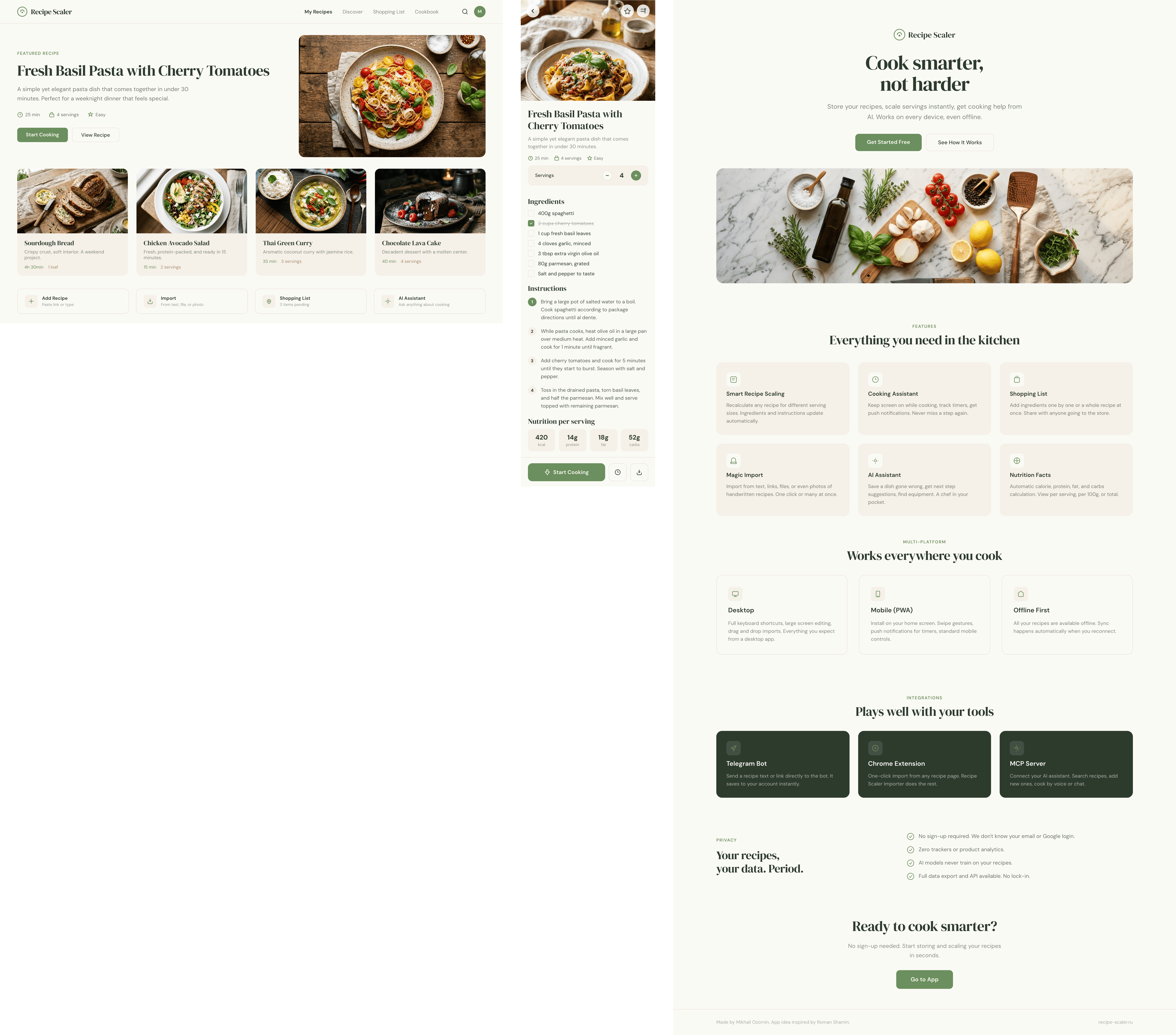
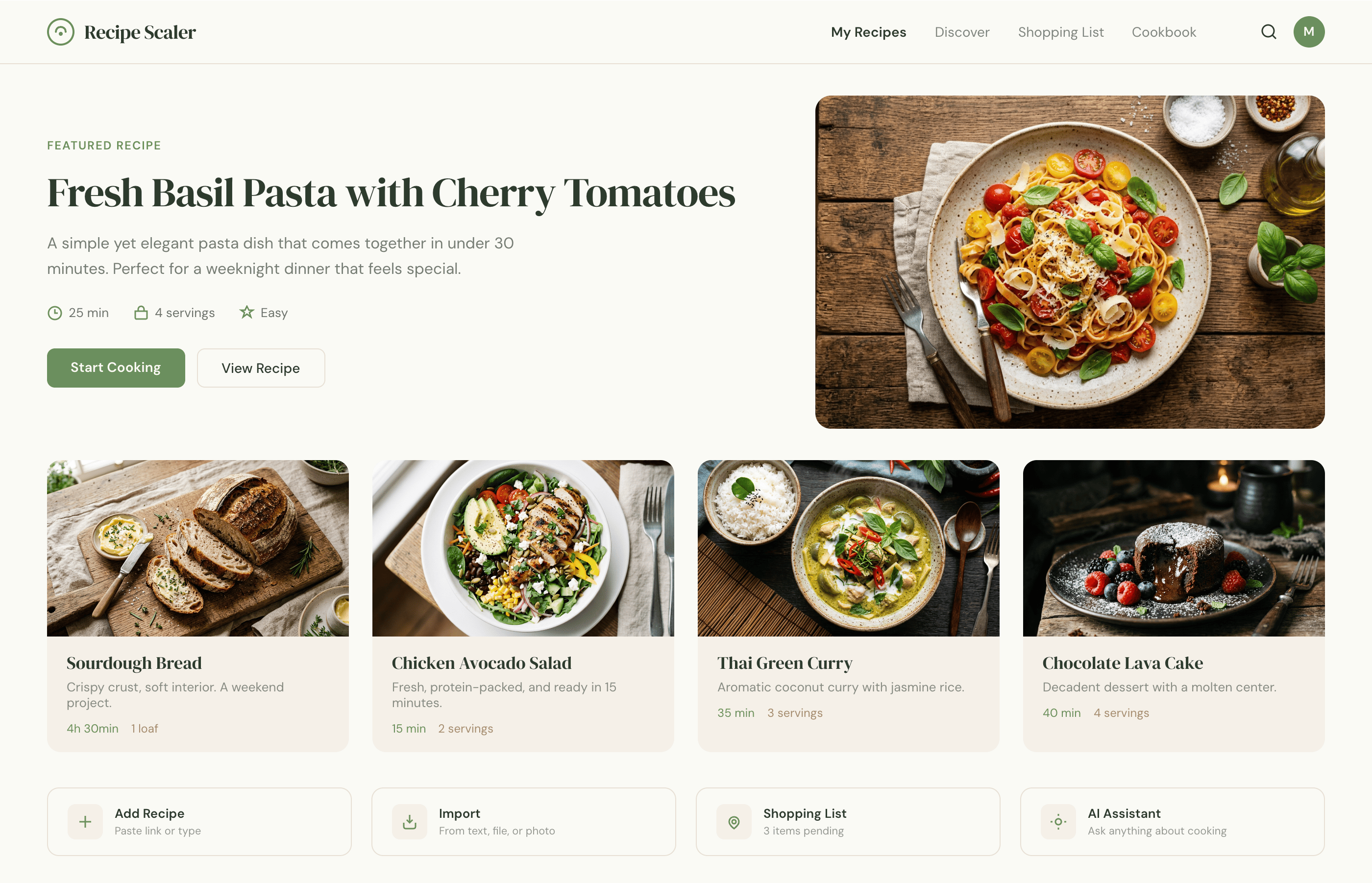
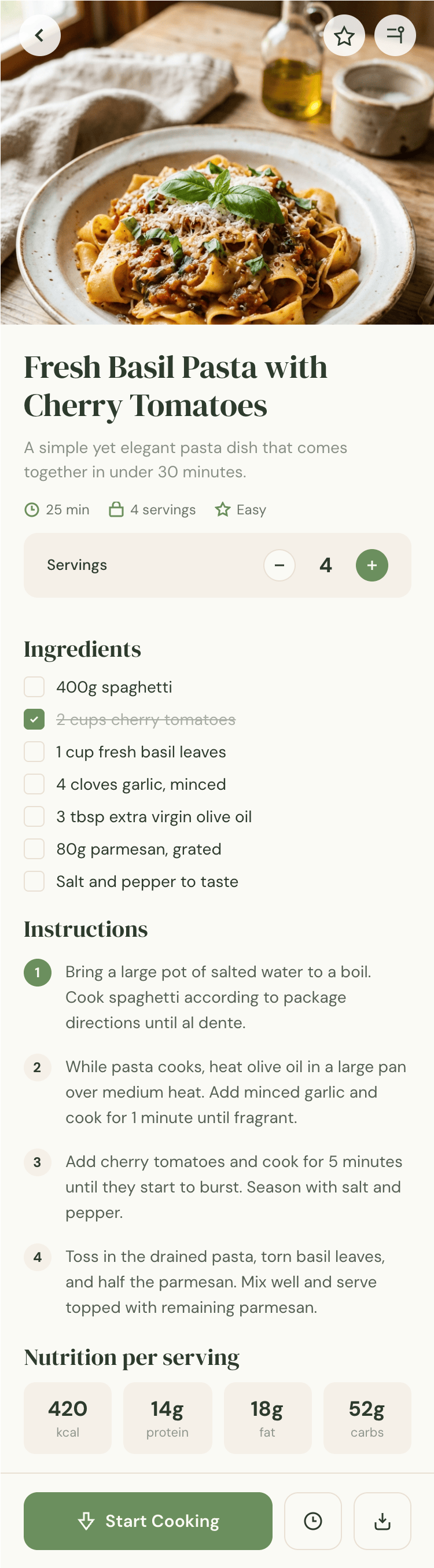
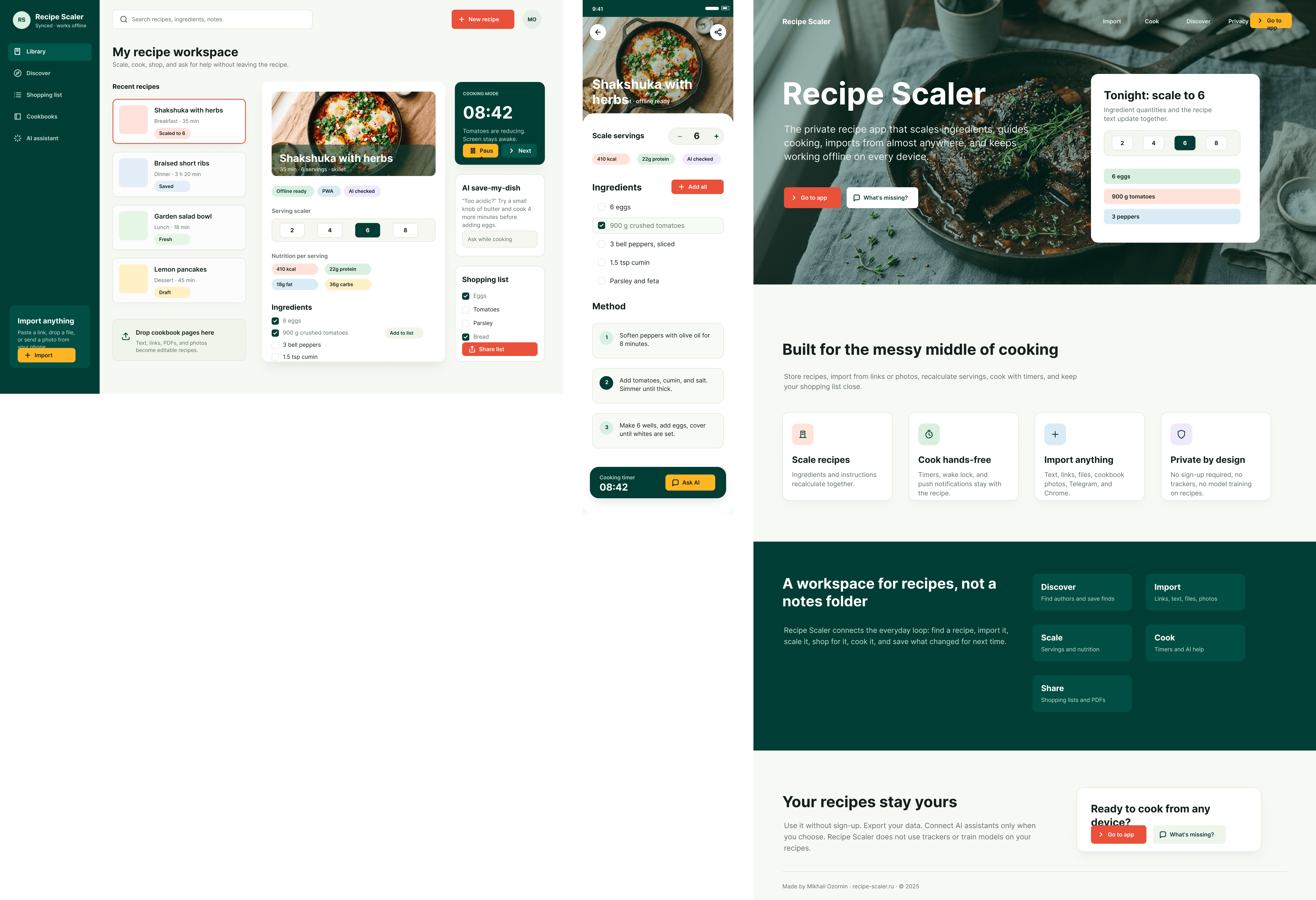
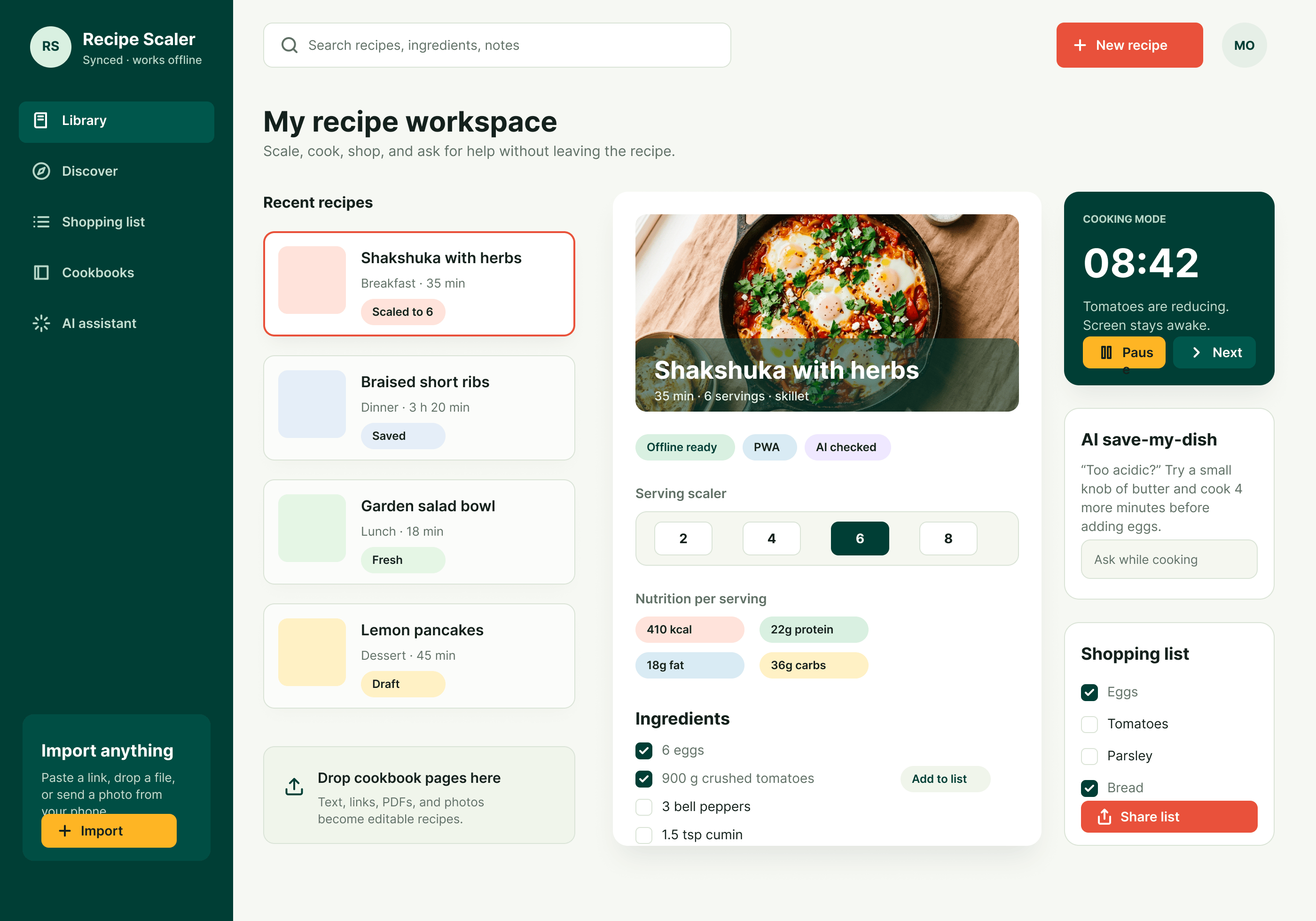
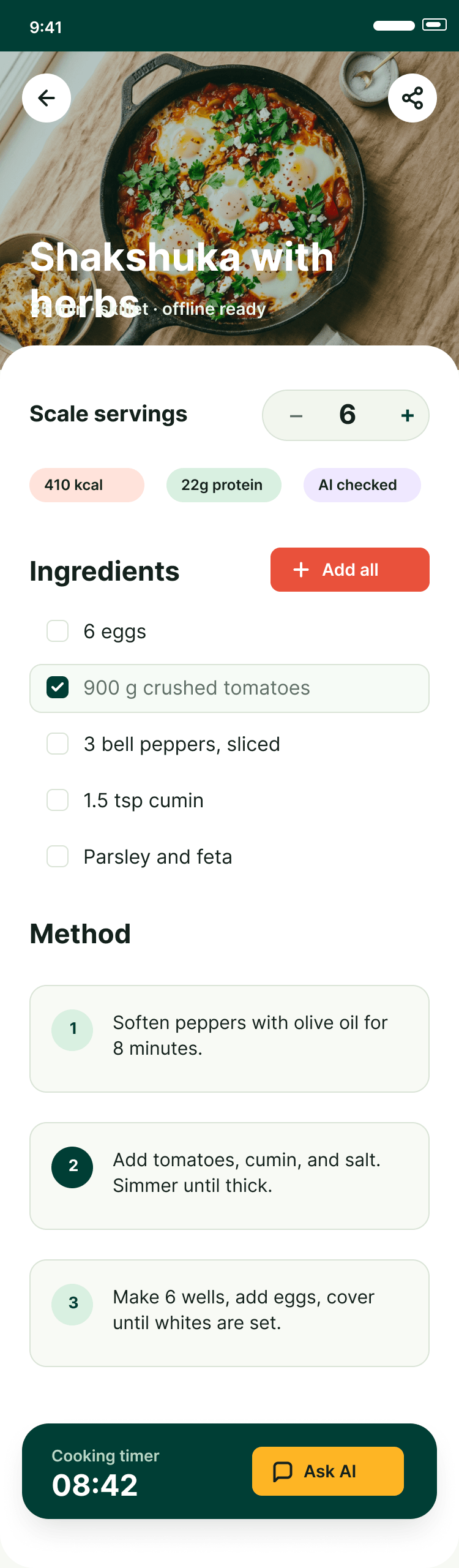
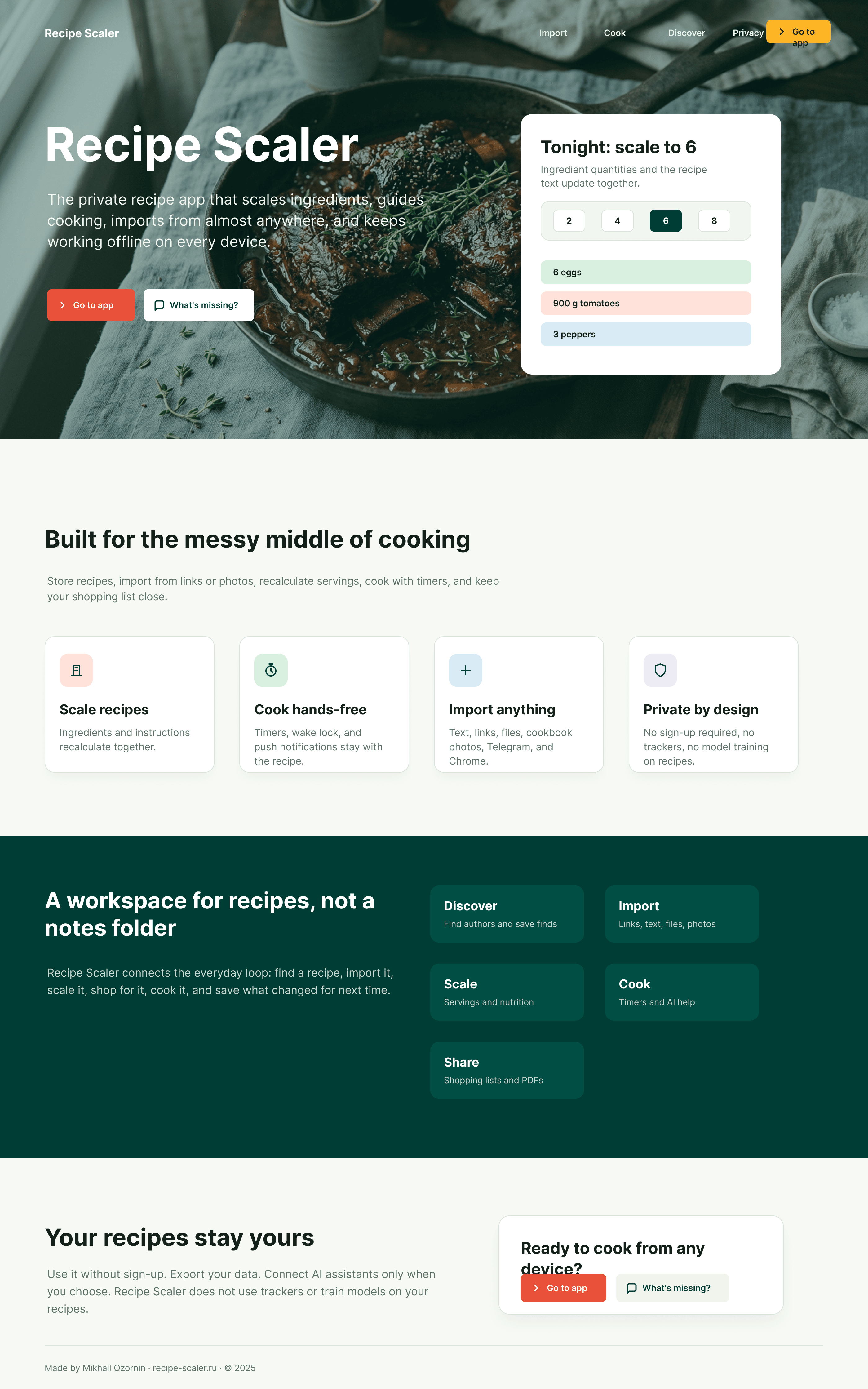
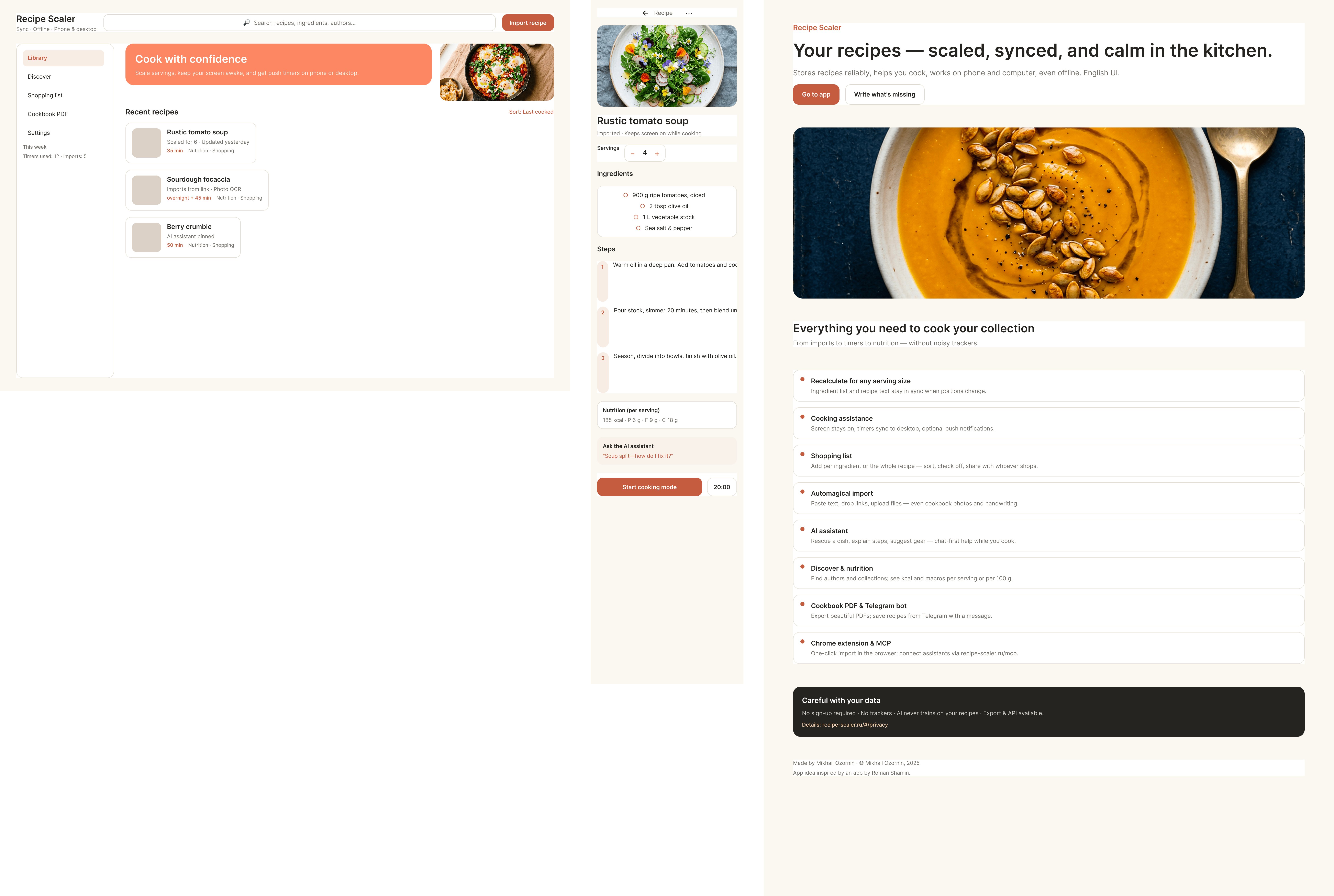
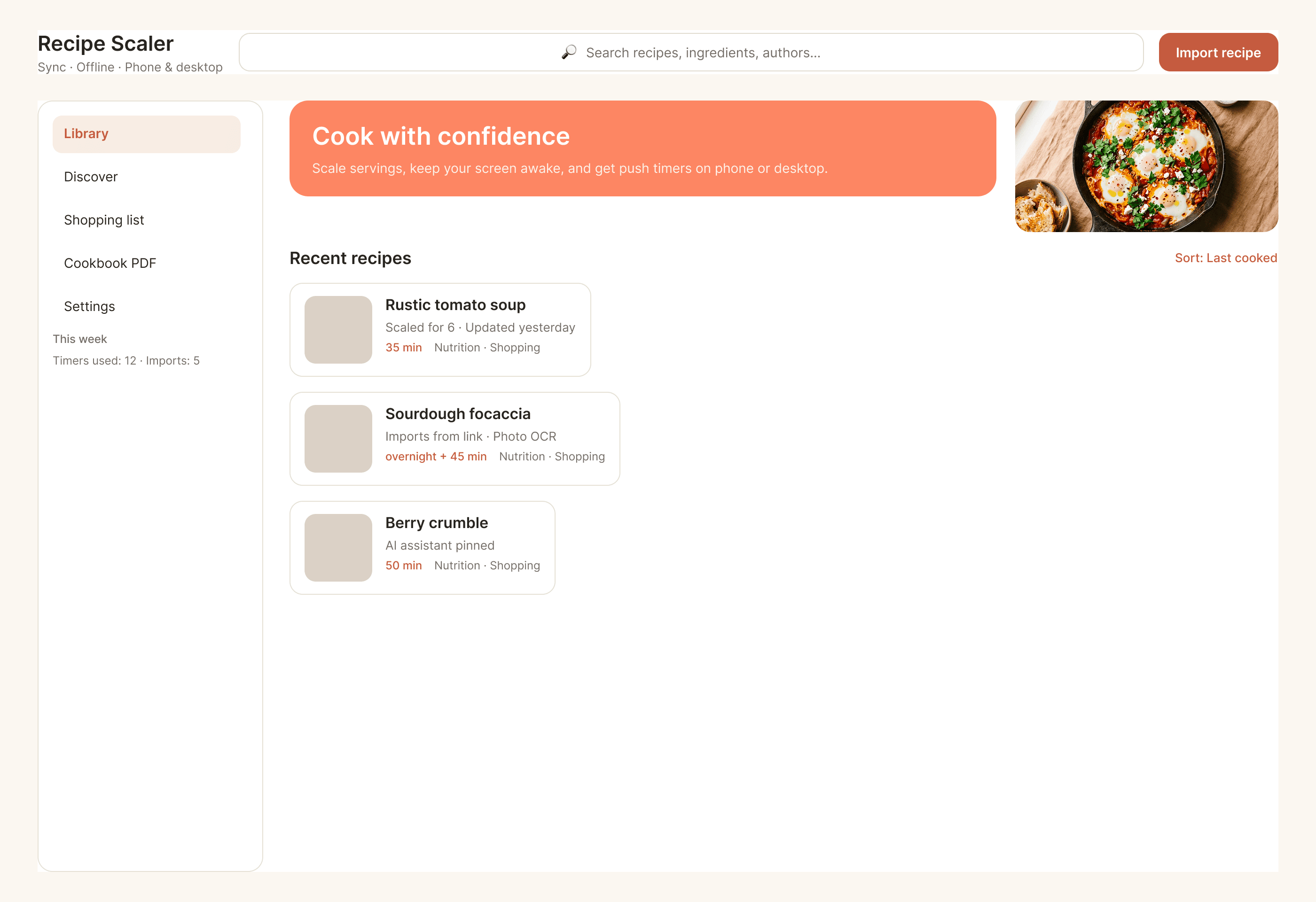
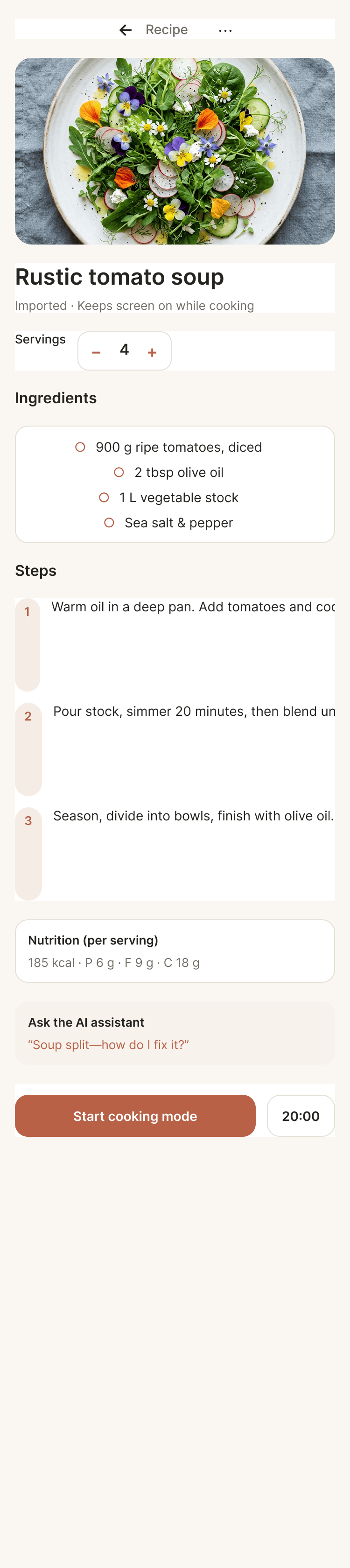
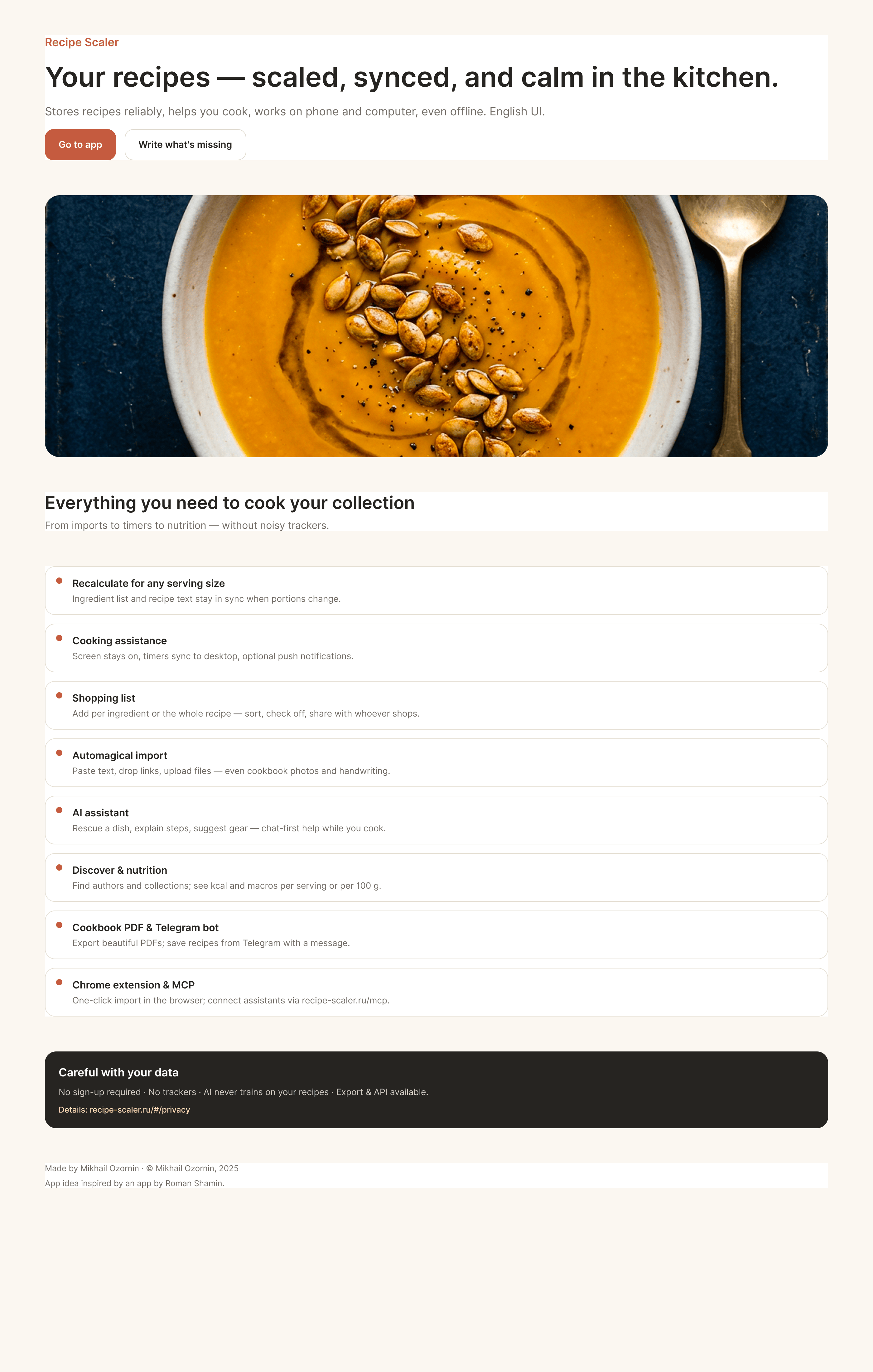
Лучший результат (всё — Опус 4.7 xhigh):


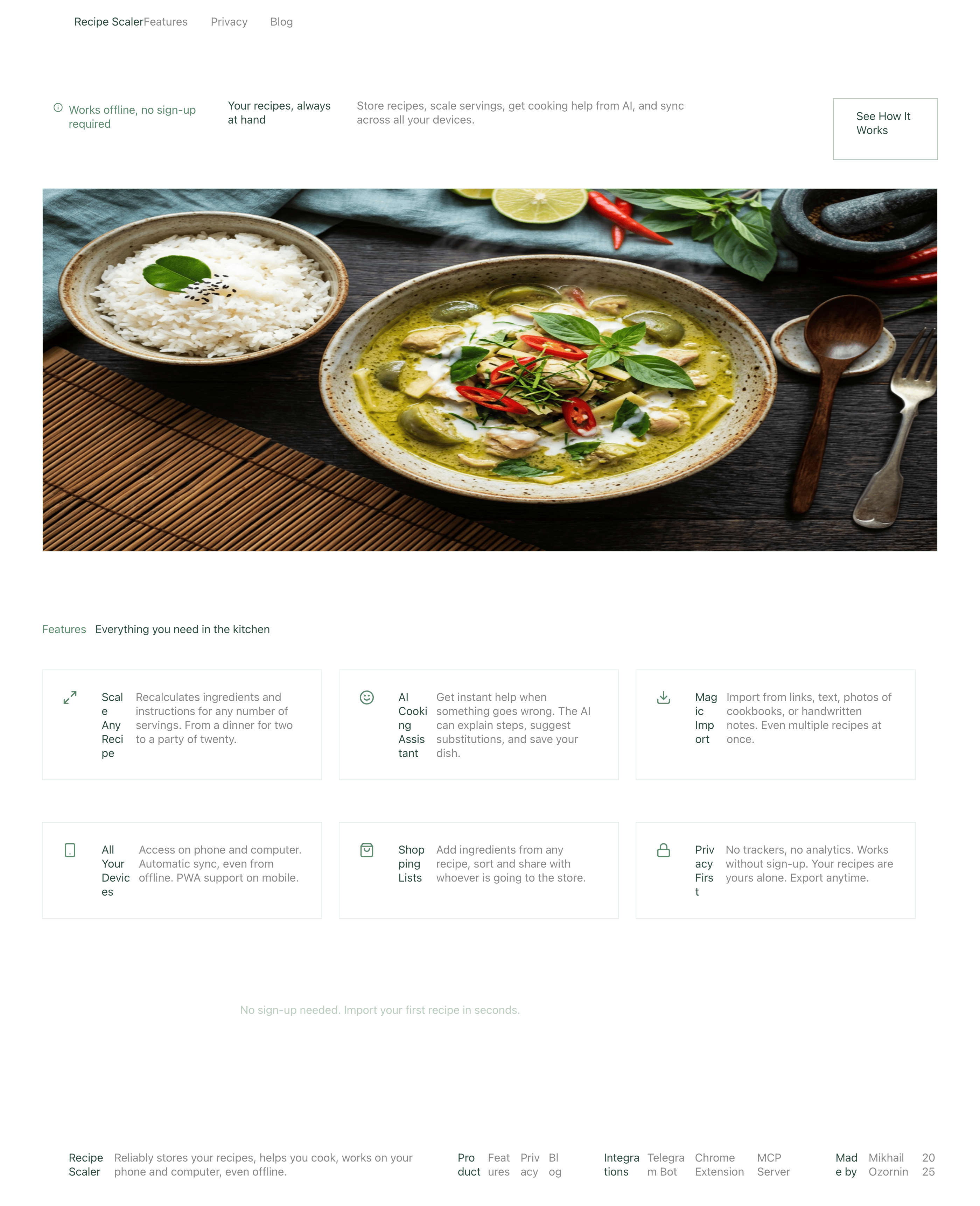
Худший результат (Хайку, Квен 3.5 и одна из итераций Дипсика)



Остальные находятся где-то между. Ниже будет табличка с результатами, а пока поделюсь впечатлениями.
2.1 Качество результата
Модели разбились на четыре категории:
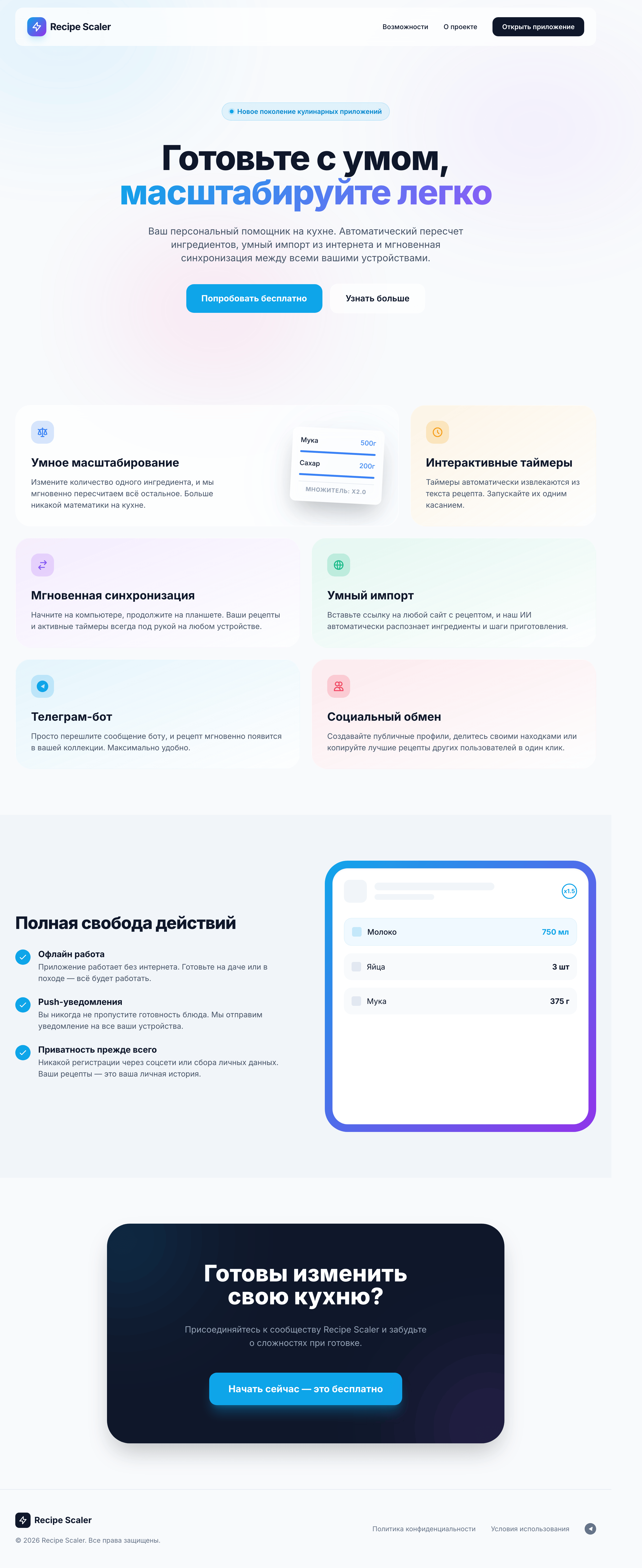
Фенси-дизайн, из которого можно выжать что-то интересное
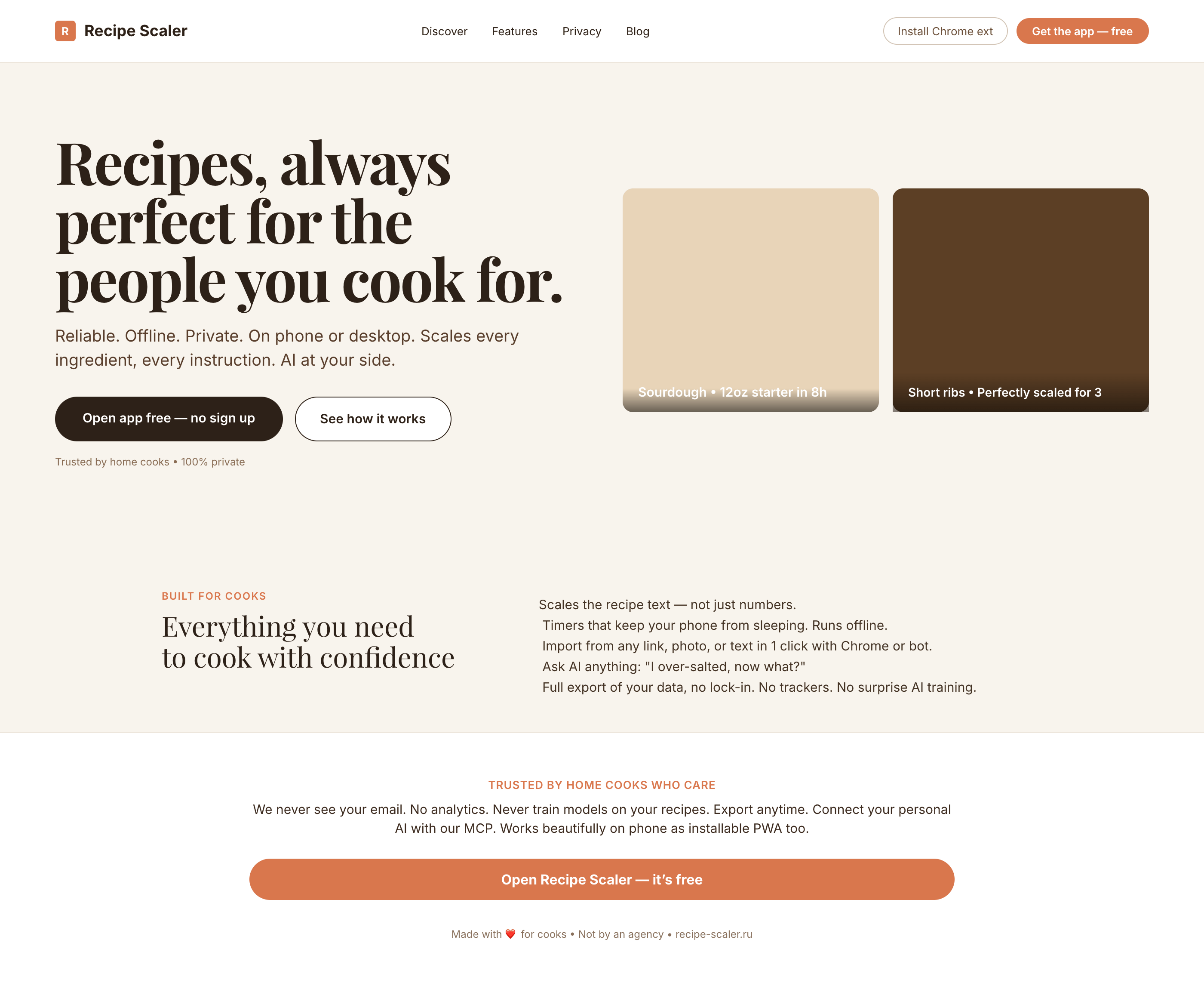
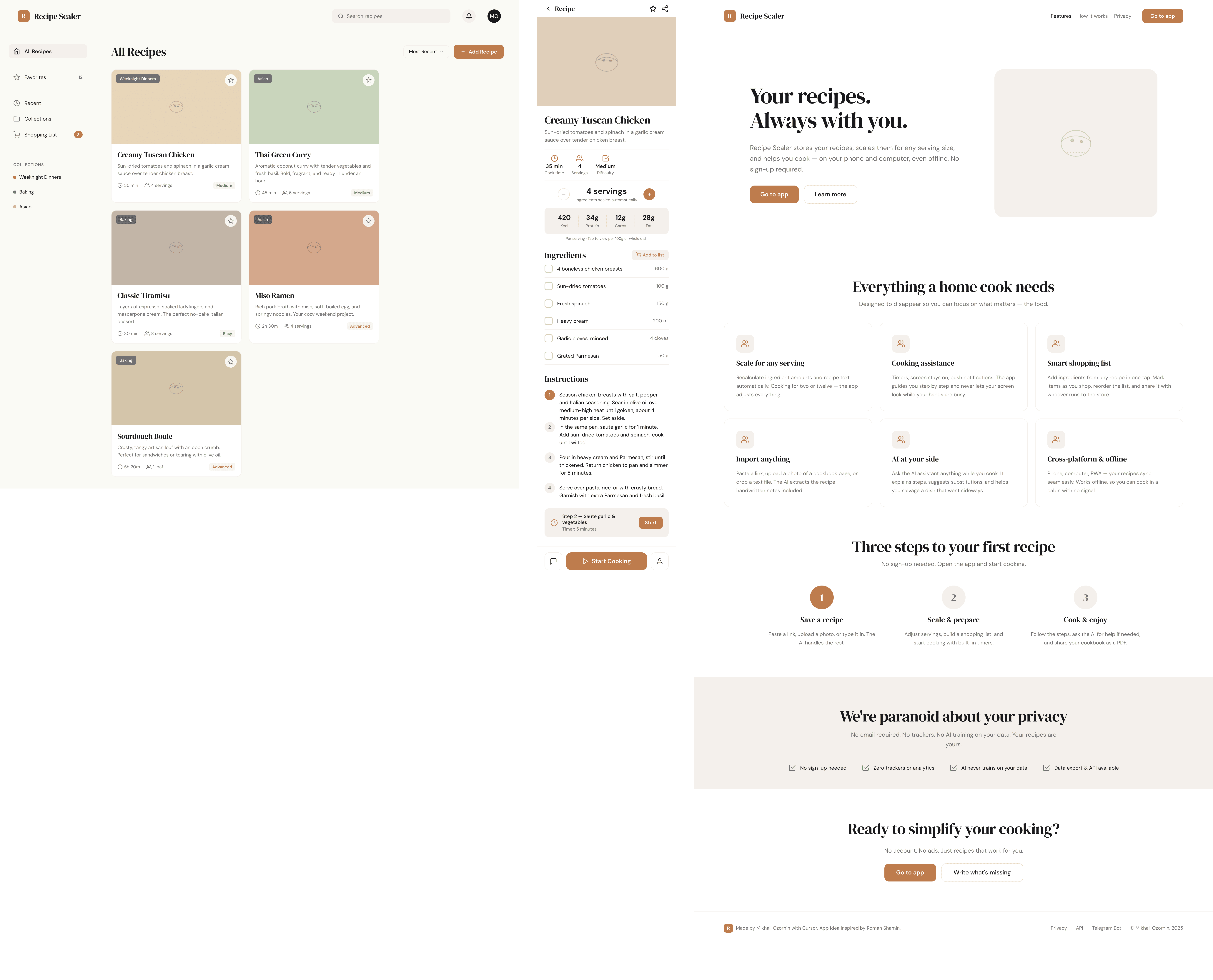
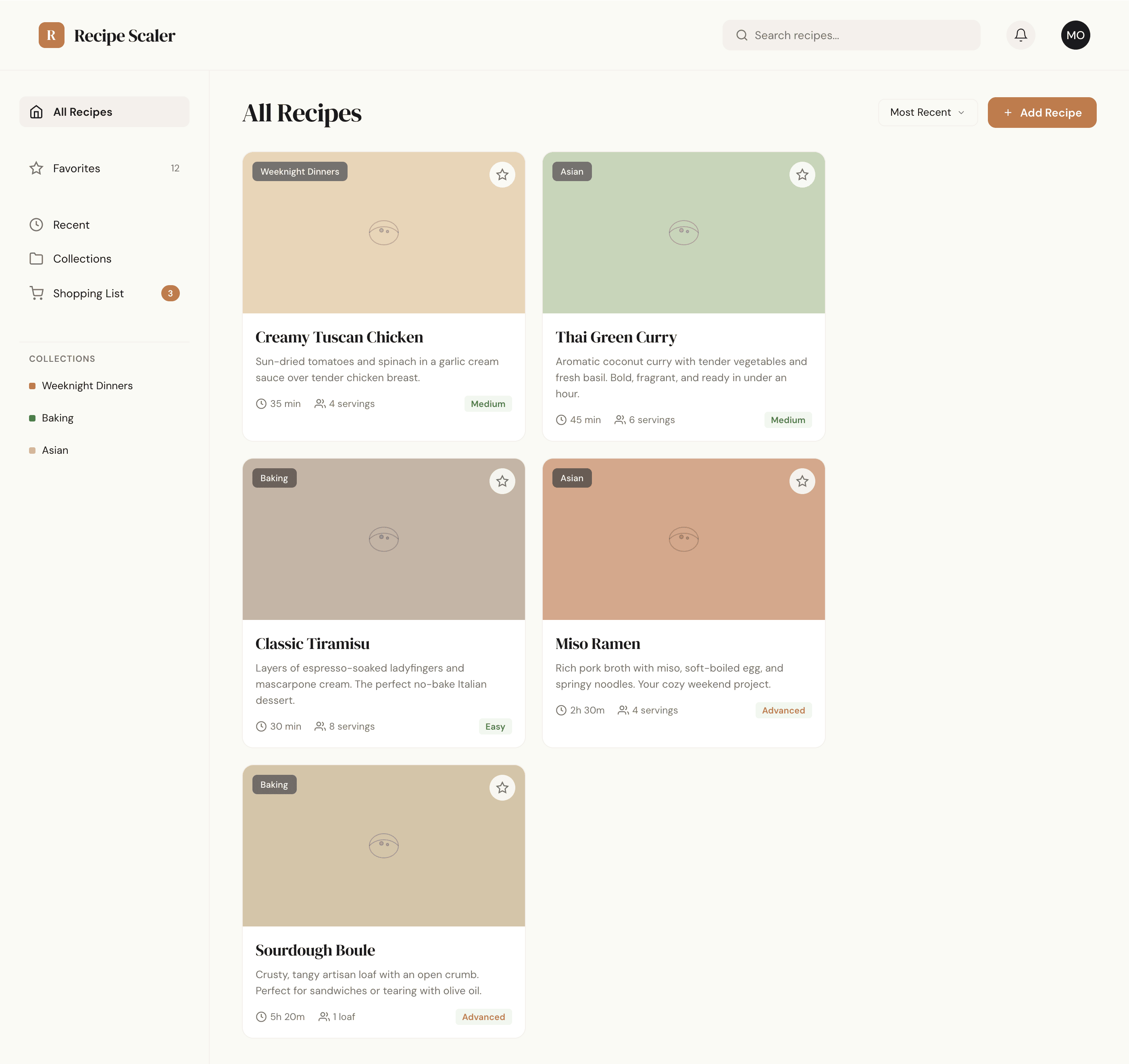
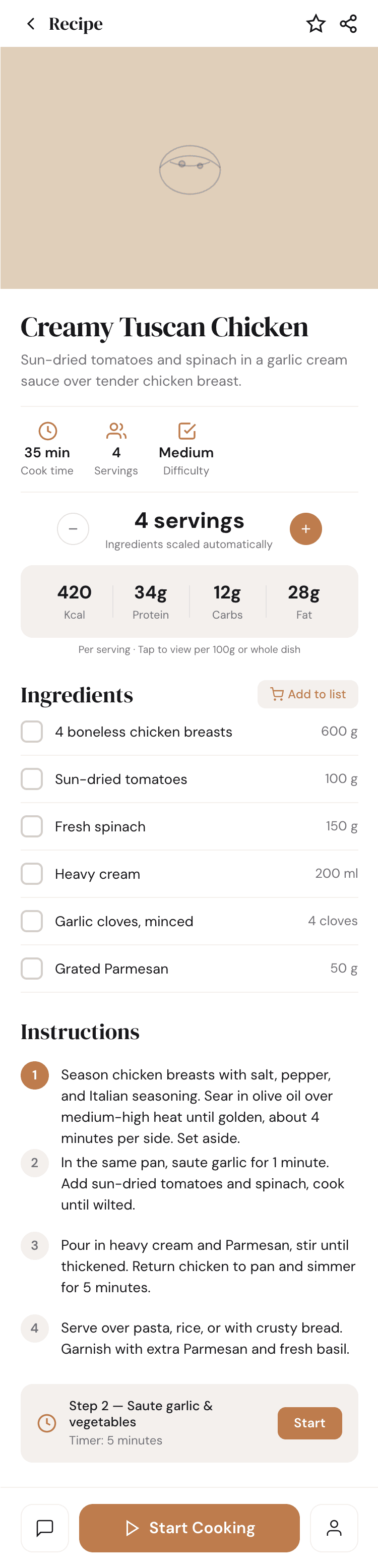
Такая модель один — Opus 4.7. Каждым этажом и микроформатом видно, что она выпендривается. Самые интересные и сложные промостраницы. Единственные промостраницы, которые не сверстаны как растянутая мобилка. Покажи такой дизайн издалека программисту, он подумает, что без дизайнера не обошлось.
Примеры мелочей оттуда:
Середнячки
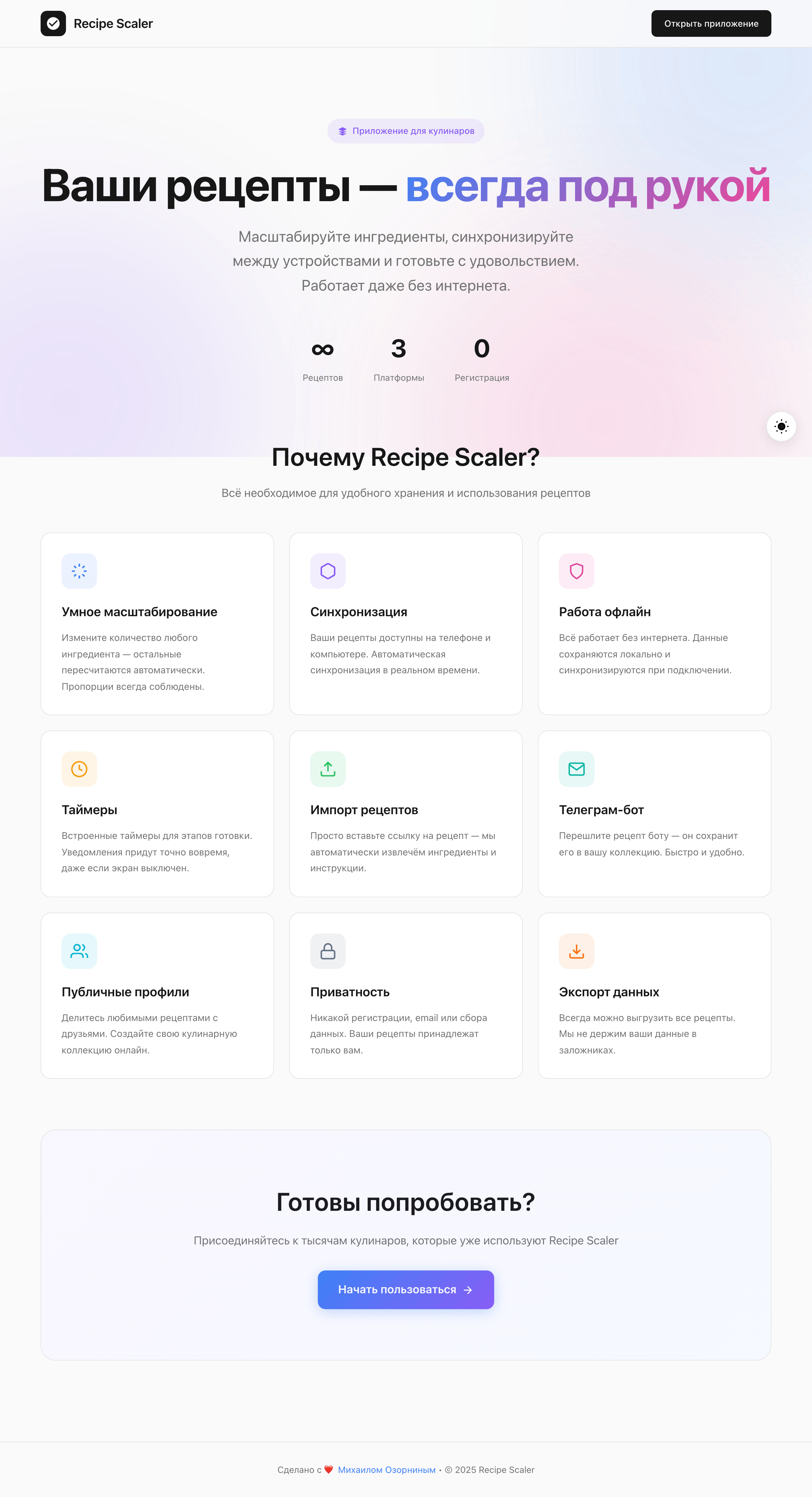
Десктопный и мобильный интерфейс простой, но понятный, промостраница скучная (ну прямо как у меня сейчас). Нейродизайн видно сразу, но он хотя бы аккуратный и чистый. При этом явных косяков нет, использовать такое когда под рукой нет дизайнера вполне можно. Opus 4.6, Sonnet 4.6, GPT 5.4, Cursor Auto, Qwen 3.6 и с натяжкой GLM 5.1 (если справится с тулами).
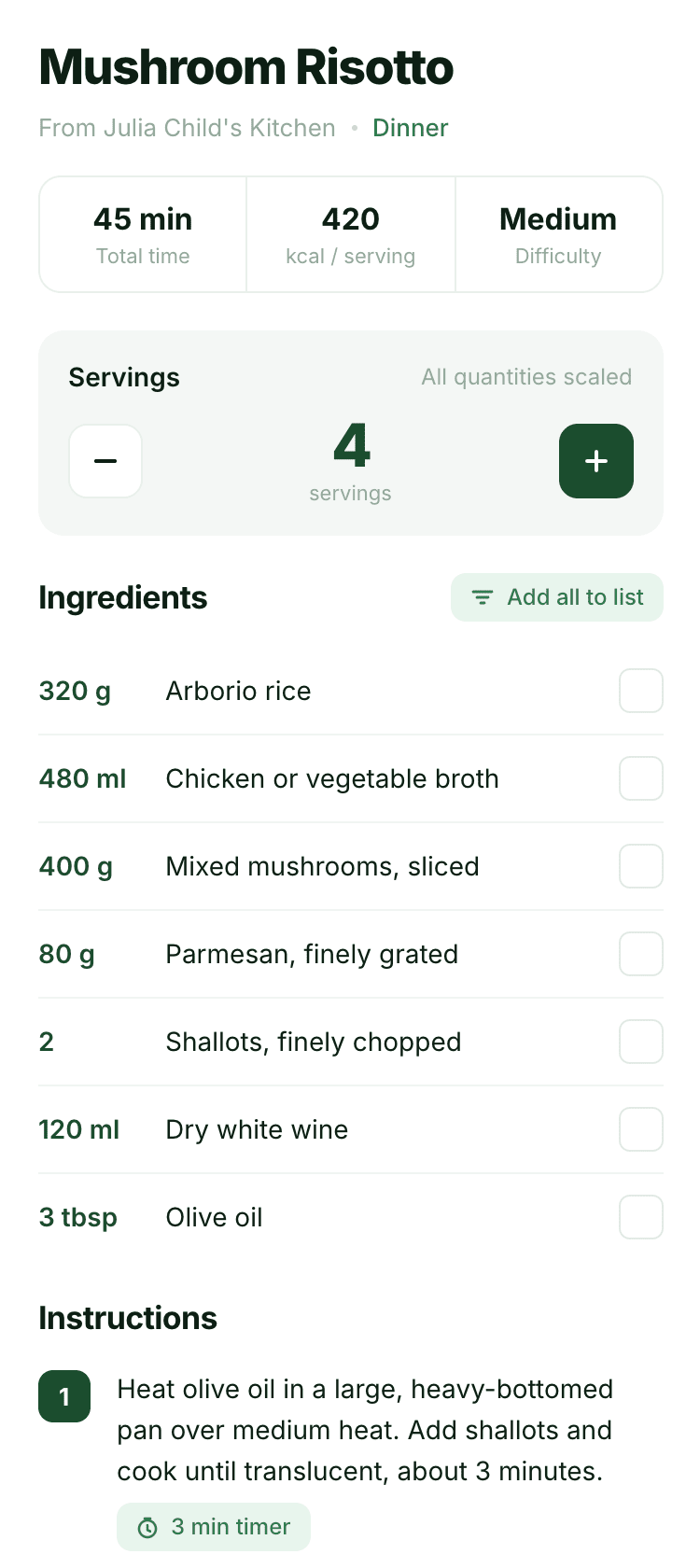
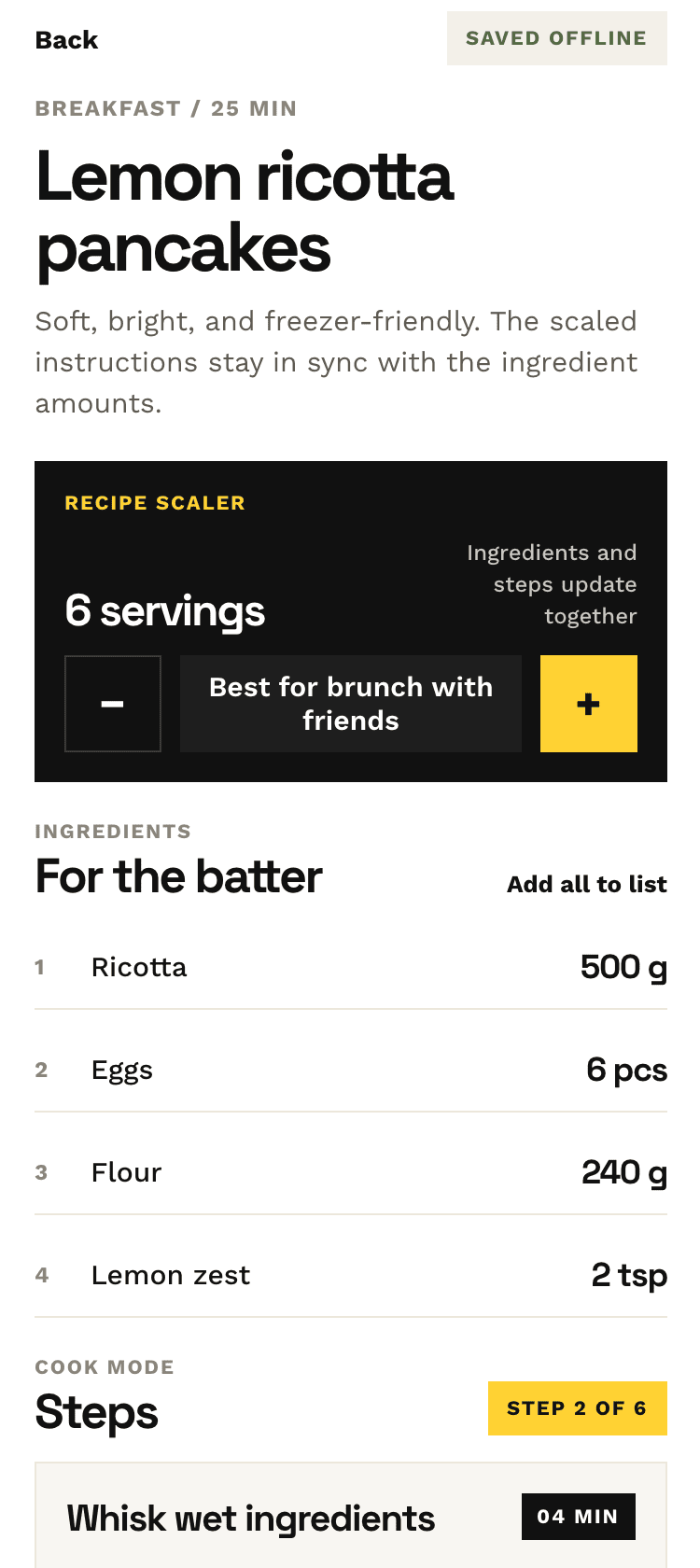
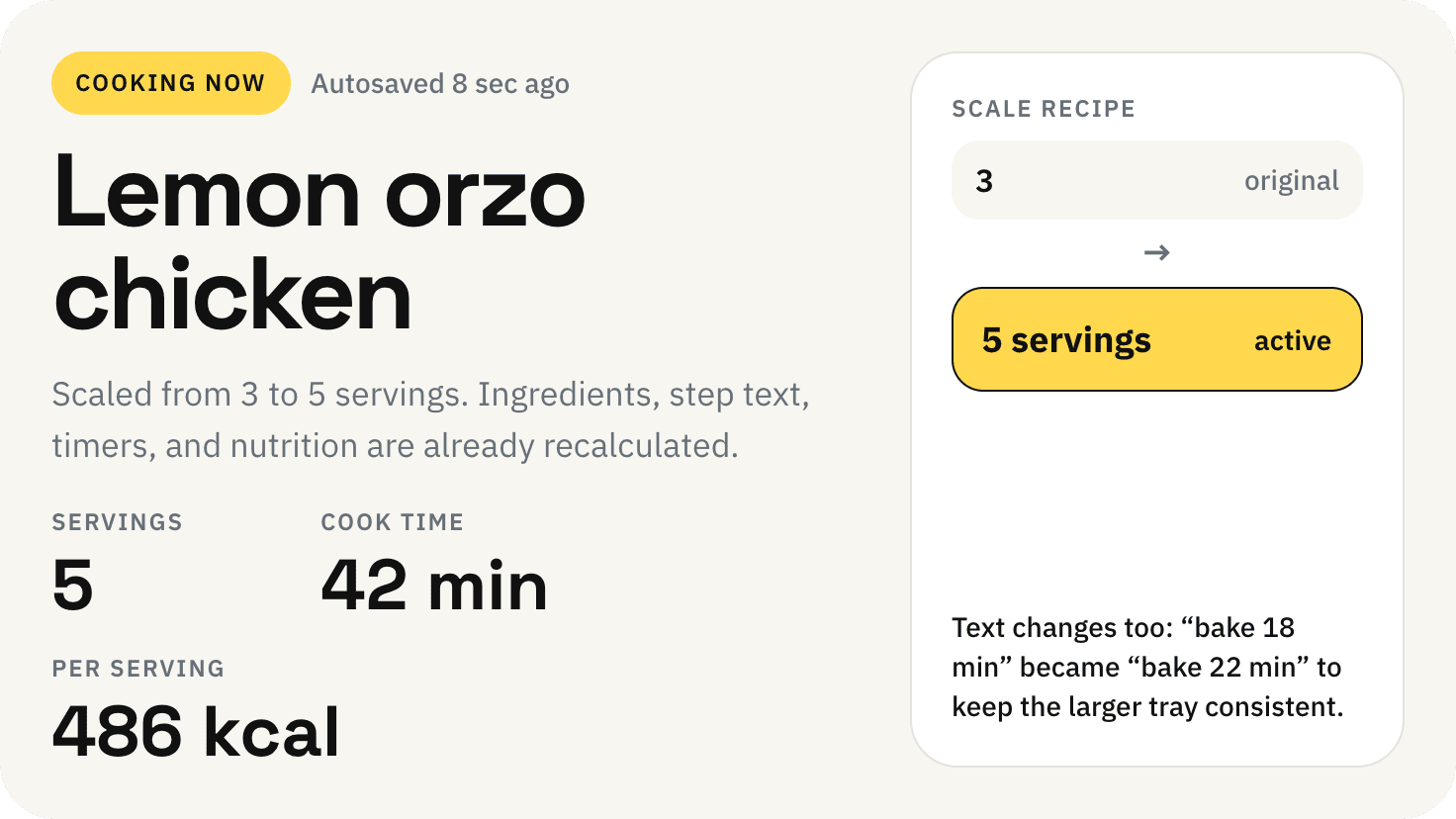
Совсем уже типичный нейрослоп-дизайн
Нейрослоп в худших его проявлениях, заметней всего его на промостранице. Буквально не за что зацепиться глазами. Например, Minimax 2.7, Kimi 2.6 (чуть лучше, но все же здесь), Composer 2 Cursor (доученный Kimi 2.5) тоже недалеко ушел. Даже в целом неплохой Gemini 3.1 Про тут. Grok 4.3 тоже говорит «всем чмоки в этом чате».
Те модели, что не смогли справиться с тулами
Это были Qwen 3.5 39, и в 50% случаев GLM 5.1 с DeepSeek V4 Pro — иногда они справлялись, иногда нет. В эту категорию попадает Haiku 4.5 Антропика, а он, на минуточку, в 1.5 раза дороже GLM 5.1 и в 4 раза дороже, чем Minimax 2.7, которые показали себя лучше его.


