
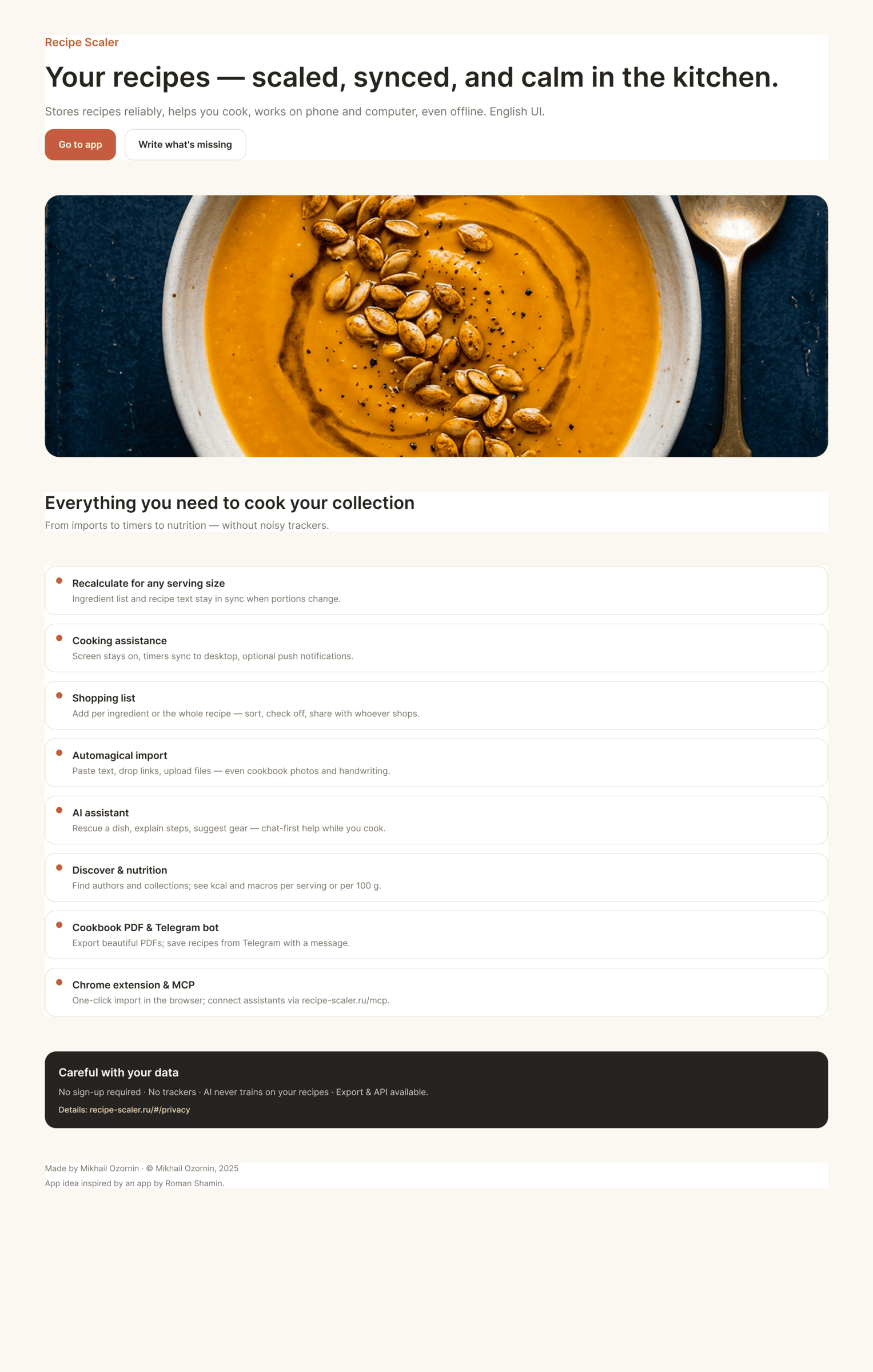
Design with AI: I tested 37 models and I’m showing 146 generated images
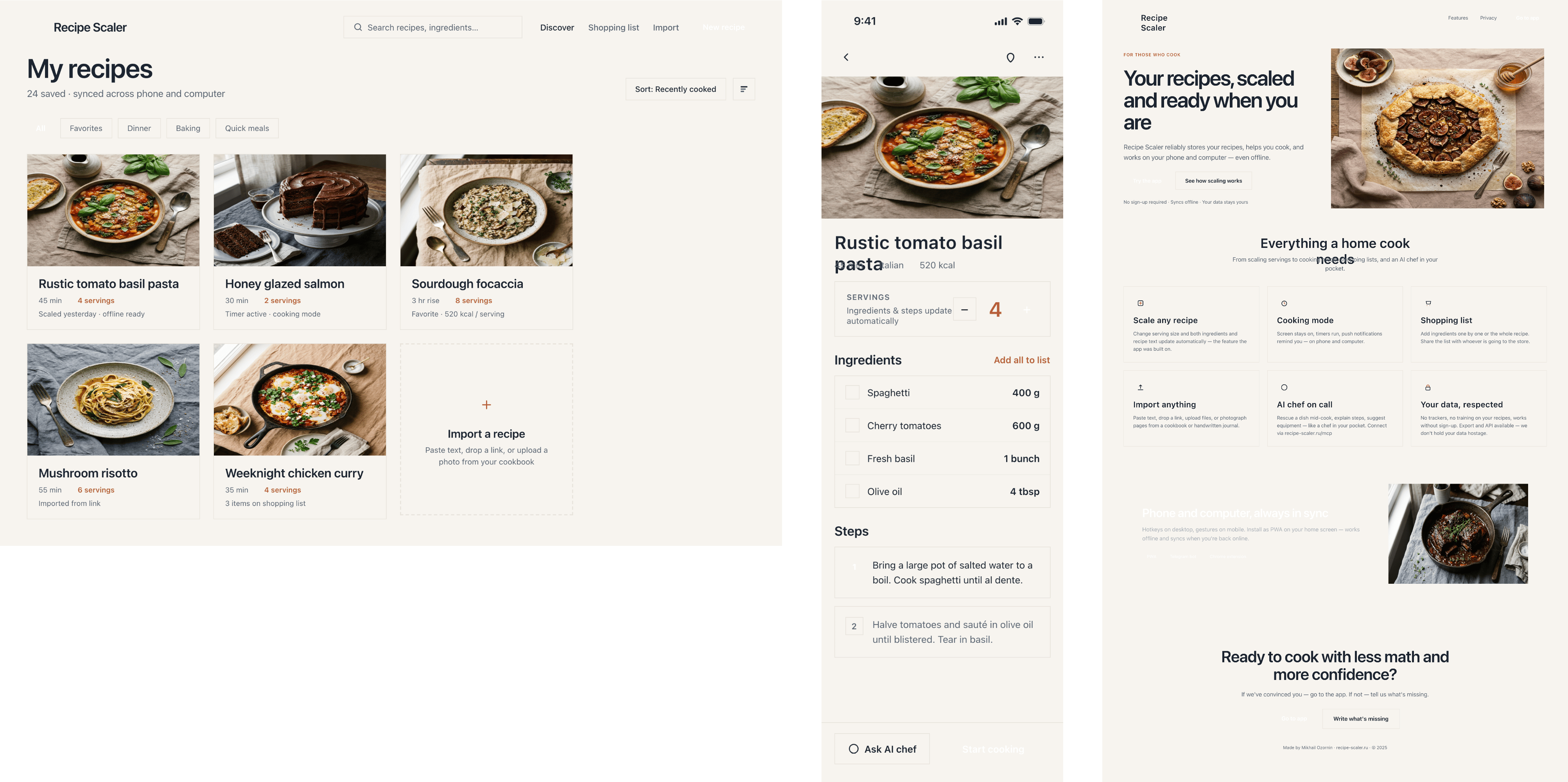
I generated the same task with 38 different agents/models and I’m showing you 150 resulting images. The cost difference between the most expensive and the cheapest option is 410x.
There’s also an original Russian version of this post: mikeozornin.ru/blog/all/llm-and-ui-design
Sometimes colleagues, often non-designers, after announcements of various Claude-Design-type things, ask me what it’s like. How does it design, what is this thing in general. How good a design can you expect, can you take a design system, and how do you bring it to production afterwards. Maybe they want to hear that neural networks