Многим не давалась концепция десктоп-приложения, некоторые делали эдиториал-сайт. Это было бы нормально в целом для сайта рецептов, но не для личного приложения менеджера рецептов. Явно я этого не формулировал, но как будто из контекста можно было догадаться.
Мне кажется, что вот таким было пользоваться ежедневно было бы не очень удобно. Усиливается это с добавлением скилла (будет ниже), там у модели начинается просто горе от ума.
У самых слабых моделей всплывают типичный нейрослоп: рамки на рамках, градиенты или цветные плашки, мусор везде, эмодзи, плохая иерархия и ритм. Ощущение, что экраны собрали из того, что не пригодилось моделям получше.


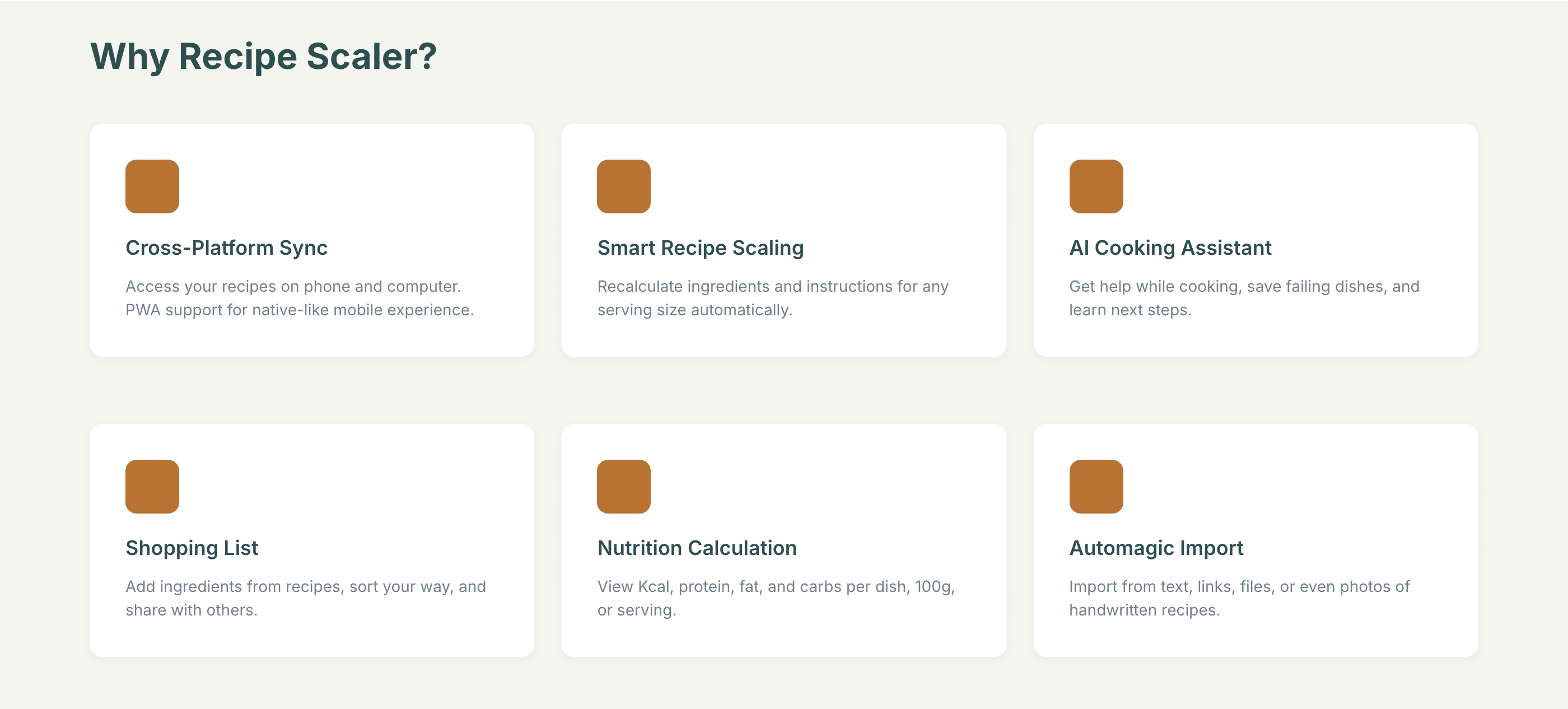
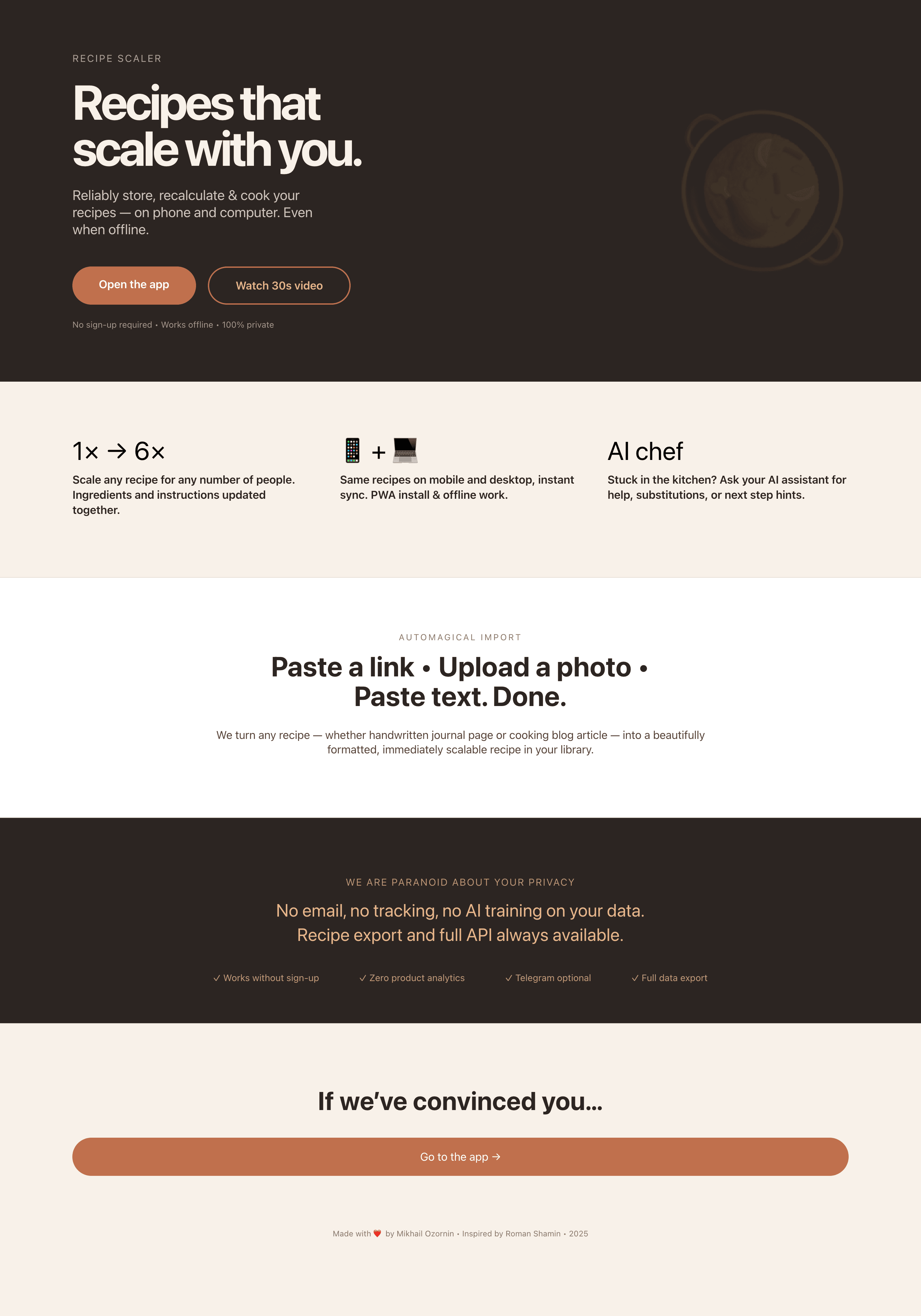
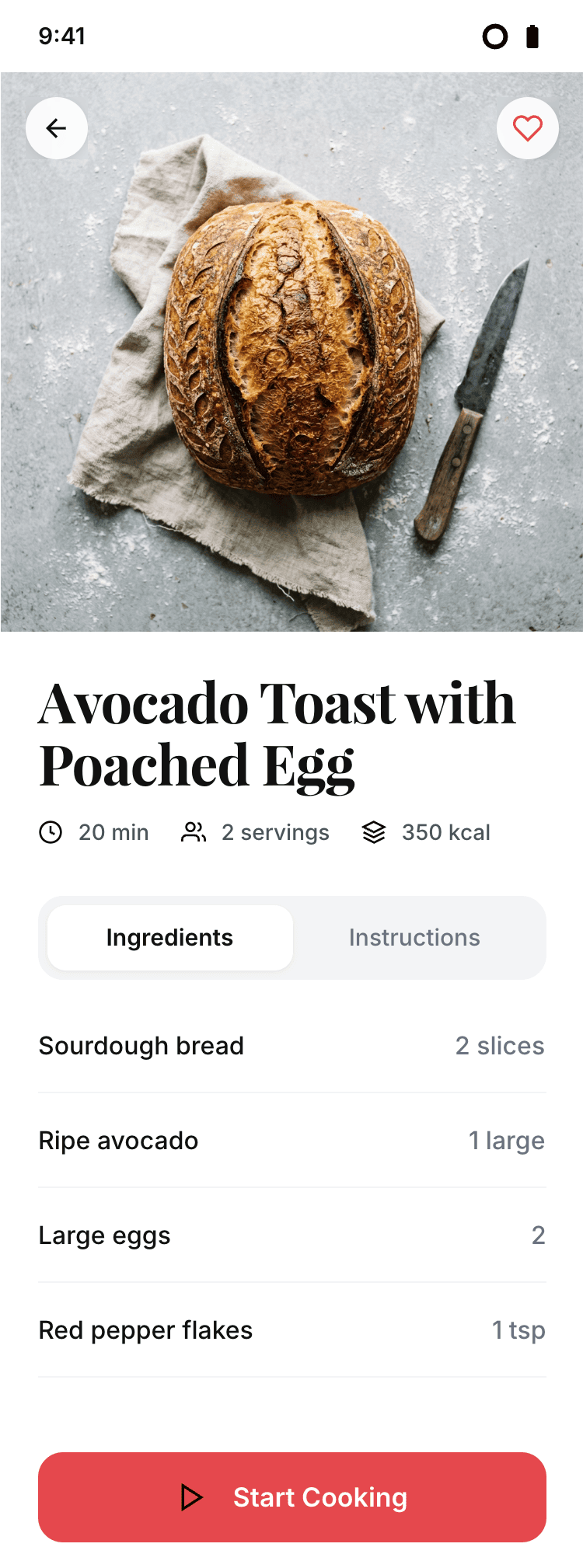
Заметно, что у всех с мобильной версии лучше, чем с промо. Там в целом более простая верстка, меньше элементов, сильные ограничения (узкая колонка). Как следствие — верстка лучше, надежнее и крепче. Как только появляется широкая страница, многие не могут сделать лучше, чем просто растянуть мобильную верстку по ширина 375 → 1400.
Кими 2.6 как-то справился с мобилкой, но не смог ничего на подобном уровне сделать с промостранице. Десктоп тоже плохой.
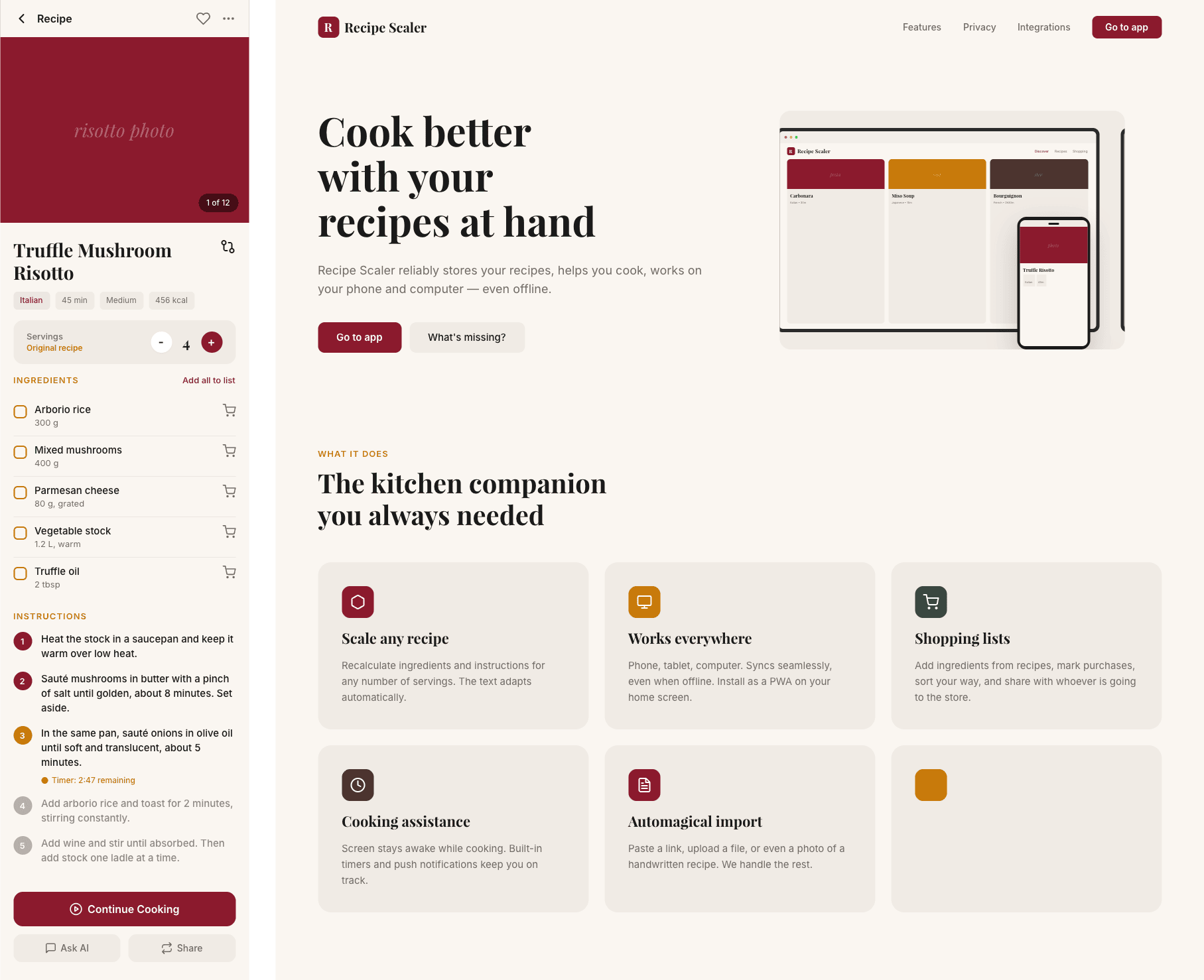
2.2 Качество верстки
В Paper все модели верстают примерно одинаково — нормально, в Фигме же ГПТ верстал совсем плохо. Все в одном фрейме, по сути — абсолютами. Кожаного дизайнера за такое бы на ревью не похвалили. Он же (ГПТ) в Пейпере верстал нормально, видимо тулы Пейпера попроще, получше и более понятны.
Фигма — все сверстано в одном фрейме, размеры рандомные, по сути если бы в вебе все верстали абсолютами, это ГПТ 5.5.
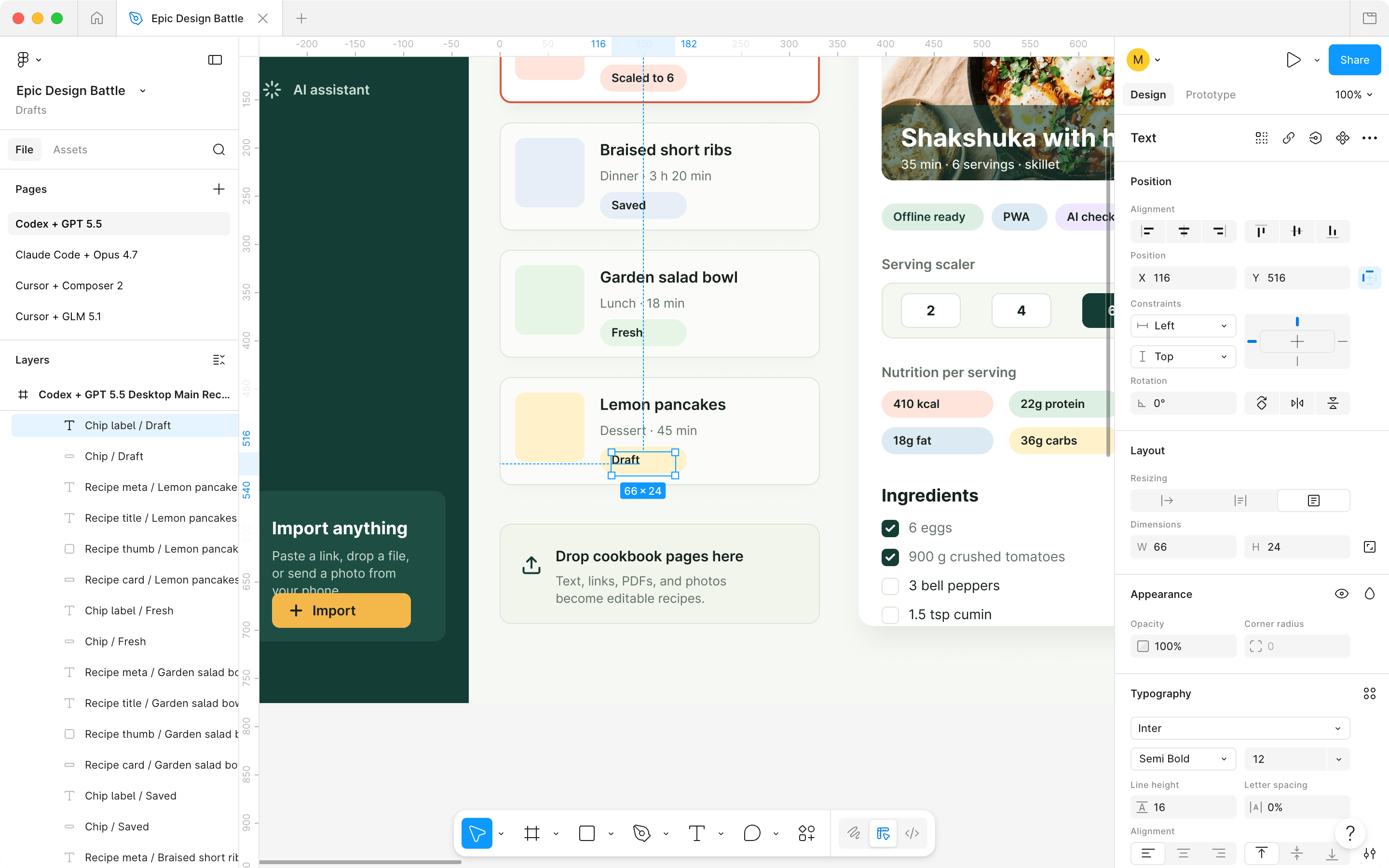
Тот же ГПТ 5.5 в Пейпере — в целом все чисто, дом-структура нормальная, некоторые слои даже хорошо названы. Кратная разница.
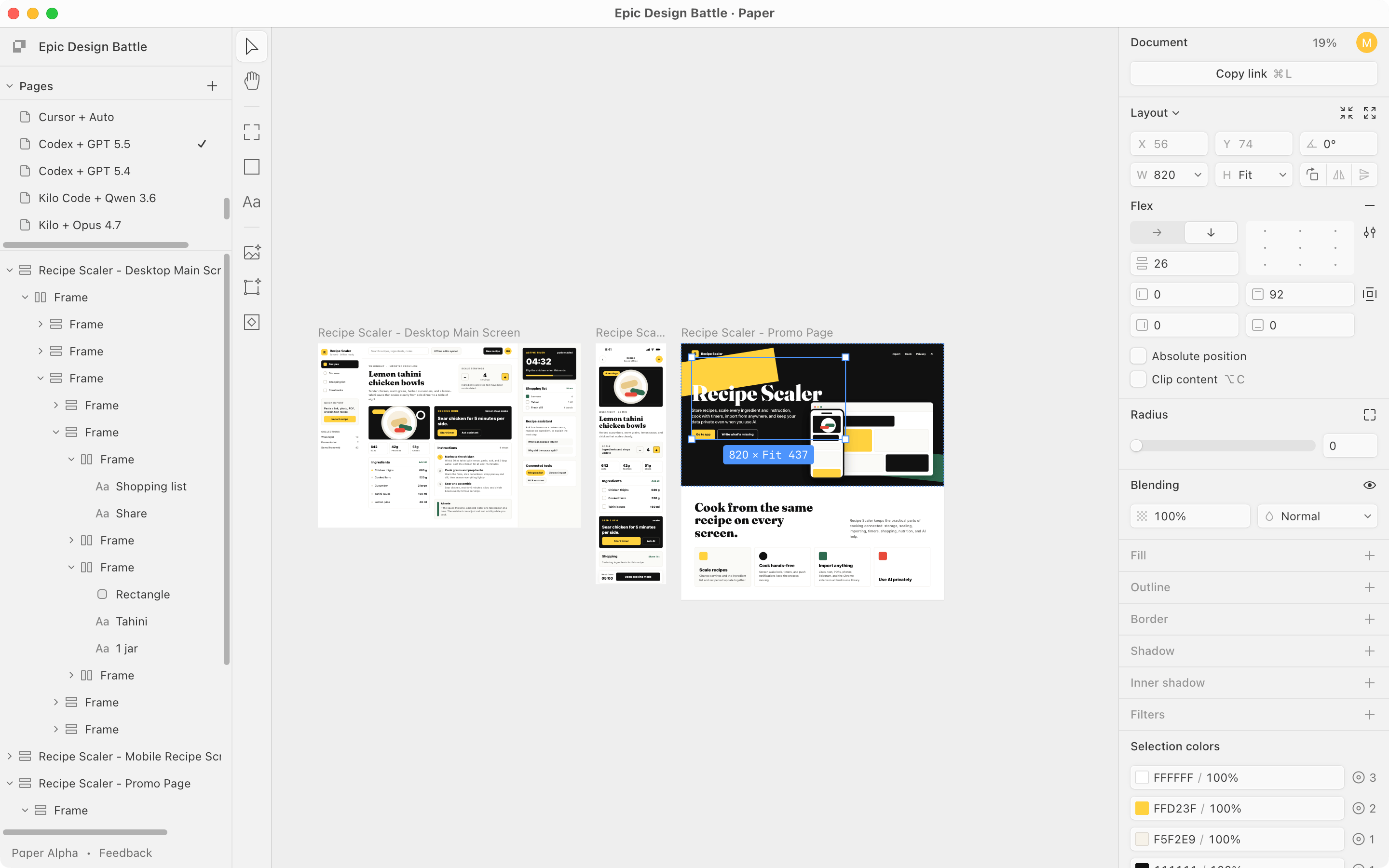
2.3 Размышления и удивления по ходу эксперимента
- Поразительно, насколько модели ГПТ плохи в дизайне. Как модели для разработки они в целом нормальные, и отторжения не вызывают, а для дизайна ужас. Причем на том одном эксперименте, что я делал, 5.5 оказалась даже хуже, чем 5.4, хотя дороже примерно вдвое. Единственная СОТА-модель (state of the art), которая проигрывает многим более слабым, в том числе китайцам.
- Гемини 3.1 показал себя очень плохо. И в Антигравити (их агент, форк винсёрфа) и в Курсоре. И если про Антигравити я могу понять, он очень плохо сделан, то Курсор — нормальный агент. Недопустимо плохо для модели такого уровня.
- Агент в целом не принципиально влияет на результат, он не может сделать из не-опус-модели опус-результат. Т. е. результат в этой простой задаче в первую очередь определяется моделью, и лишь потом агентом. При этом, разница все еще есть. ГПТ 5.4 в Курсоре показал себя даже лучше, чем в родном Кодексе.
- Курсор + Опус 4.7 оказался вдвое дороже чем та же модель в Кило, Курсор очень активно собирал обратную связь и постоянно себя скриншотил. Результат в целом мне тоже нравится больше. Особенно должна помочь такая
- У моделей есть стиль. ГПТ во всех агентах узнается, Опус 4.7 тоже узнается во всех. По результату я бы предположил, что Опус 4.7 и Опус 4.6 явно тяготеют к одной модели, стиль похожий. У Соннета стиль другой, это не просто обрезанный Опус, это разные модели. А вот Опус от снижение рисонинга (xhigh → med) делает хуже, но остается тем же Опусом по стилю.
- Модели, которые по ценам за токены совпадают, не совпадают в финальной цене. Формально ГПТ 5.5 и Опус 4.7 стоит одинаково (ГПТ — 30 долларов, Опус 4.7 — 25). Но это цена за миллион токенов, а тратят они по-разному. Именно 5.5 у меня нет, но был в Курсоре ГПТ 5.4 — у него 4.5 М токенов, а у Опуса (тоже в Курсоре) — 15 М.
- Разница между самым дорогим и дешевым вариантами — 410 раз. Понятно, что и разница между ними в качестве — тоже дофига, может даже больше, чем в 410 раз.
- Визуально работы Опуса неплохие, но разваливаются в мелочах. Начиная с того, что решение не той задачи, не того продукта, заканчивая версткой. Издалека красиво, но как начнешь смотреть — клинит от кринжа. Наверное примерно такой же уровень кринжа у технарей, когда приносишь им вайбкод-код. Почти все варианты проще выкинуть, чем пытаться доработать.
- Еще один неприятный результат — аккаунт на Опенроутере забанили от моделей ОпенАПИ, Клода и Гемини. Пока не могу сказать почему, пытаюсь разобраться.
3 Все результаты по одному
Квоты для Клод кода указаны до недавнего двухкратного увеличения пятичасовой квоты. Т. е. нужно делить предположительно на два. Я не везде засек время или квоту, не везде квоту в целом можно было понять. Там, где написано токены — это и входящие, и исходящие токены, с учетом кеша, поэтому так много.
Полная таблица результатов ниже.
3.1 Paper MCP
| Агент | Модель + параметры | Время | Токены | Стоимость | Комментарий |
| Antigravity | Gemini 3.1 Pro, high | 15 мин | — | — | Очень плохо использует тулы, чудовищная интеграция в инструмент |
| Antigravity | Gemini 3.5 Flash | — | — | — | Заметно лучше, чем Gemini 3.1 Pro (но рост от его уровня несложный). Единственный, кто решил сделать дарк-мод. |
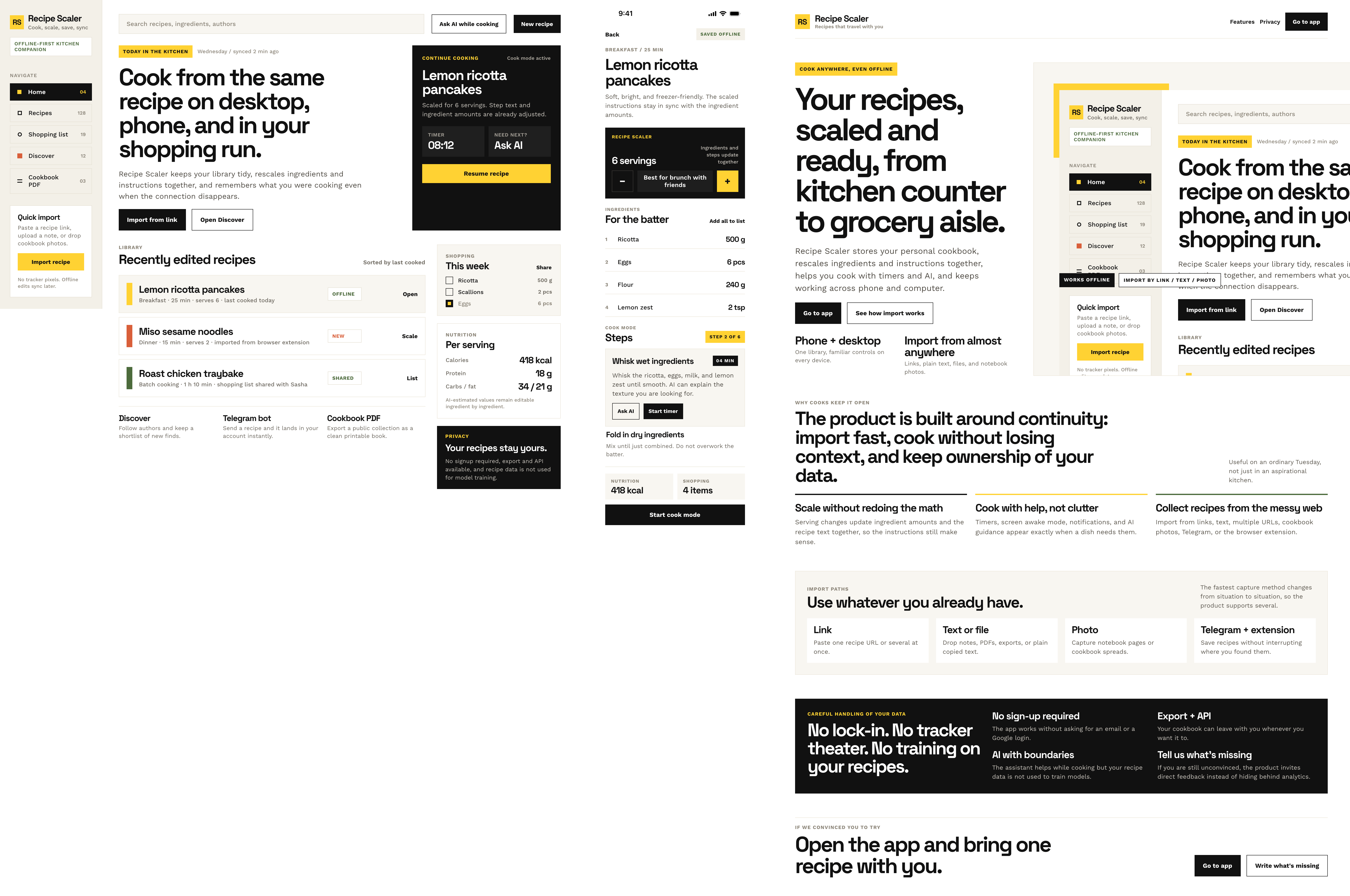
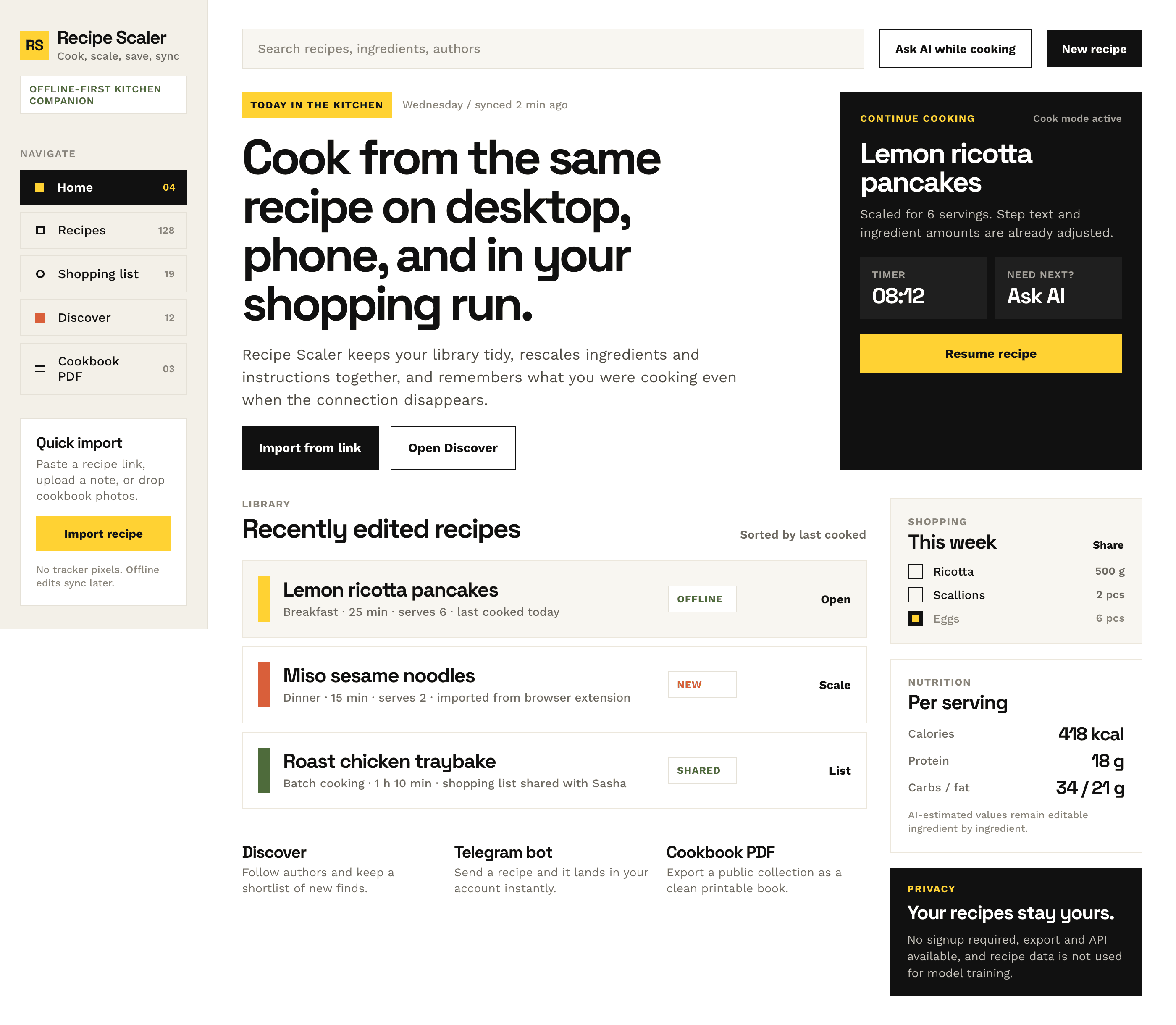
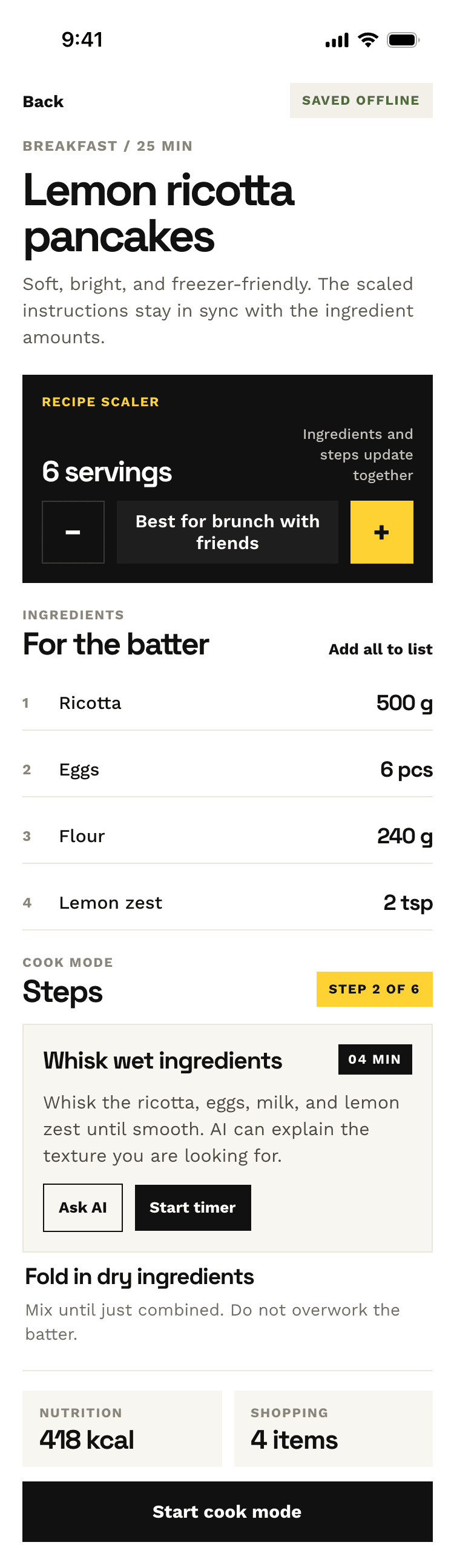
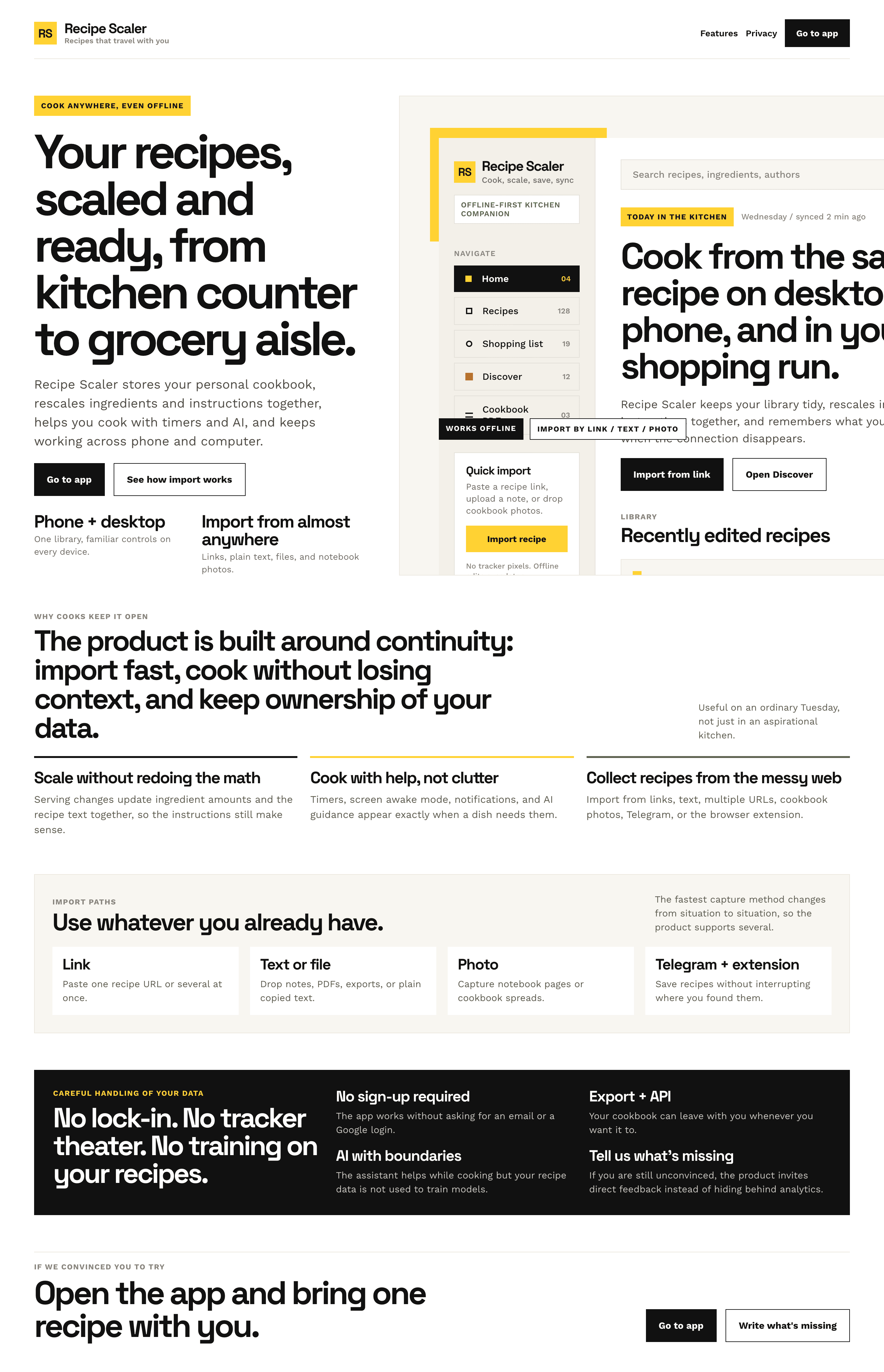
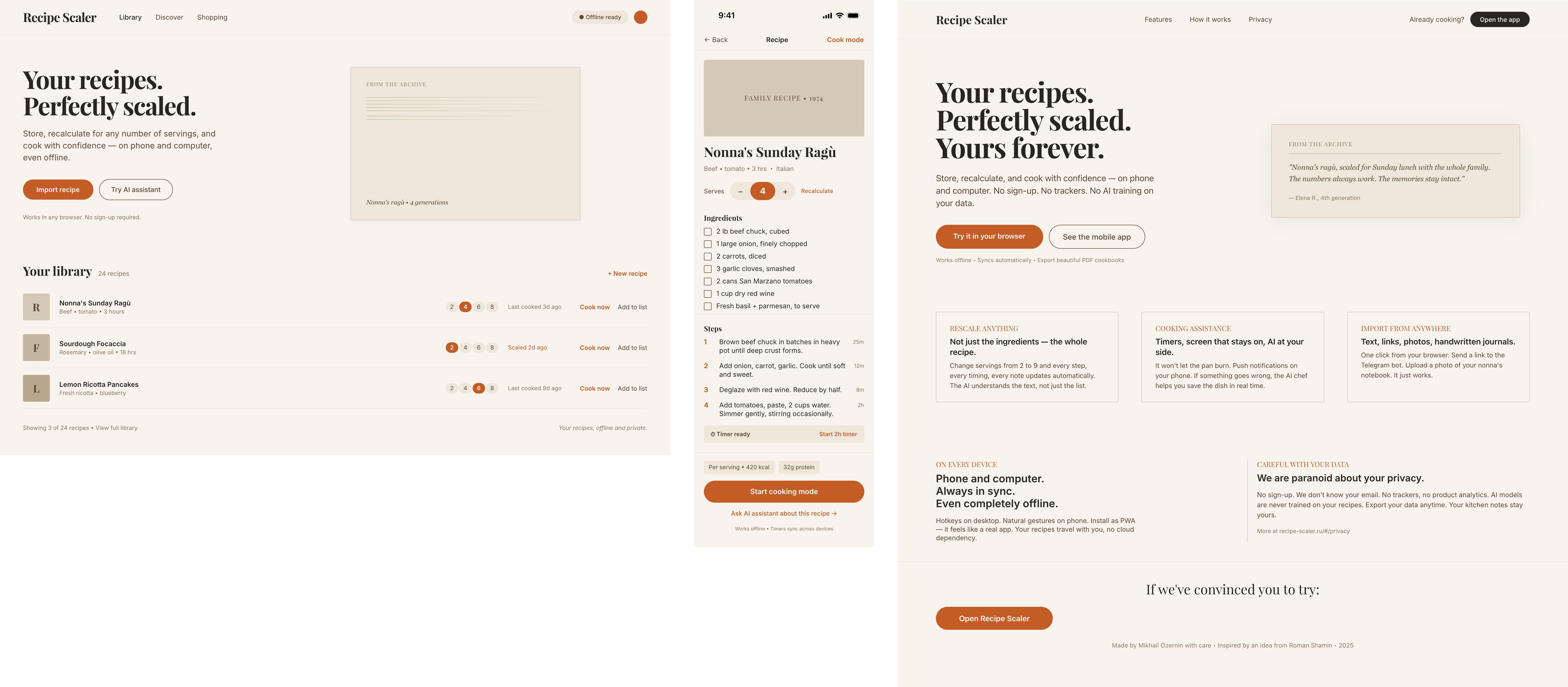
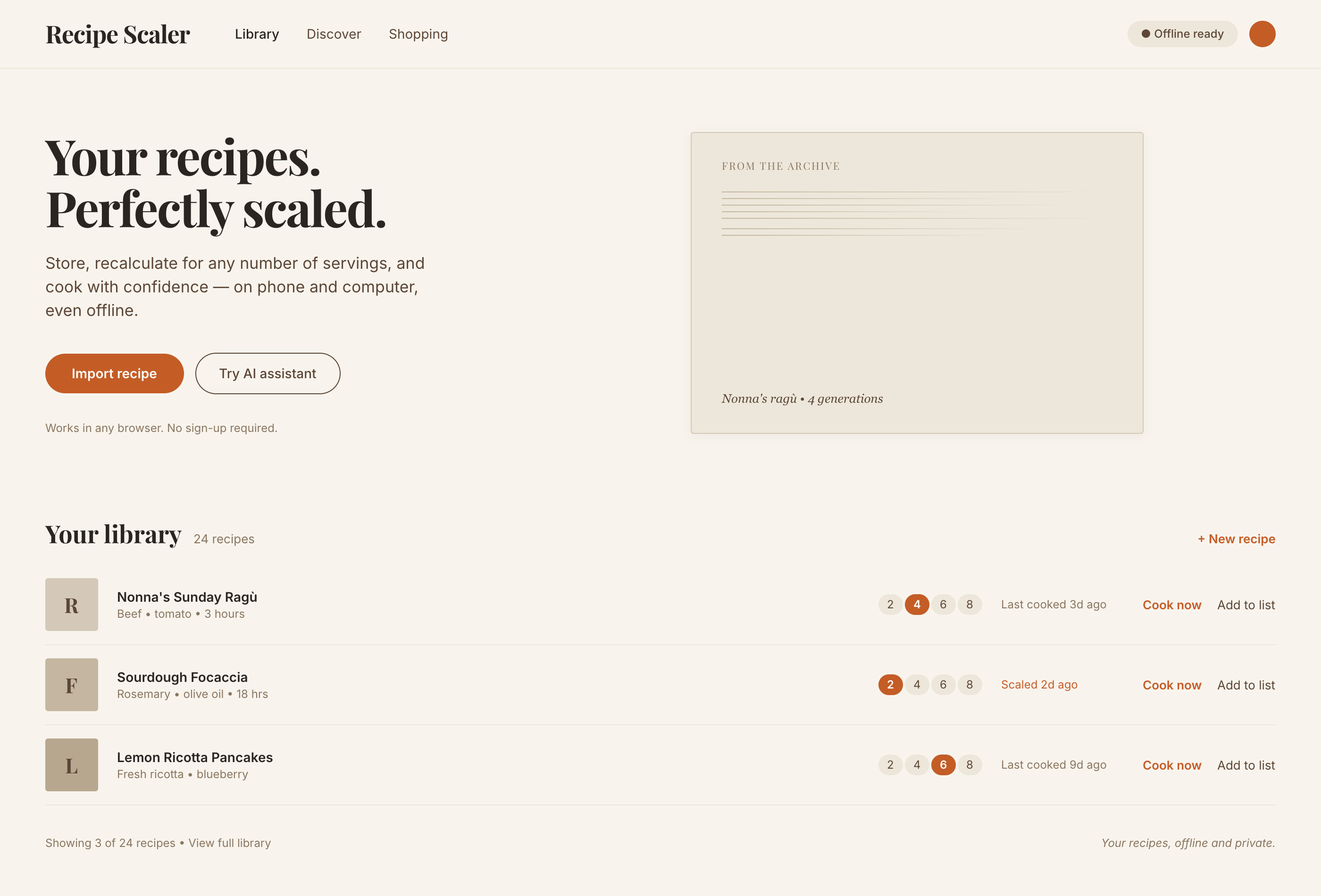
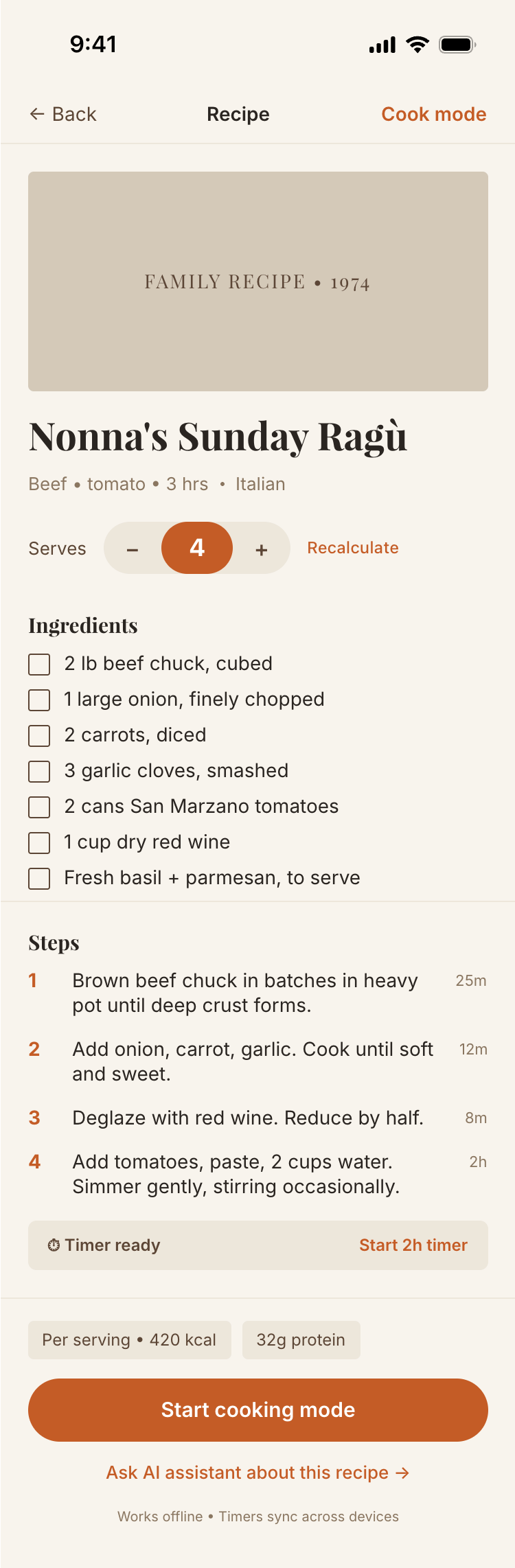
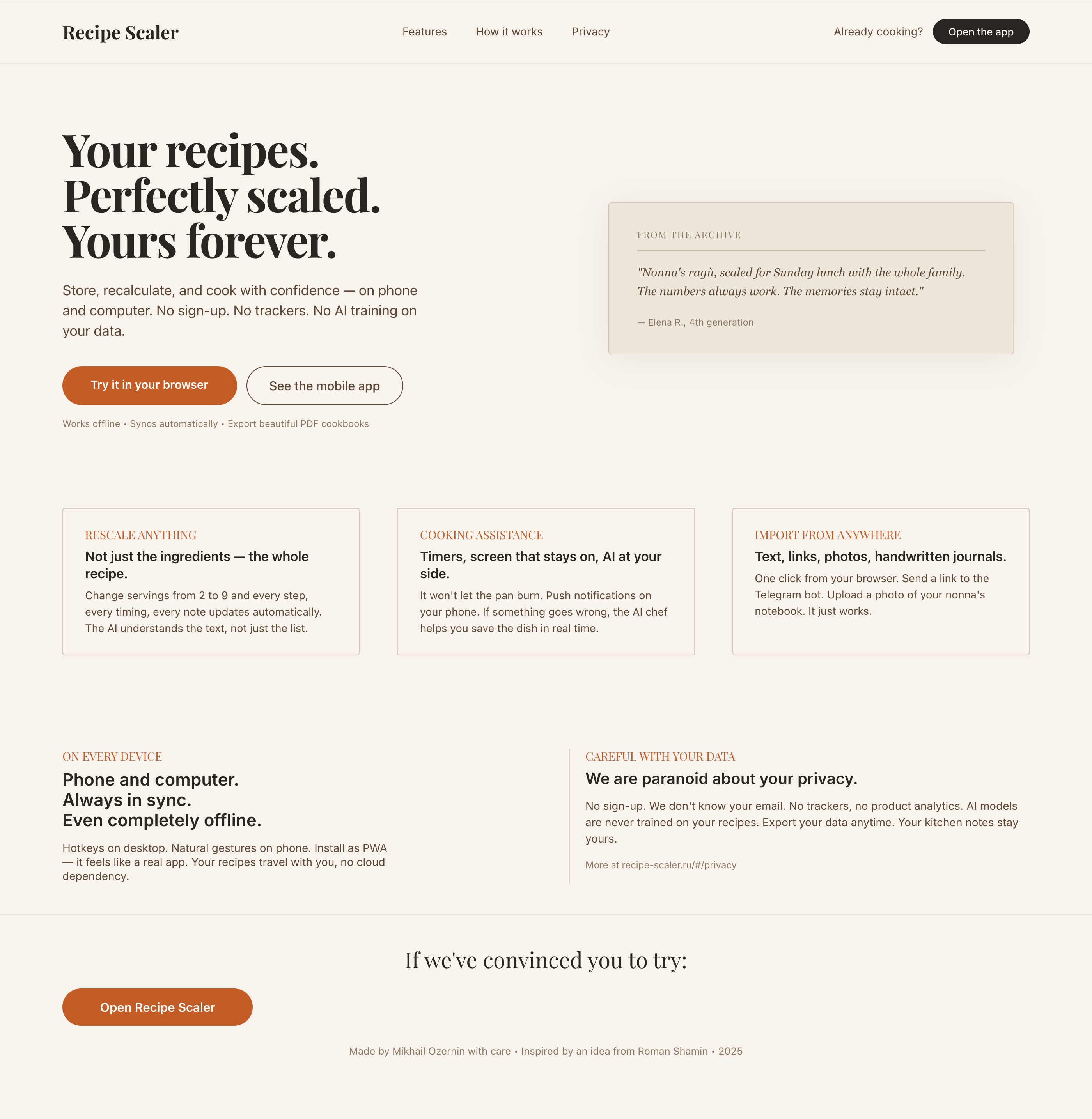
| Claude Code | Opus 4.7, xhigh | 10—15 мин | — | 75%+ квоты pro · 5h | Недолго. Дорого. Офигенно. |
| Claude Code | Opus 4.8, xhigh | — | — | 53% квоты pro · 5h (уже удвоенной) | Жрет больше, делает не факт, что лучше, чем 4.7. За три экрана съел половину уже удвоенной 5h pro-квоты. |
| Claude Code | Opus 4.7, med | 5—10 мин | — | 56% квоты pro · 5h | Сохраняет стиль Опуса 4.7, упрощает реализацию |
| Claude Code | Opus 4.6, Max reasoning | — | — | 37% квоты pro · 5h | В целом выглядит как упрощенный Опус 4.7, сильно ближе к Соннету по общему лейауту |
| Claude Code | Sonnet 4.5, xhigh | 8 мин | — | 25% квоты pro · 5h | Существенно ближе к китайским моделям и моделям попроще. Аккуратно, но совсем нейтрально, совсем упрощено |
| Claude Code | Haiku 4.5 | 3 мин | — | 6% квоты pro · 5h | Не справился даже с тулами. Нет ни одной причины использовать |
| Codex | GPT 5.5, xhigh | 15 мин | — | 26% квоты plus · 5h | Очень дешево по сравнению с опусом, результат соответствующий. Худший результат из СОТА-моделей (state of the art, которые) |
| Codex | GPT 5.4, xhigh | 15 мин | — | 17% квоты plus · 5h | Удивительно, что мне этот вариант нравится даже больше, чем у ГПТ 5.5 |
| Cursor | Auto | 25 мин | 13.7M | $4.33 | Поразительно хороший результат для Авто-режима. Не знаю кто делал, может быть общую задачу делал как раз Опус на лоу-ризонинге, а реализация была каким-то ГПТ-нано. Выбор стиля как будто от Опуса |
| Cursor | Opus 4.7 | 35 мин | 15M | $12.30 | Вдвое дороже, чем Опус 4.7 у Кило. Очень много проверяет себя, скриншотил буквально каждый этап и каждый блок. Результат чуть лучше |
| Cursor | GPT 5.4, xhigh | 11 мин | 4.5M | $2.20 | Агент другой, модель узнается, это все тот же ГПТ 5.4, что был в Кодексе. Но тут как будто чуть лучше вышло. |
| Cursor | Gemini 3.1 Pro | 8 мин | 3.4M | $2.01 | Результат сопоставимый с Гемини в Антигравити. Очень плохо для модели такого уровня. |
| Cursor | Grok 4.3 | ~18 мин | 3M | $1.65 | От Грока впечатления смешанные. Мобилка в целом норм, на уровне других. Промо хуже чем собраться. Я думал будет дешевле, Грок 4.1 был очень классный именно за счет того, что стоил ну очень мало. |
| Cursor | GLM 5.1 (z.ai coding plan) | ~7 мин | — | 37% квоты lite · 5h | ГЛМ в Курсоре почему-то не смог справиться с тулами |
| Cursor | Composer 2 | 5 мин | 1.3M | $0.33 | Очень примитивно, но и зато очень дешево. Не соответствует тому уровню, что Курсор заявляет о своей модели, конечно. Но они честно говорили, что делают модель для кода в первую очередь |
| Cursor | Composer 2.5 | — | 1.6M | $0.21 | Сопоставим по стоимости с Composer 2, качество подросло, но все еще сильно не очень |
| Cursor | MiMo V2.5 Pro | — | 4.8M | 4.8M из 4,1B включённых попугаев | Включённая модель Курсора; в подписке очень дёшево, в дизайне слабо |
| Source Craft | Default | 7 мин | — | 65 попугаев из 4500 квоты | Вроде недорого, но пользоваться смысла нет, нейрослописный нейрослоп |
| Source Craft | Default Thinking | 10 мин | — | 74 попугаев из 4500 квоты | Как будто Default и Default Thinkign модели в Яндекс Сорс Крафте не просто разные режимы одной модели, а разные модели: слишком разный результат, у рисонинг модели даже хуже. |
| Kilo Code | Opus 4.7 (Kilo cloud) | 27 мин | 6.3M | $6.96 | Типичный Опус 4.7. Местами чисто, интересно, издалека дак прямо супер-пупер |
| Kilo Code | Hy3 preview (Kilo cloud) | — | 1.6M | $0.06 | Самая модная опенсорс-модель на опенроутере. Очень так себе. |
| Kilo Code | Qwen 3.6 Max Preview (Kilo cloud) | 17 мин | 2.2M | $0.42 | В целом Квен для меня справился неплохо. Туповато, по крепко вполне. В промо просел как все. 1/30 от Опуса по цене. |
| Kilo Code | Qwen 3.5 397 | 6 мин | — | — | Не справился с тулами |
| Kilo Code | Grok Build 0.1 + Google Skill | — | — | $0.83 | Тот же промт со скиллом Google design; сравните с OpenCode Grok Build 0.1 без скилла |
| OpenCode | Opus 4.7, xhigh reasoning (OpenRouter) | — | 2.7M | $2.74 | Неплохо, что было бы в мобилке не знаю, потому что после этого экрана опенроутер меня забанил от американских СОТА-моделей |
| OpenCode | Kimi 2.6 (OpenRouter) | 42 мин | 3.62M | $1.78 | Мобилка лучше остального, остальное плохо. Из забавного все дублировалось, но он потом через скриншоты обнаруживал и стирал сам. Из-за этого возился очень долго — 40+ минут. |
| OpenCode | Grok 4.3 (OpenRouter) | — | 1.57M | $1.09 | Грок уже был выше, но в отличие от Курсора, Опенкод с моделью вообще не справился, результат сильно хуже, чем у Курсора |
| OpenCode | Grok Build 0.1 (OpenRouter) | — | 3.7M | $1.24 | Быстро, слабо, дорого для такого качества |
| OpenCode | DeepSeek V4 Pro (Deepseek Cloud), Max Reasoning | — | 4.1M | $0.09 | Дипсик очень дешев, но справился лишь один раз. Мобилку можно смотреть, остальное плохо |
| OpenCode | DeepSeek V4 Pro (Deepseek Cloud), Max Reasoning | — | 2.5M | $0.05 | Дипсик очень дешев, но справился лишь один раз. Мобилку можно смотреть, остальное плохо |
| OpenCode | GLM 5.1 (z.ai coding plan) | — | — | — | В отличие от Курсора Опенкод смог добиться чего-то от ГЛМ, вышло в целом ок для его цены. Он стоит дешевле Хайку, которы не смог буквально ничего |
| OpenCode | Qwen 3.5 397 | — | — | — | Не смогло ничего |
| OpenCode | MiniMax 2.7 (OpenRouter) | 3 мин | 242K | $0.03 | Невероятно быстро, невероятно дешево, качество соответствующее |
| OpenCode | Qwen 3.7 Max Preview (OpenRouter) | — | 3.13M | $7.95 | Дорого для своего результата, не улучшилось с 3.6 Max. Очень плохо работал с тулами (может быть особенность опенкода) |
3.2 Figma MCP
| Агент | Модель + параметры | Время | Токены | Стоимость | Комментарий |
| Claude Code | Opus 4.7, xhigh | ~19 мин | — | 121% квоты pro · 5h | Опус в своем стиле, издалека особенно, но сожрал больше целой 5-часовой квоты |
| Codex | GPT 5.5, xhigh | 20 мин | — | 16% квоты plus · 5h | В фигме смог чуть лучше, чем в пейпере. Верстает чудовищно просто |
| Cursor | GLM 5.1 (z.ai coding plan) | 25 мин | — | 13% квоты lite · 5h | В целом похуже чем в пейпере. Макет десктопа снизу это я перетащил слой куда нужно, ГЛМ не осилил корректный ДОМ |
| Cursor | Composer 2 | 6 мин | 1.4M | $0.43 | Катастрофически плохо, хуже чем в пейпере |
Полный список всех картинок
Paper MCP
Antigravity + Gemini 3.1 Pro, high
Очень плохо использует тулы, чудовищная интеграция в инструмент.
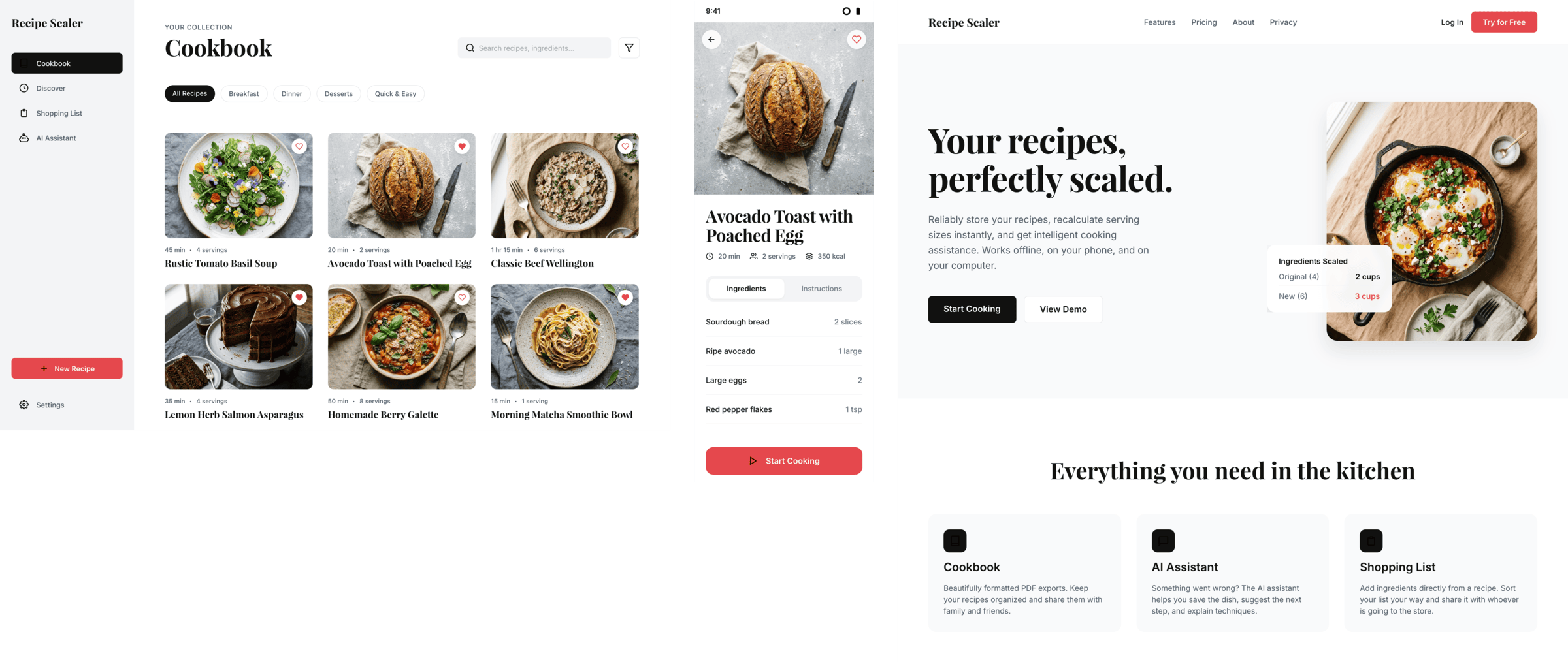
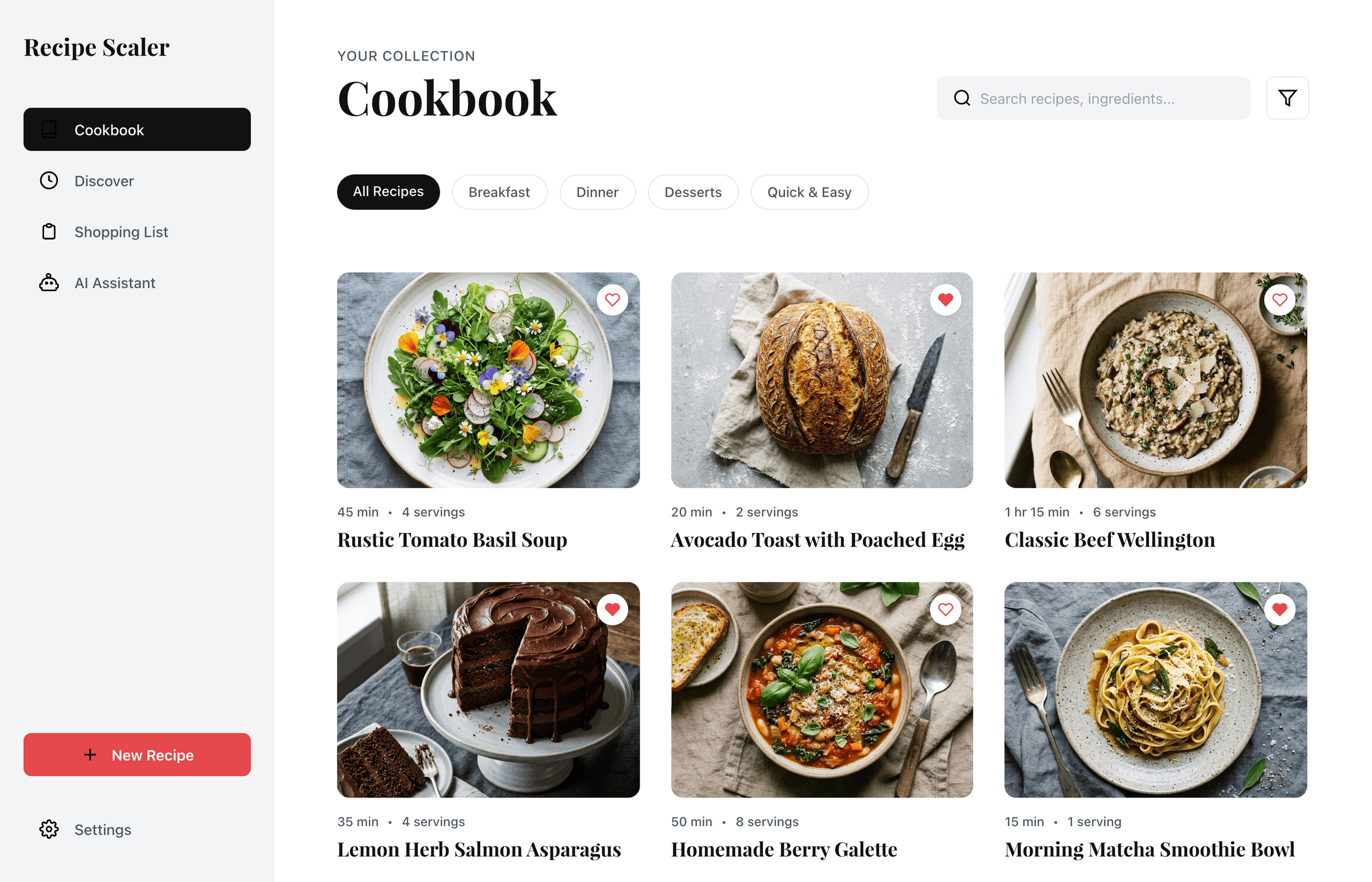

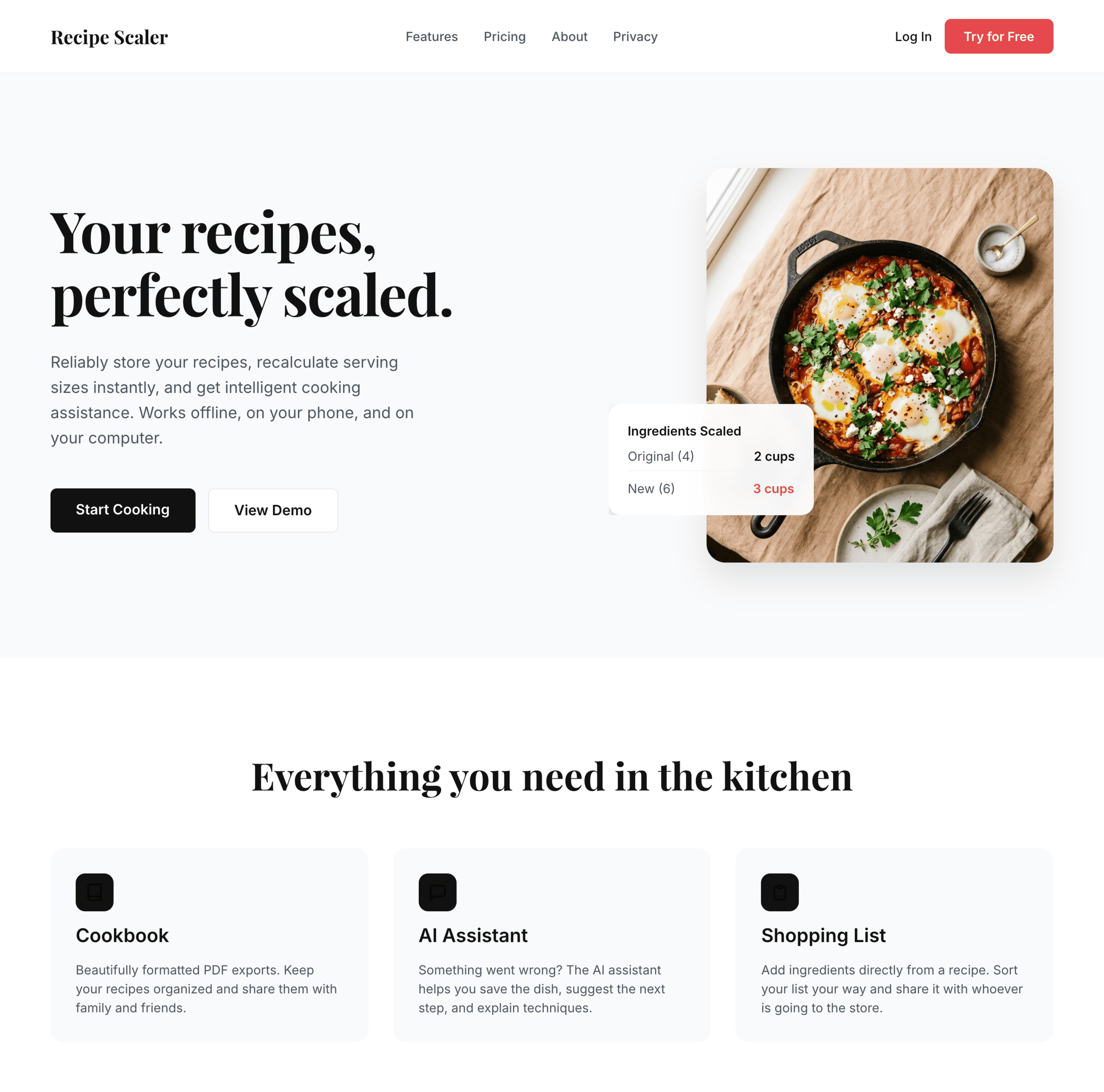
Antigravity + Gemini 3.5 Flash
Заметно лучше, чем Gemini 3.1 Pro (но рост от его уровня несложный). Единственный, кто решил сделать дарк-мод.
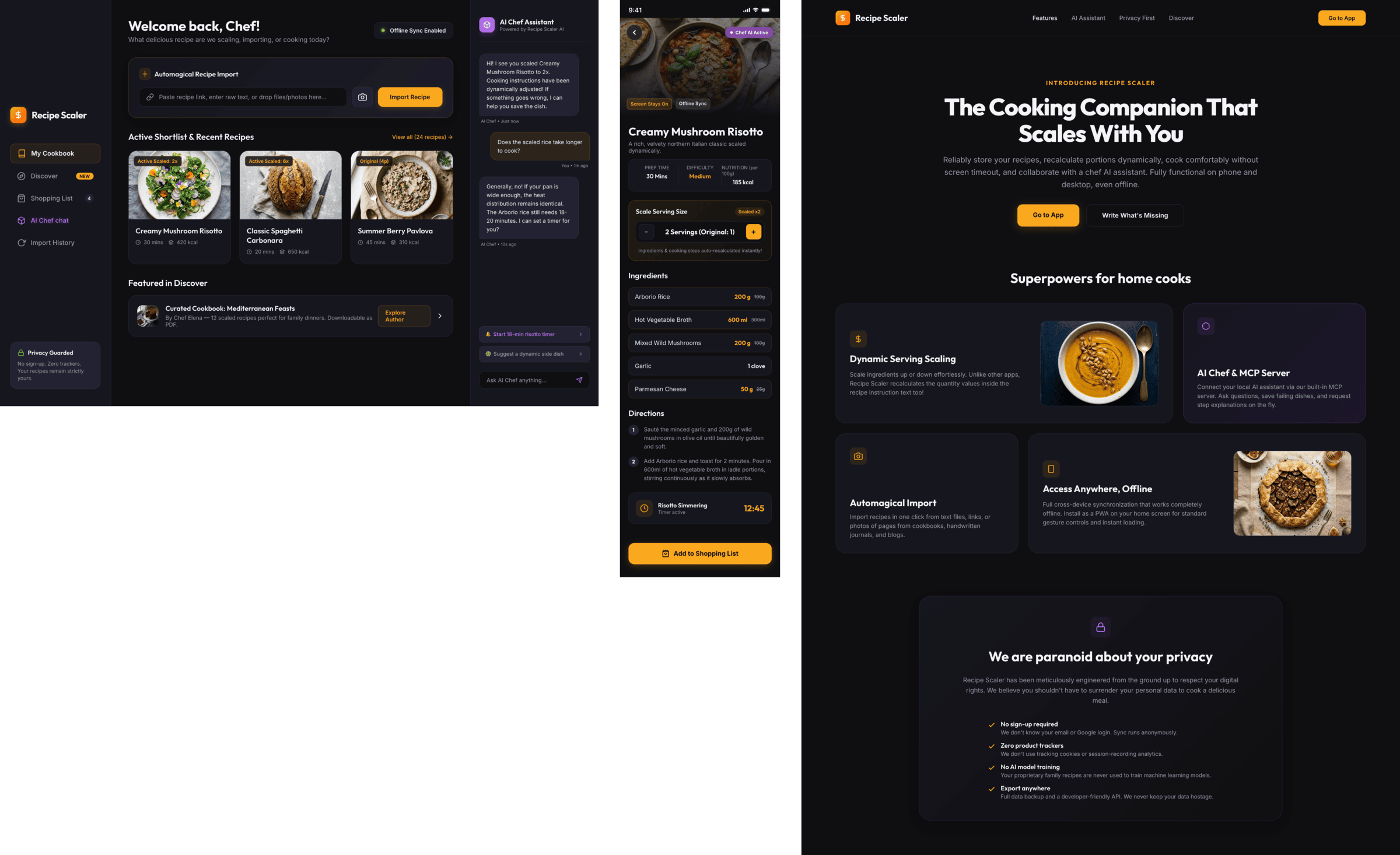
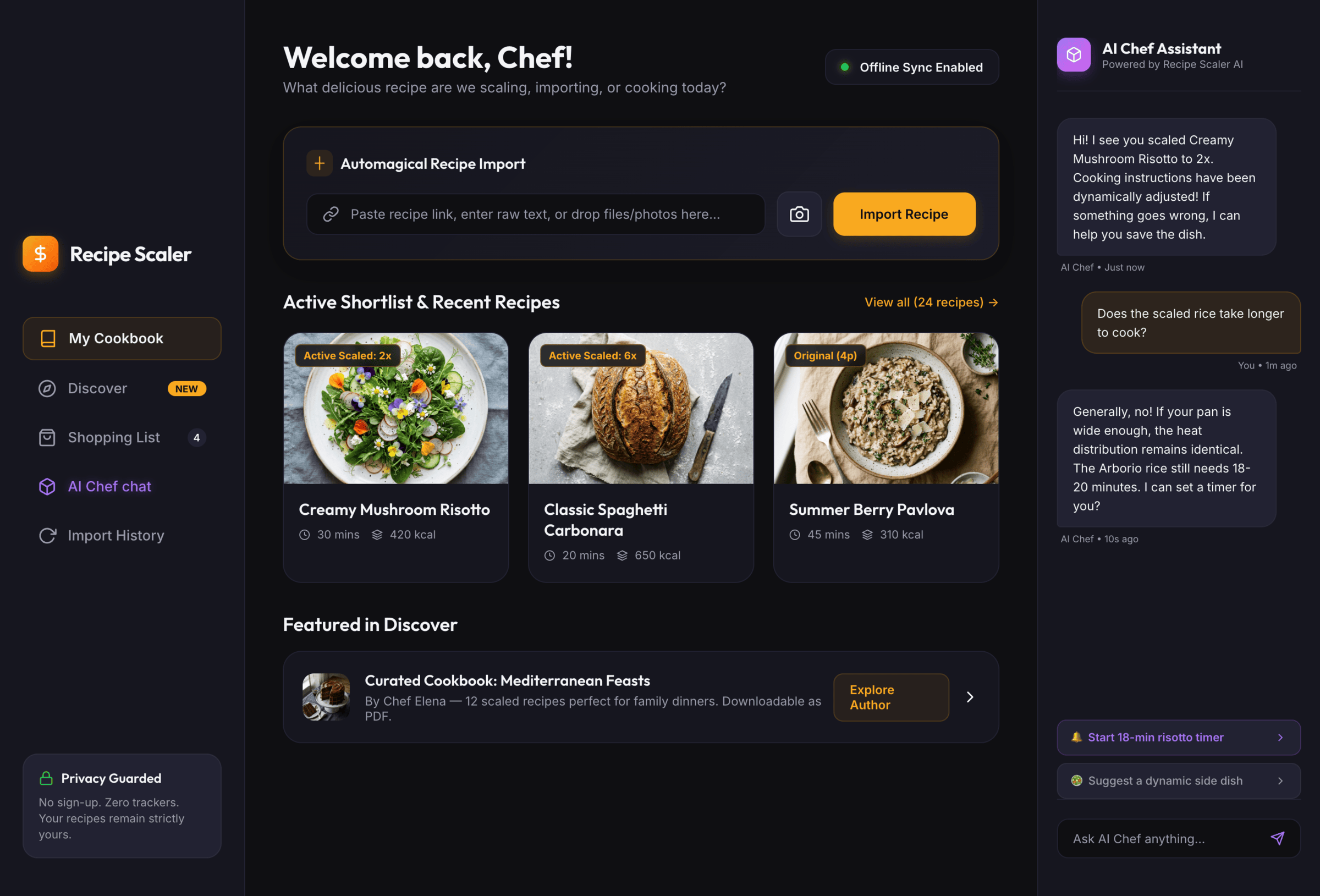
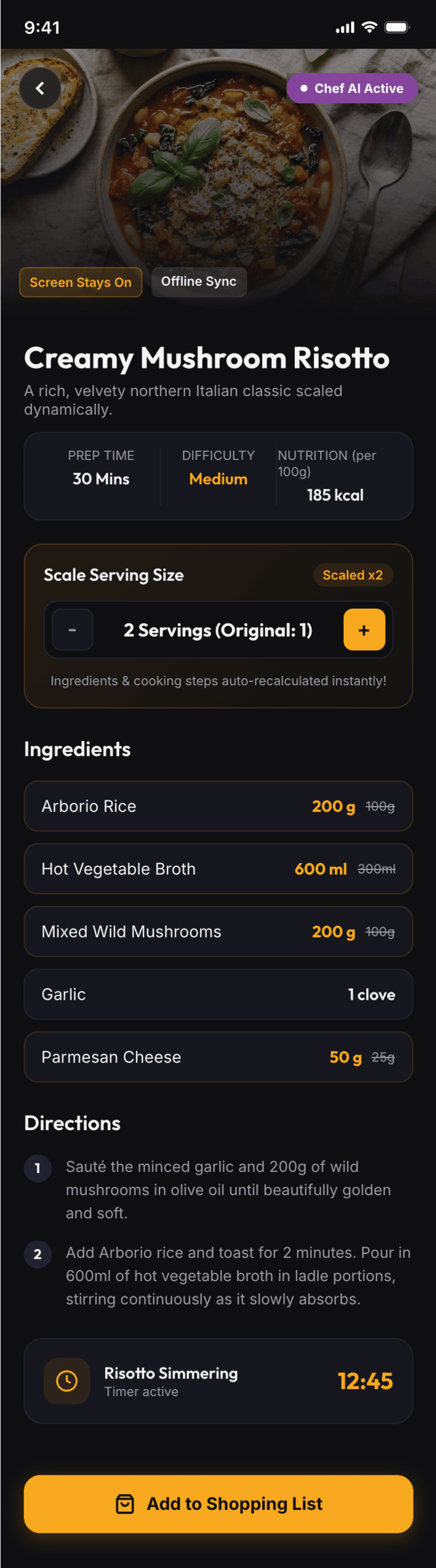
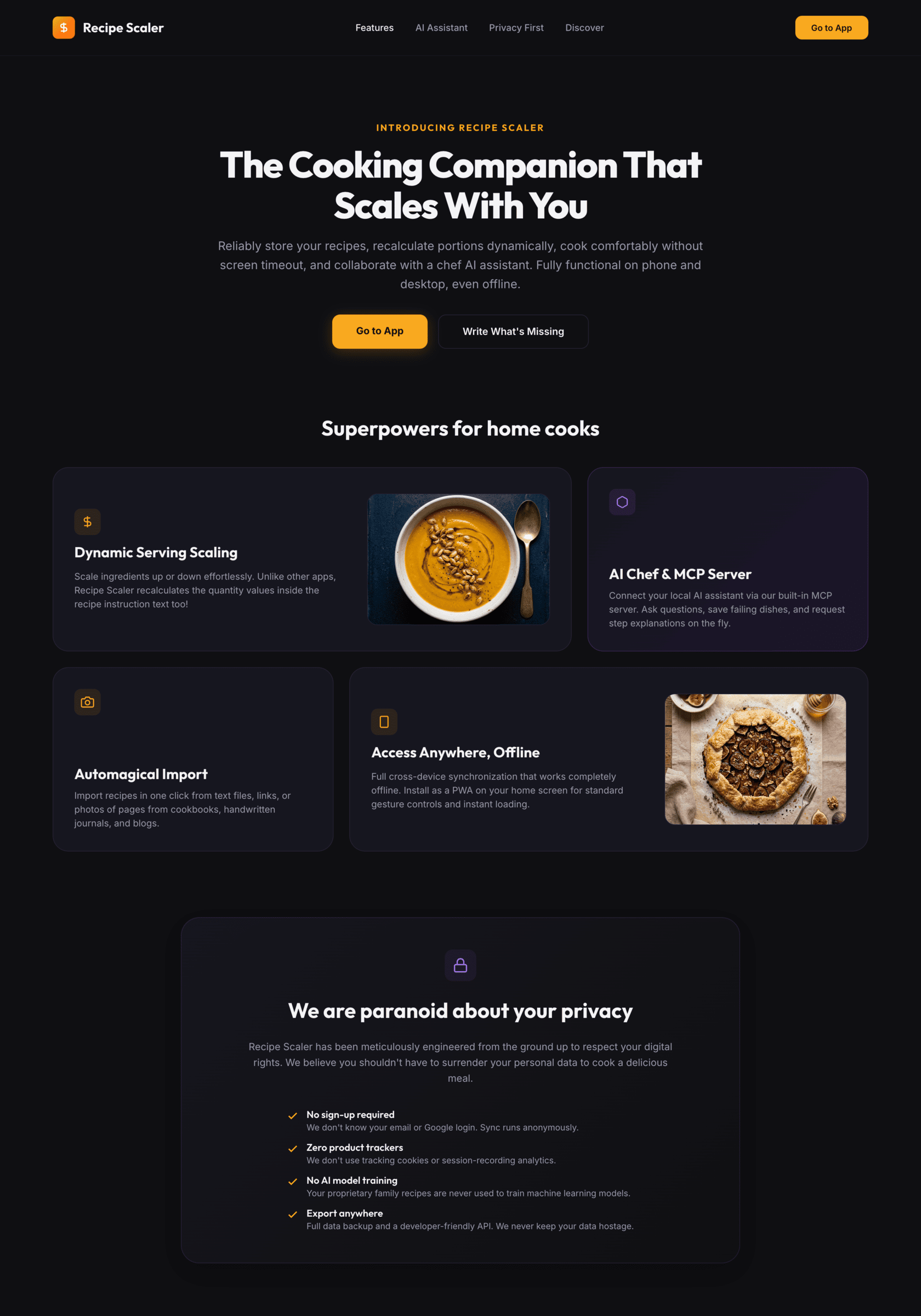
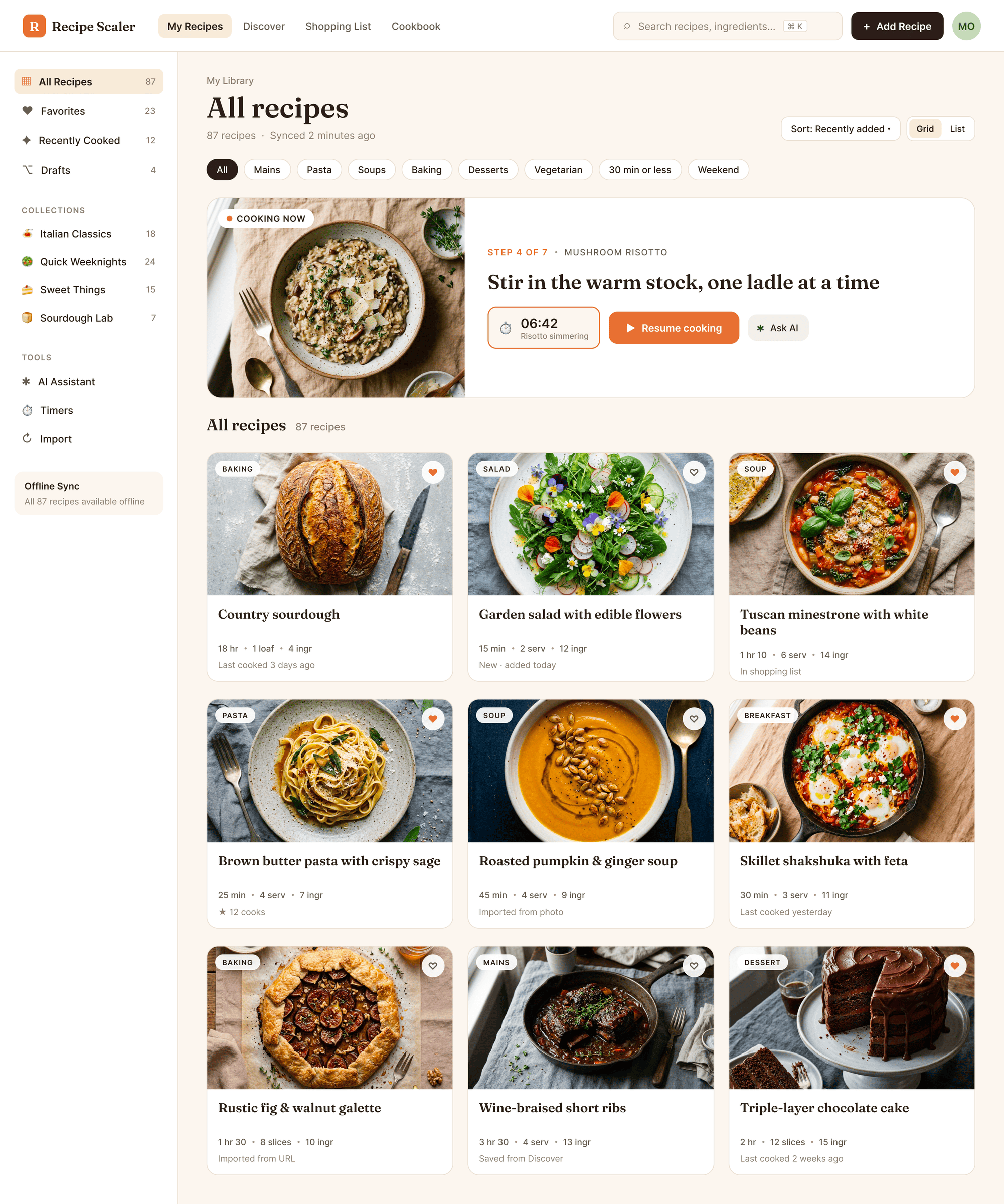
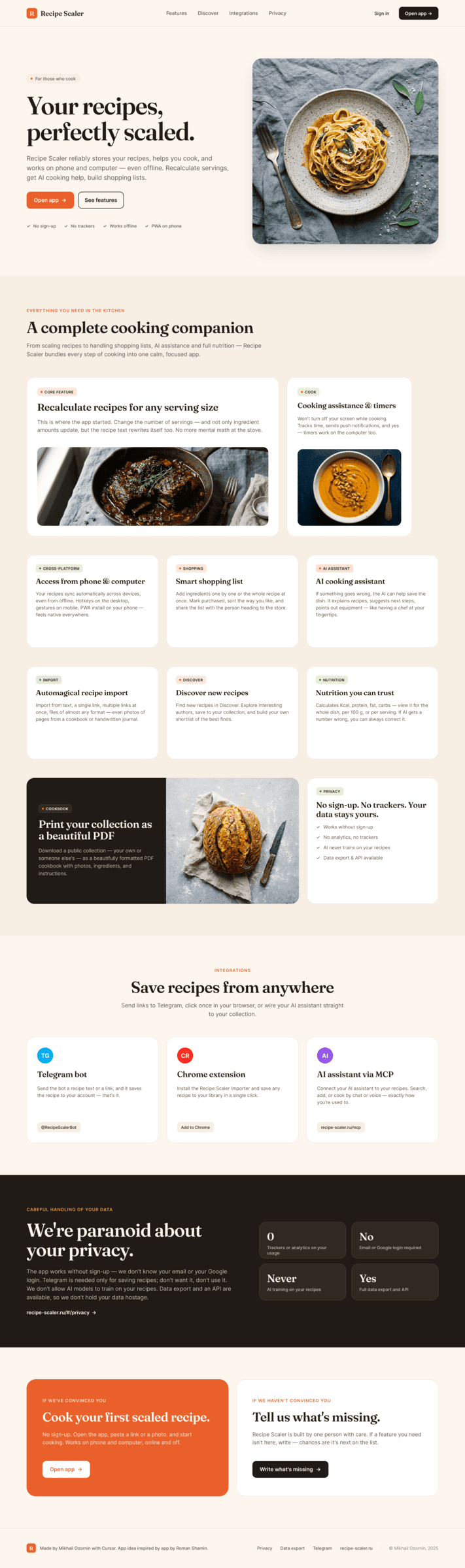
Claude Code + Opus 4.7, xhigh
Недолго. Дорого. Офигенно.
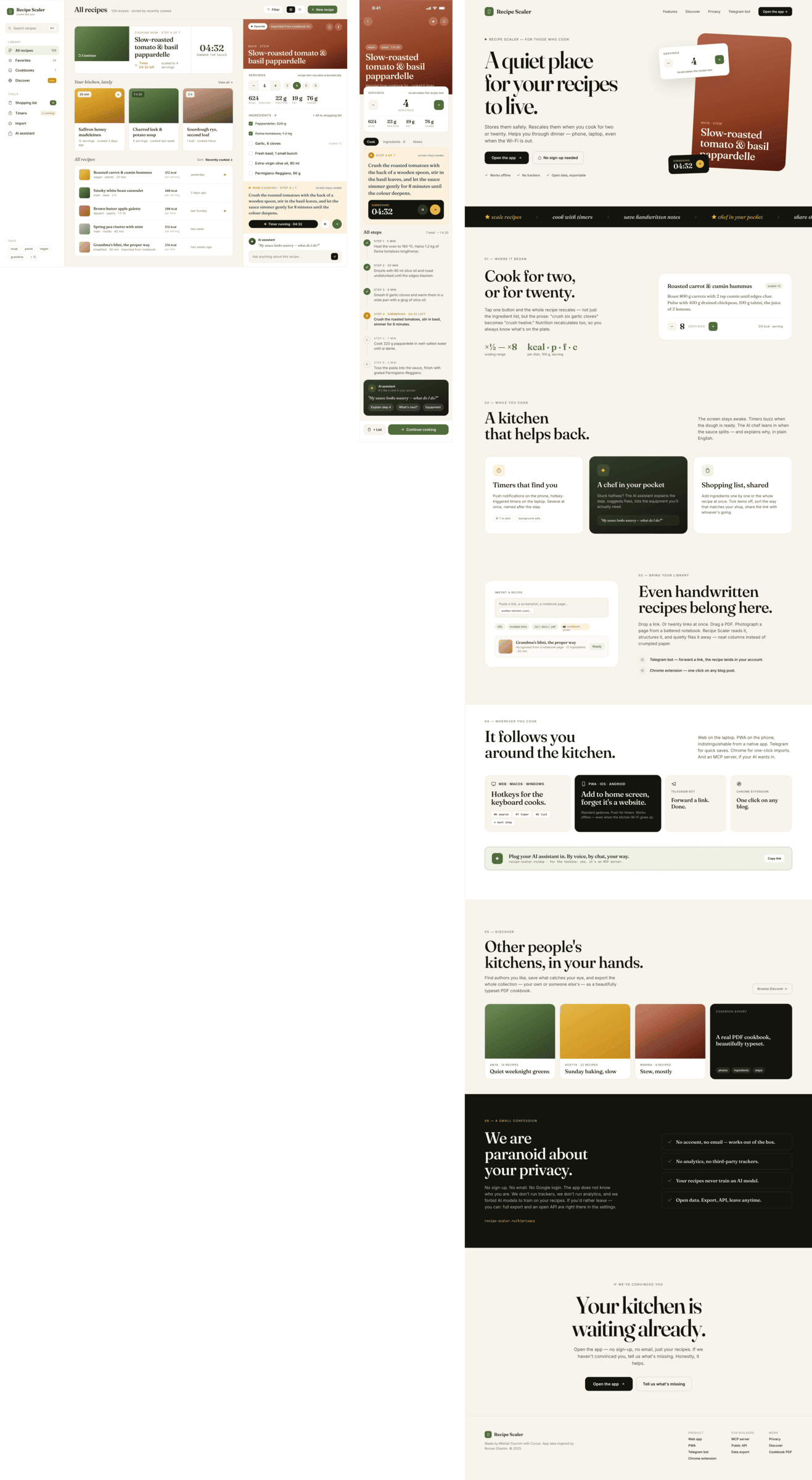
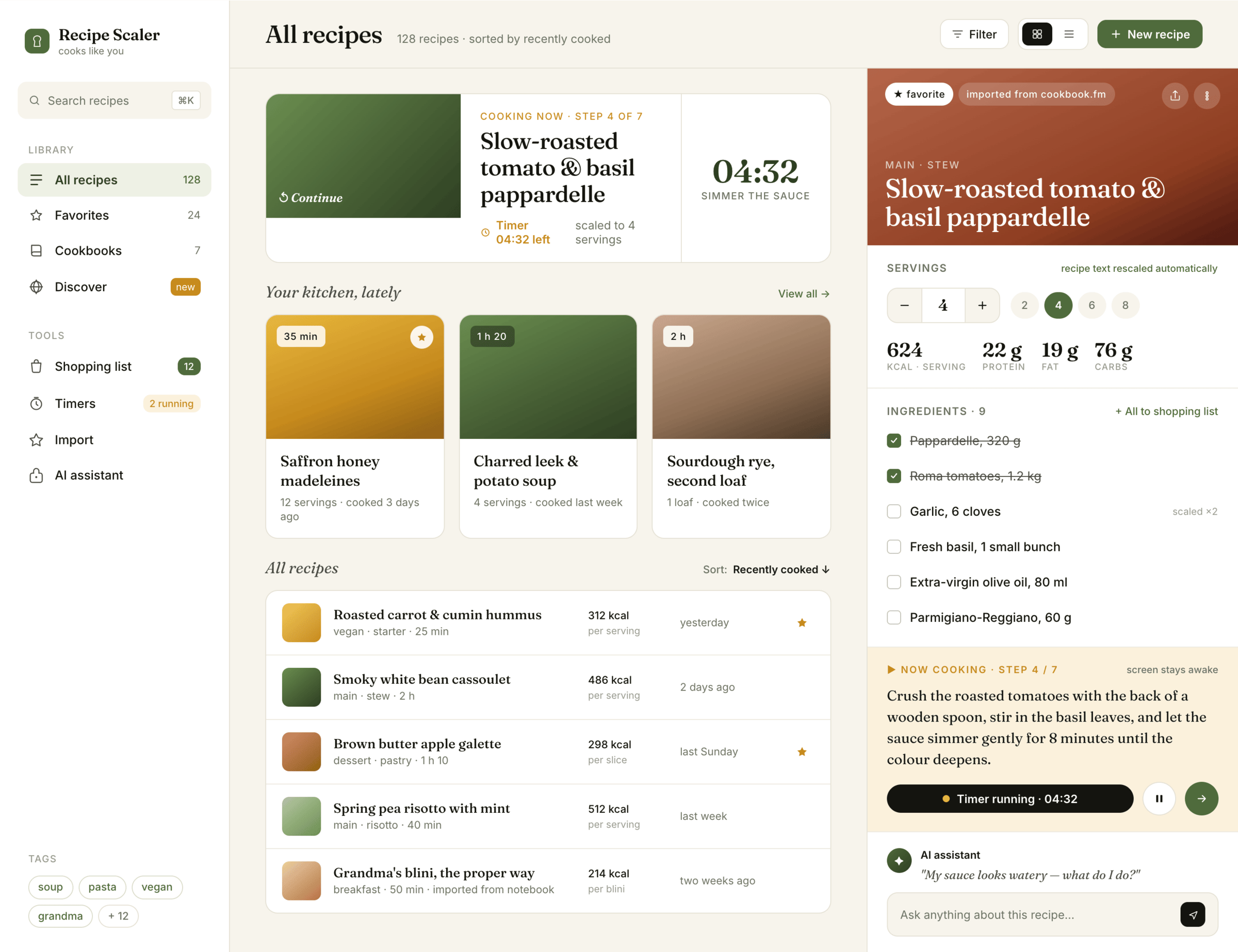
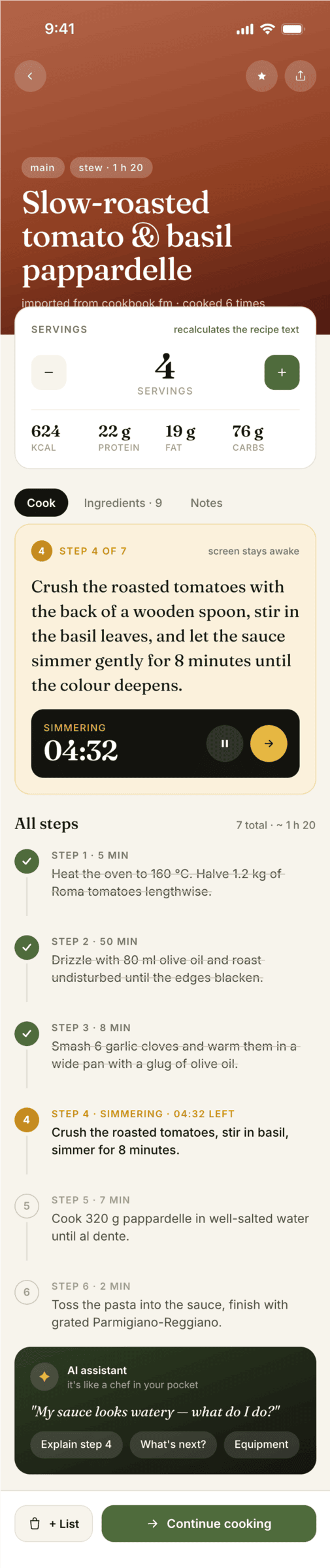
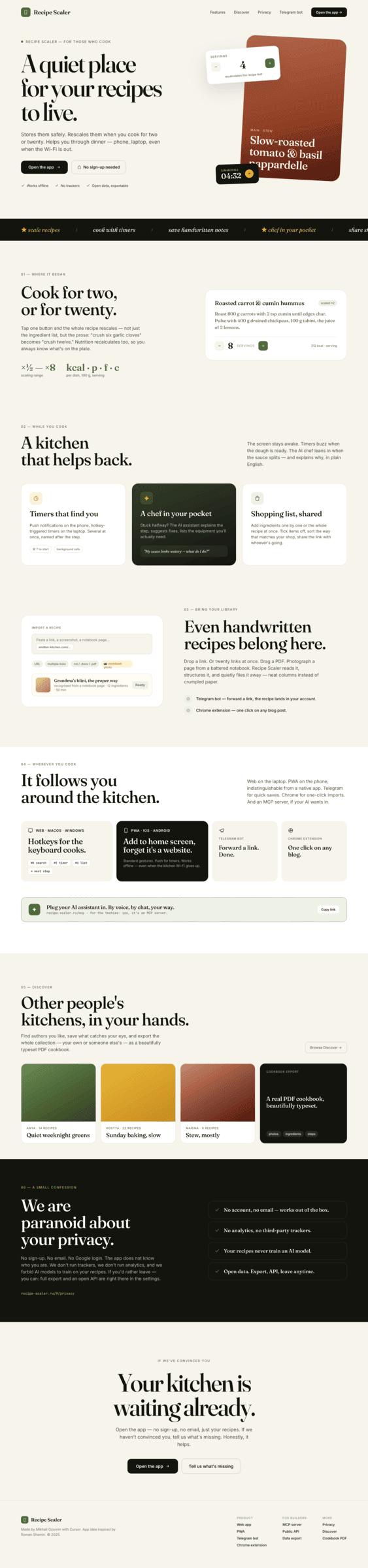
Claude Code + Opus 4.8, xhigh
Всё ещё уровень Опуса; на три экрана съел половину уже удвоенной 5h pro-квоты.
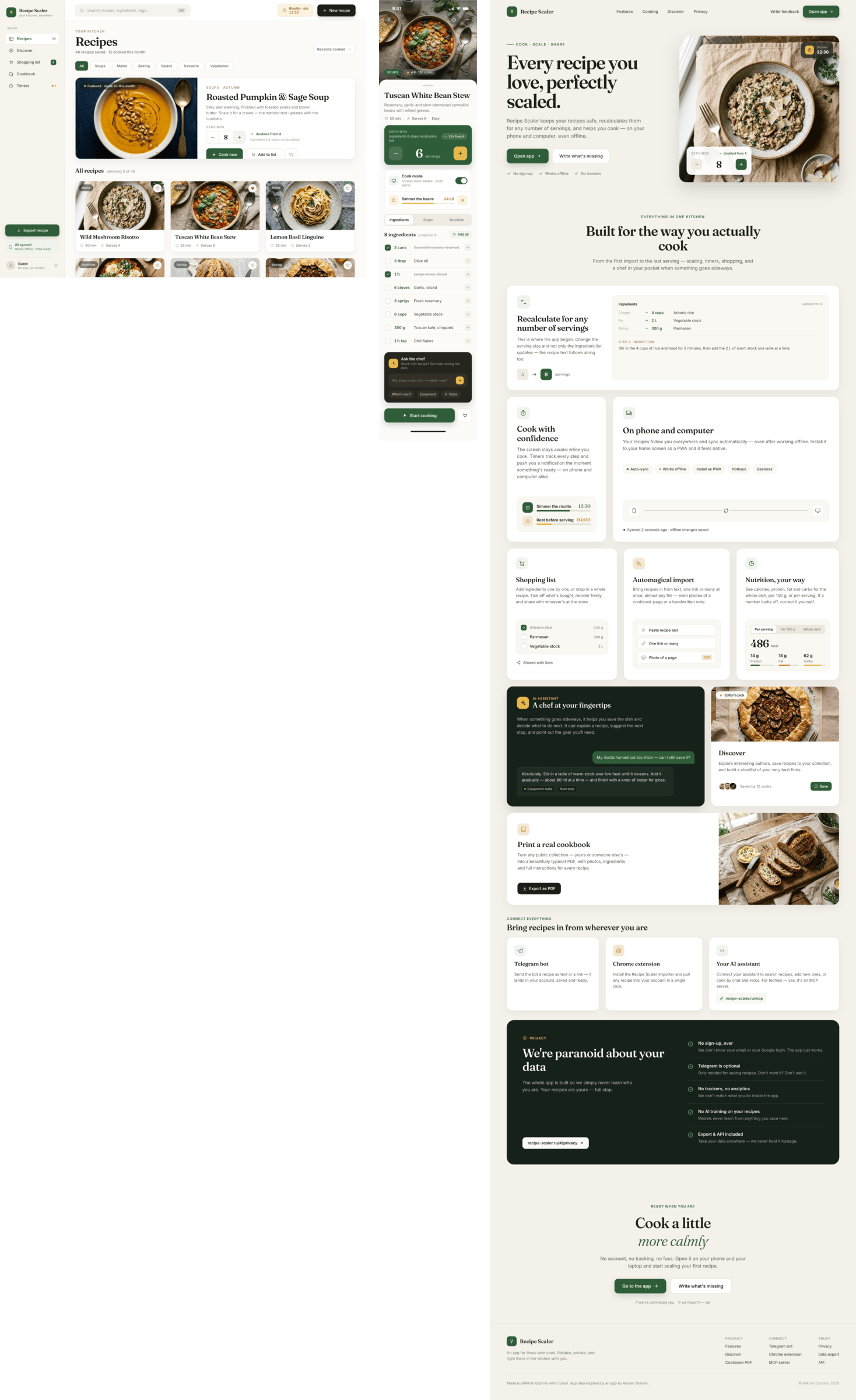
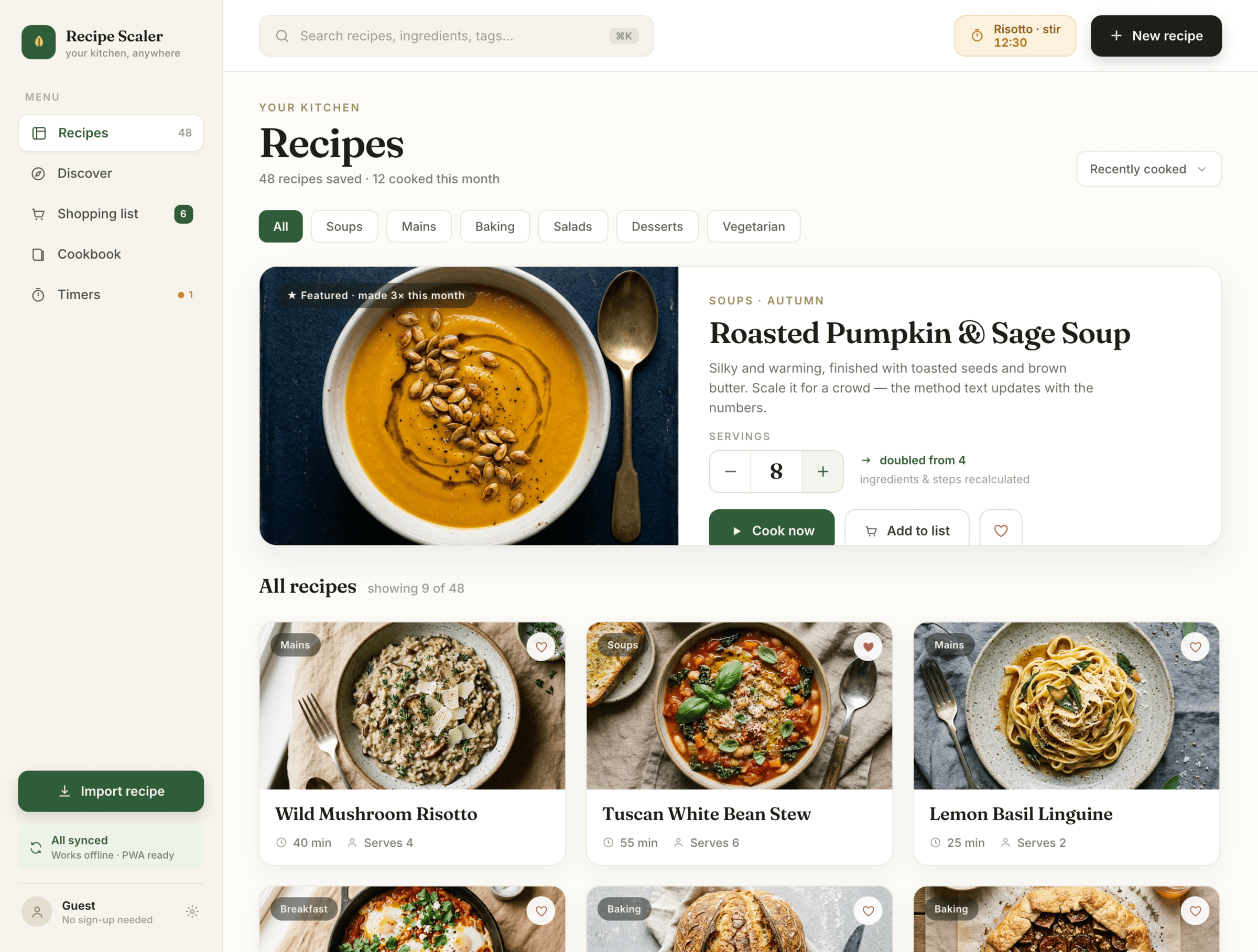
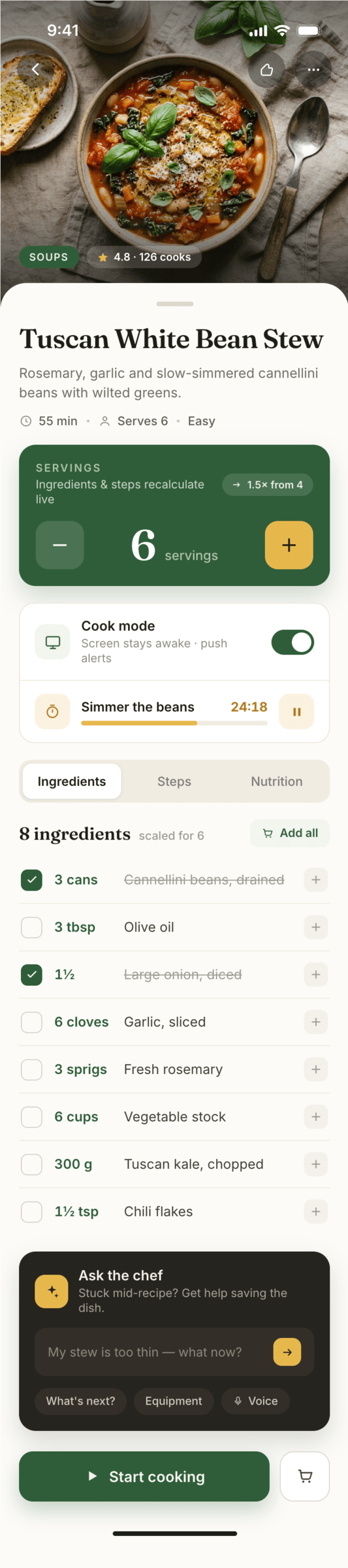
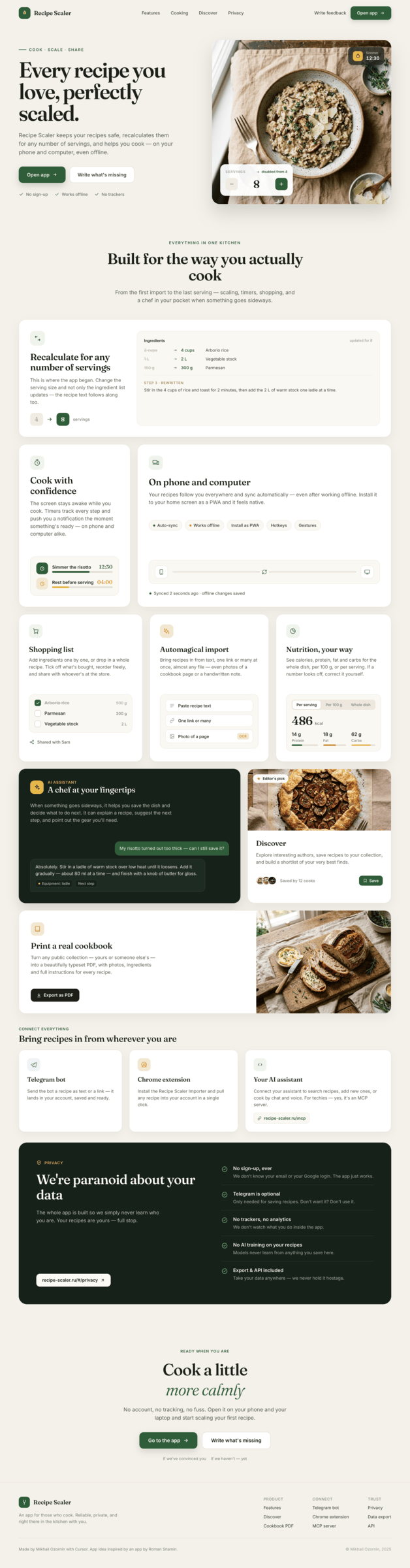
Claude Code + Opus 4.7, med
Сохраняет стиль Опуса 4.7, упрощает реализацию.
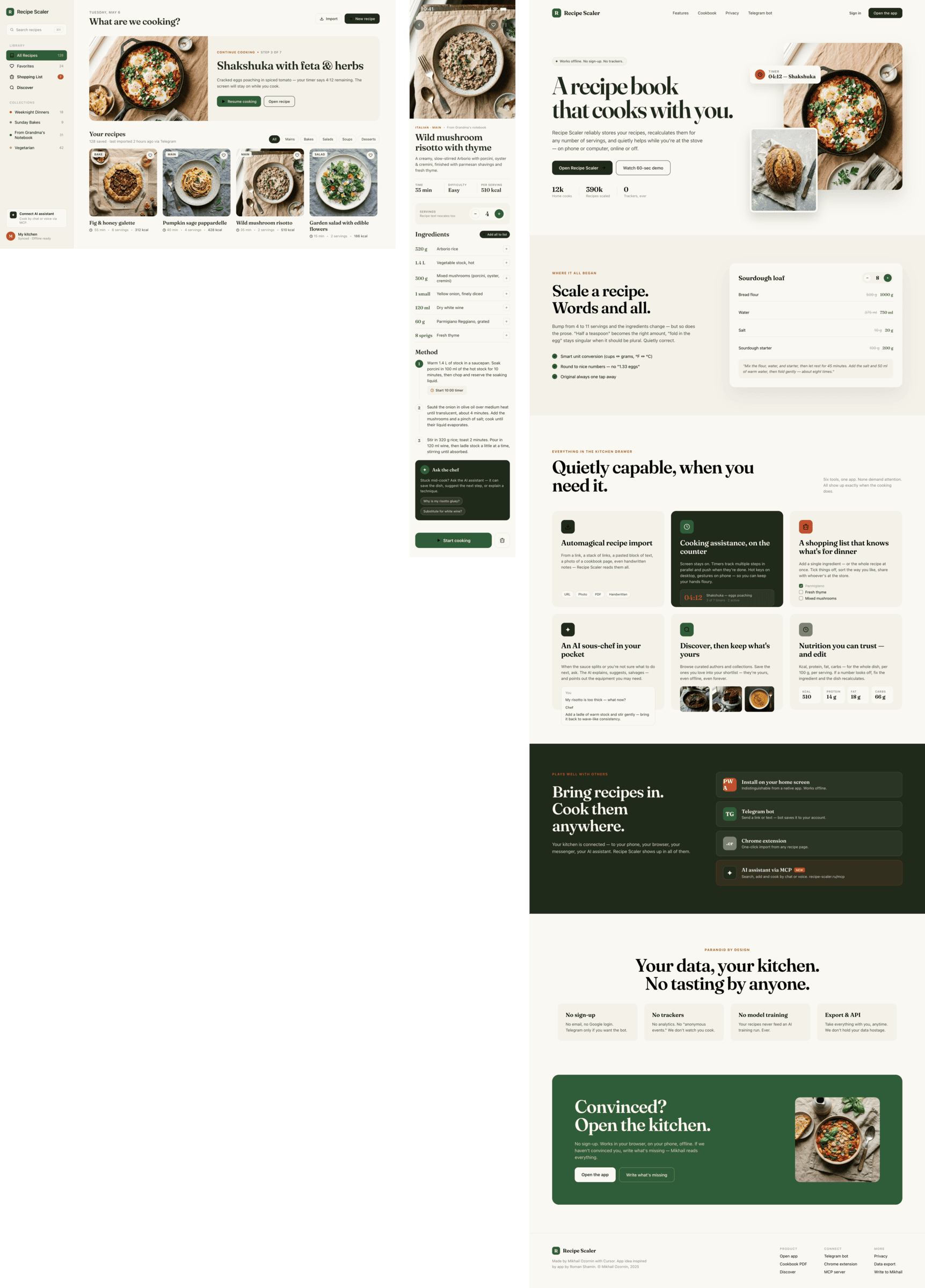
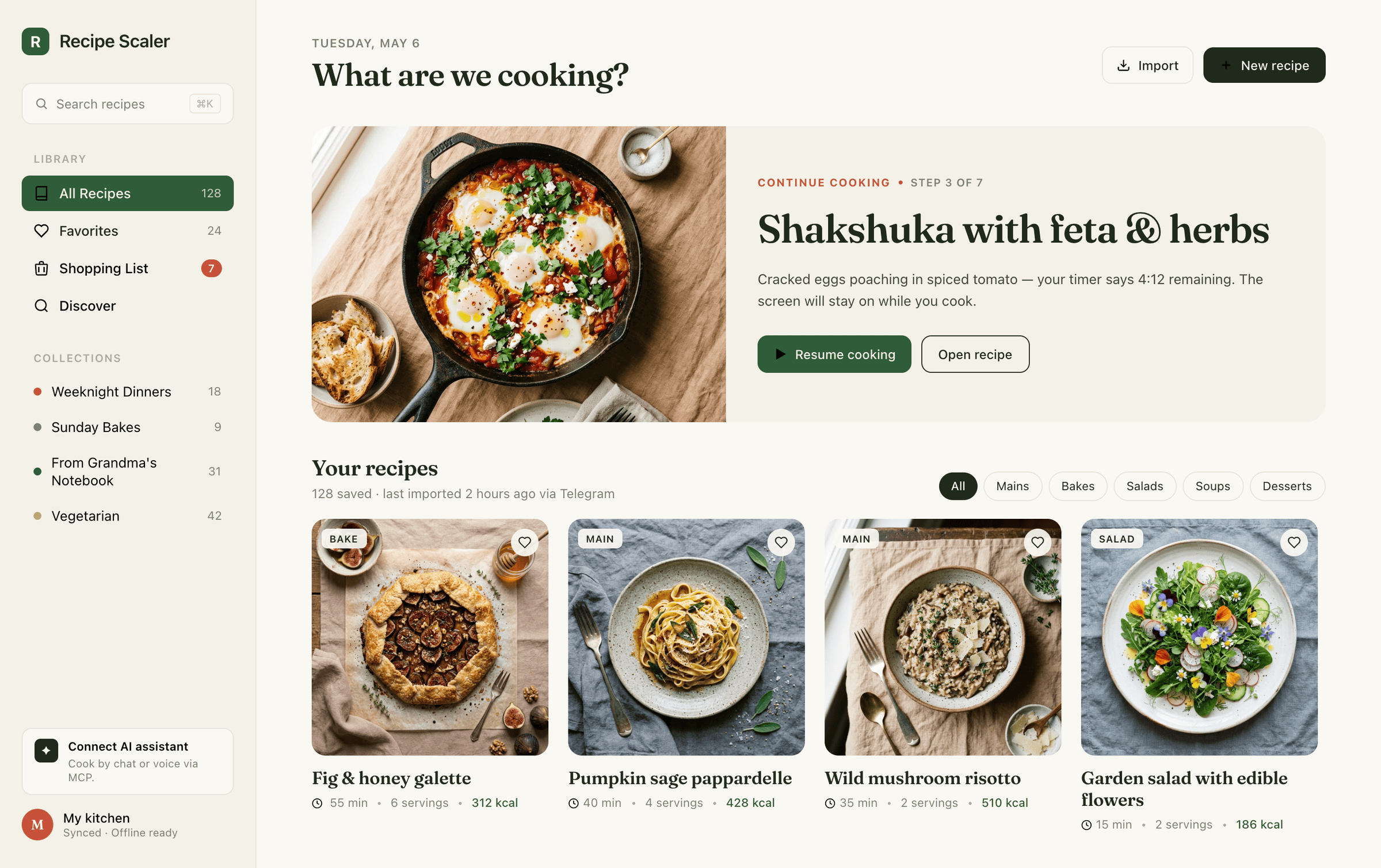