will replace not only them, the developers, but designers too — then we’ll go cut tables, roast coffee or work as couriers together.
I decided to check how things stand with AI-design at the beginning of May 2026. The situation is changing fast, in half a year all of this will already be outdated, but for now it’s like this.
1 The experiment plan
I’ll describe the experiment plan: the procedure and the limitations, so that you can first, understand how much you can trust the results, and second, validate or repeat them yourself.
TL;DR; The agents drew three screens: desktop, mobile and a promo page through Paper MCP.
1.1 Procedure
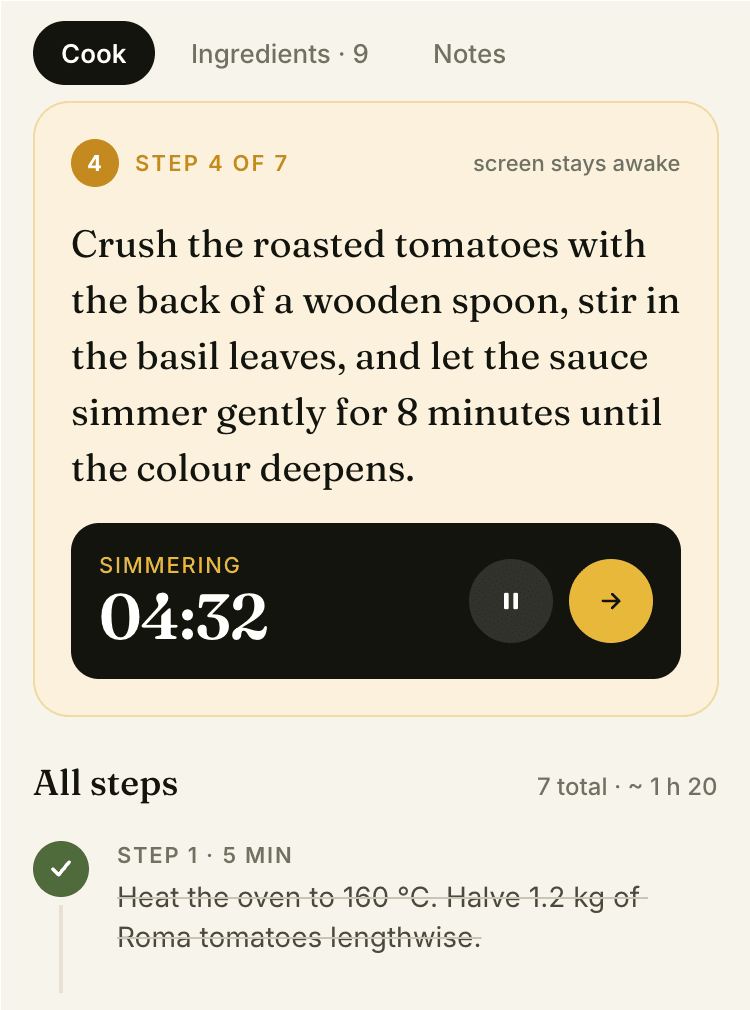
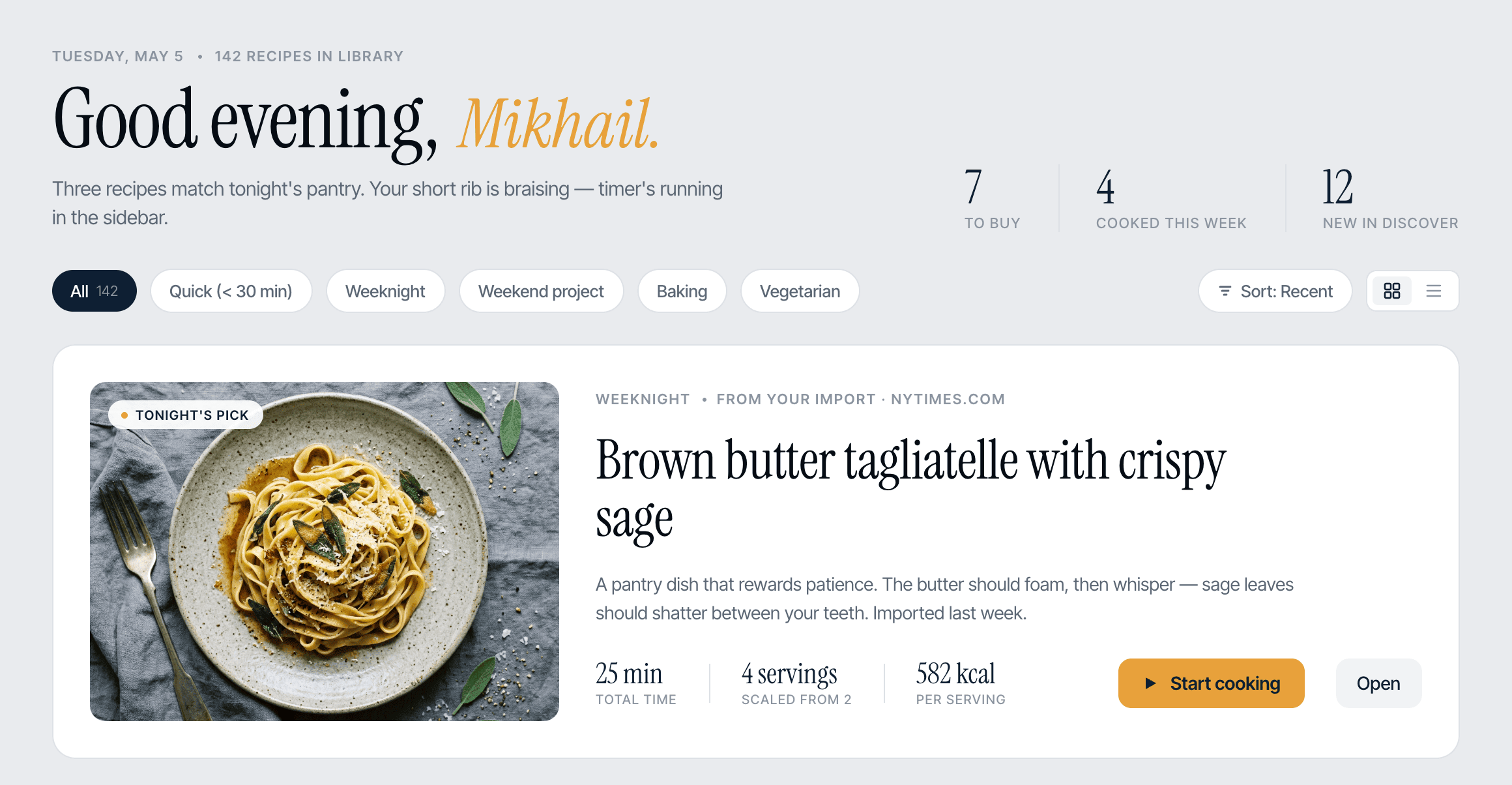
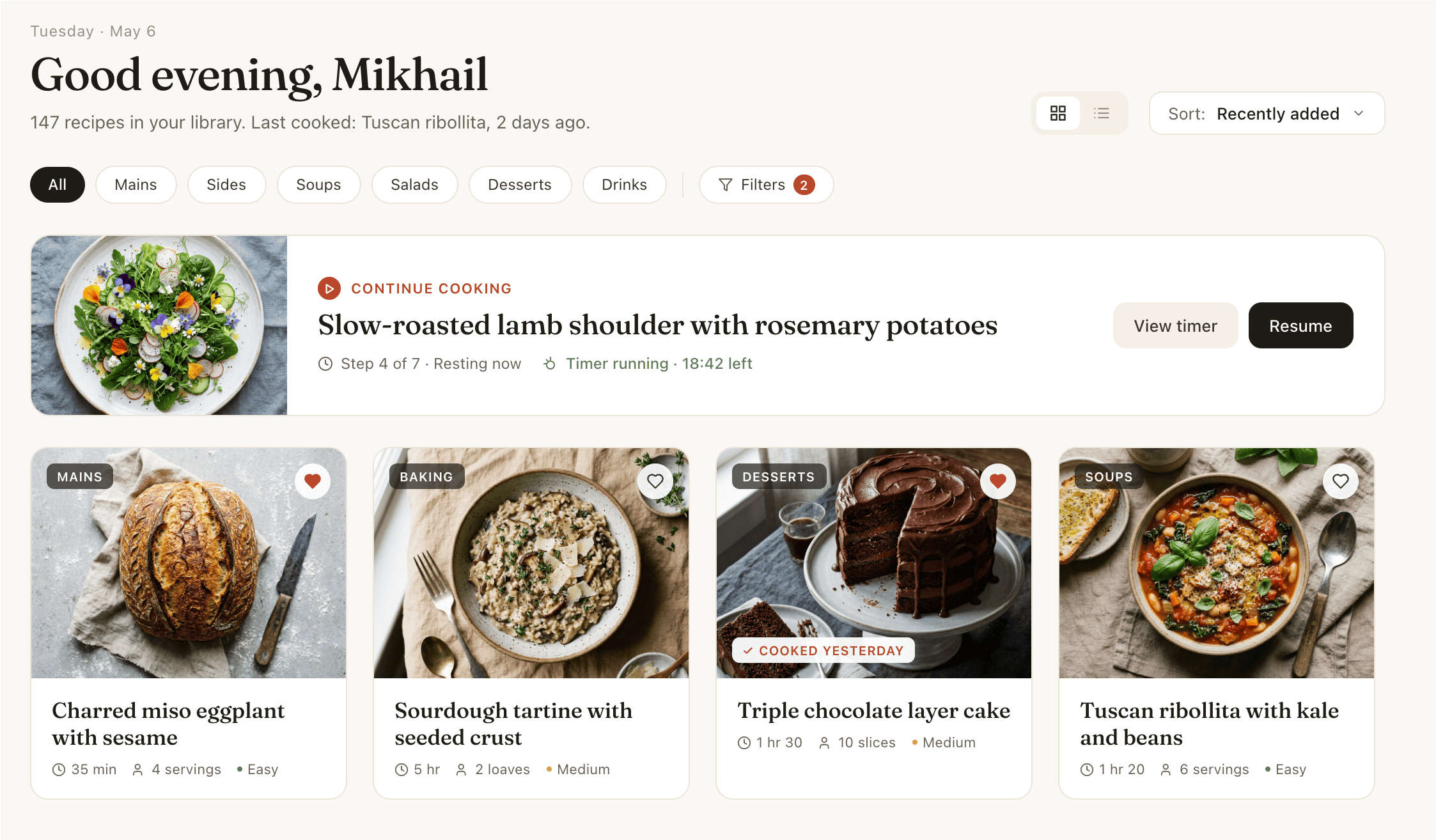