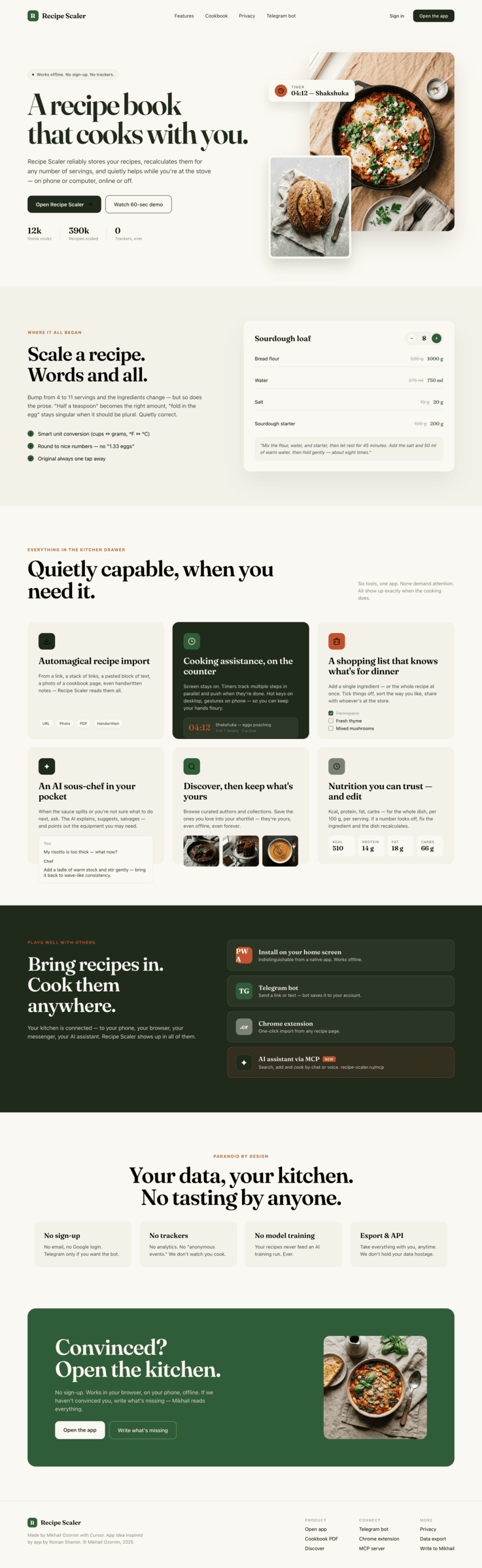
Claude Code + Opus 4.6, max
В целом выглядит как упрощенный Опус 4.7, сильно ближе к Соннету по общему лейауту.
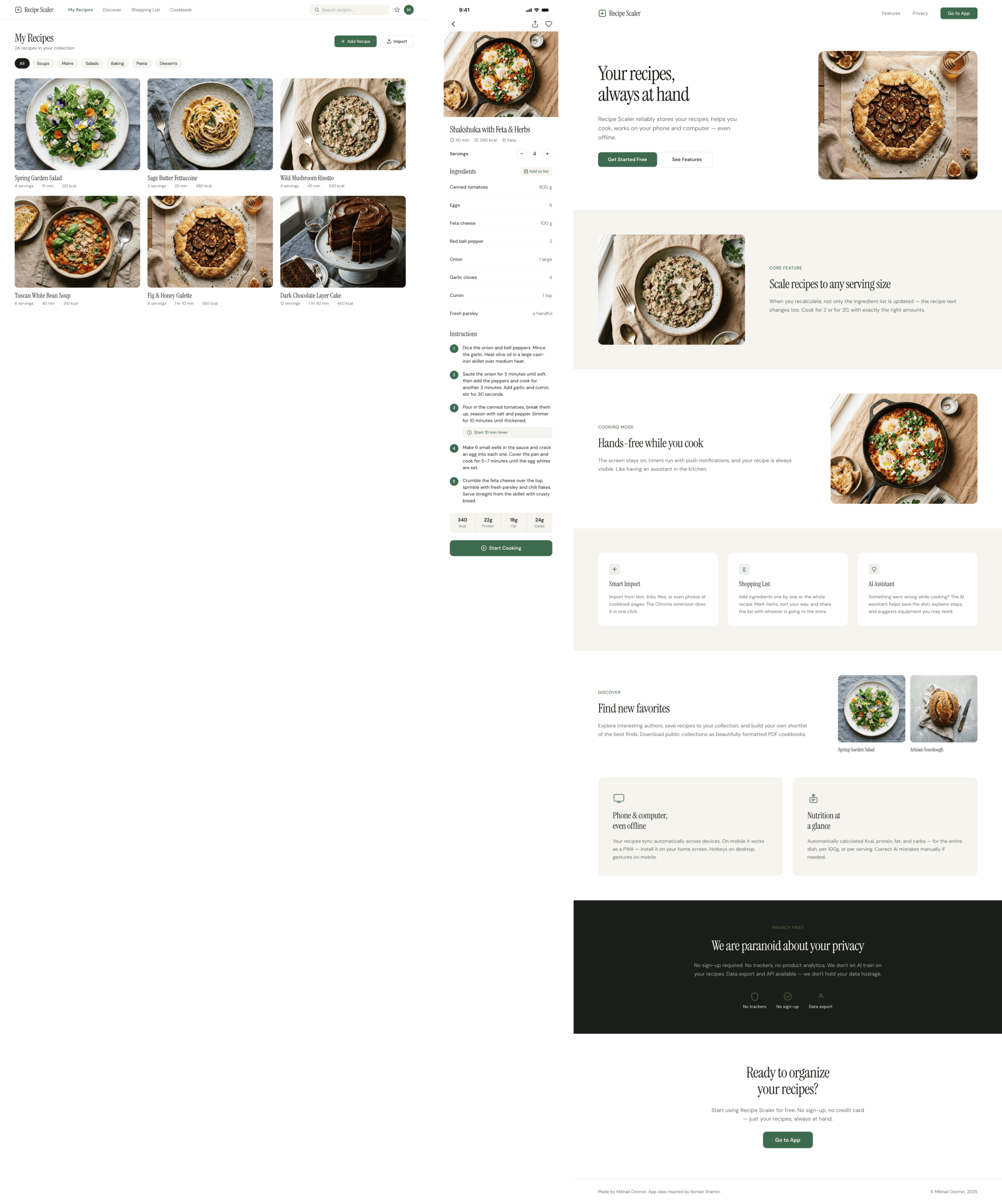
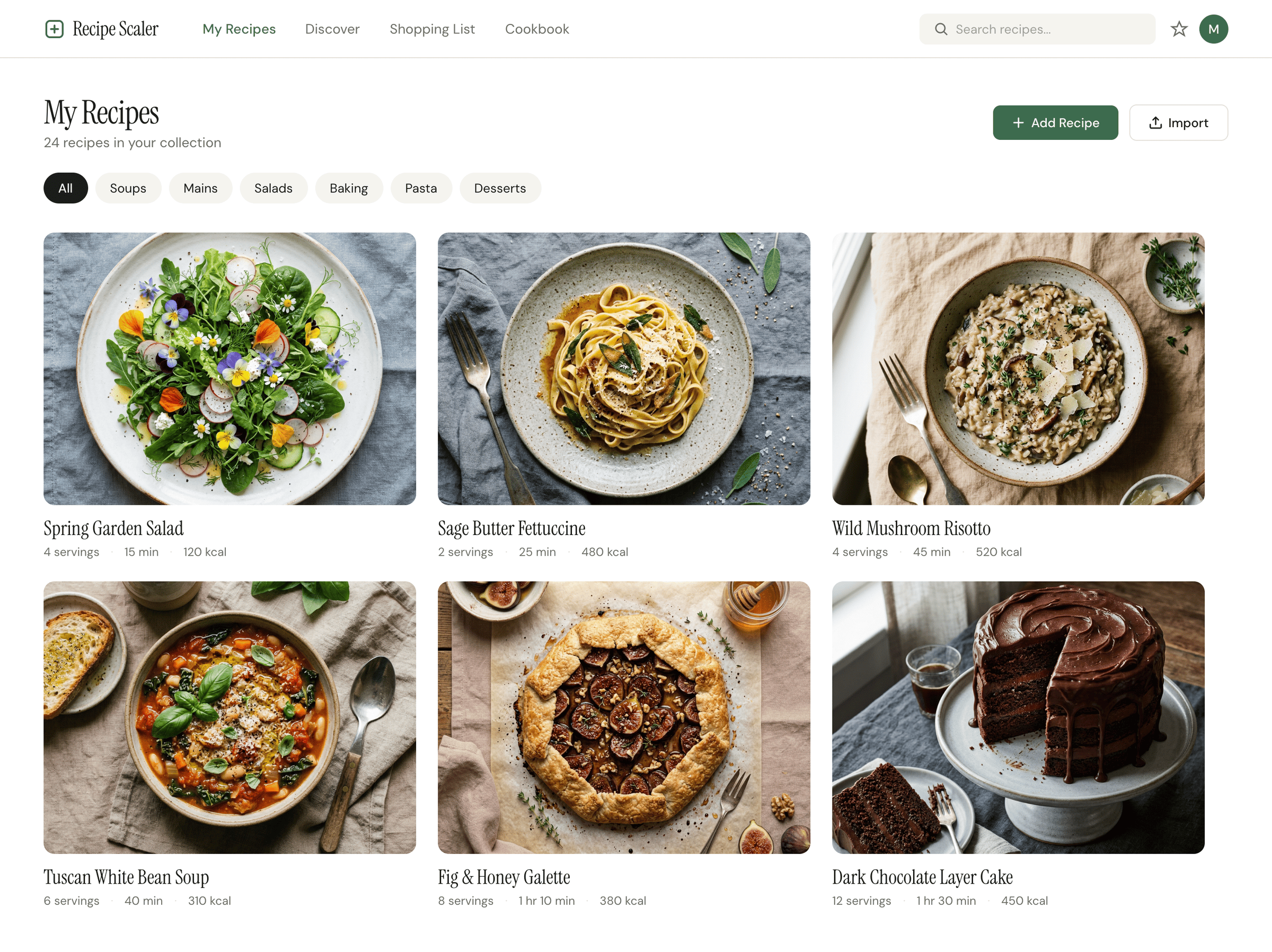
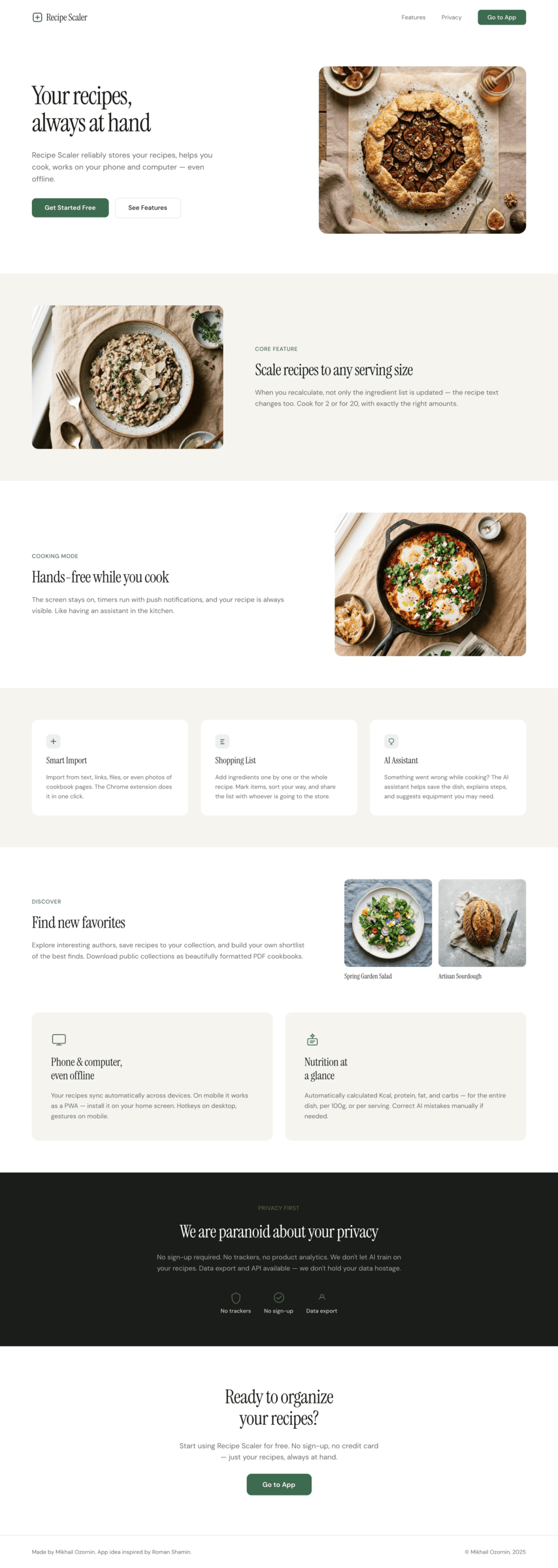
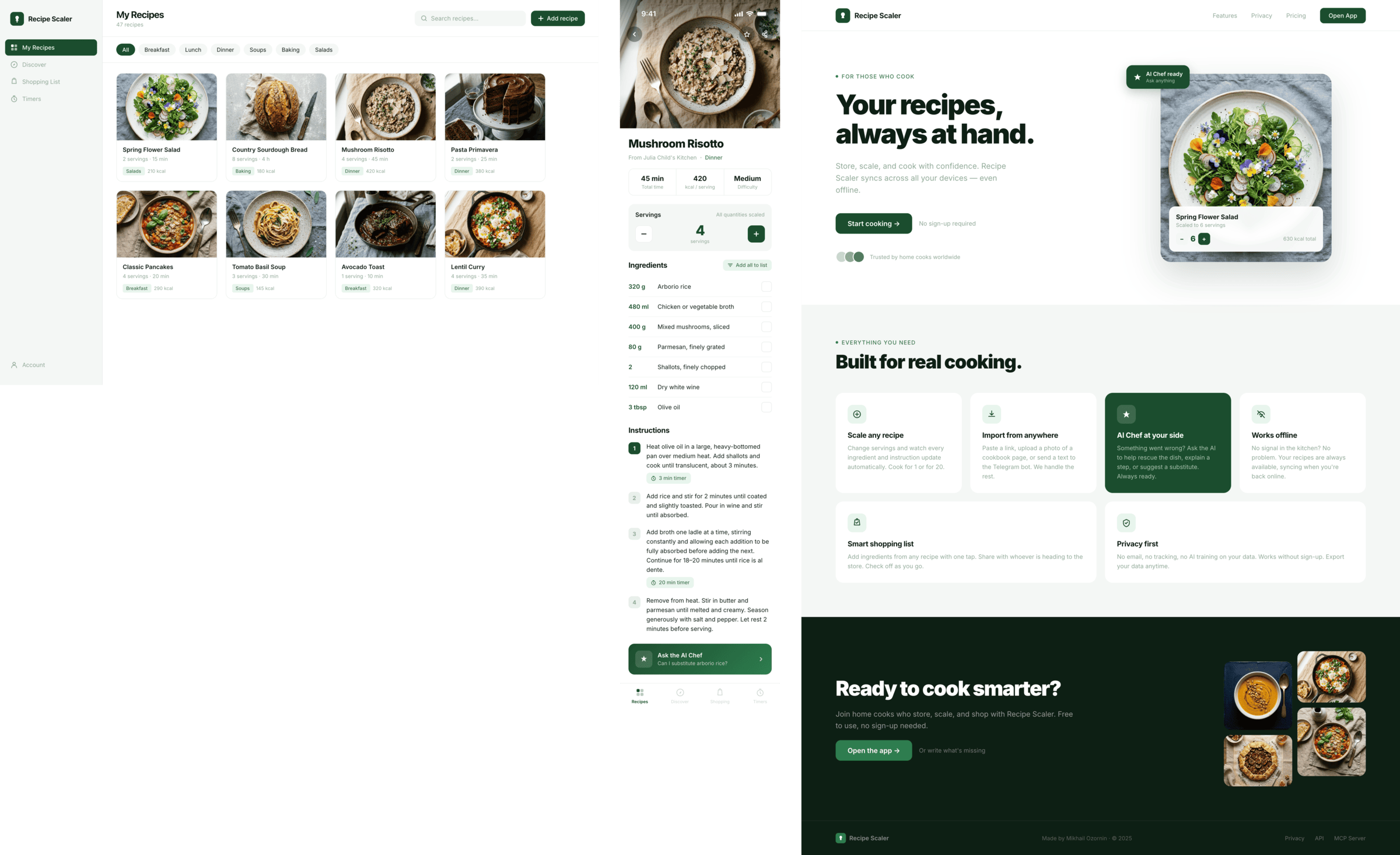
Claude Code + Sonnet 4.5, xhigh
Существенно ближе к китайским моделям и моделям попроще. Аккуратно, но совсем нейтрально, совсем упрощено.
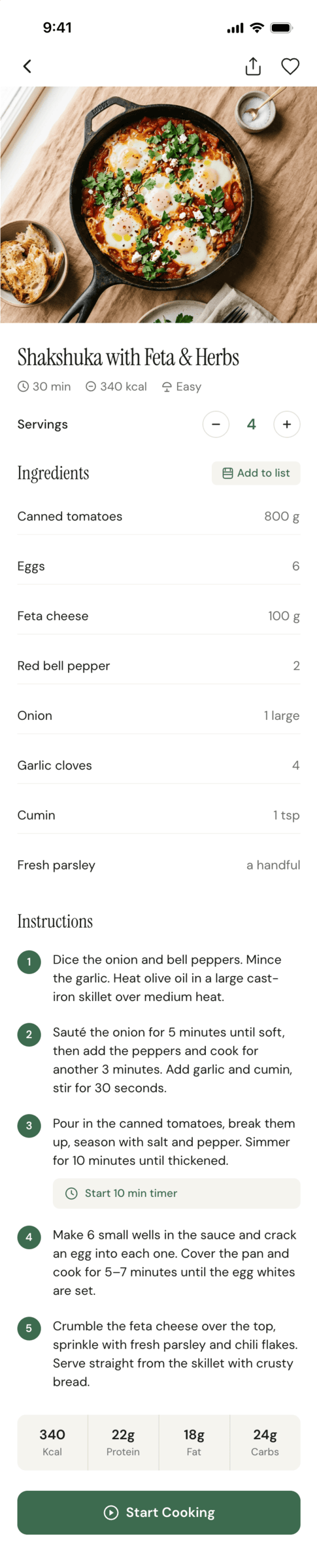
Claude Code + Haiku 4.5
Не справился даже с тулами. Нет ни одной причины использовать.




Codex + GPT 5.5, xhigh
Очень дешево по сравнению с опусом, результат соответствующий. Худший результат из СОТА-моделей (state of the art, которые).
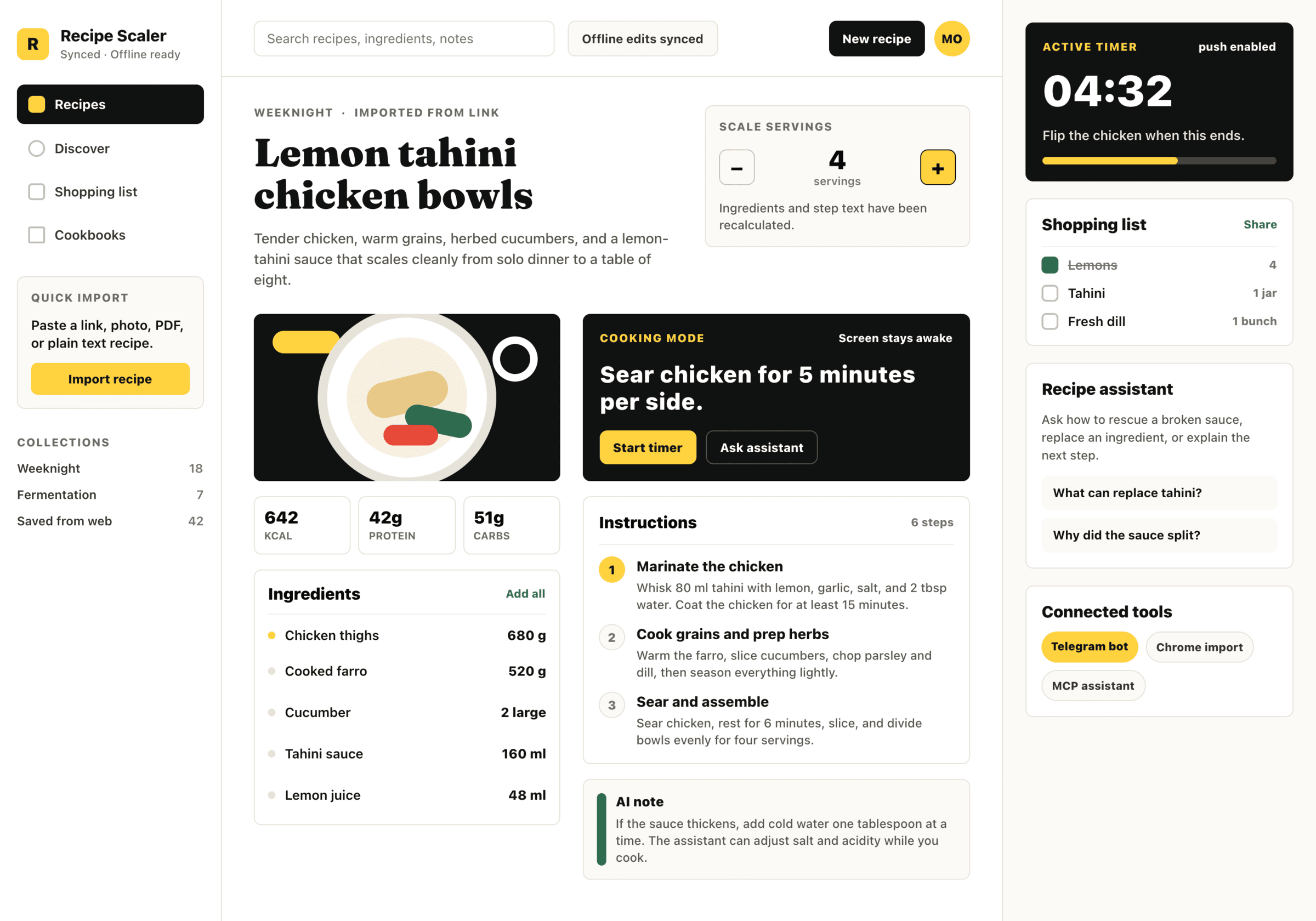
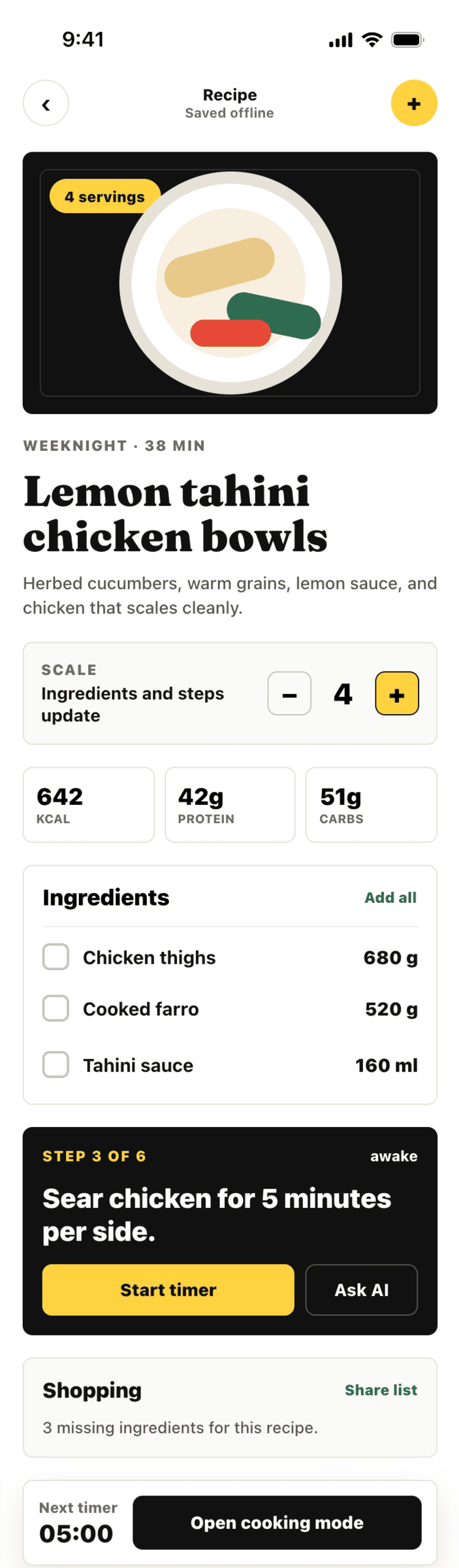
Codex + GPT 5.4, xhigh
Удивительно, что мне этот вариант нравится даже больше, чем у ГПТ 5.5.
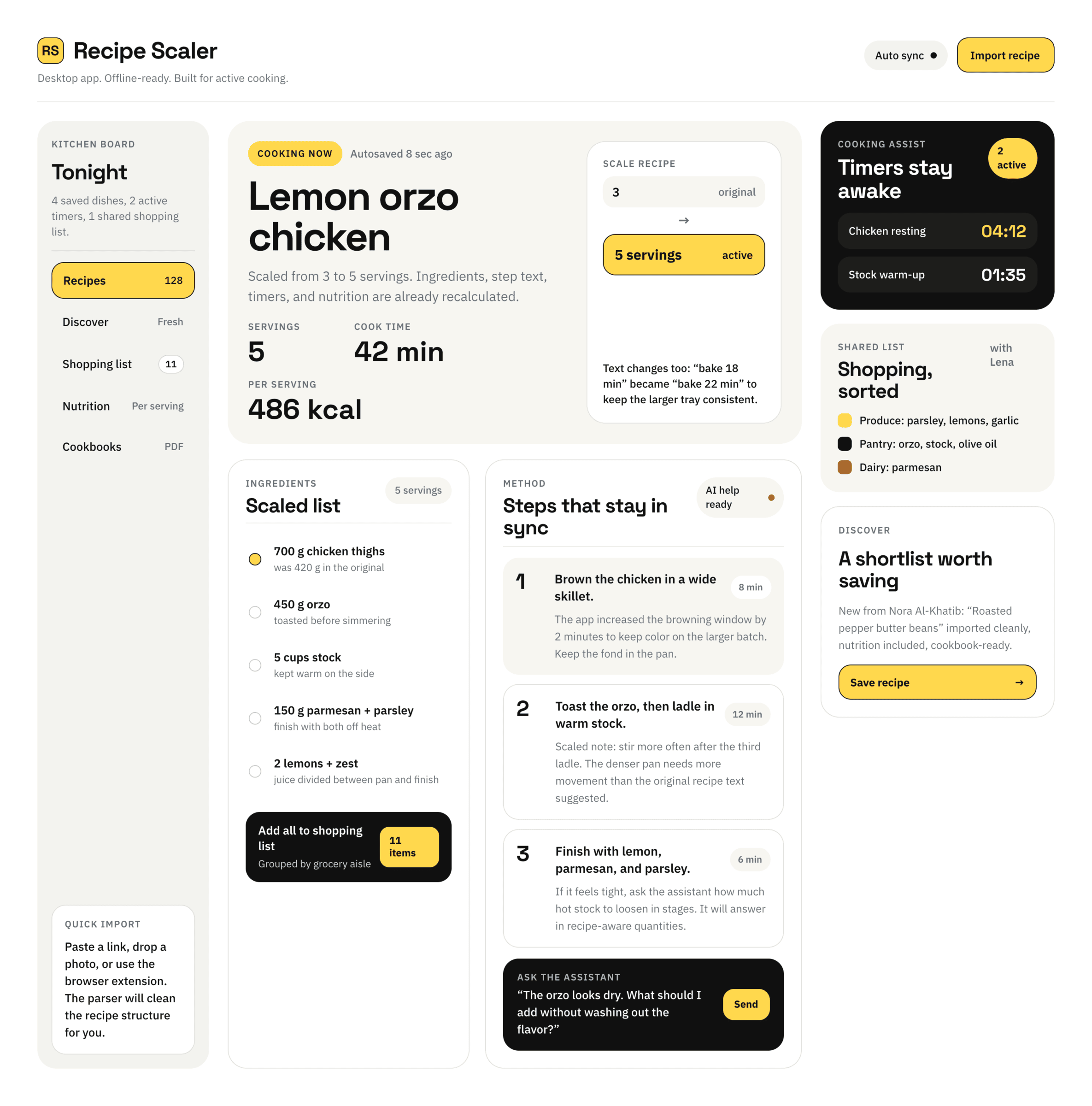
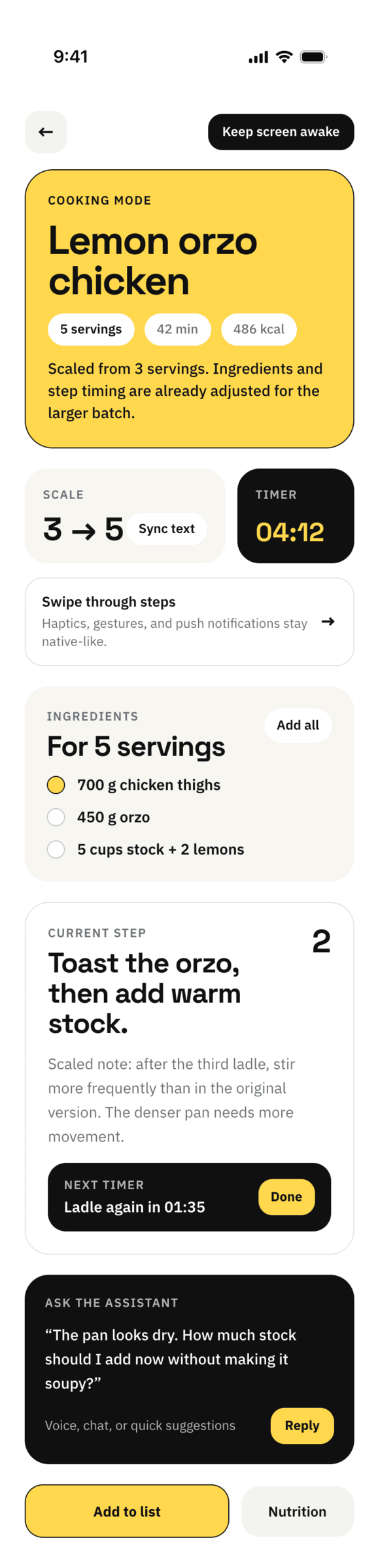

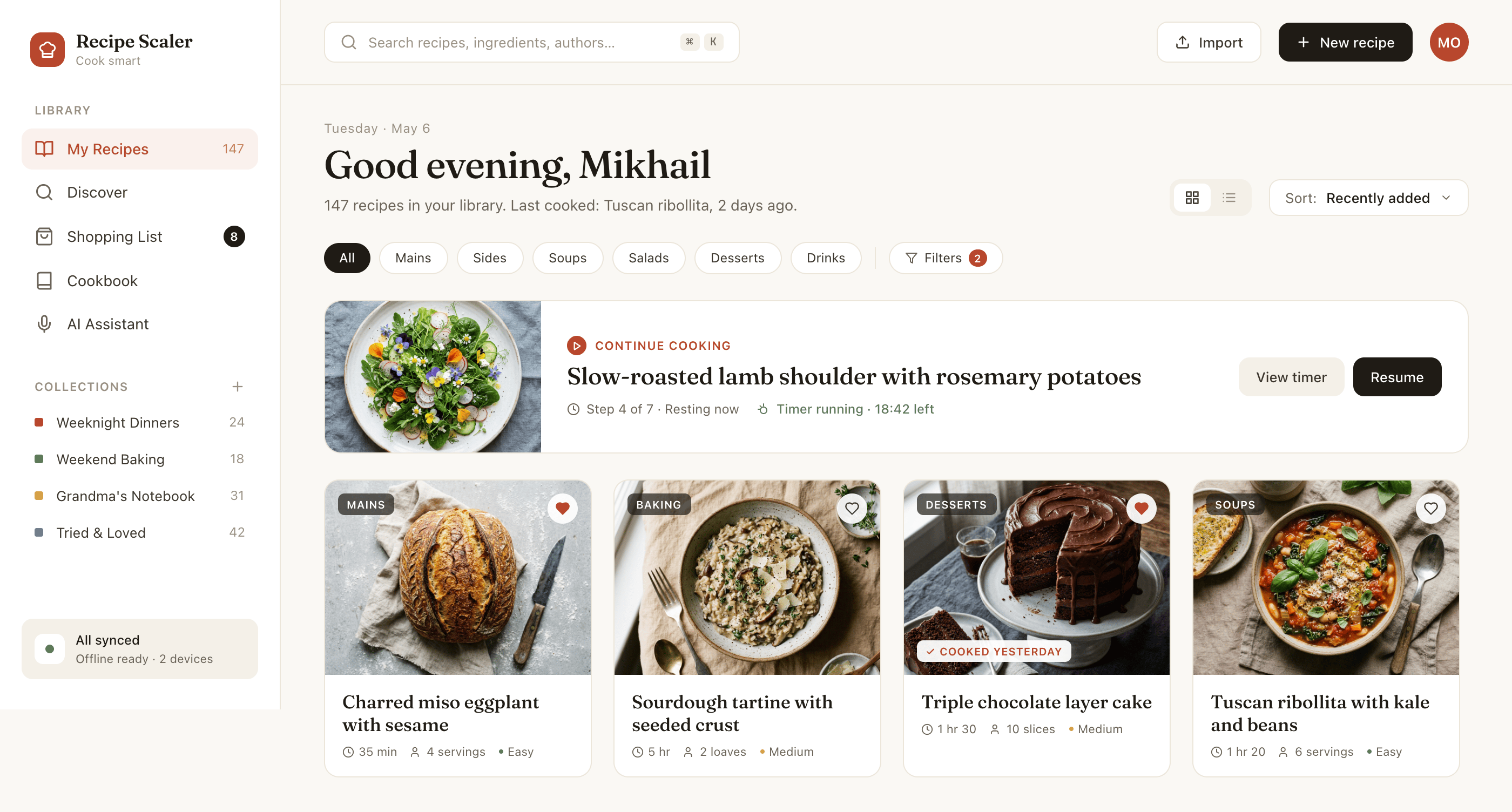
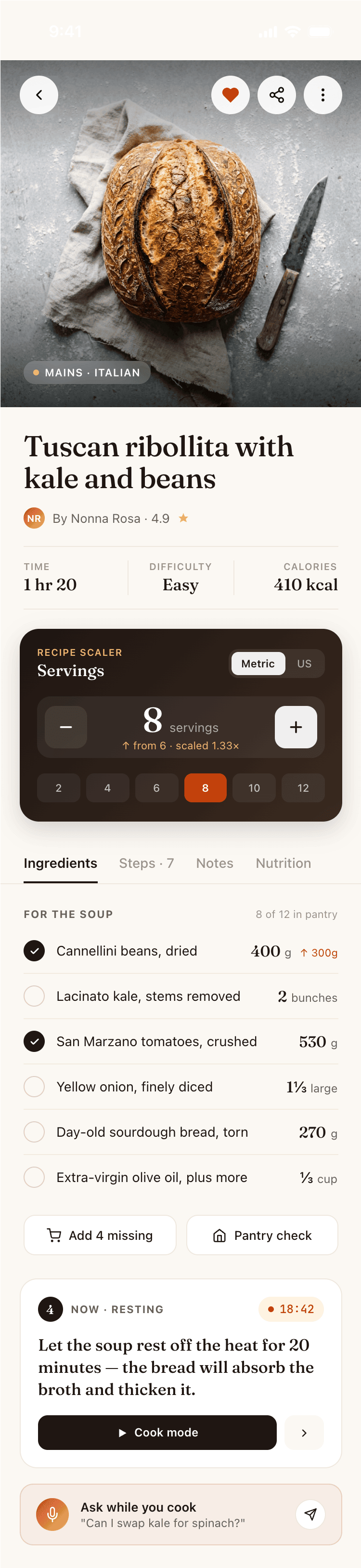
Cursor + Auto
Поразительно хороший результат для Авто-режима. Не знаю кто делал, может быть общую задачу делал как раз Опус на лоу-ризонинге, а реализация была каким-то ГПТ-нано. Выбор стиля как будто от Опуса.
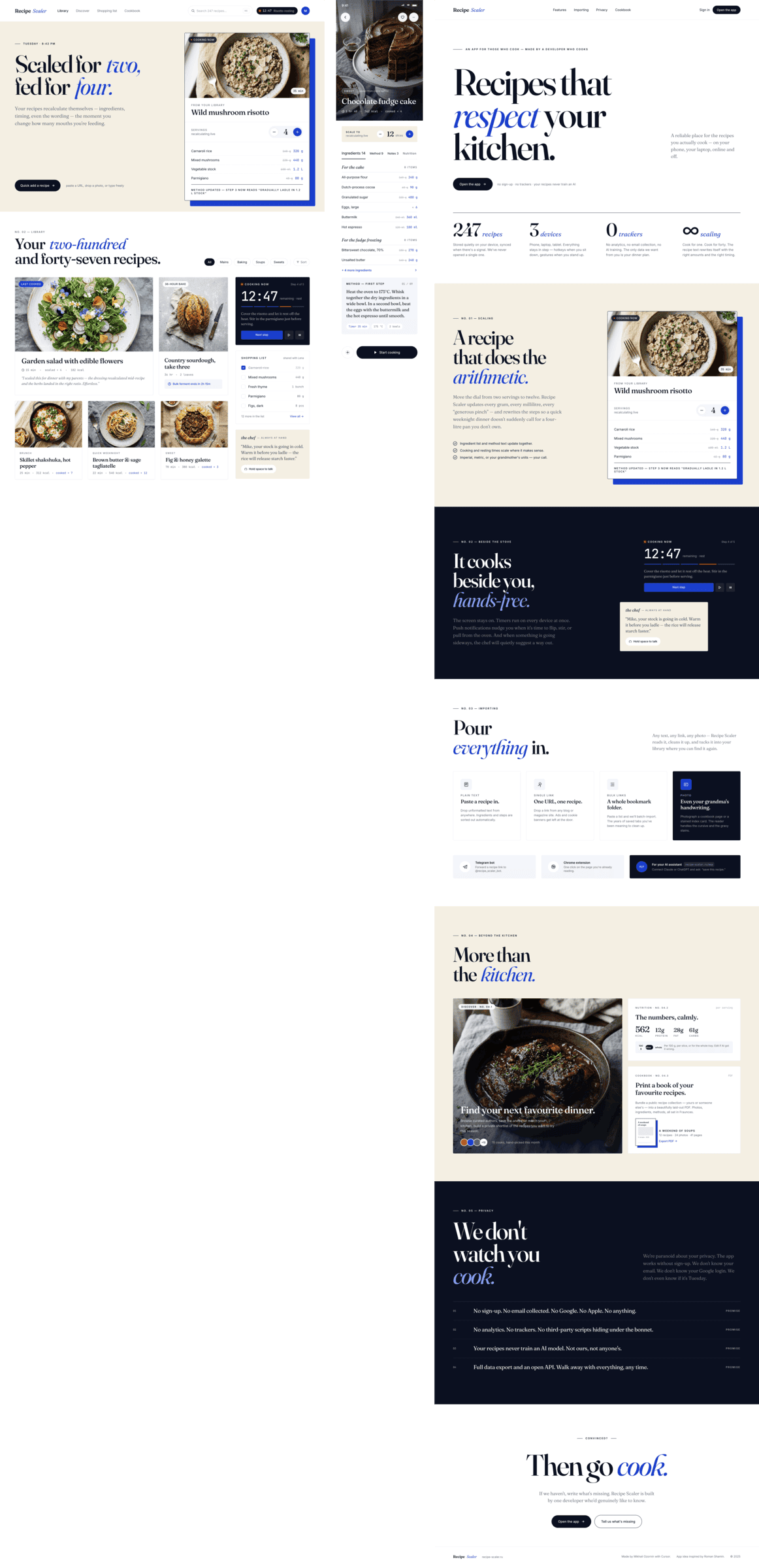
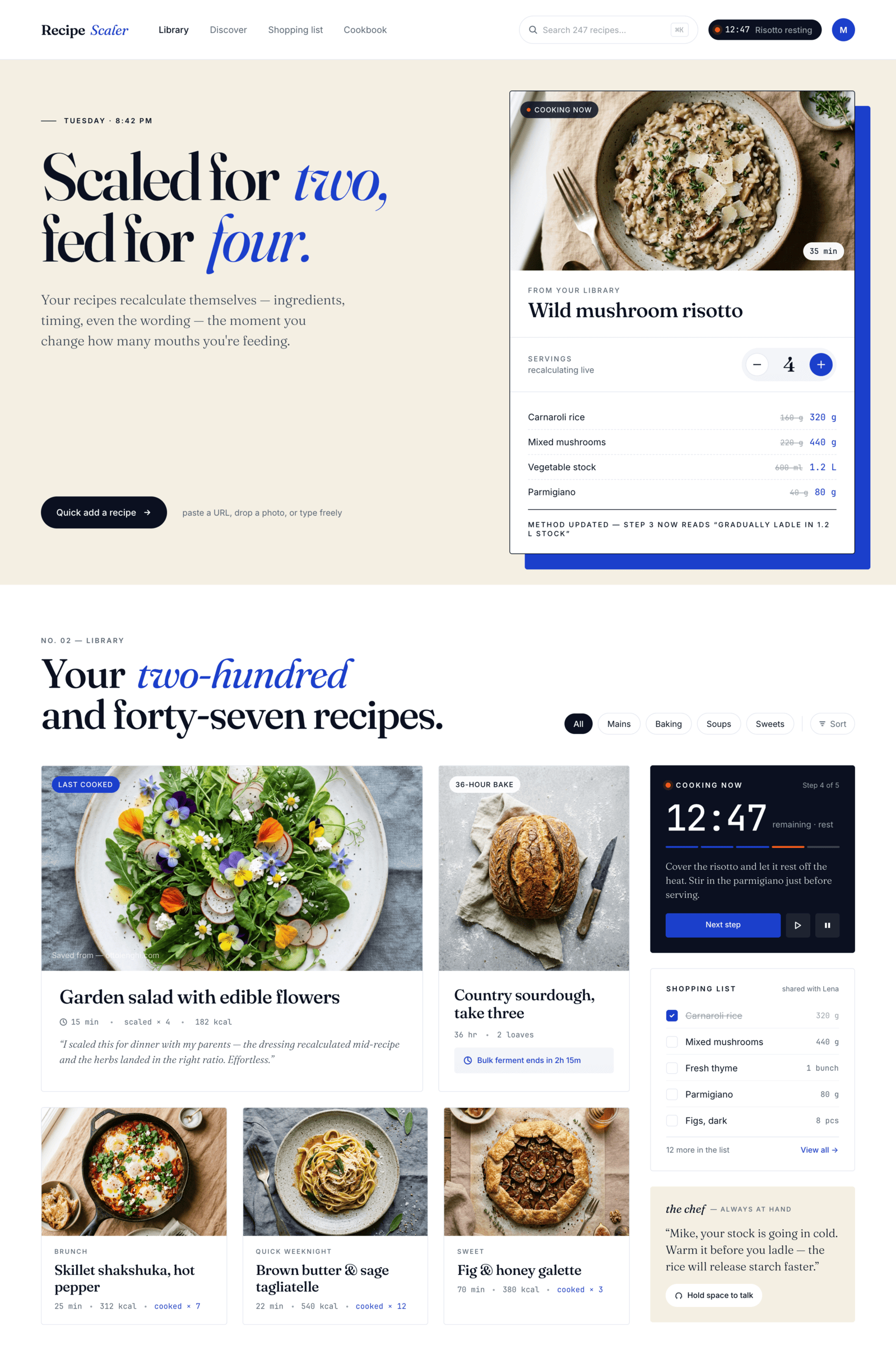
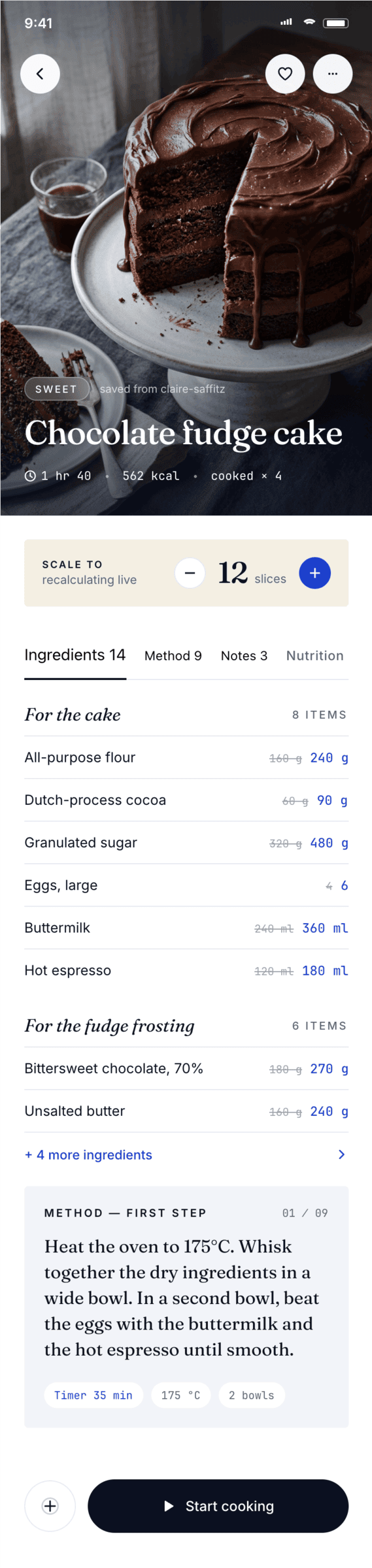
Cursor + Opus 4.7
Вдвое дороже, чем Опус 4.7 у Кило. Очень много проверяет себя, скриншотил буквально каждый этап и каждый блок. Результат чуть лучше.
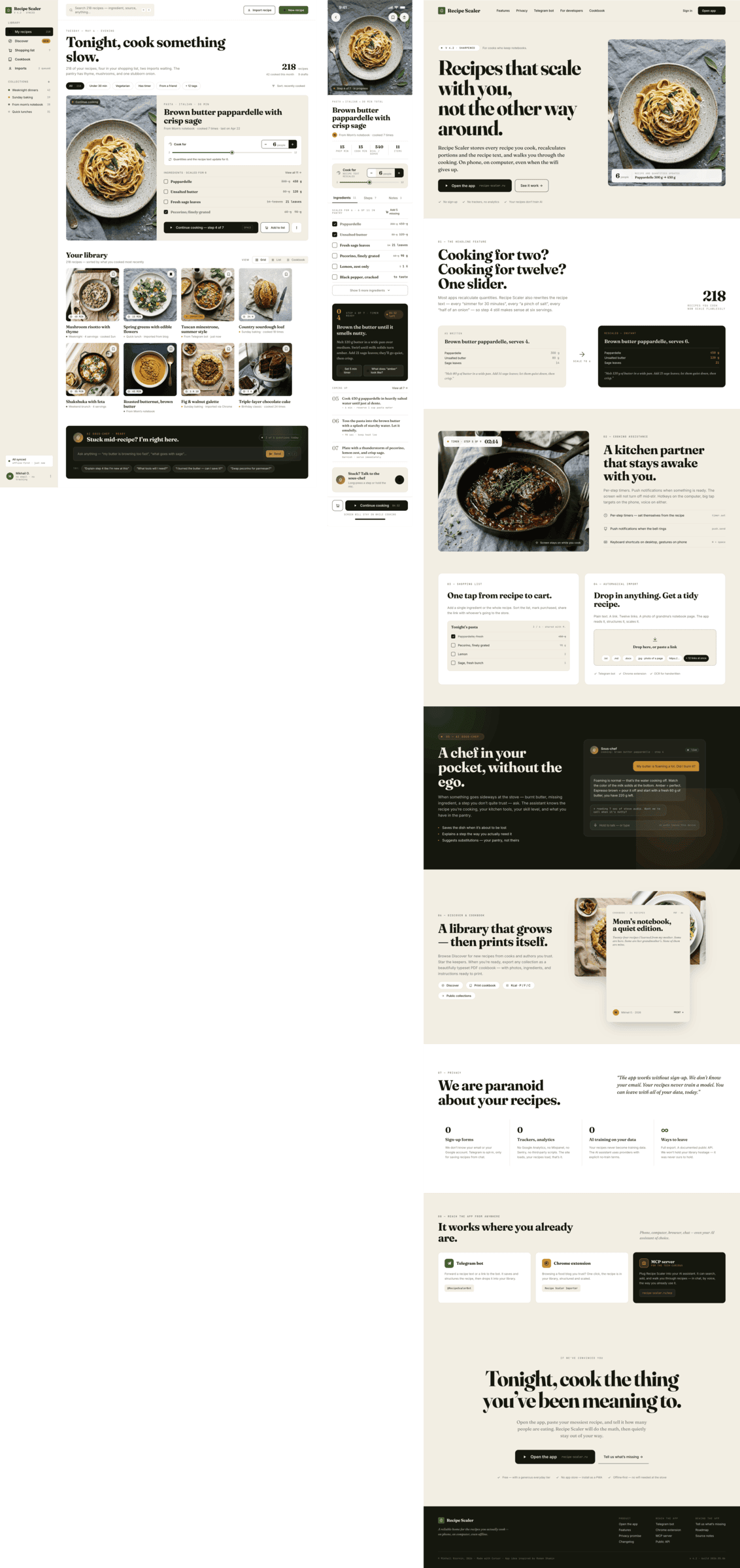

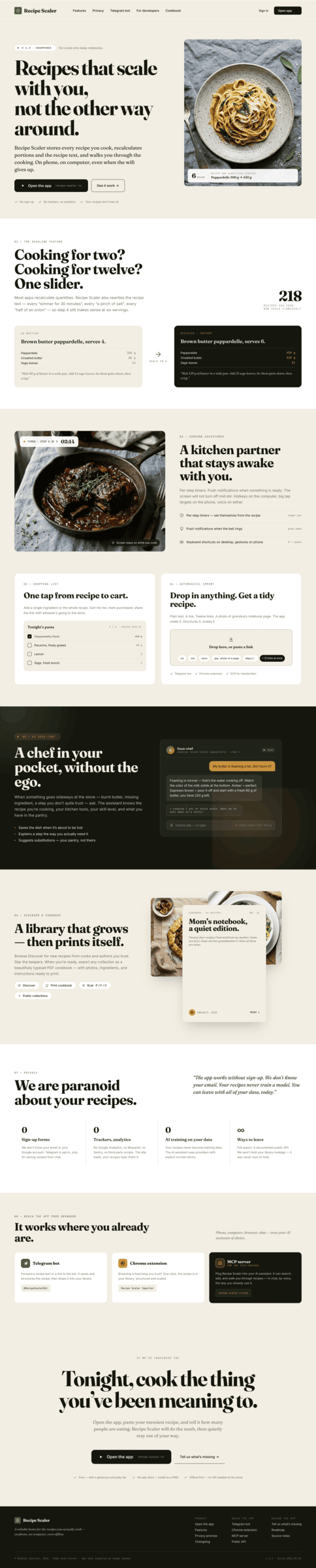
Cursor + GPT 5.4, xhigh
Агент другой, модель узнается, это все тот же ГПТ 5.4, что был в Кодексе. Но тут как будто чуть лучше вышло.
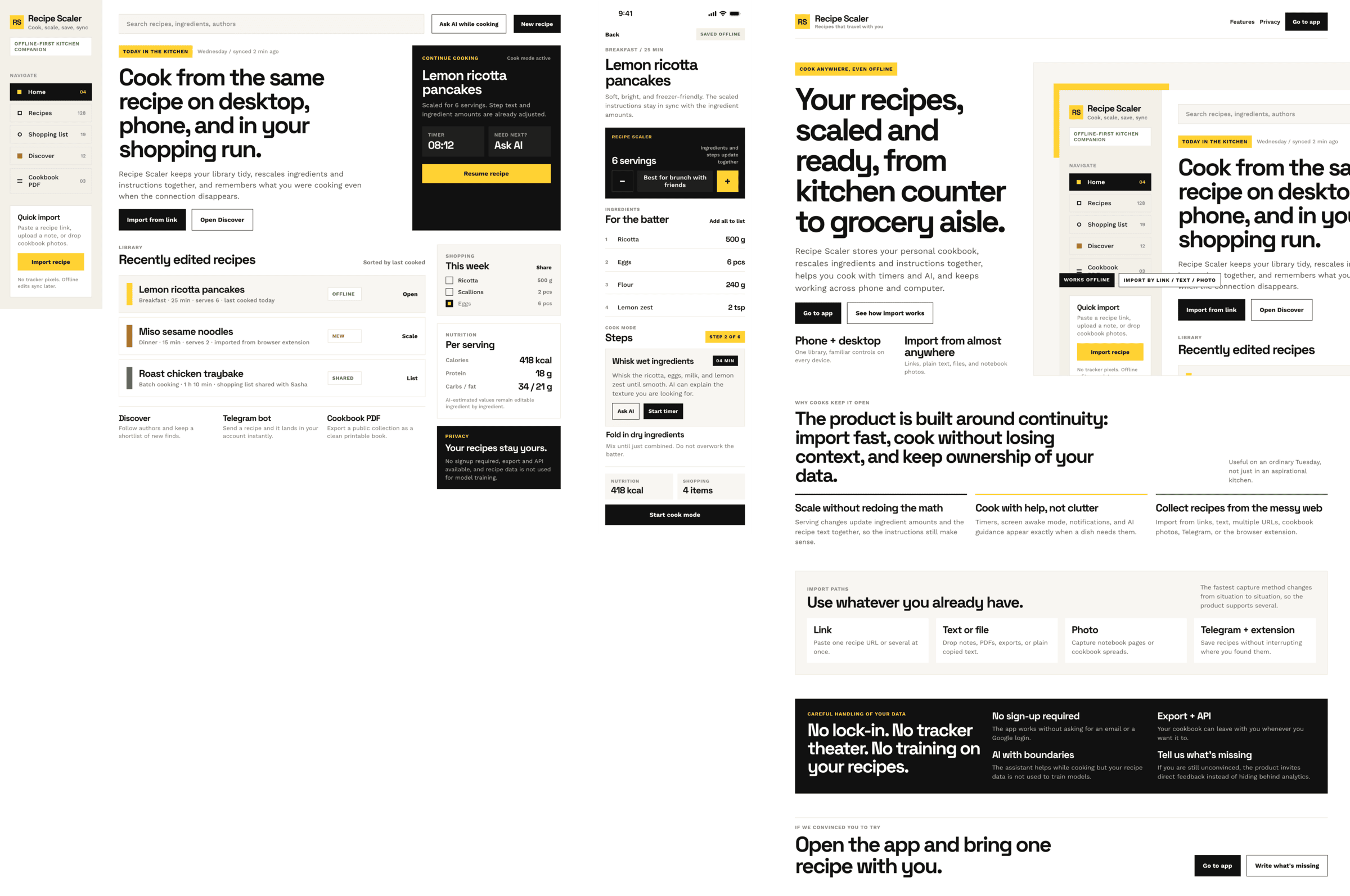
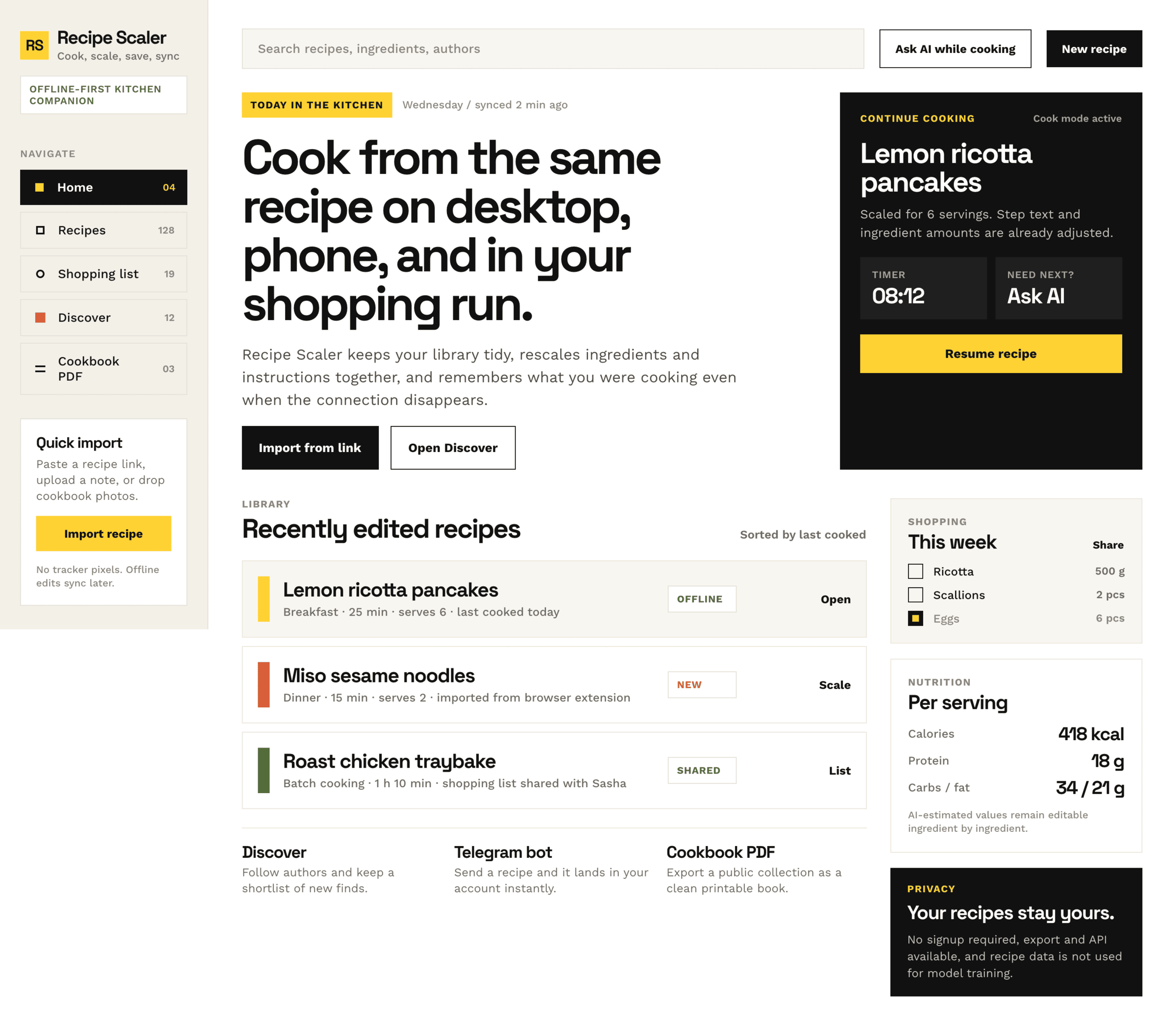
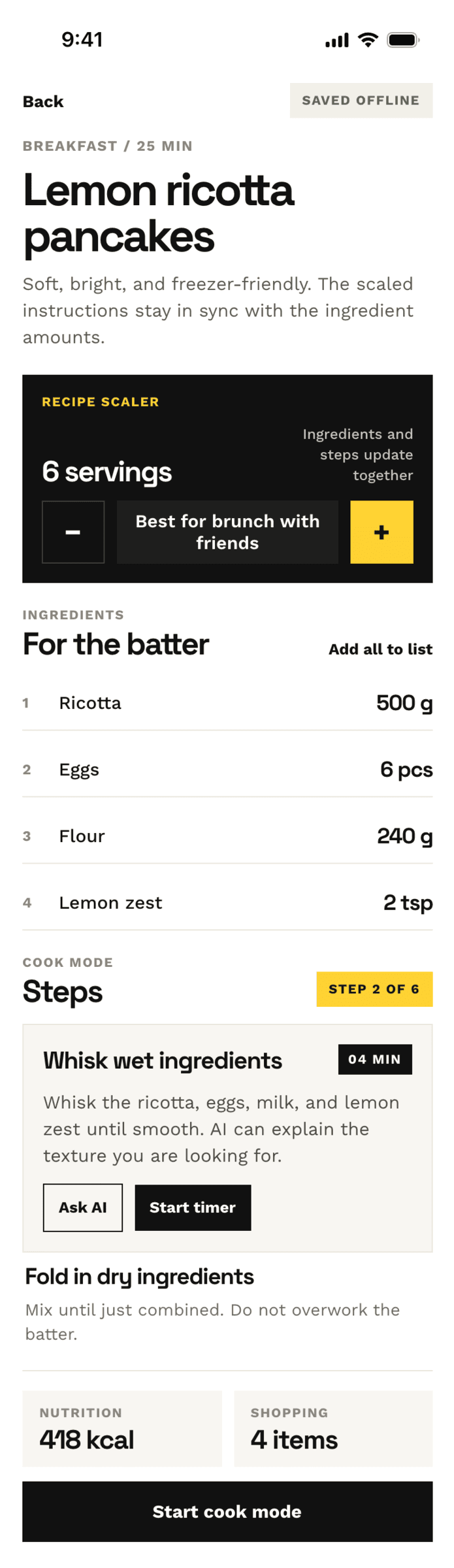
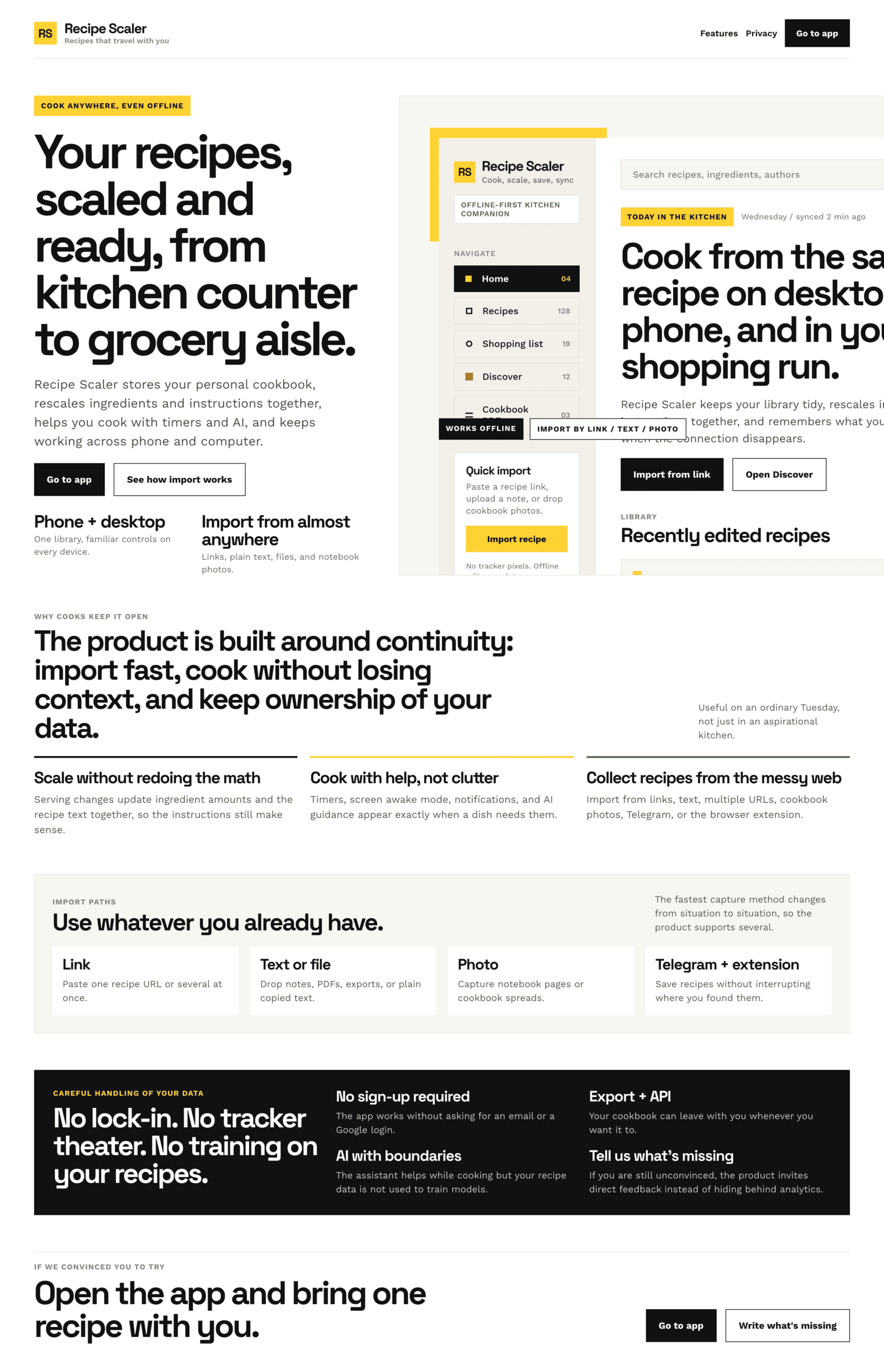
Cursor + Gemini 3.1 Pro
Результат сопоставимый с Гемини в Антигравити. Очень плохо для модели такого уровня.
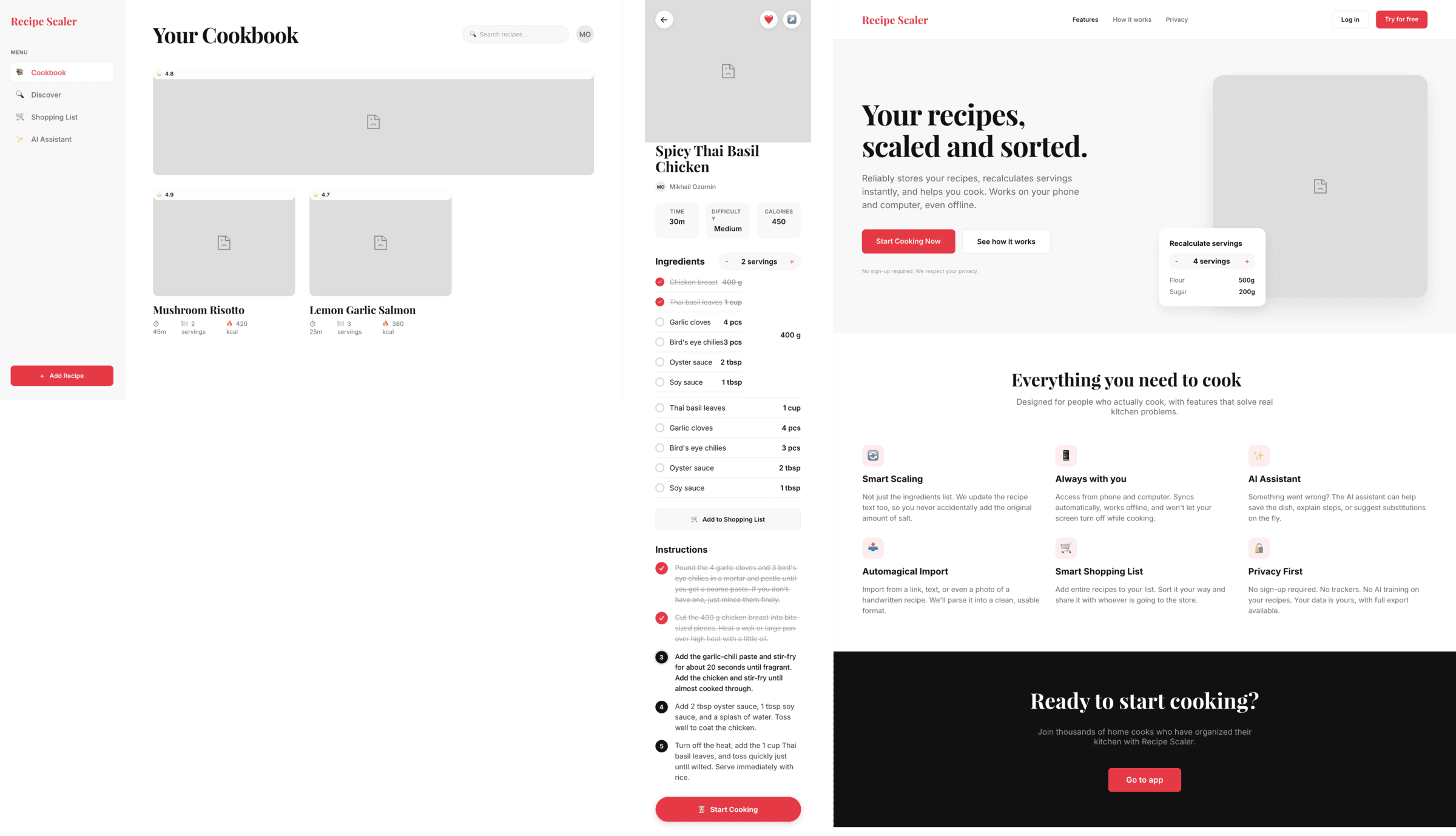

Cursor + Grok 4.3
От Грока впечатления смешанные. Мобилка в целом норм, на уровне других. Промо хуже чем собраться. Я думал будет дешевле, Грок 4.1 был очень классный именно за счет того, что стоил ну очень мало.
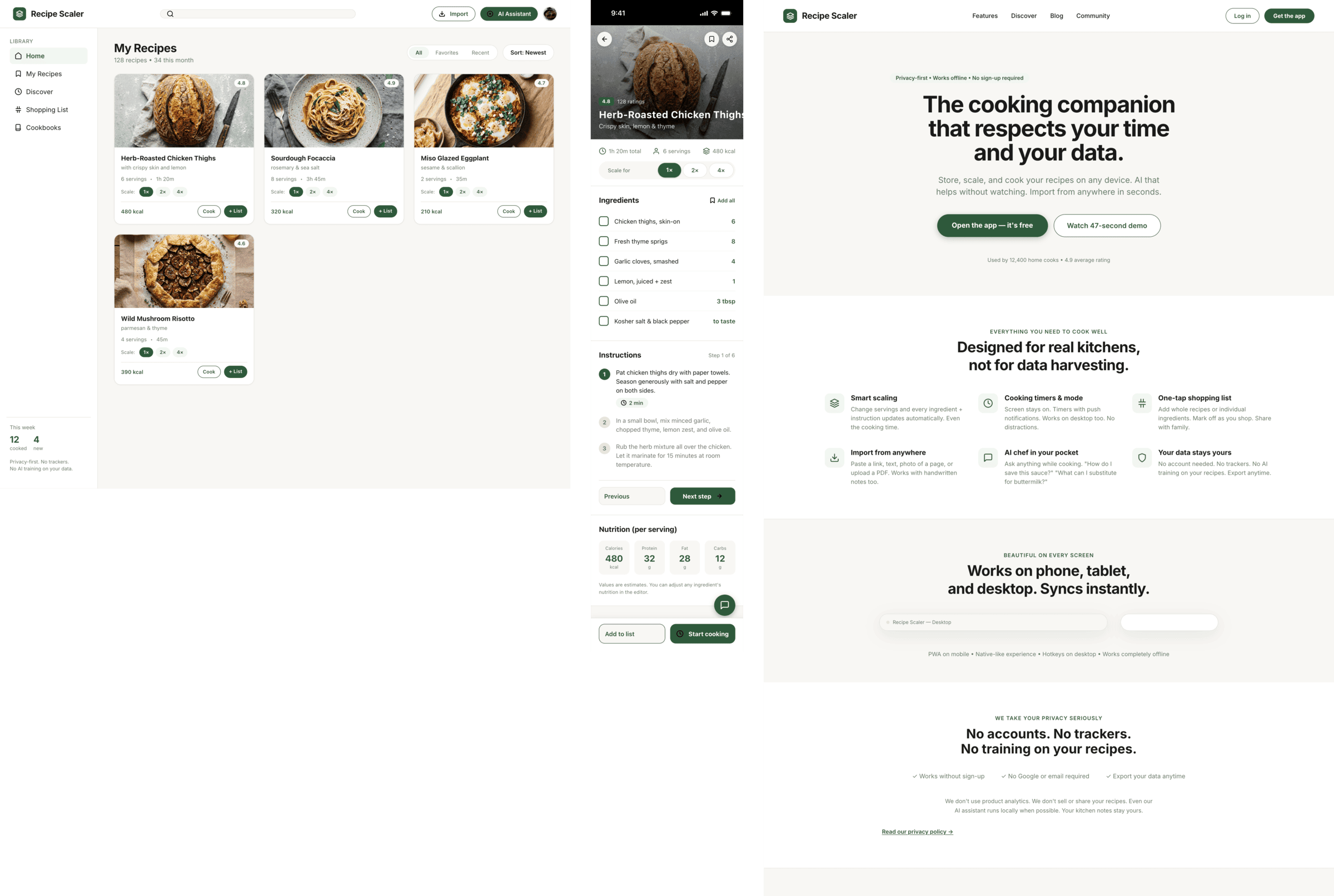
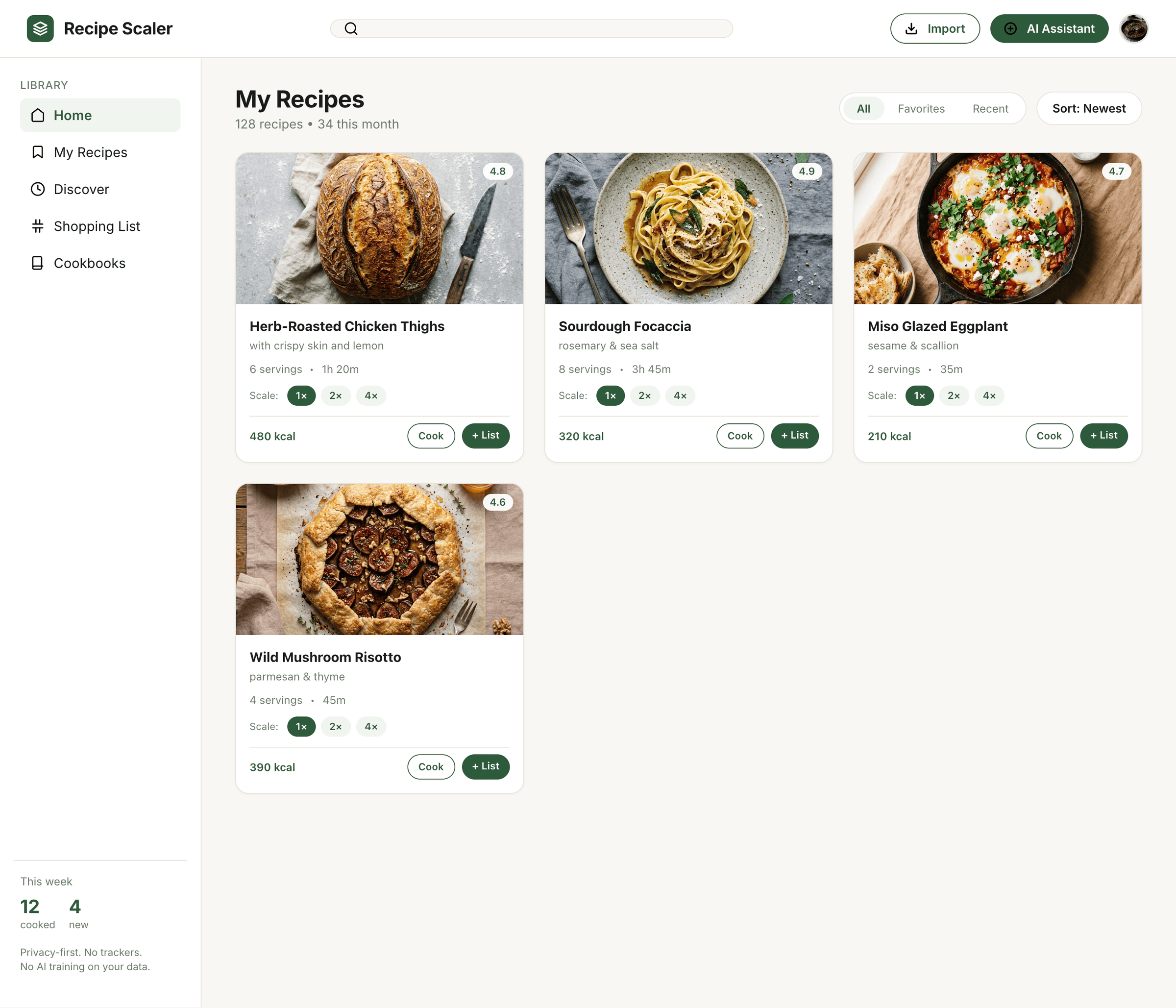
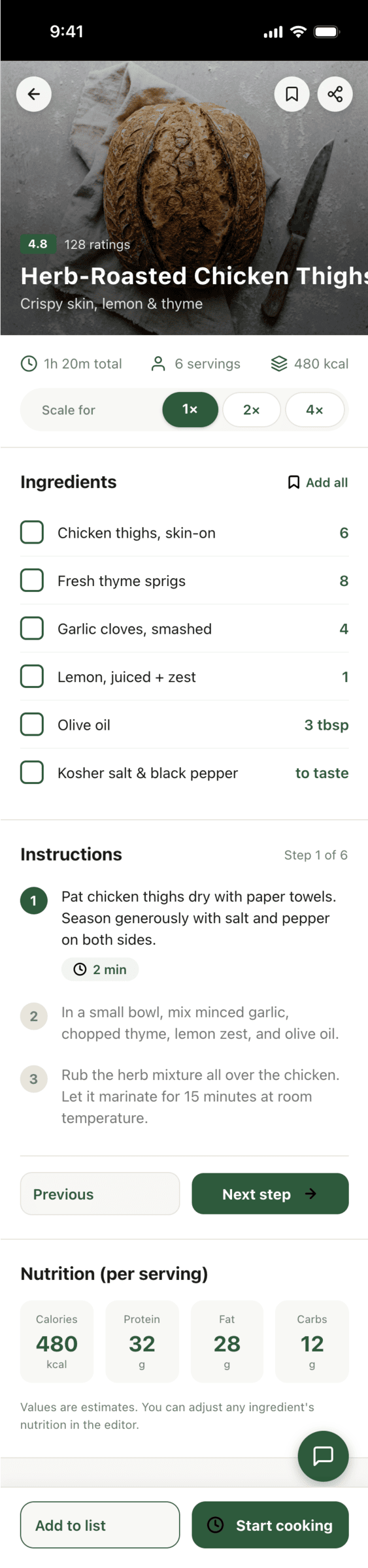
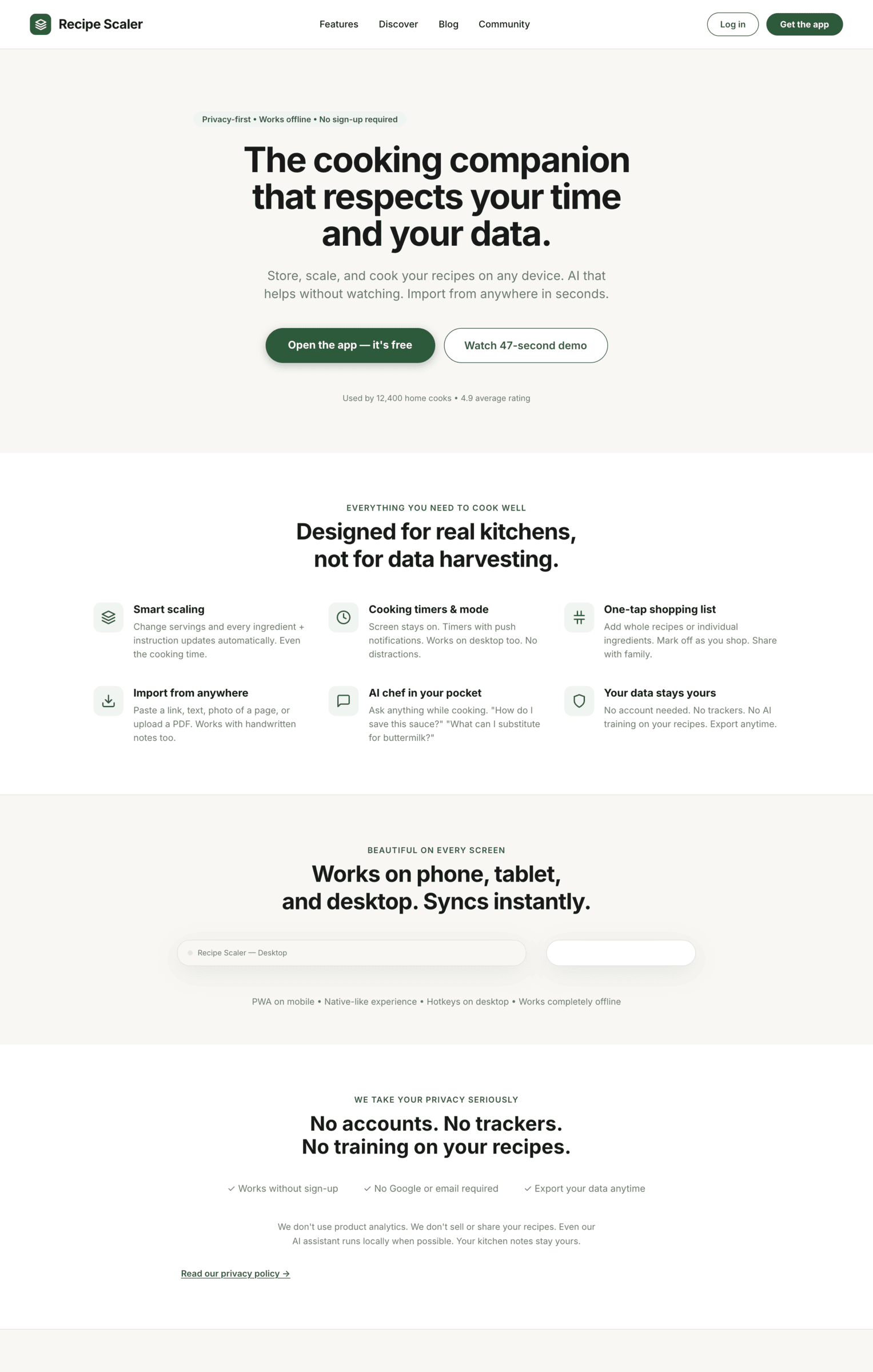
Cursor + GLM 5.1 (z.ai coding plan)
ГЛМ в Курсоре почему-то не смог справиться с тулами.
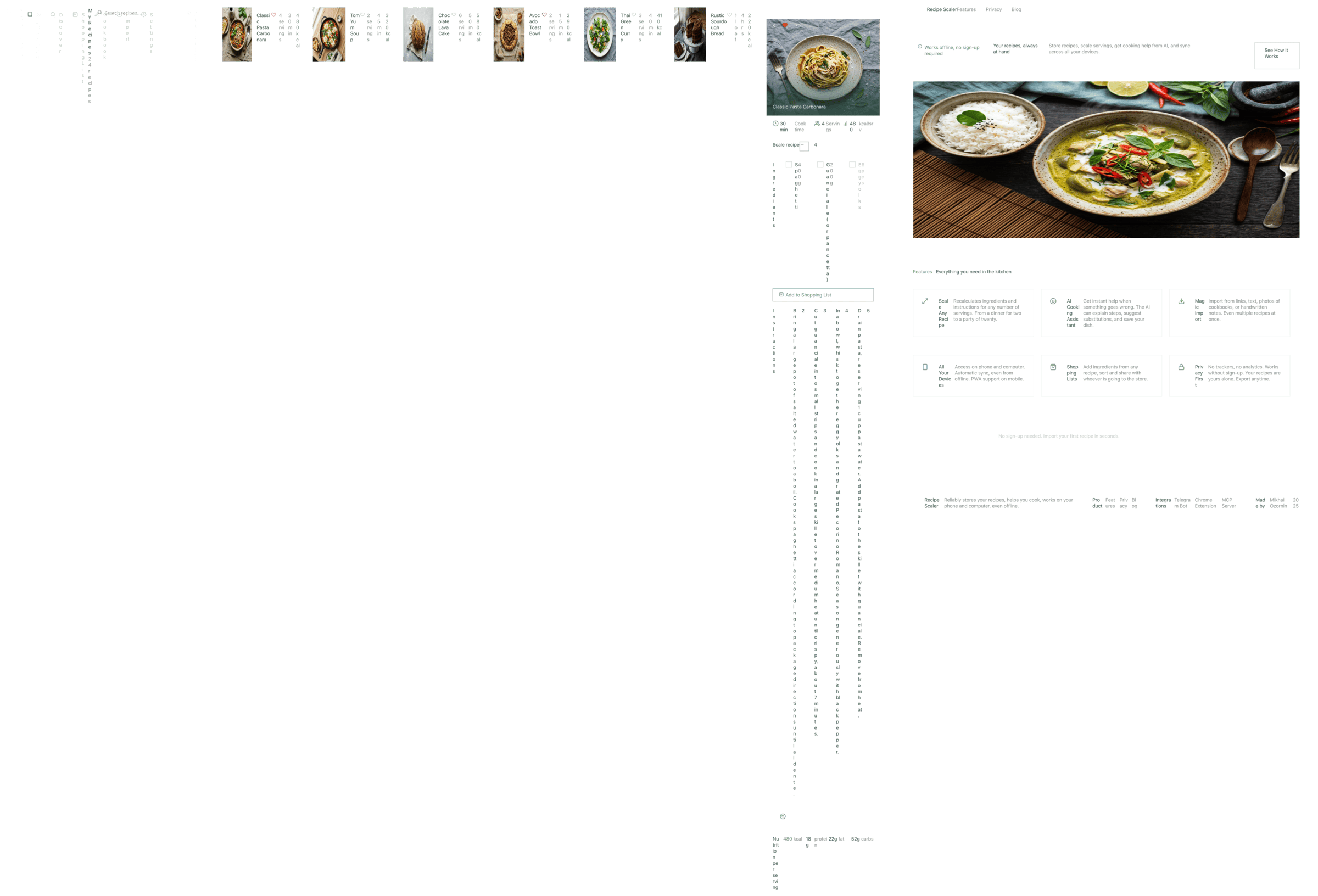


Cursor + Composer 2
Очень примитивно, но и зато очень дешево. Не соответствует тому уровню, что Курсор заявляет о своей модели, конечно. Но они честно говорили, что делают модель для кода в первую очередь.
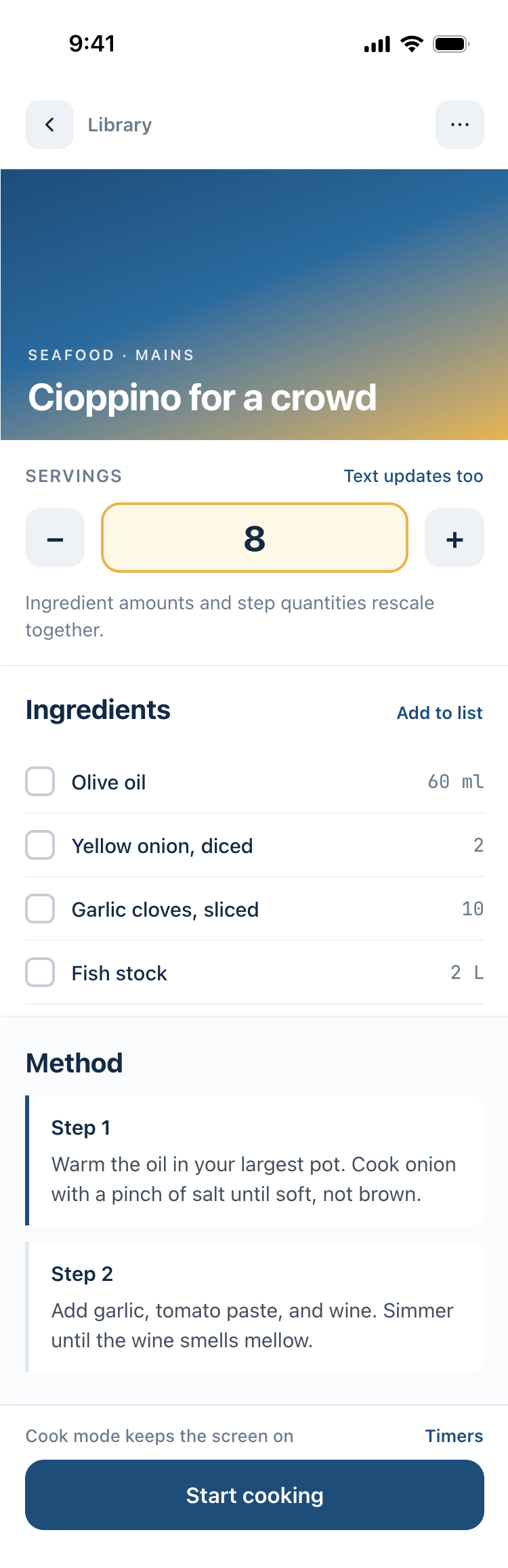
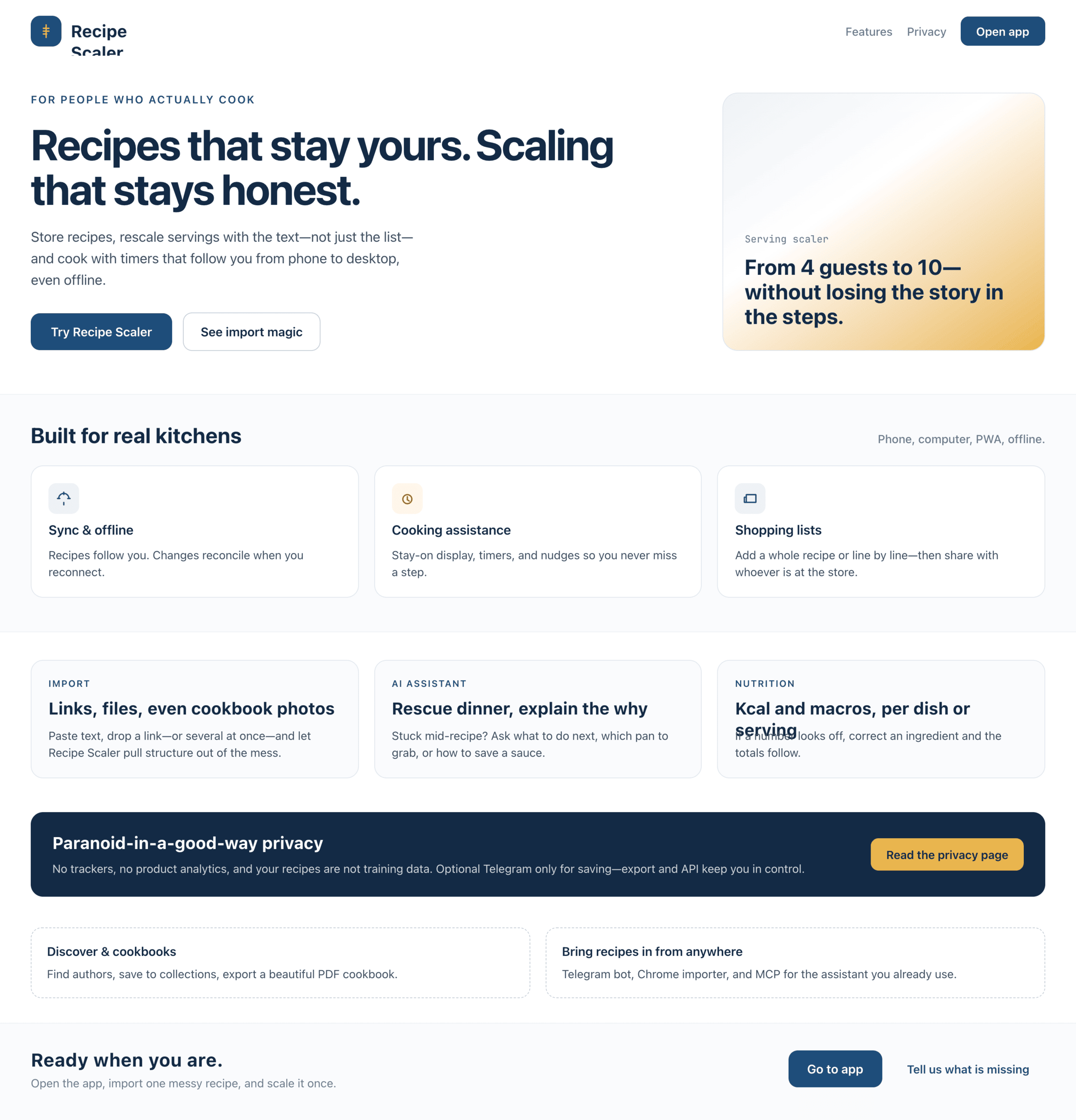
Cursor + Composer 2.5
Сопоставим по стоимости с Composer 2, качество подросло, но все еще сильно не очень.
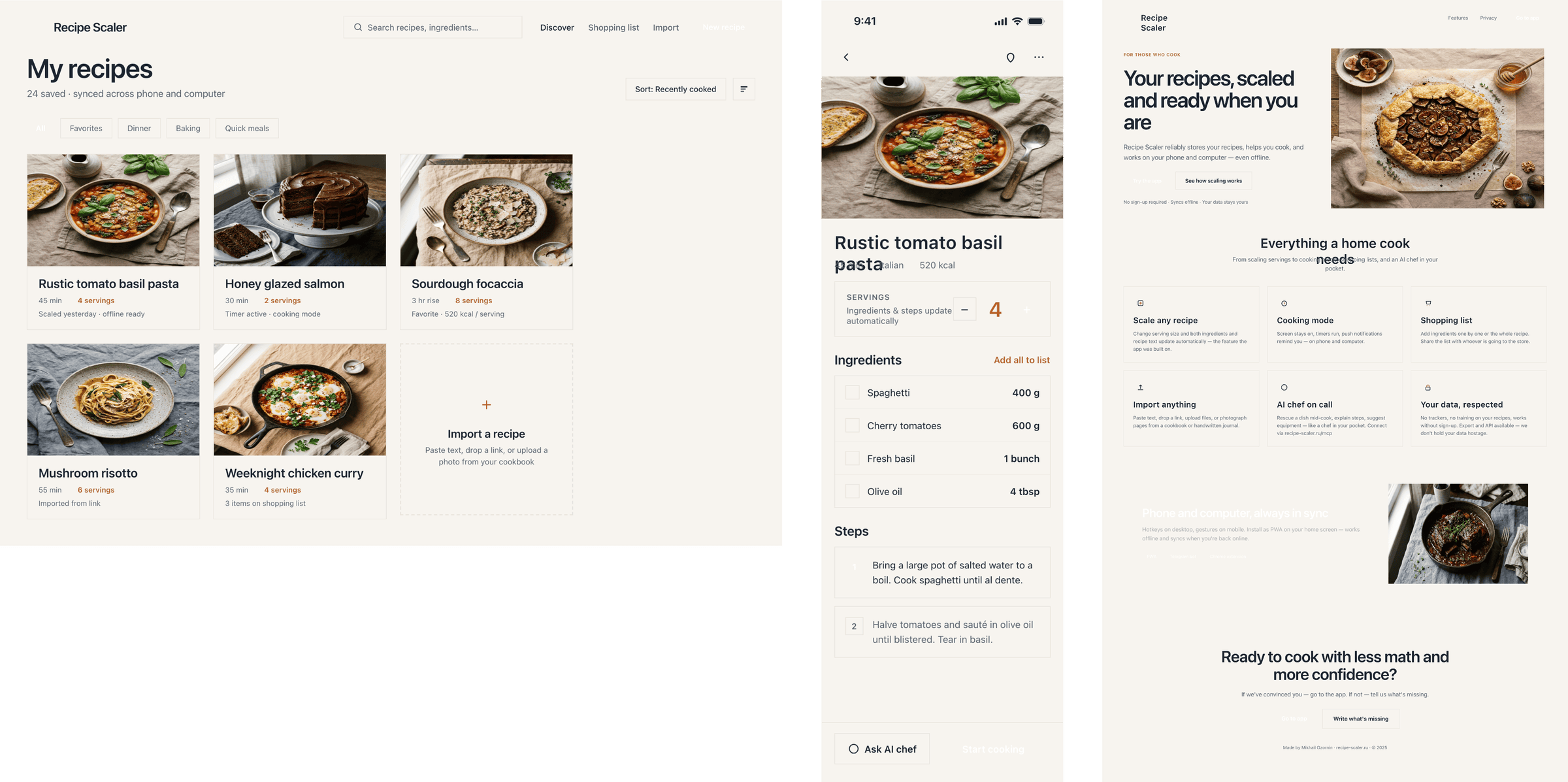
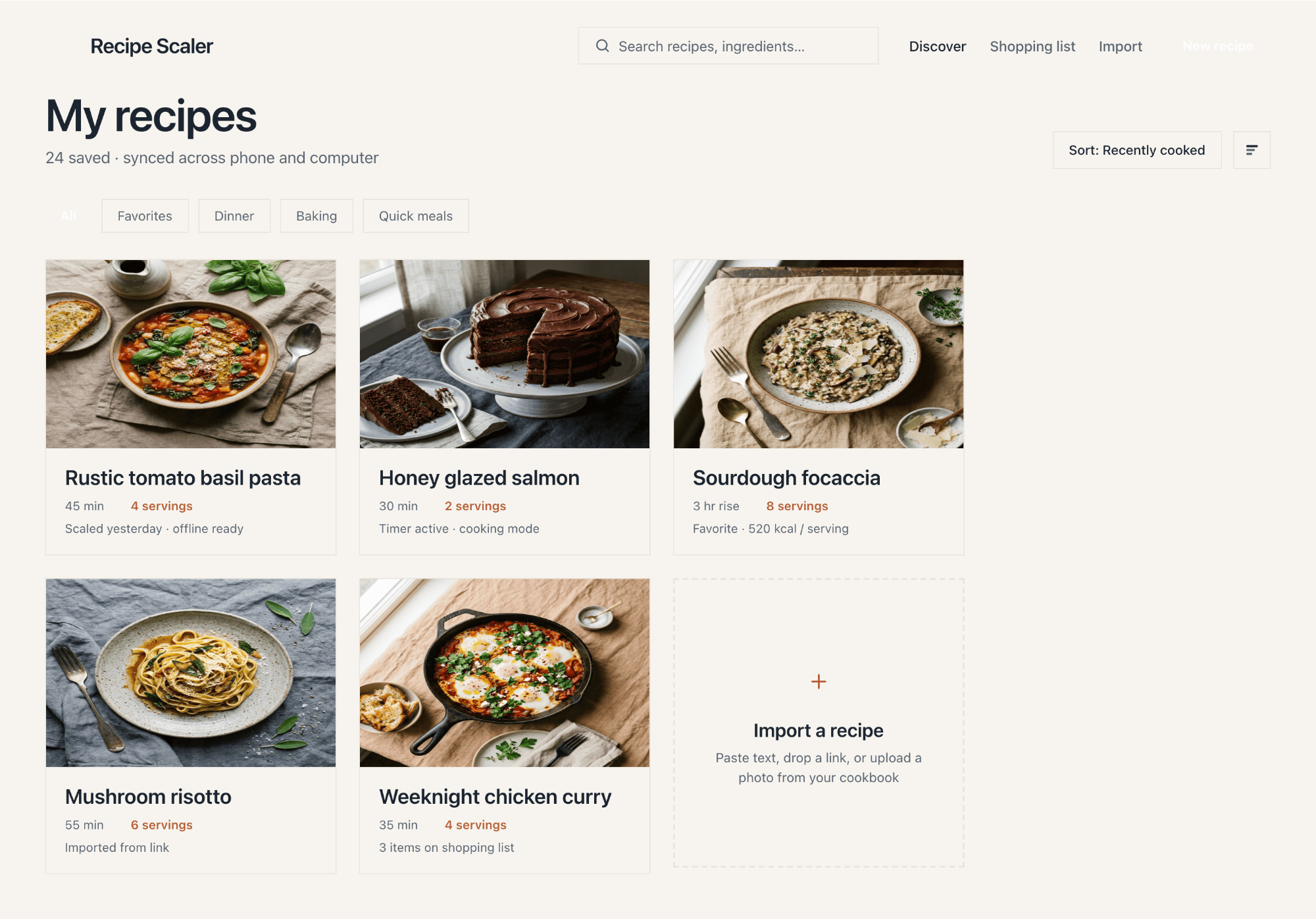
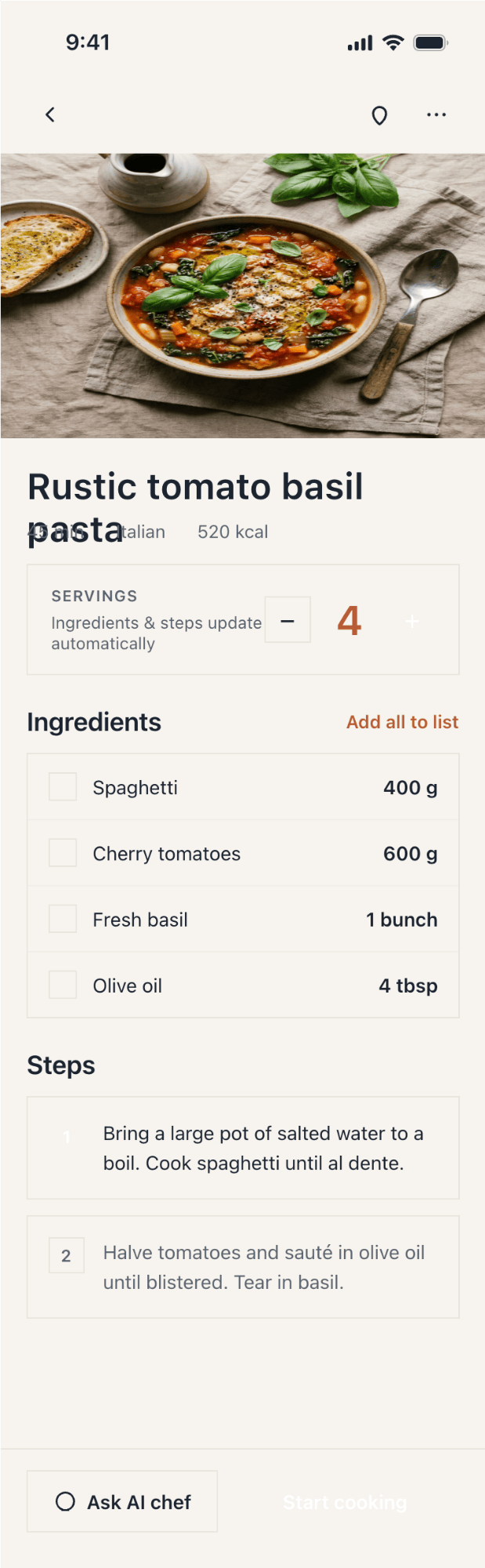
Cursor + MiMo V2.5 Pro
Включённая модель Курсора; в подписке очень дёшево, в дизайне слабо.
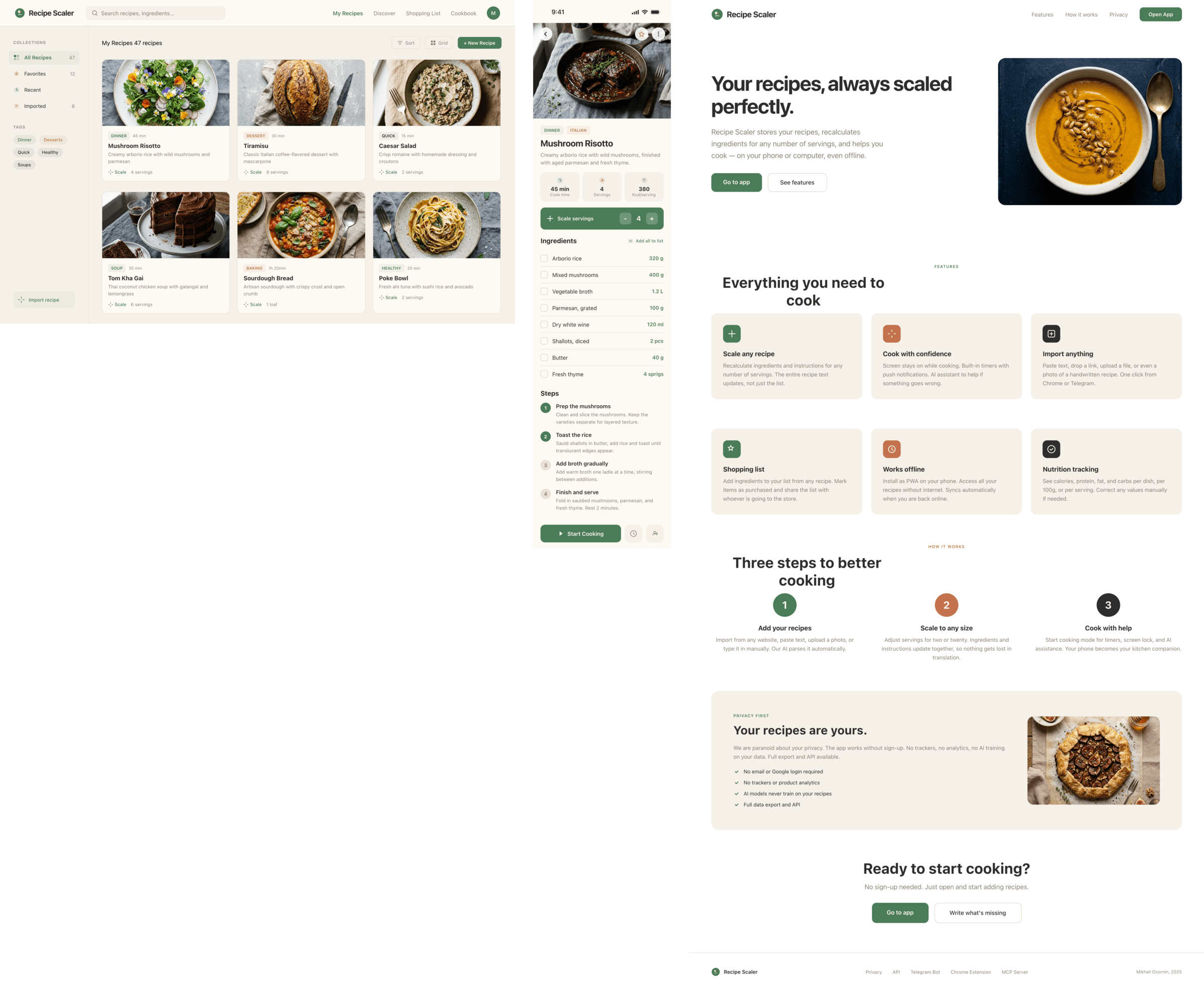
Source Craft + Default
Вроде недорого, но пользоваться смысла нет, нейрослописный нейрослоп.
Source Craft + Default Thinking
Как будто Default и Default Thinkign модели в Яндекс Сорс Крафте не просто разные режимы одной модели, а разные модели: слишком разный результат, у рисонинг модели даже хуже.
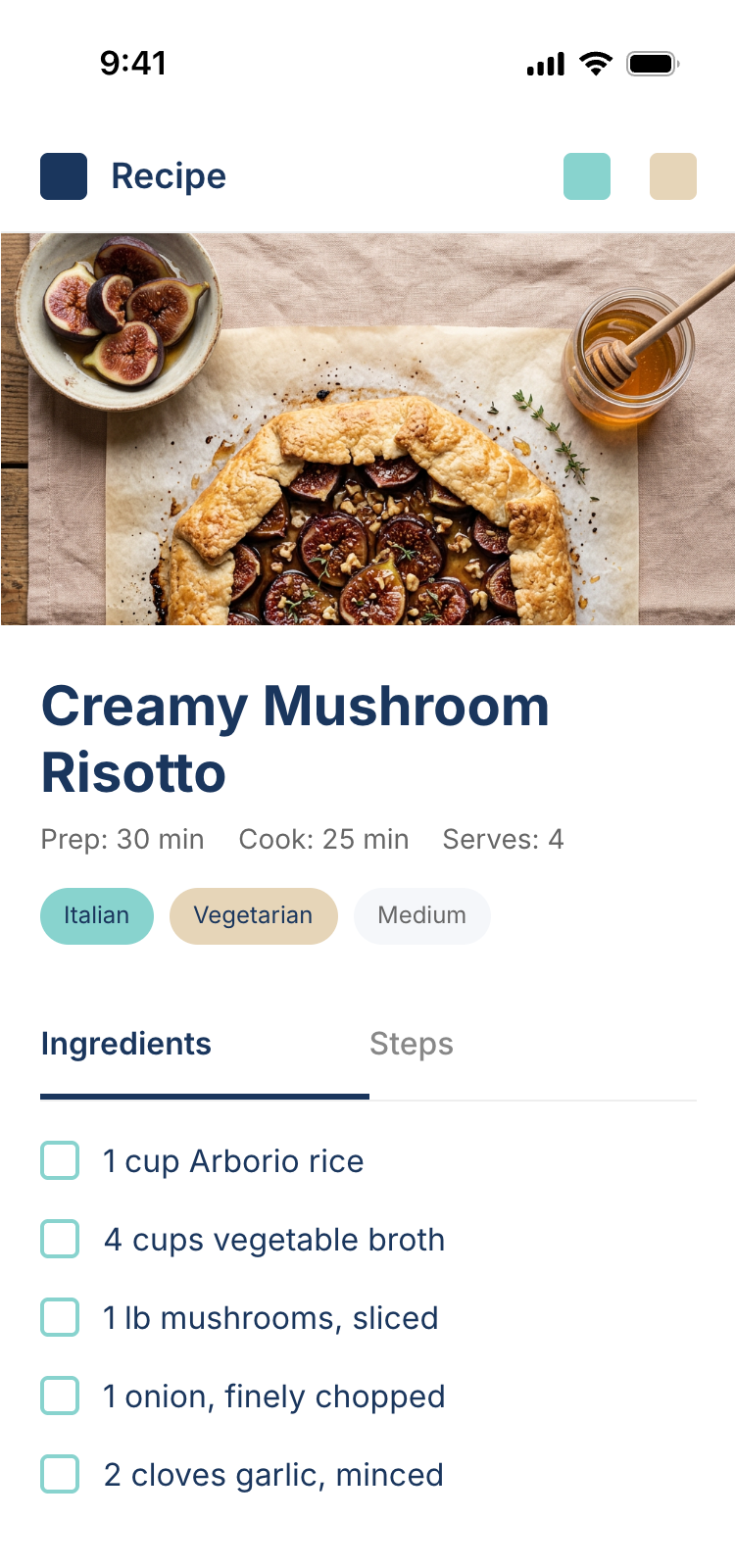
Kilo Code + Opus 4.7 (Kilo cloud)
Типичный Опус 4.7. Местами чисто, интересно, издалека дак прямо супер-пупер.
Kilo Code + Hy3 preview (Kilo cloud)
Самая модная опенсорс-модель на опенроутере. Очень так себе.
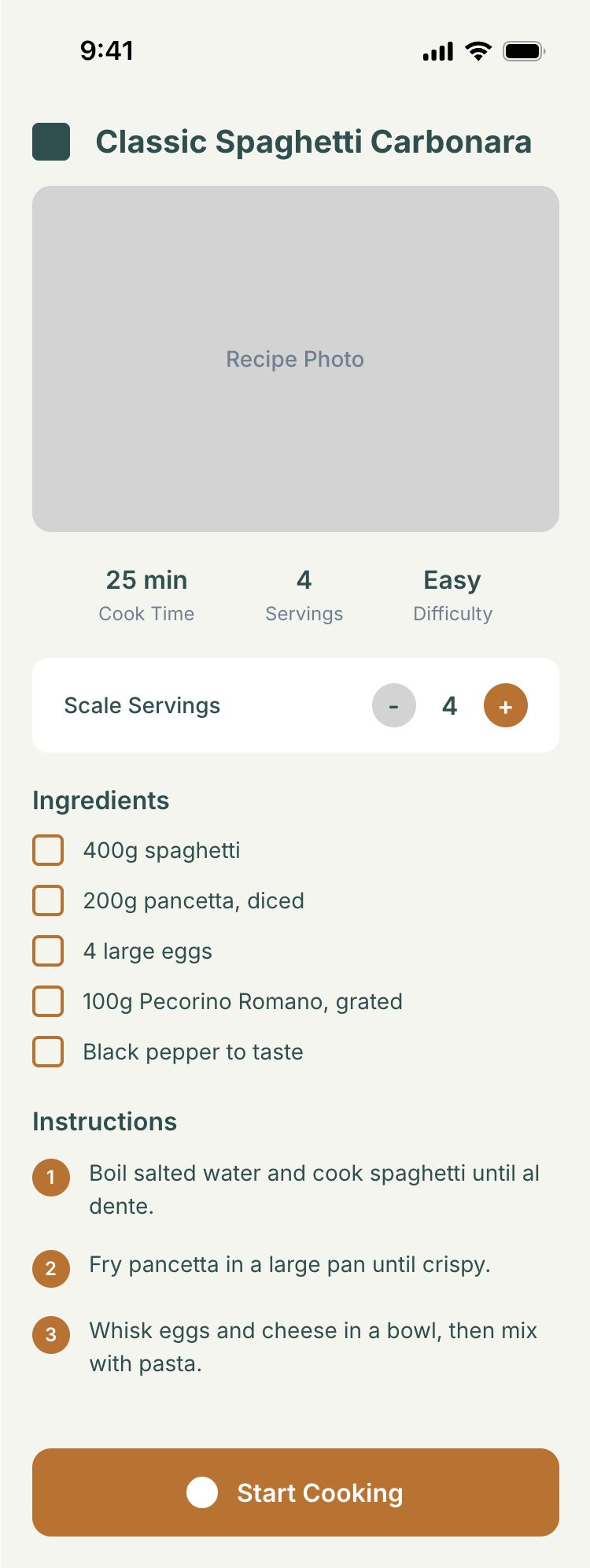
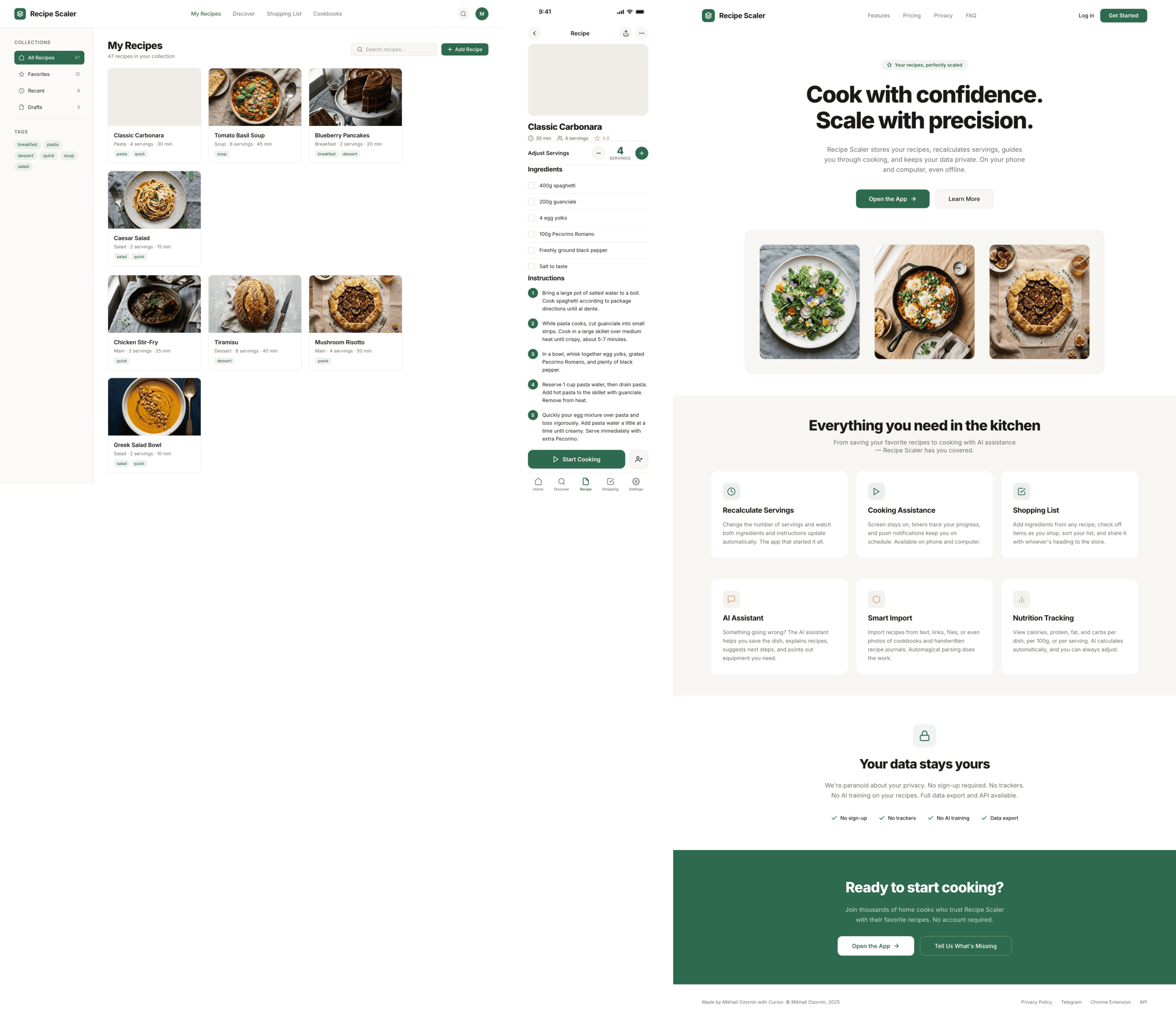
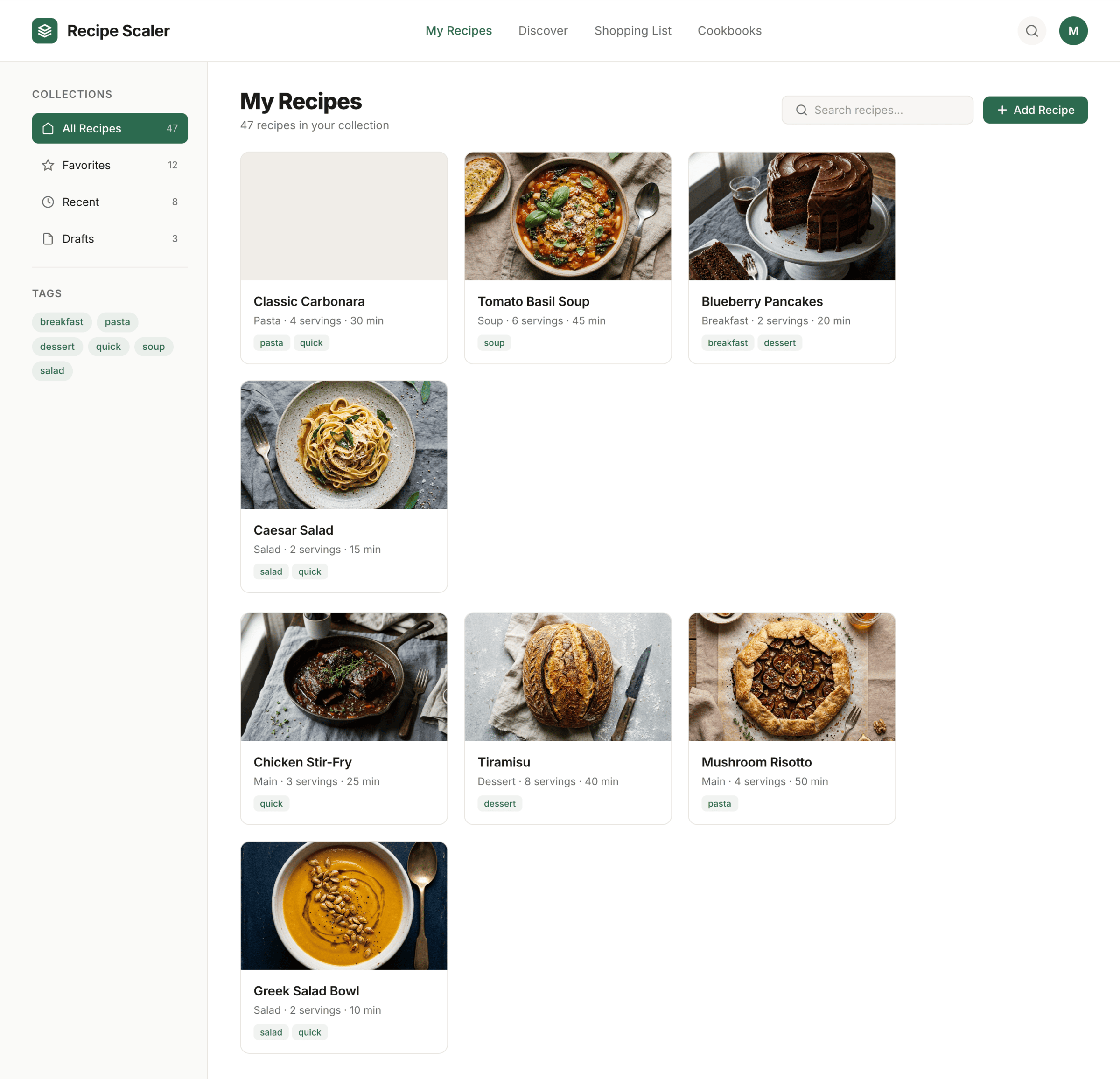
Kilo Code + Qwen 3.6 Max Preview (Kilo cloud)
В целом Квен для меня справился неплохо. Туповато, по крепко вполне. В промо просел как все. 1/30 от Опуса по цене.
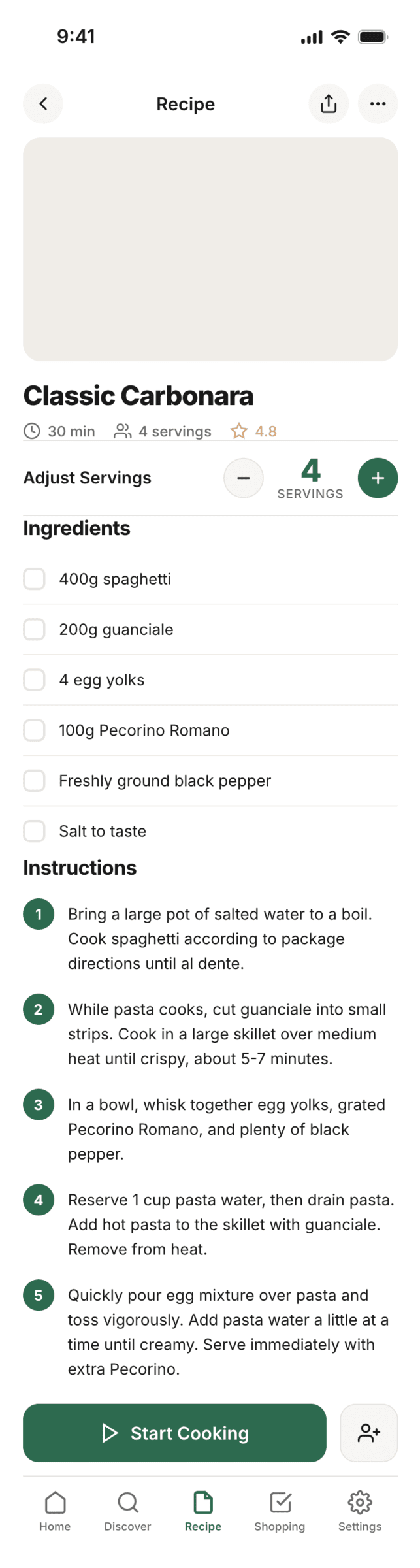
Kilo Code + Qwen 3.5 397
Не справился с тулами.