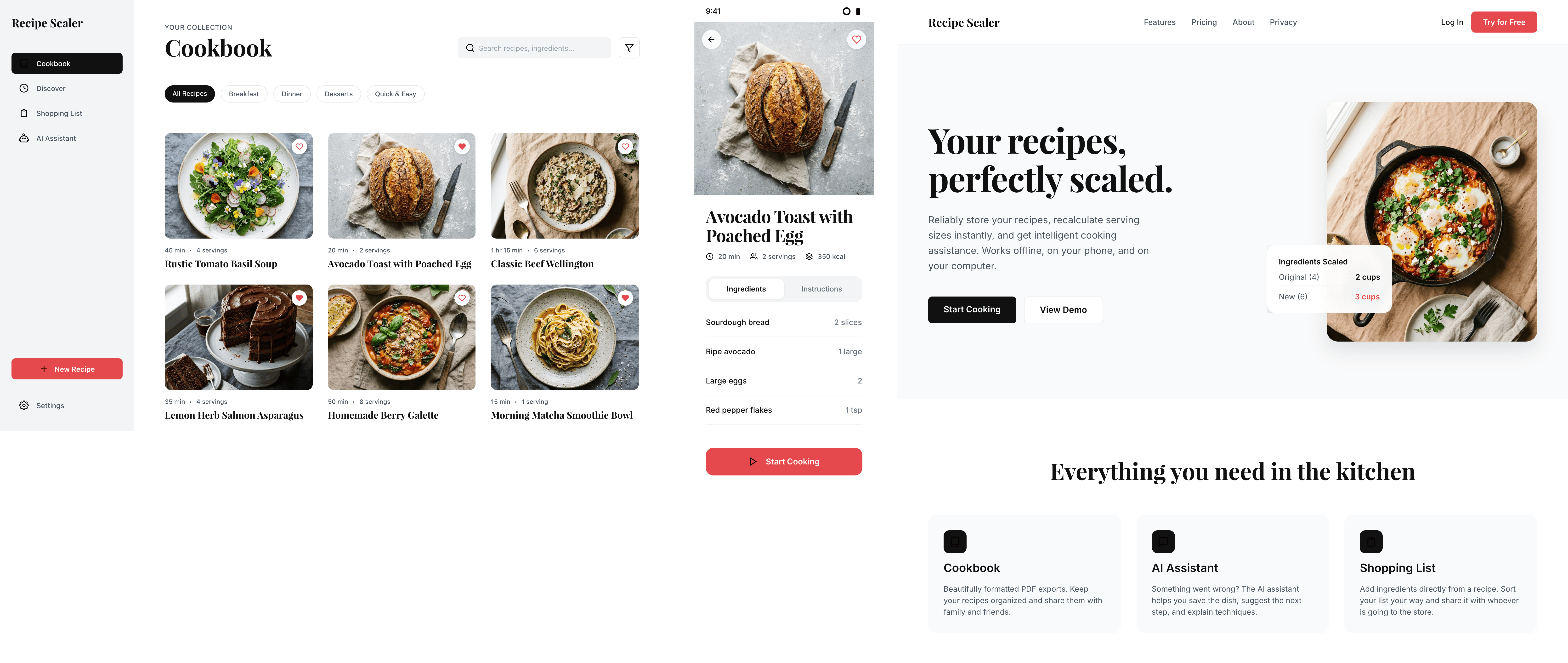
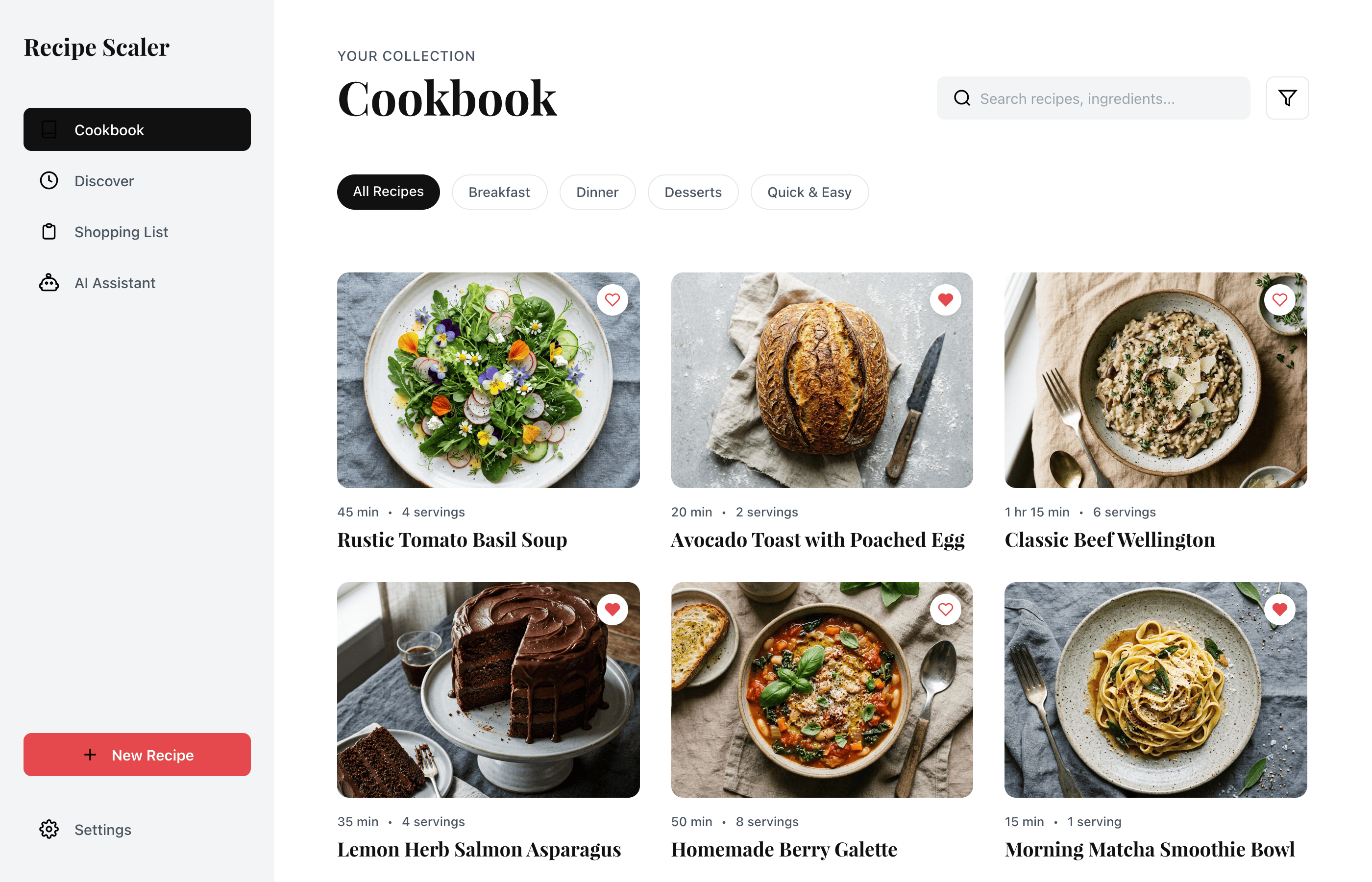
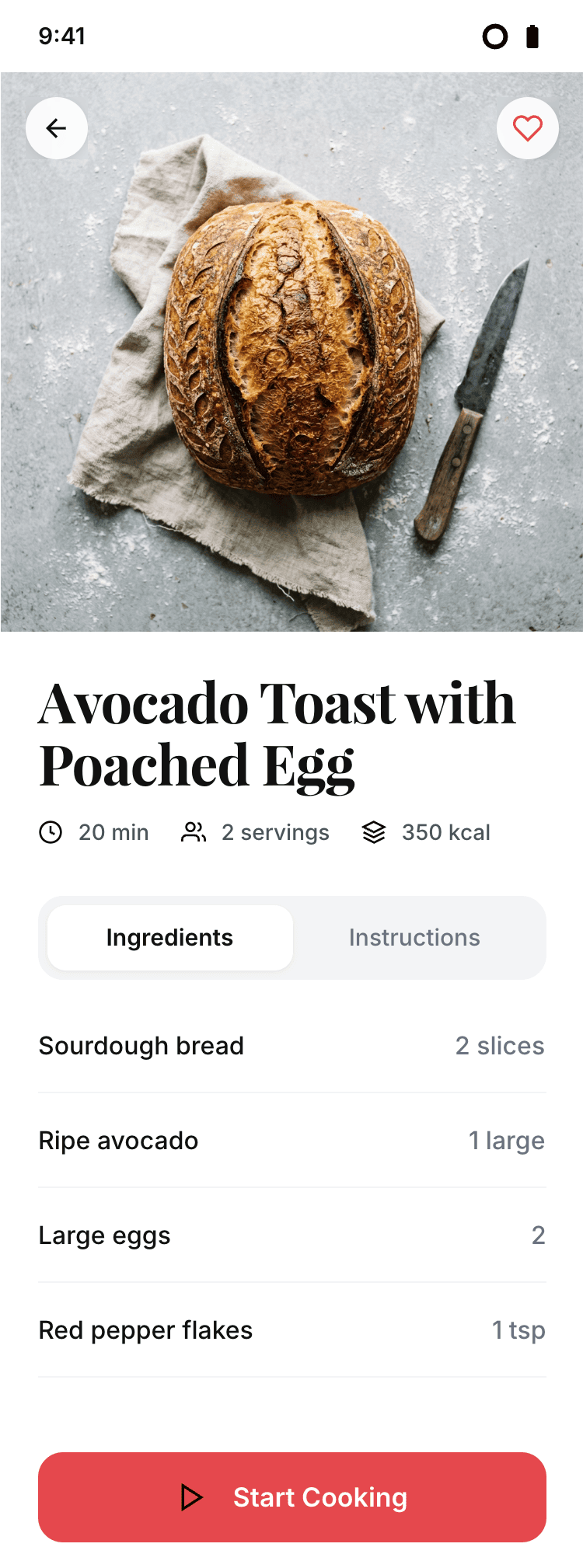
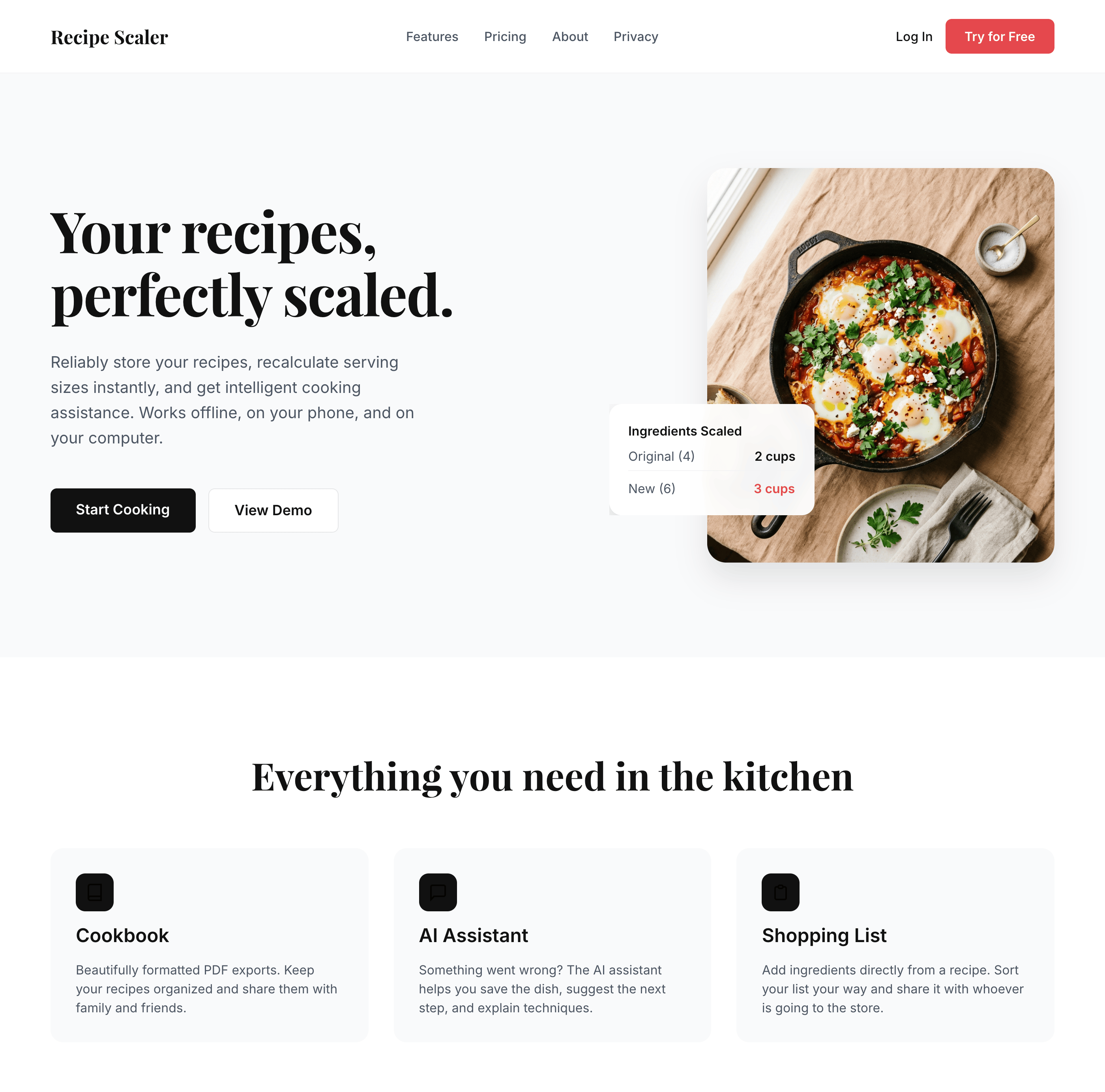
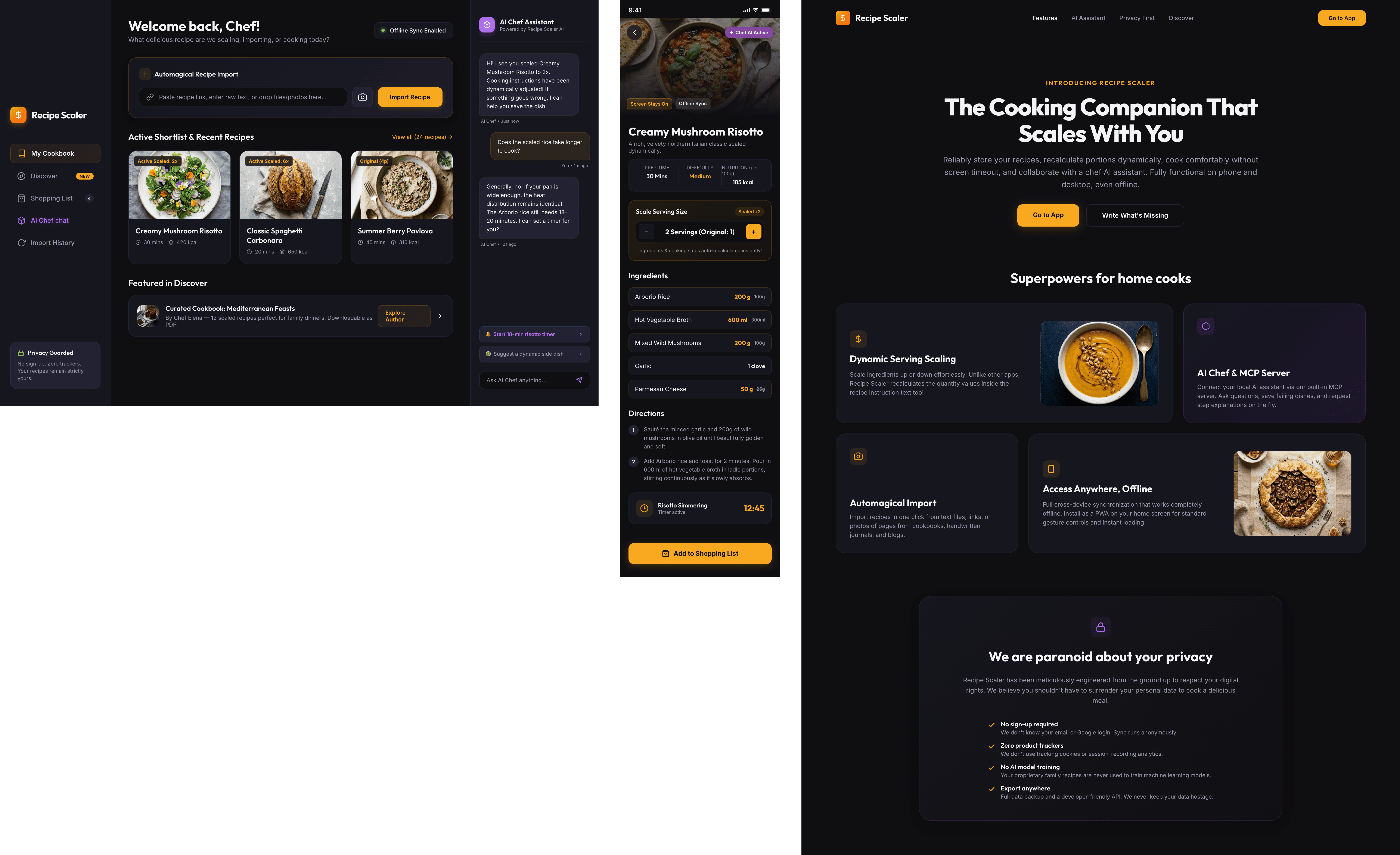
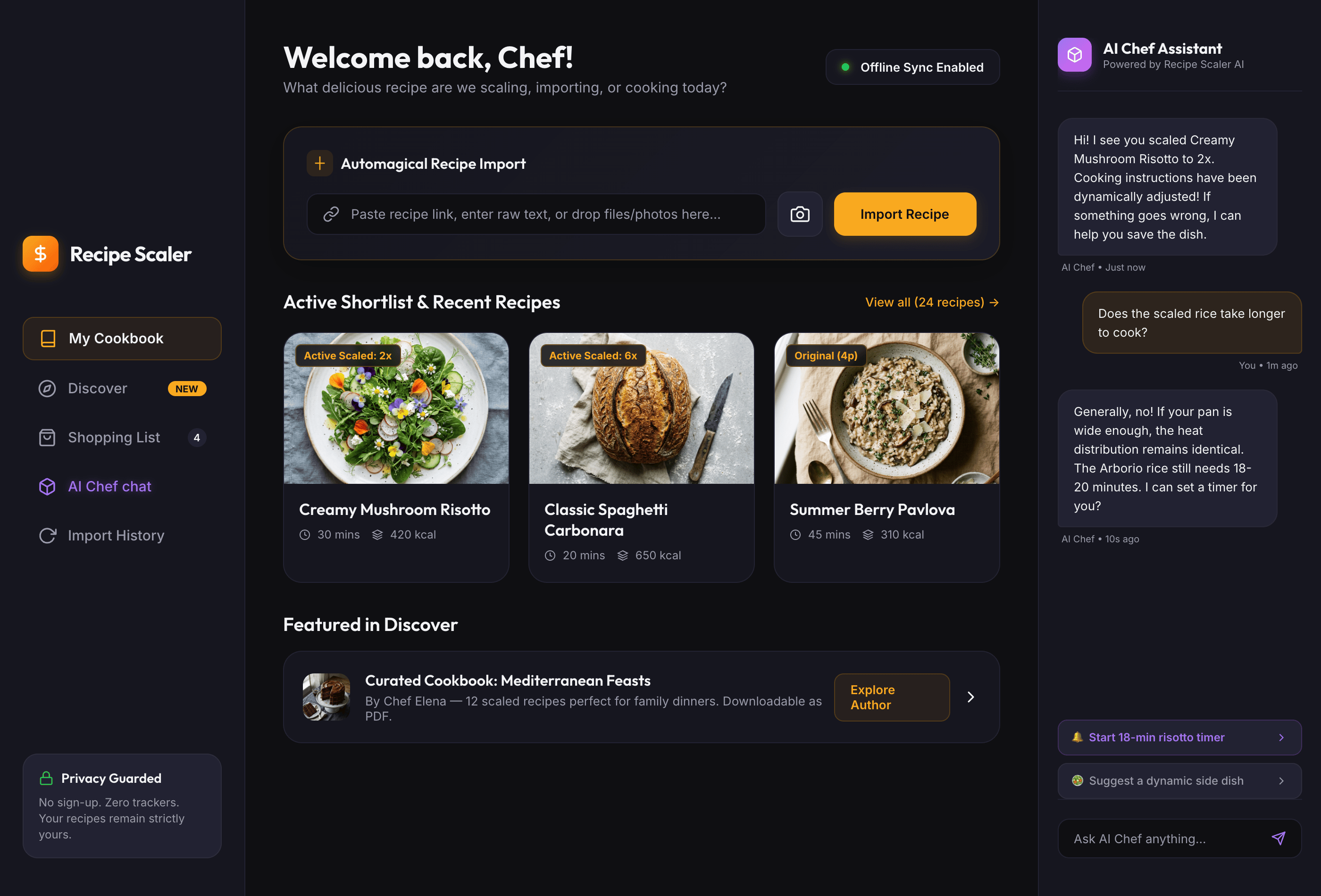
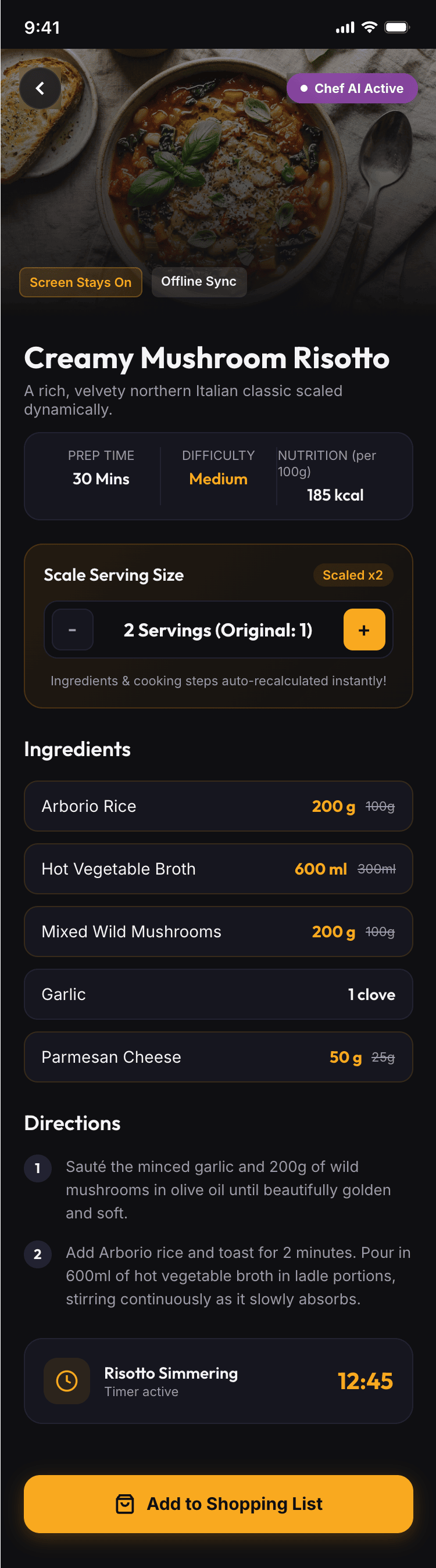
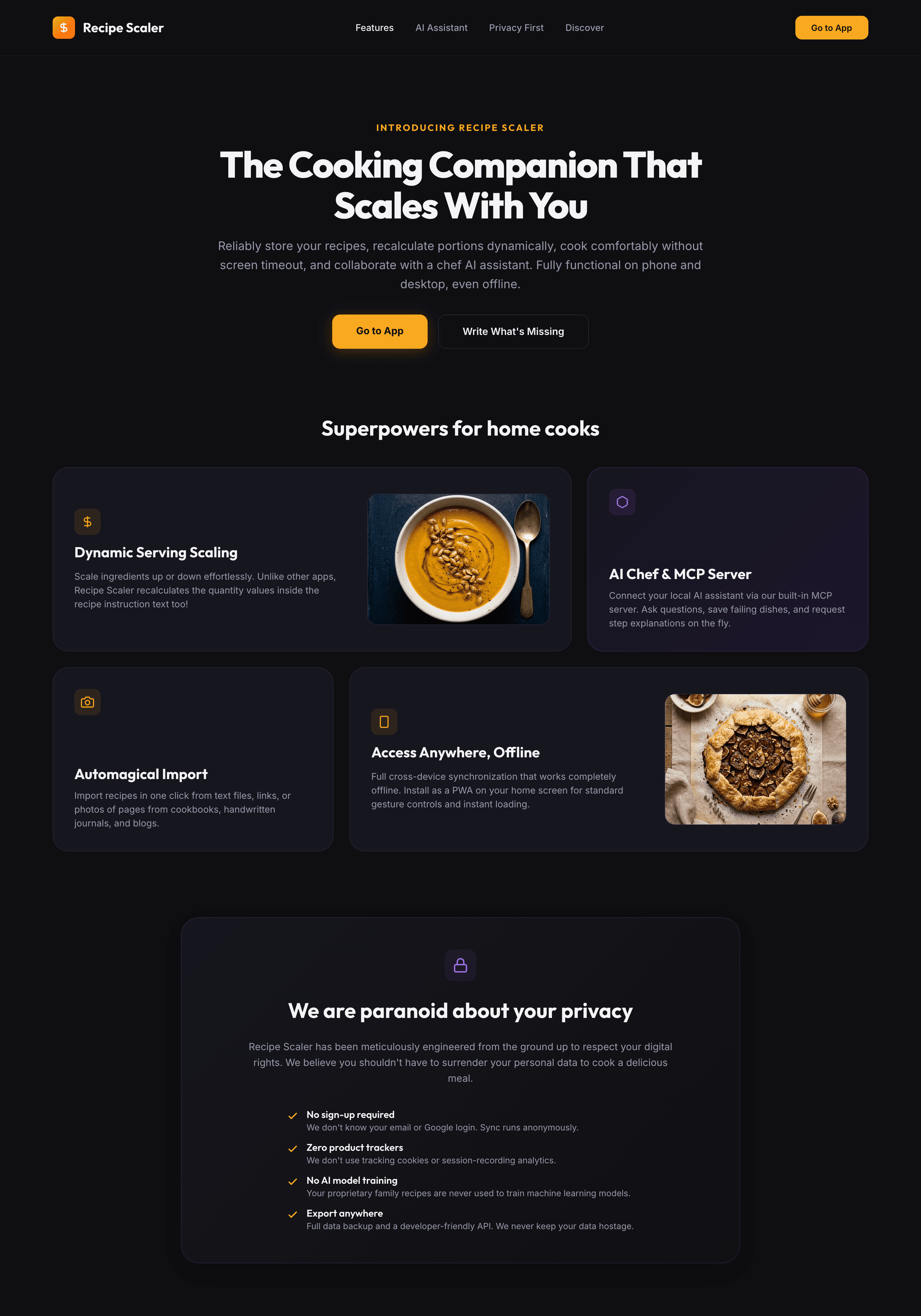
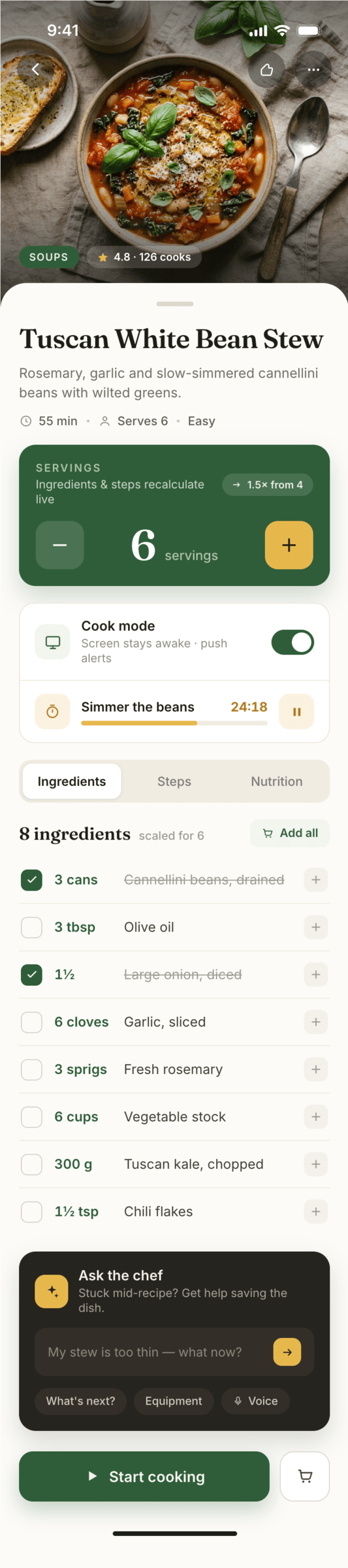
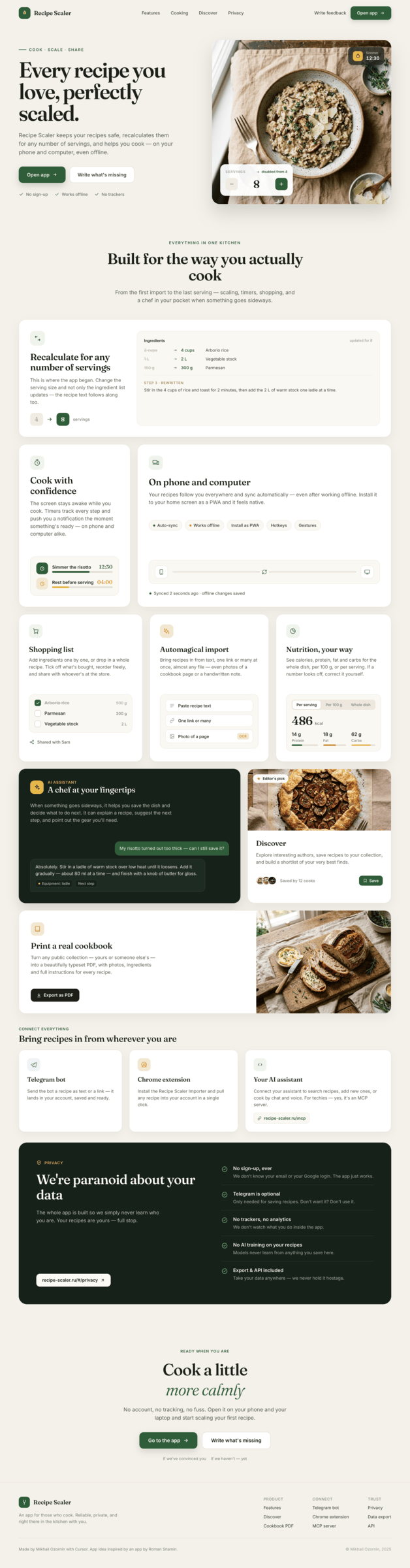
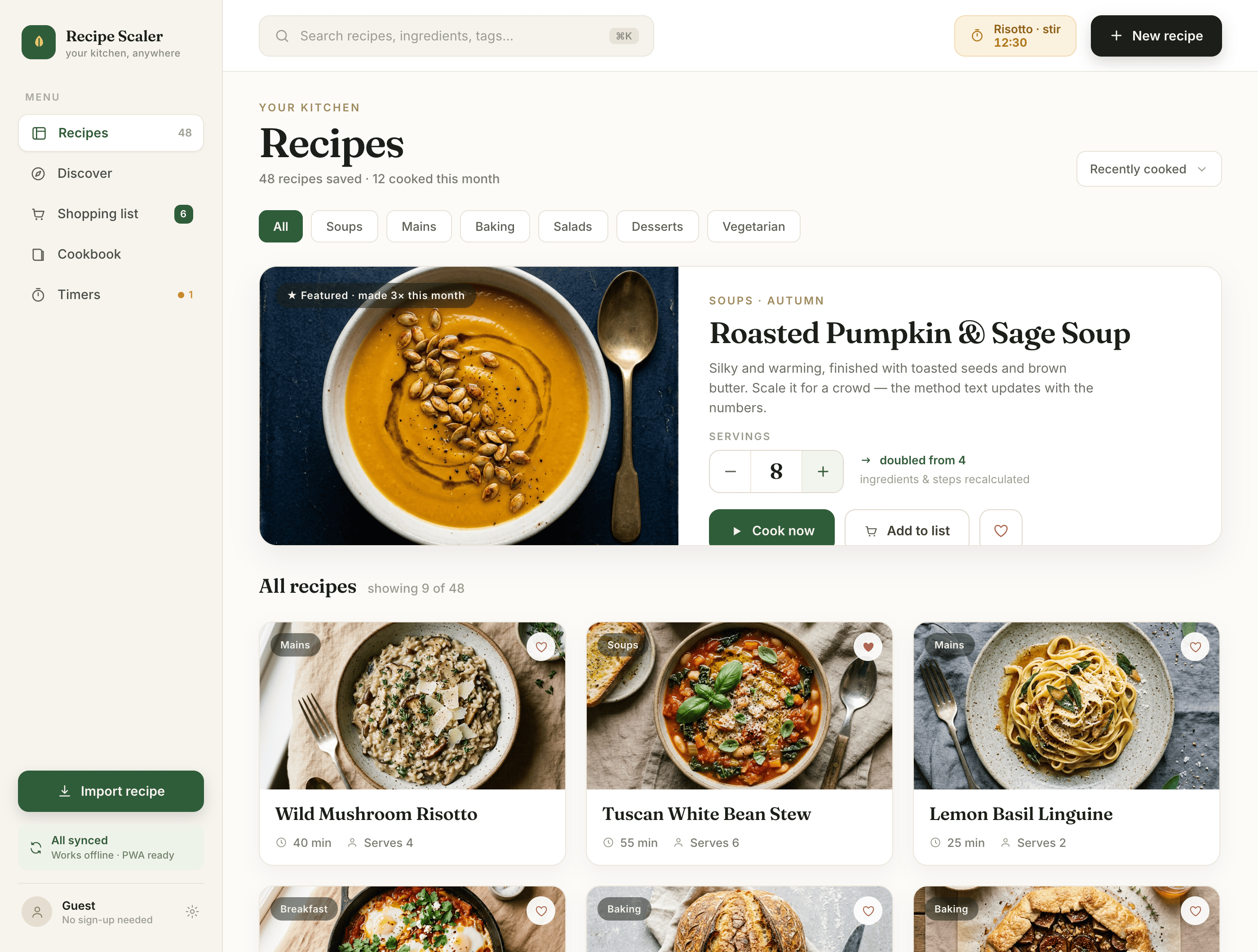
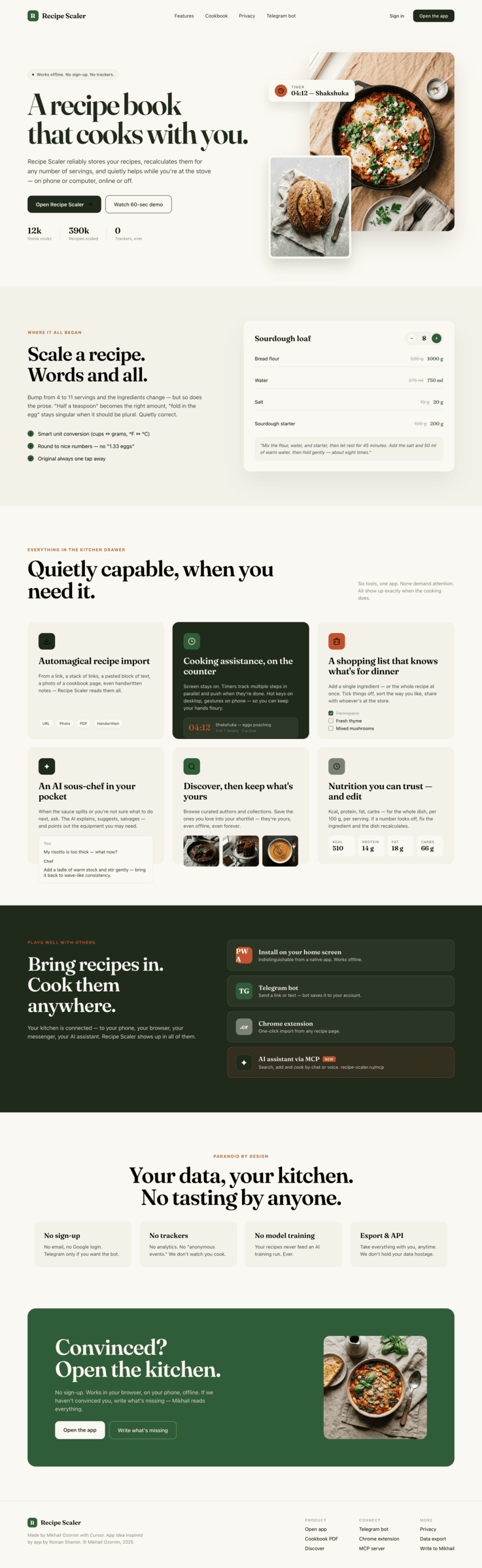
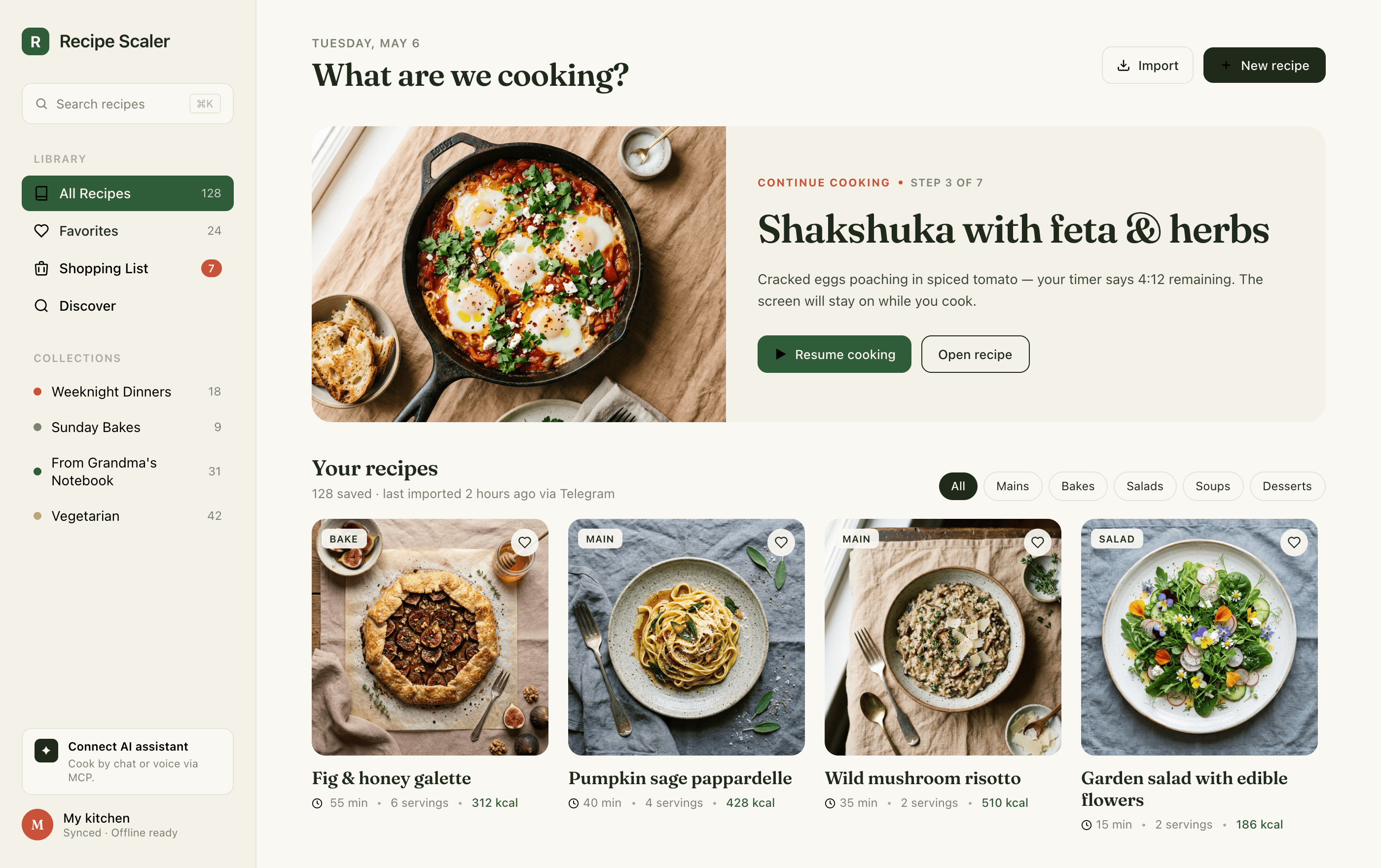
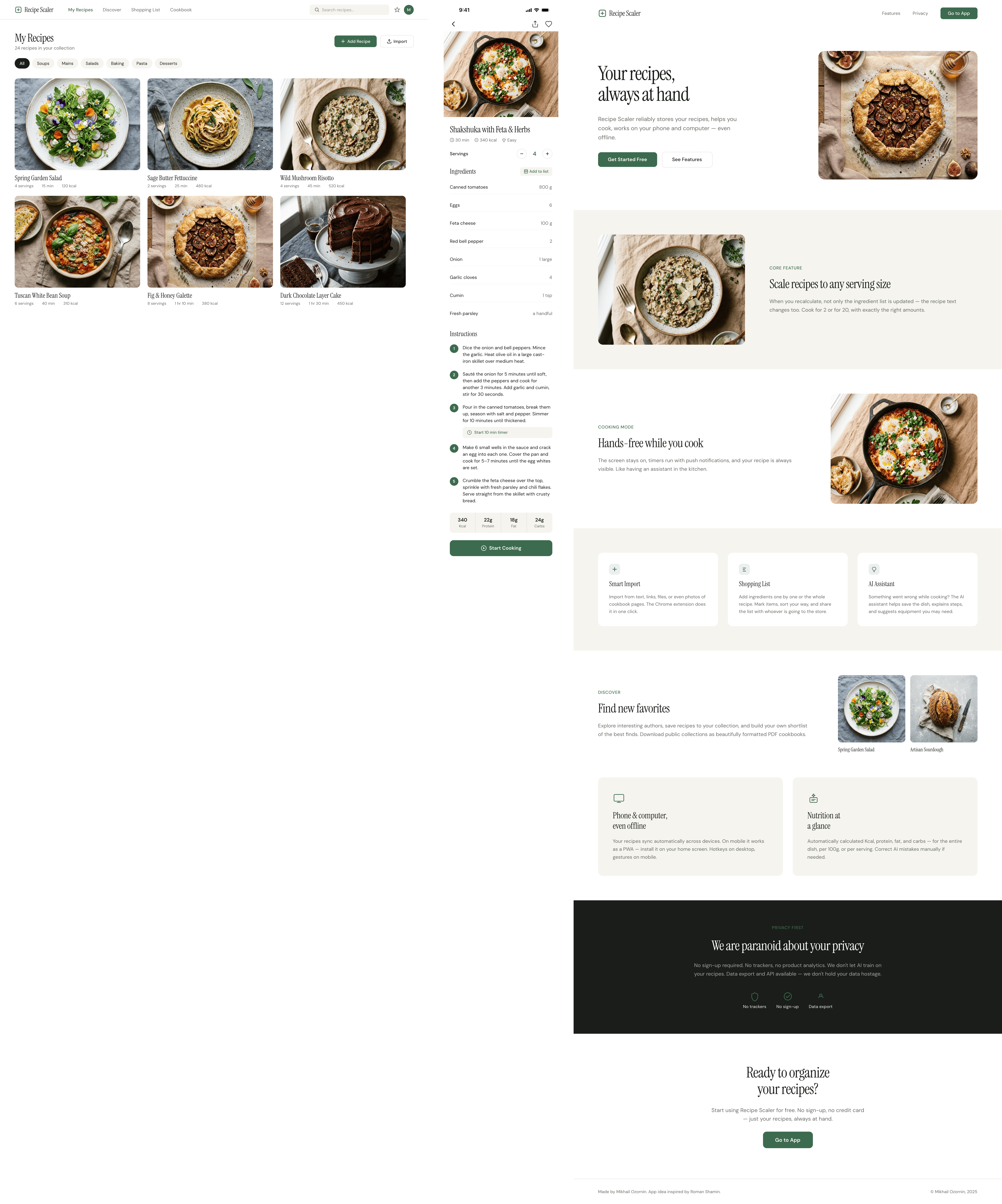
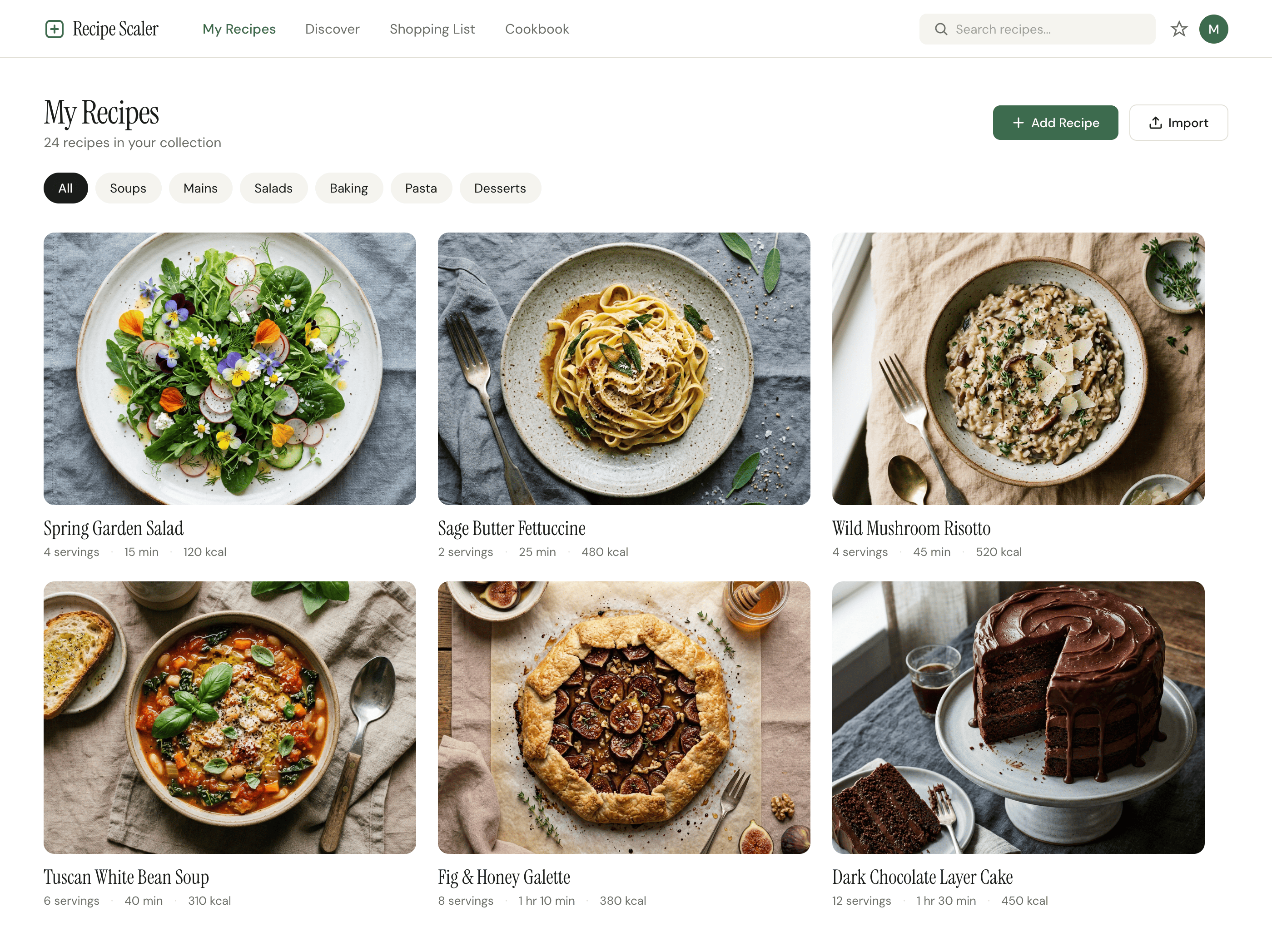
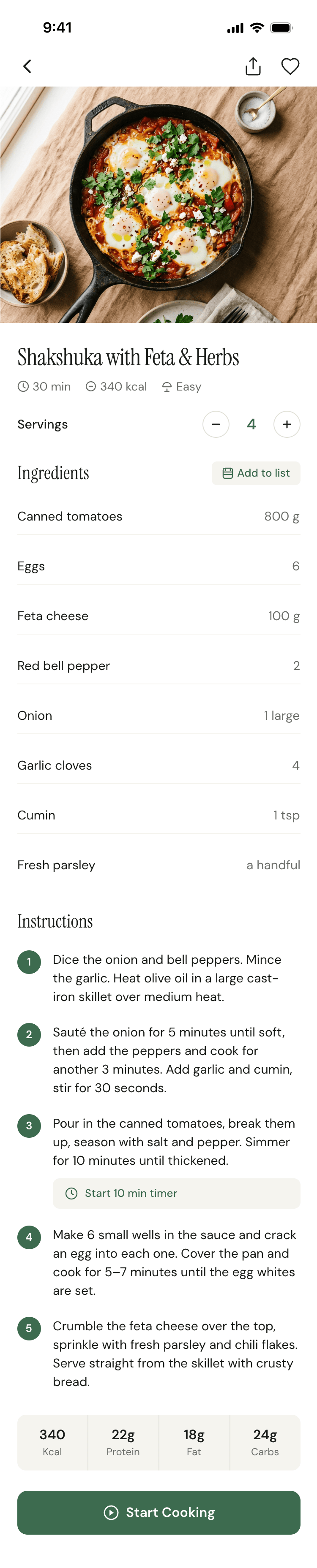
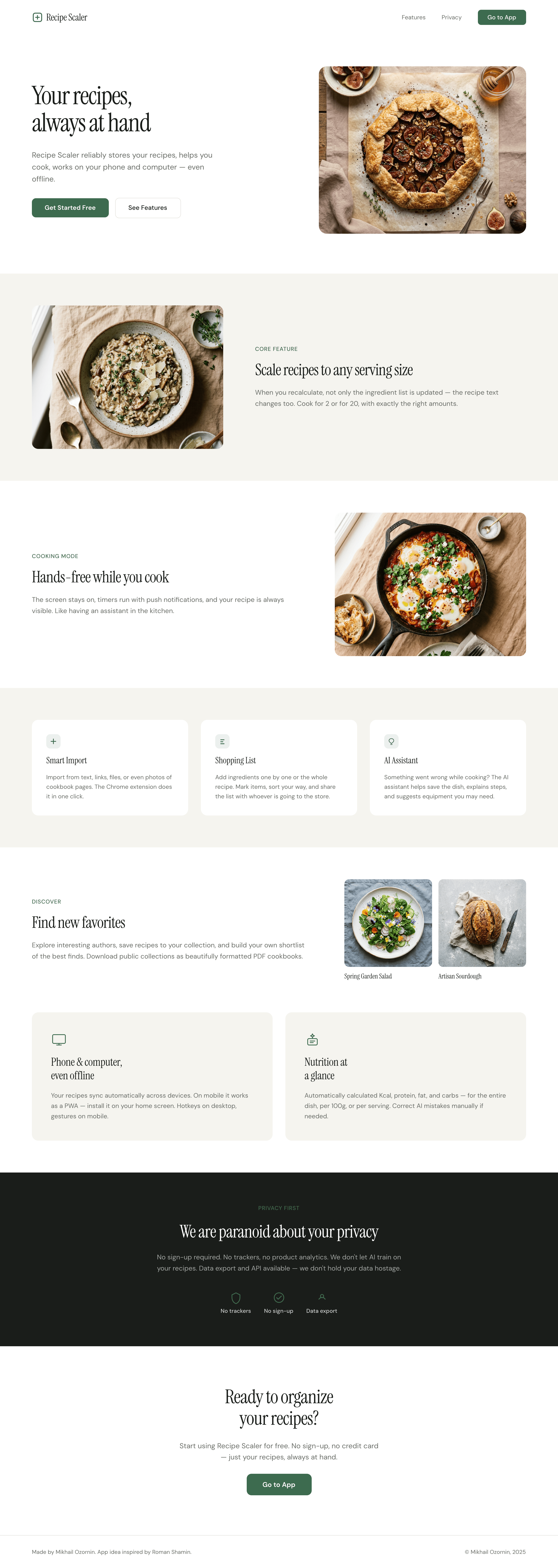
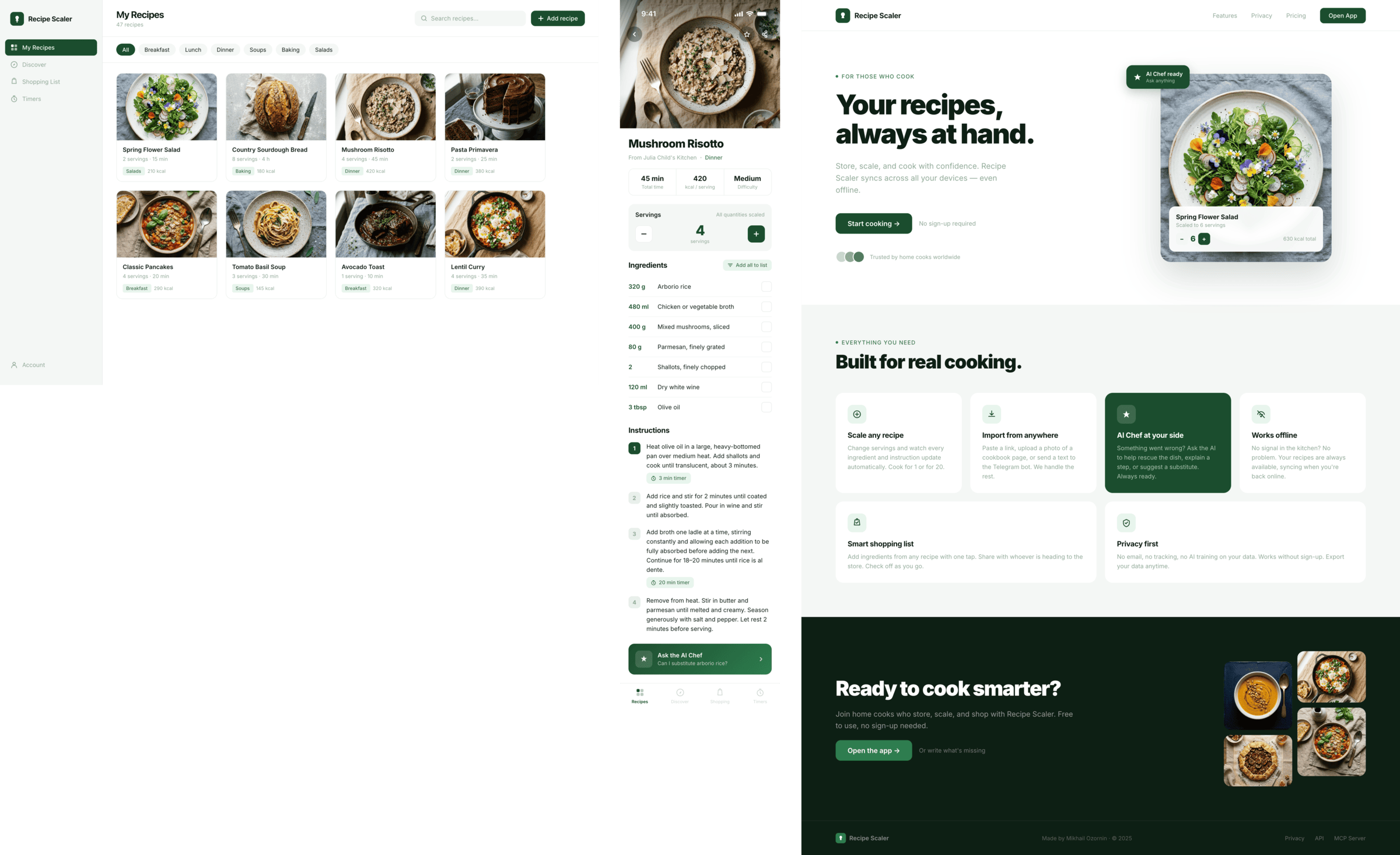
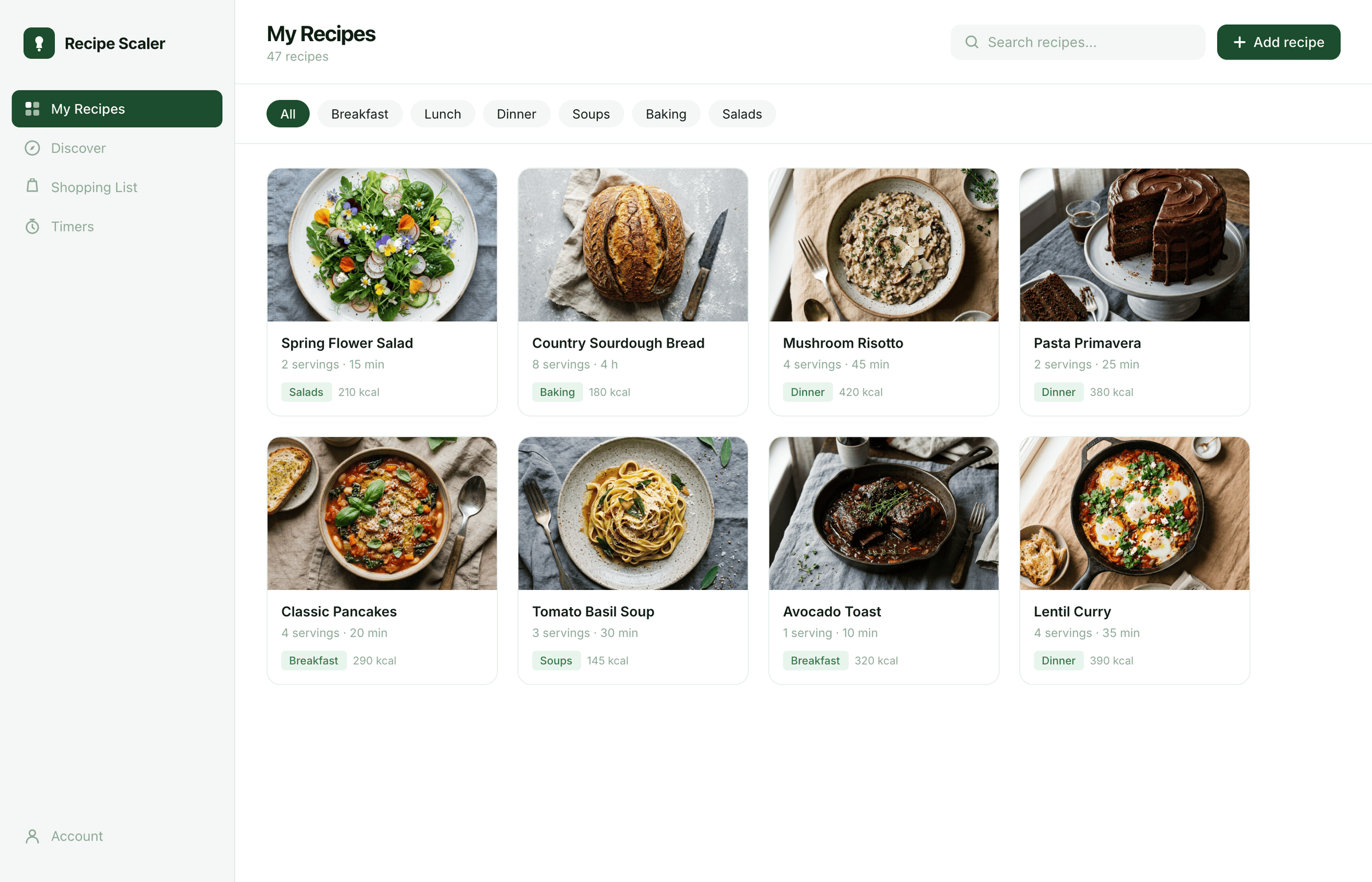