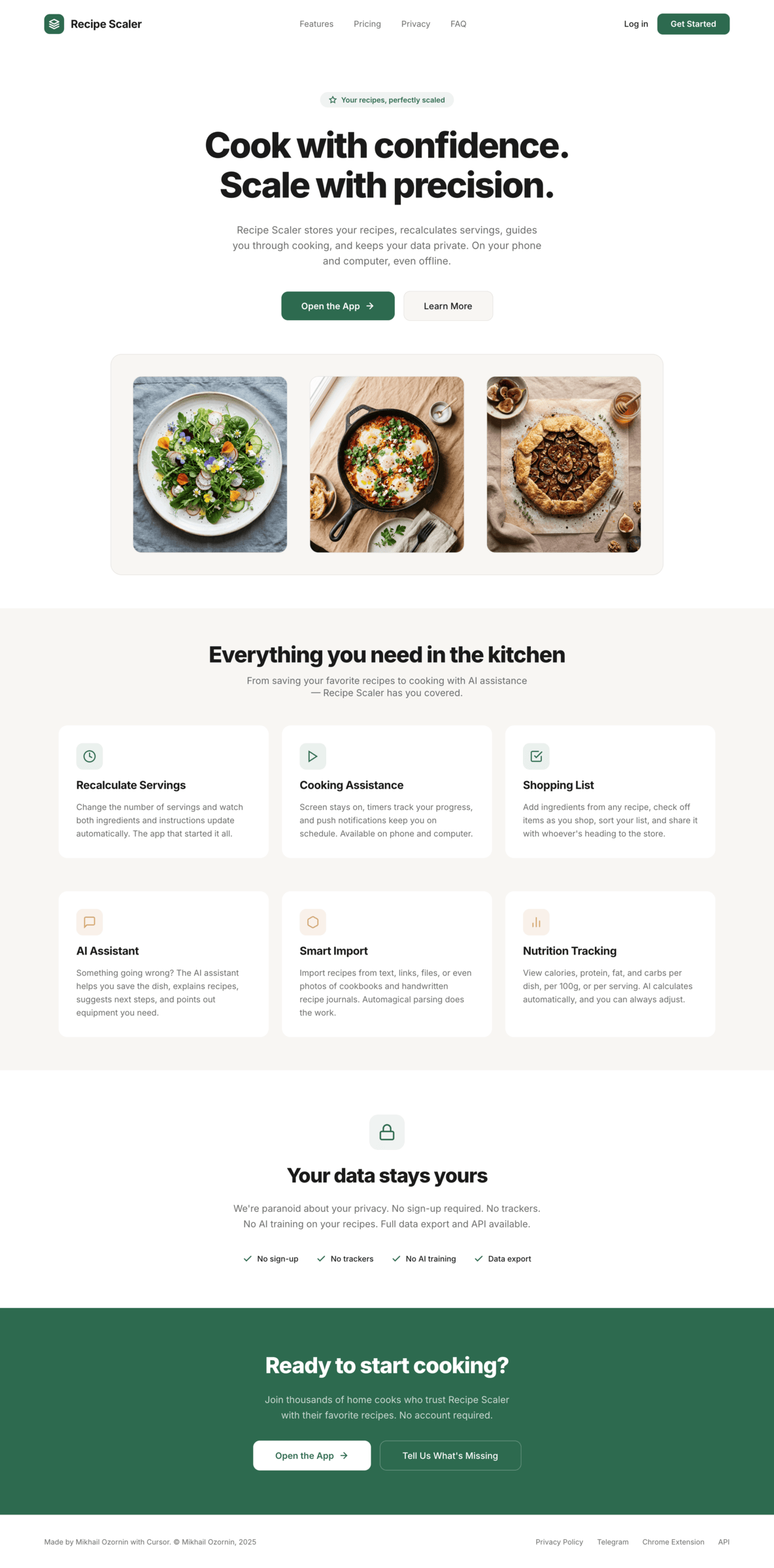
Kilo Code + Grok Build 0.1 + Google Skill
Тот же промт со скиллом Google design; сравните с OpenCode Grok Build 0.1 без скилла.
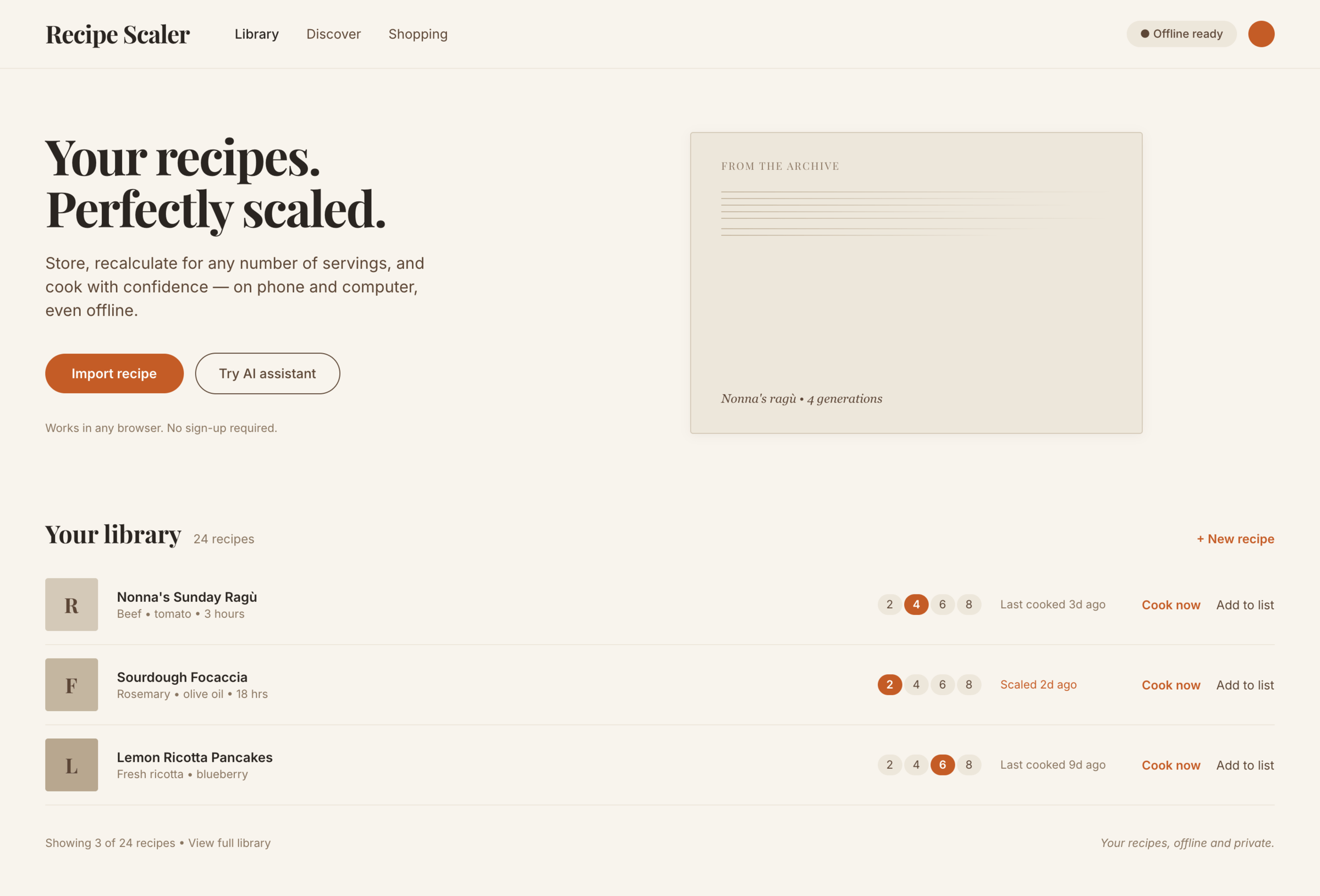
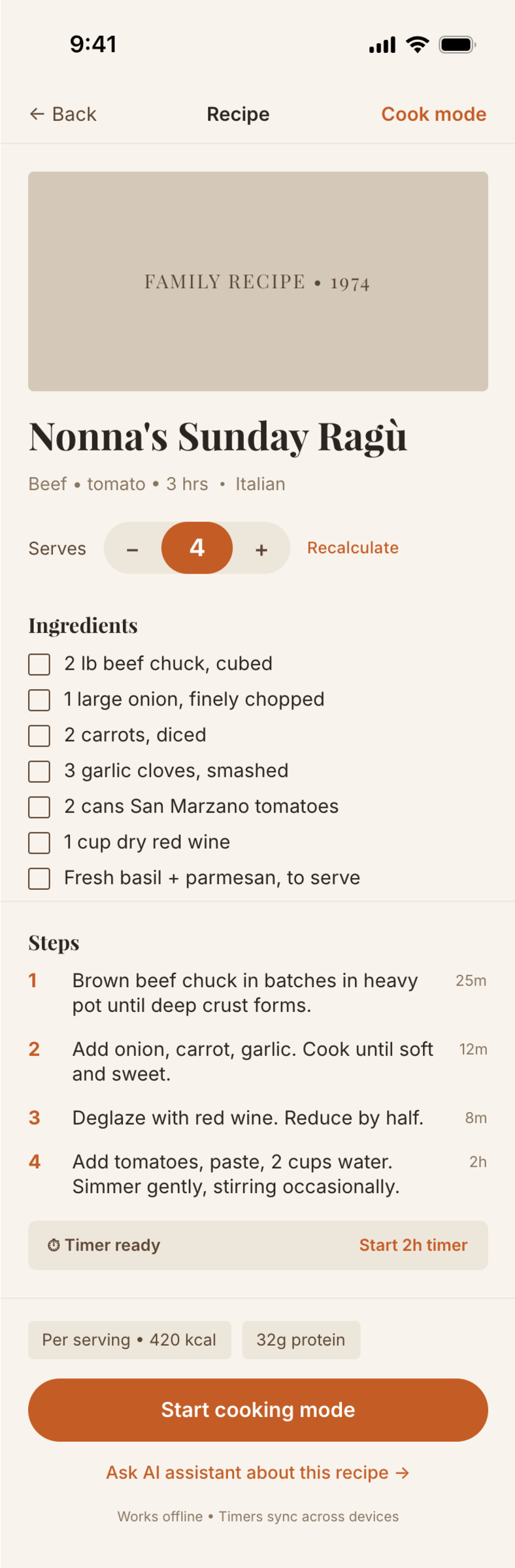
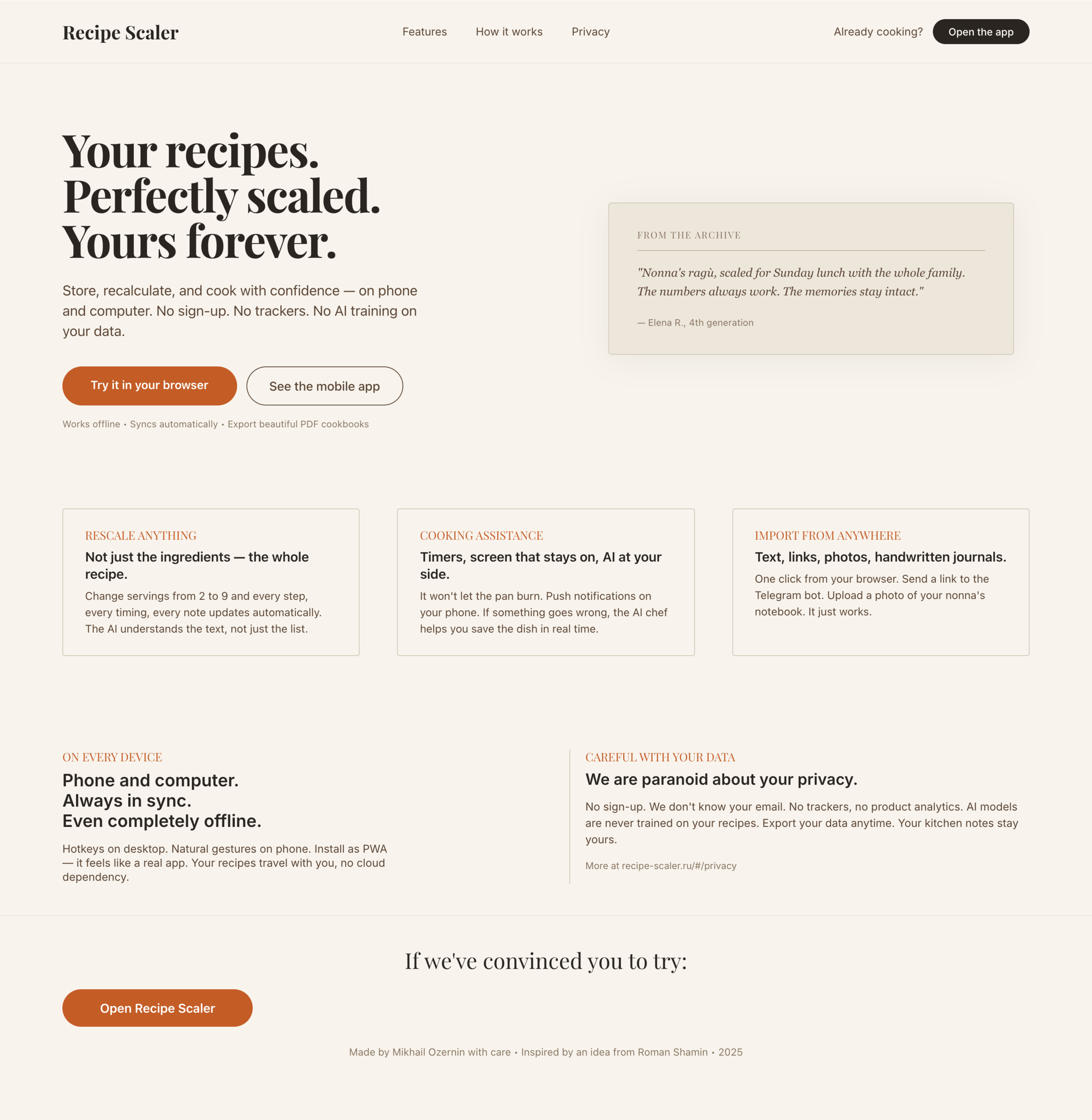
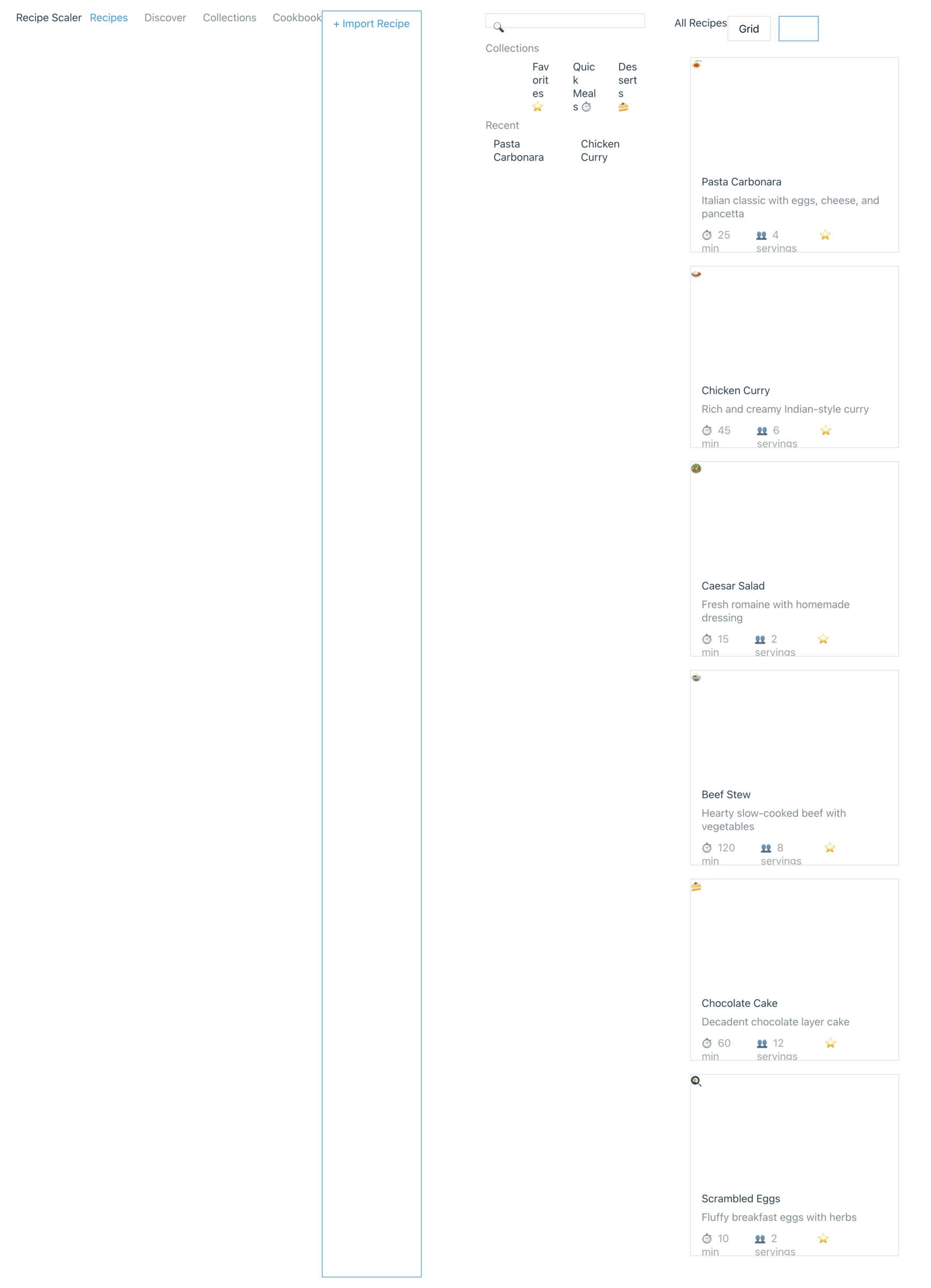
OpenCode + Opus 4.7, xhigh reasoning (OpenRouter)
Неплохо, что было бы в мобилке не знаю, потому что после этого экрана опенроутер меня забанил от американских СОТА-моделей.
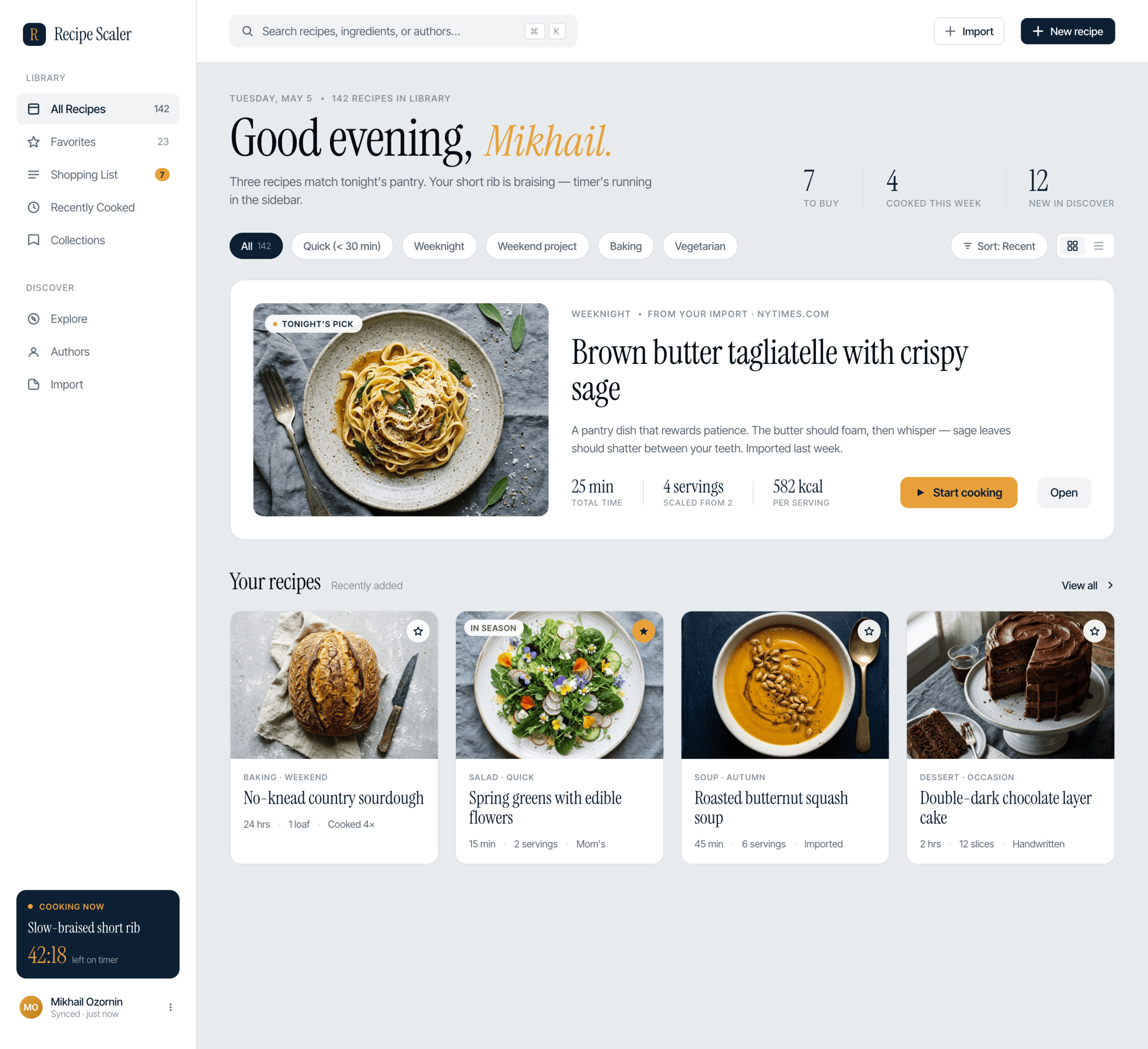
OpenCode + Kimi 2.6 (OpenRouter)
Мобилка лучше остального, остальное плохо. Из забавного все дублировалось, но он потом через скриншоты обнаруживал и стирал сам. Из-за этого возился очень долго — 40+ минут.
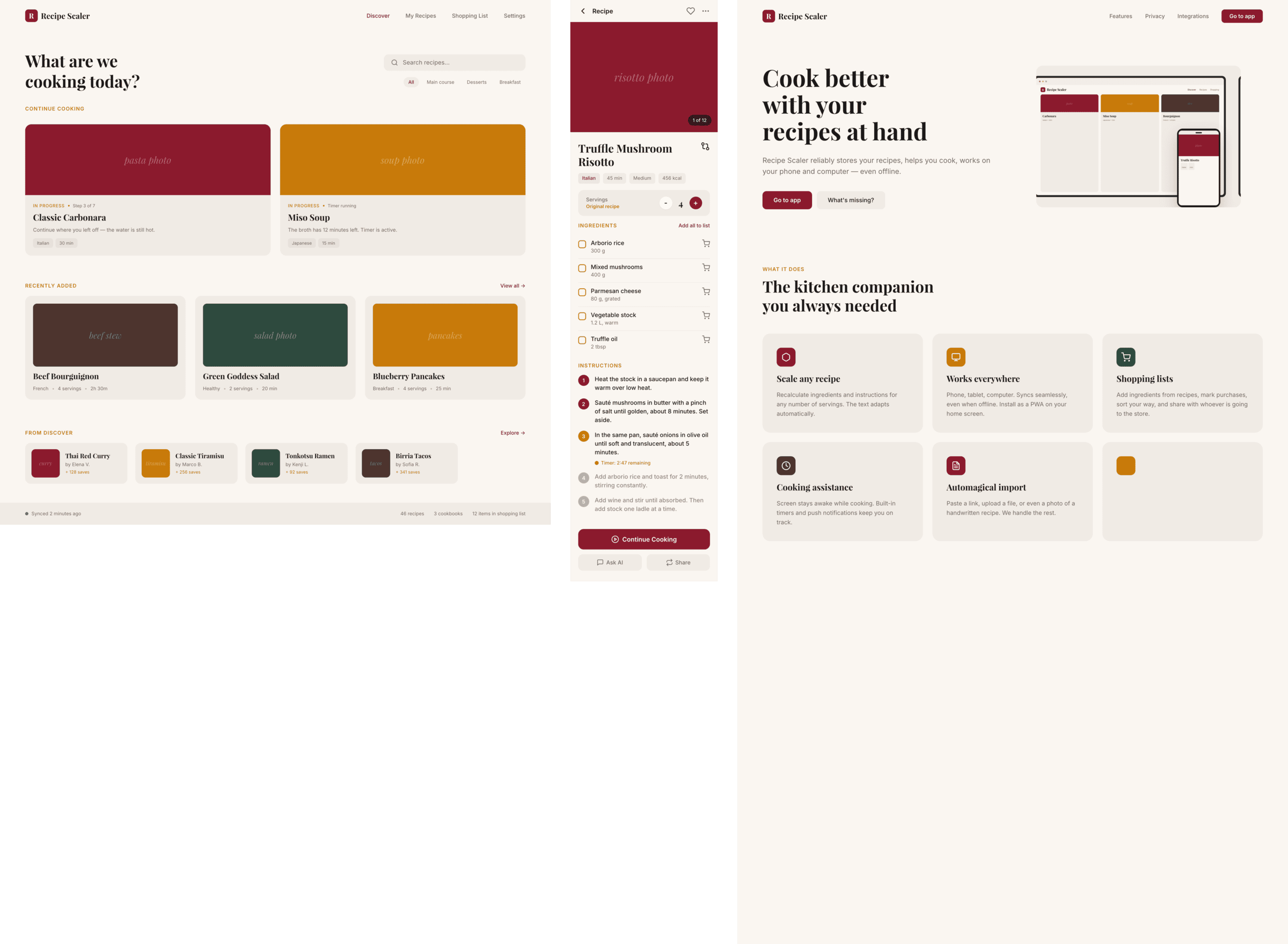
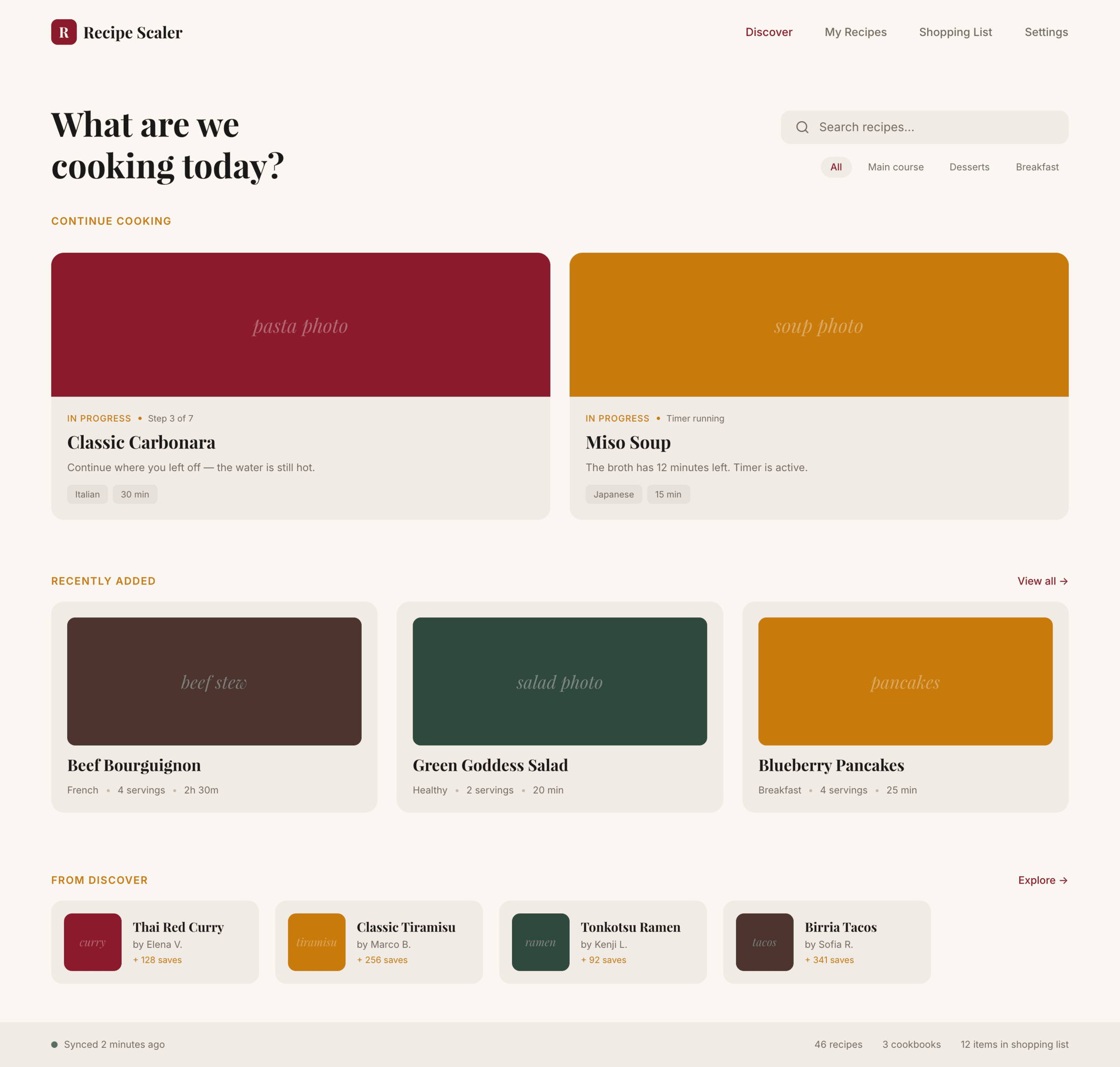
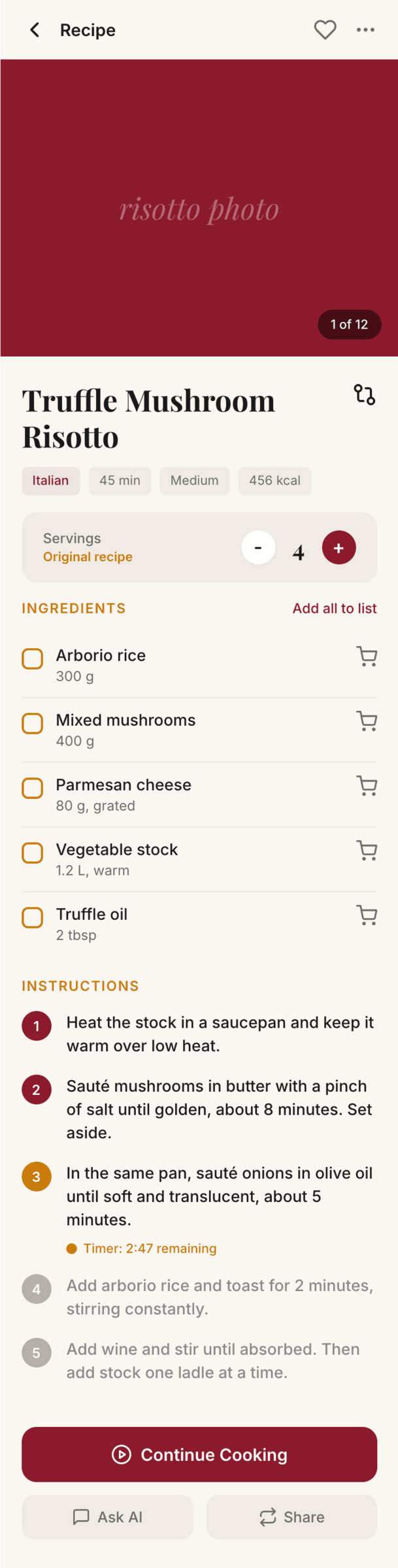
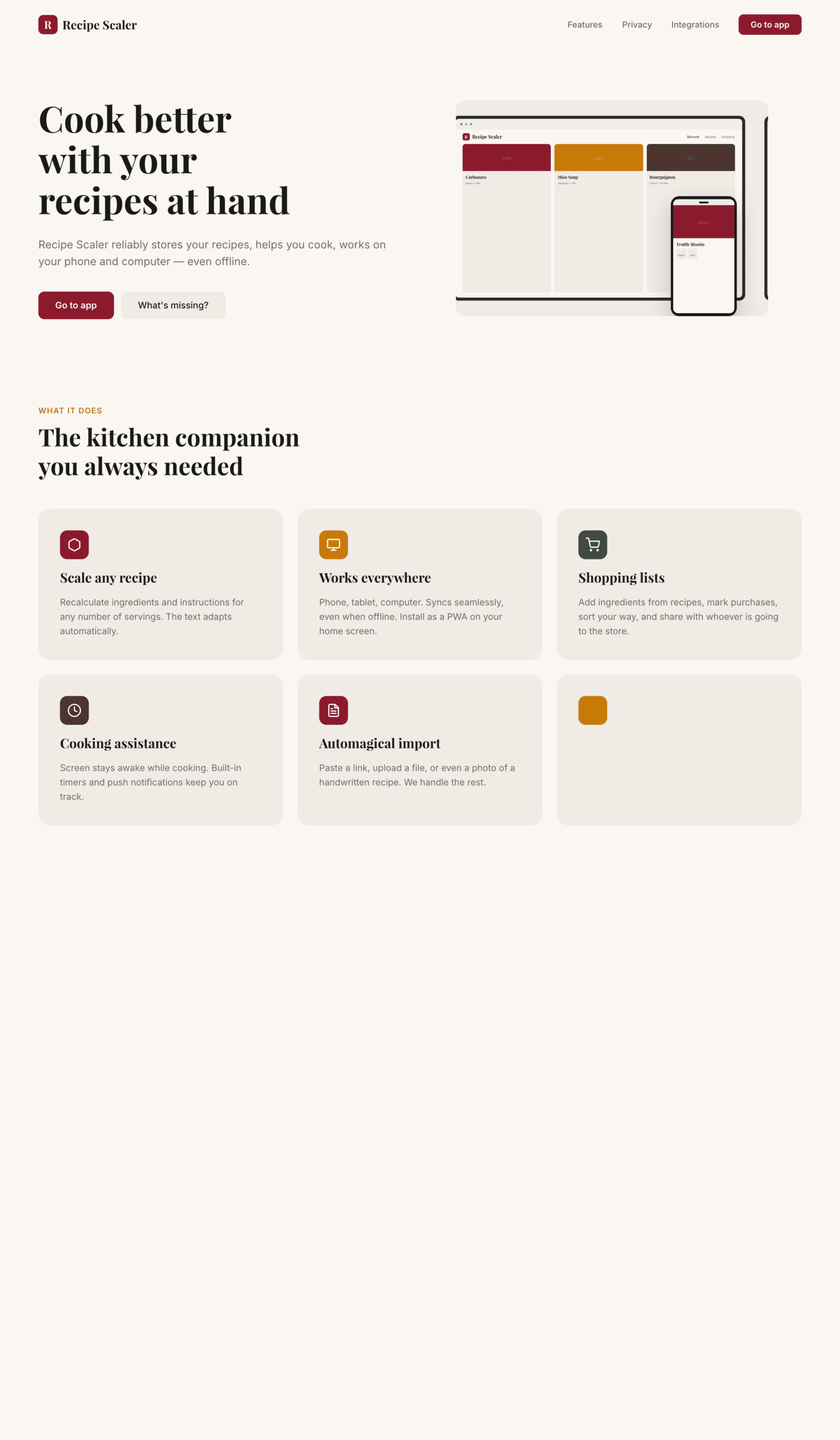
OpenCode + Grok 4.3 (OpenRouter)
Грок уже был выше, но в отличие от Курсора, Опенкод с моделью вообще не справился, результат сильно хуже, чем у Курсора.
OpenCode + Grok Build 0.1 (OpenRouter)
Быстро, слабо, дорого для такого качества.
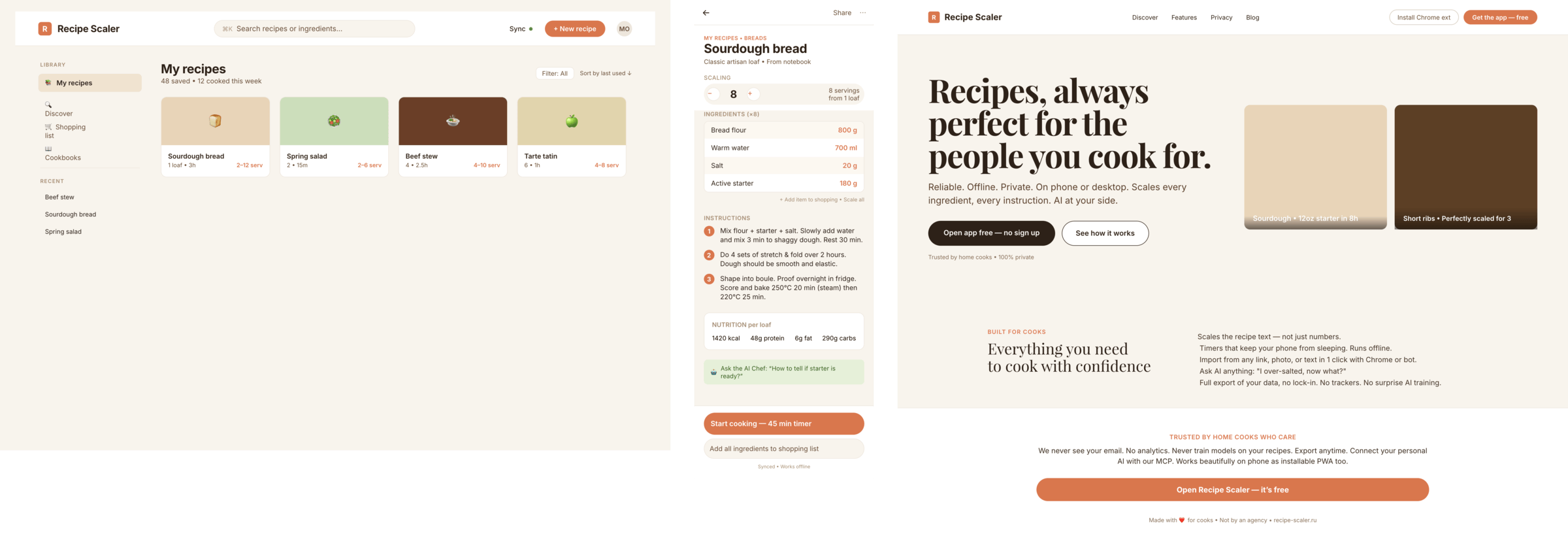
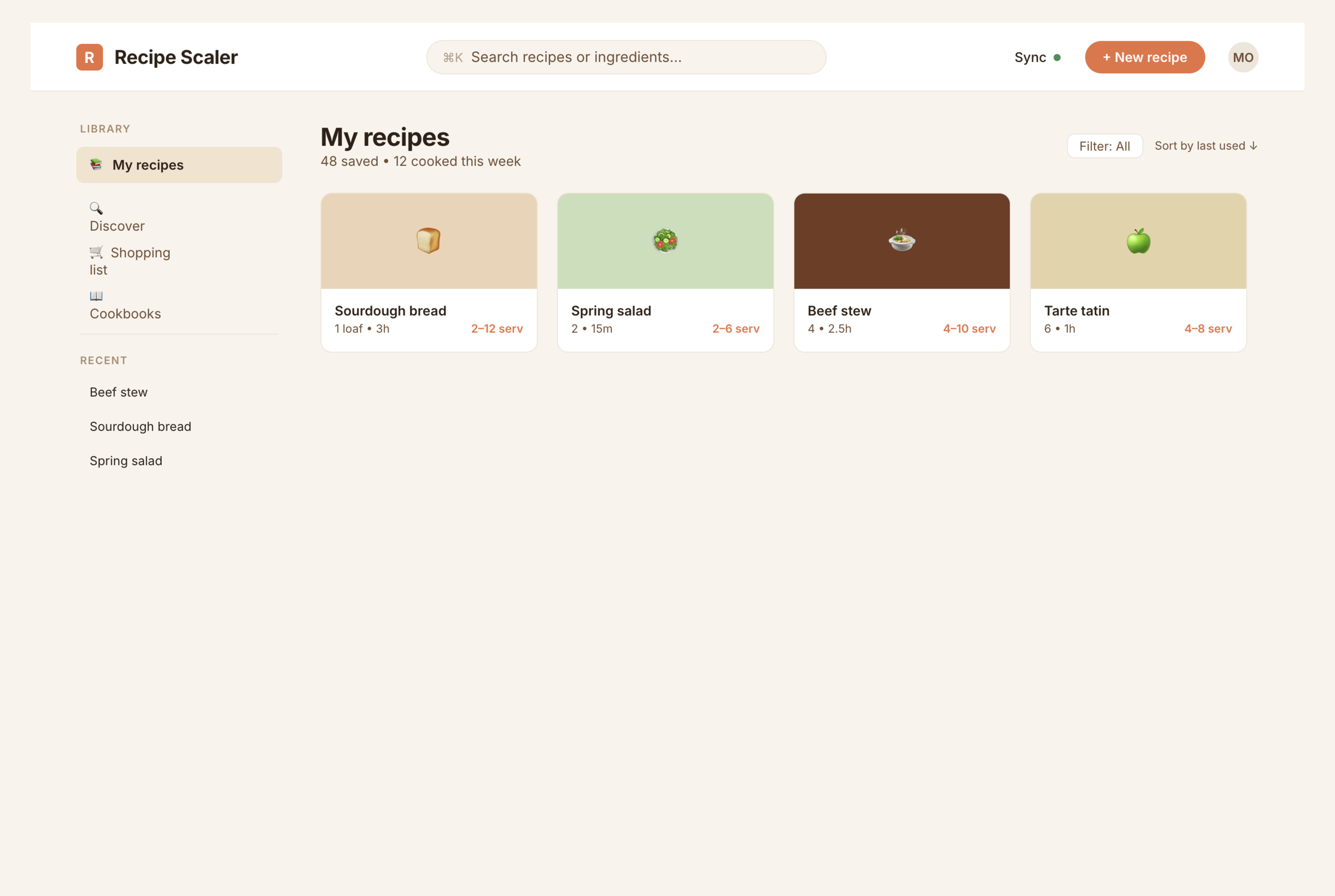
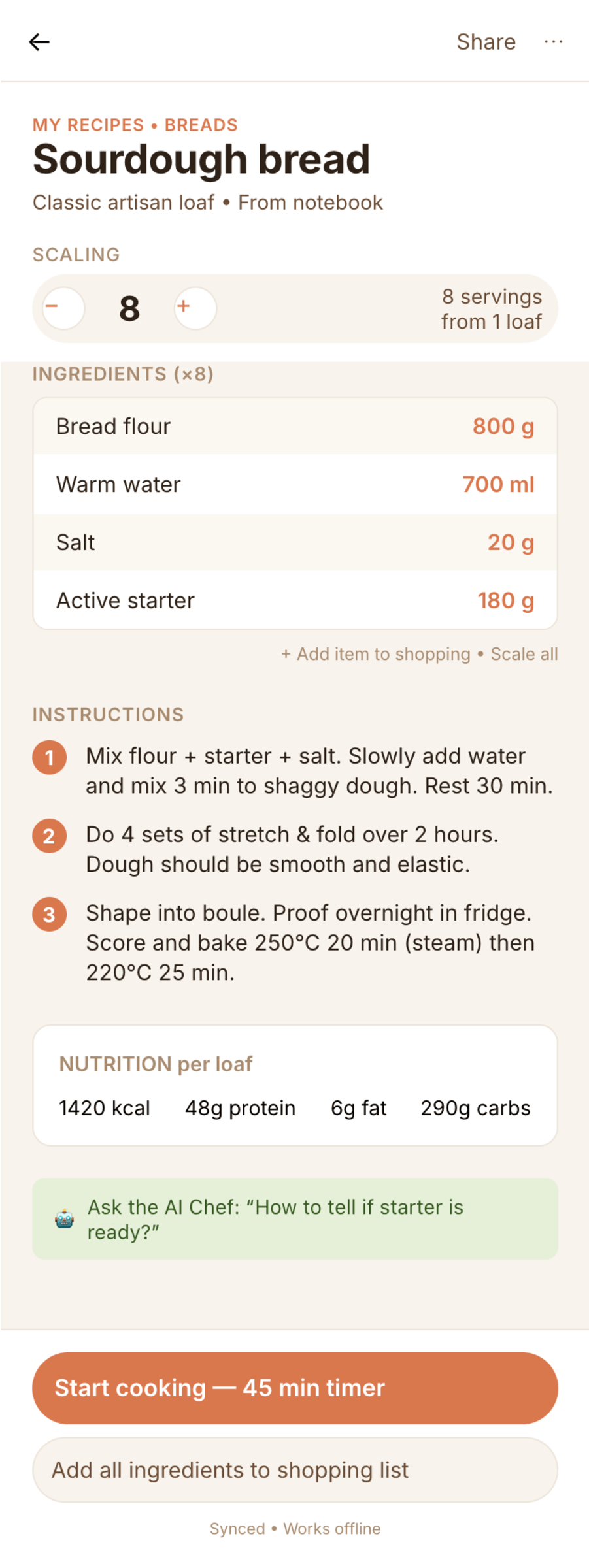
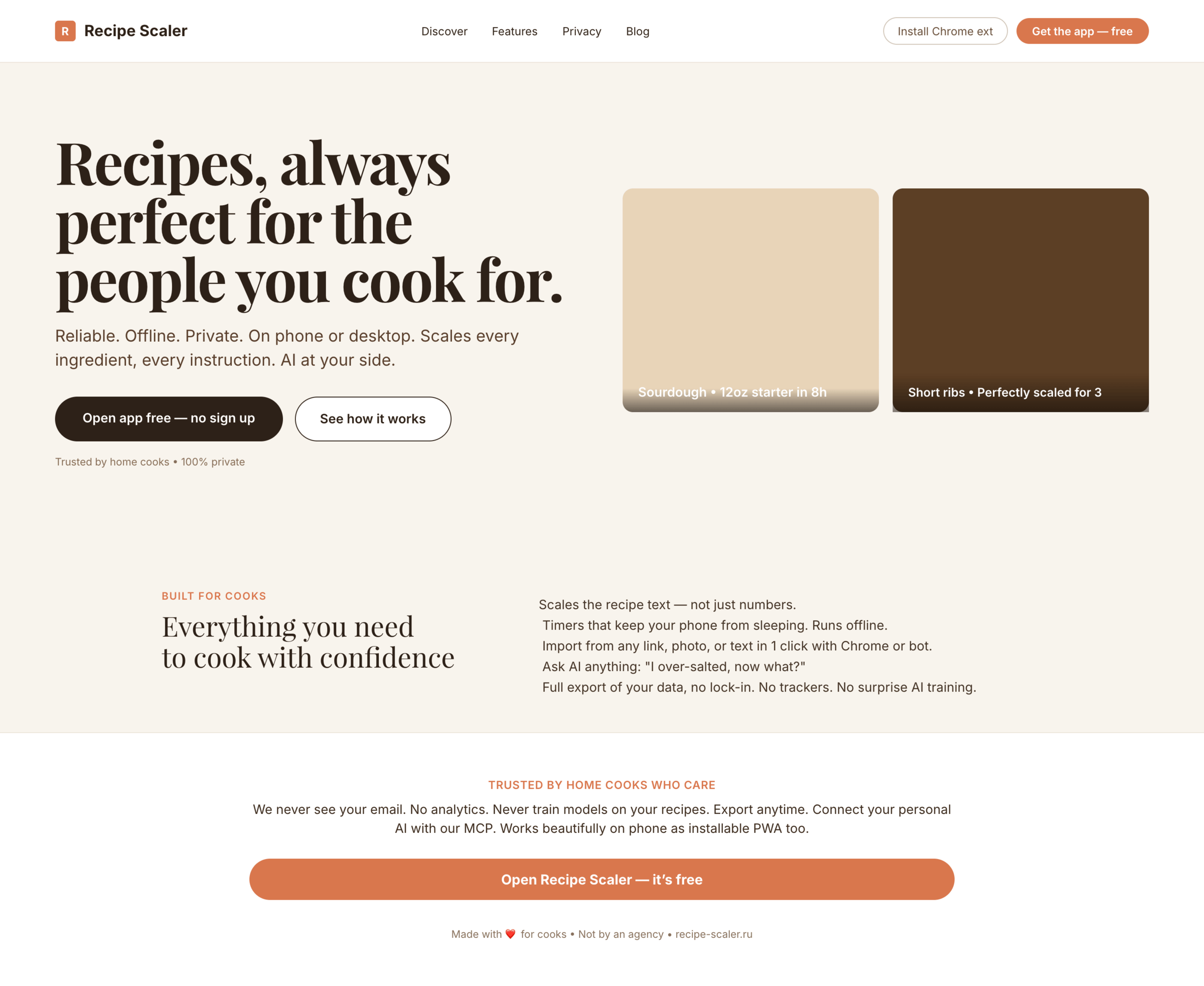
OpenCode + DeepSeek V4 Pro (Deepseek Cloud), Max Reasoning
Дипсик очень дешев, но справился лишь один раз. Мобилку можно смотреть, остальное плохо.
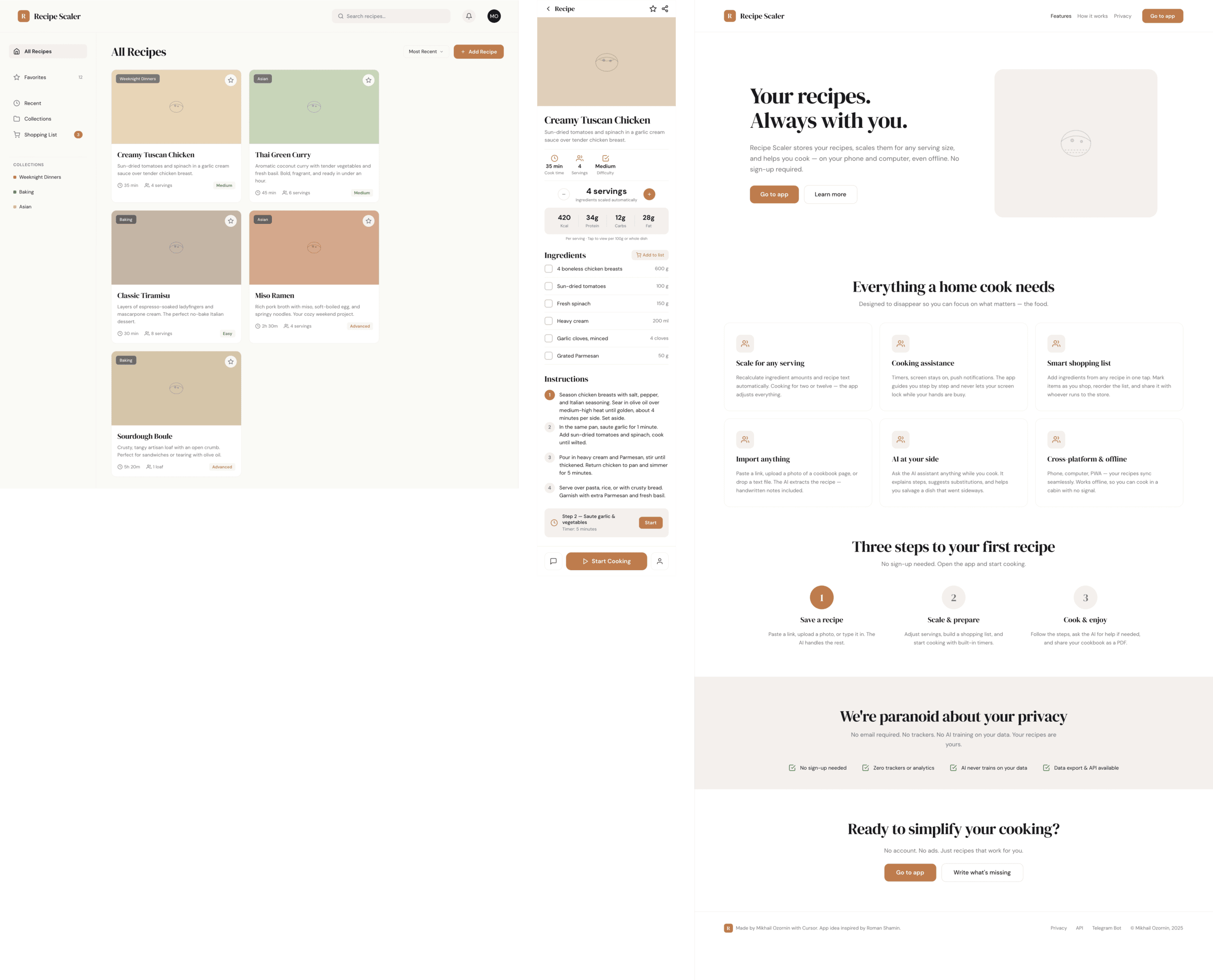
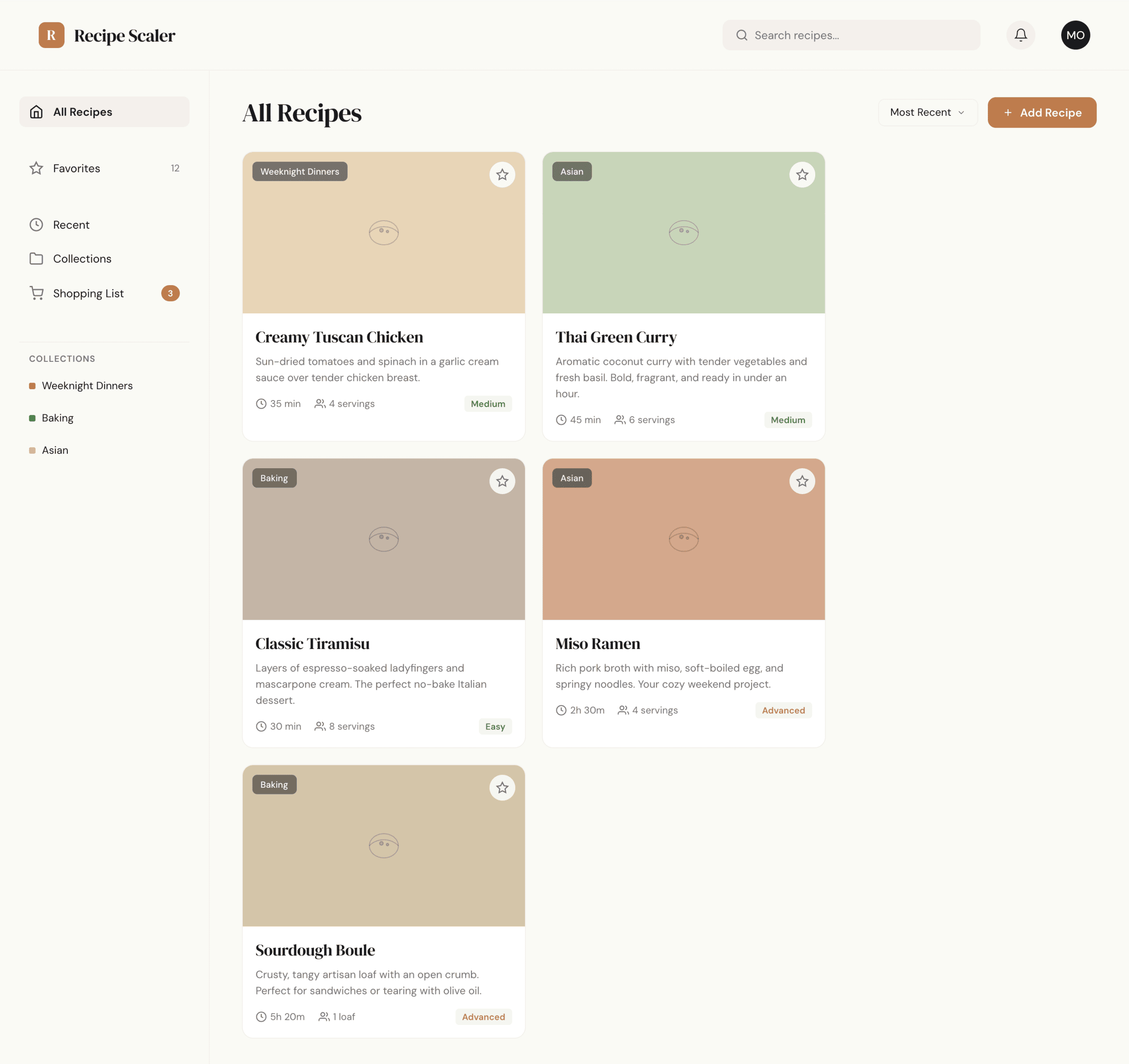
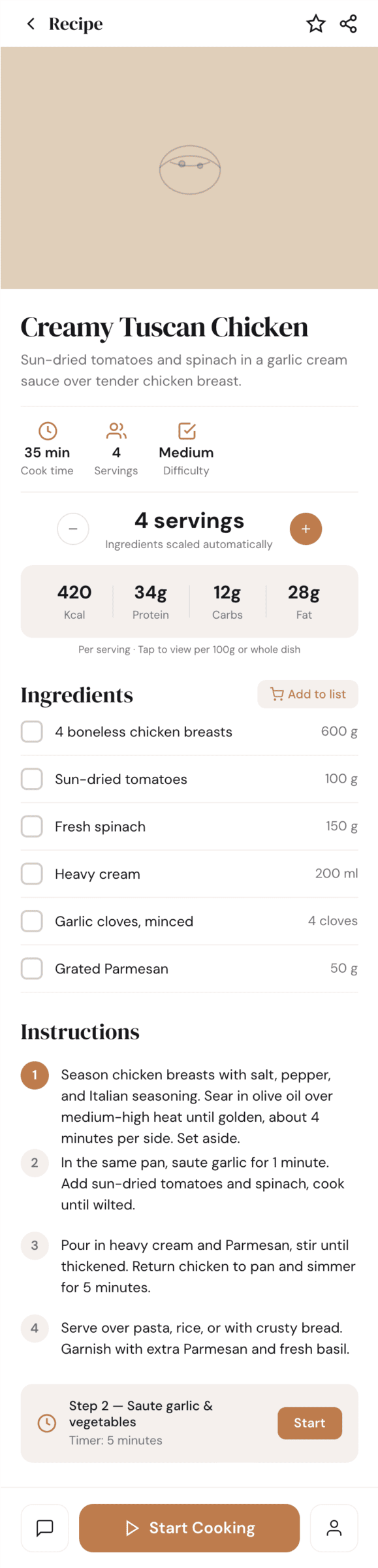
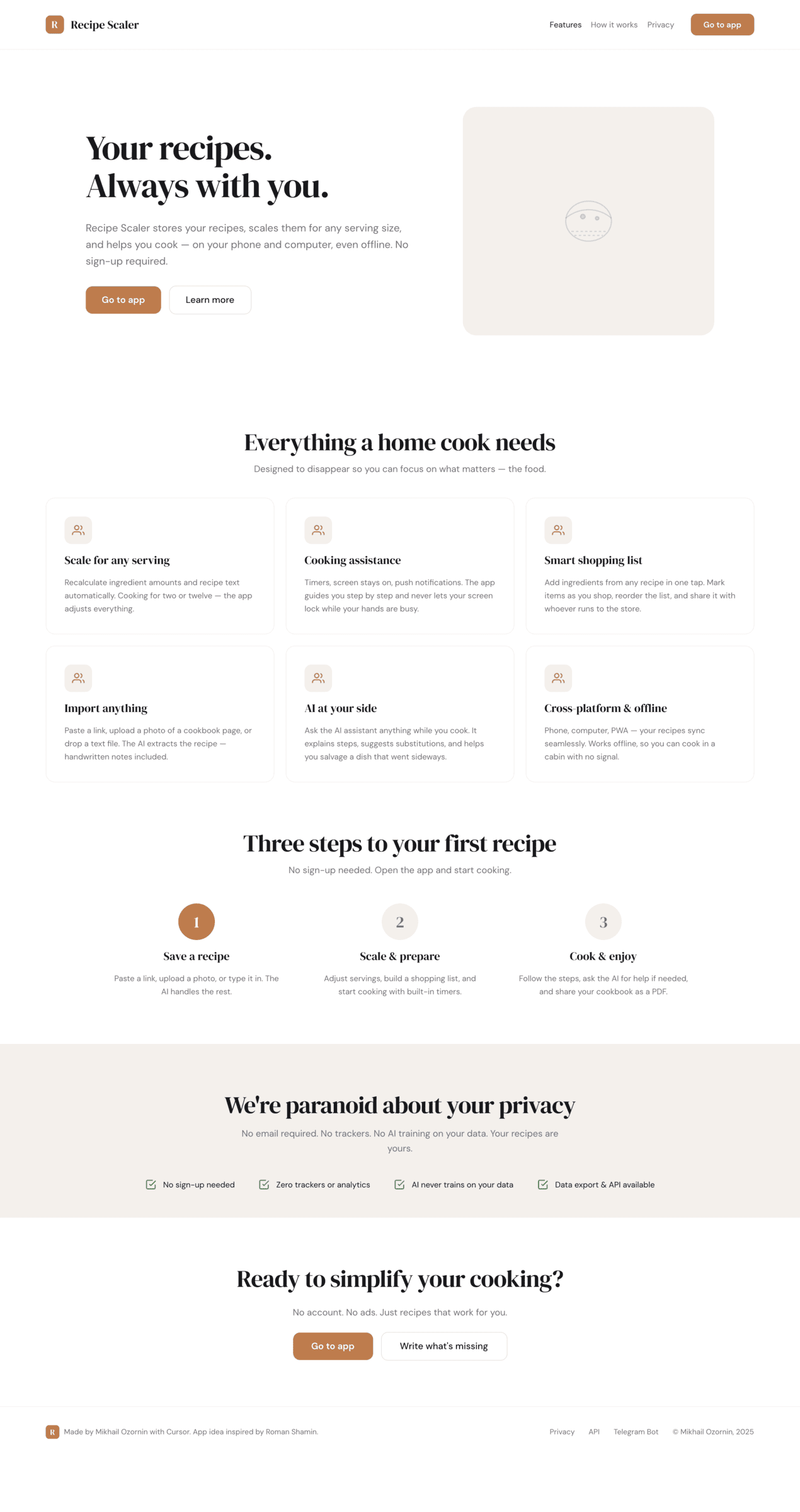