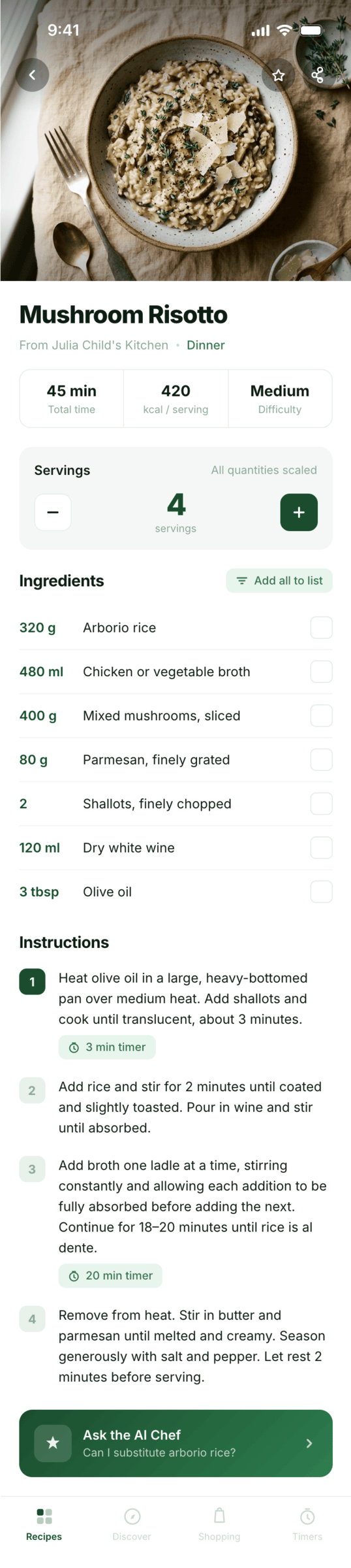
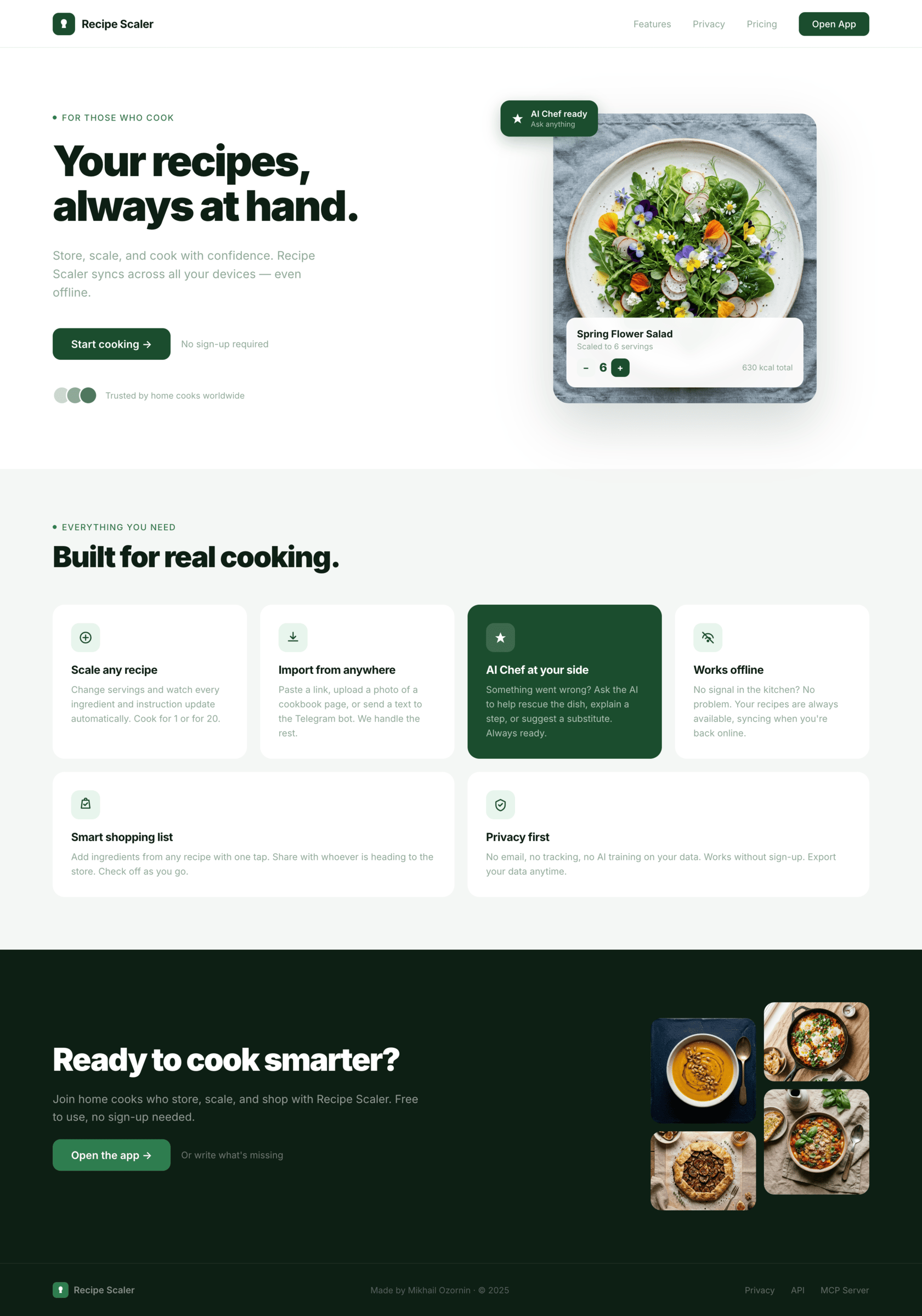
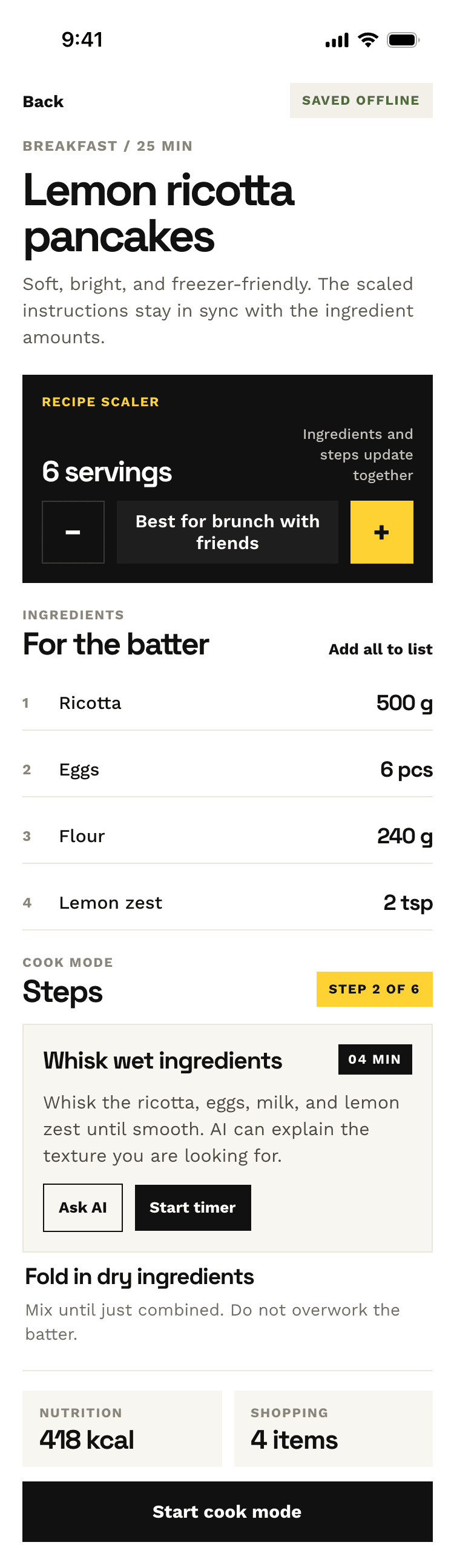
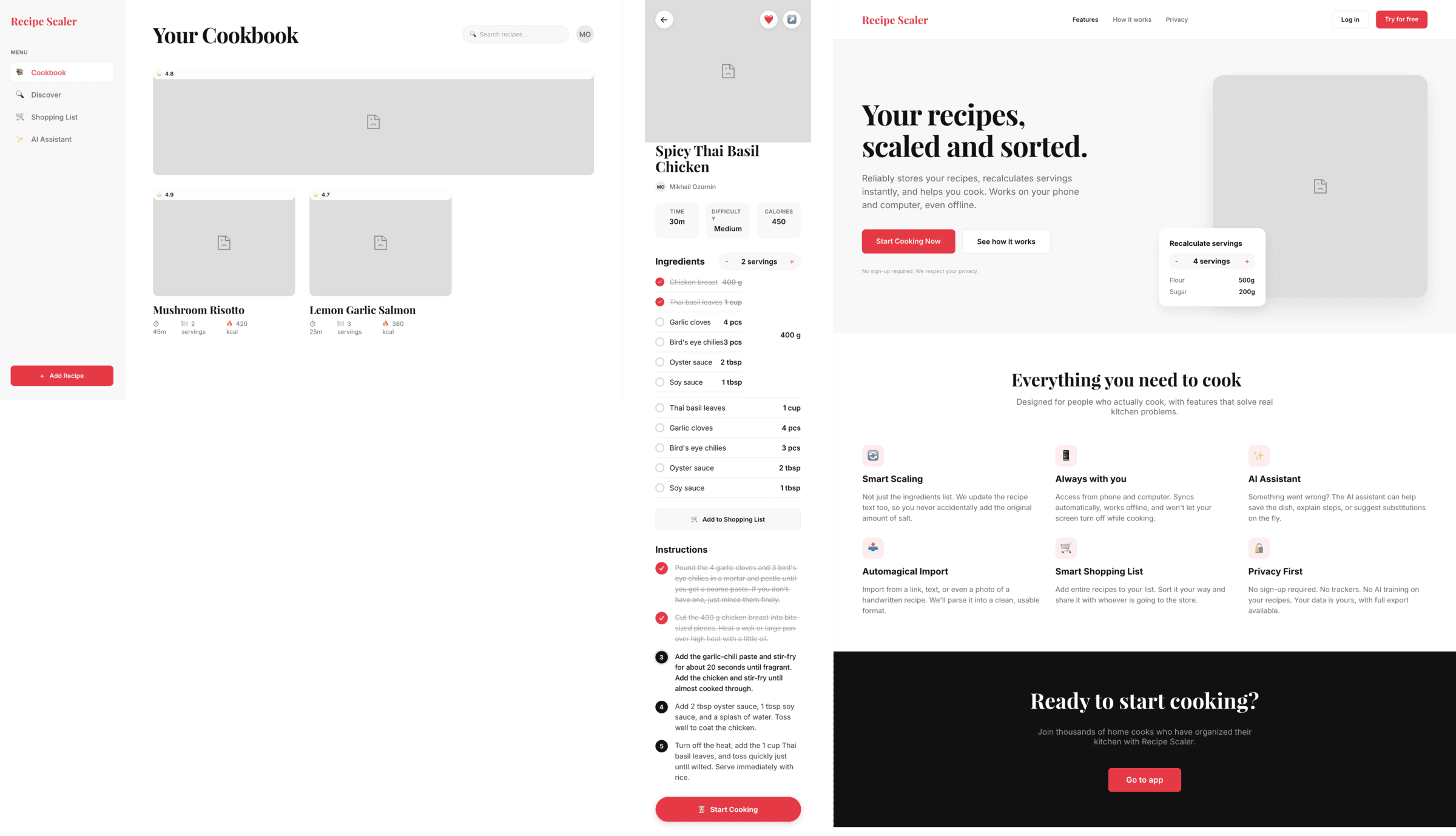
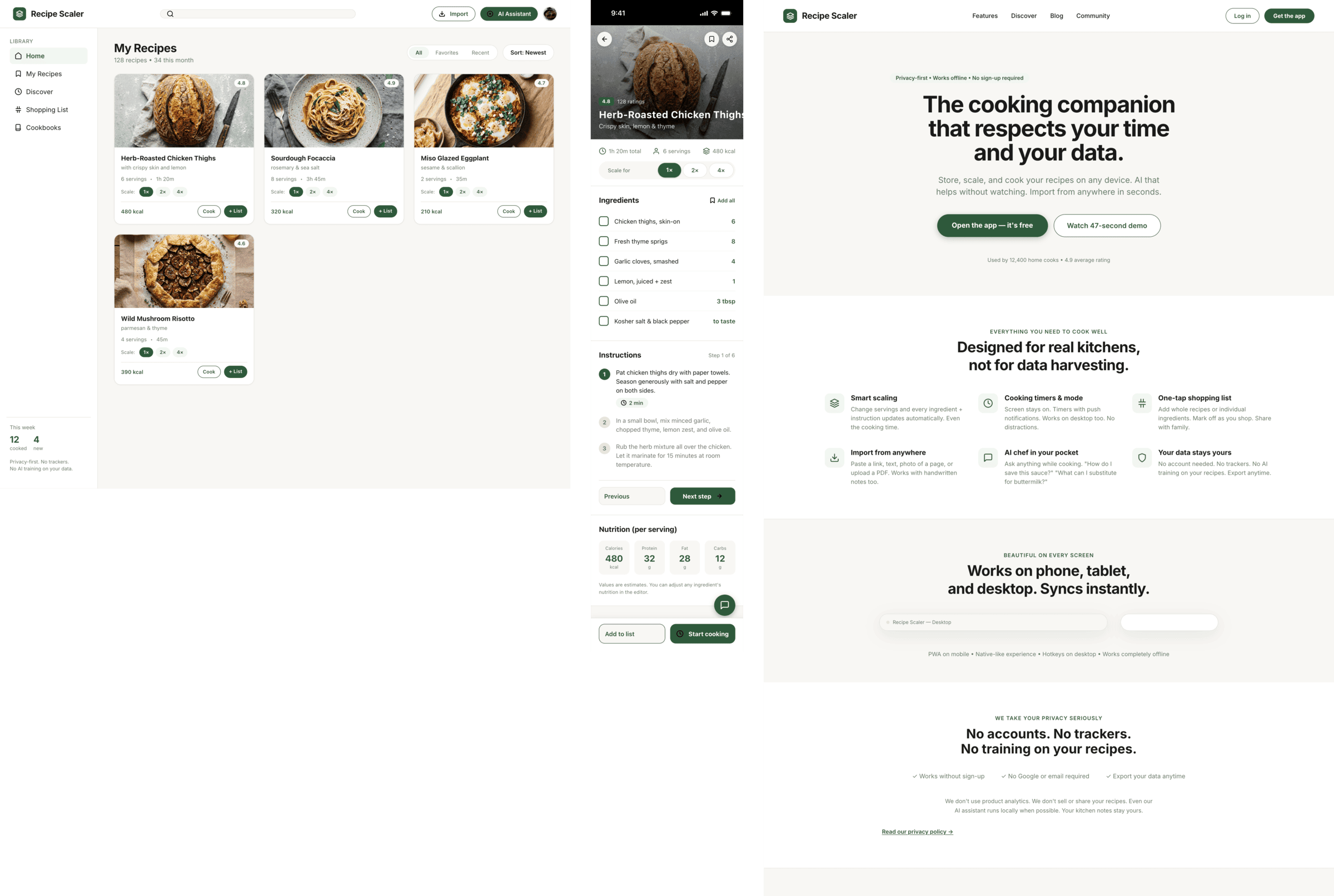
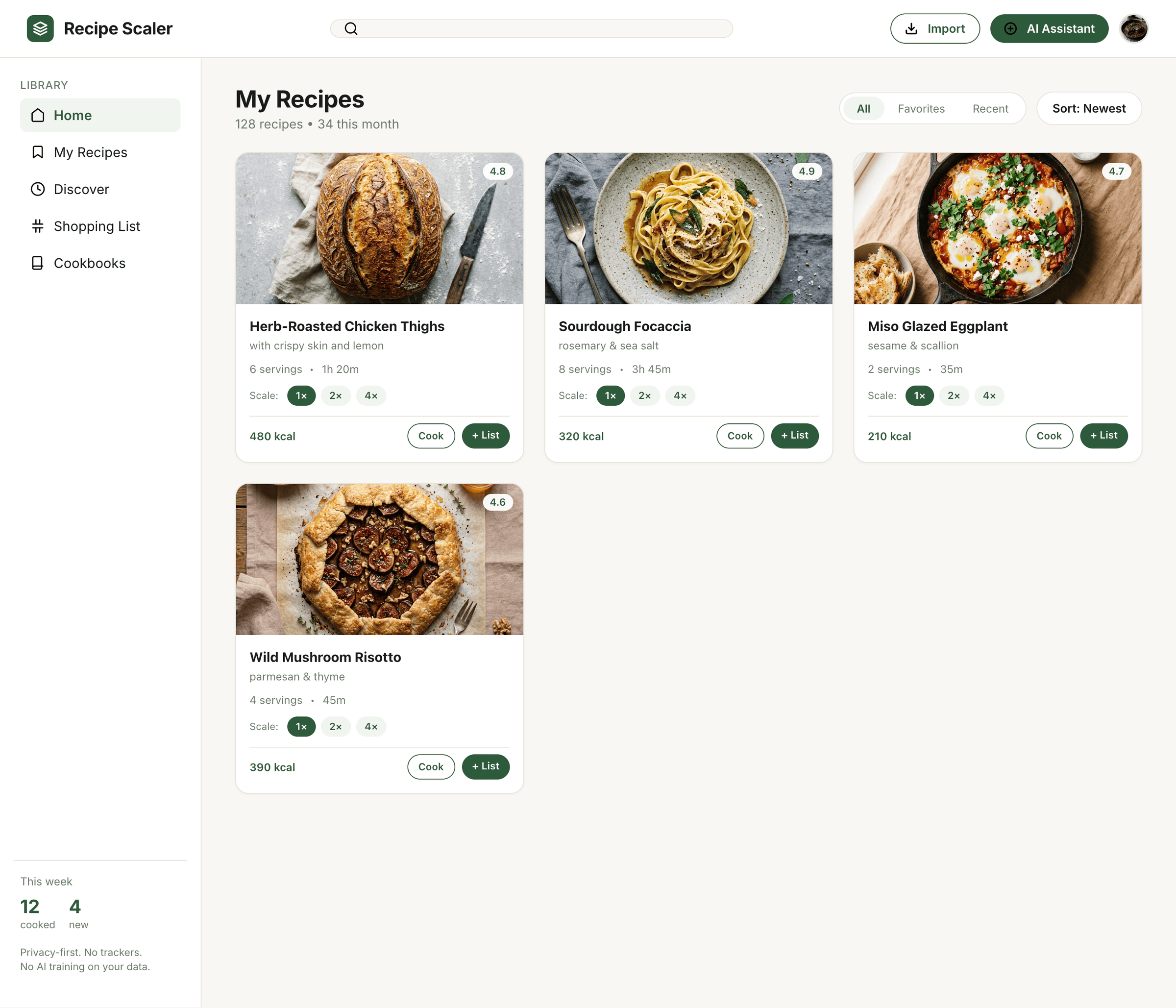
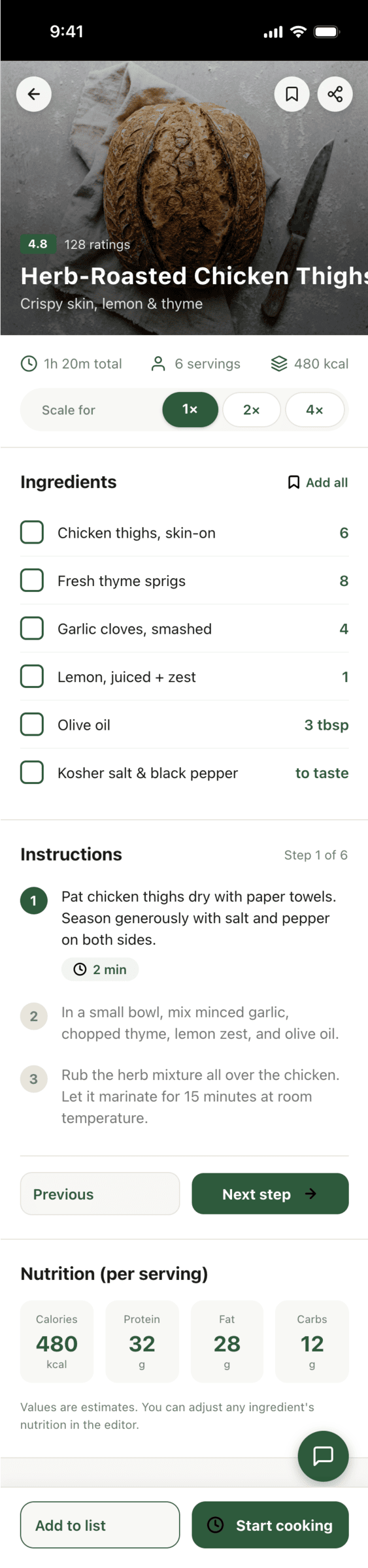
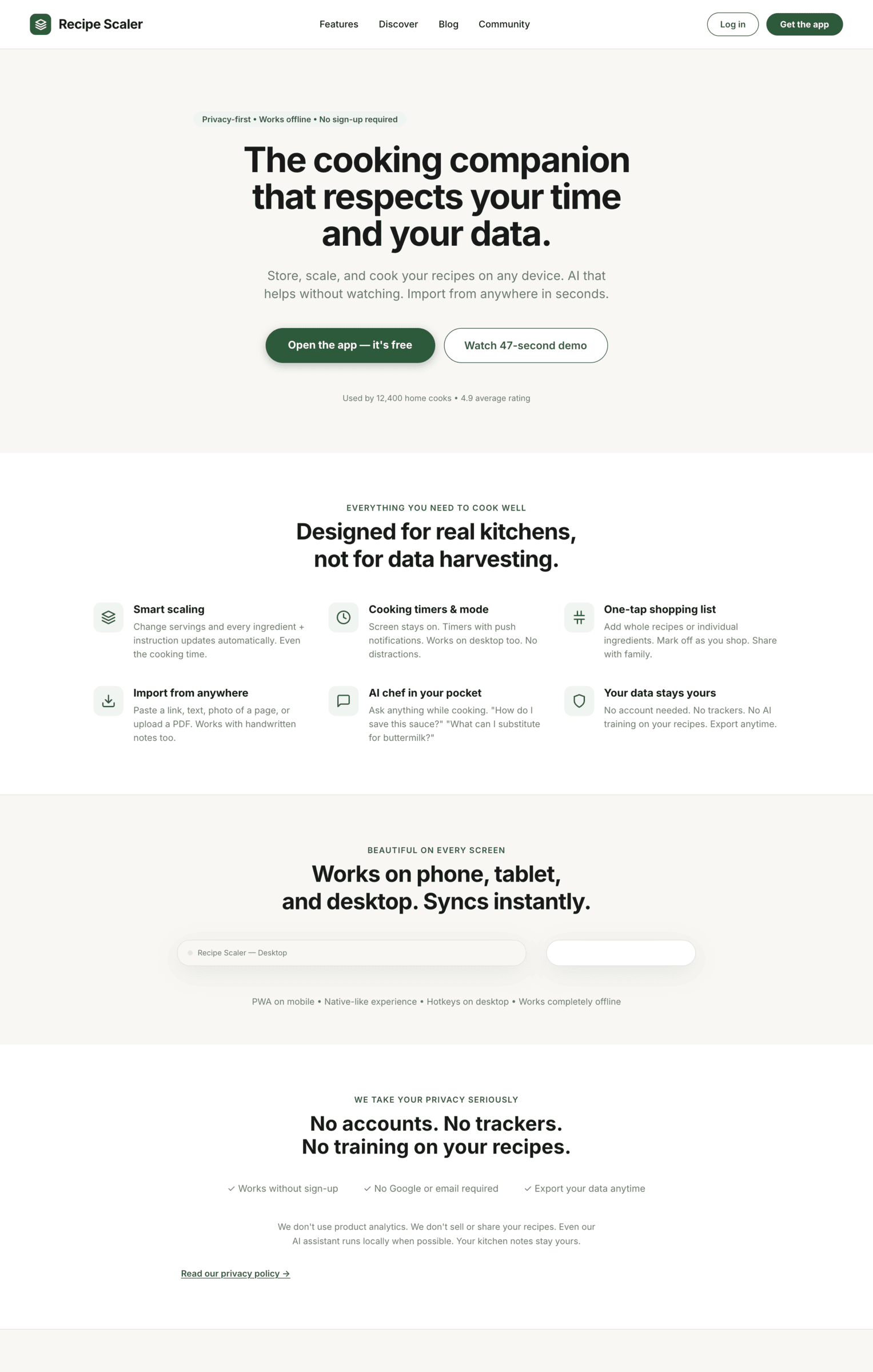
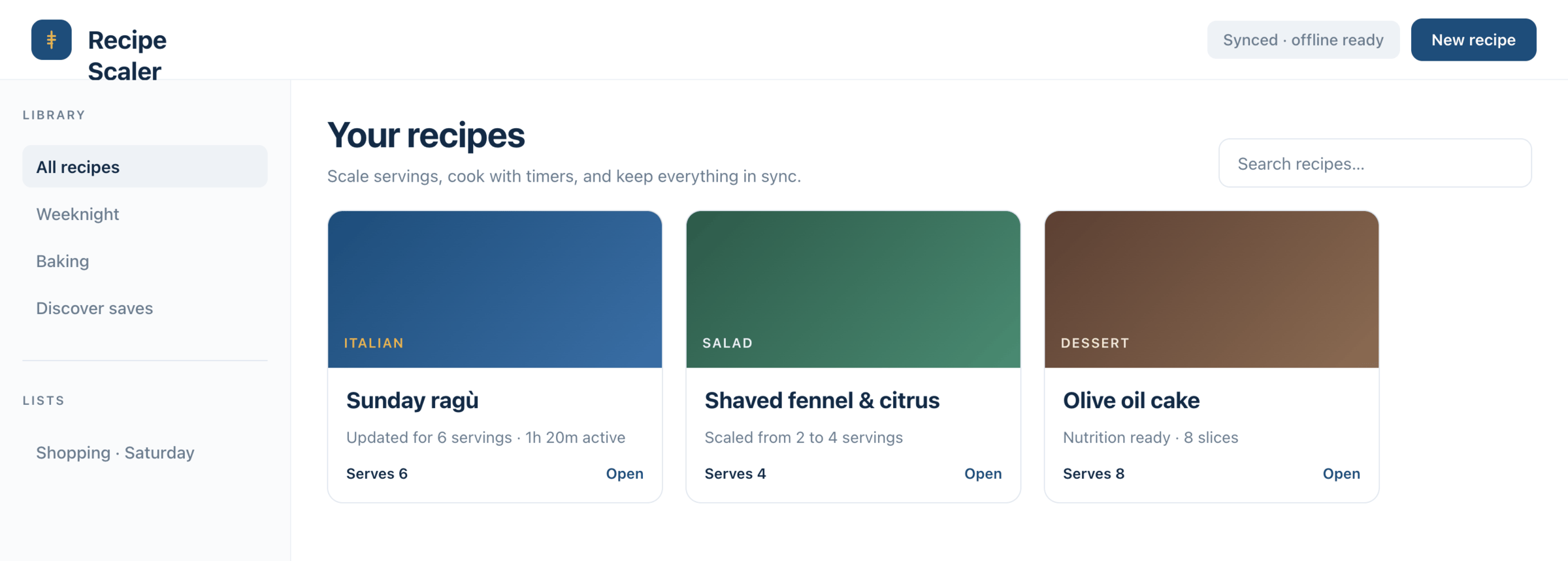
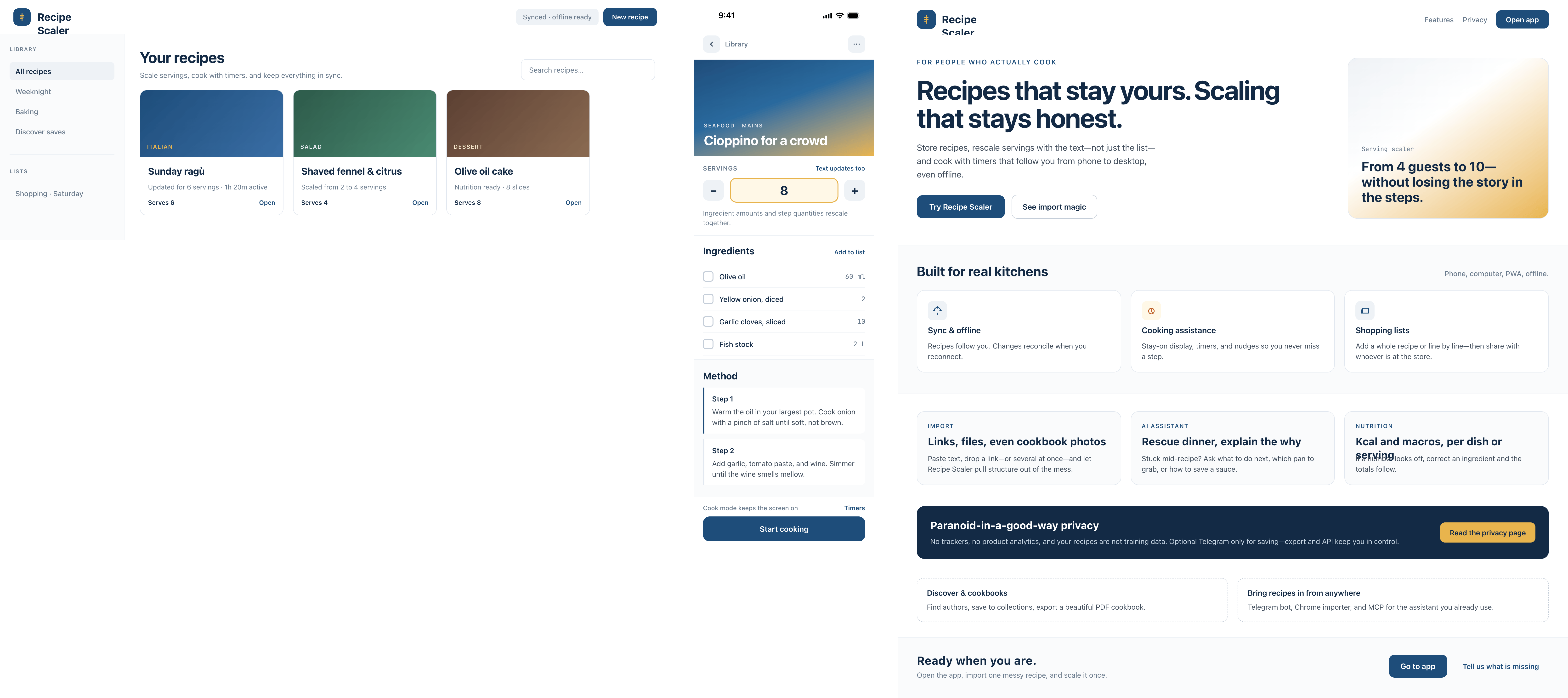
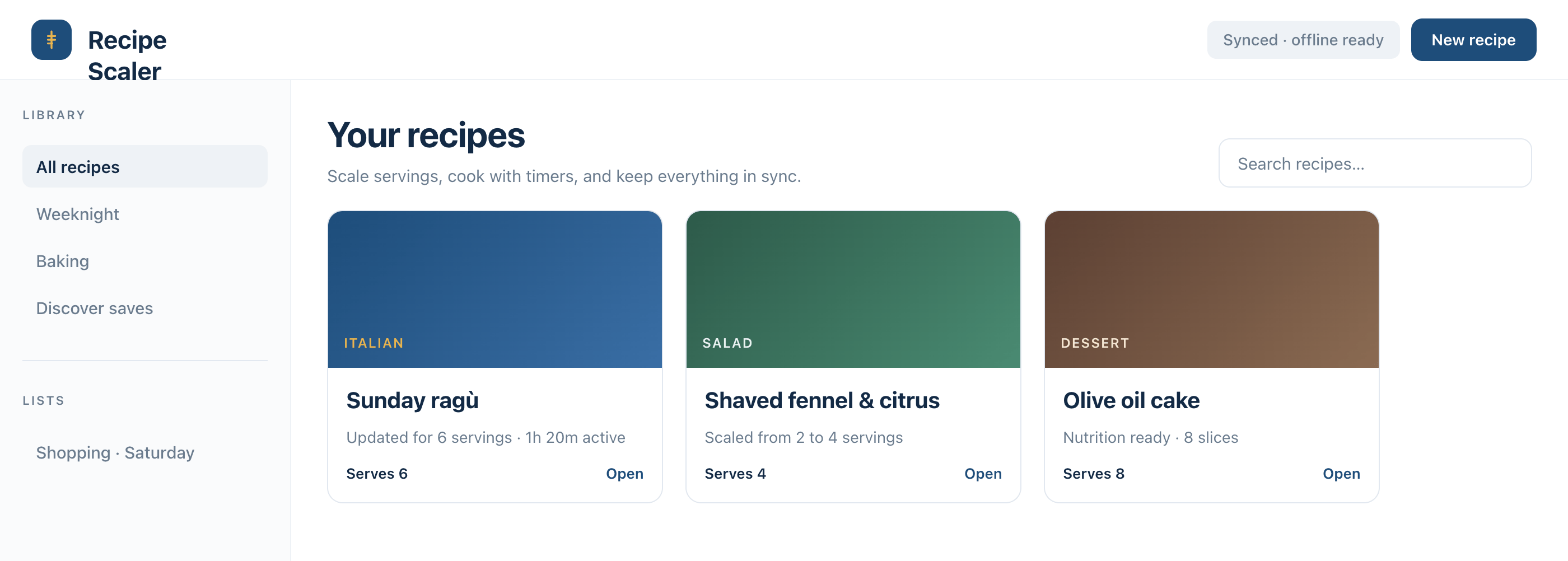
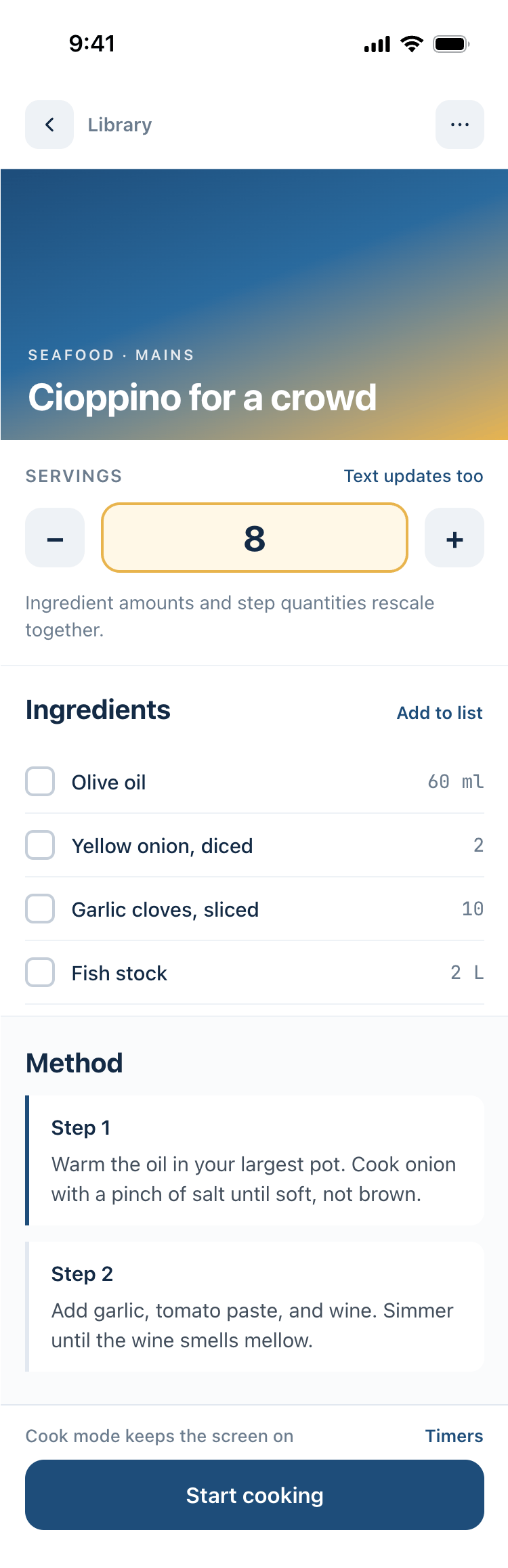
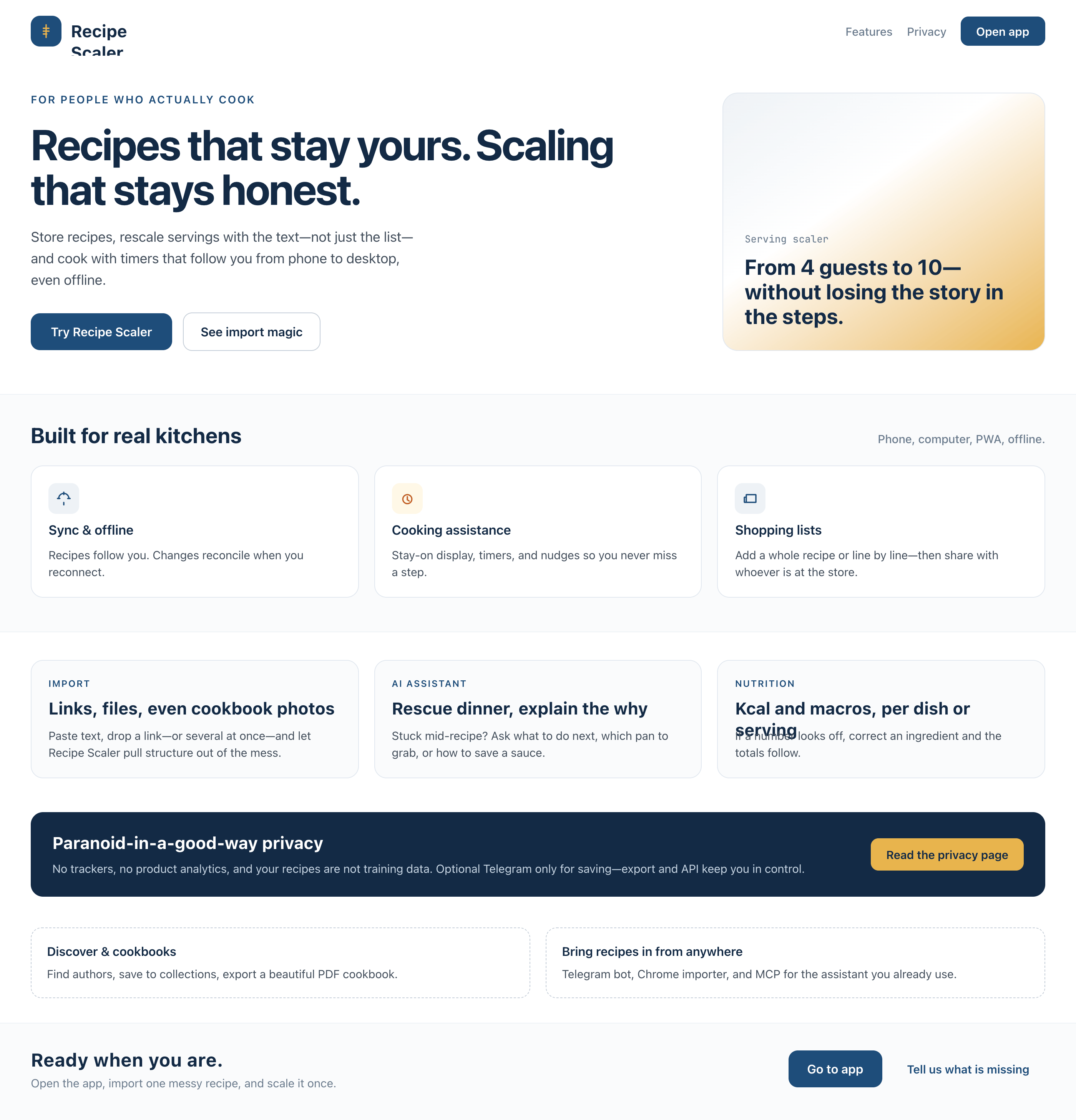
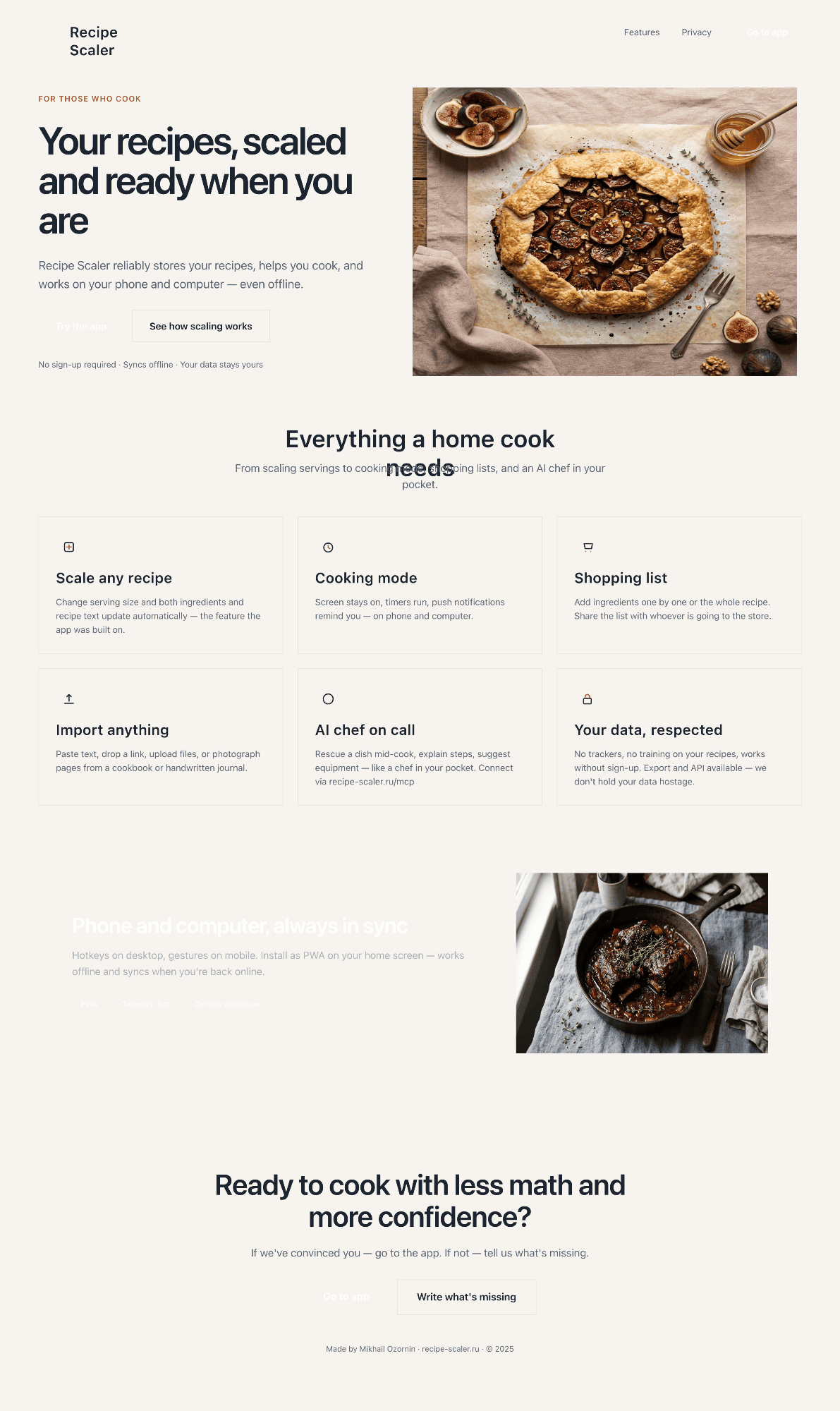
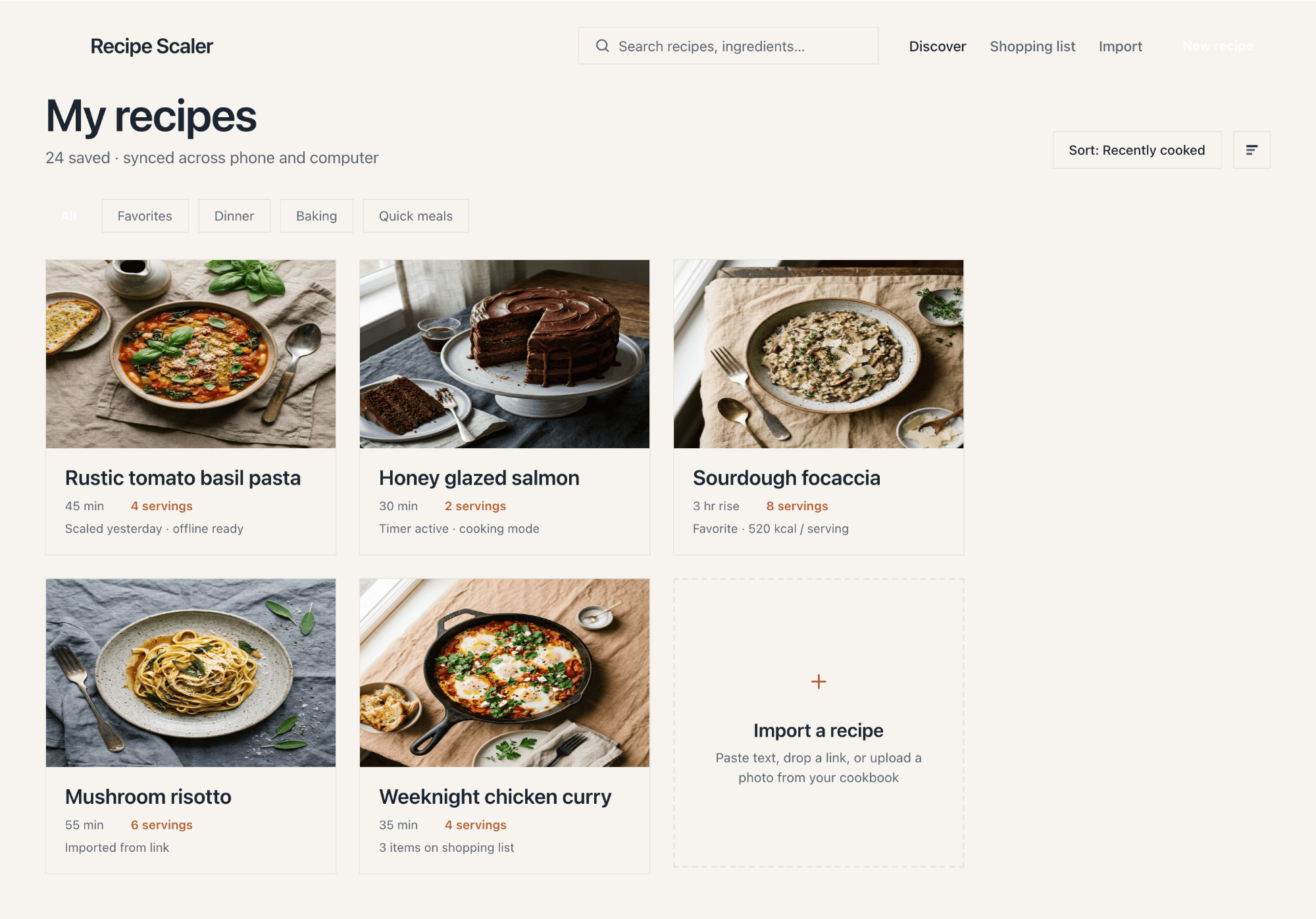
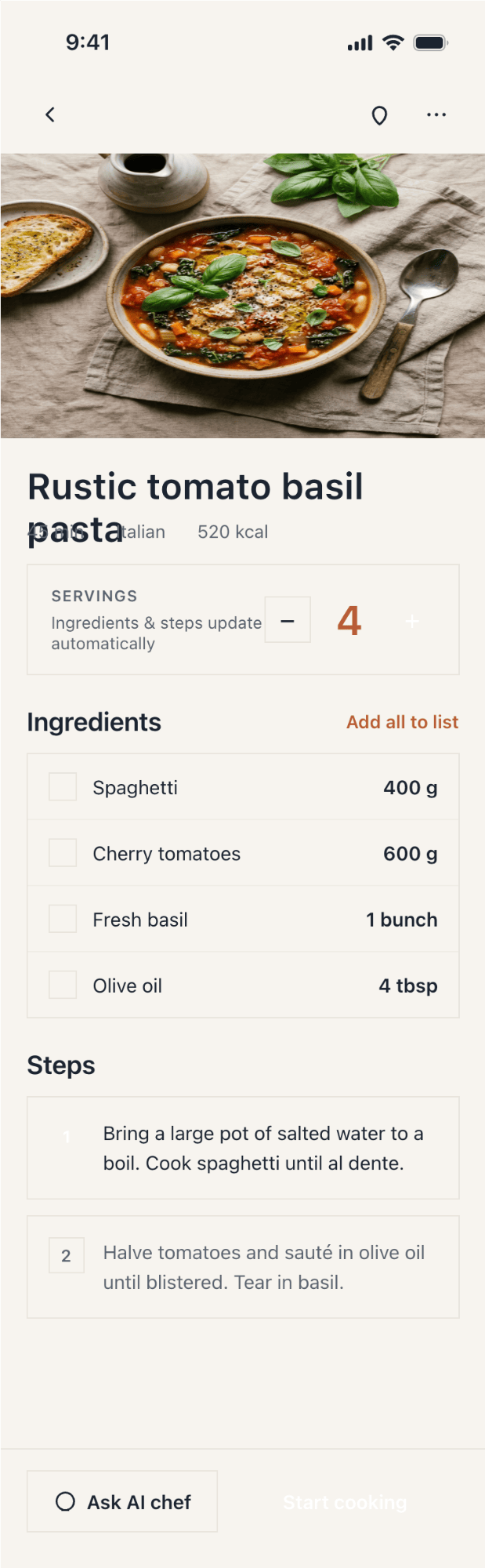
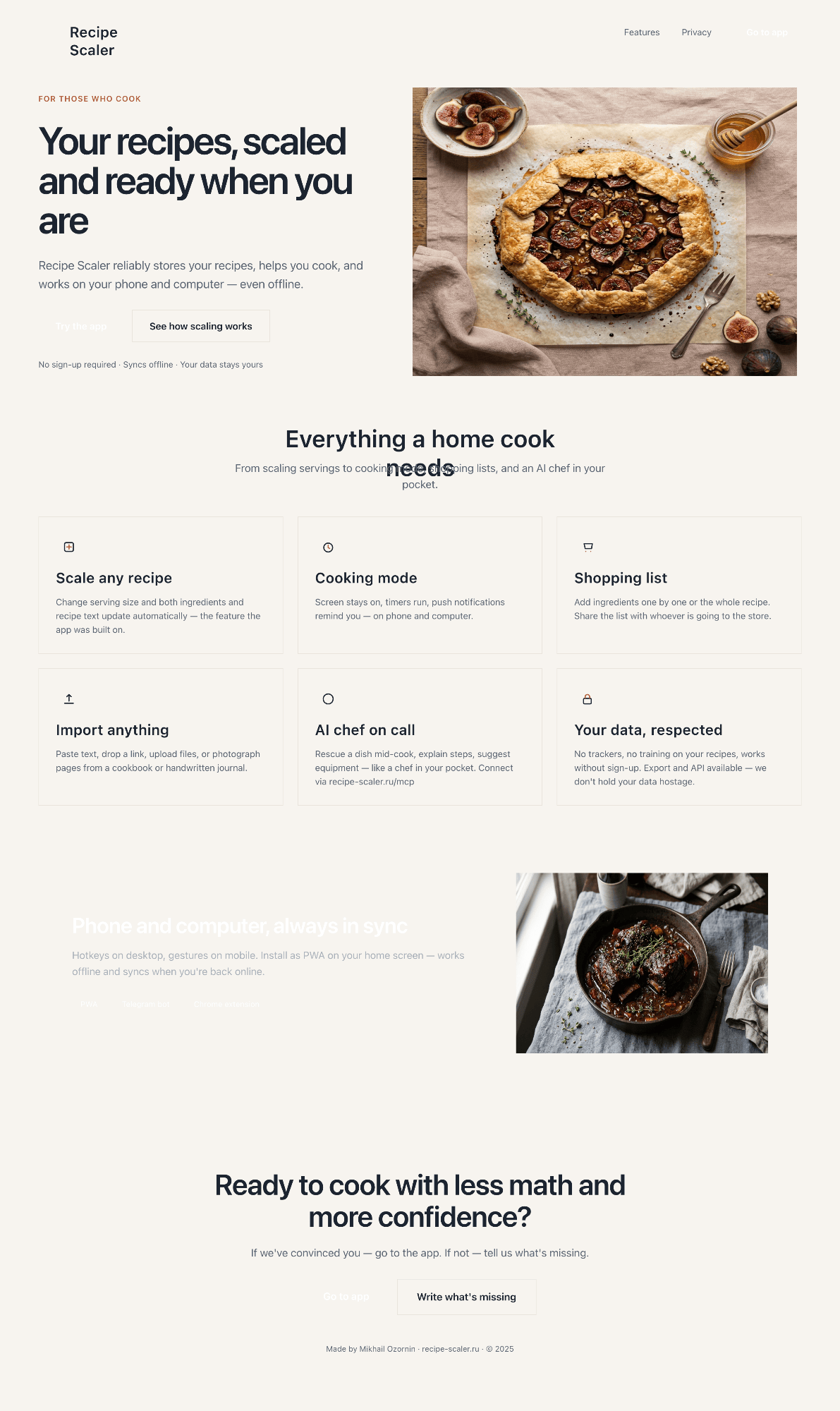
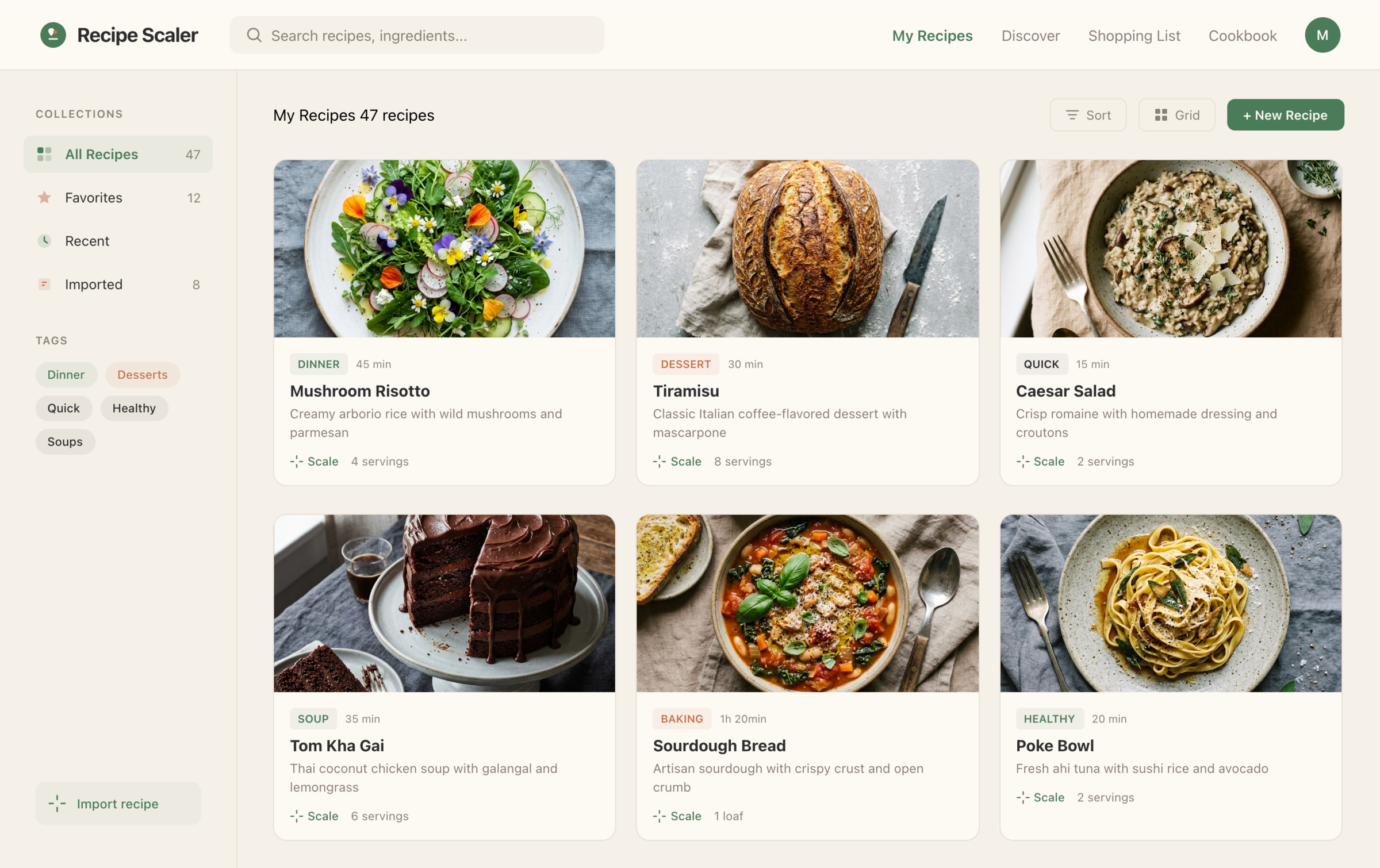
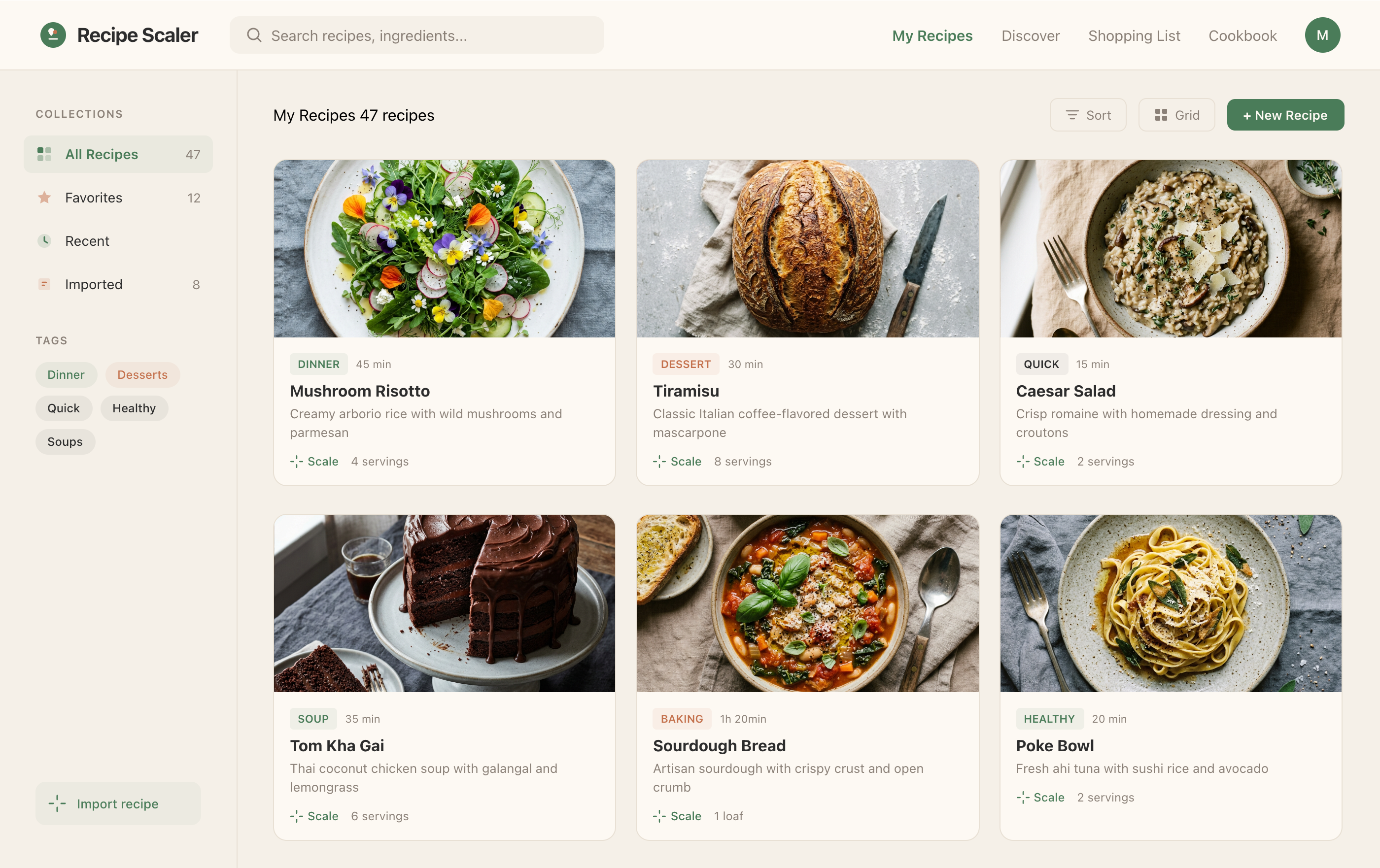
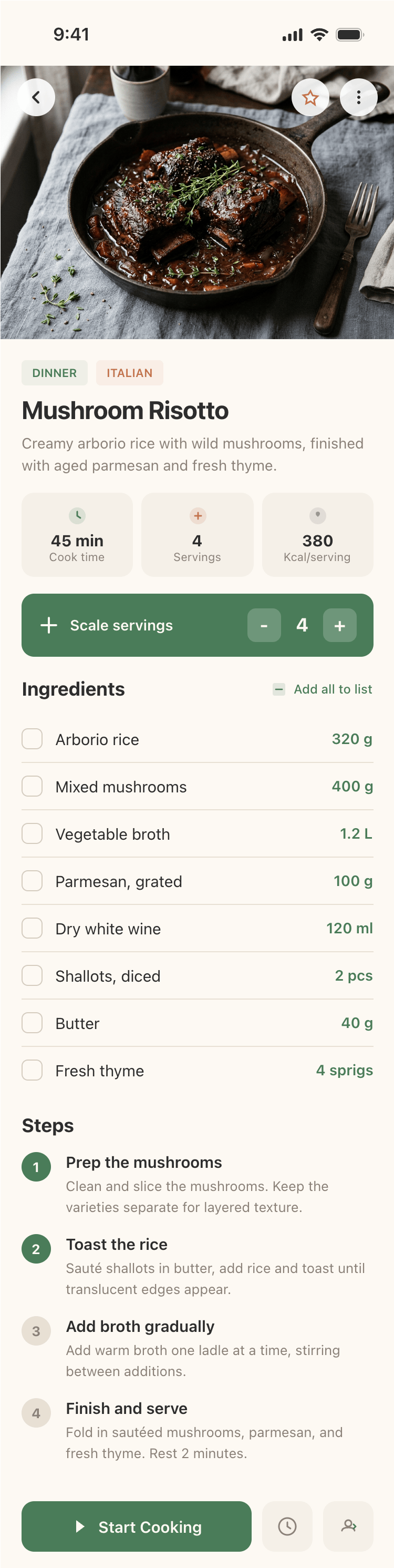
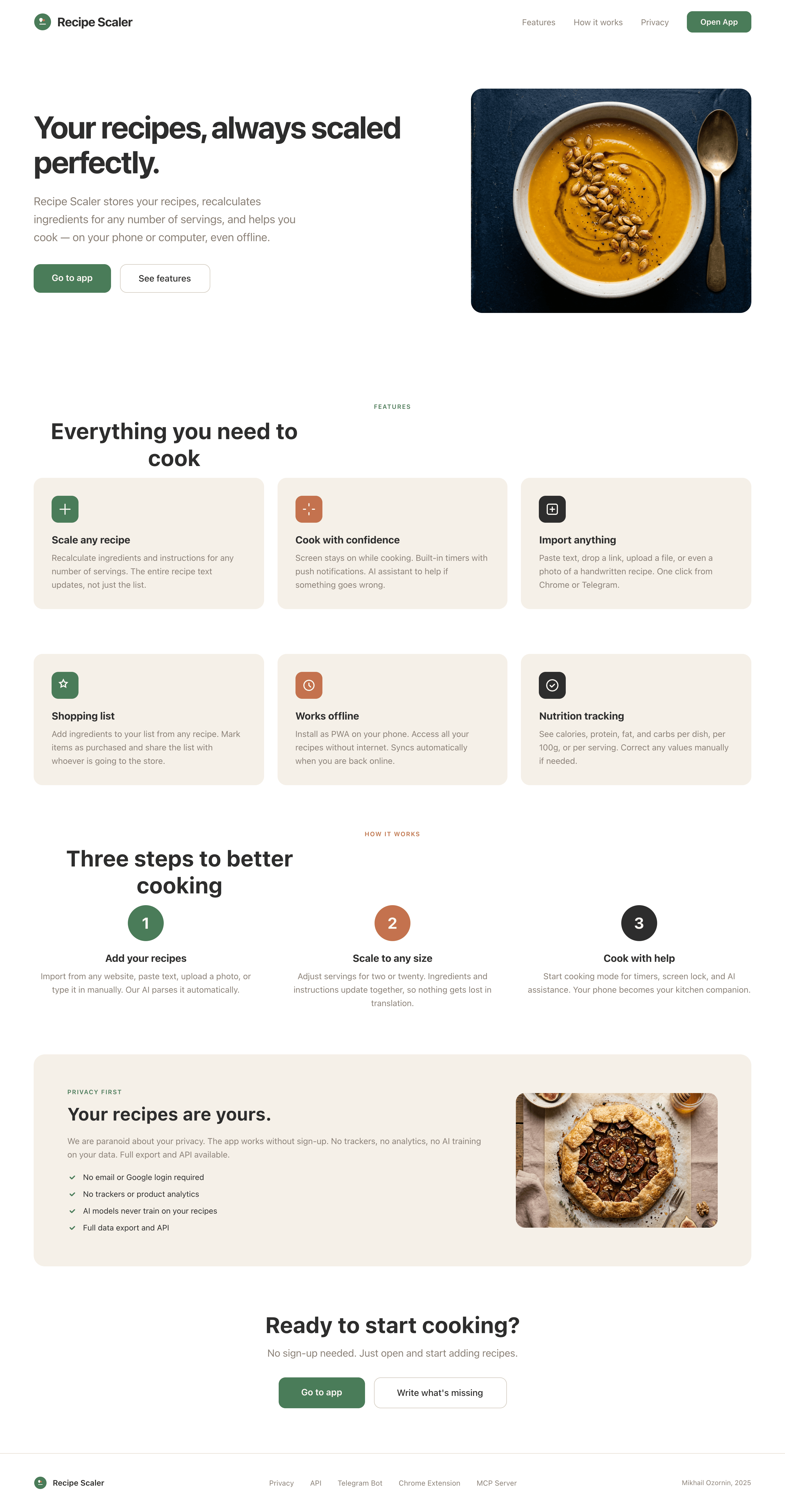
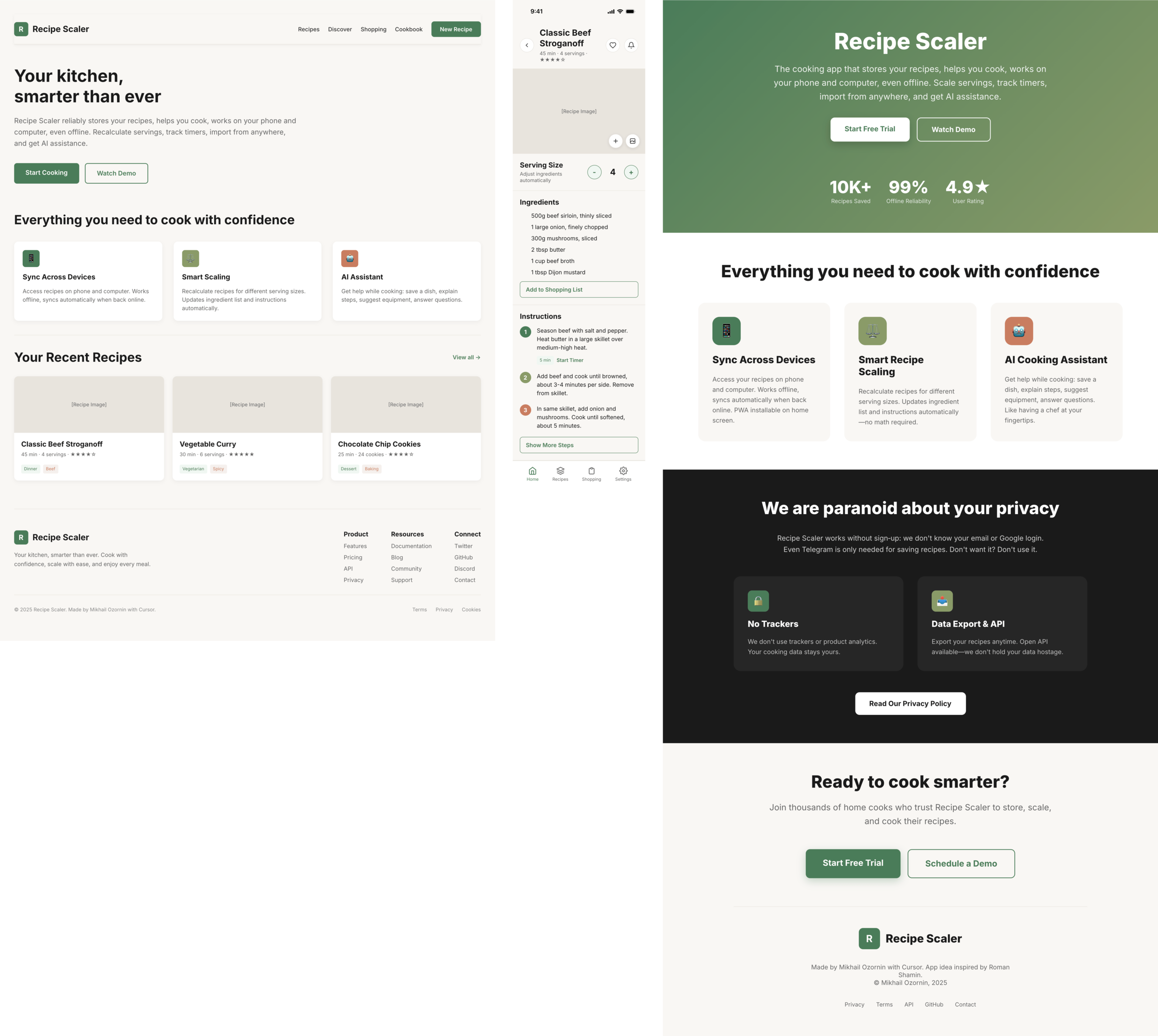
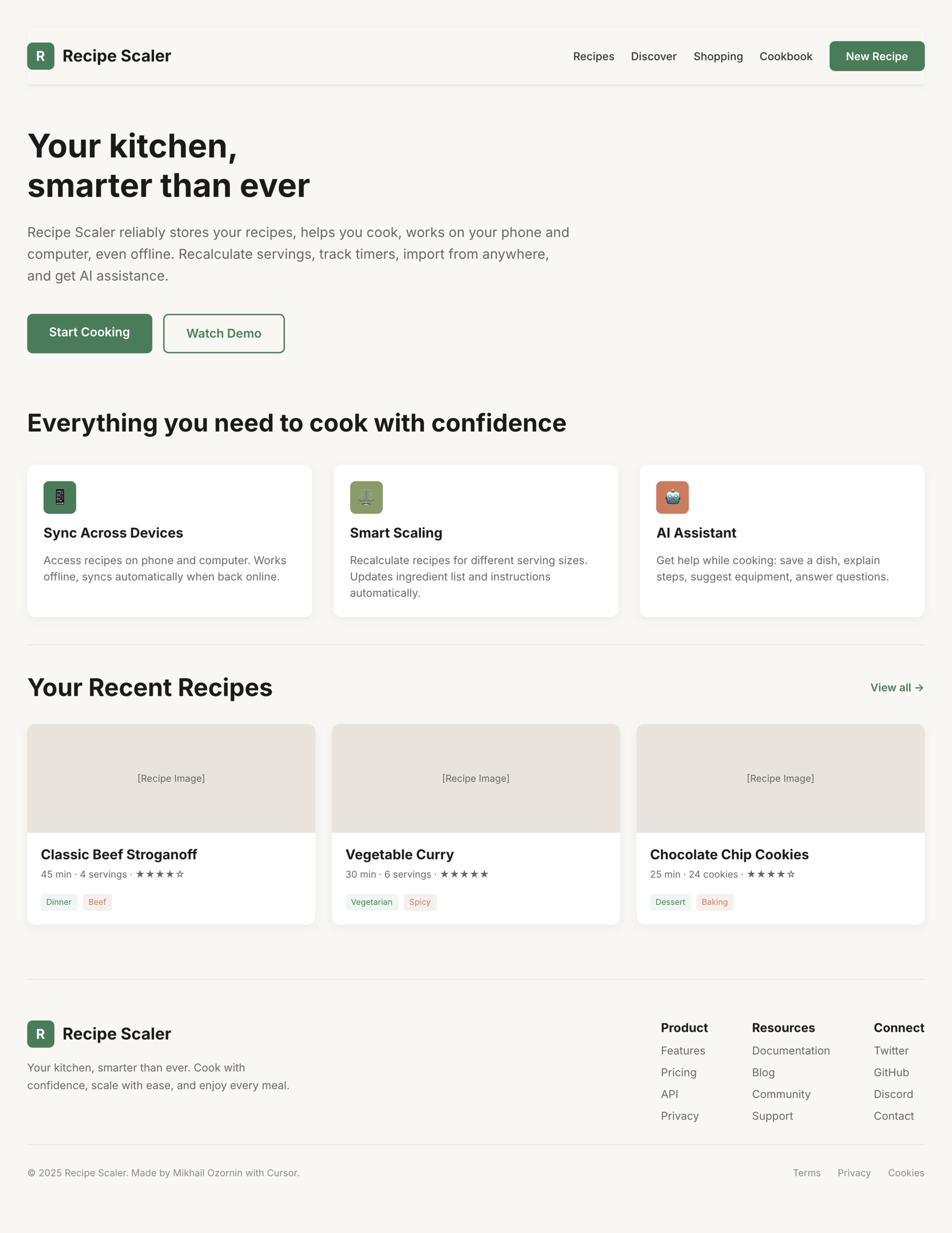
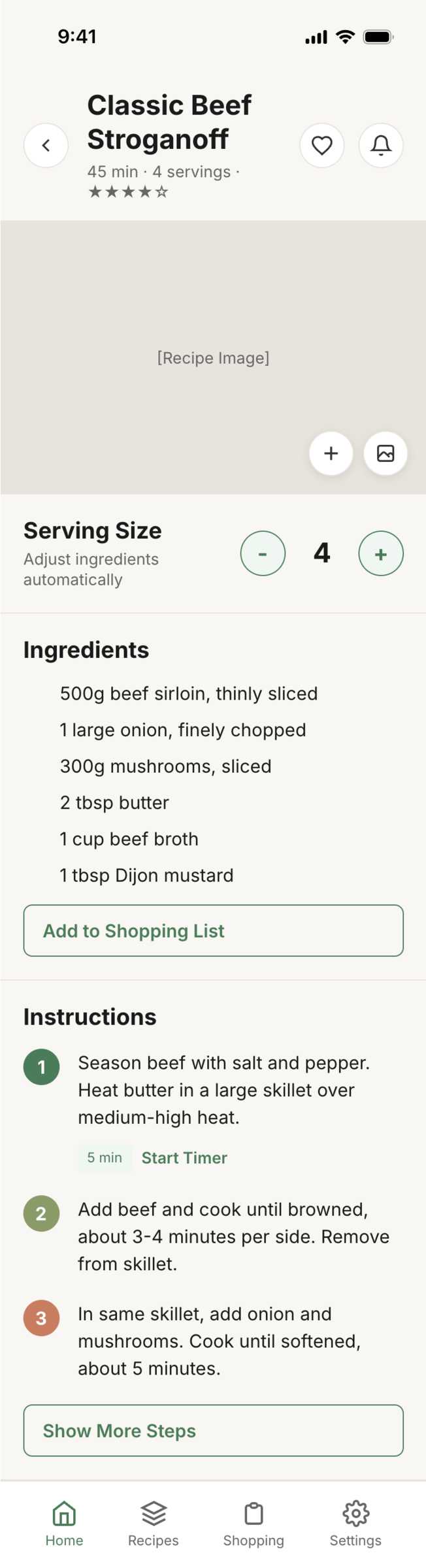
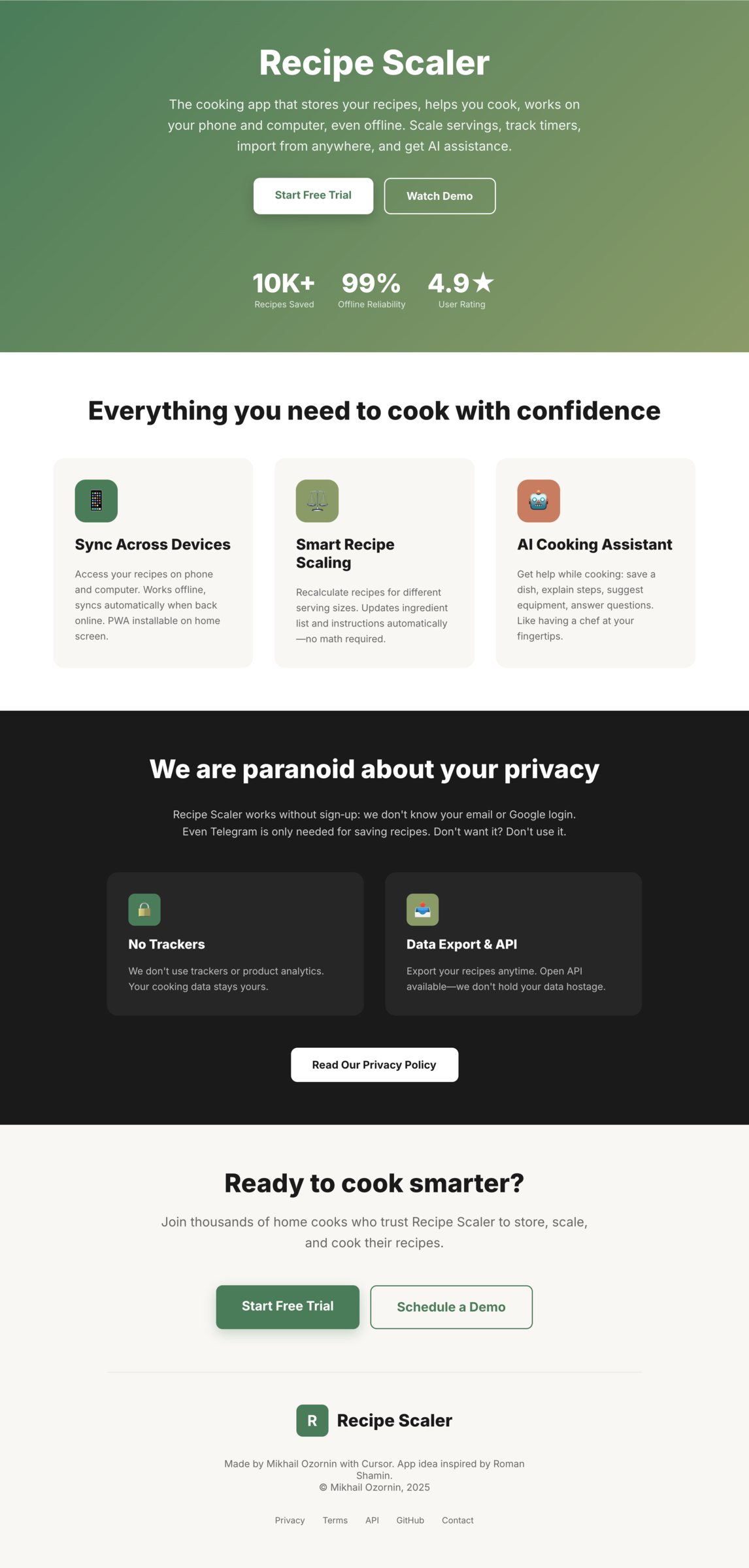
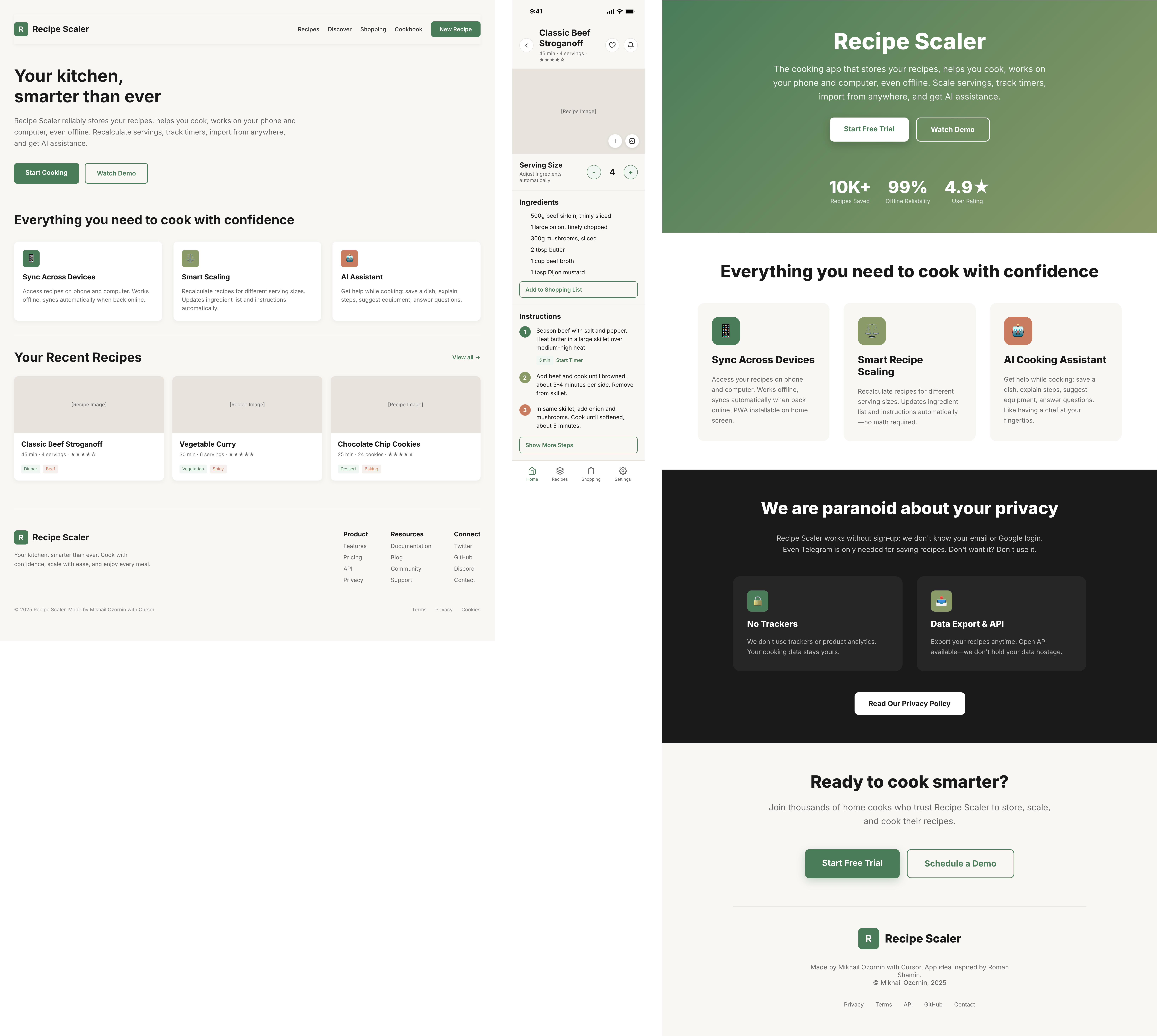
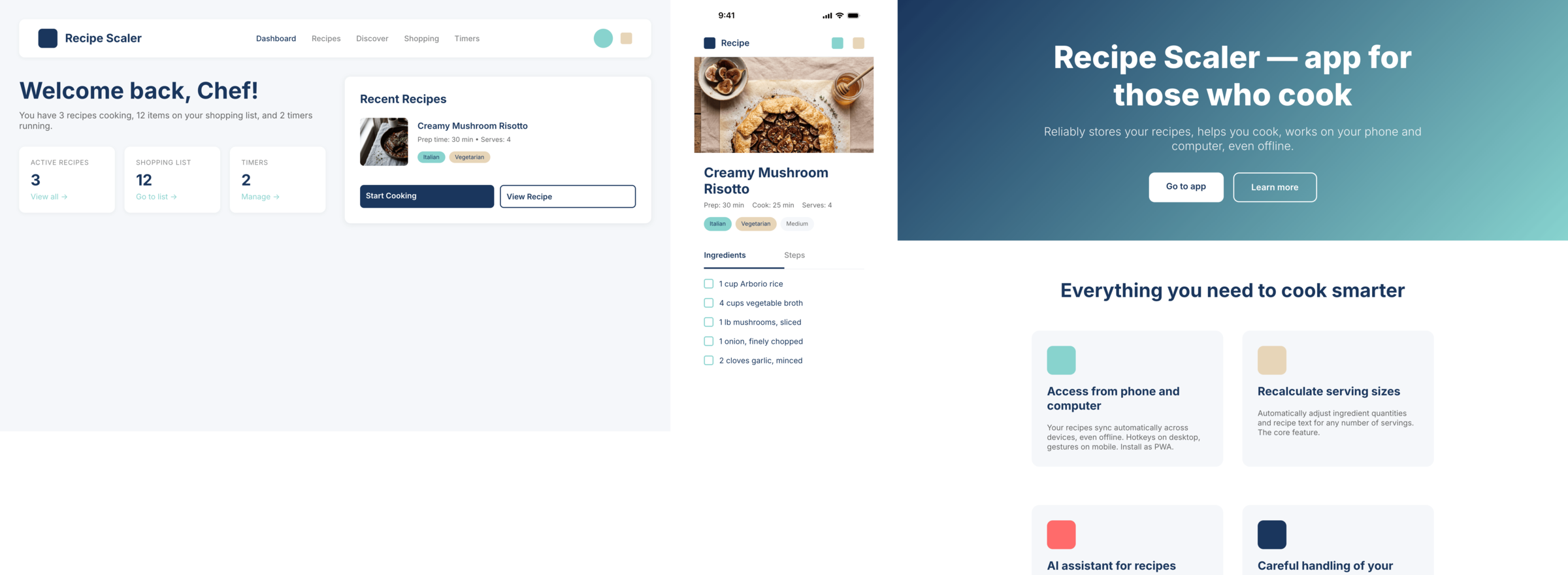
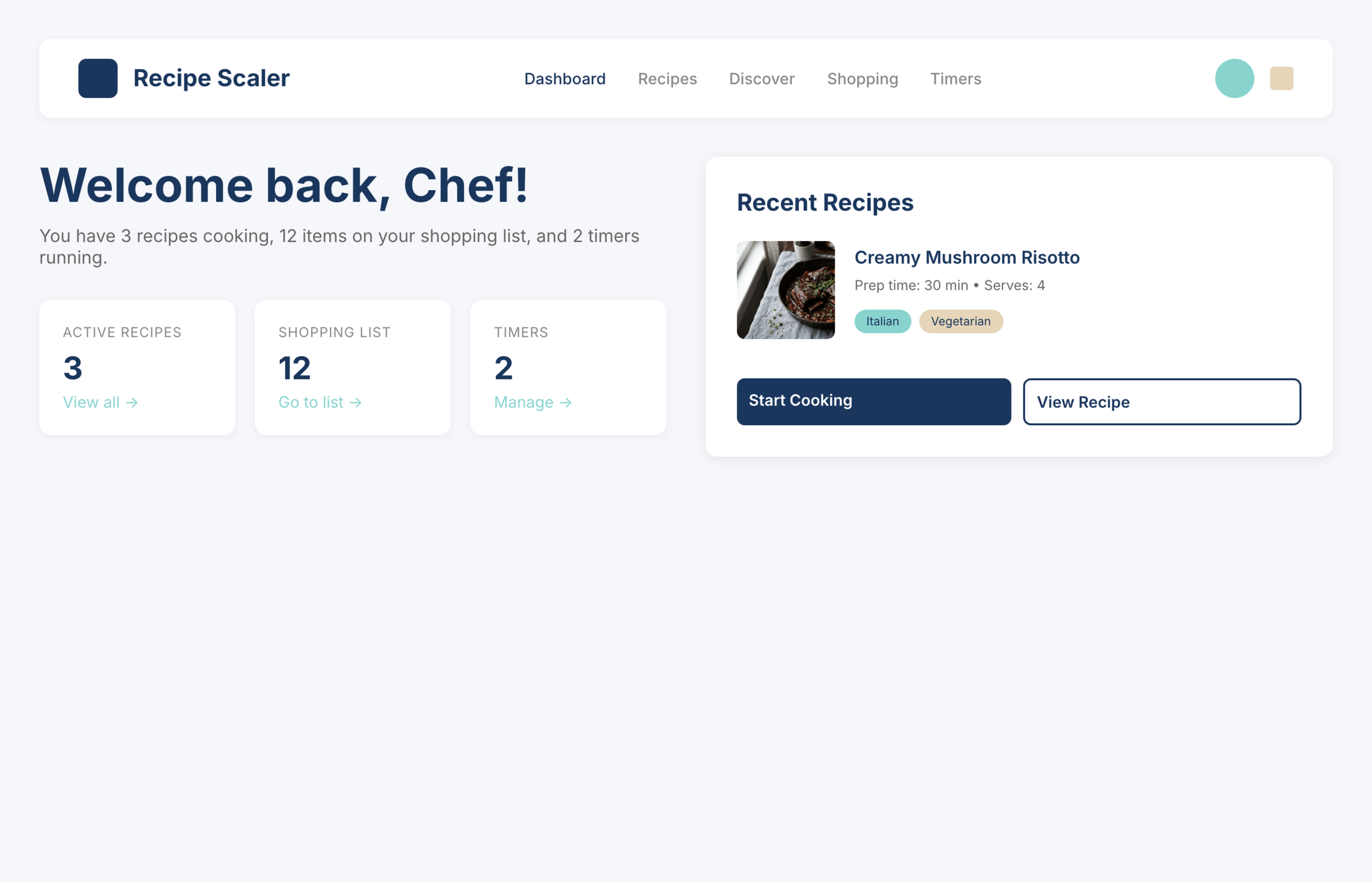
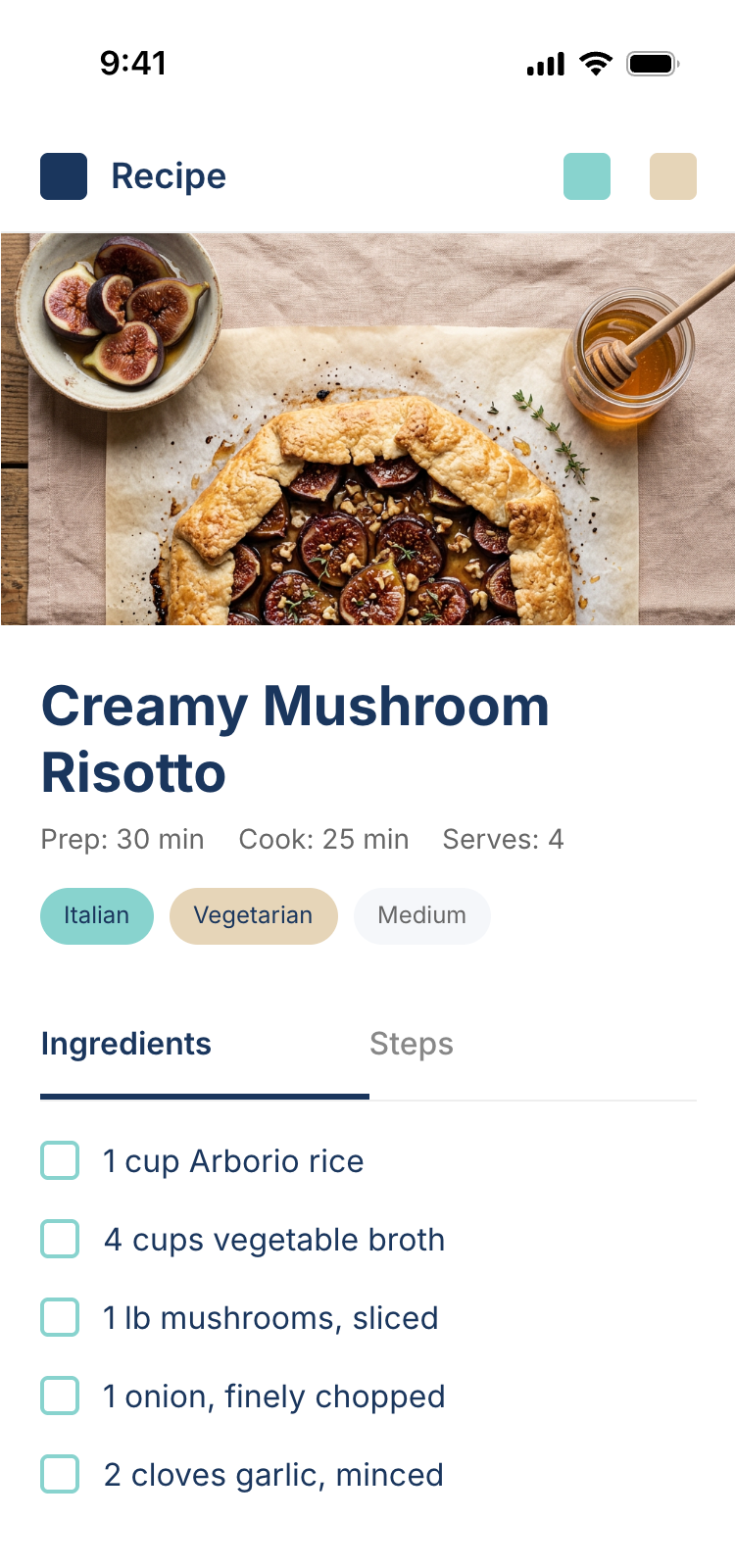
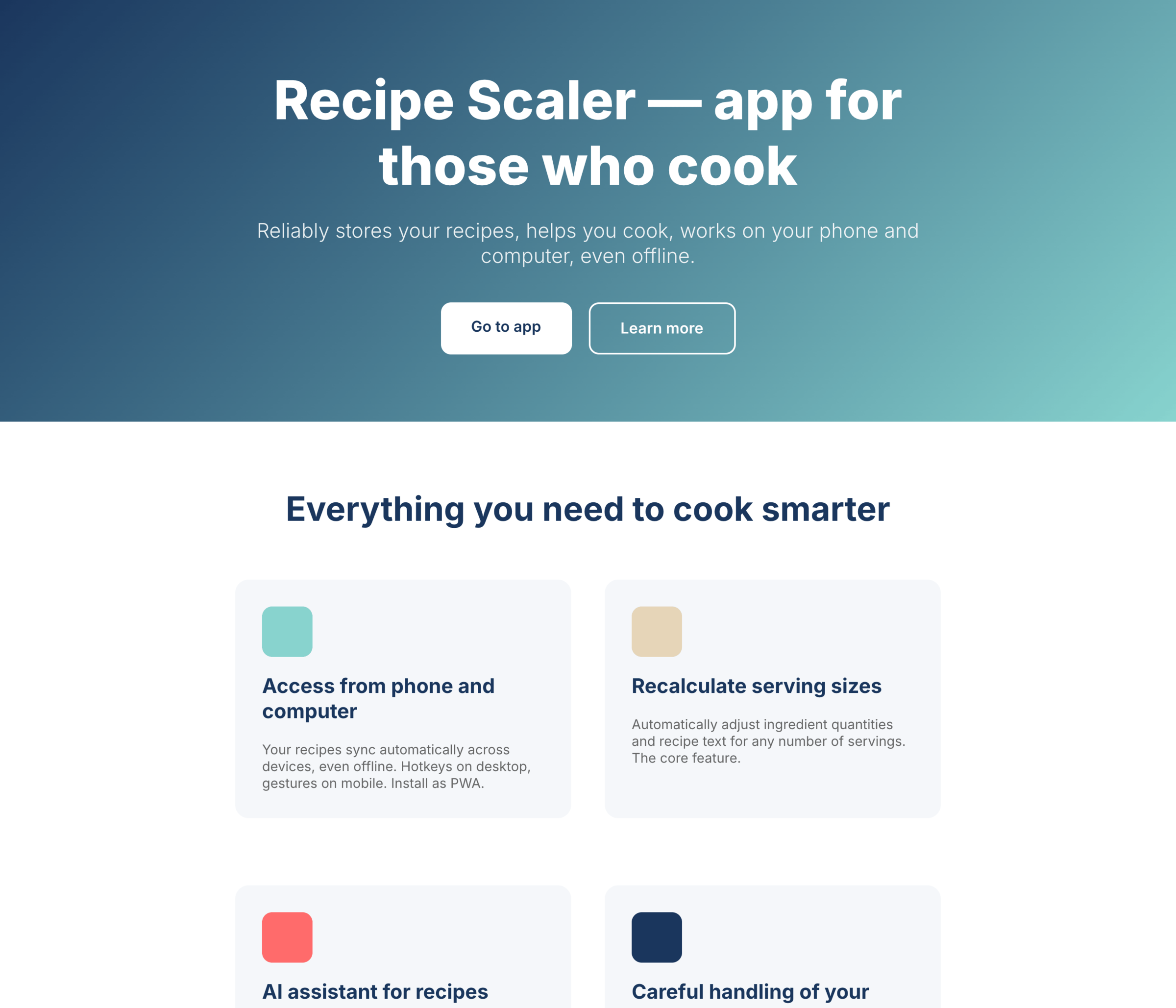
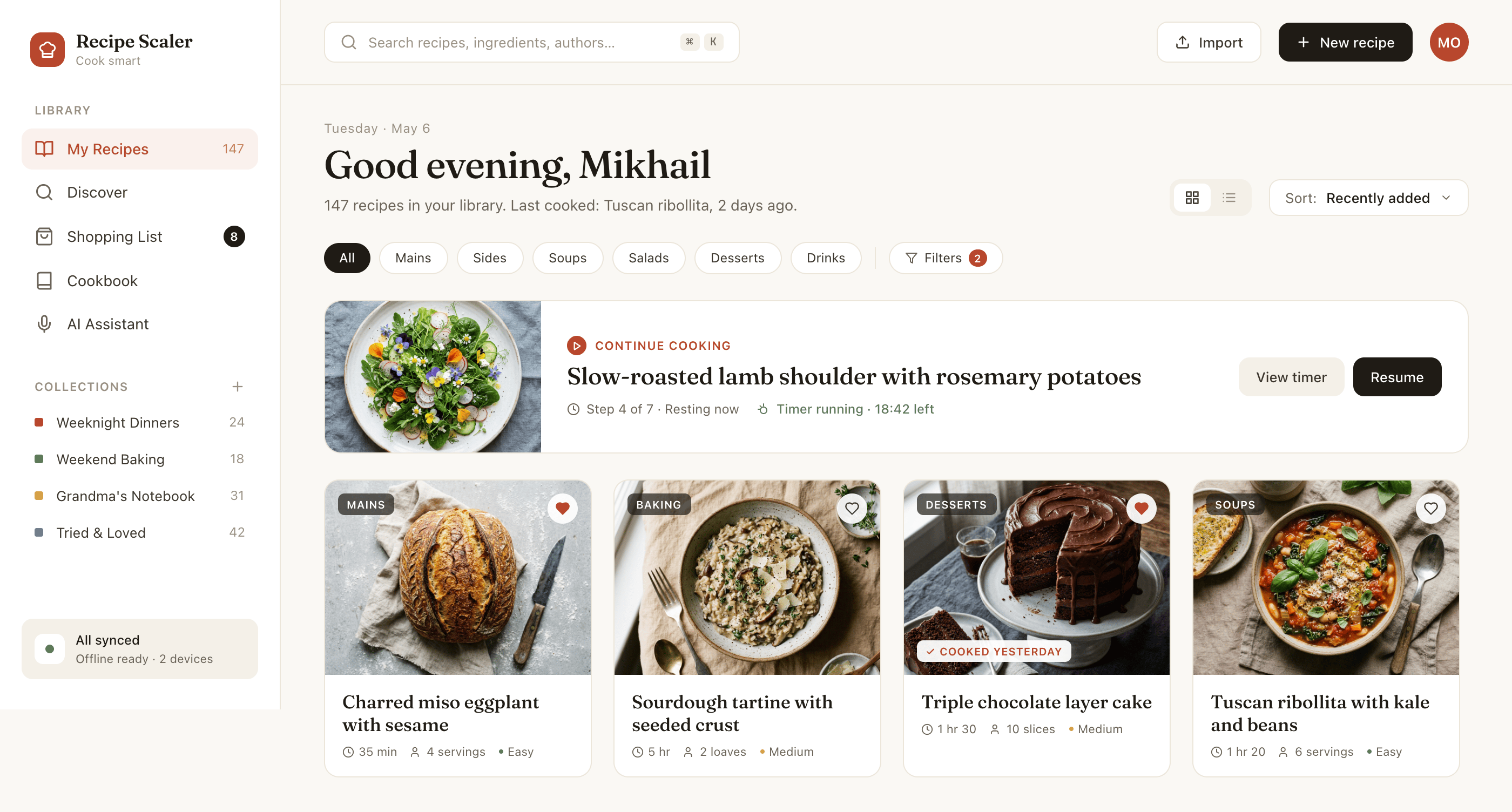
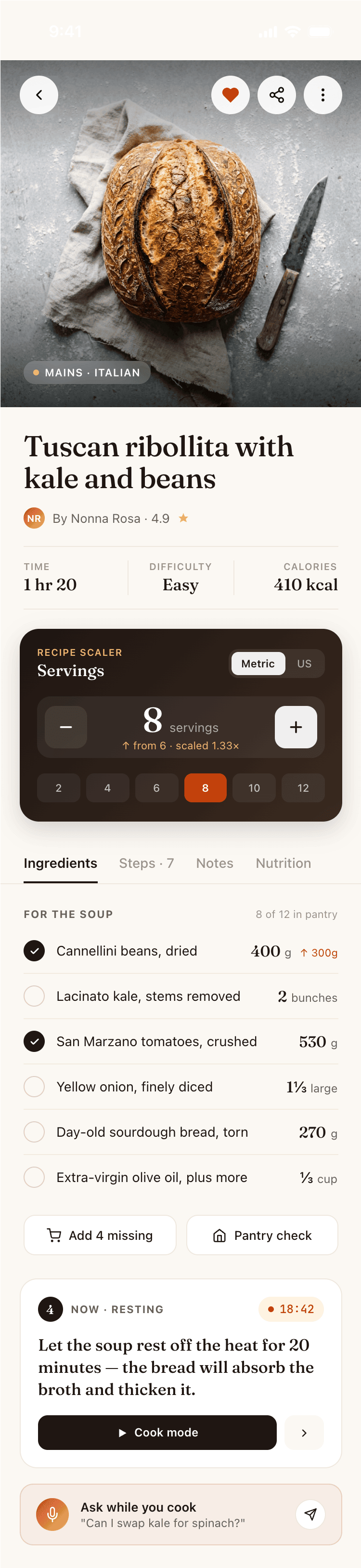
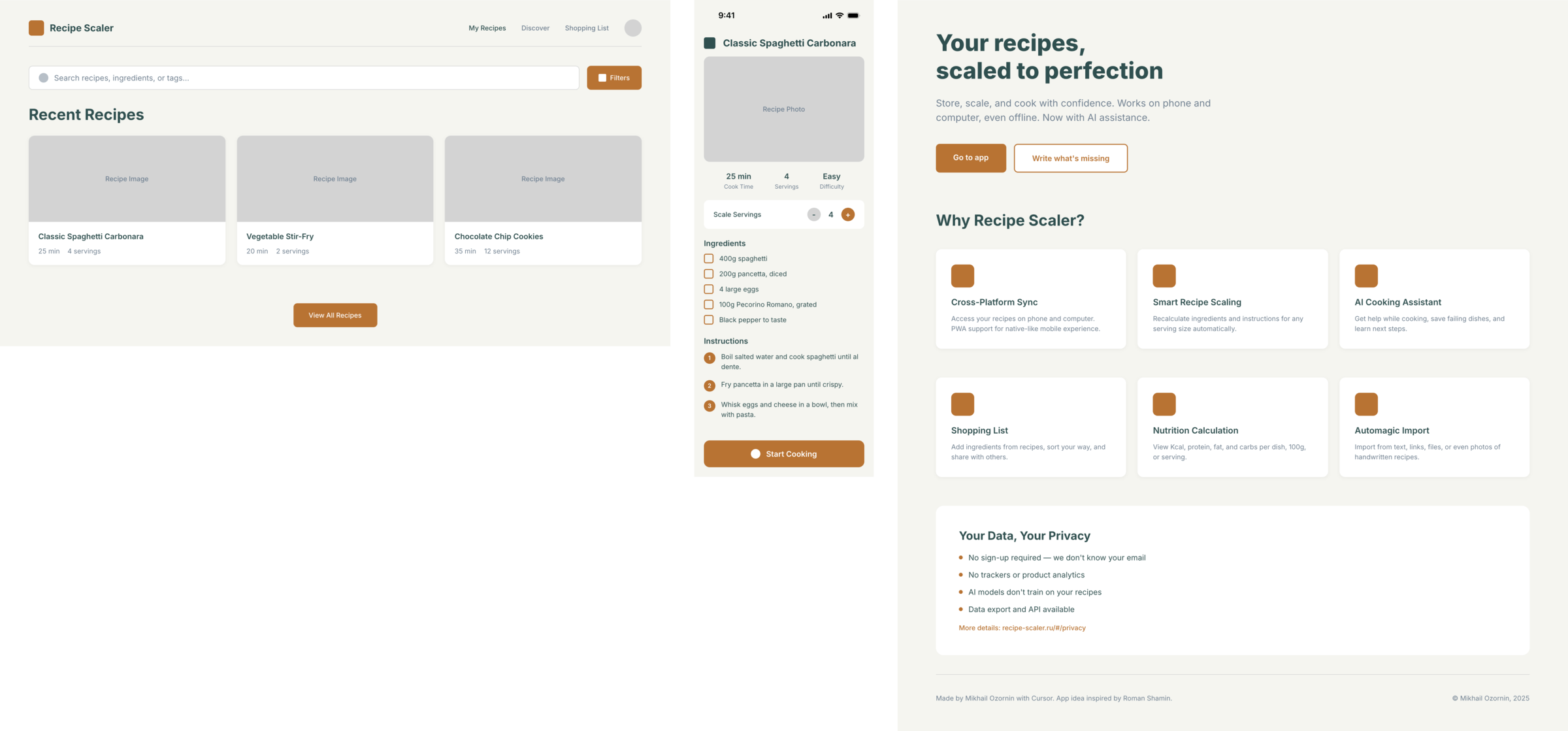
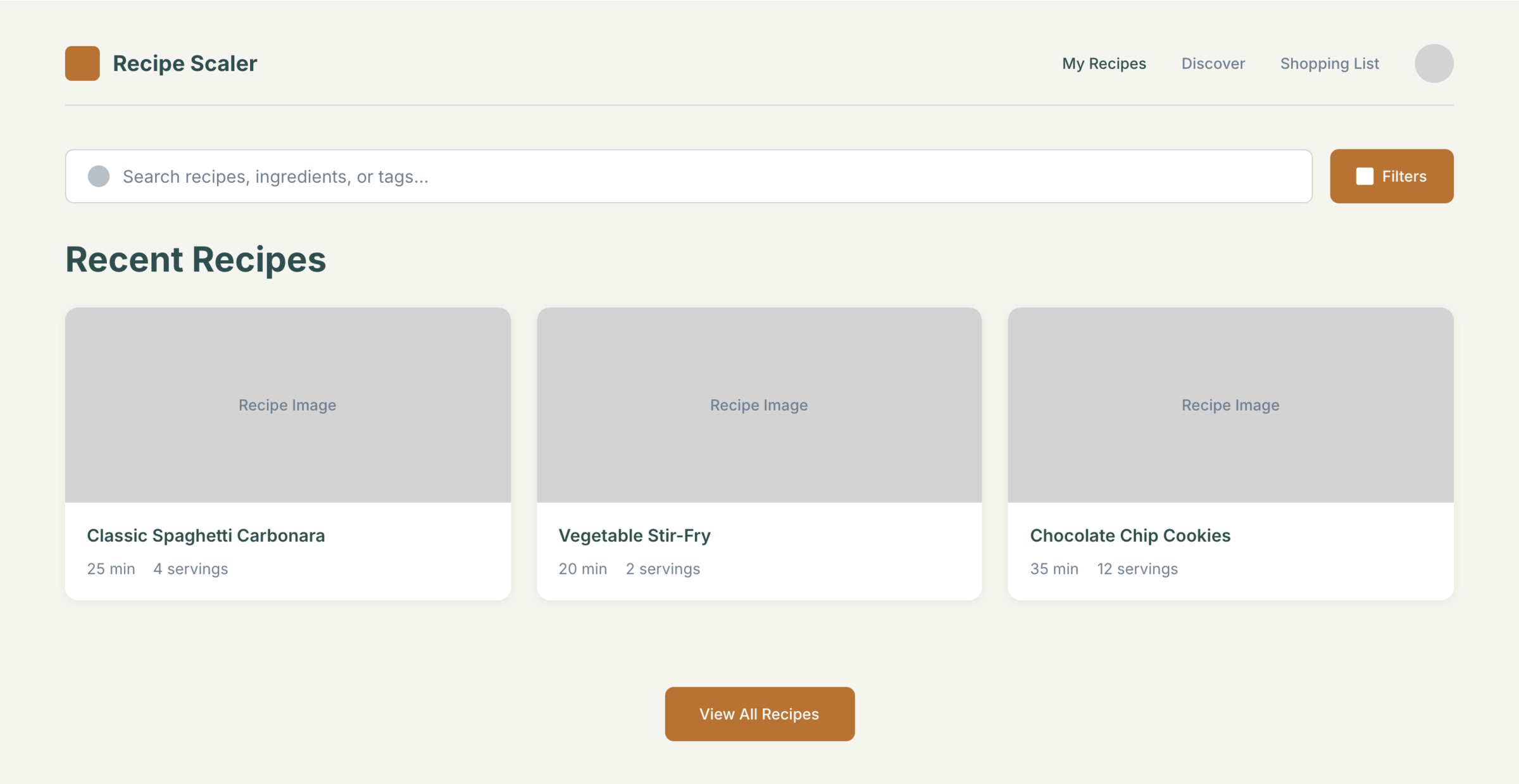
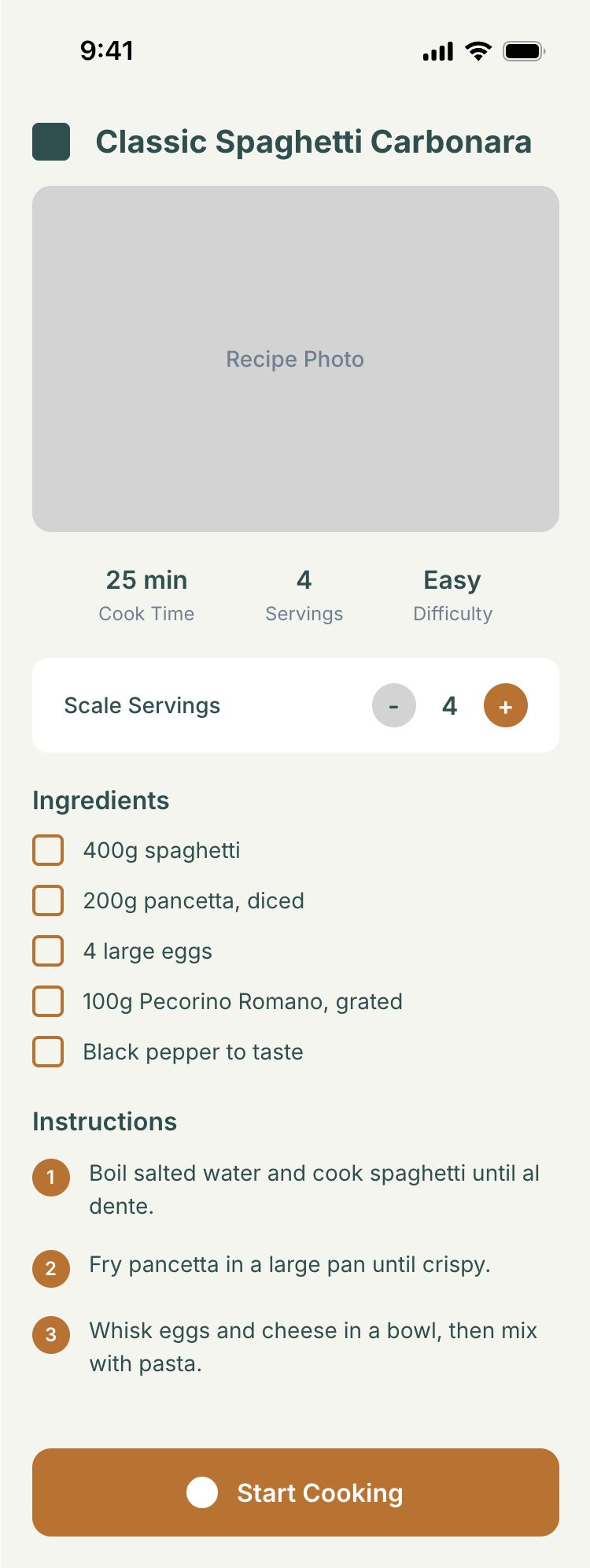
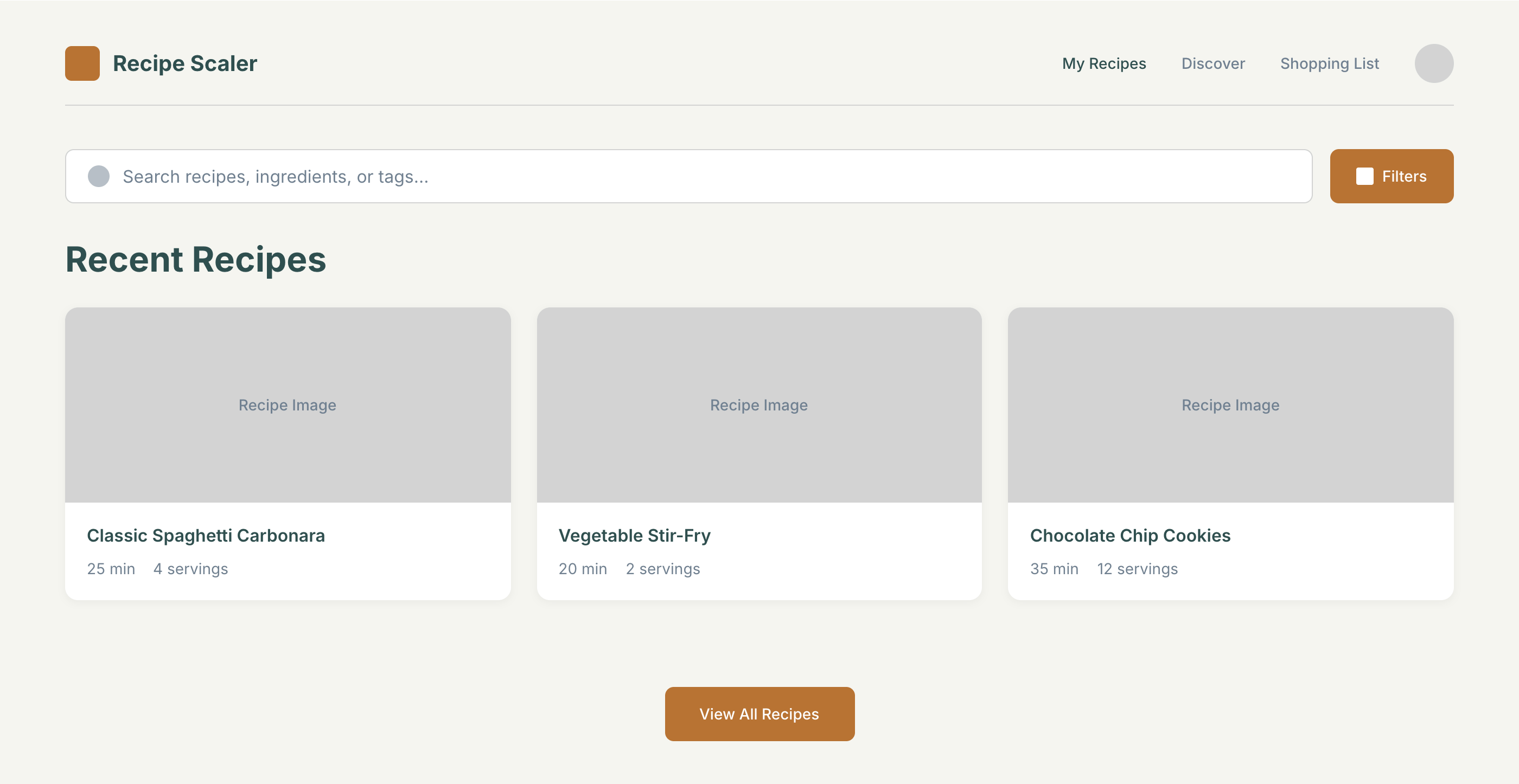
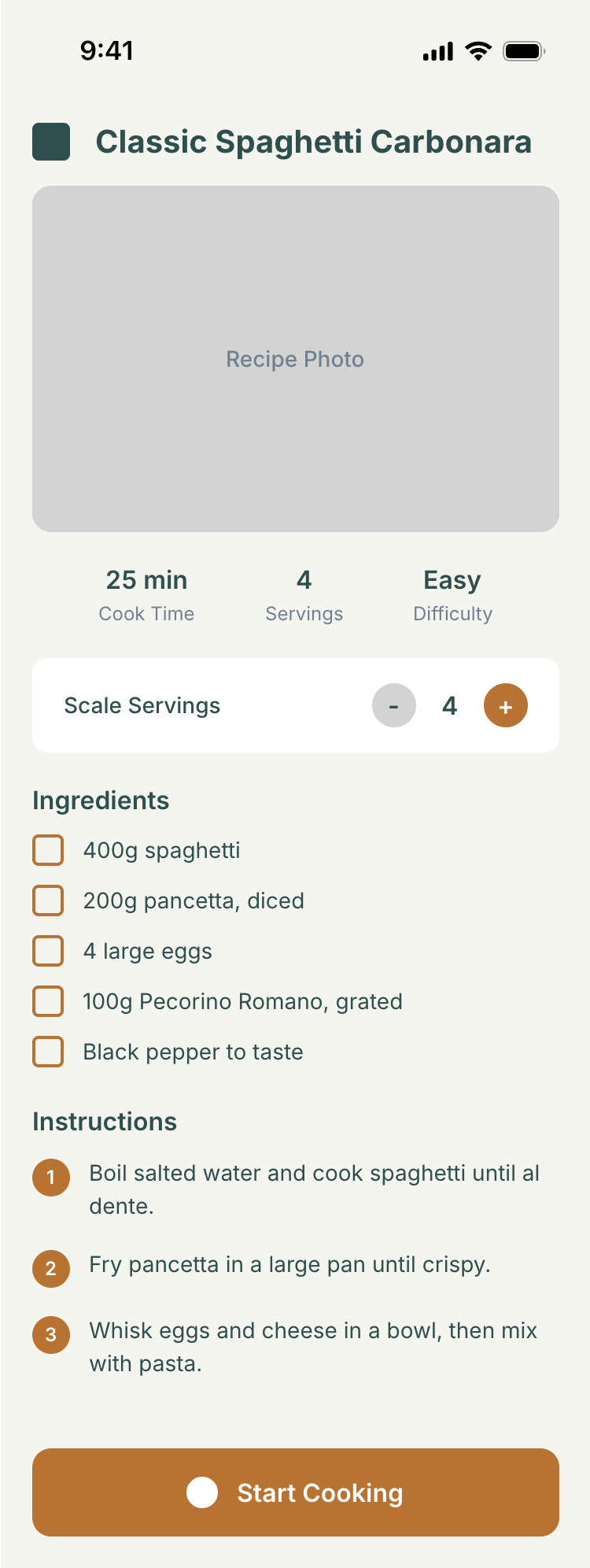