OpenCode + GLM 5.1 (z.ai coding plan)
В отличие от Курсора Опенкод смог добиться чего-то от ГЛМ, вышло в целом ок для его цены. Он стоит дешевле Хайку, которы не смог буквально ничего.
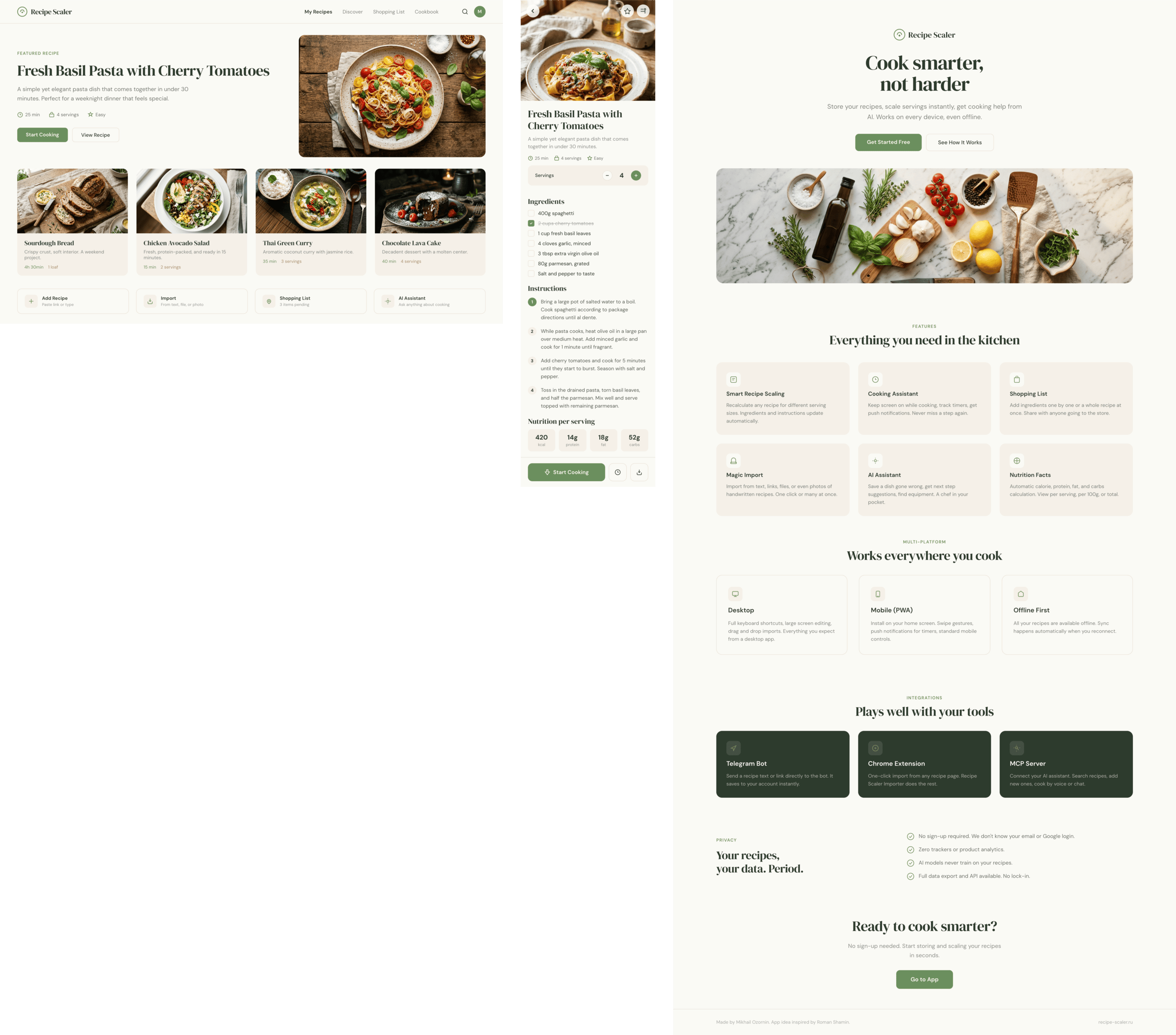
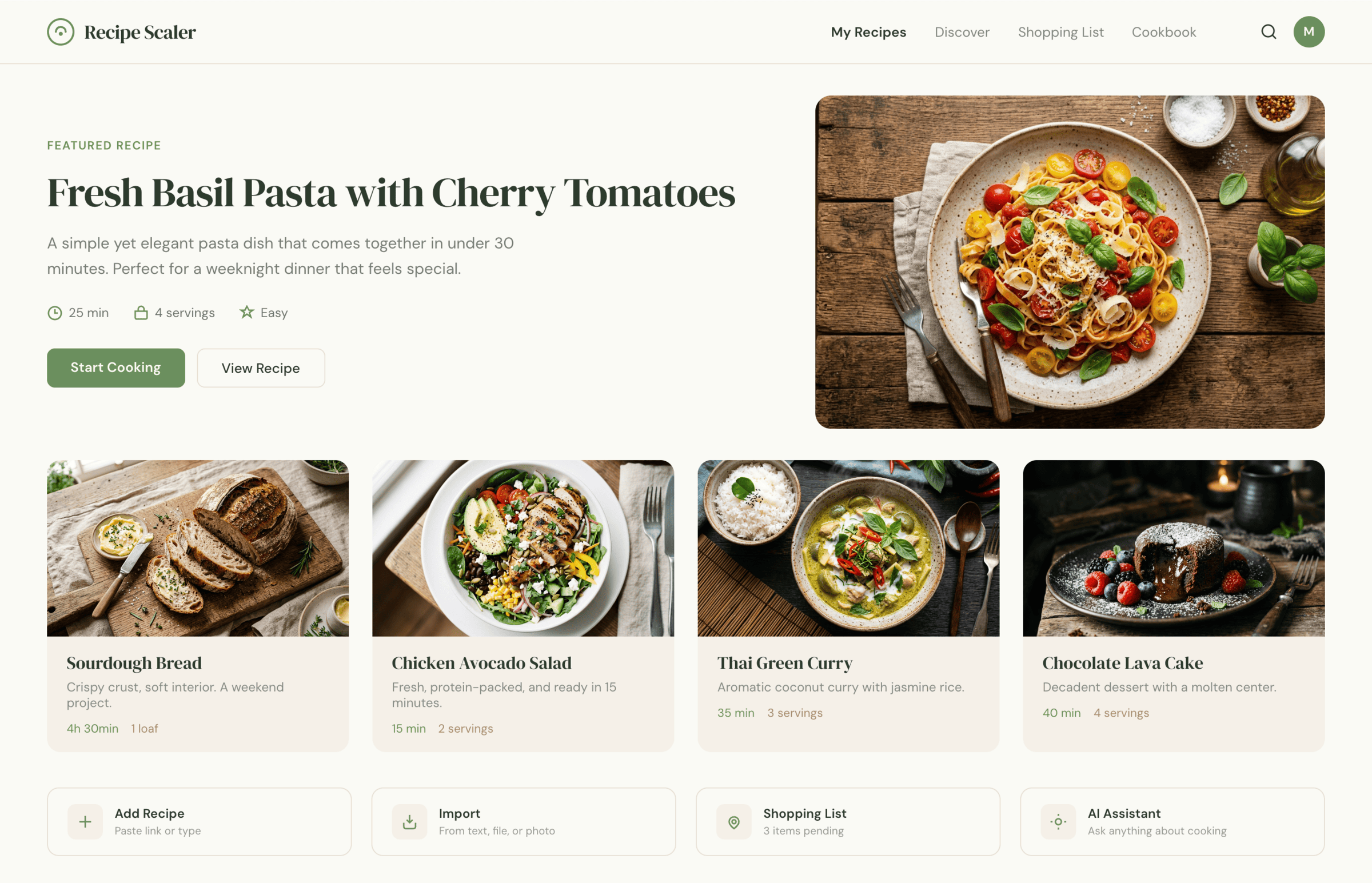
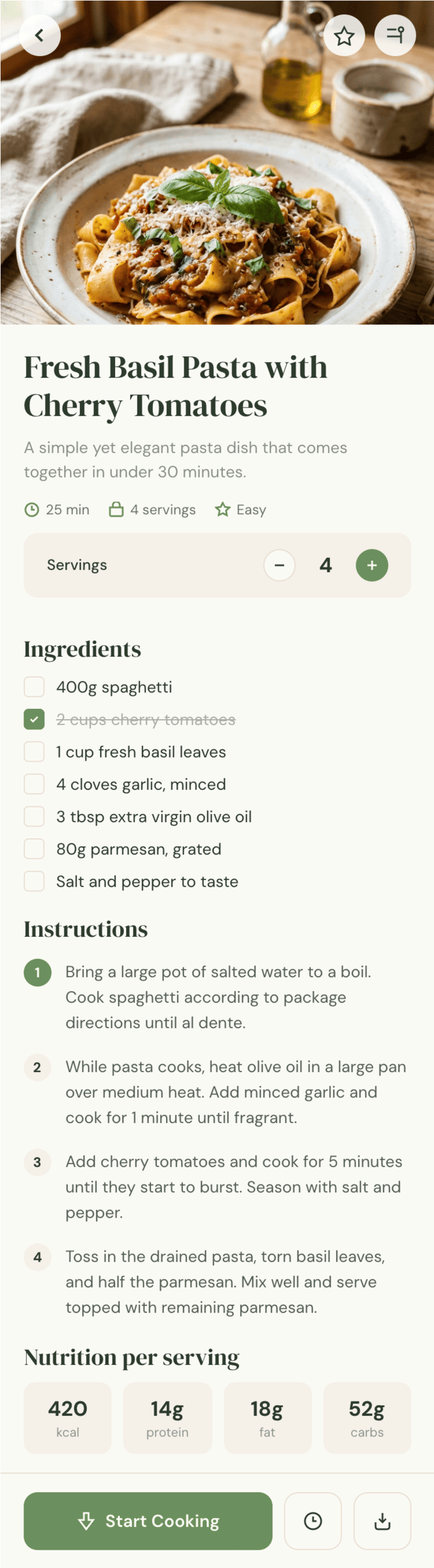
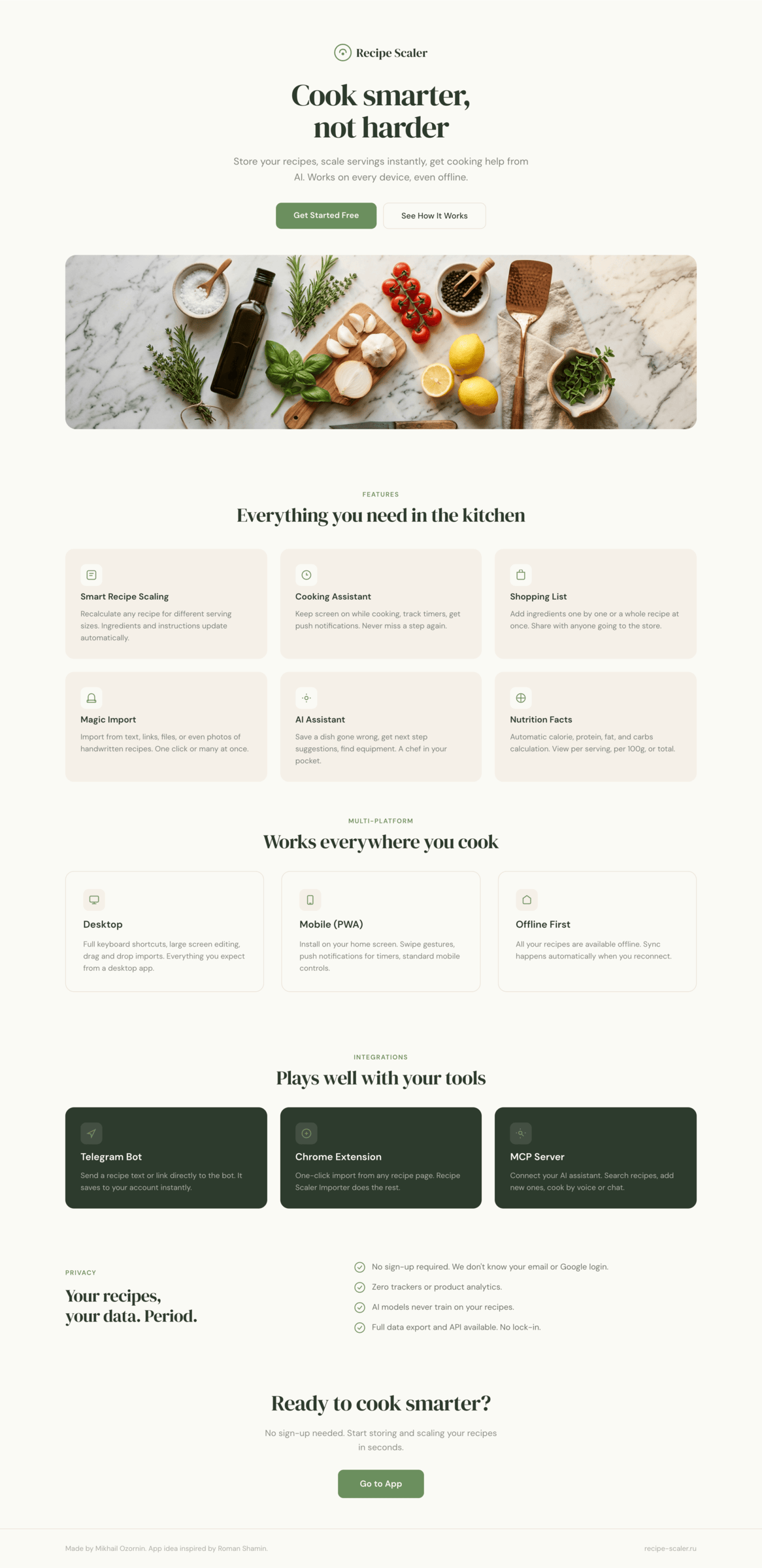
OpenCode + Qwen 3.5 397
Не смогло ничего.

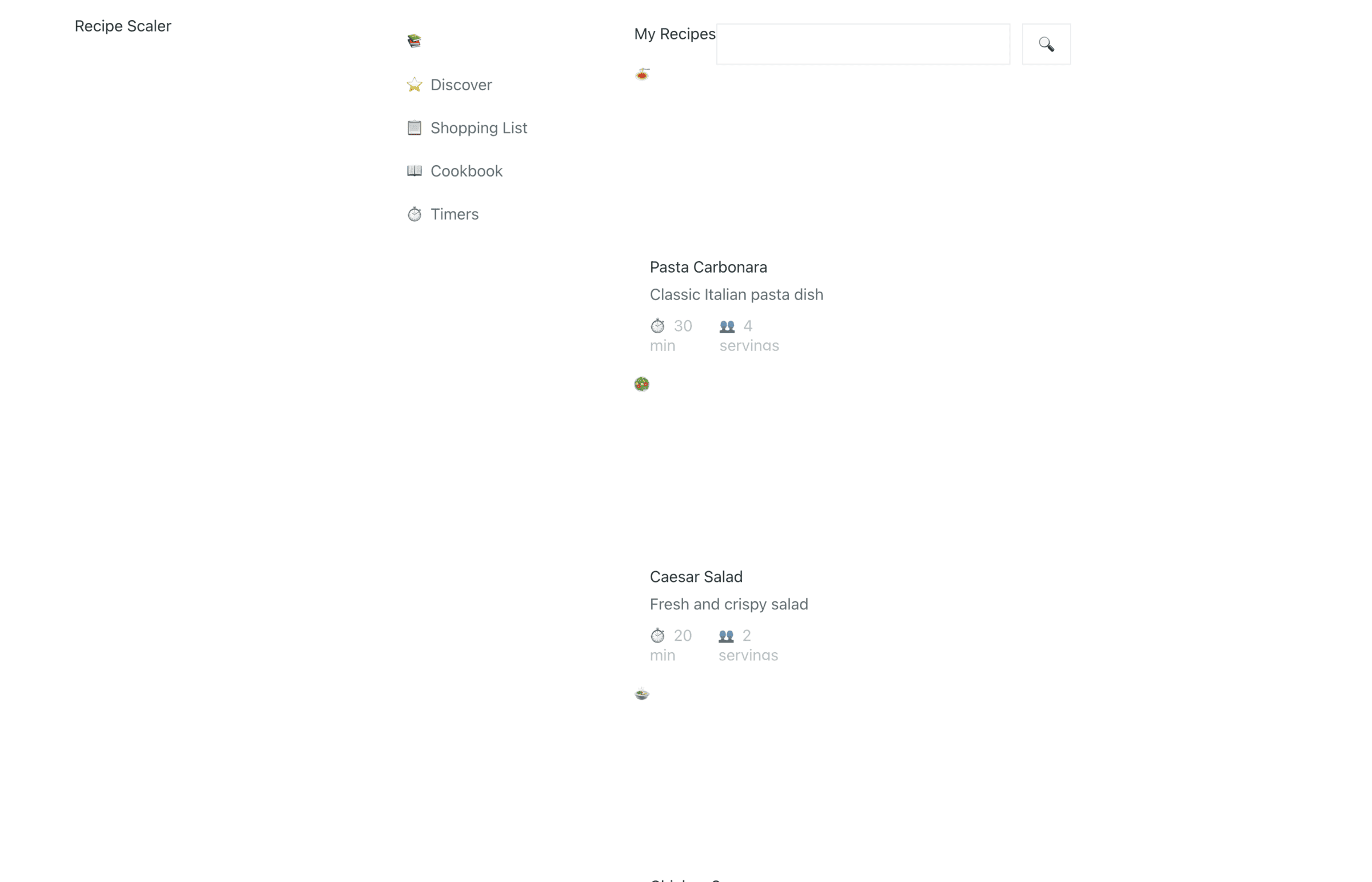


OpenCode + MiniMax 2.7 (OpenRouter)
Невероятно быстро, невероятно дешево, качество соответствующее.
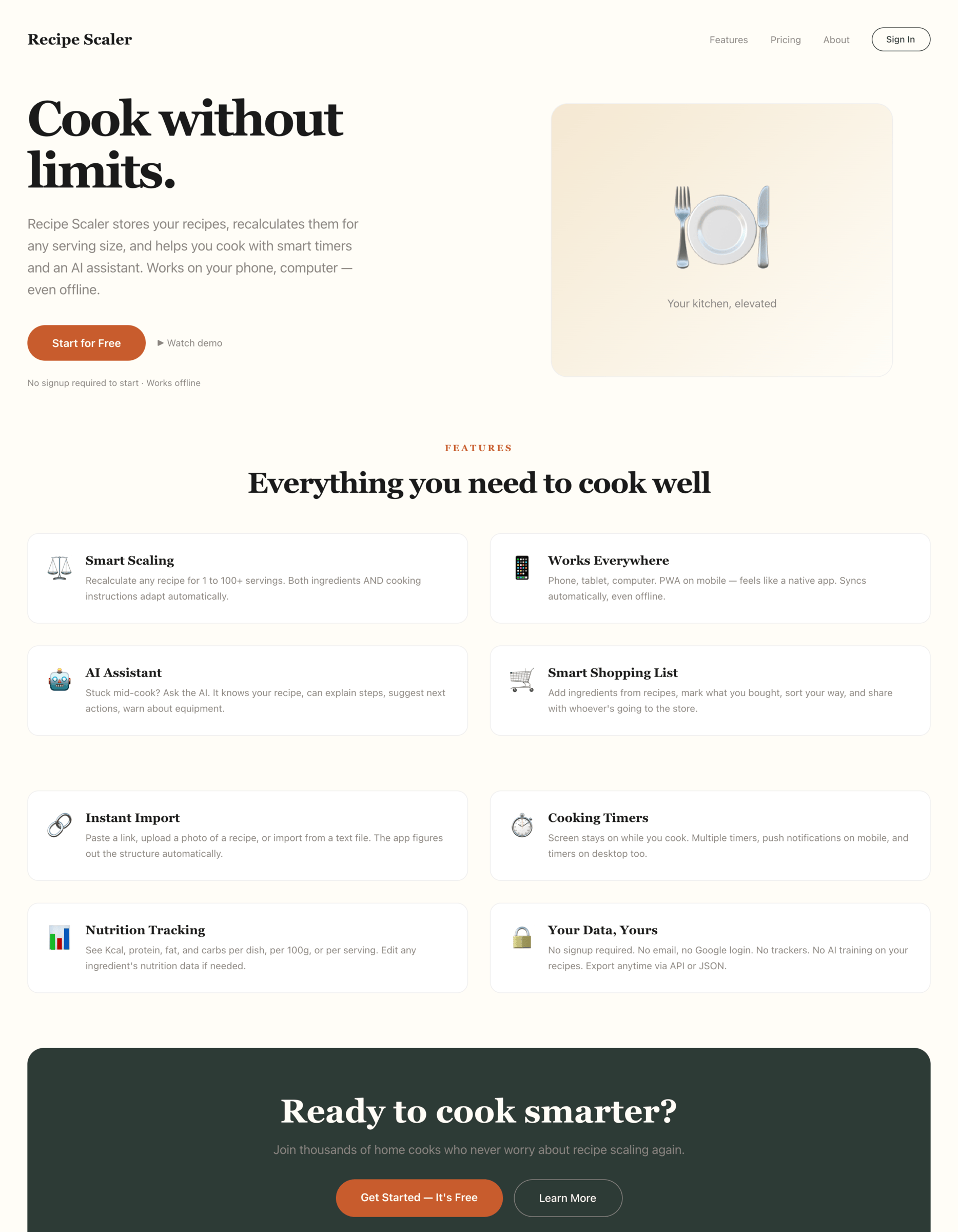
OpenCode + Qwen 3.7 Max Preview (OpenRouter
Дорого для своего результата, не улучшилось с 3.6 Max. Очень плохо работал с тулами (может быть особенность опенкода).
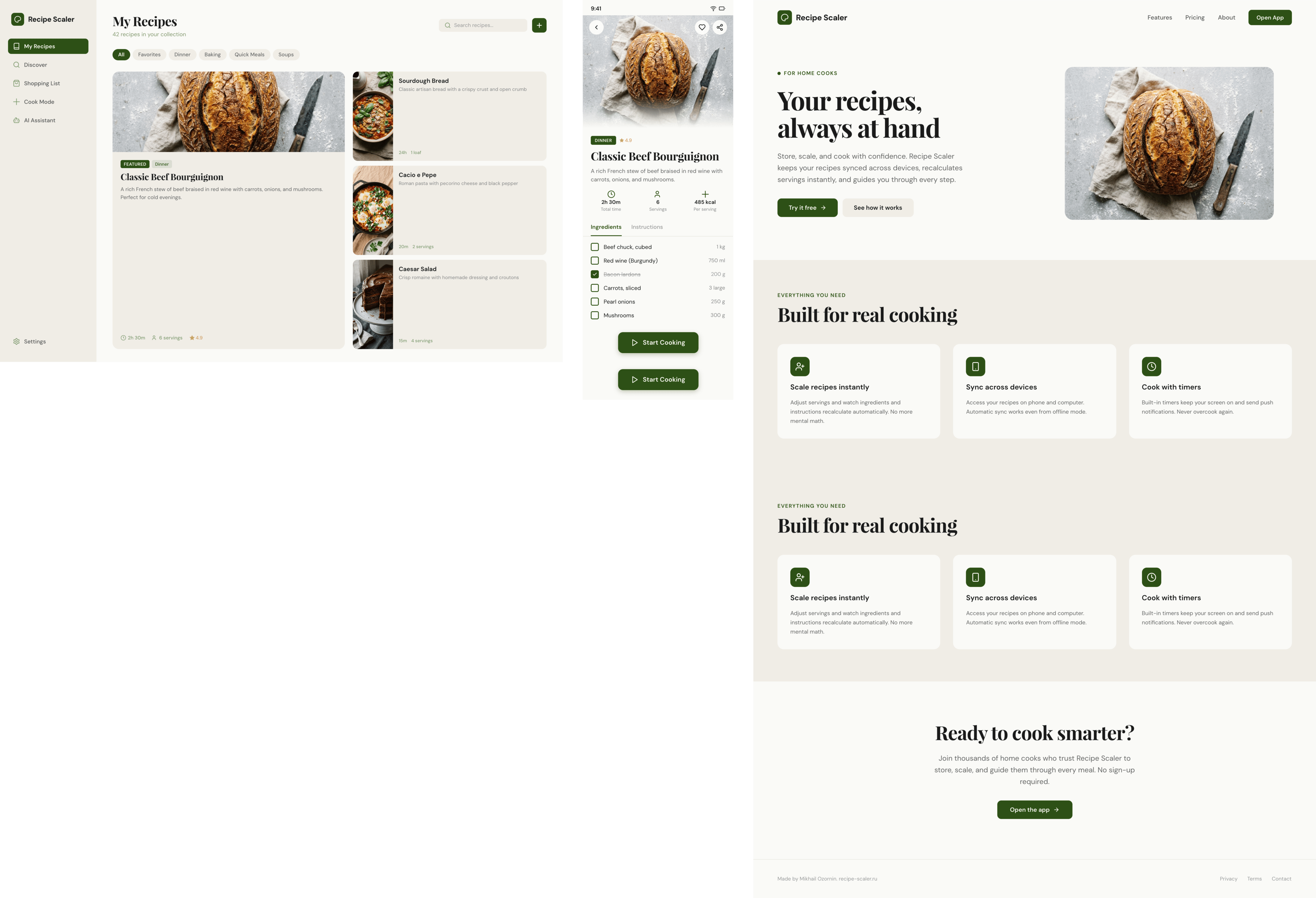
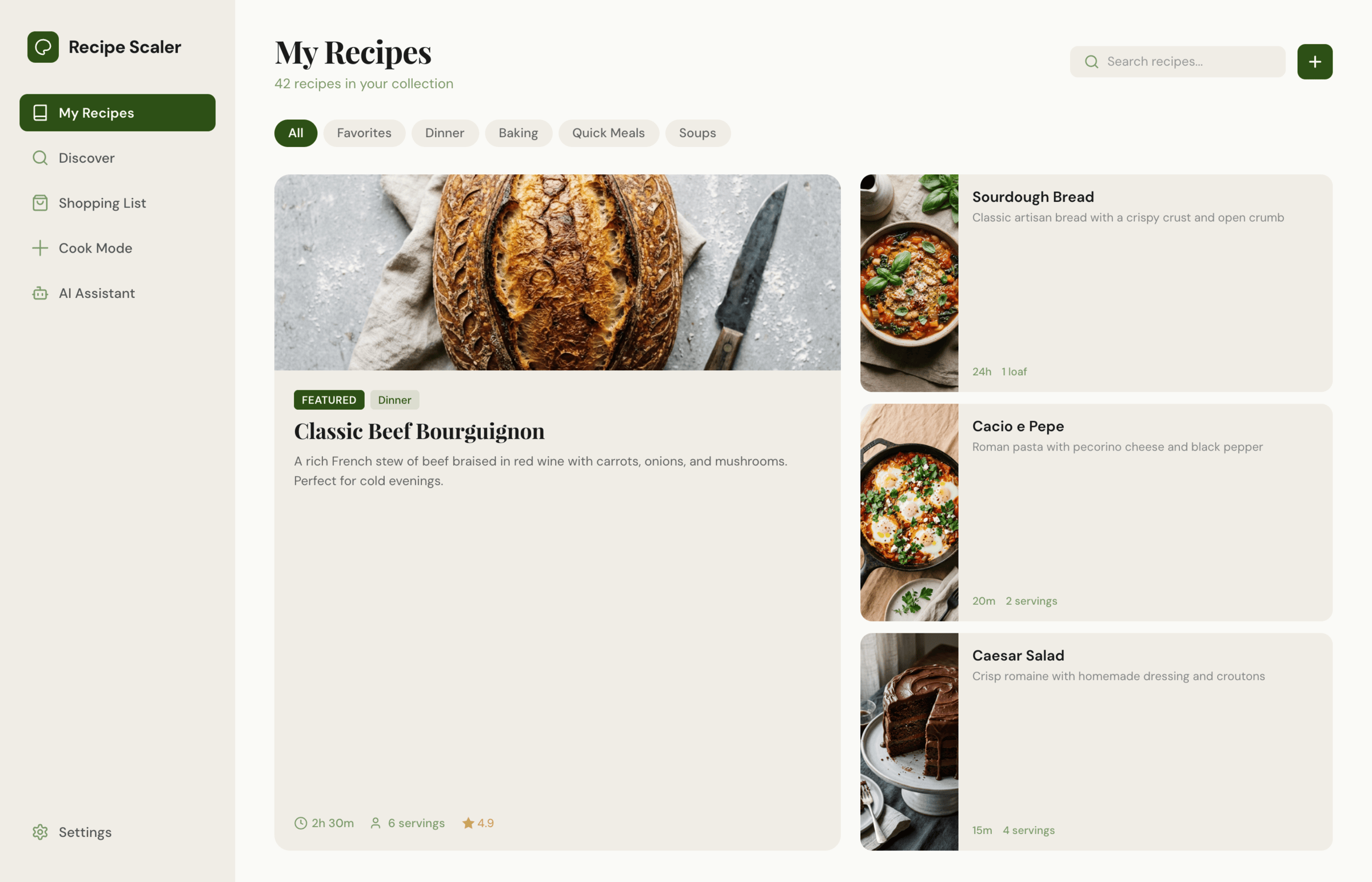
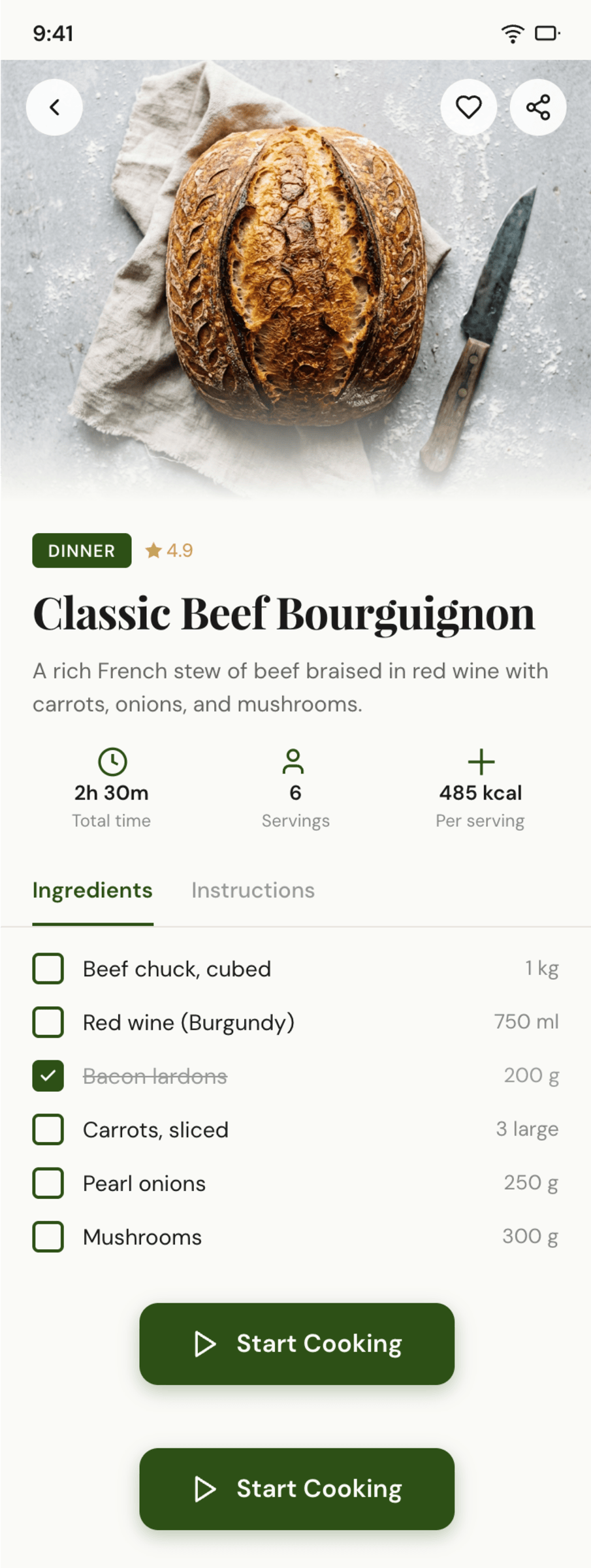
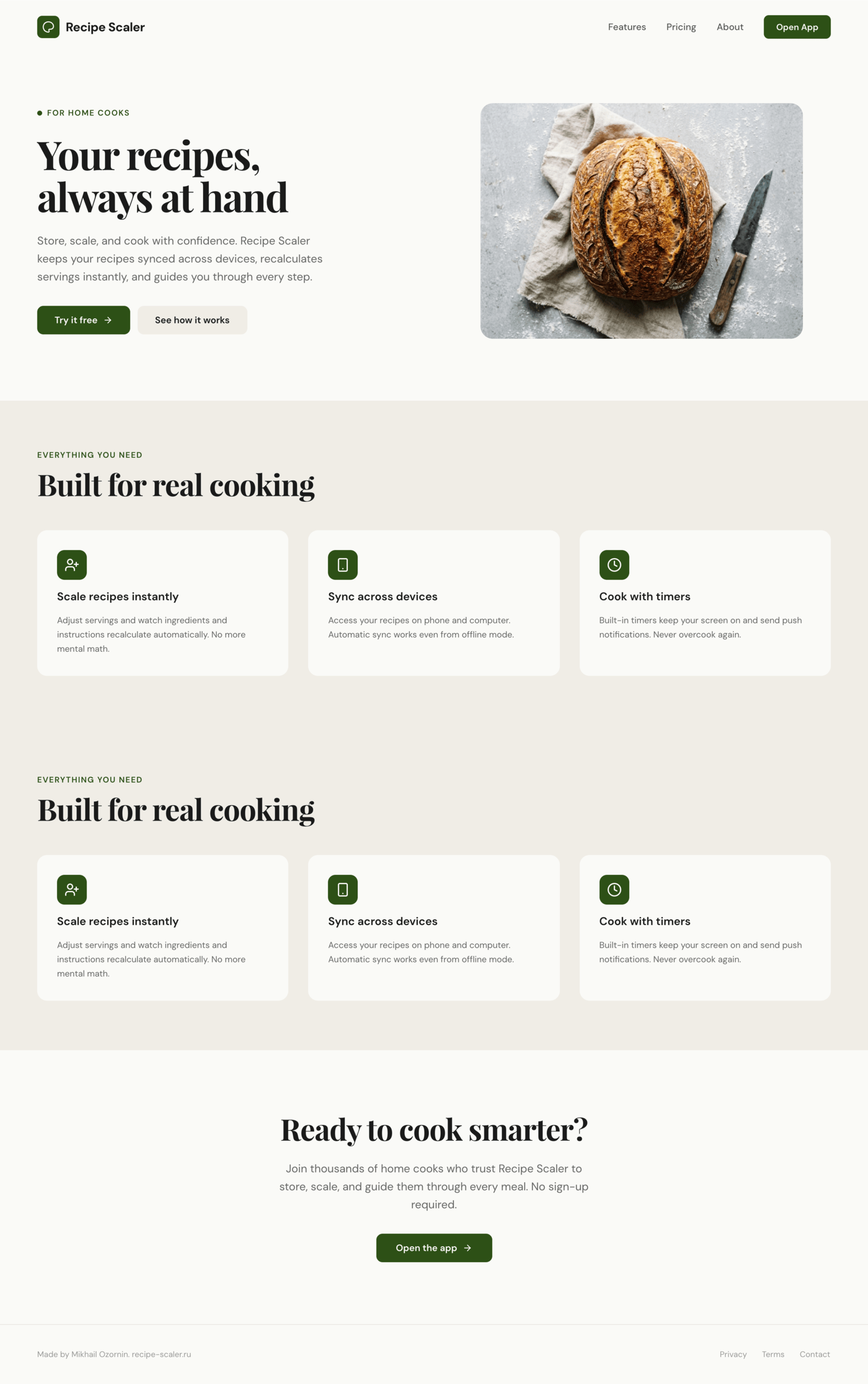
Figma: Claude Code + Opus 4.7, xhigh
Опус в своем стиле, издалека особенно, но сожрал больше целой 5-часовой квоты.
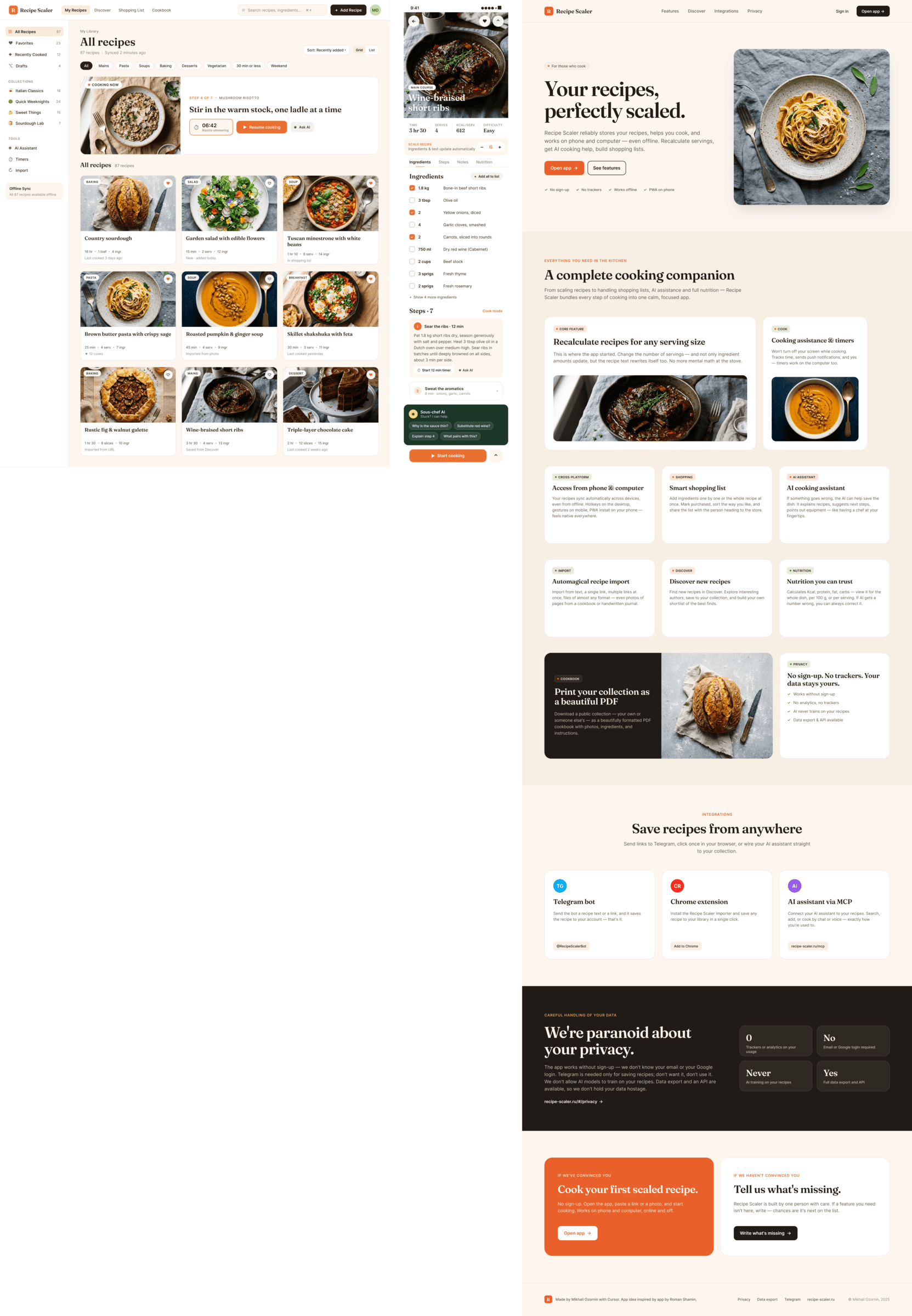