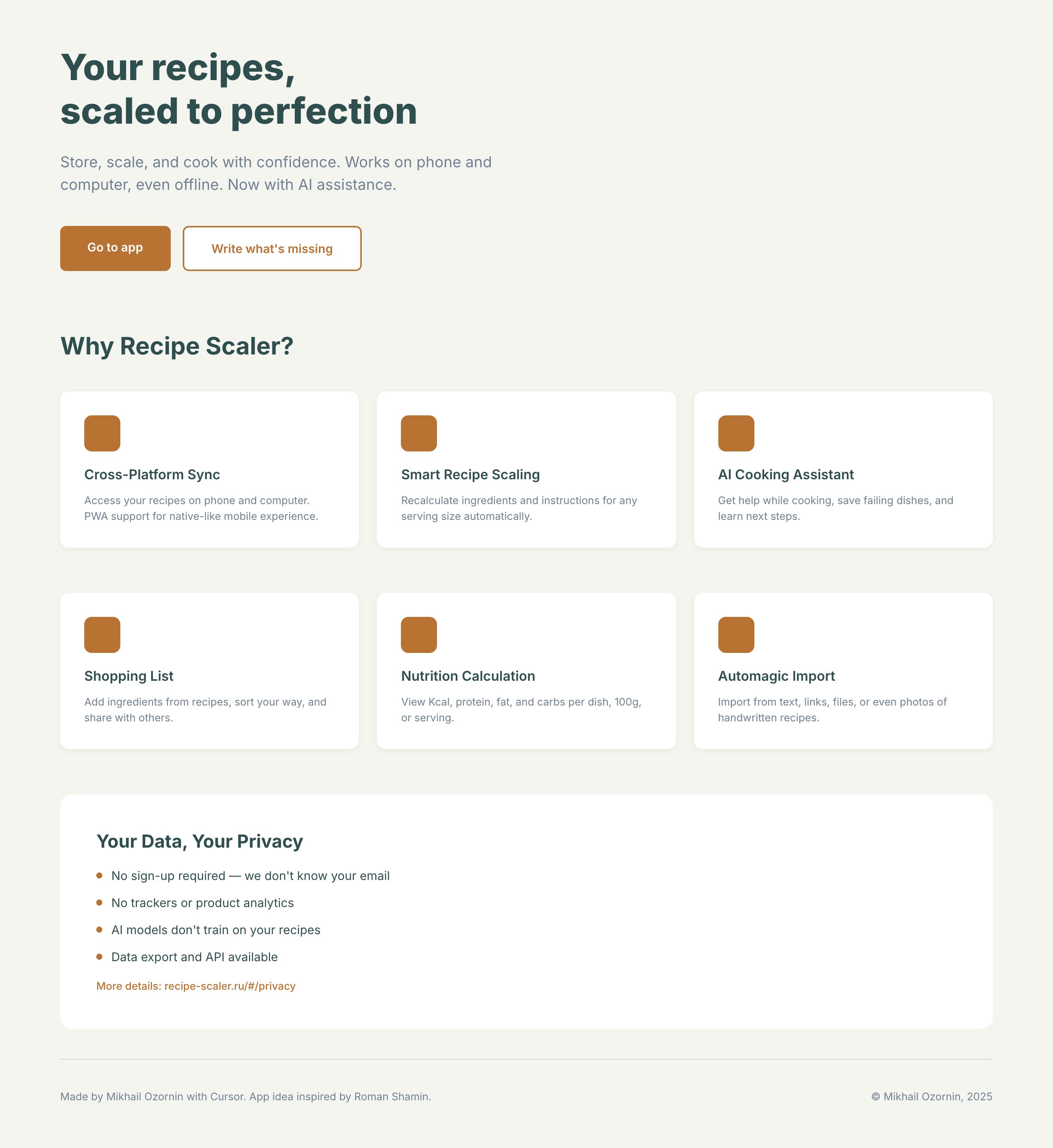
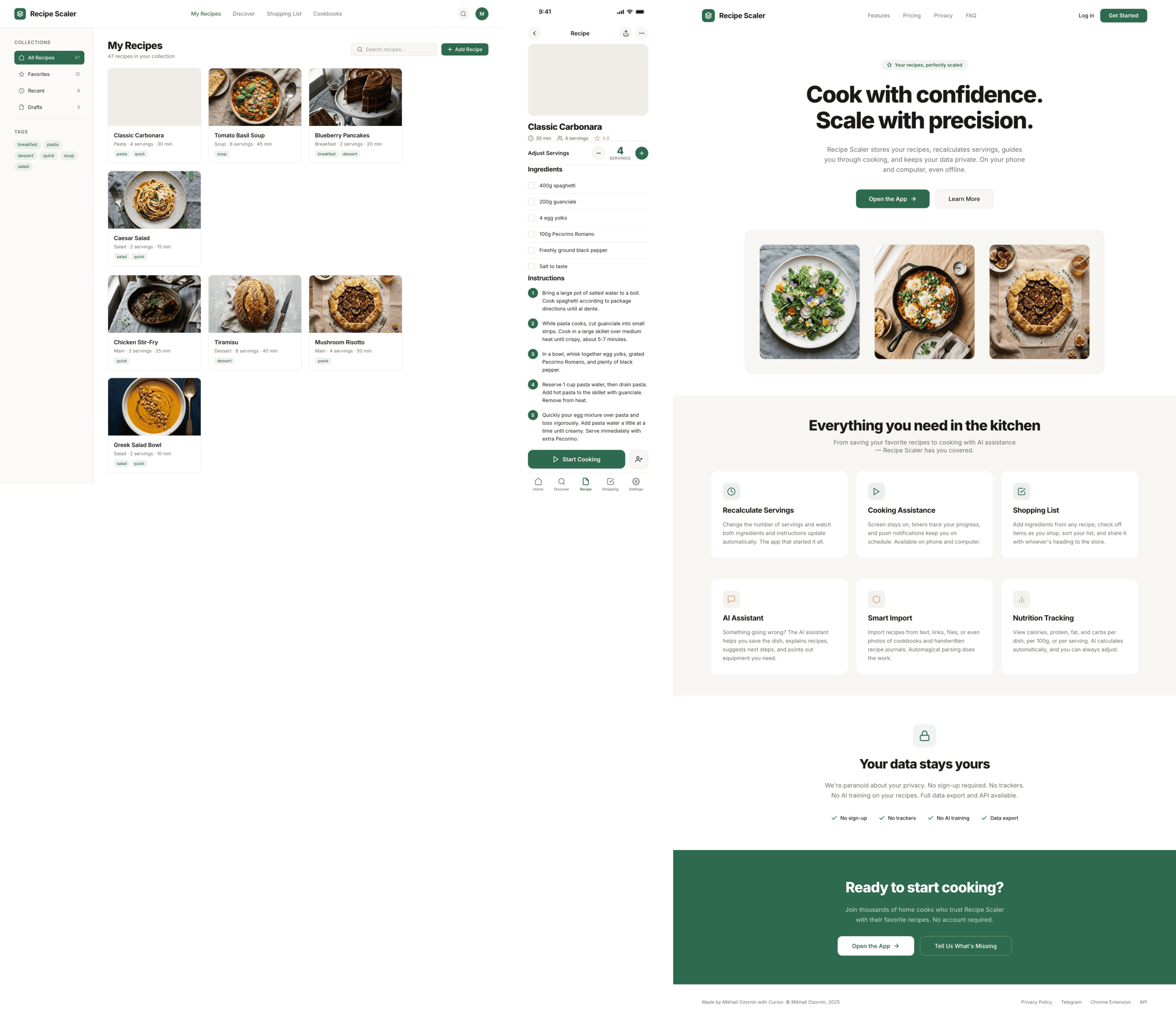
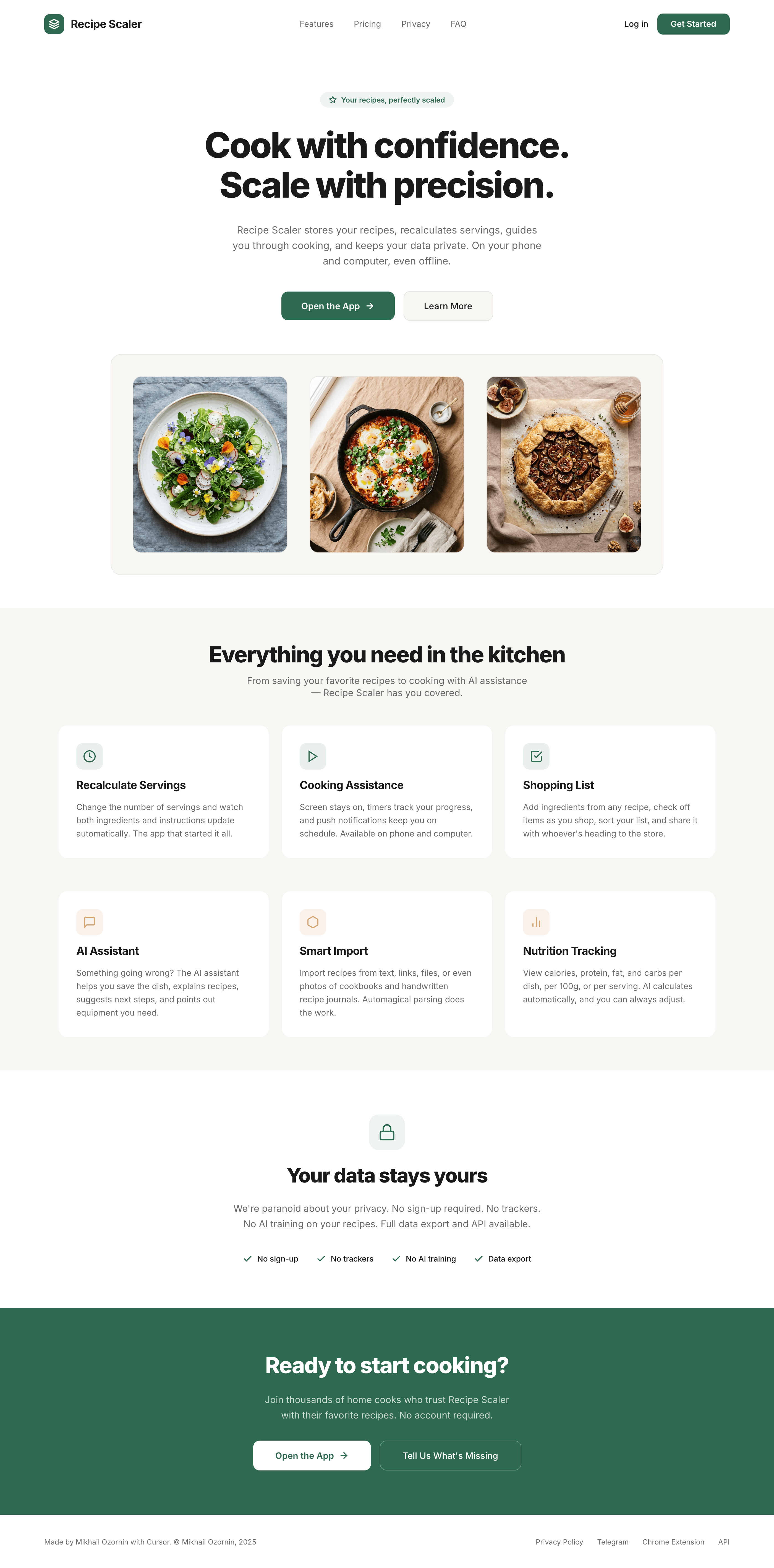
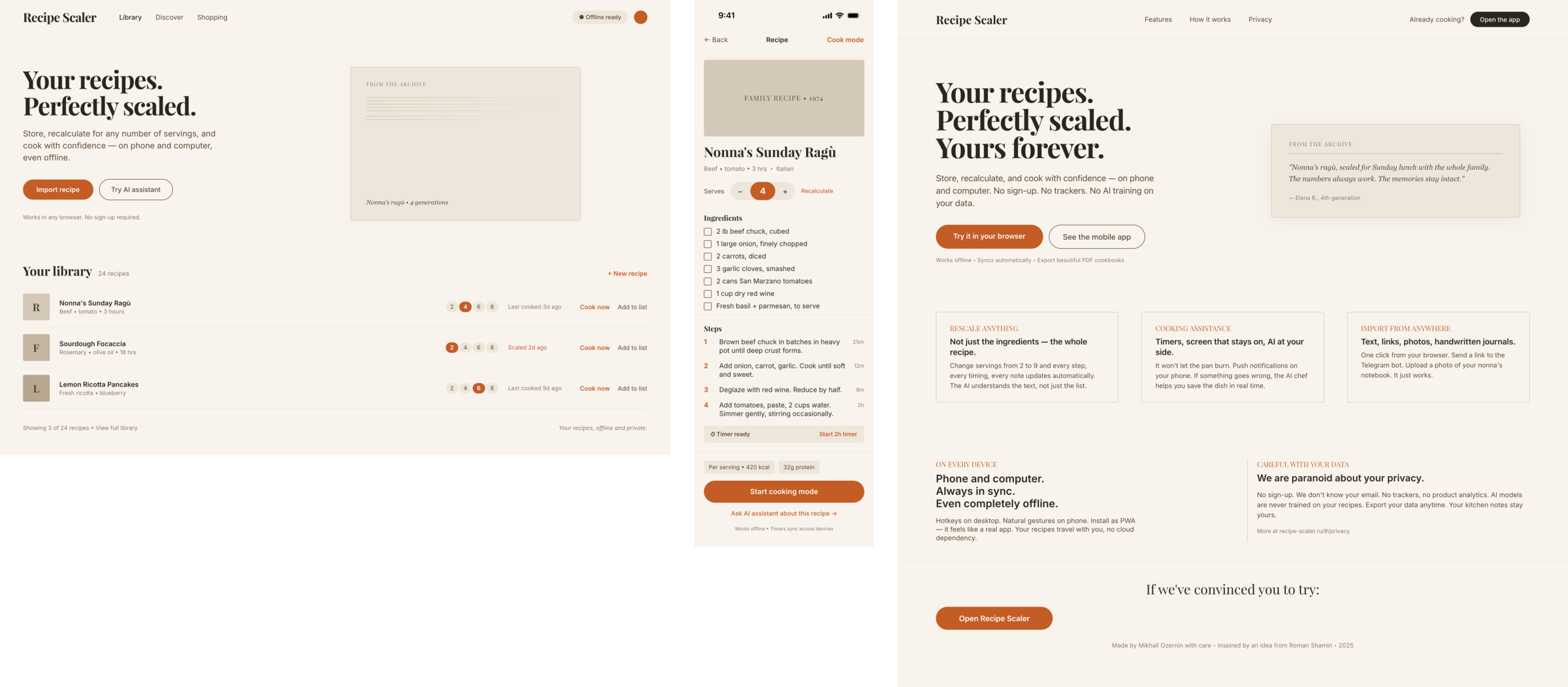
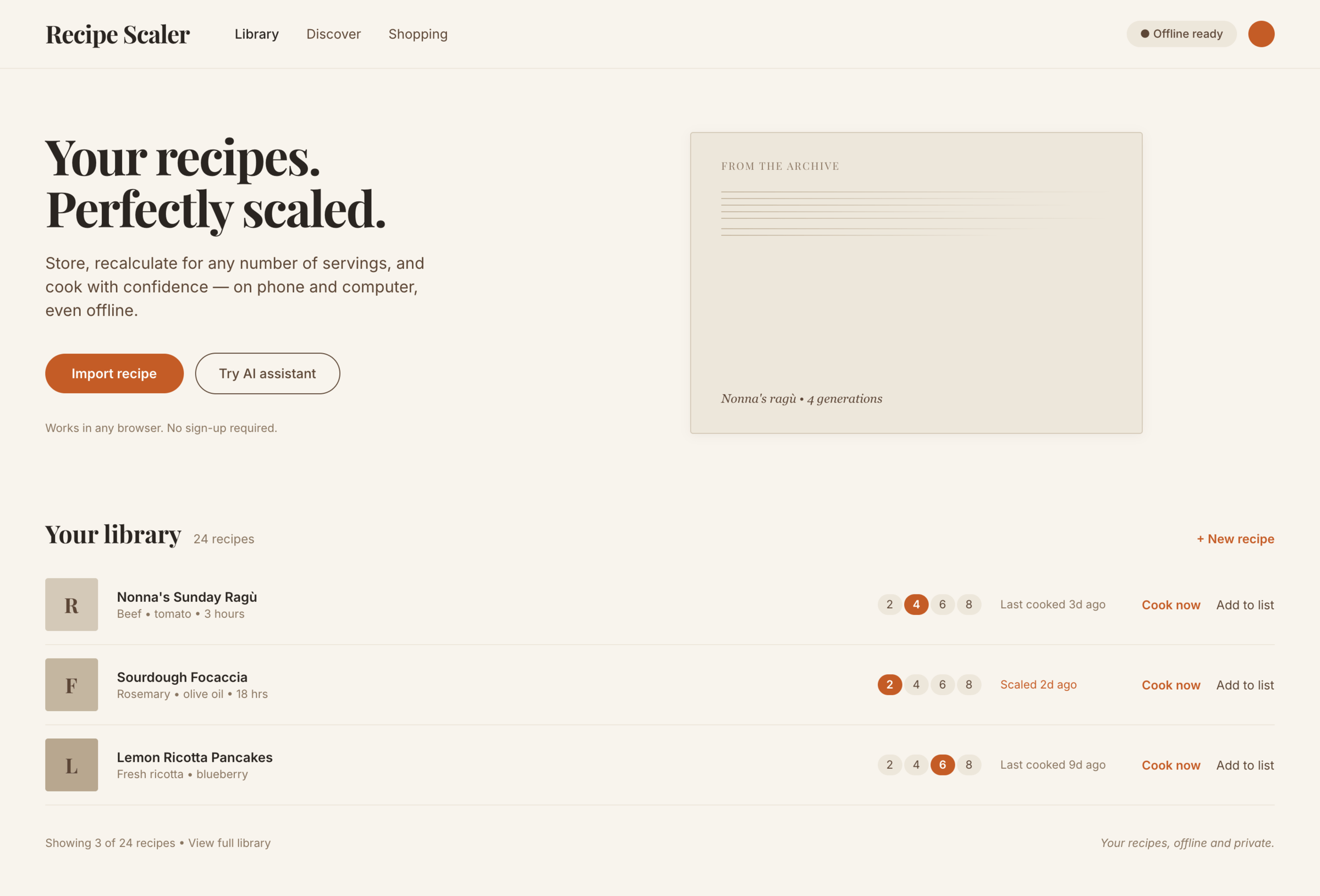
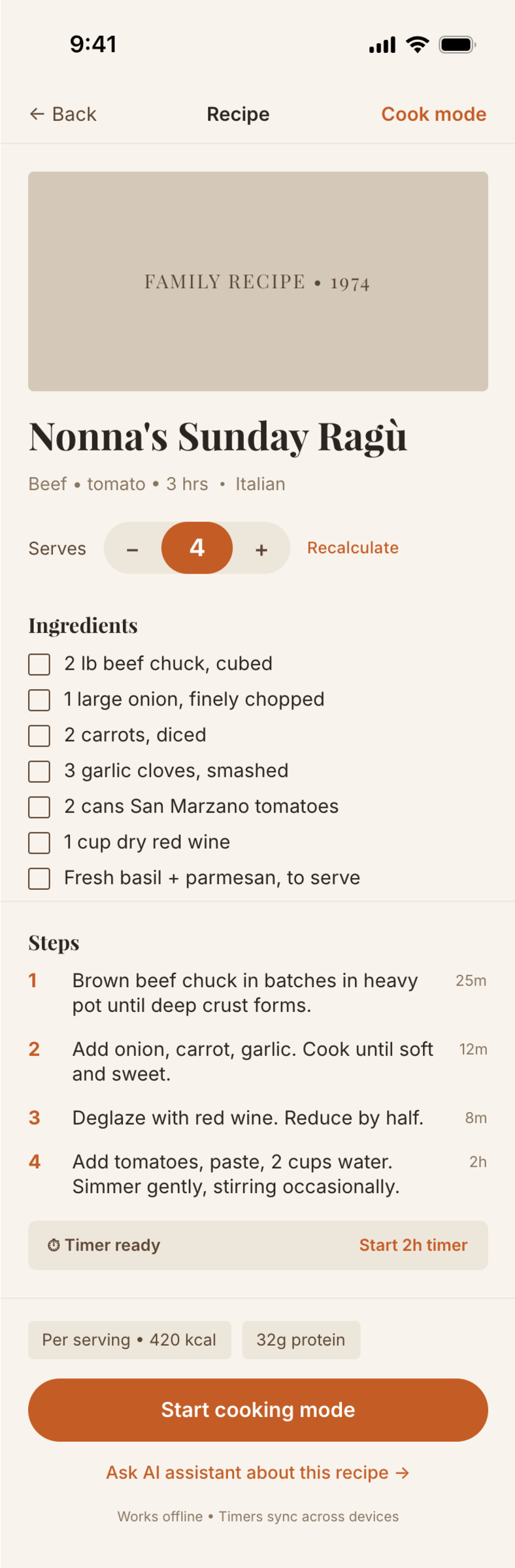
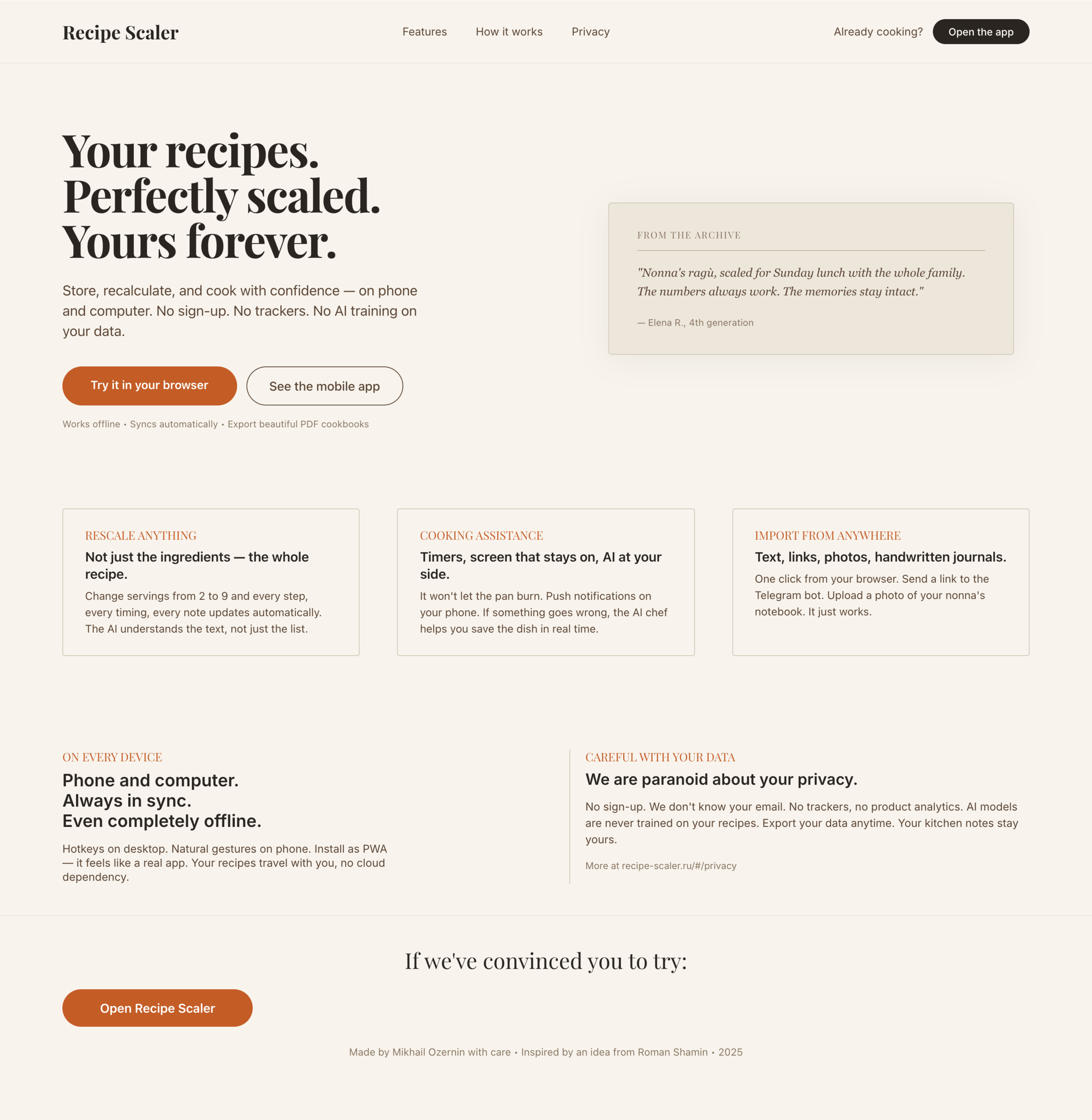
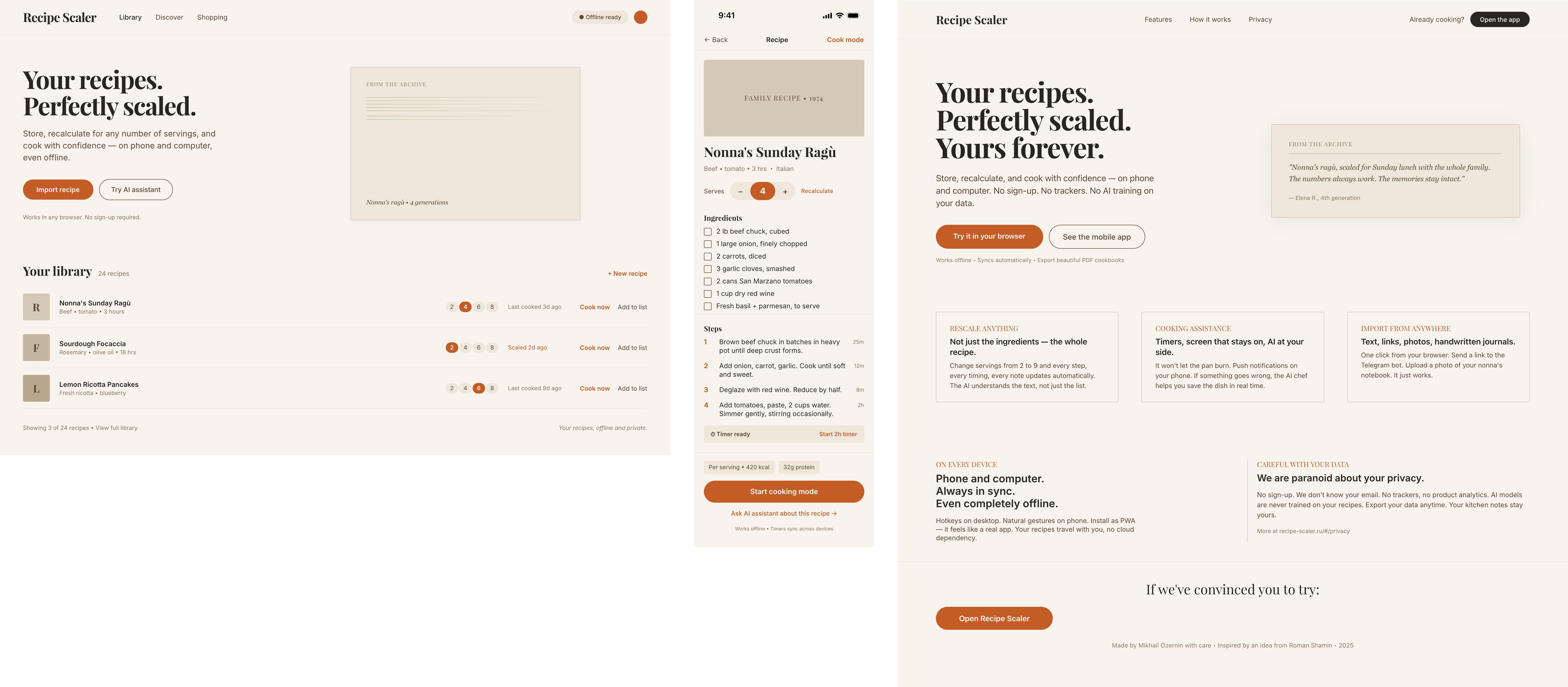
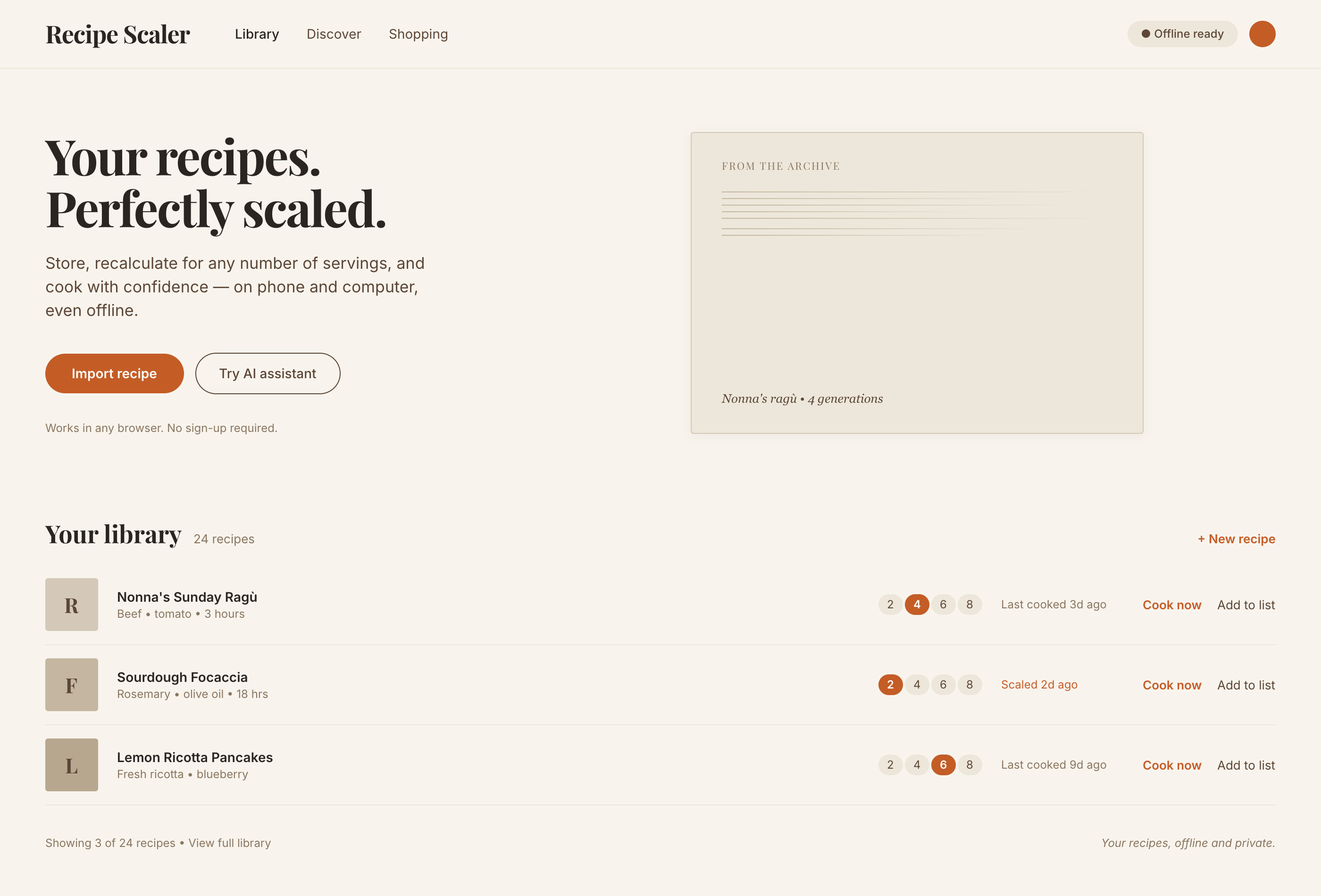
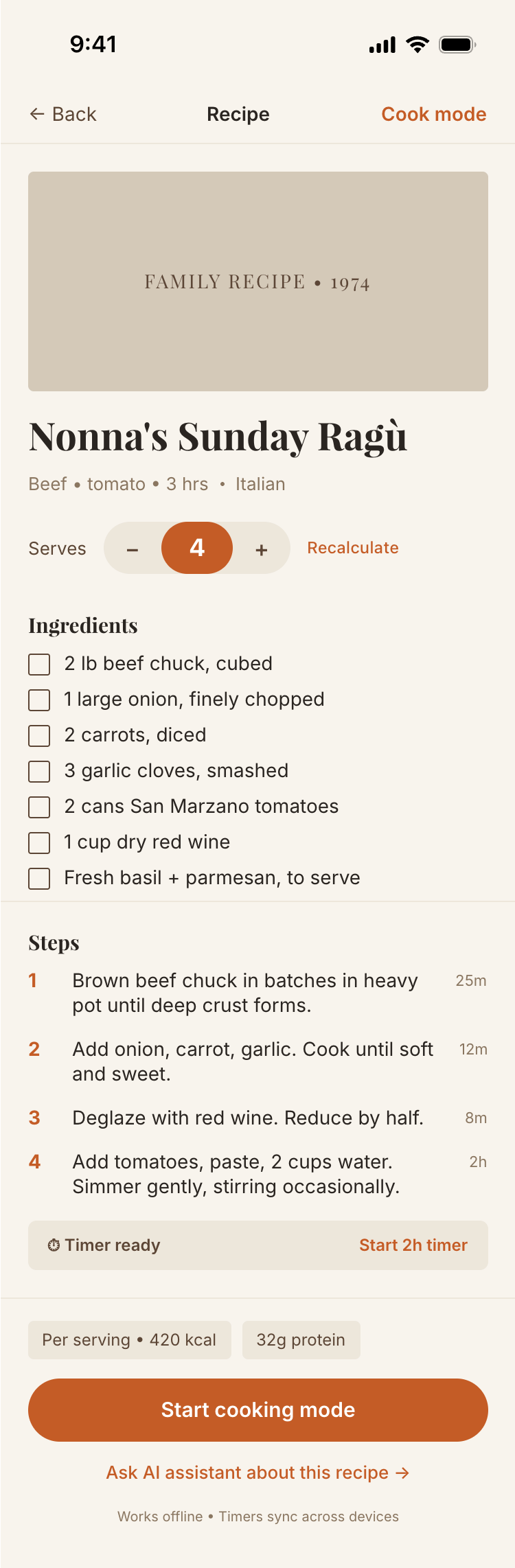
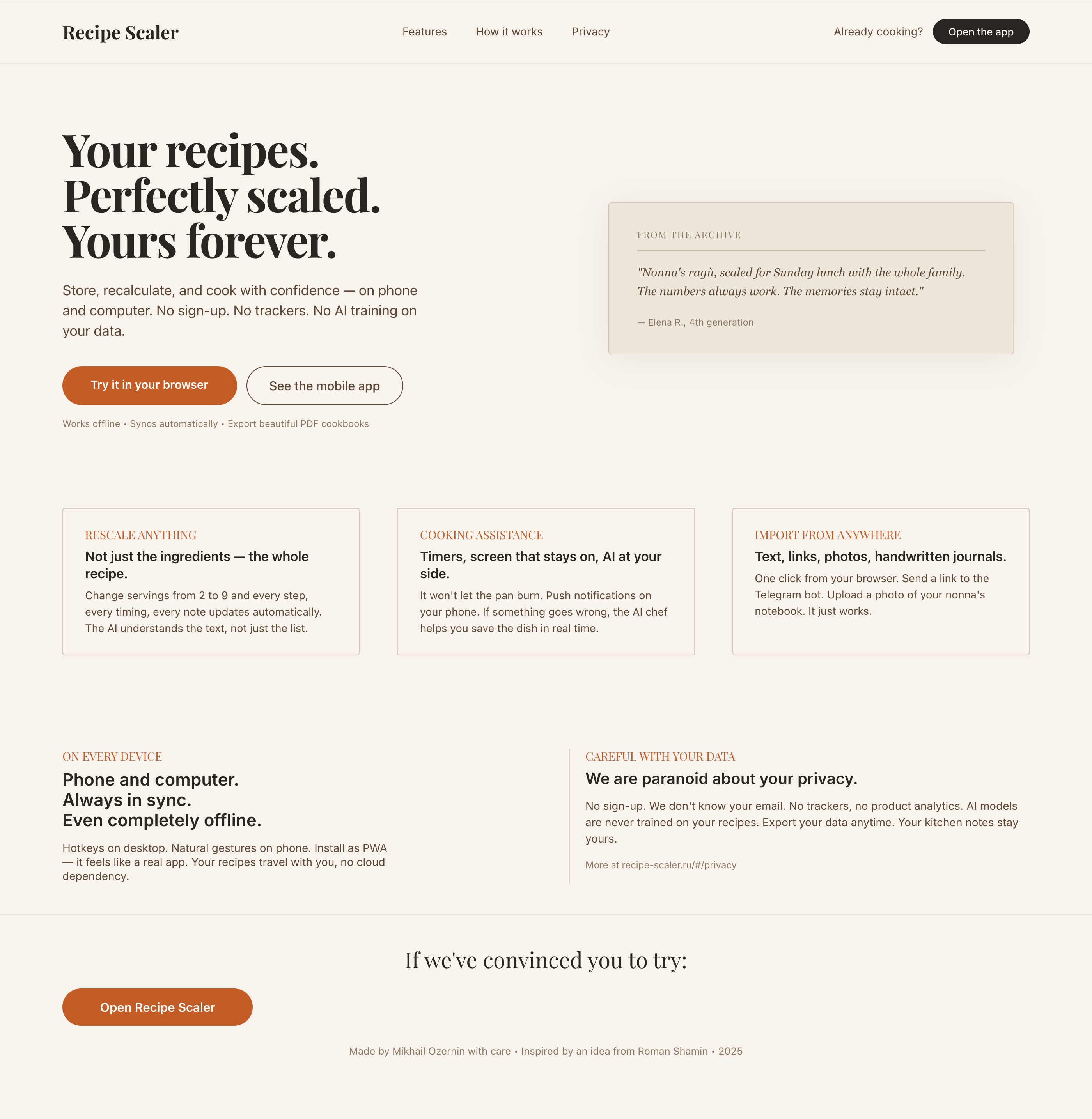
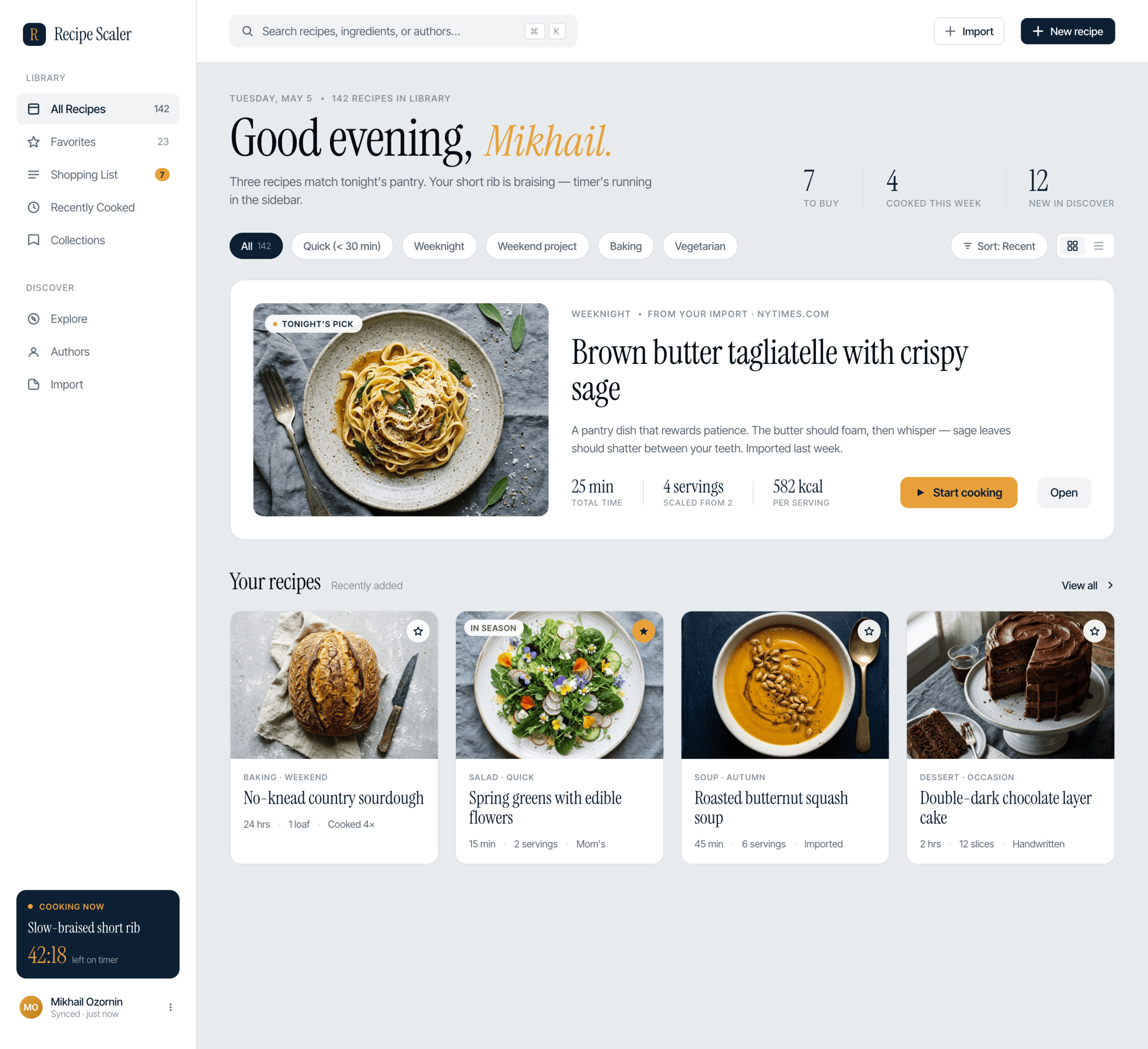
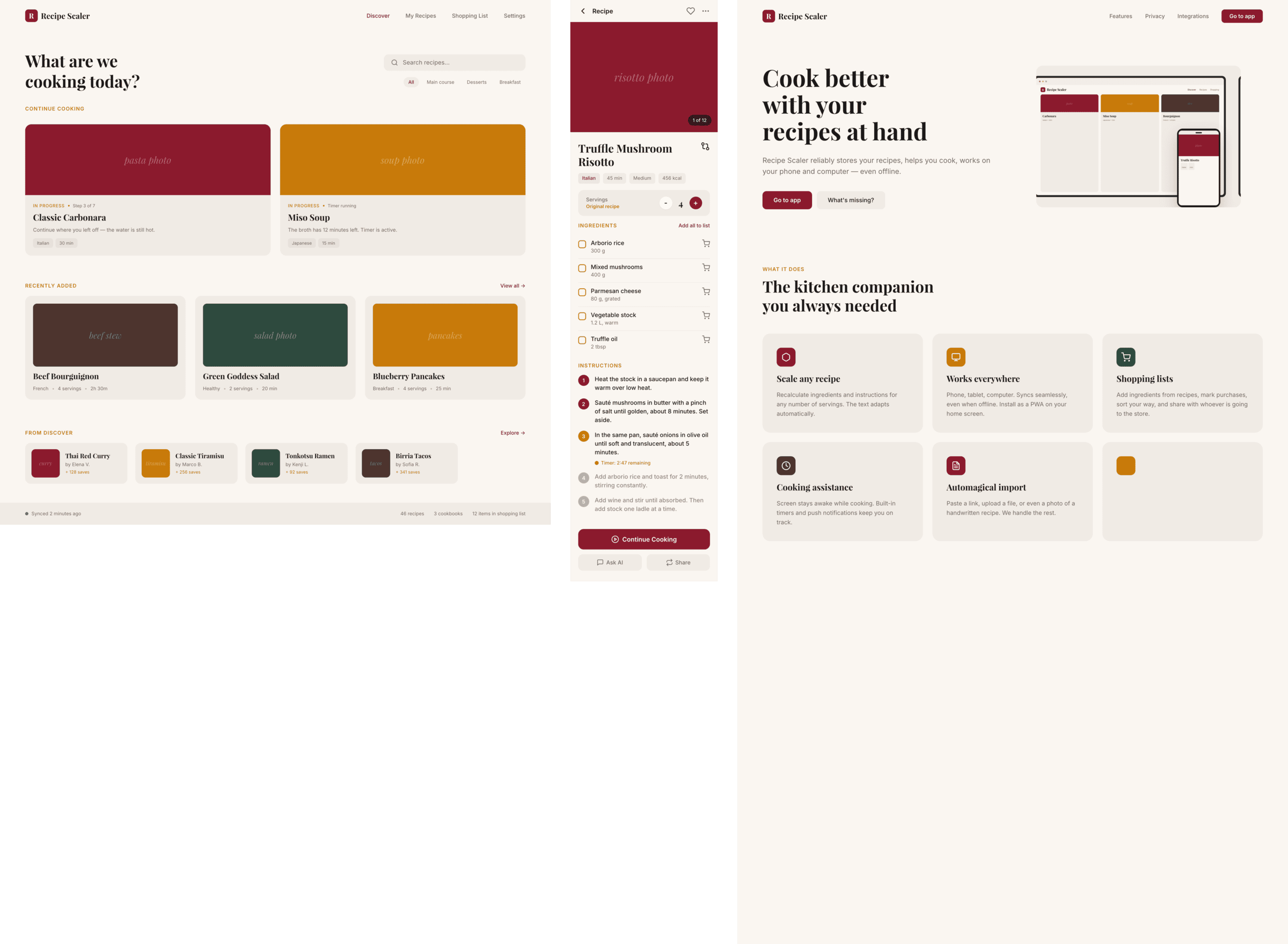
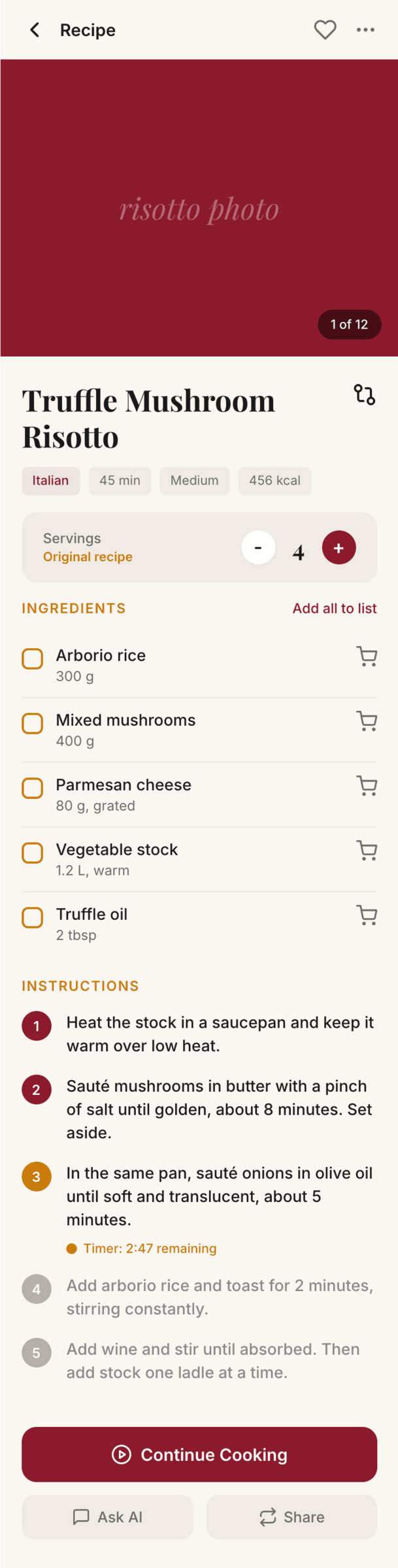
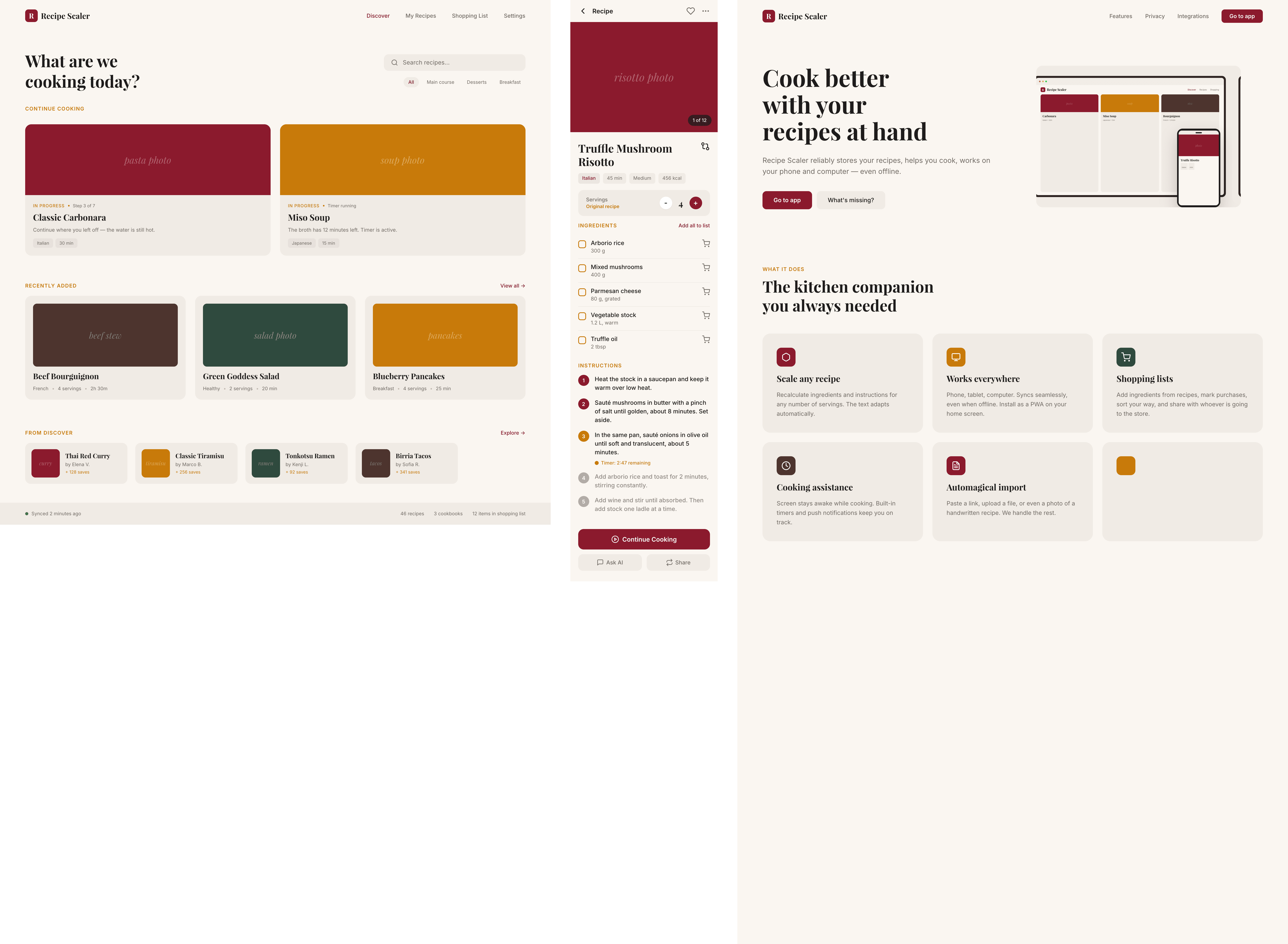
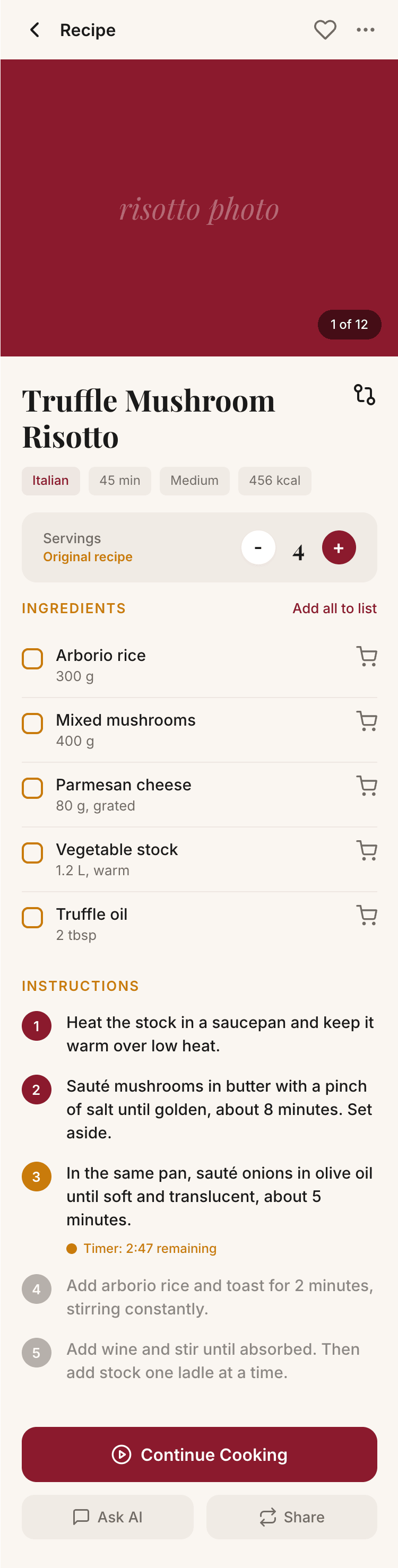
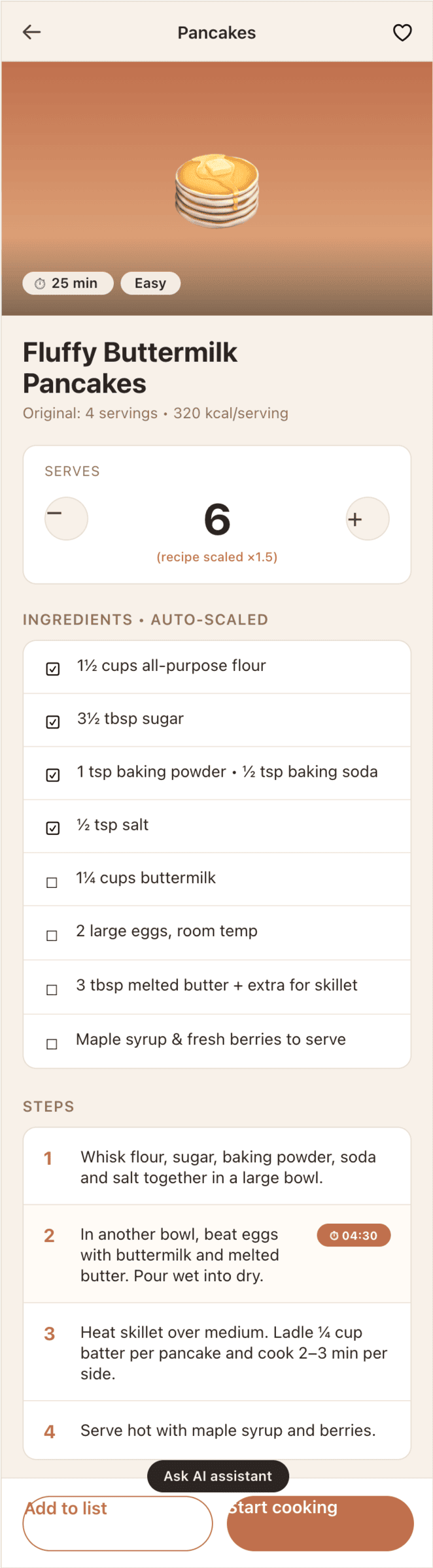
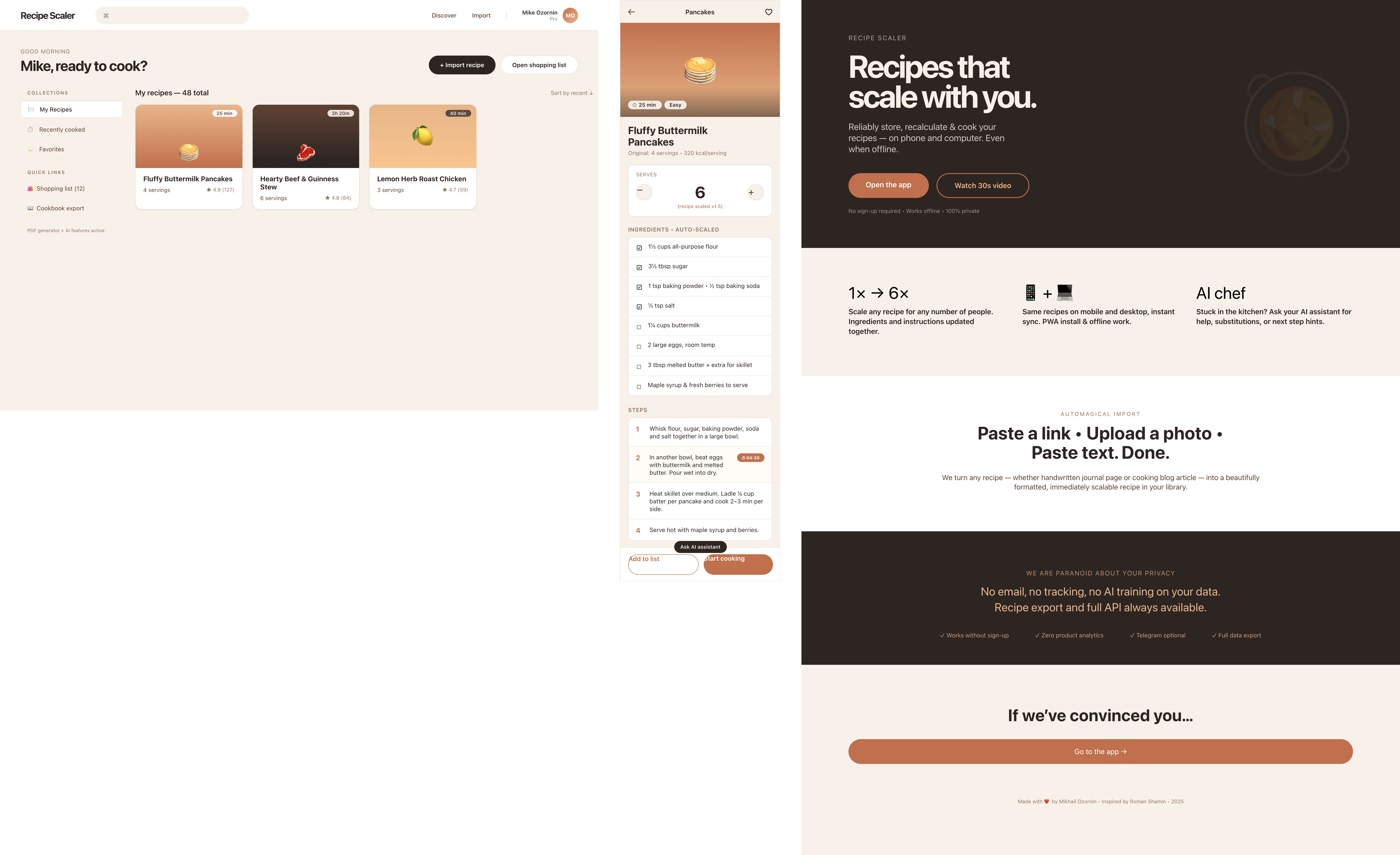
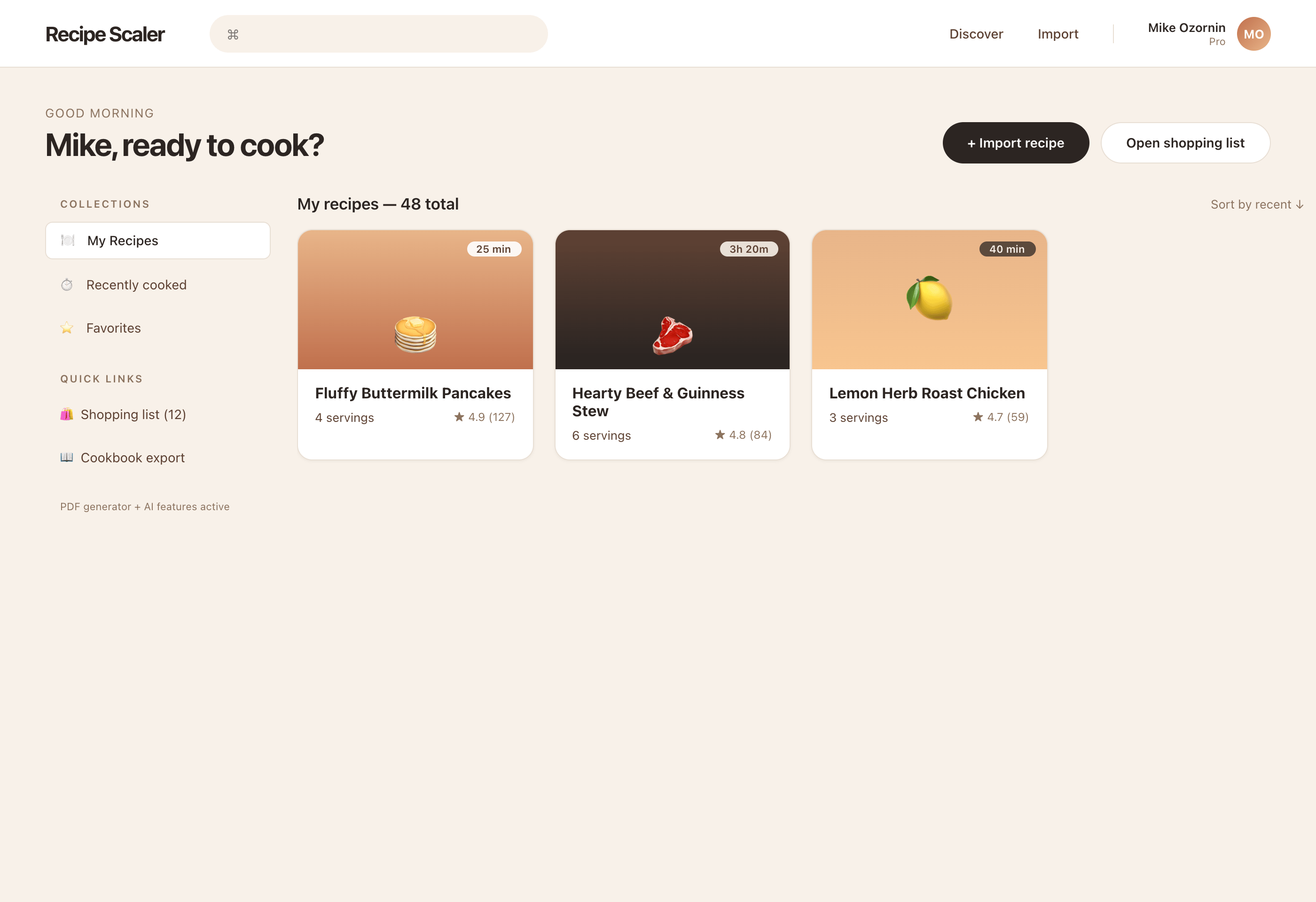