Figma: Codex + GPT 5.5, xhigh
В фигме смог чуть лучше, чем в пейпере. Верстает чудовищно просто.
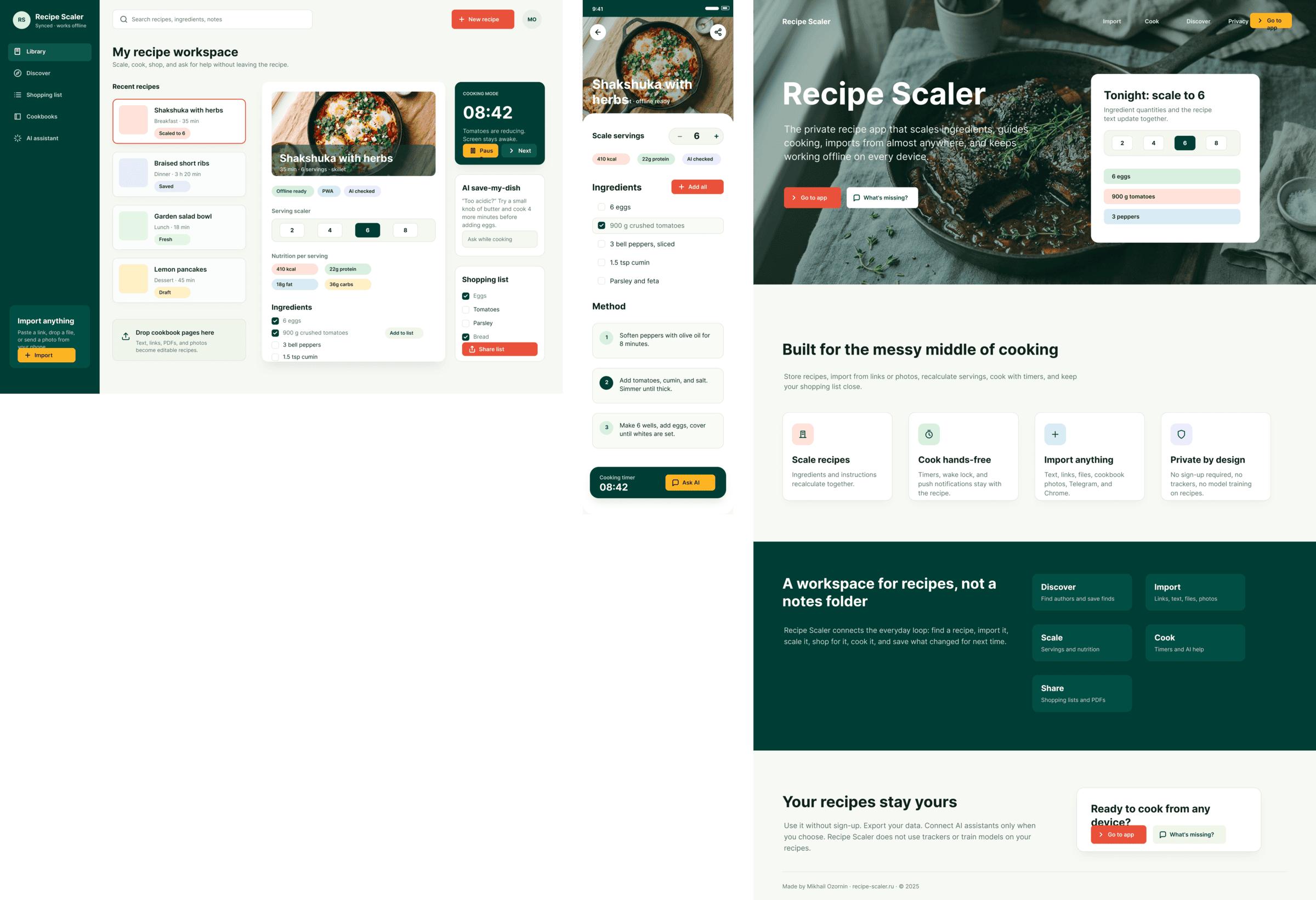
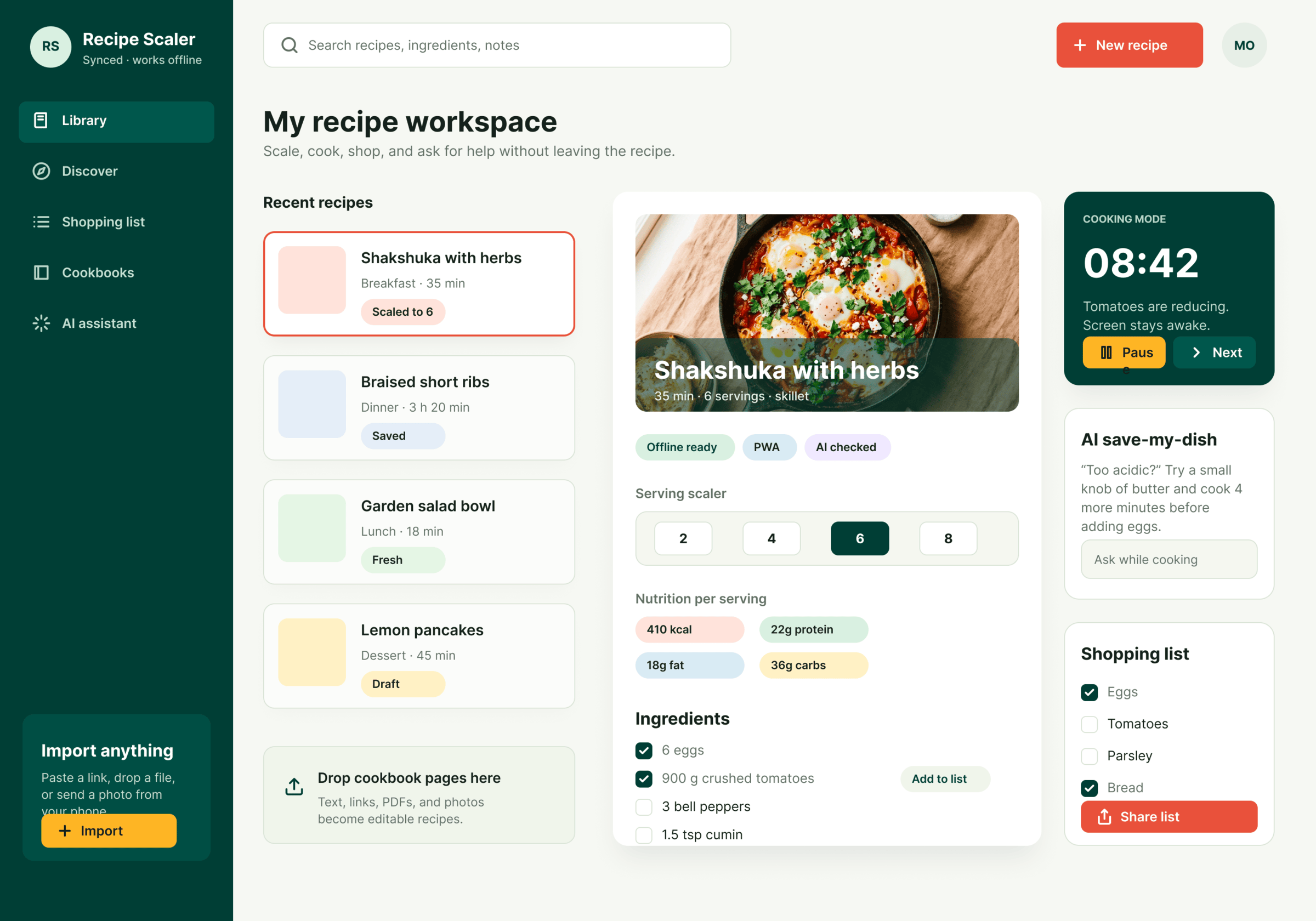
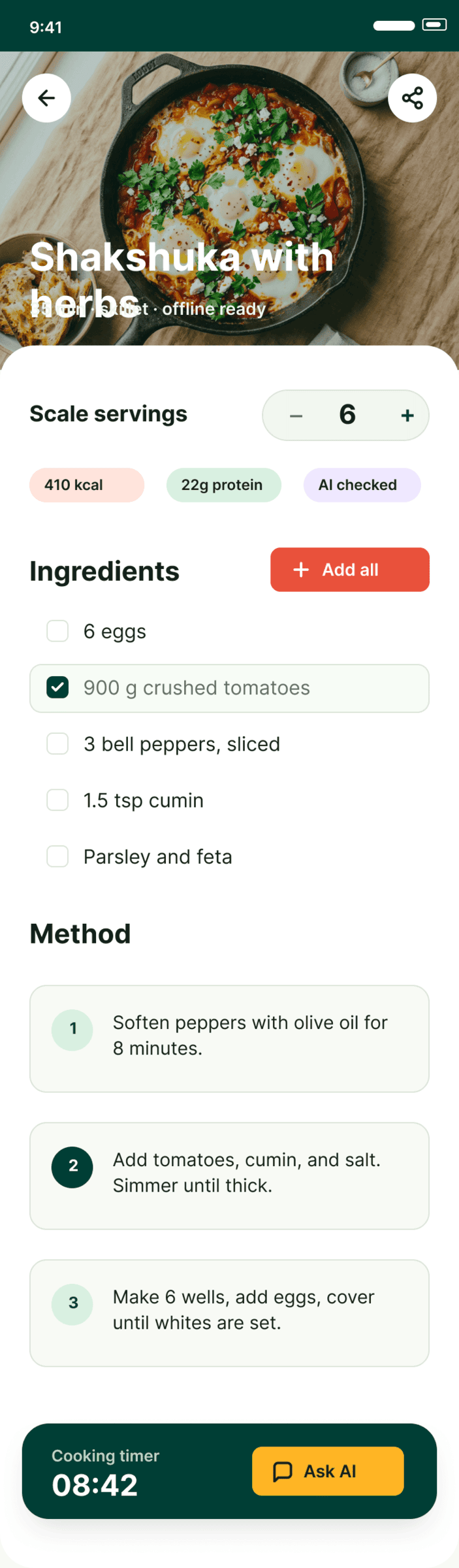
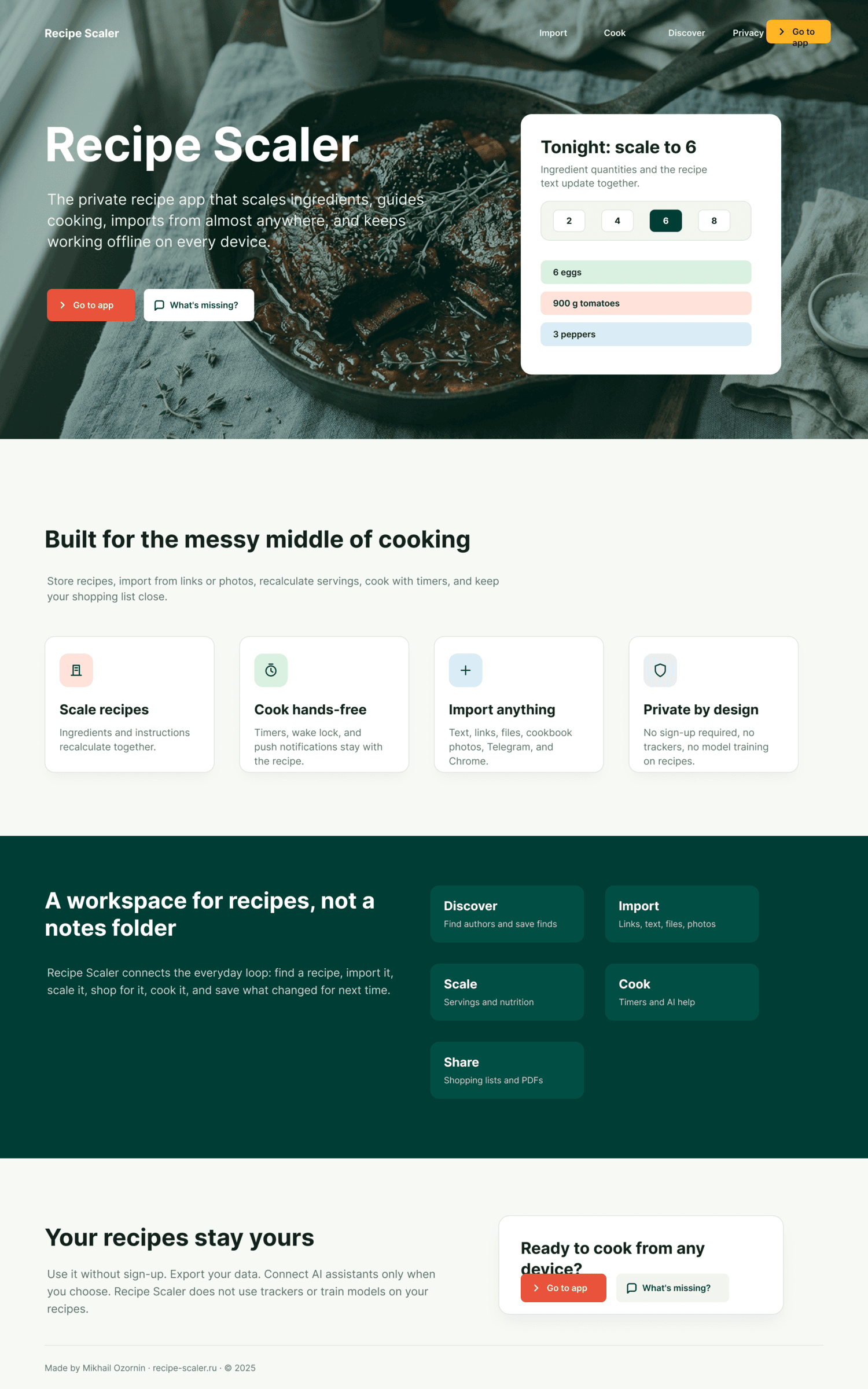
Figma: Cursor + GLM 5.1 (z.ai coding plan)
В целом похуже чем в пейпере. Макет десктопа снизу это я перетащил слой куда нужно, ГЛМ не осилил корректный ДОМ.
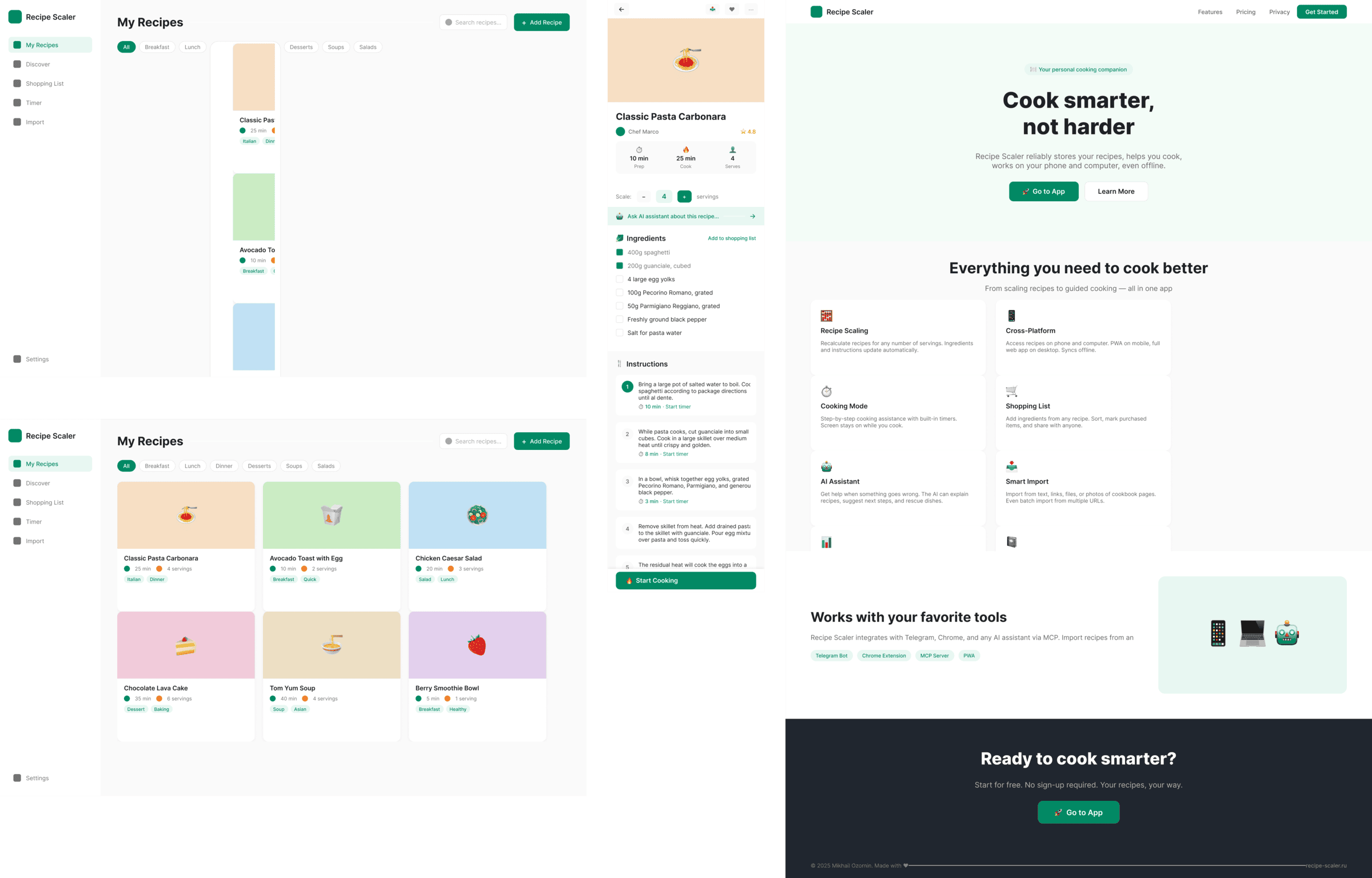
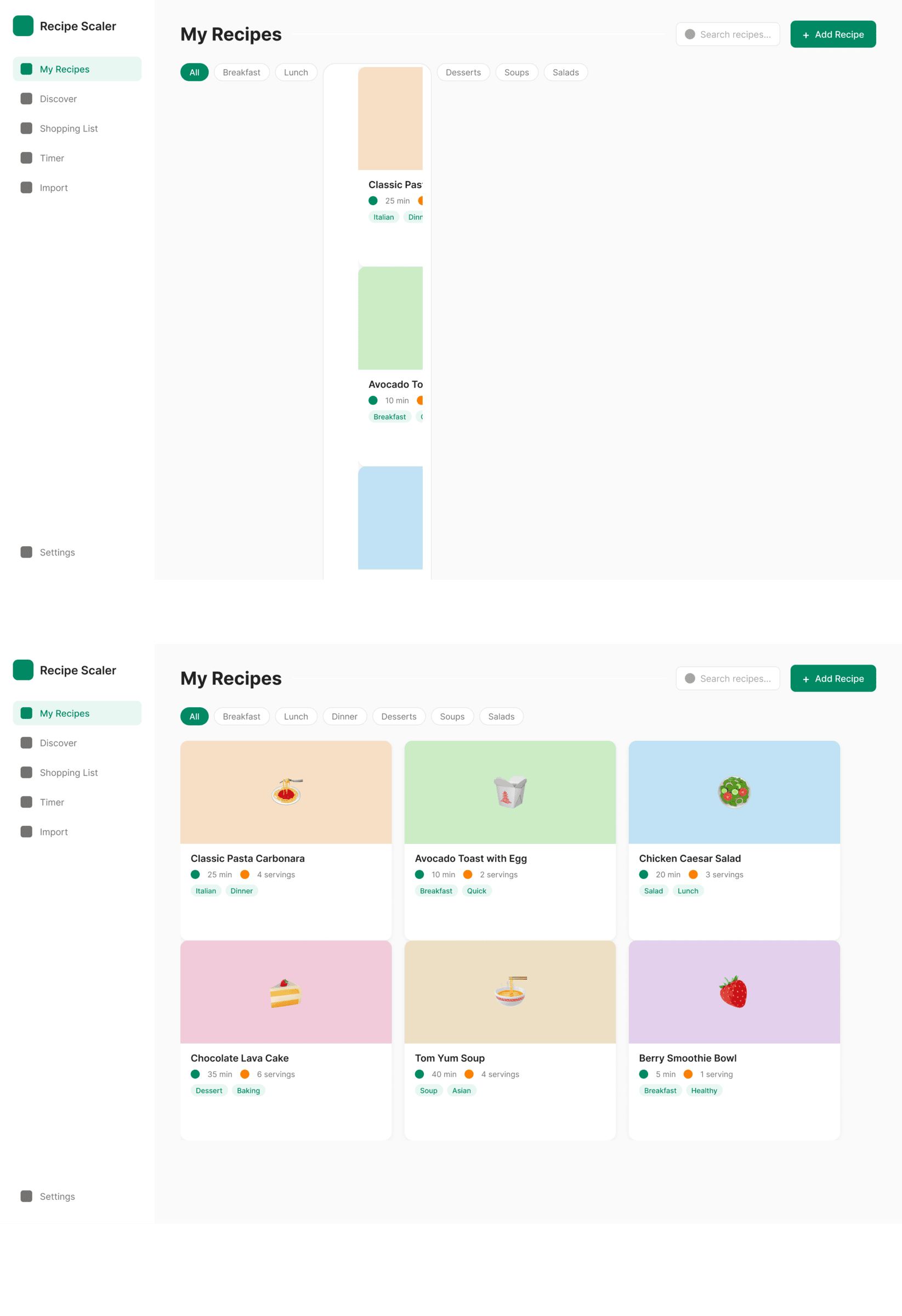
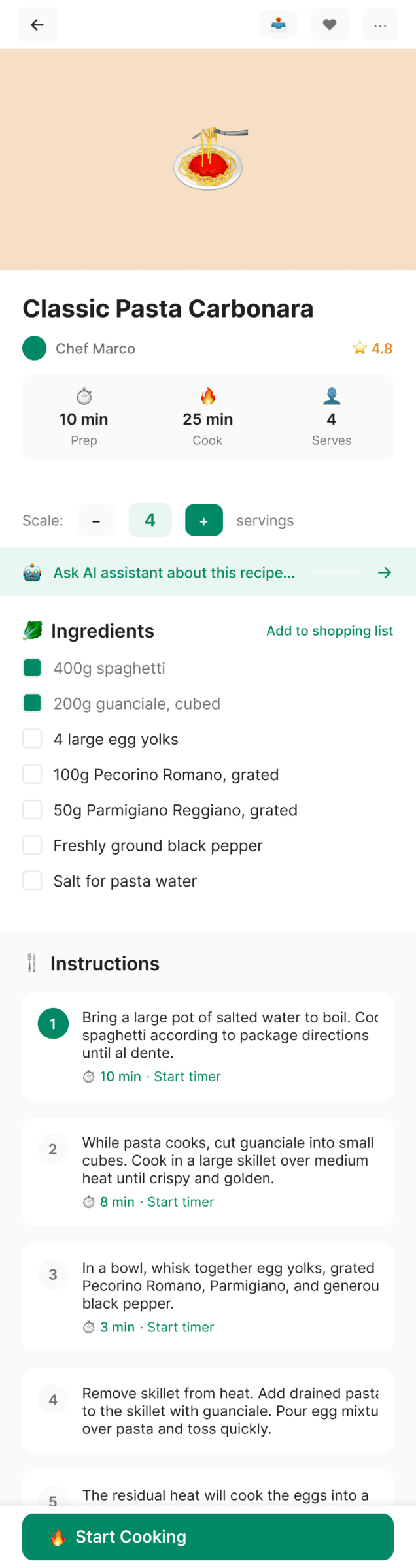
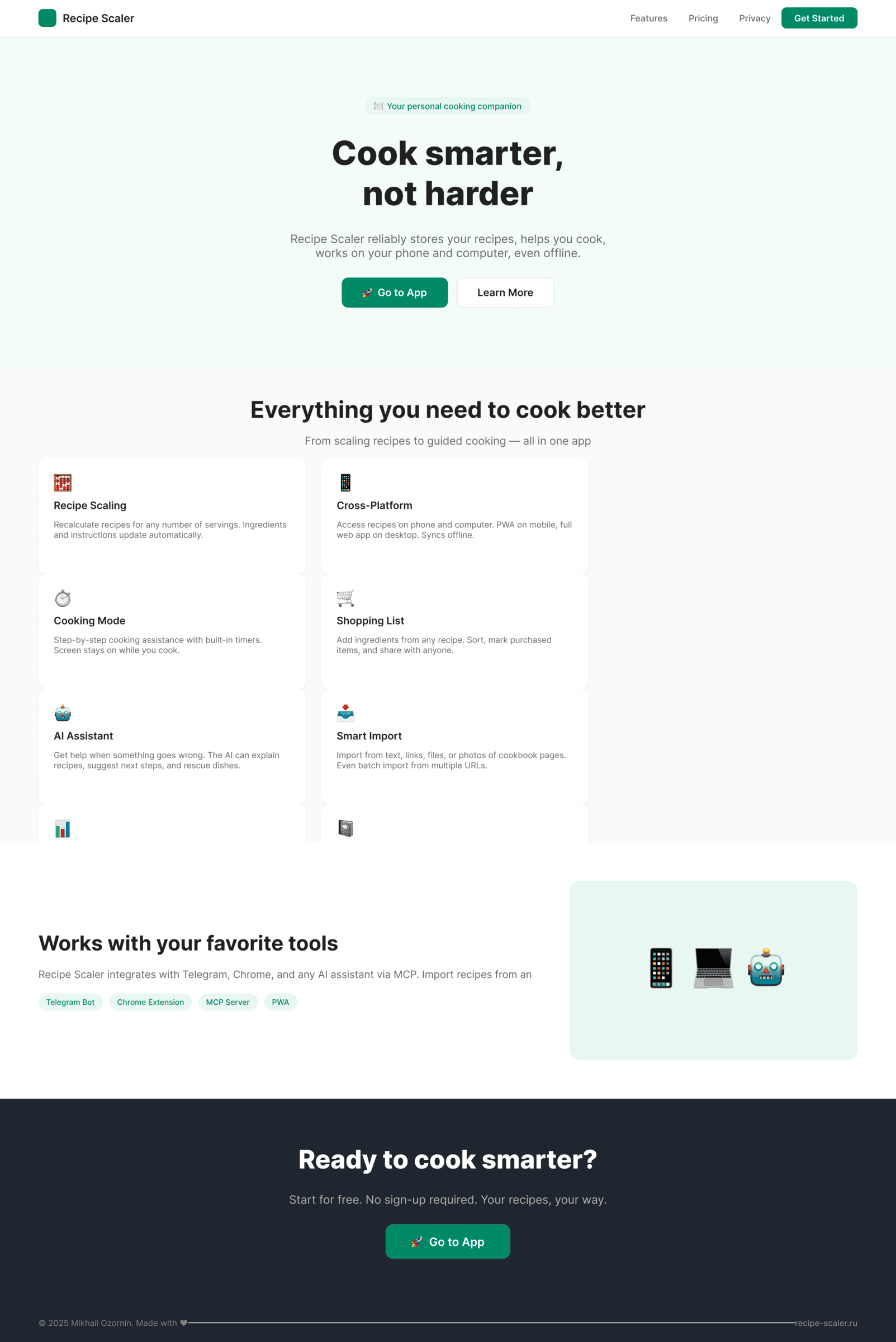
Cursor + Composer 2
Катастрофически плохо, хуже чем в пейпере.
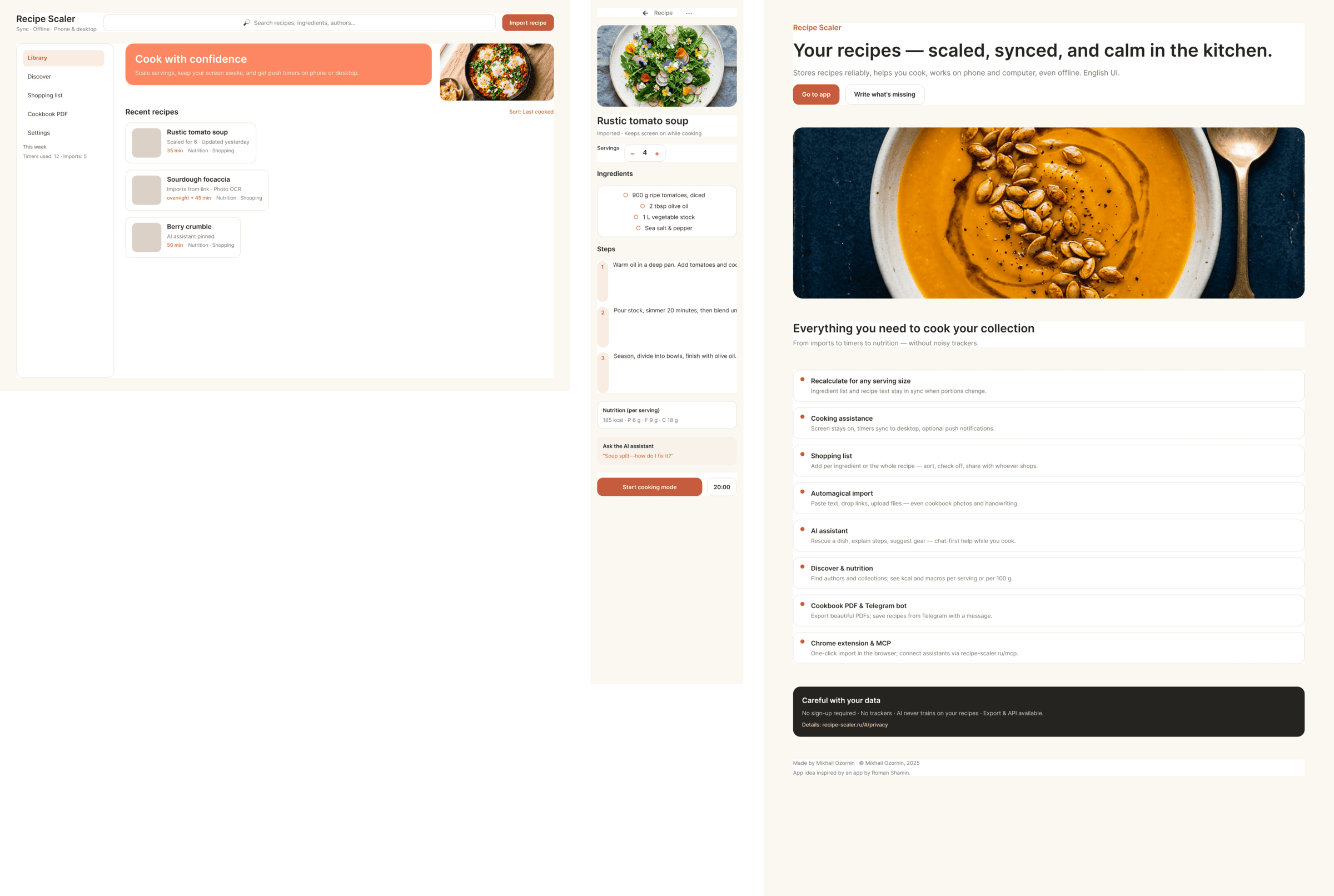
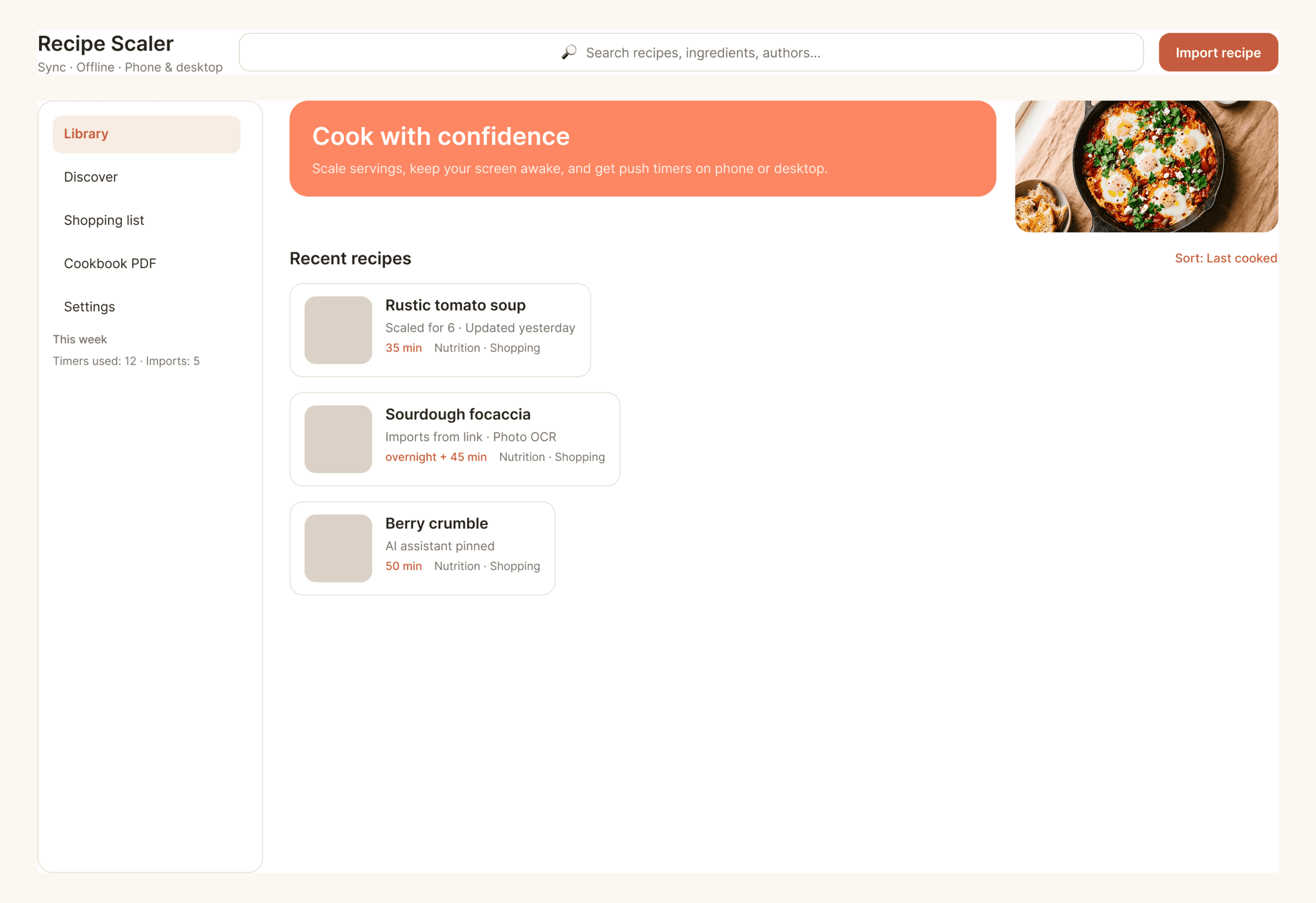
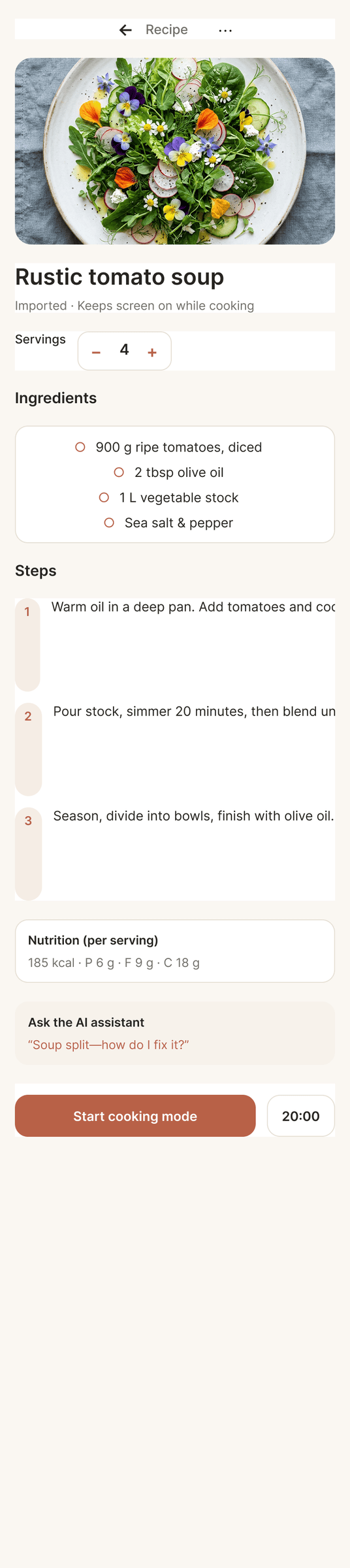
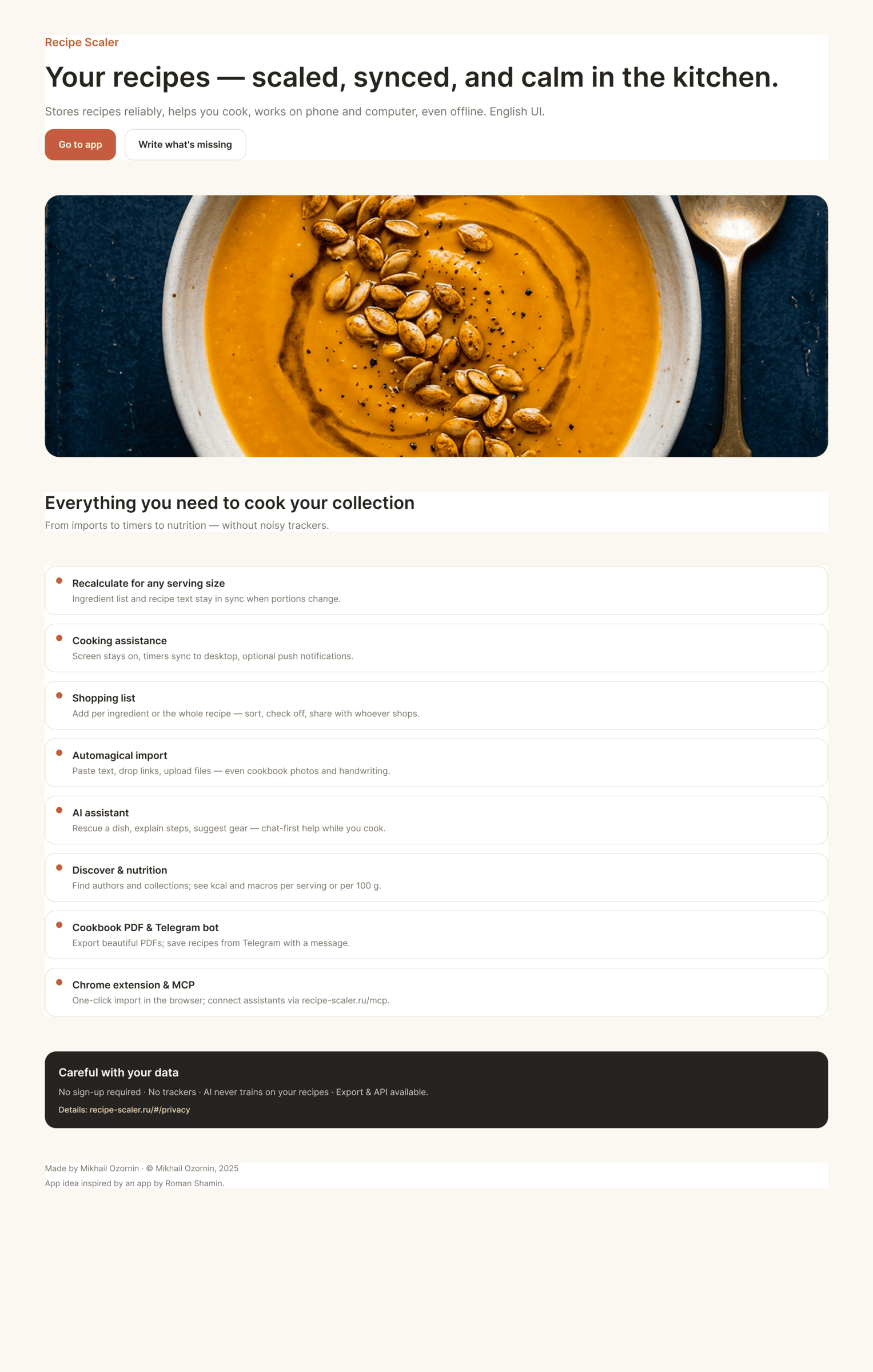
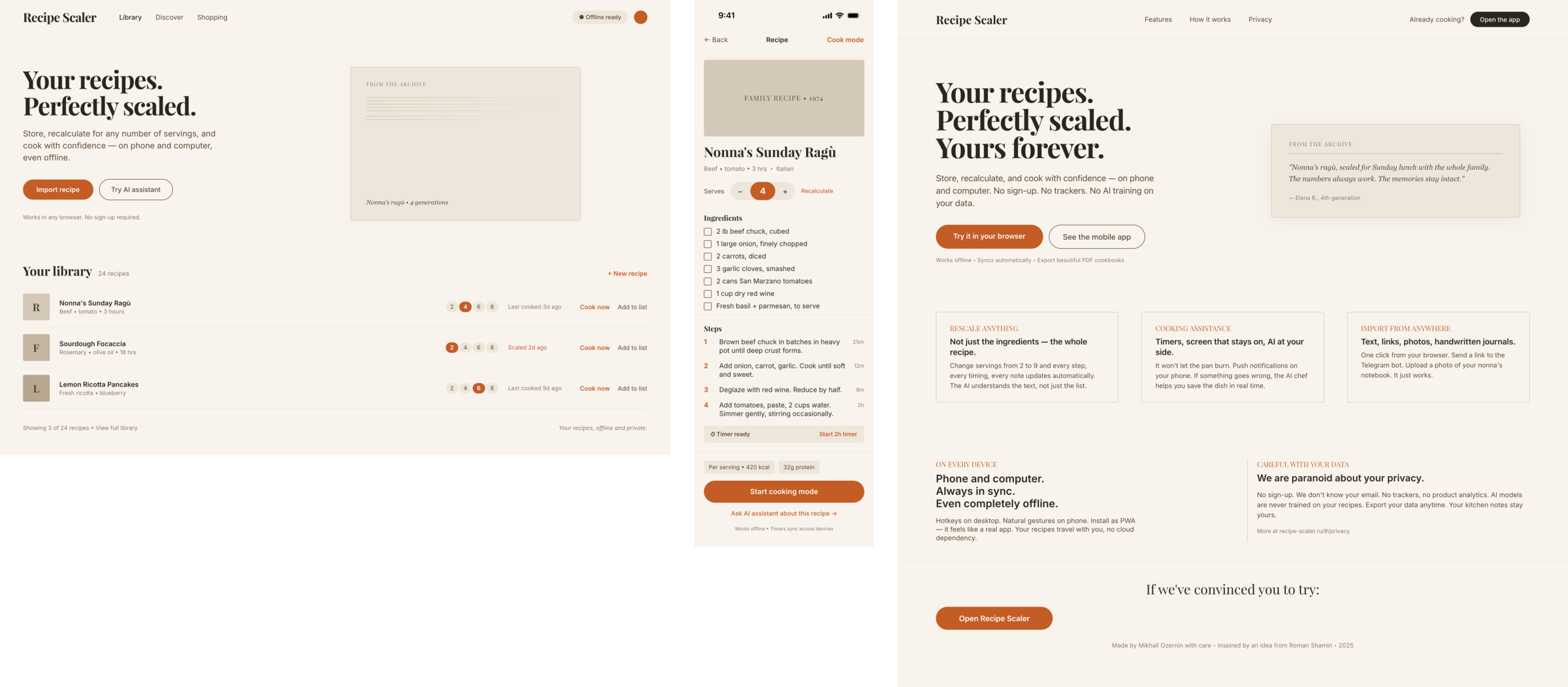
После основного эксперимента я реши попробовать дать скилл Impeccable и посмотреть как он повлияет. Тот же самый промт, но со скиллом. Полный конфиг — Claude Code + Opus 4.7, xhigh + Frontend Design Skill
Сделал только один десктопный экран, много жрет, еще более фенси, чем было. Один экран сожрал 44% 5h · pro-квоты в клод коде. Как будто Опус стал еще более опусным и началось какое-то горе от дизайн-ума. Каждый пиксель кричит «смотри какой я красивый». Ошибки есть, но дизайн стал еще более дизайнерским.
4 Сколько все это стоило, вы спросите
В целом в таблице есть цены, доллары в Курсоре виртуальные (входили в подписку), остальные реальные.
~20 $ — модели
16 $ — Paper Pro с бо́льшим лимитом на MCP.
3×20 $ — подписки Клод, Кодекса и Курсора, но они уже были.
Самый дорогой вариант стоил бы 12,30 $ (Курсор + Опус 4.7), самый дешевый — 0,03 (Минимакс 2.7), разница — 410 раз. Опус работал не на 100%, если бы я включил макс-ризонинг, то было бы примерно ×2.
5 Будущие эксперименты
Что хотелось бы проверить еще, что не вошло в эту серию:
- Проверить со скиллами: насколько те или иные скиллы могут улучшить дизайн.
- Проверить, задав стили, юзерсценарии и прочий контекст.
- Проверить, разрешив задавать уточняющие вопросы: про задачи, продукт, стиль и пользователя.
- Проверить, что будет, если дать ему грубый скетч интерфейса и довести до ума.
- Дать существующий экран и попросить добавить стиля или улучшить только интерфейс без полной переделки структуры.
- Дать почитать советы Горбунова по верстке и проверить снова.
6 Выводы
- Опус — на коне. Дорого и офигенно. Удивительно, что следующим идет даже не GPT. Ни 5.4, ни даже 5.5 и близко не стоят. Китайские модели, да даже авто-режим Cursor, делает лучше. Код GPT 5.4 пишет хорошо, объясняет и делает анализы — хорошо. Дизайн — провально.
- Китайские модели оверфиттятся на метрики и бенчмарки. В целом все модели за пределами больших лаб такие. По метрикам SWE они уже догнали и обогнали Опус, в реальной же жизни не способны сделать простую задачу. Некоторые даже не справляются с корректным вызовом тулов. Типичный пример — Минимакс 2.7, по всем метрикам — он очень хорош, в дизайне не может ничего. Хорош он в итоге только по скорости и цене (там прямо вау). Кто-то скажет, что дипсик тоже оверфит. Про него так однозначно не скажу: во-первых, дипсик один из макетов сделал заметно лучше, во-вторых у него до сих пор какие-то проблемы с вызовом тулов, как было в версии в 3.2. Лучший результат у тех китайских моделей, которые делают свою работу, не особенно крича — Квен 3.6 (но 3.5 так себе).
- Хорошая модель делает достататочно бессмысленным дизайн самими разработчиками и продактами, если только они не разбираются в дизайне. Редко, но бывают такие. Если нет, то модель сделает быстрее и лучше. Дизайнерам пока еще есть работа, можно выдохнуть на квартал.
P. S.
Раз уж зашли, попробуйте recipe-scaler.ru, зря я что ли столько дизайн-экспериментов проводил? Если каждый десятый зайдет, у меня будет +1000% пользователей сразу.
Если вдруг у кого есть подкаст, внутренние созвоны команды или просто захотите созвониться и поговорить про все это — зовите. В Мск и Питере могу и очно. mike.ozornin@gmail.com или t.me/mikeozornin.
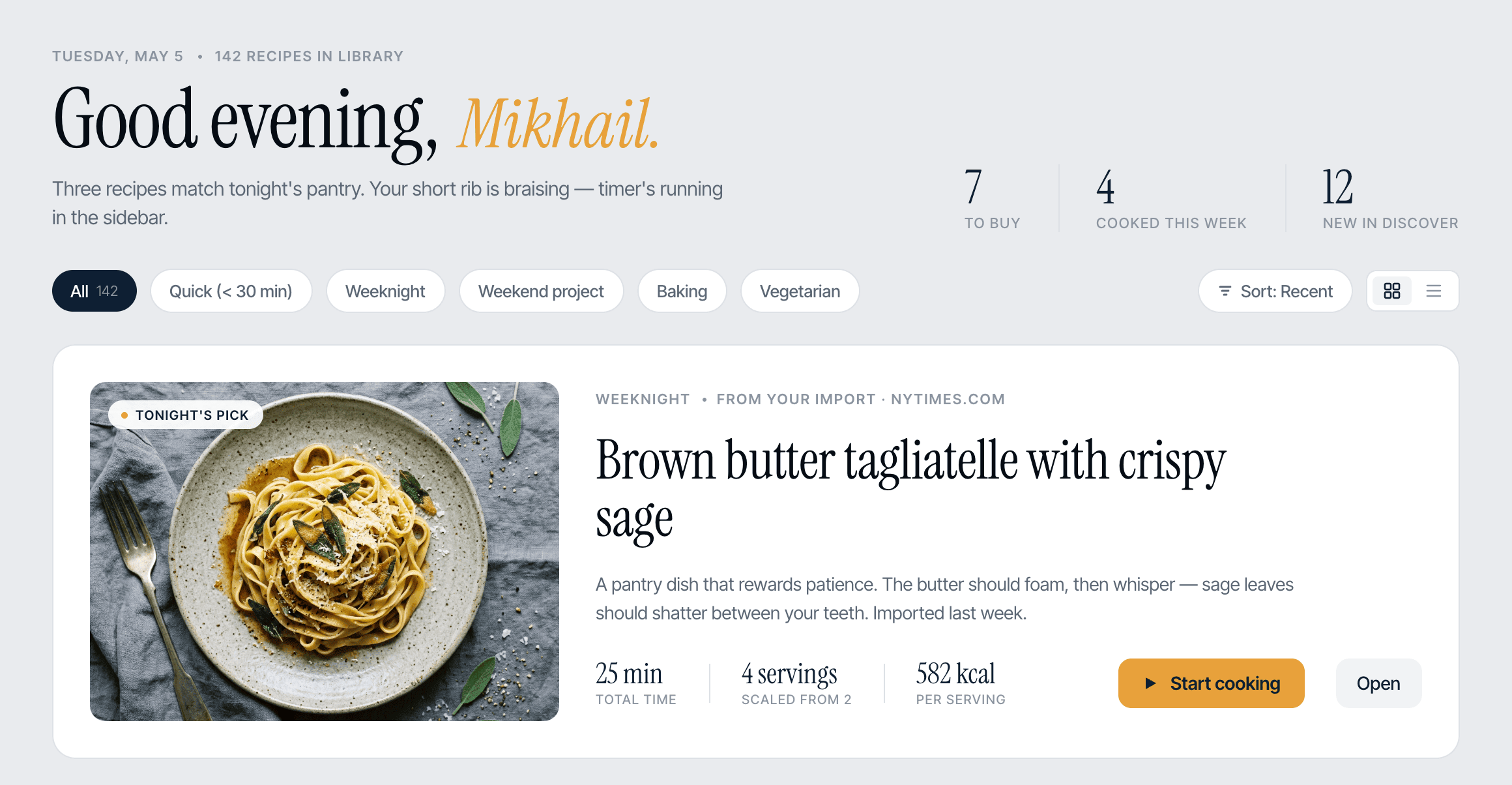
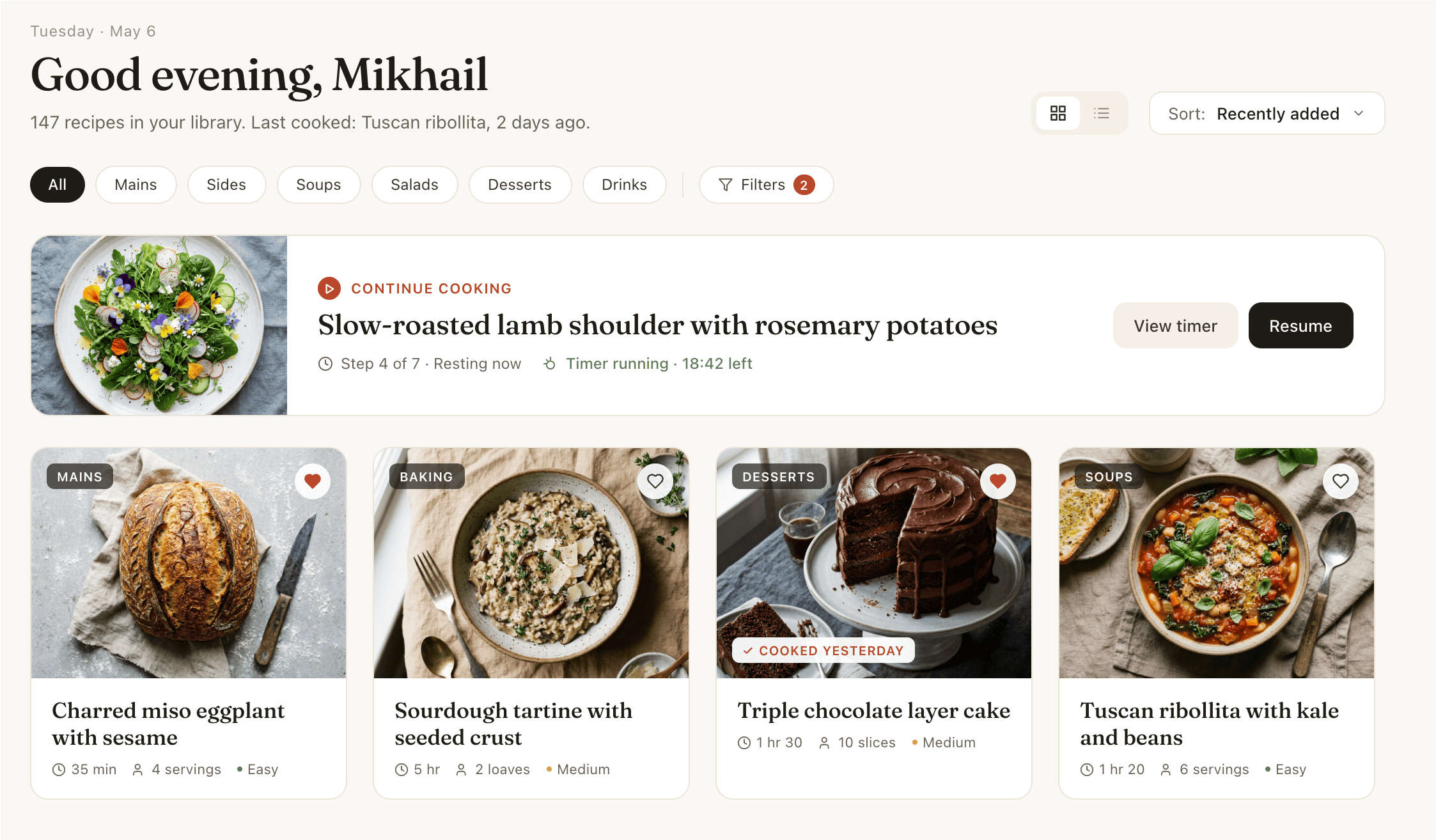
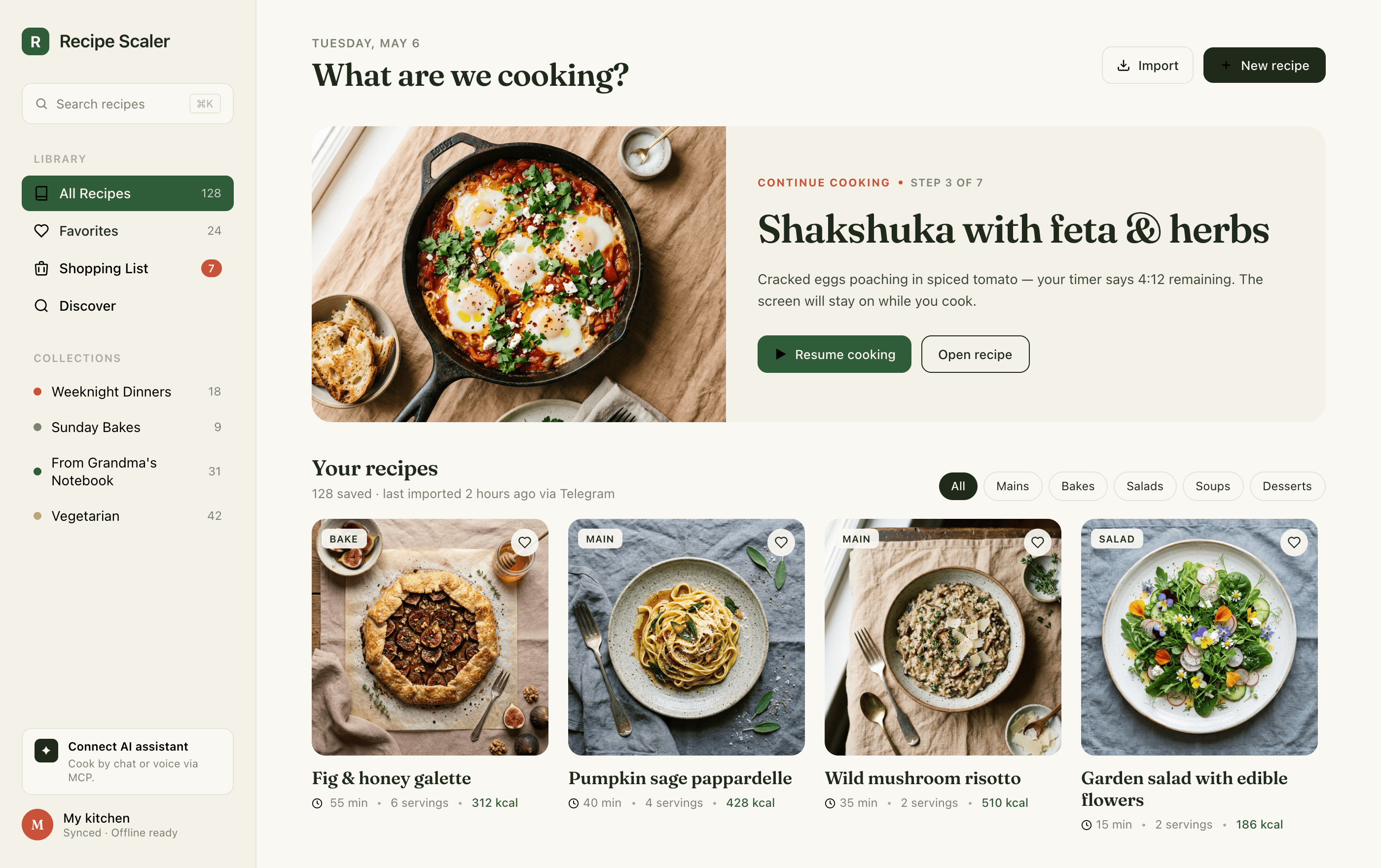
Кстати, вот как выгдядит блок аттачей поста:
upd. Добавлены новые модели: gemini 3.5 flash, grok build, mimo 2.5, opus 4.8





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
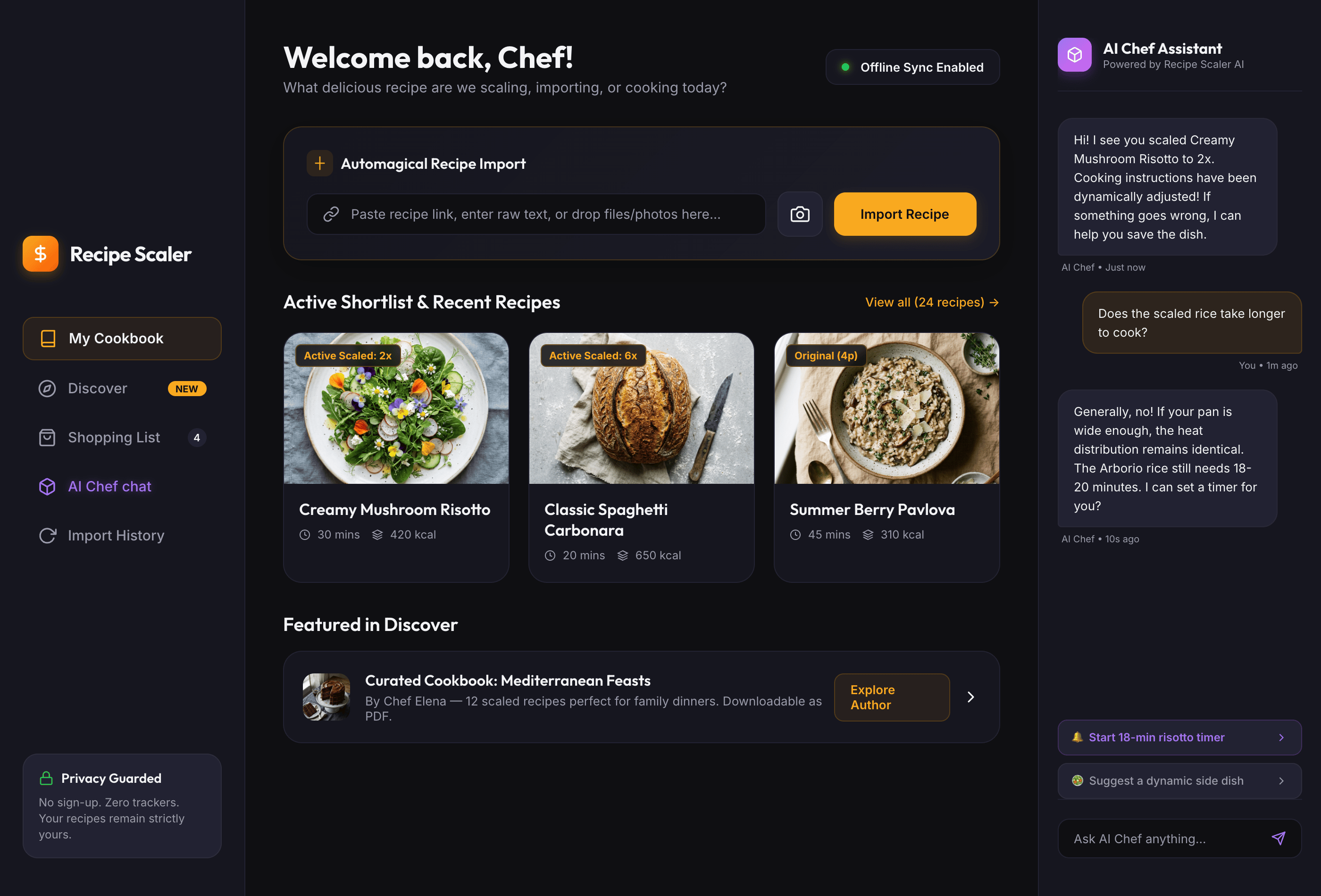{kind=link}
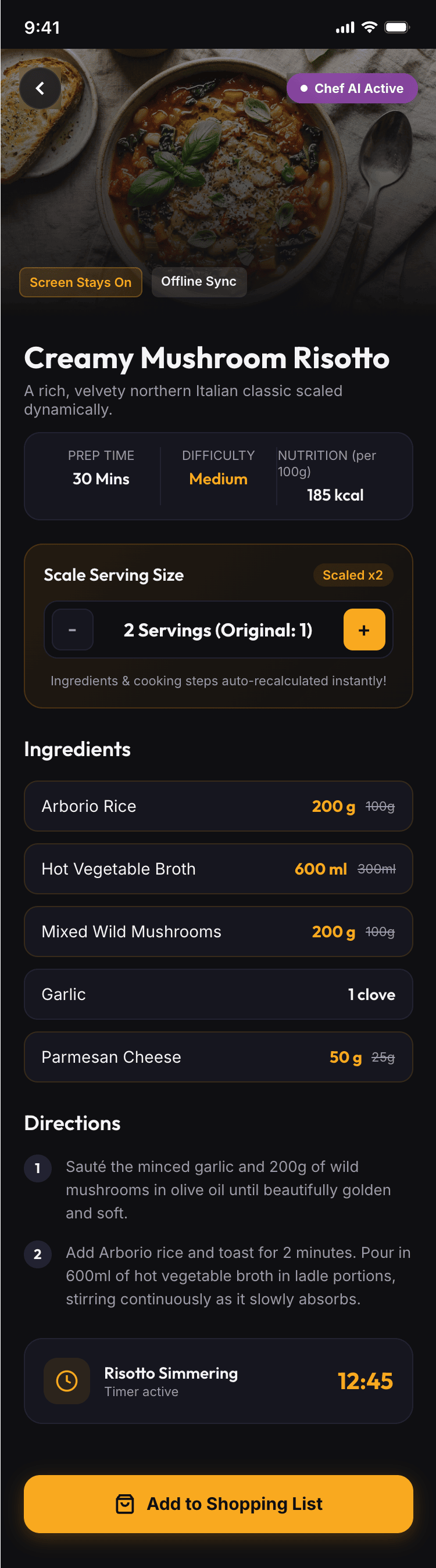{kind=link}
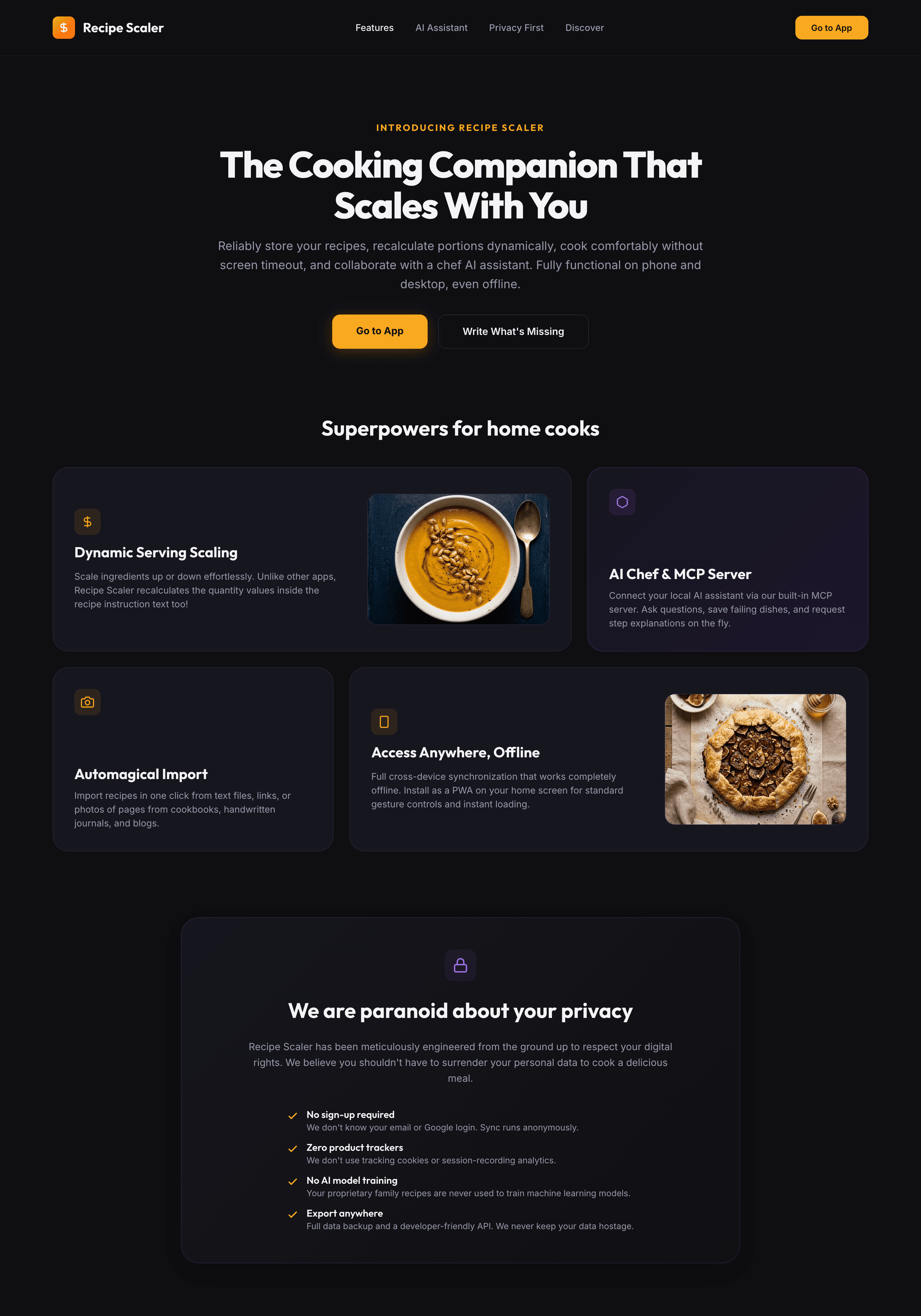{kind=link}
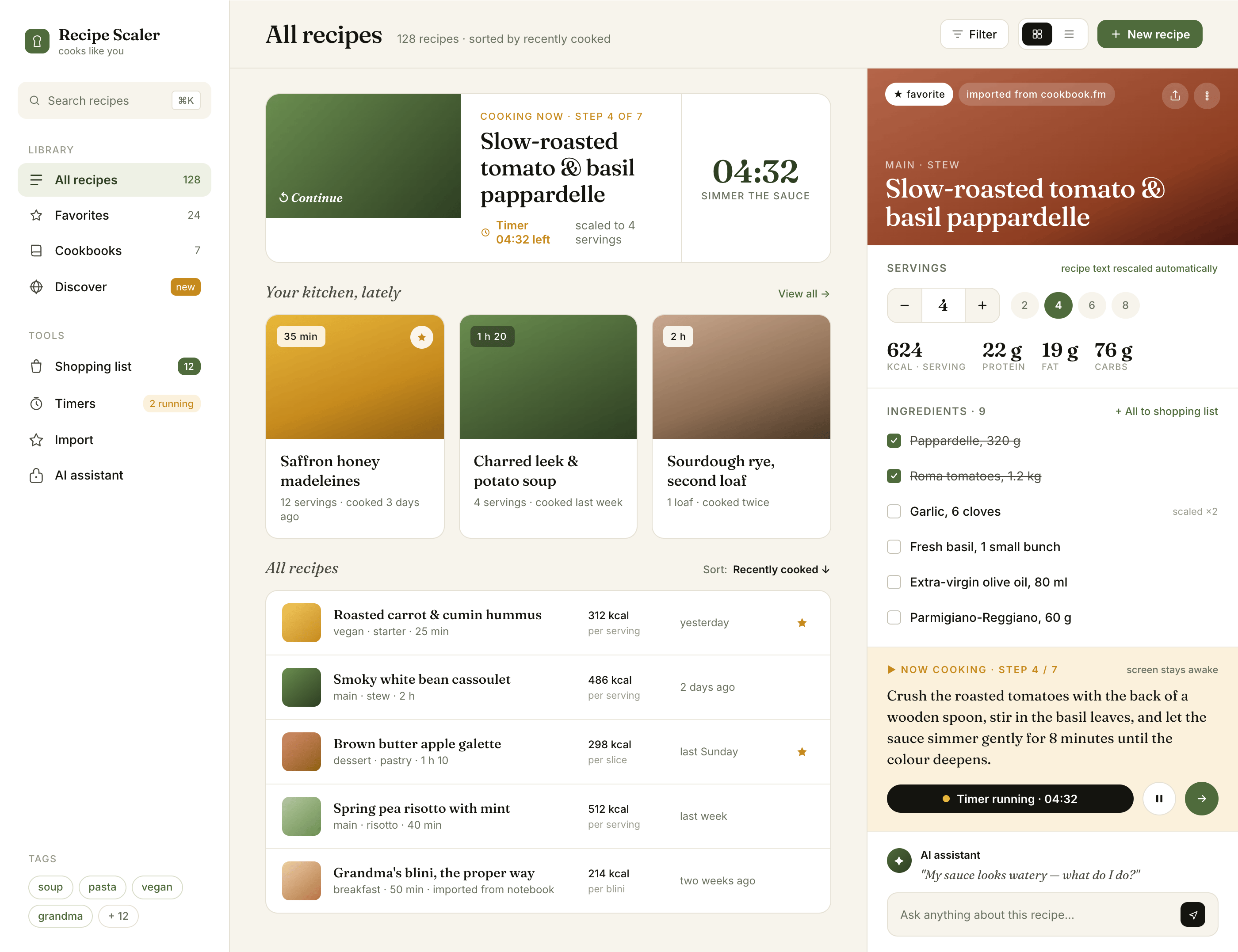{kind=link}
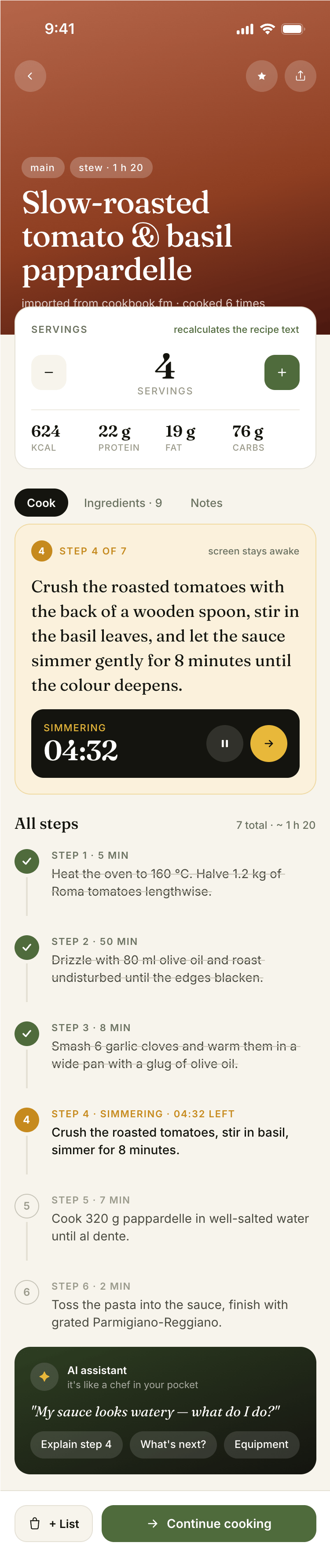{kind=link}
{kind=link}
{kind=link}
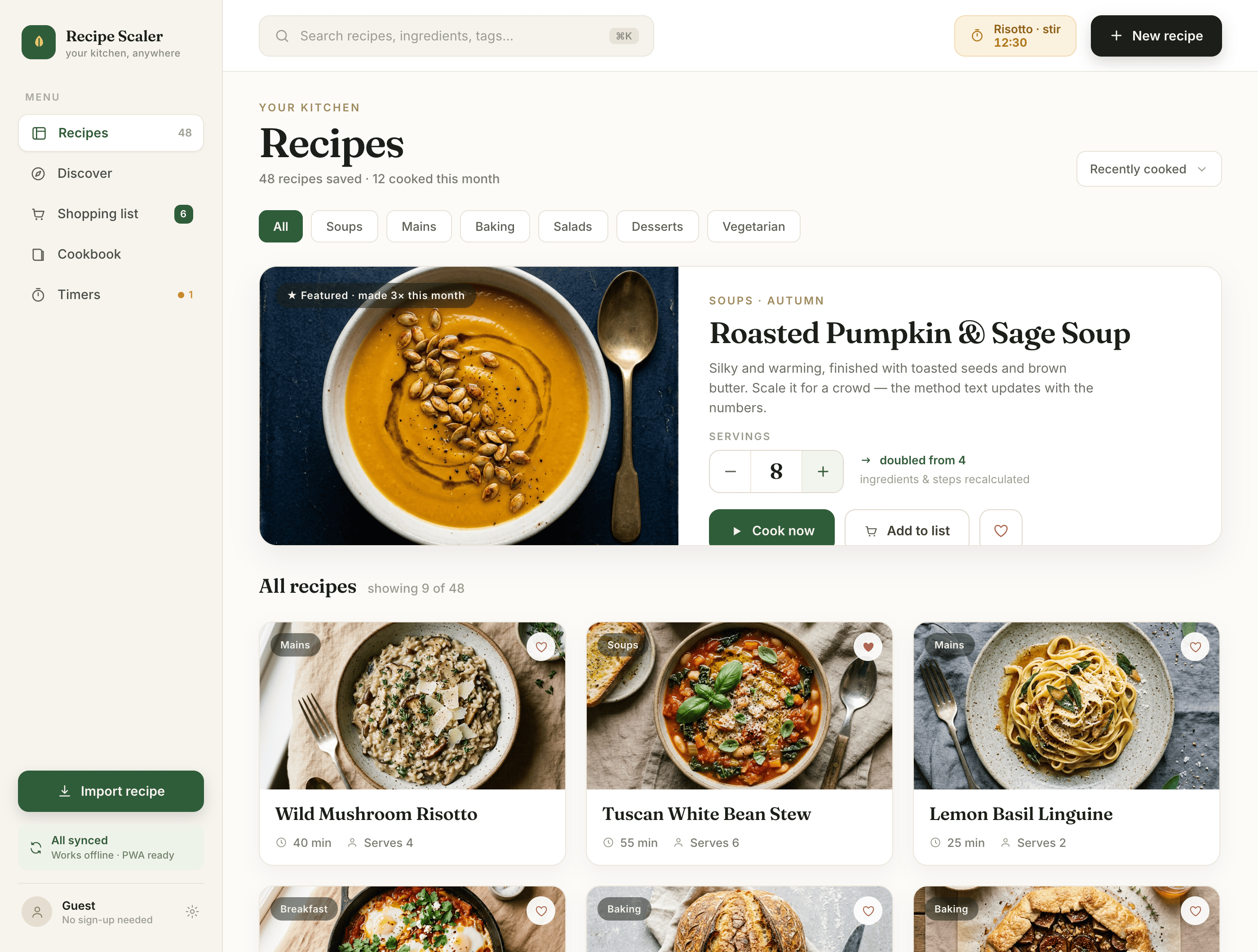{kind=link}
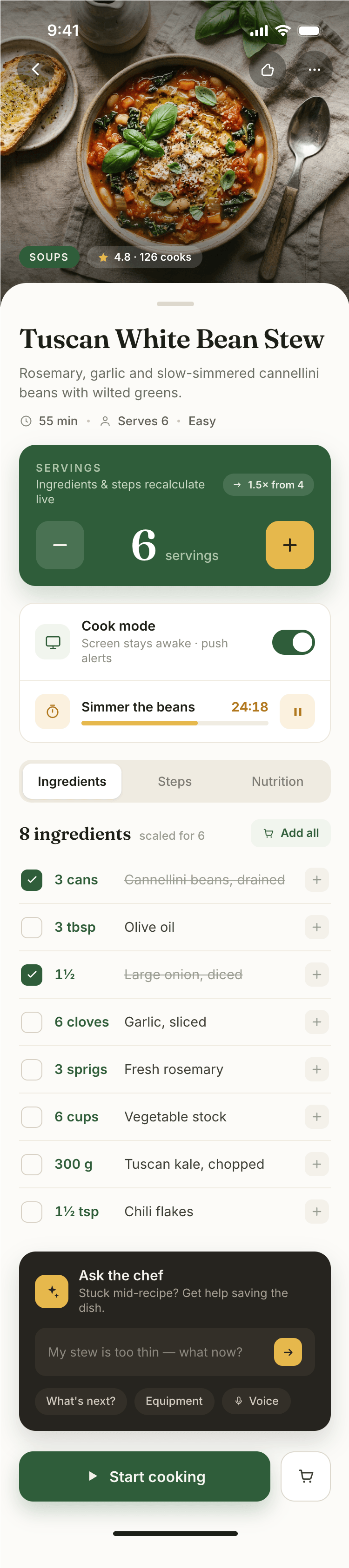{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
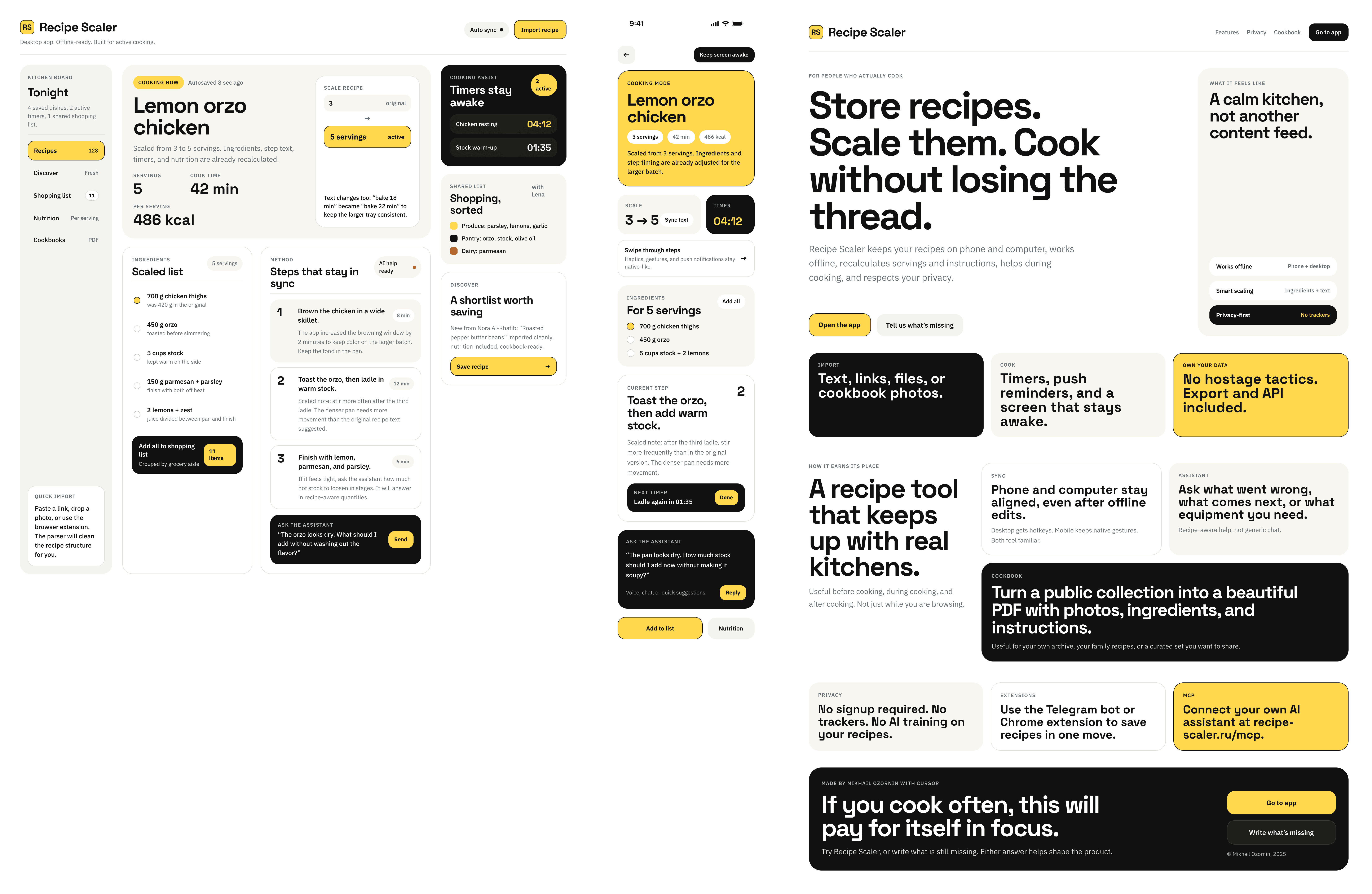{kind=link}
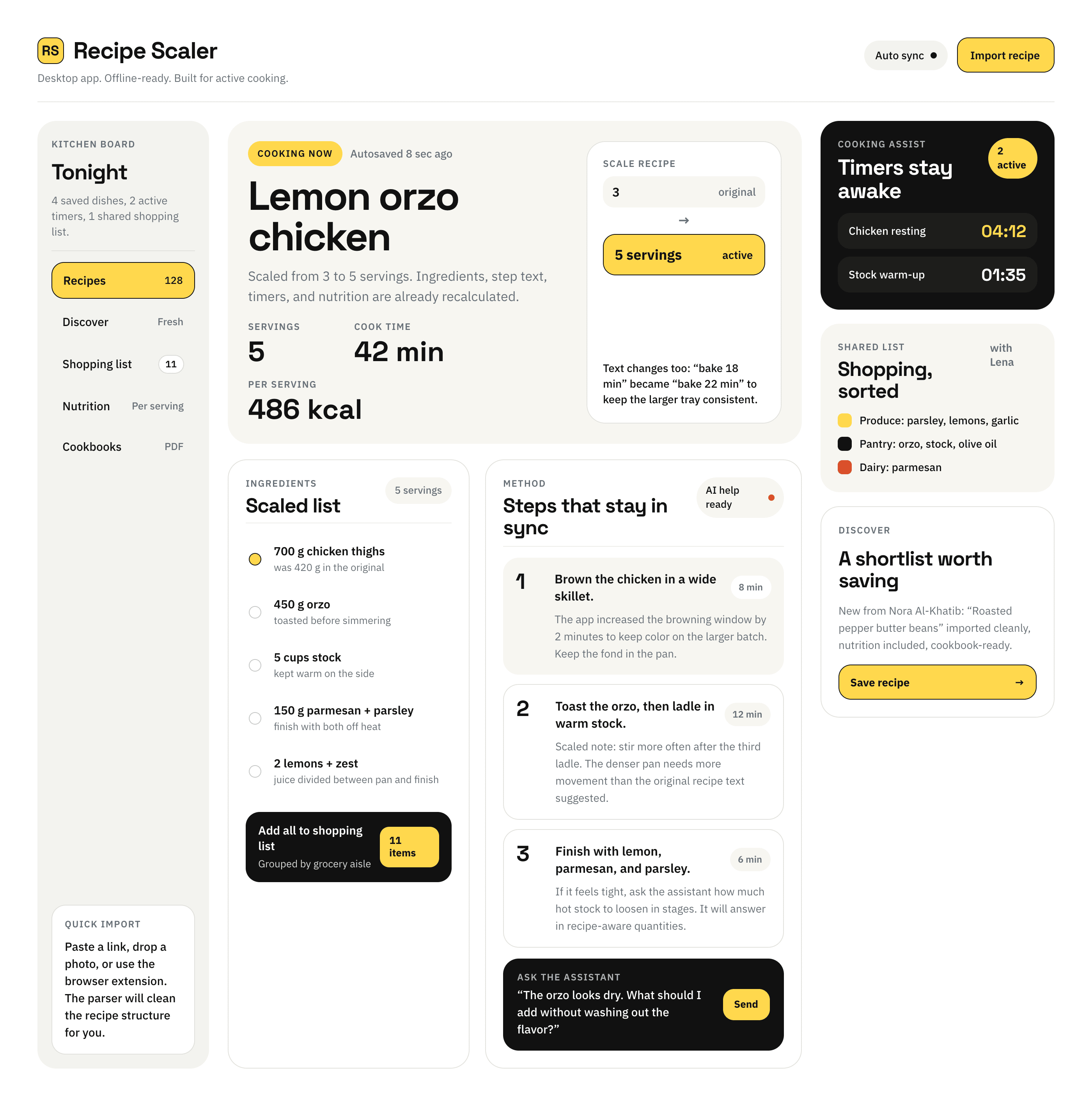{kind=link}
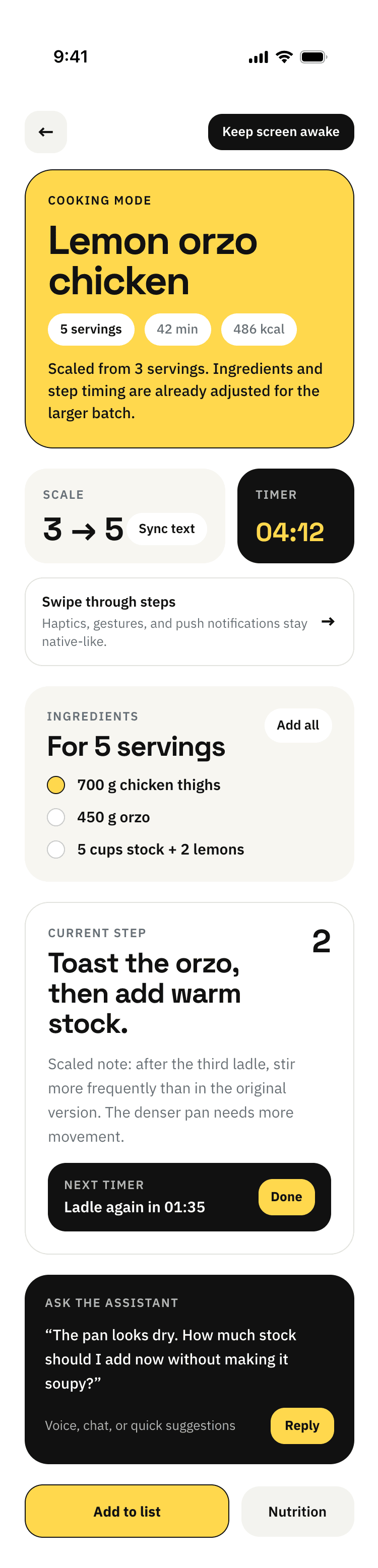{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
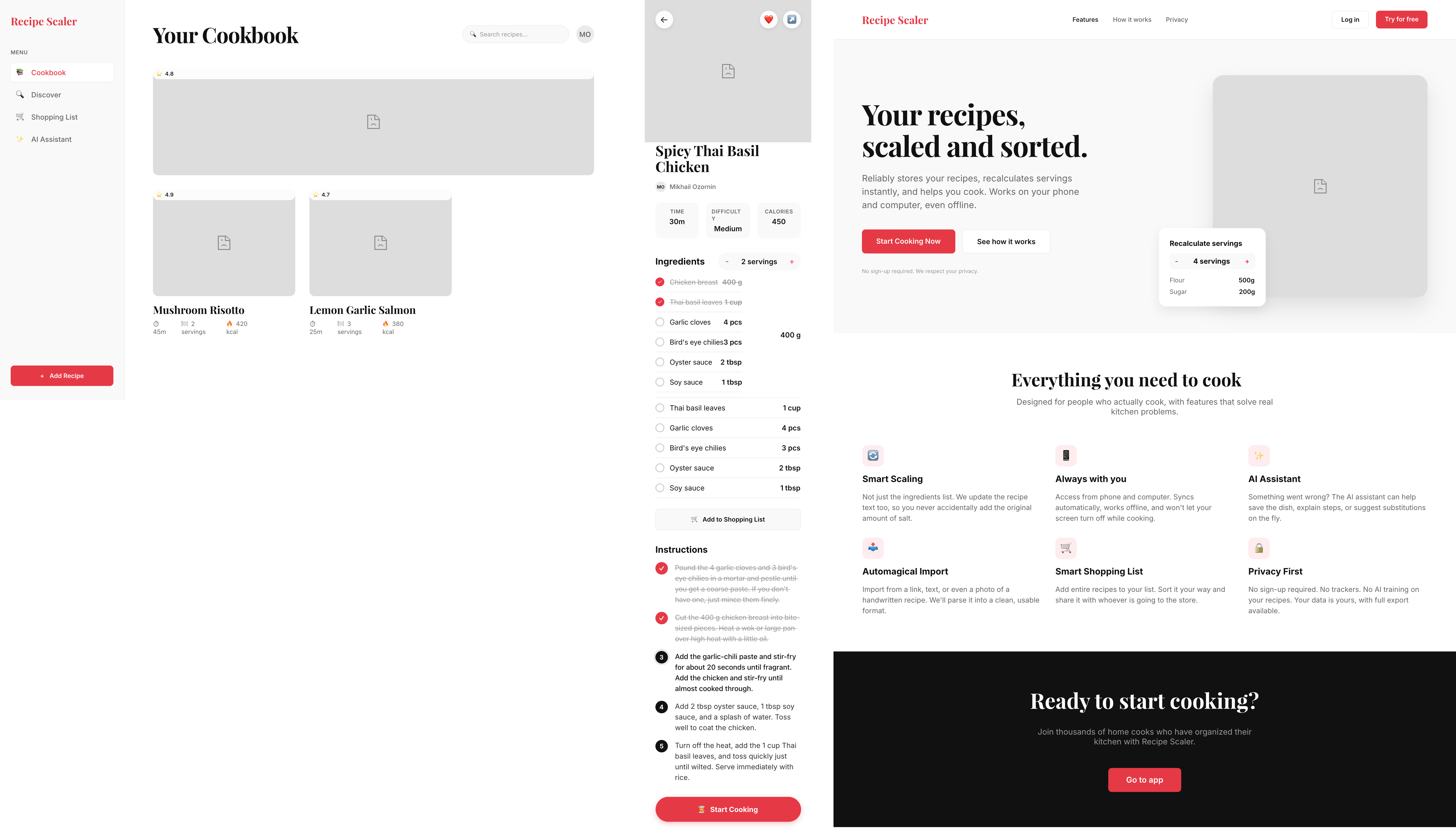{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}