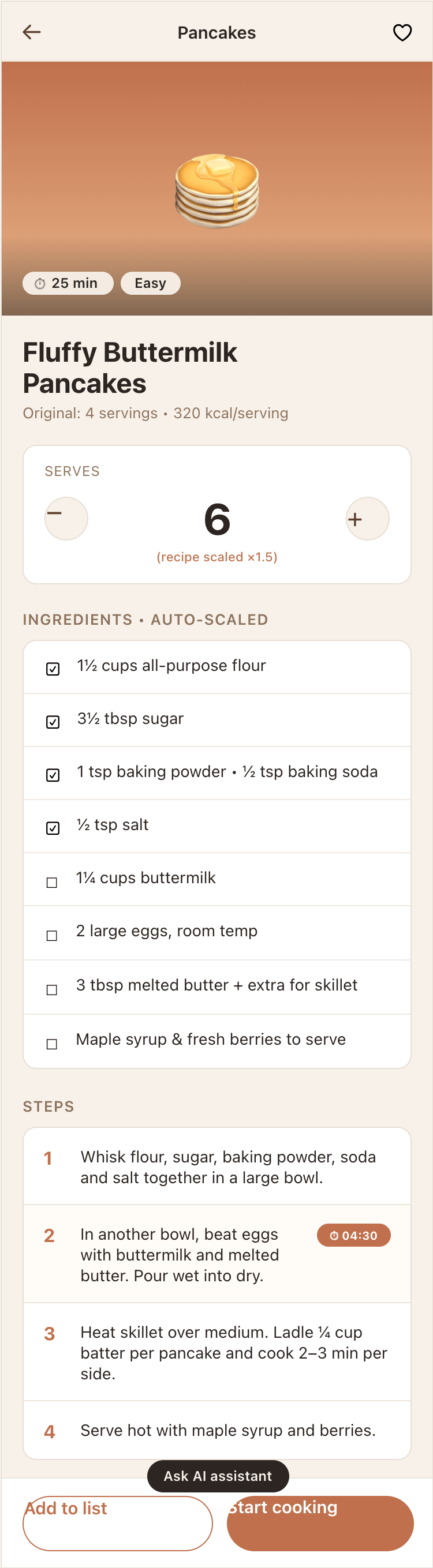
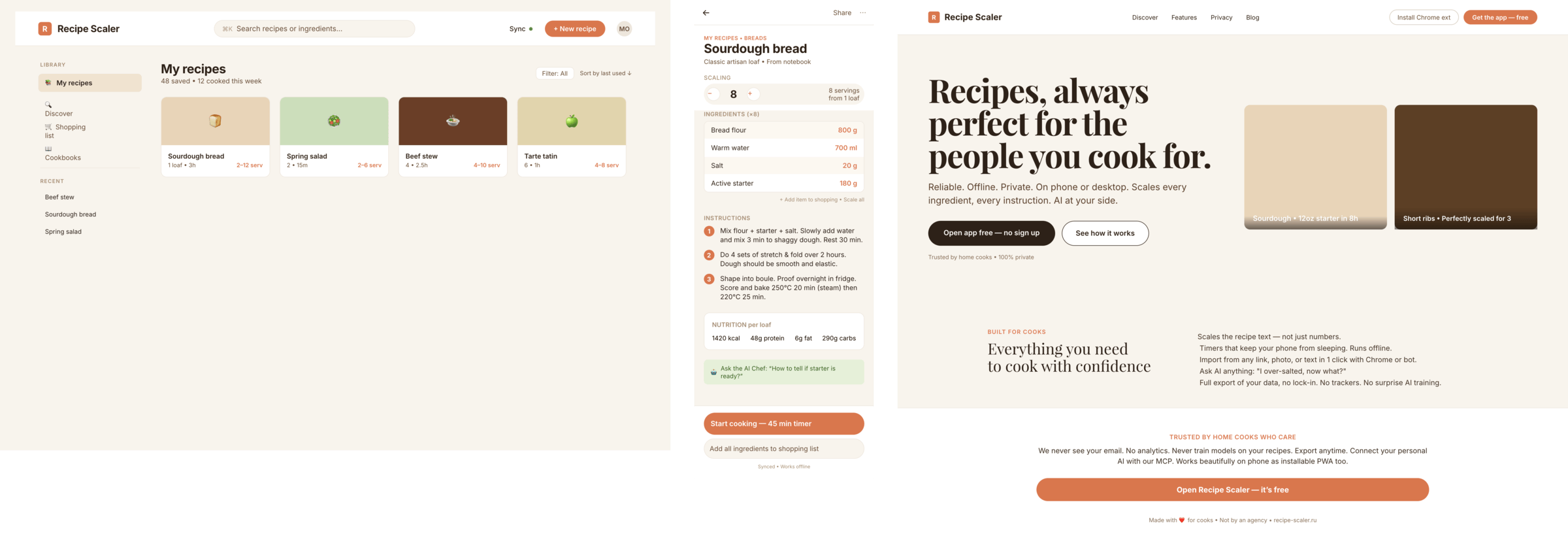
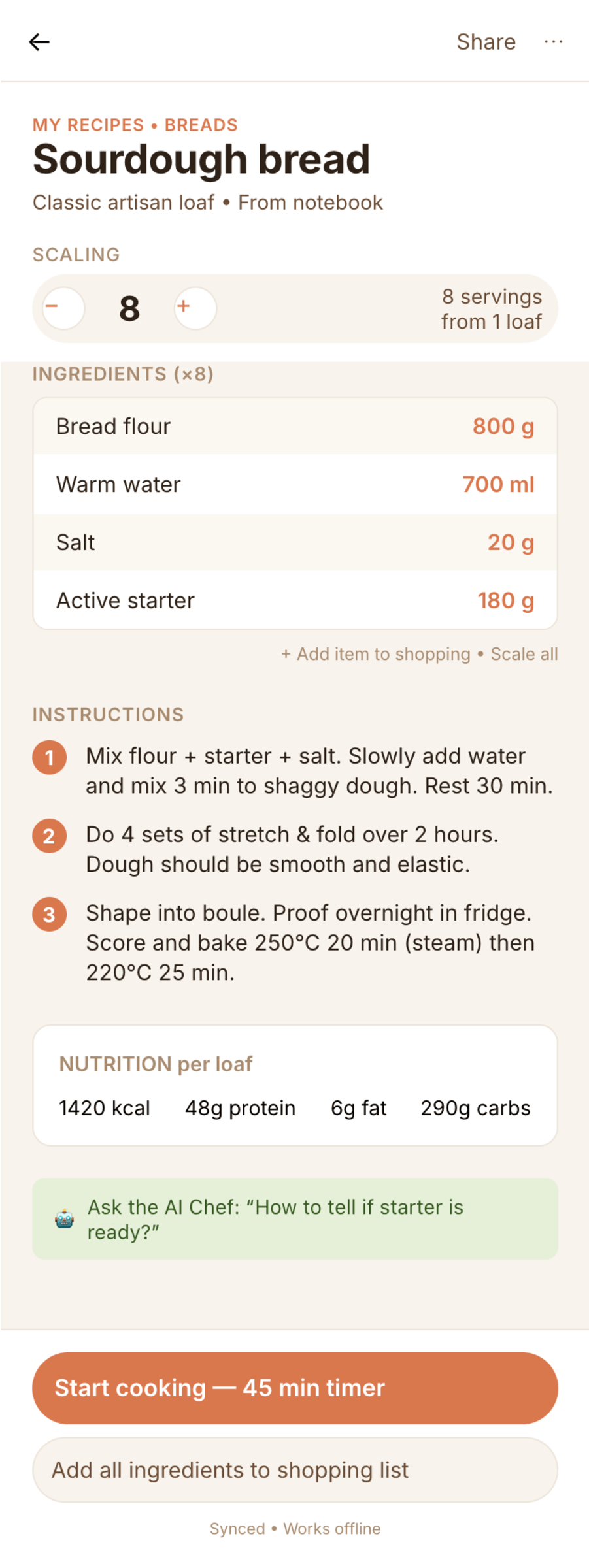
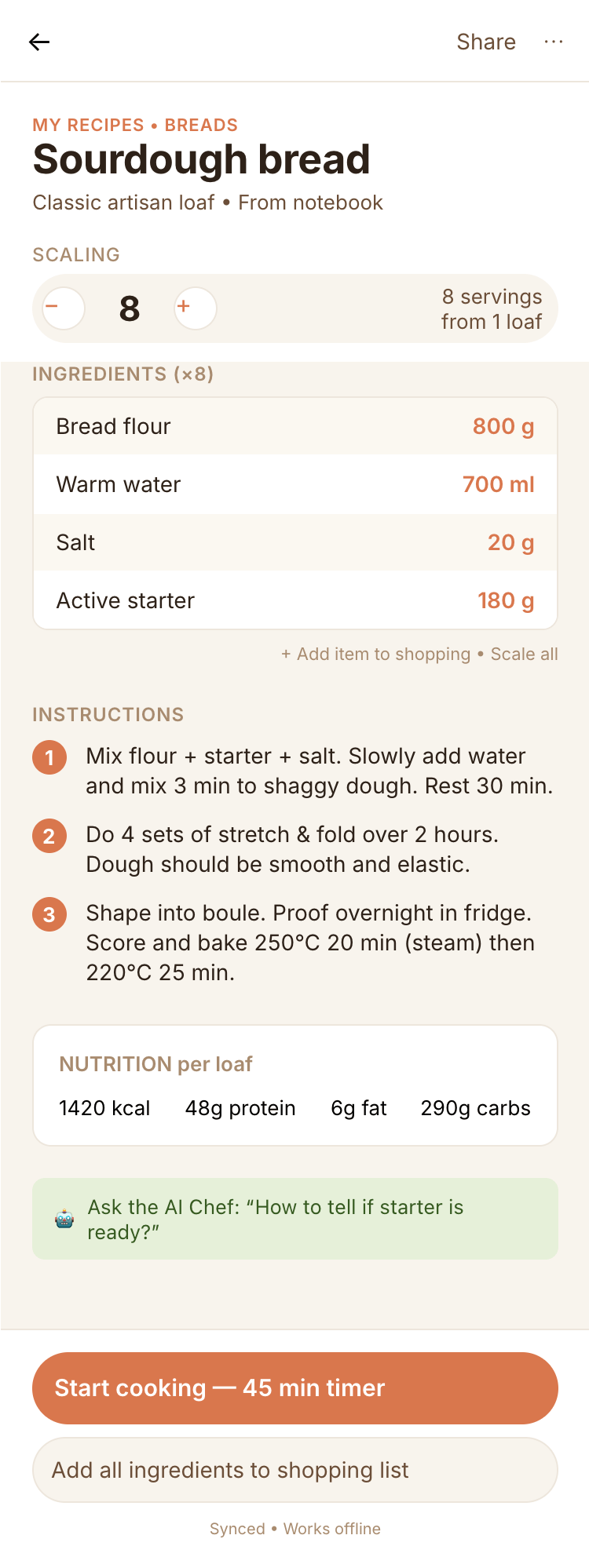
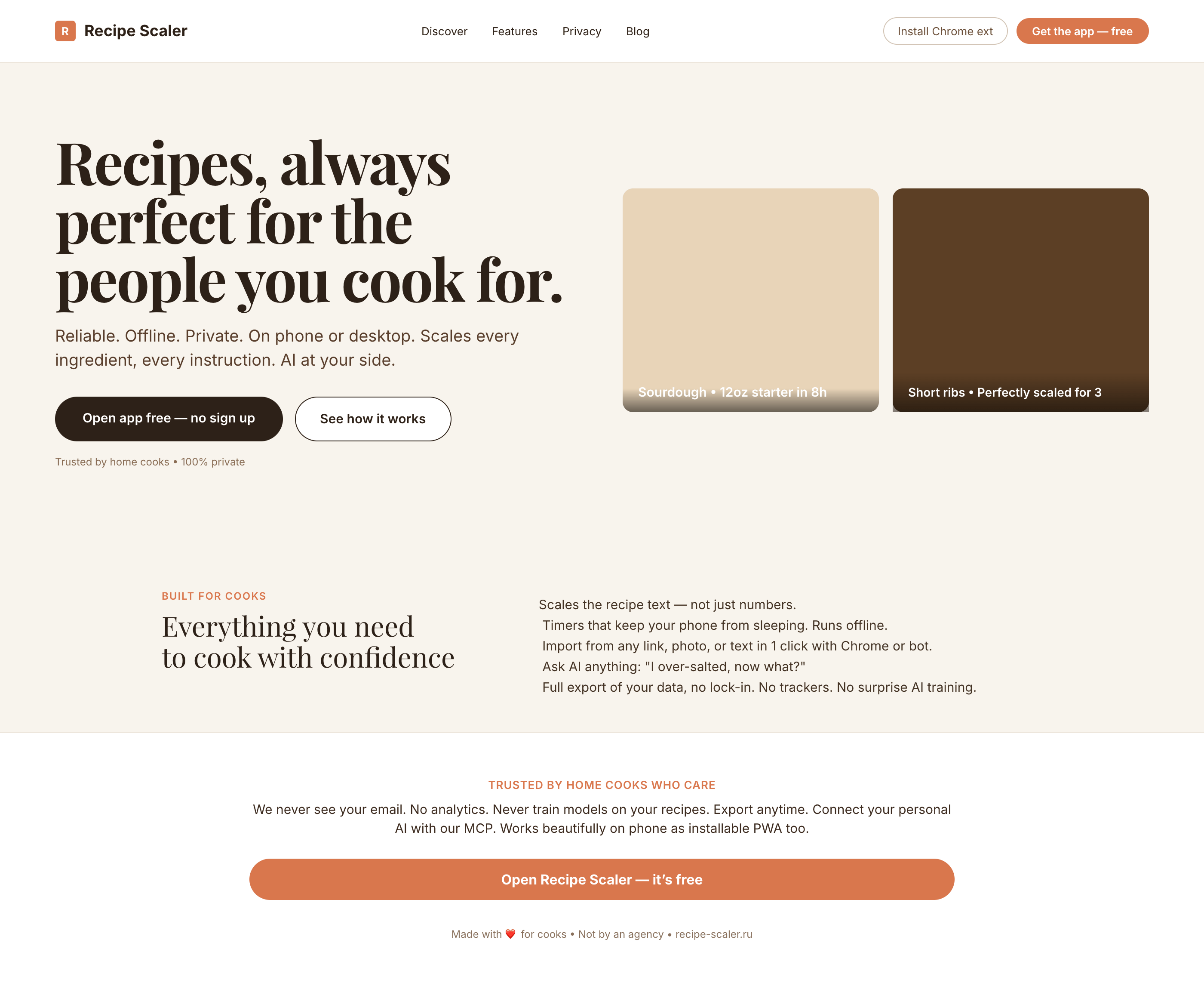
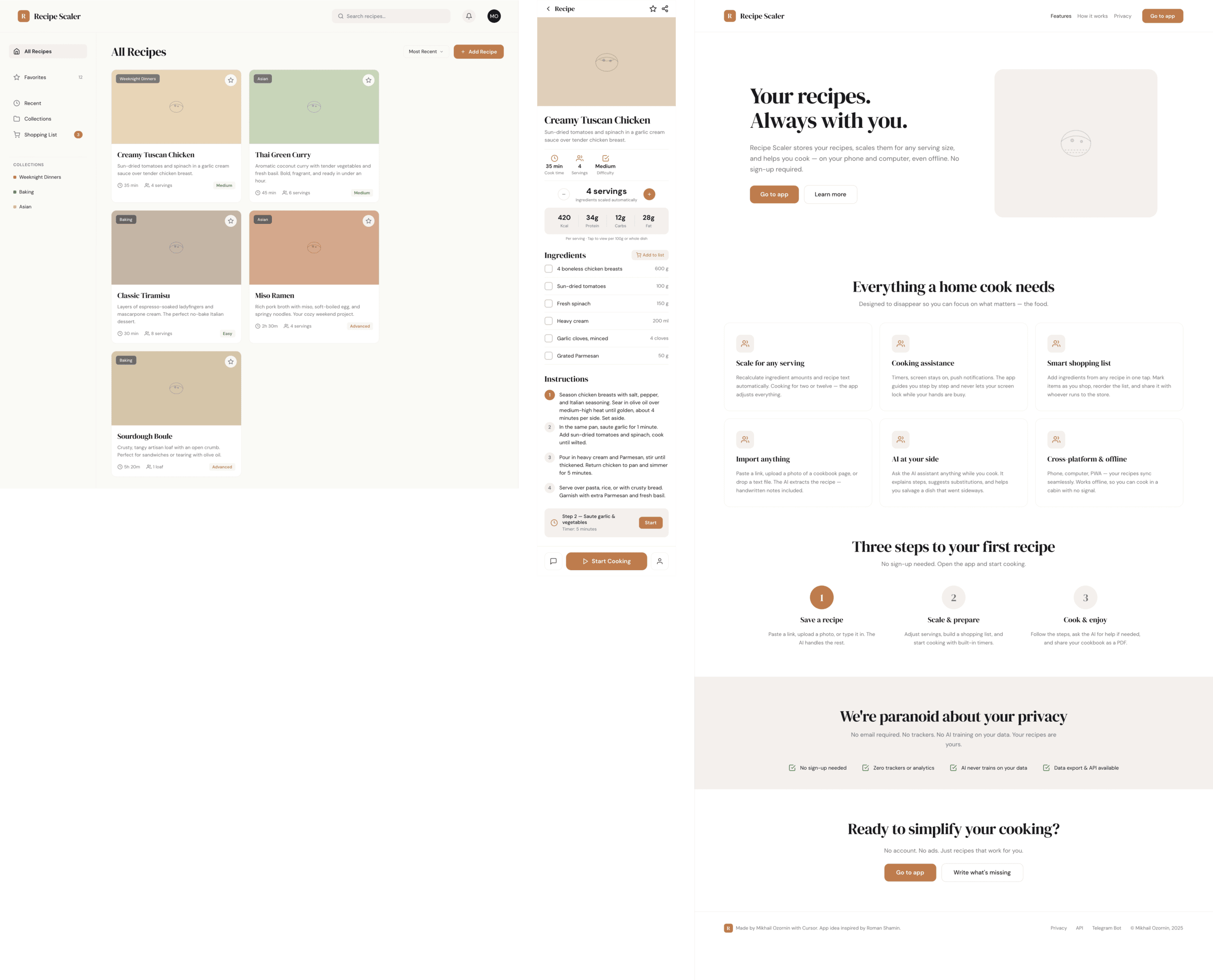
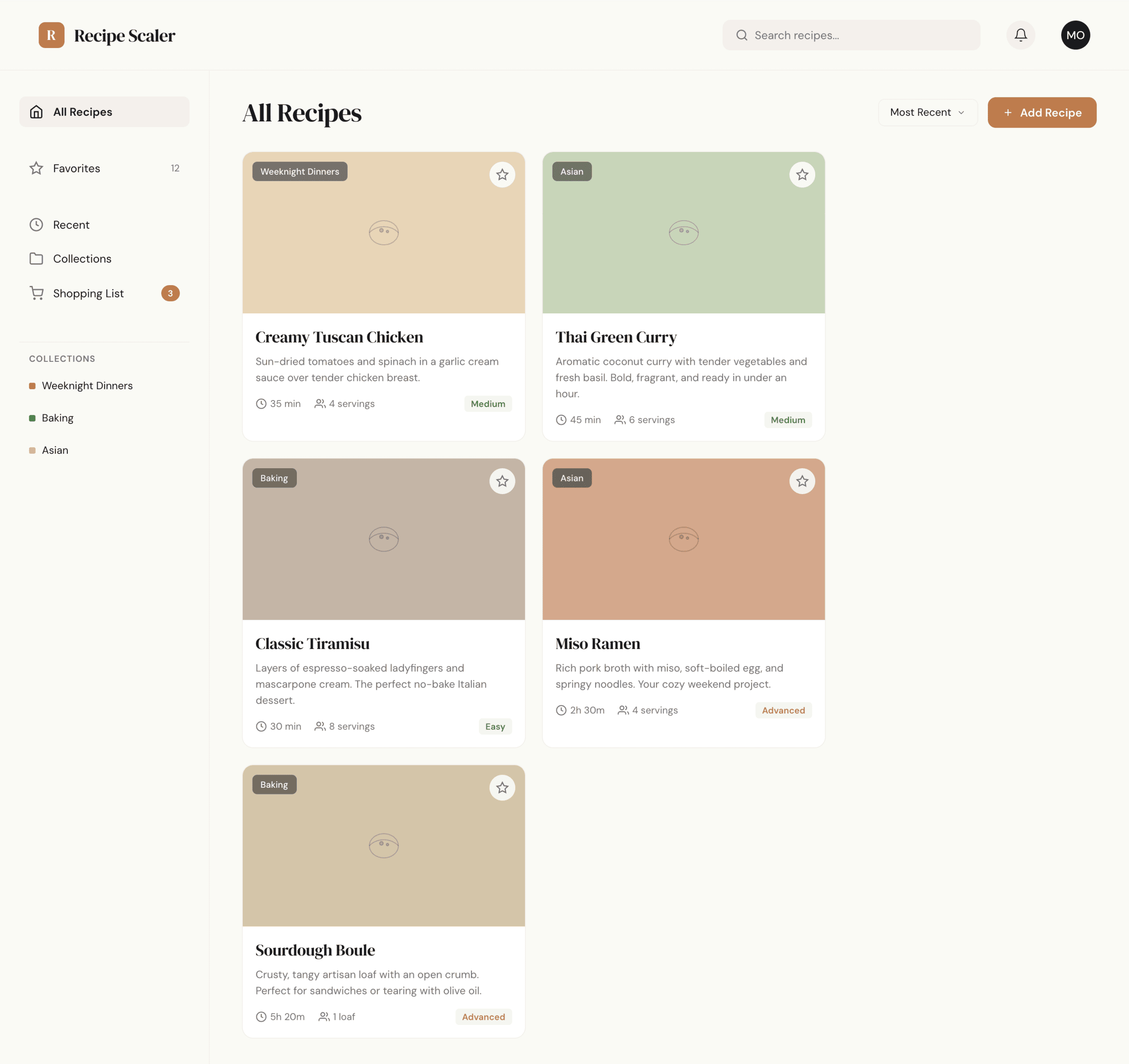
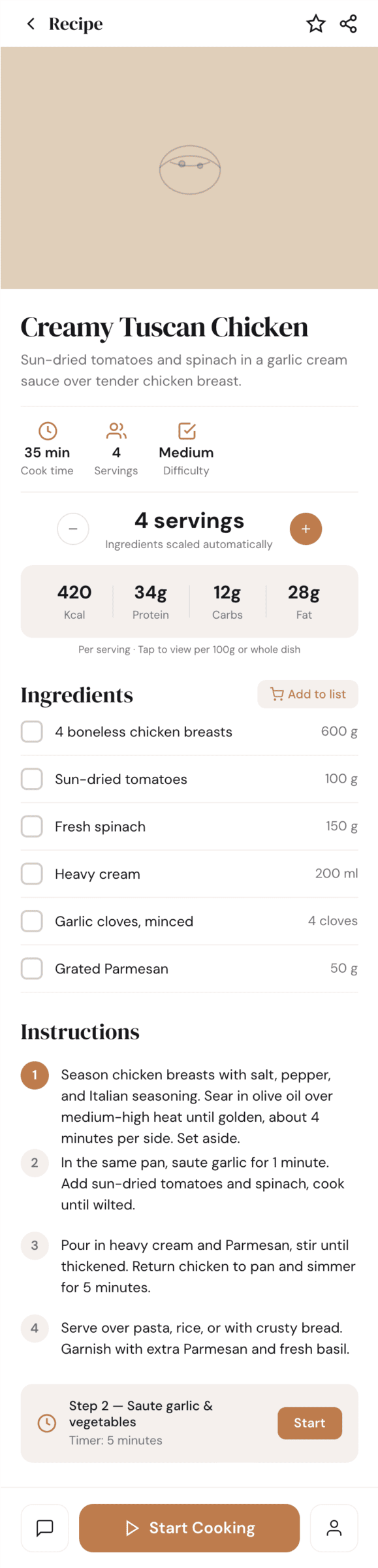
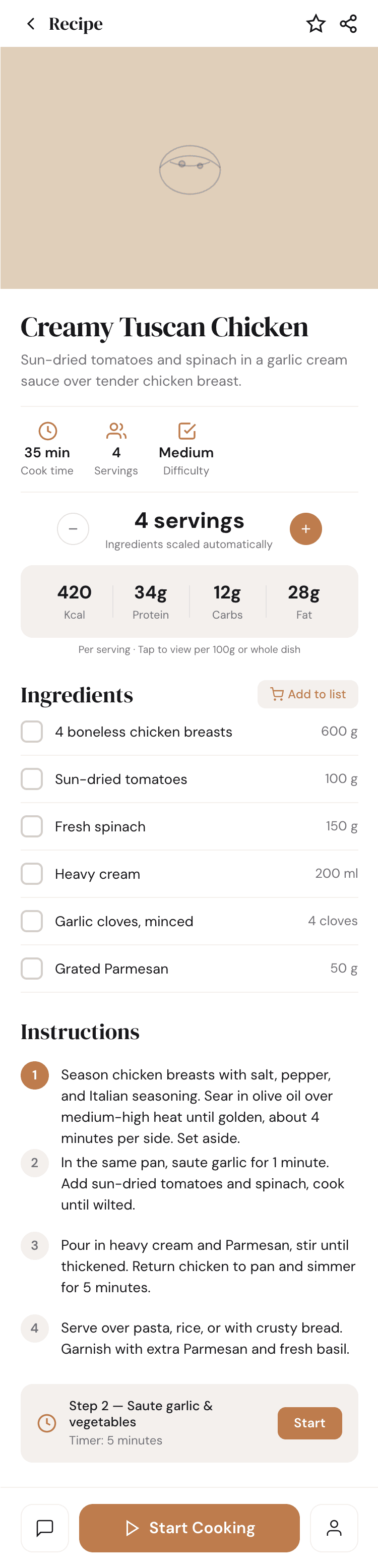
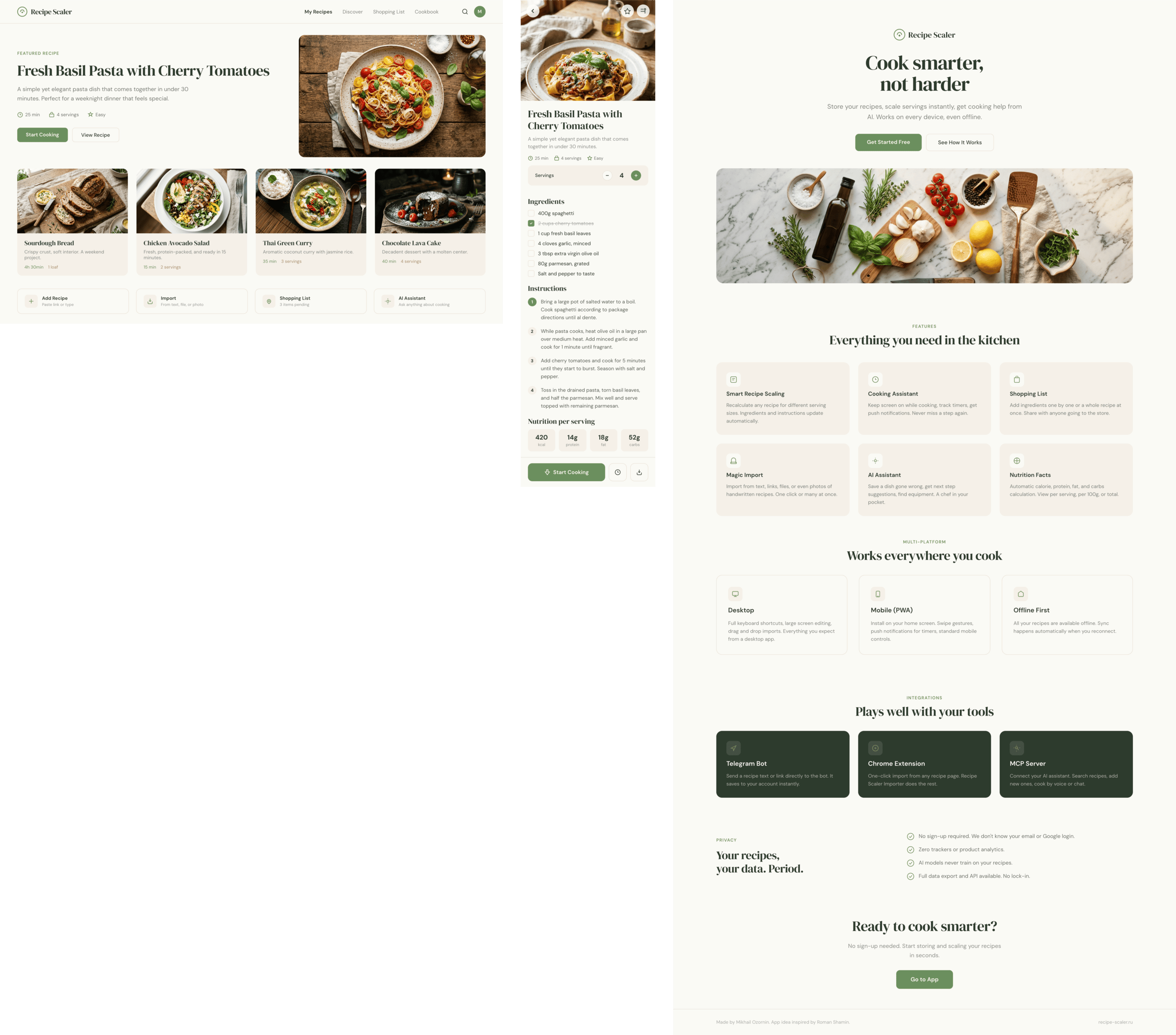
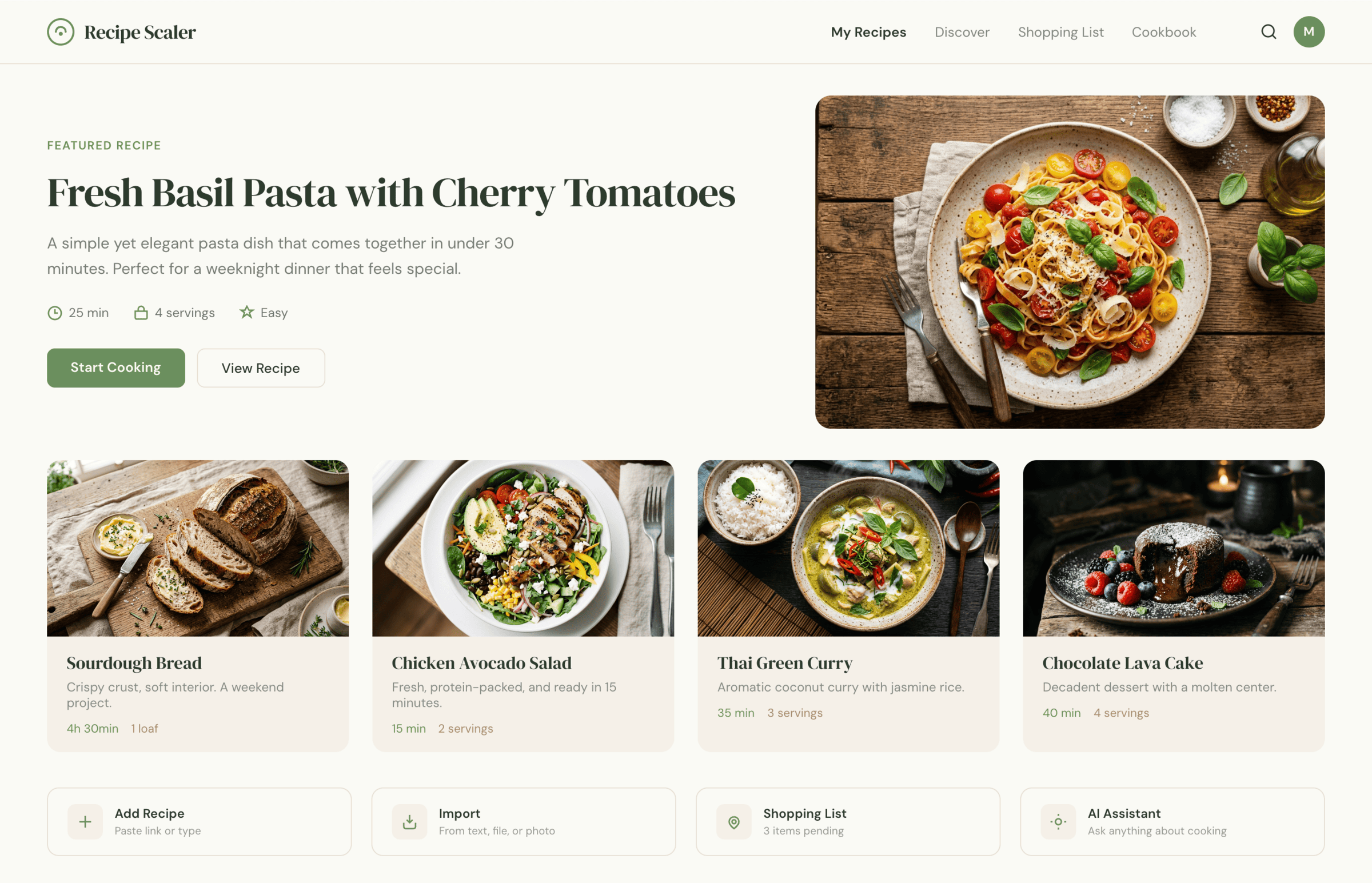
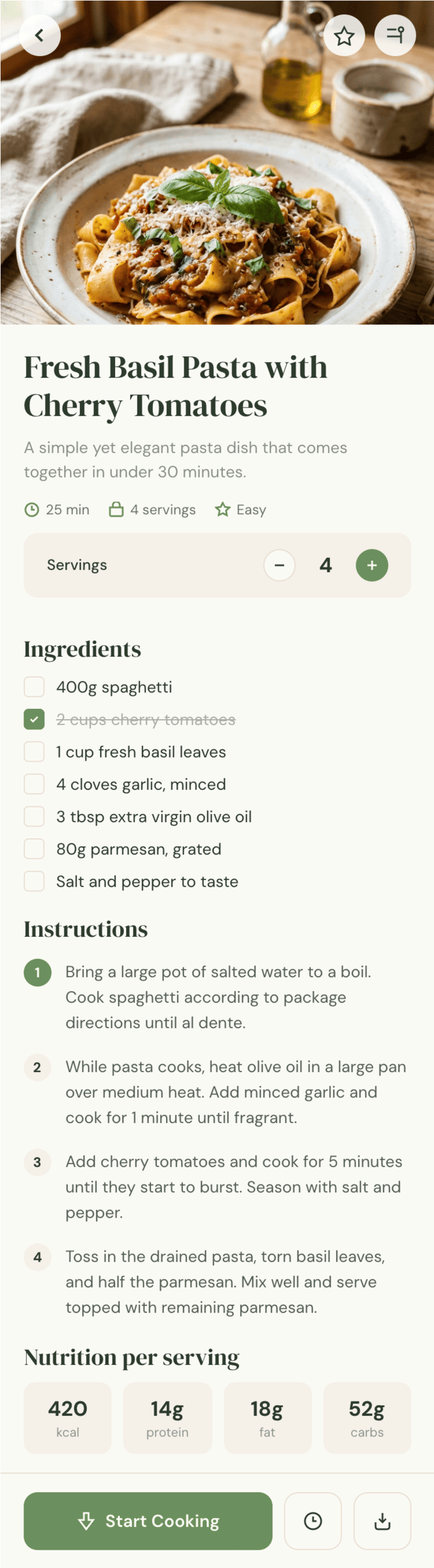
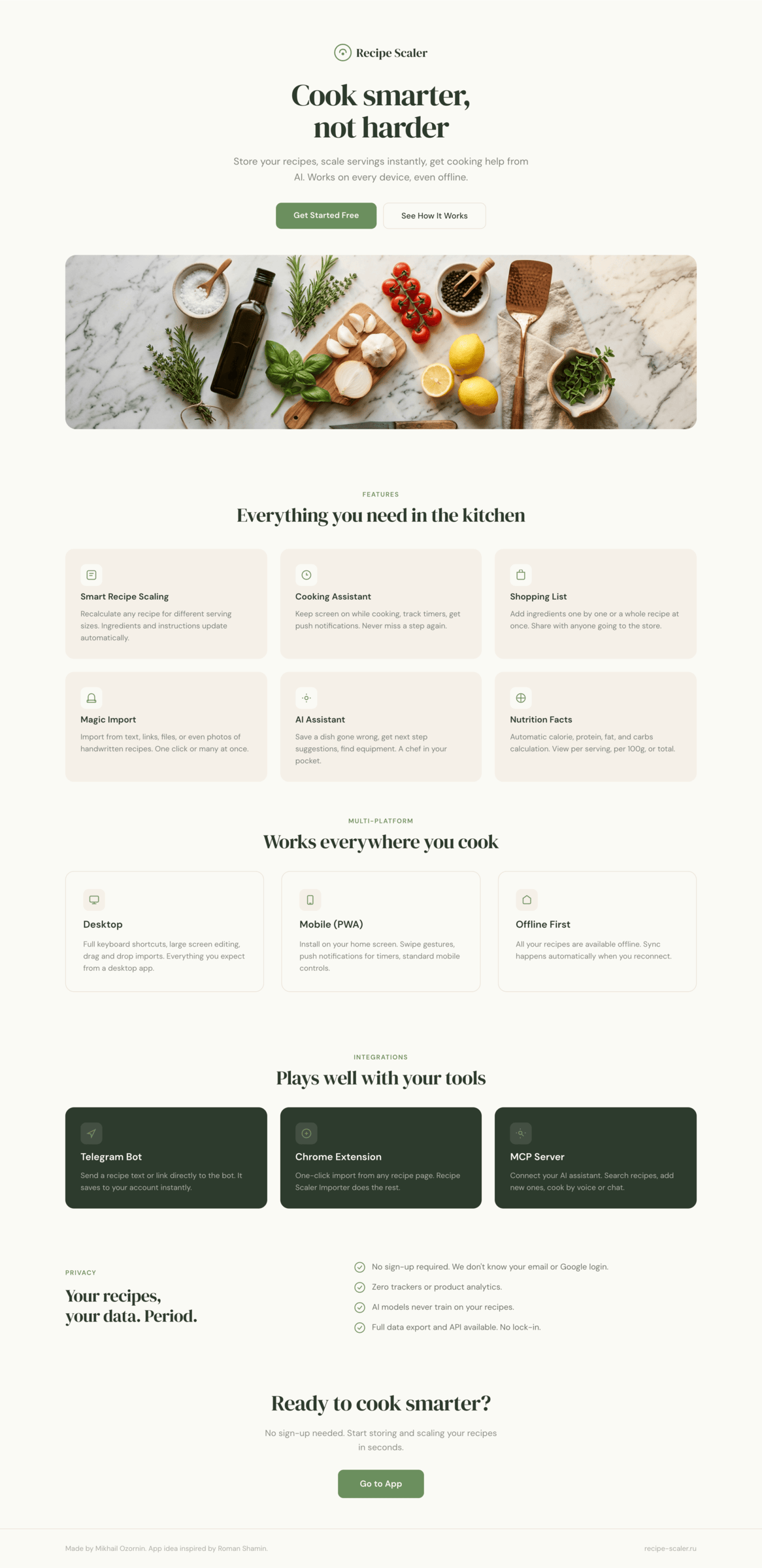
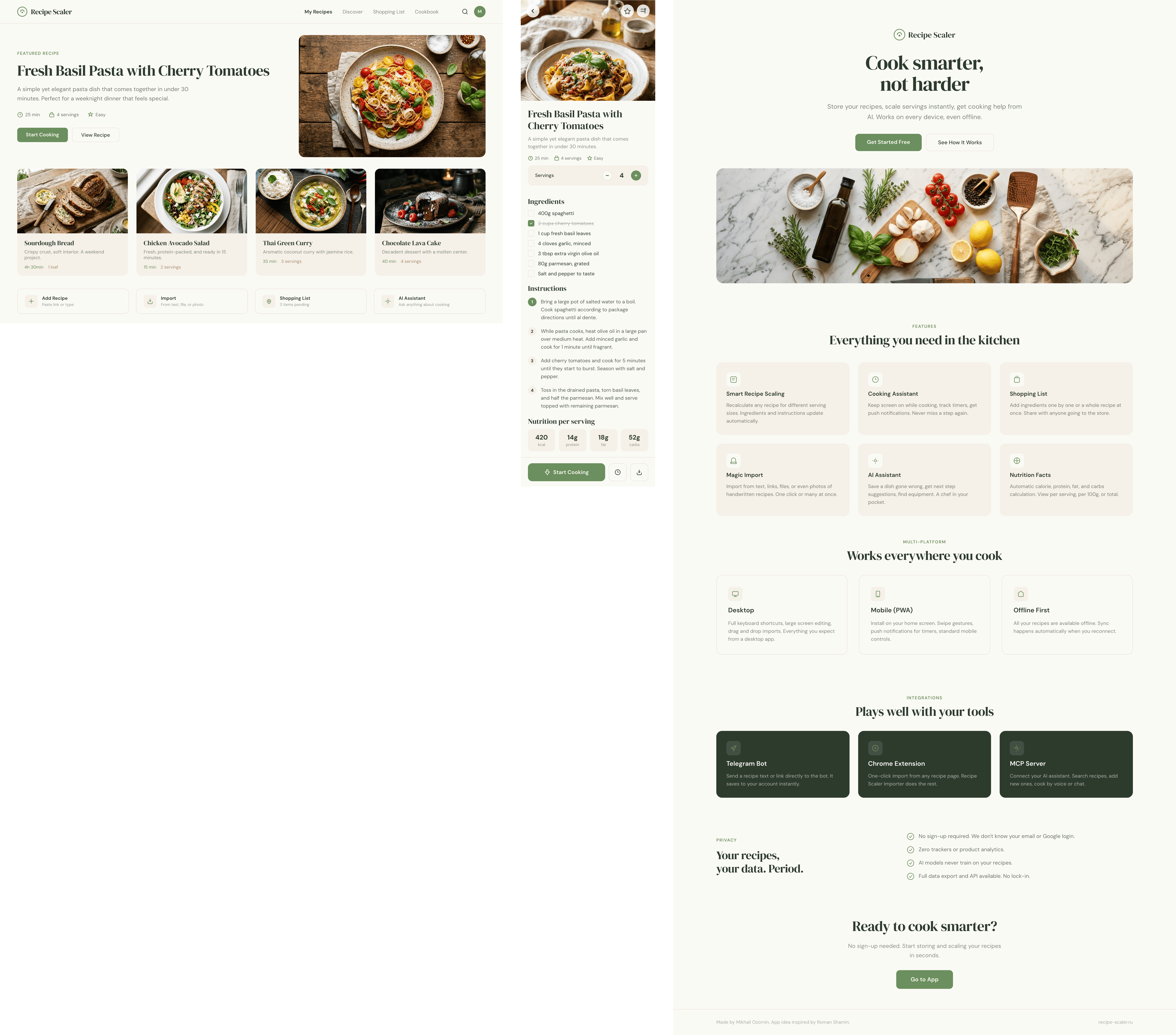
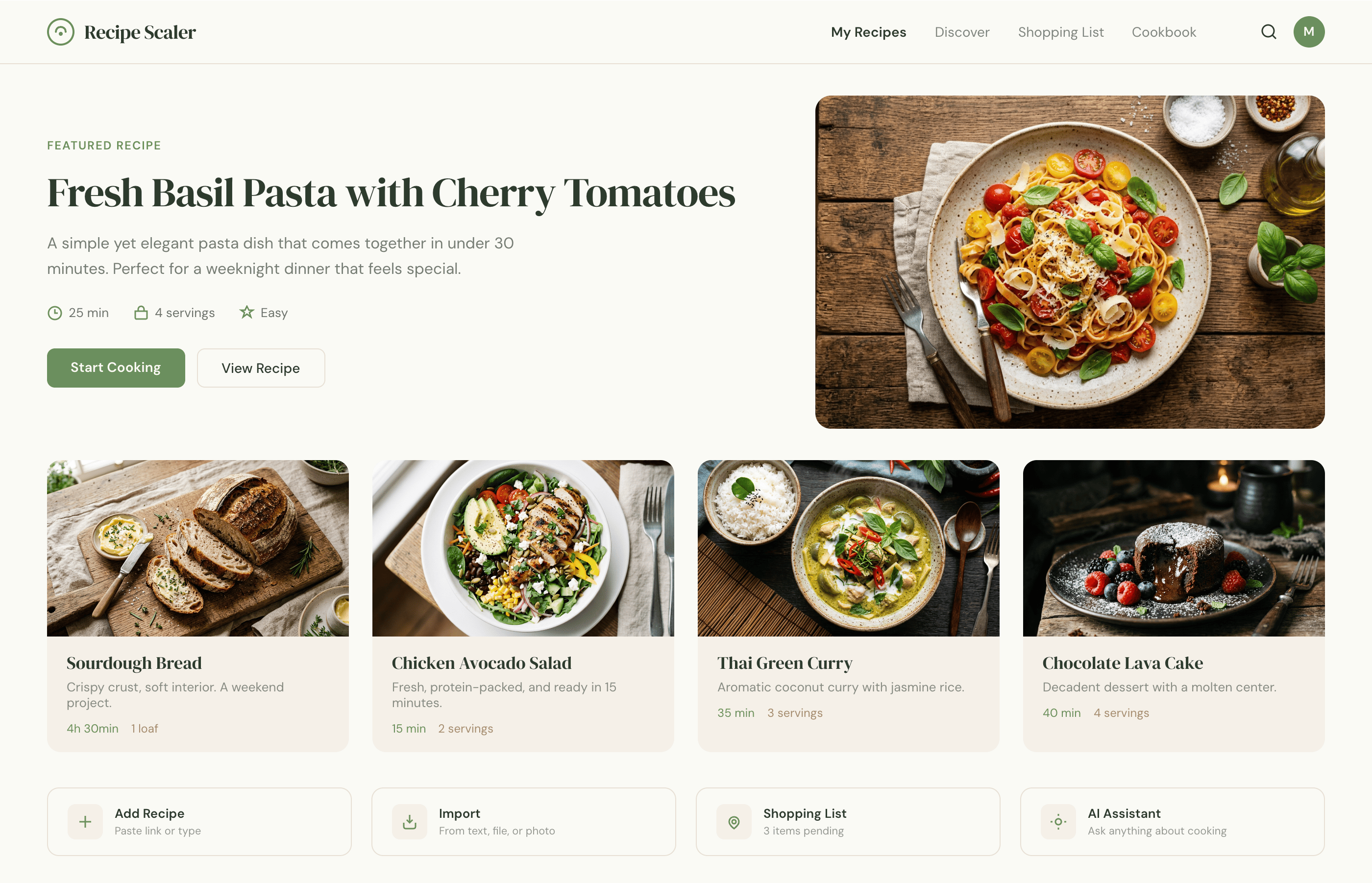
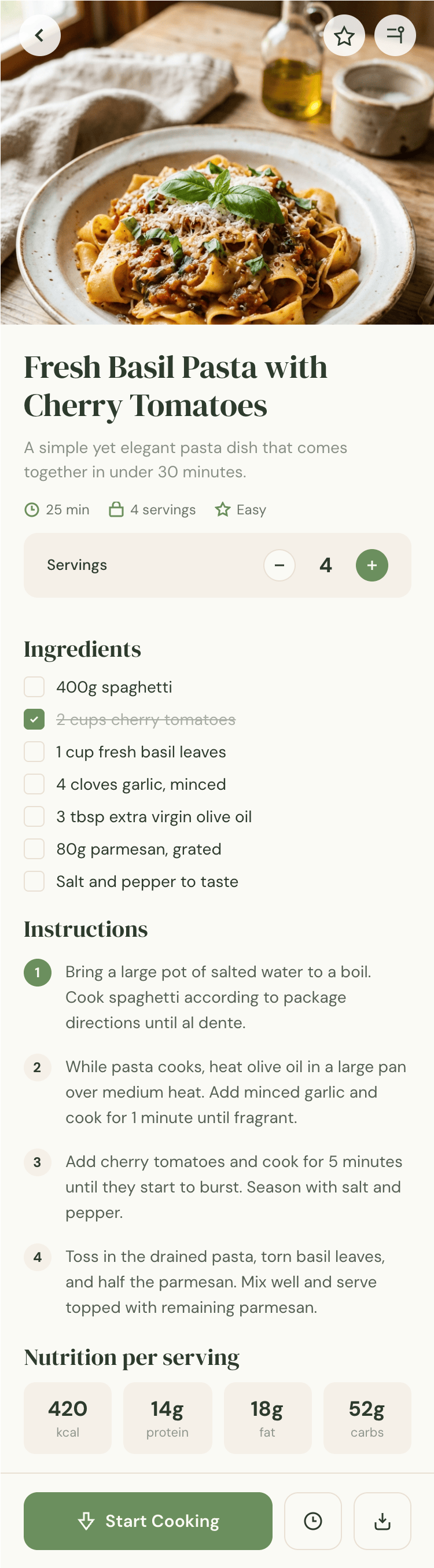
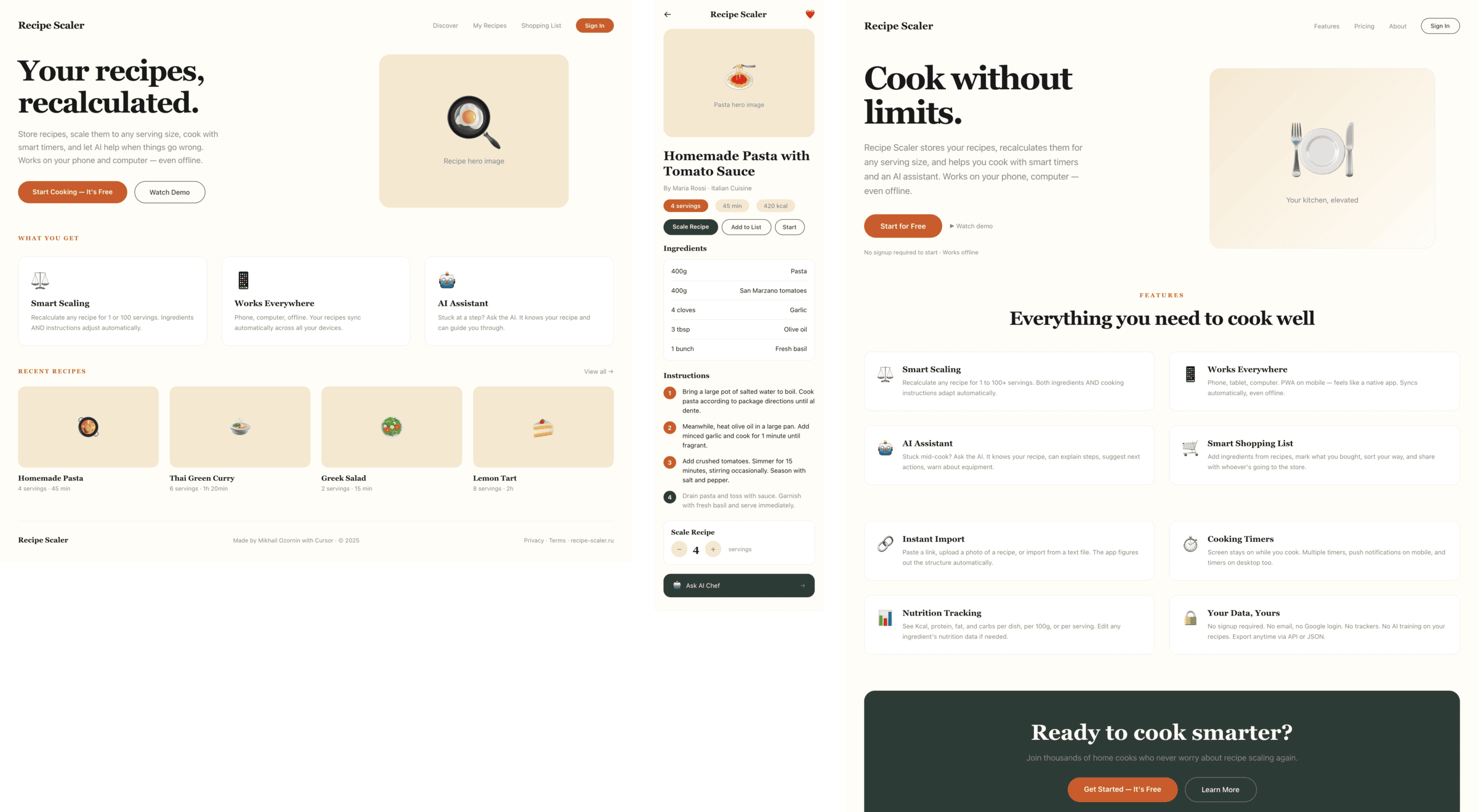
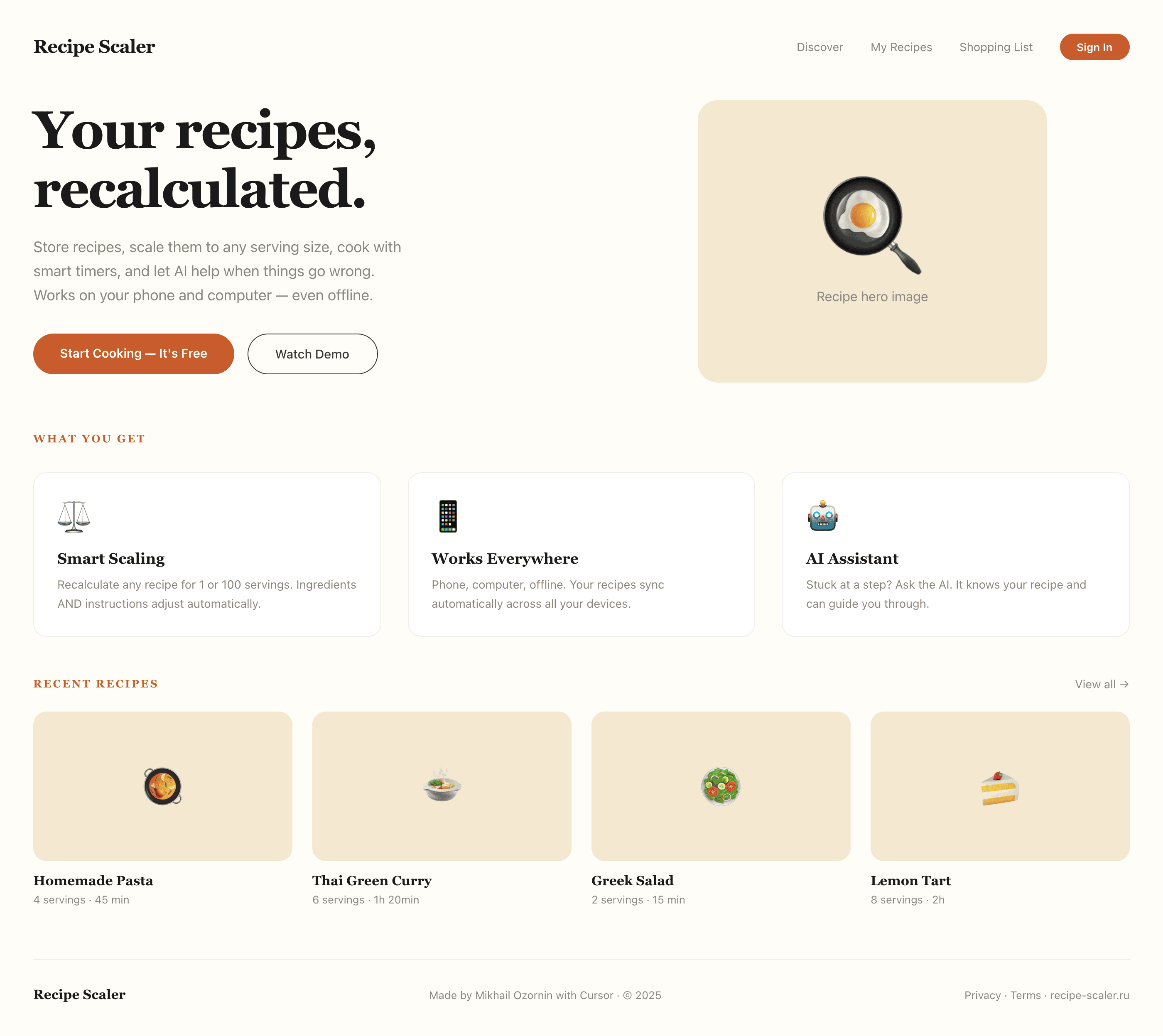
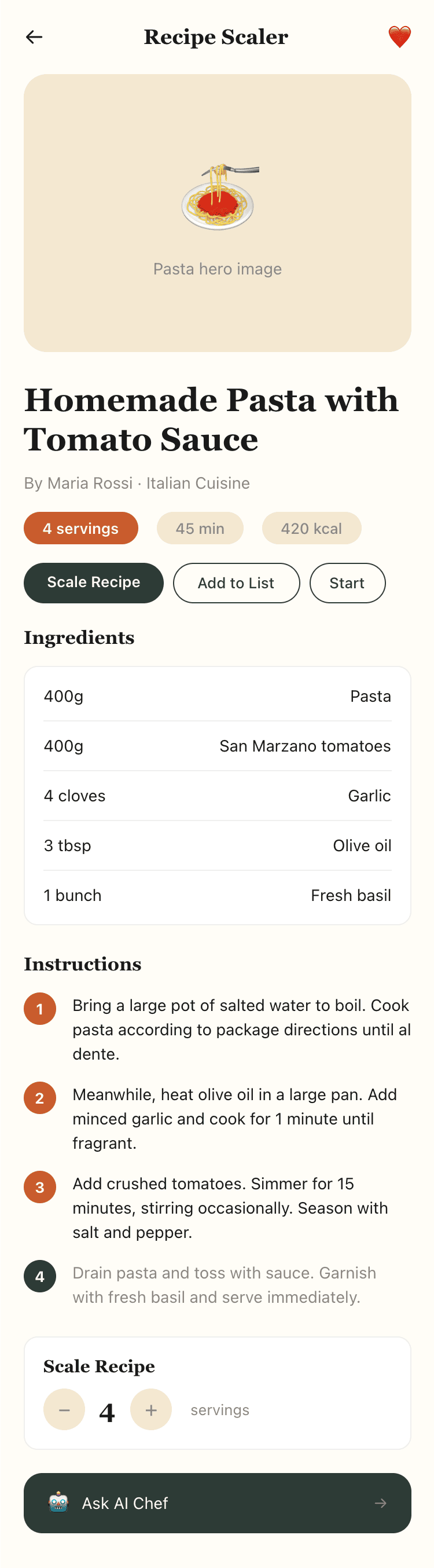
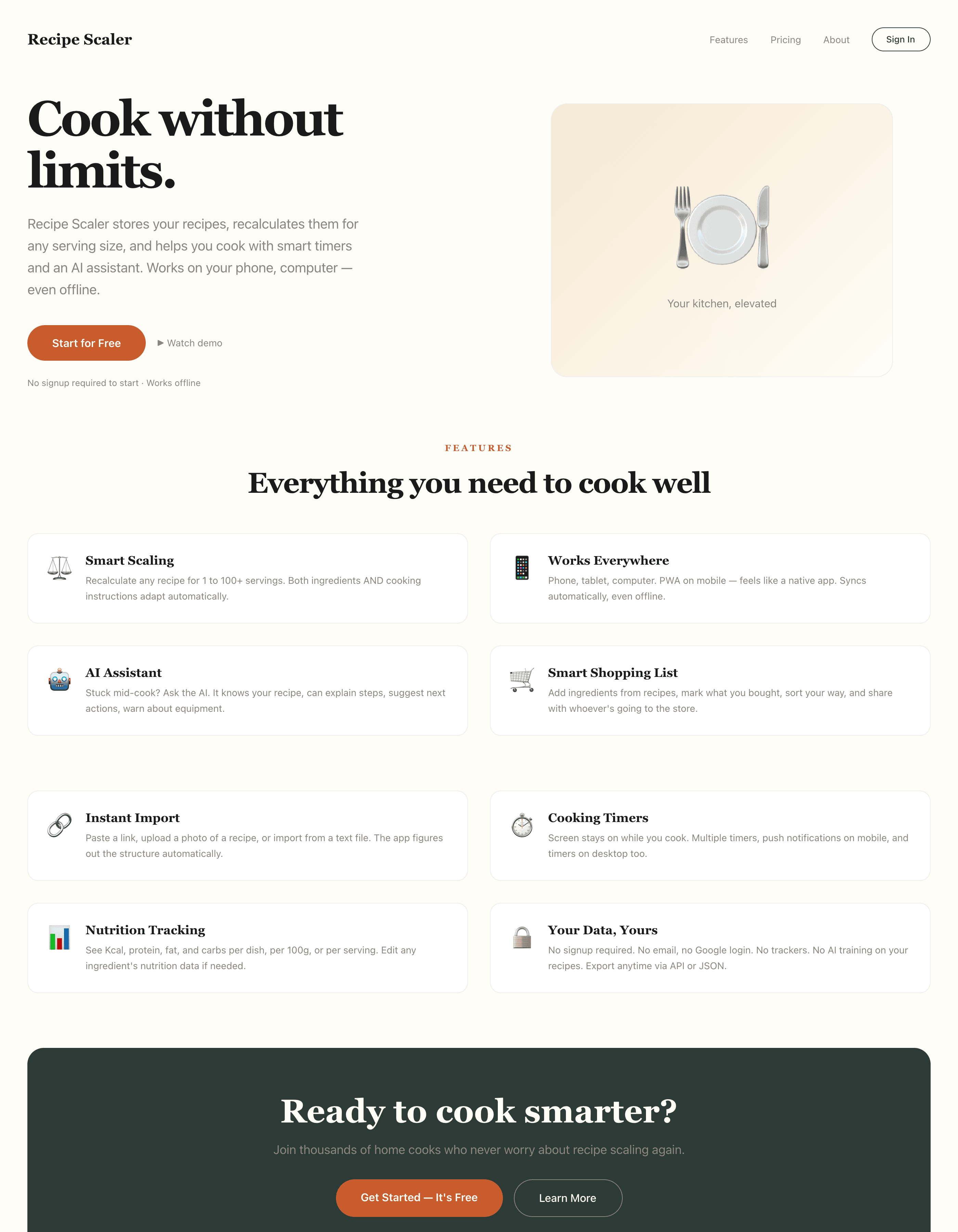
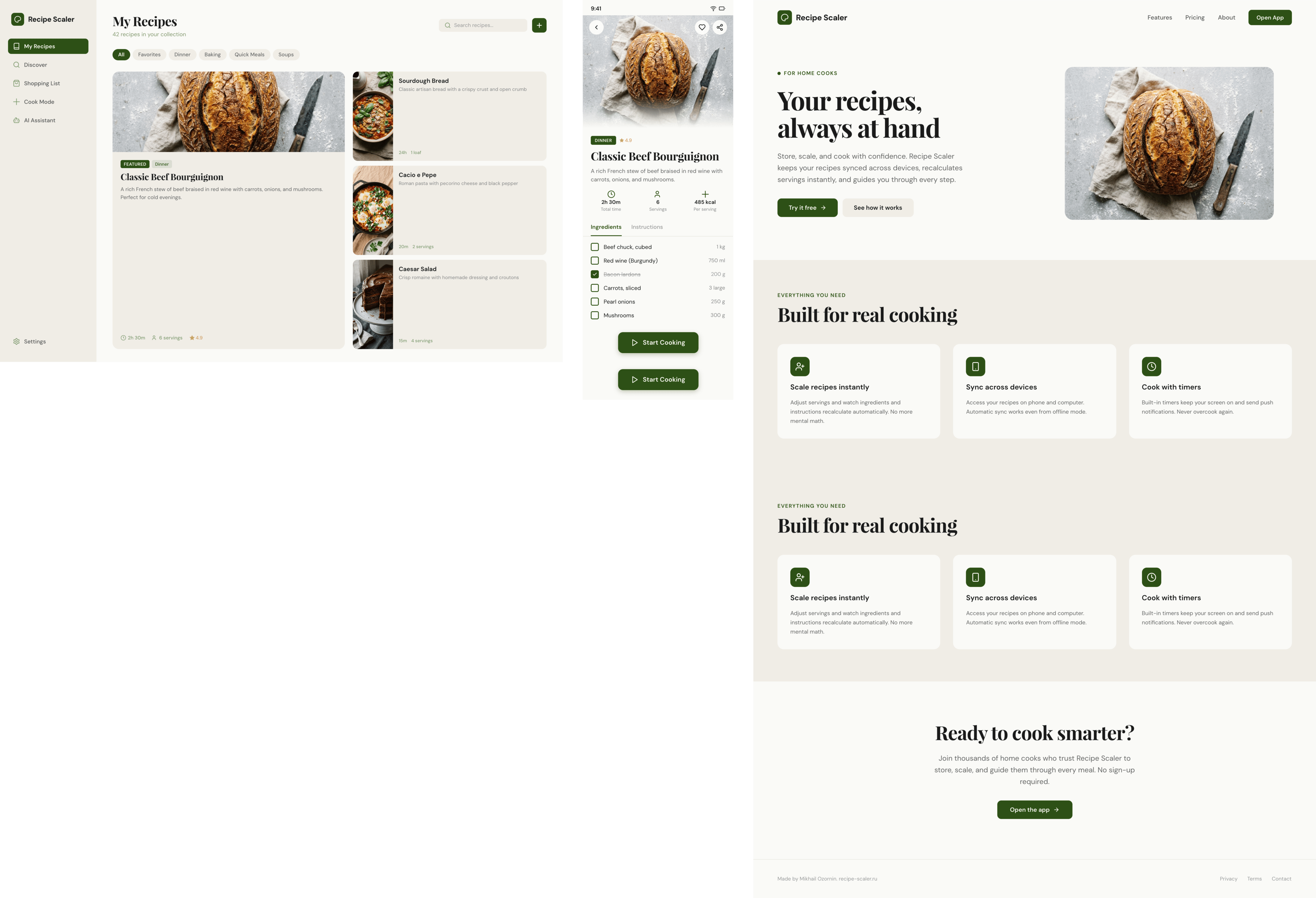
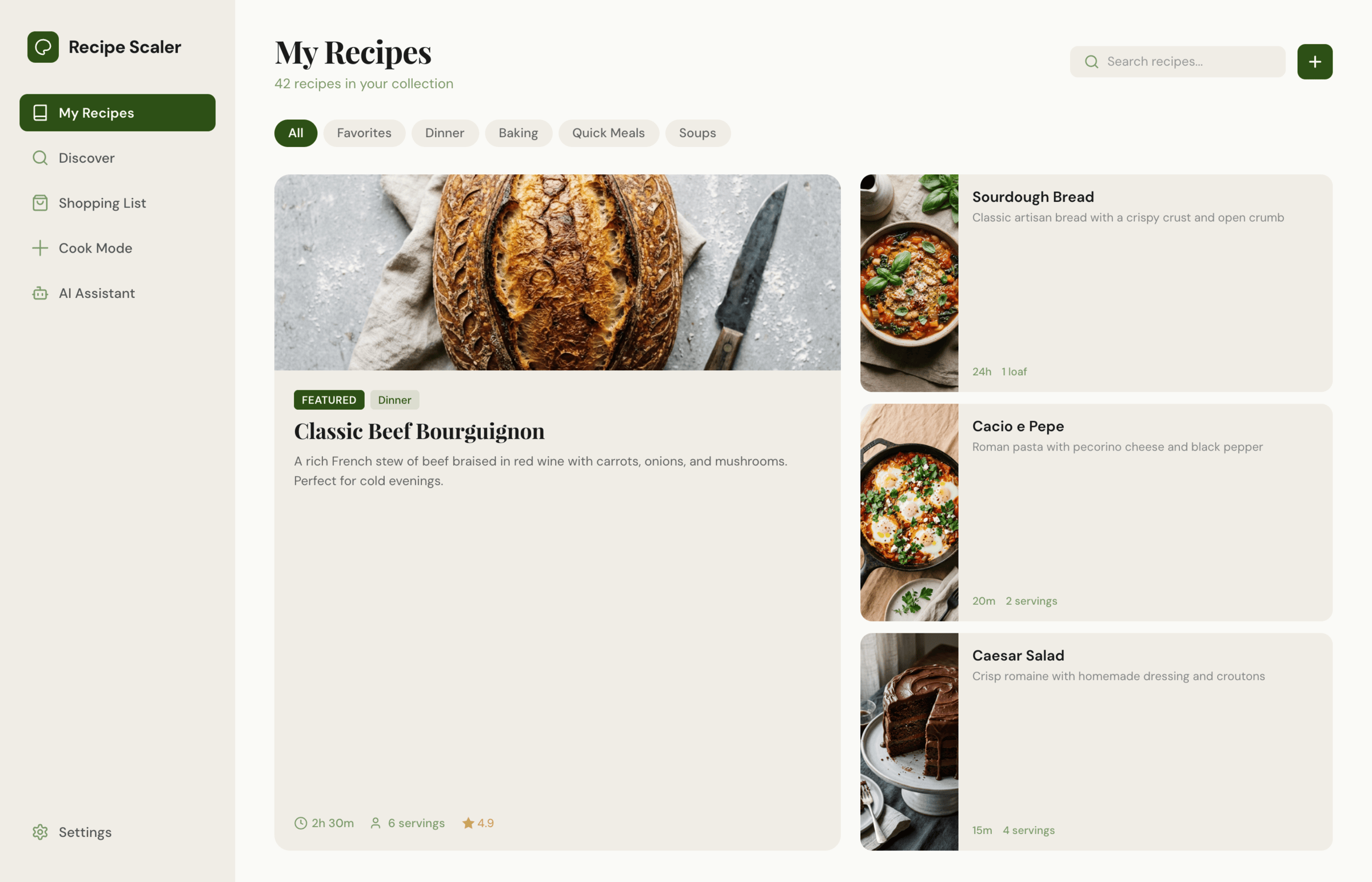
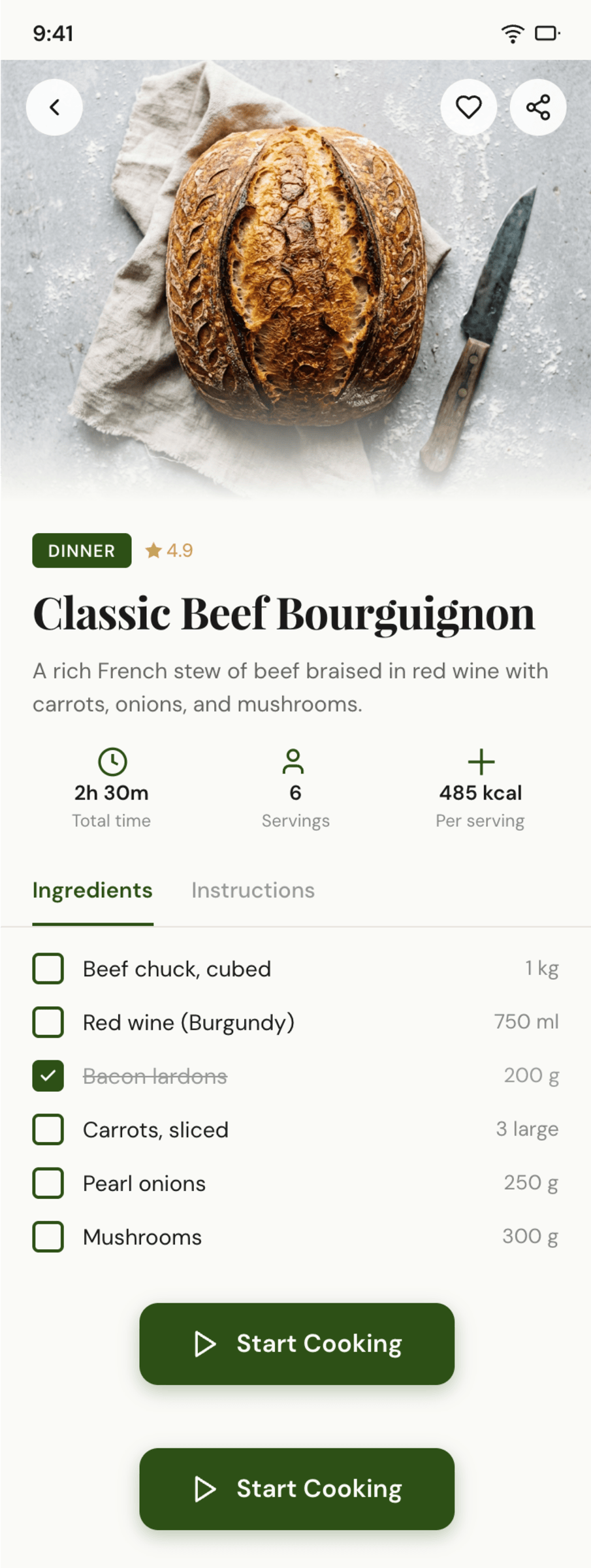
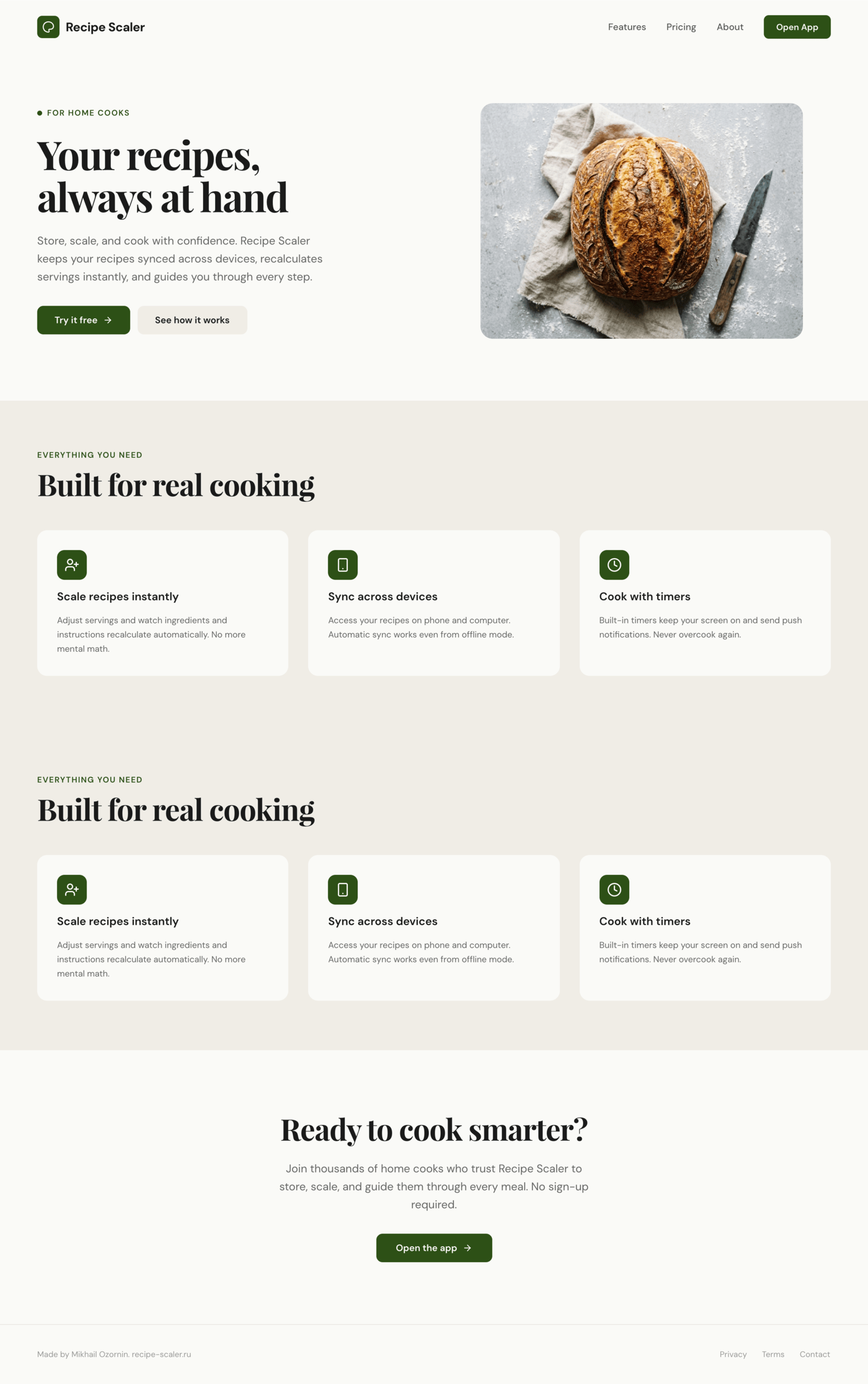
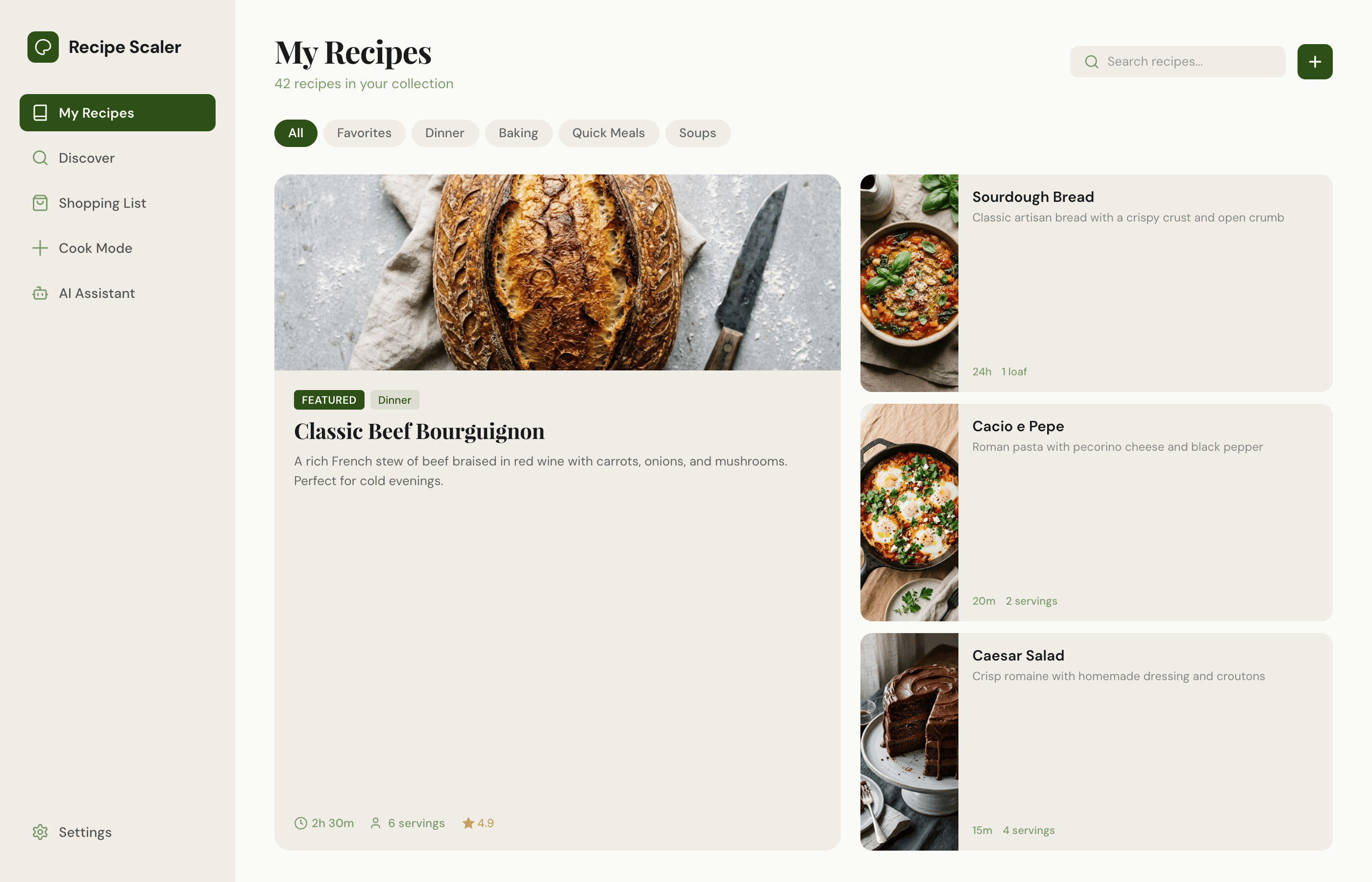
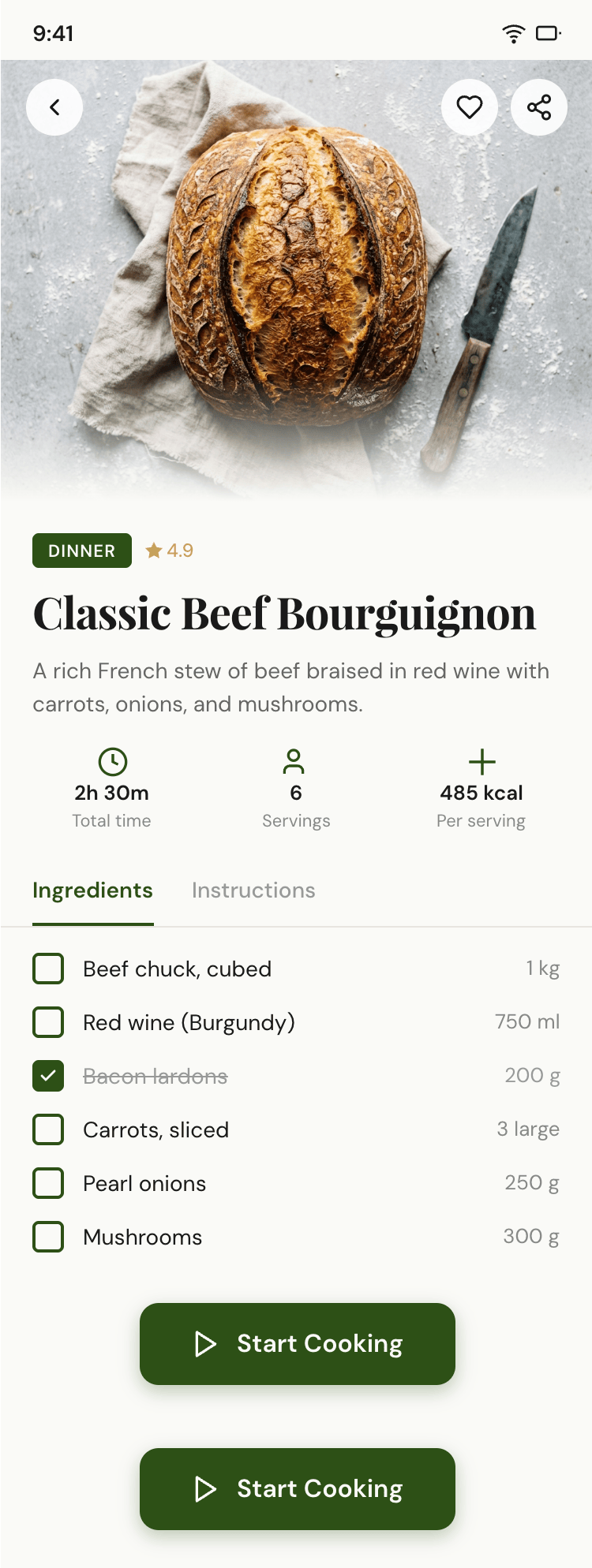
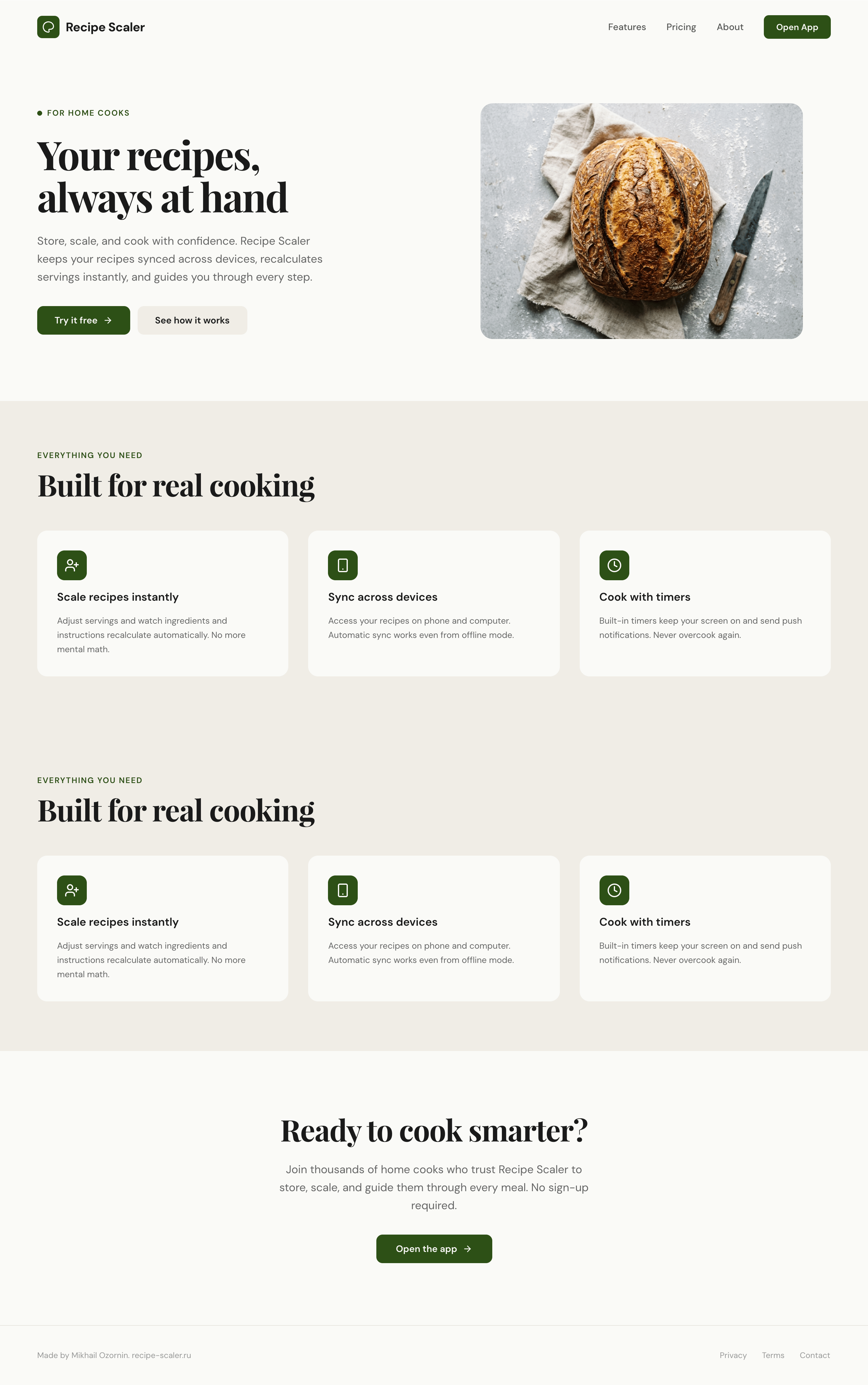
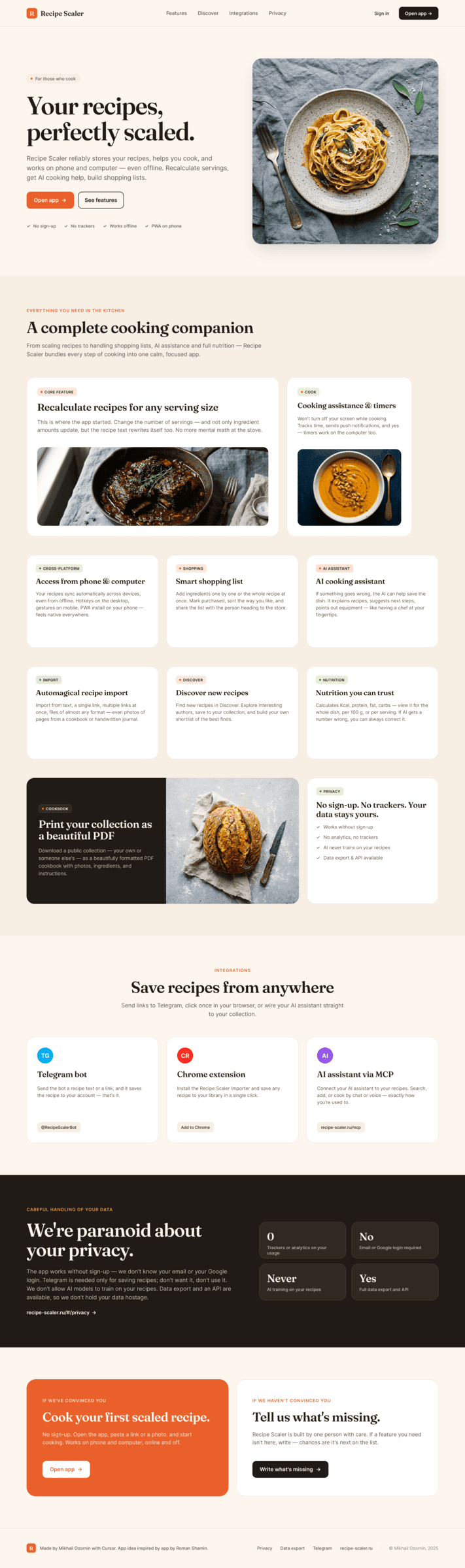
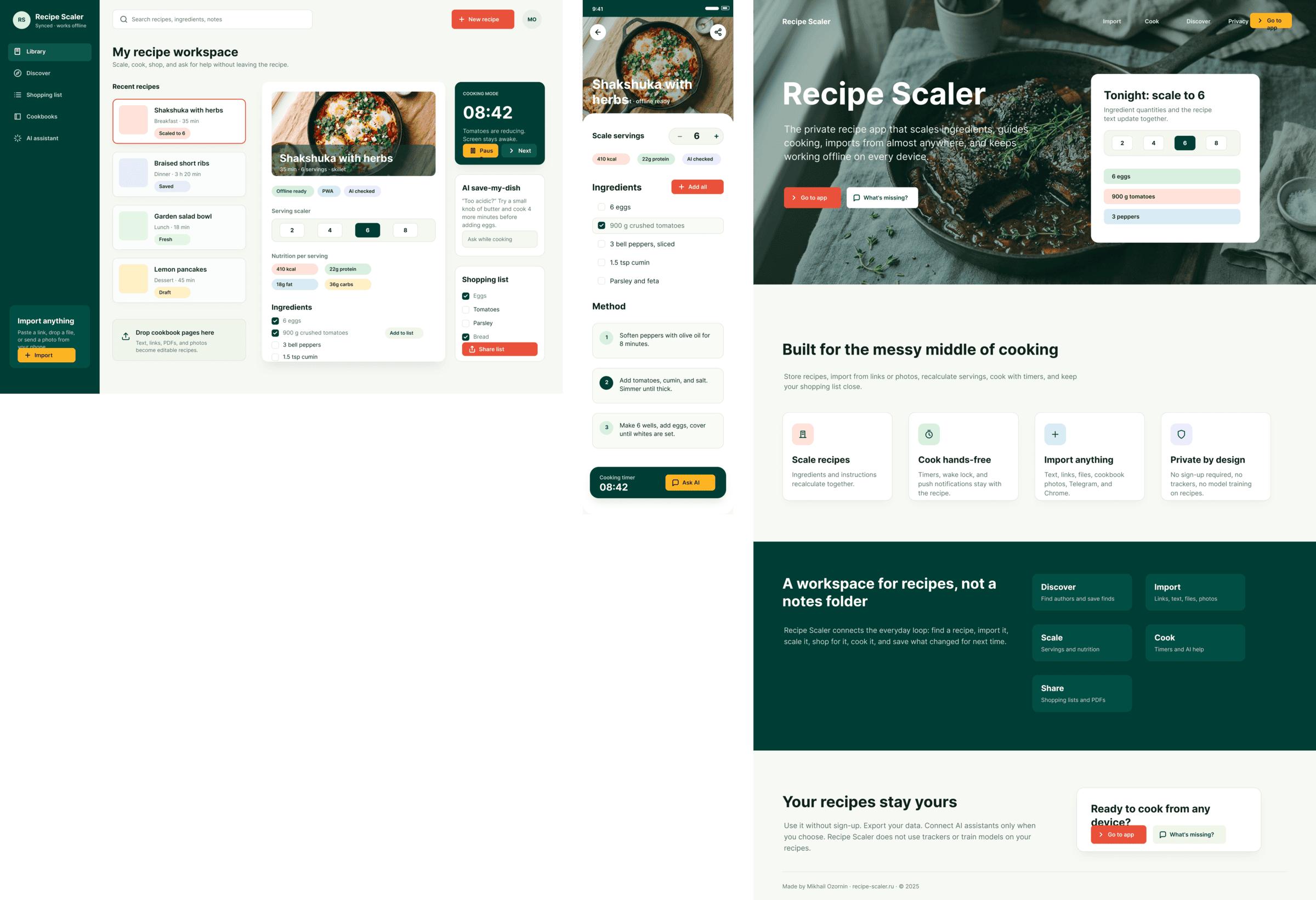
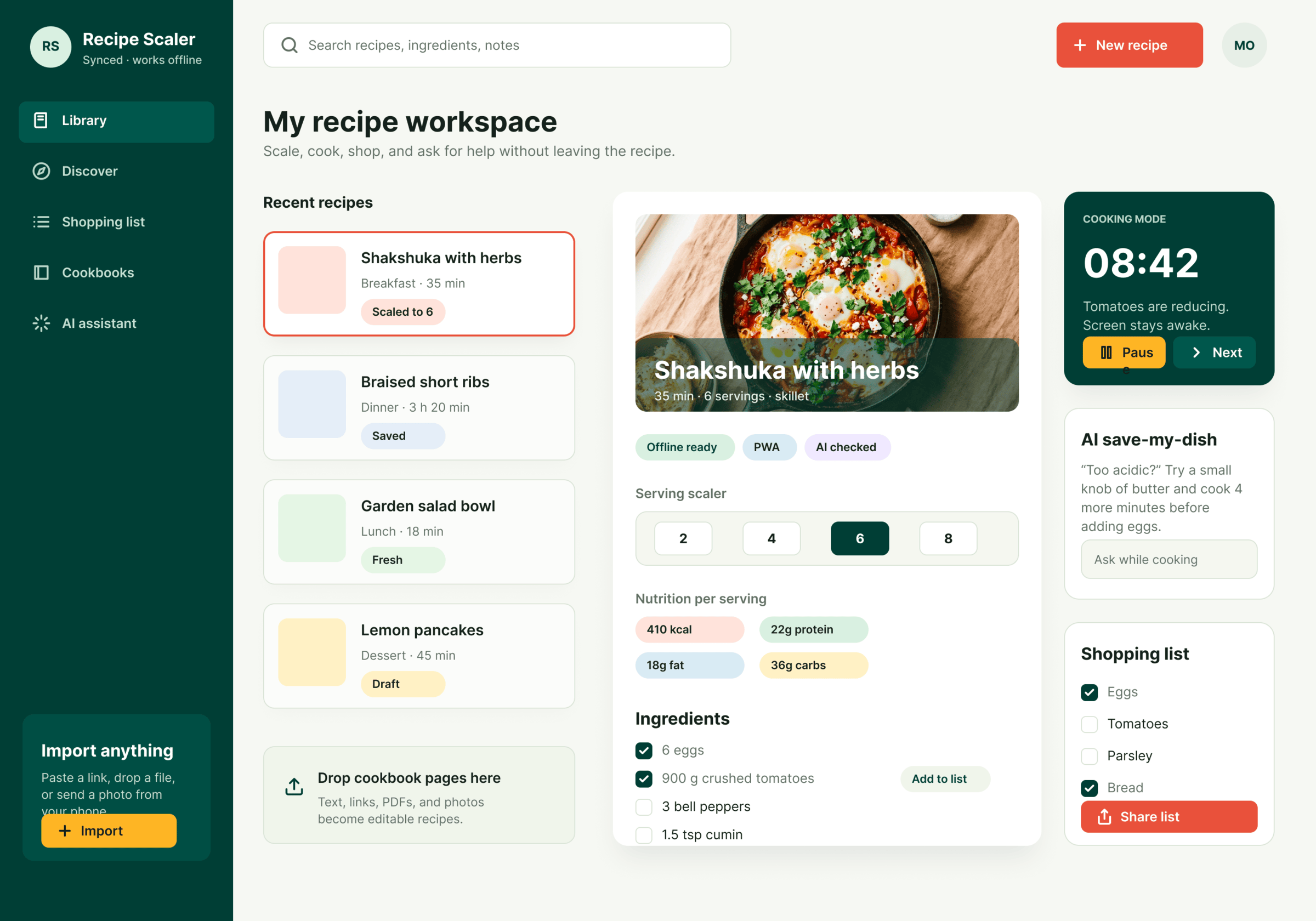
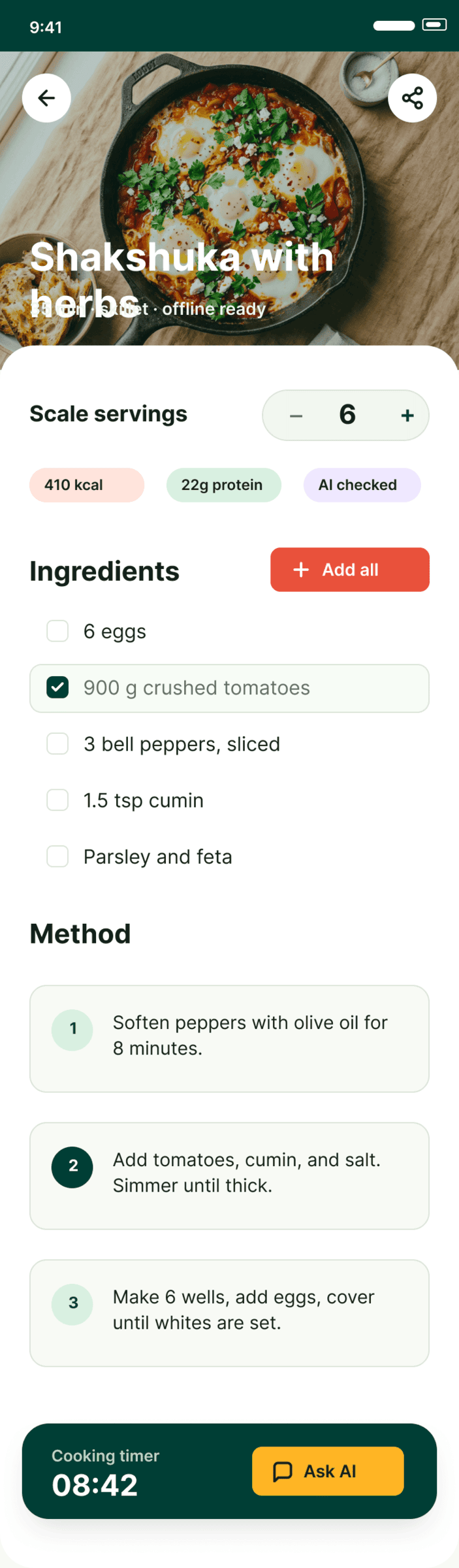
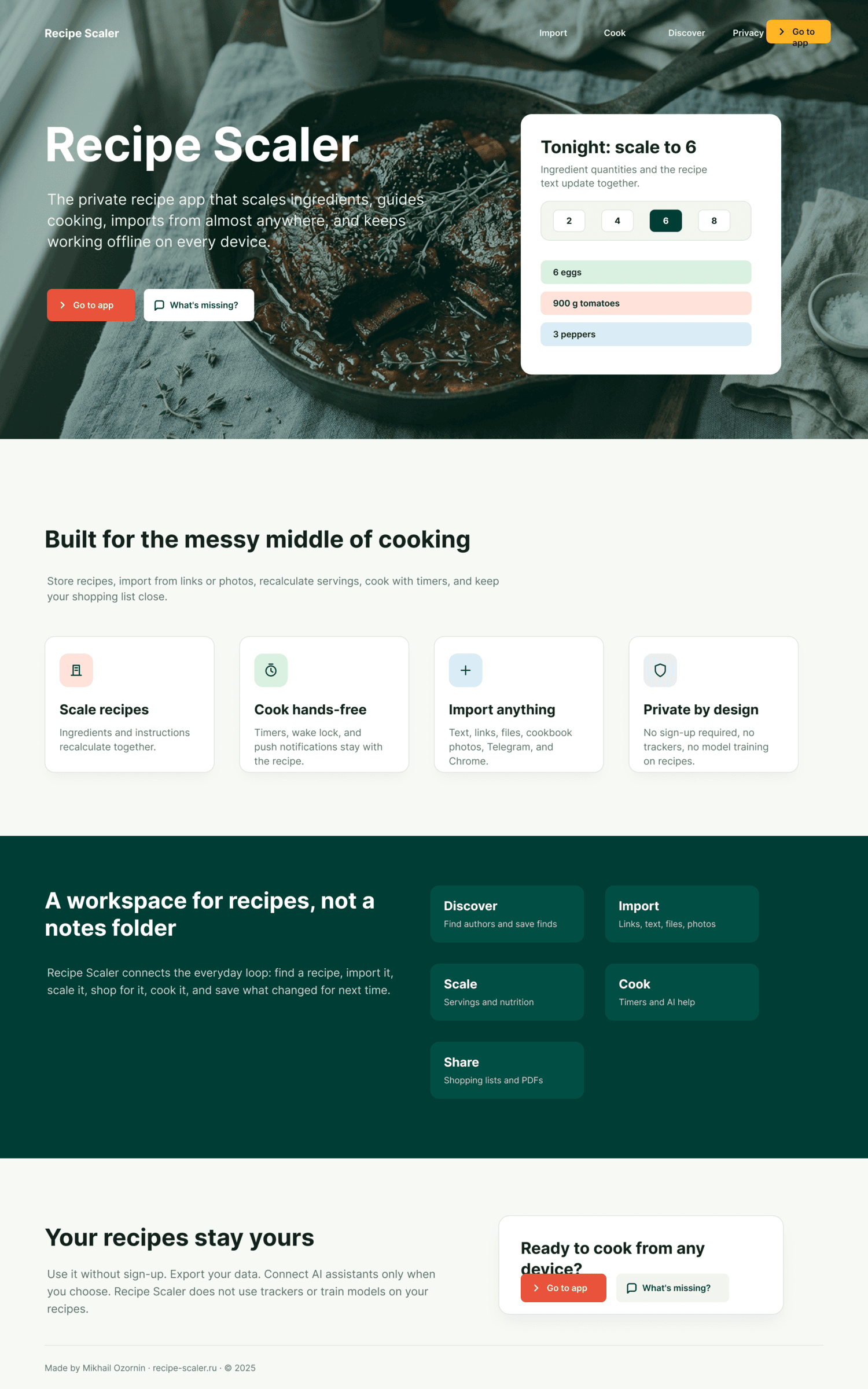
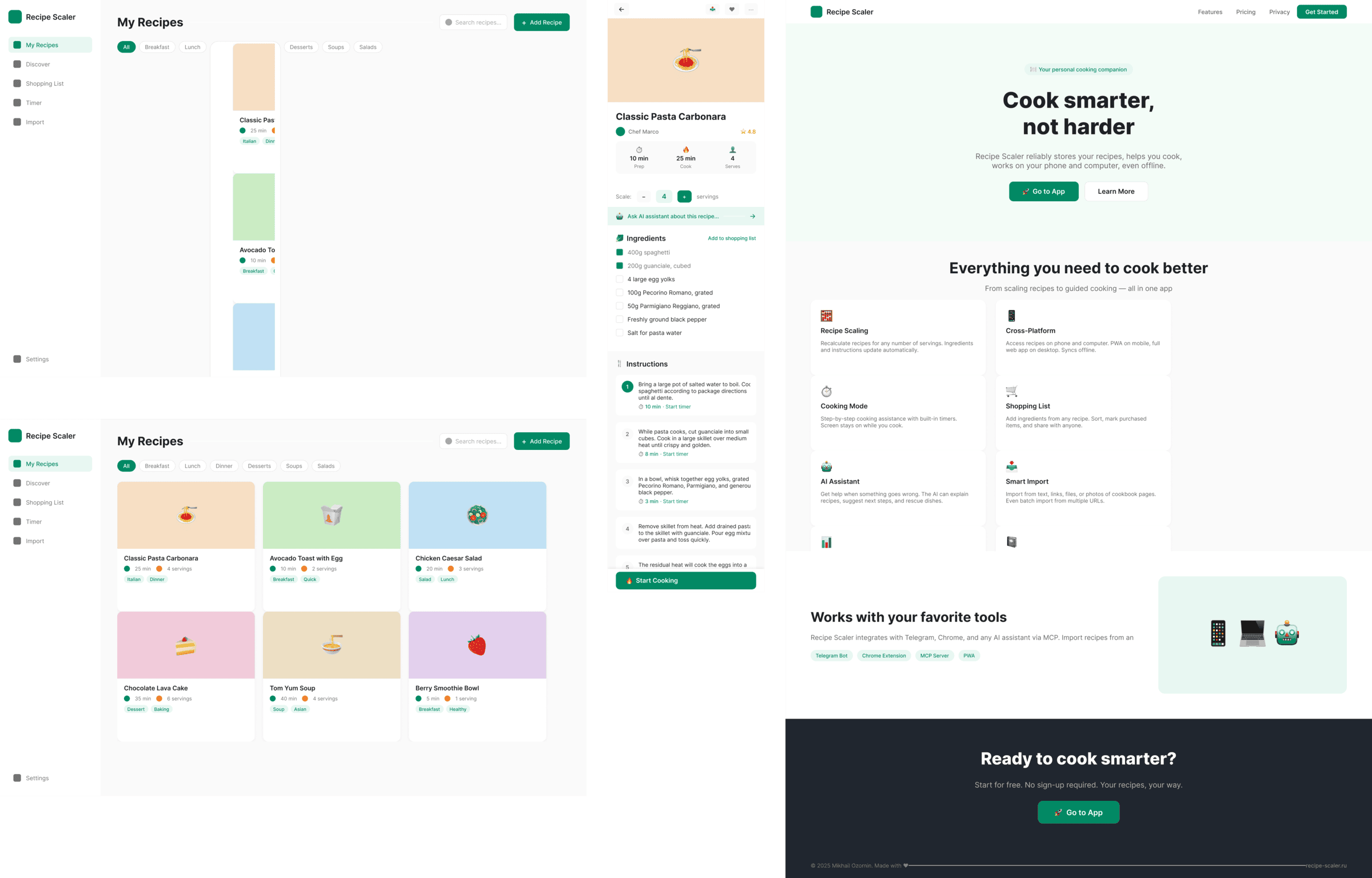
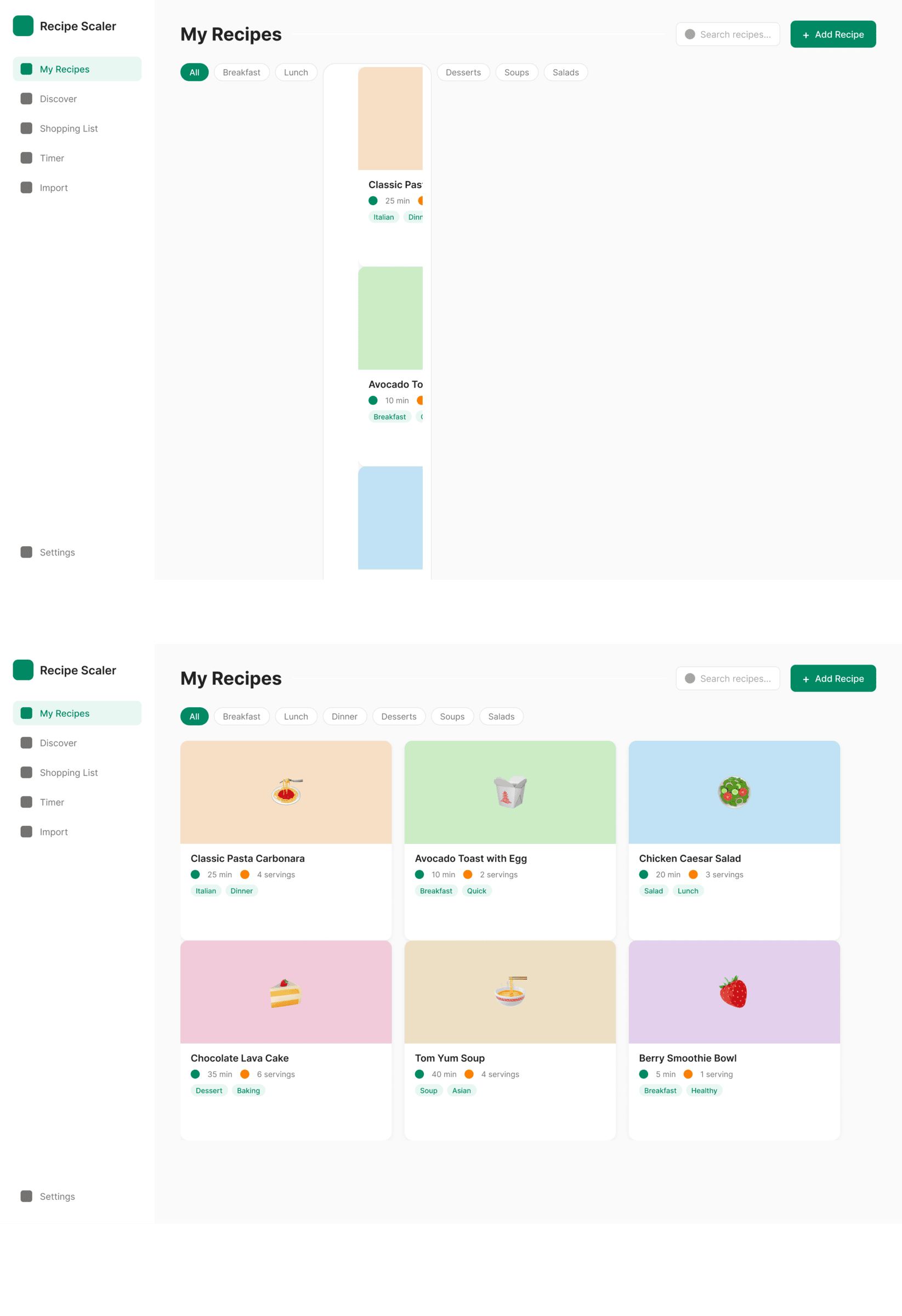
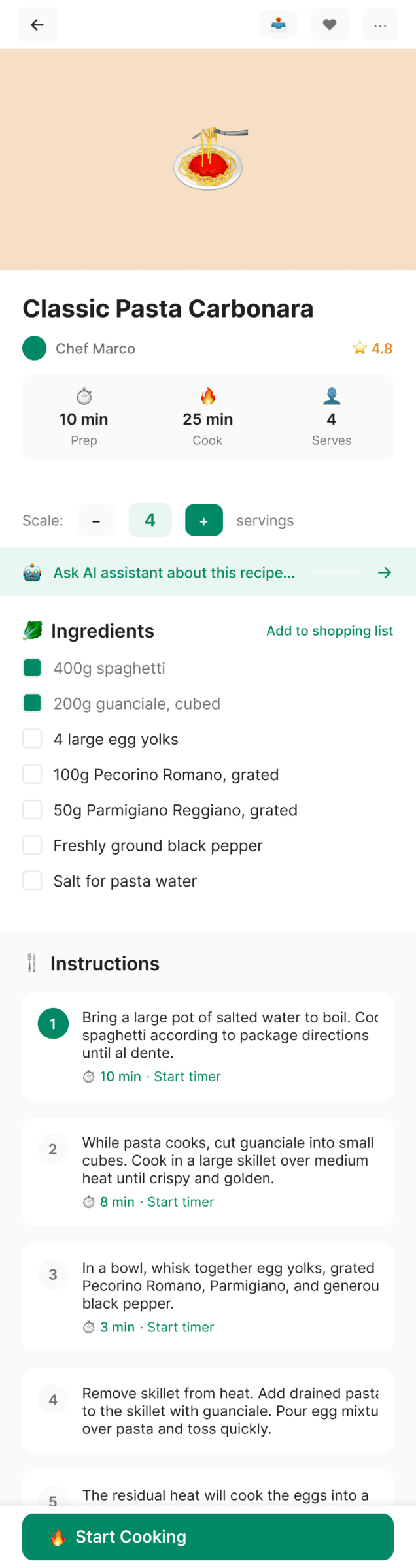
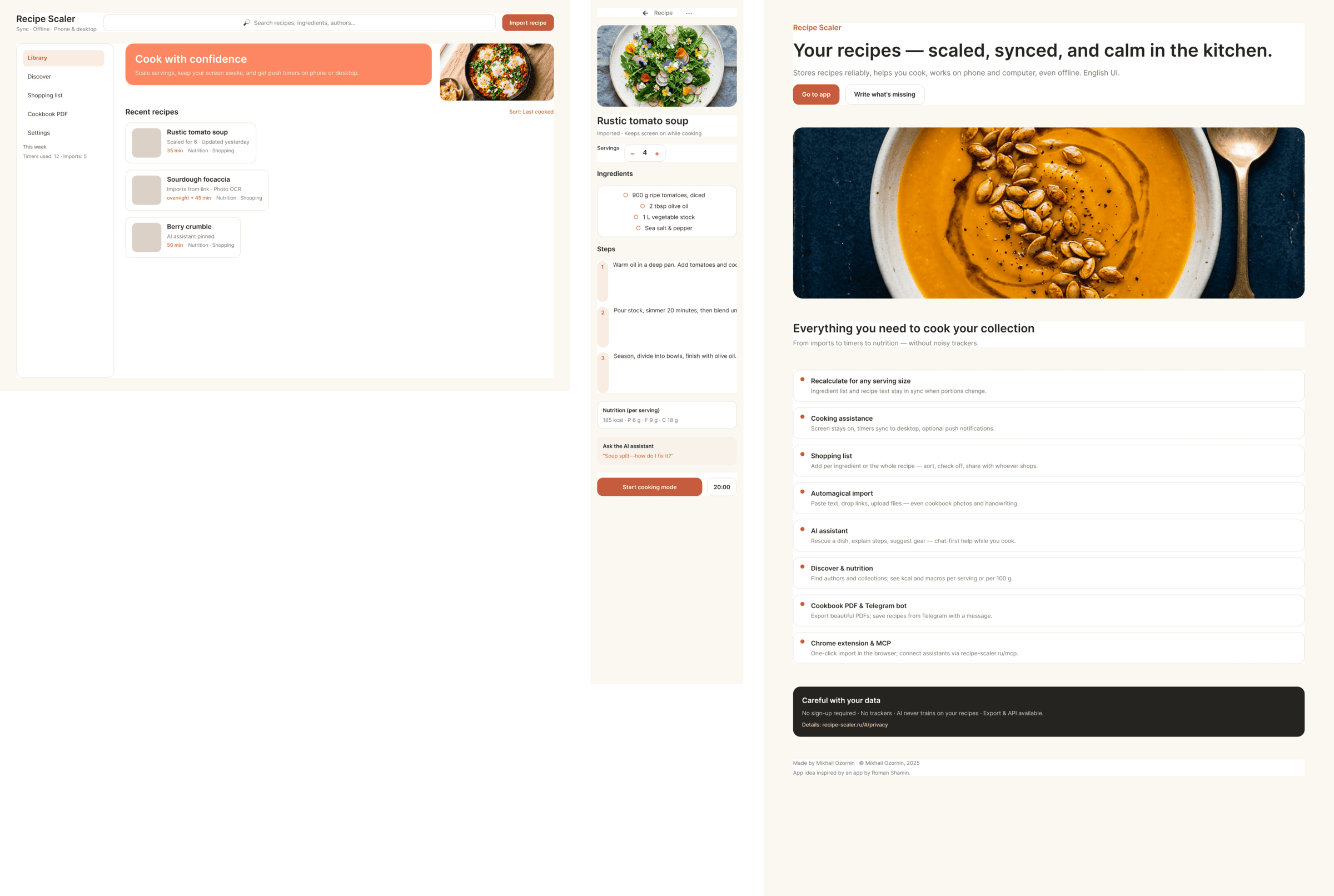
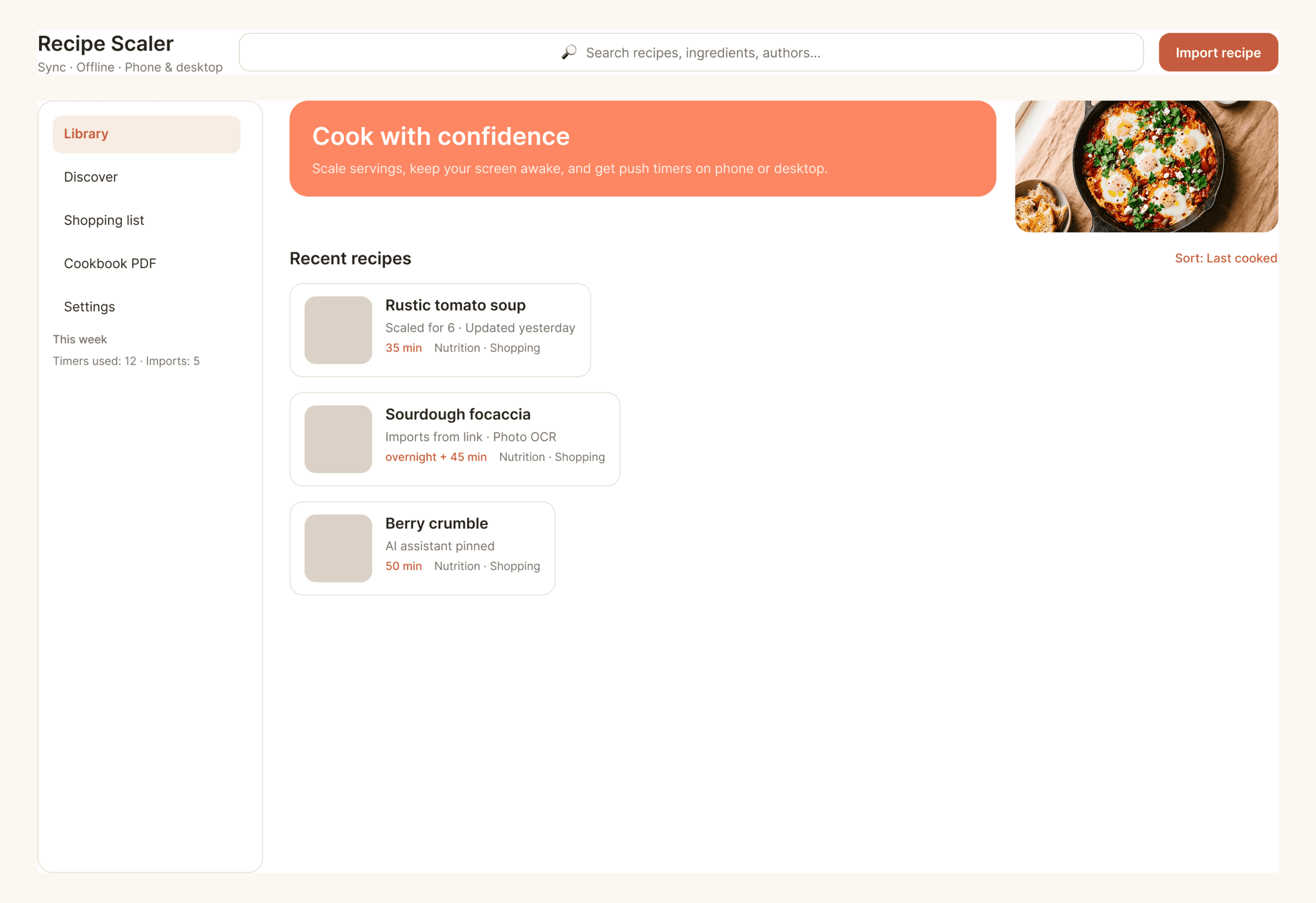
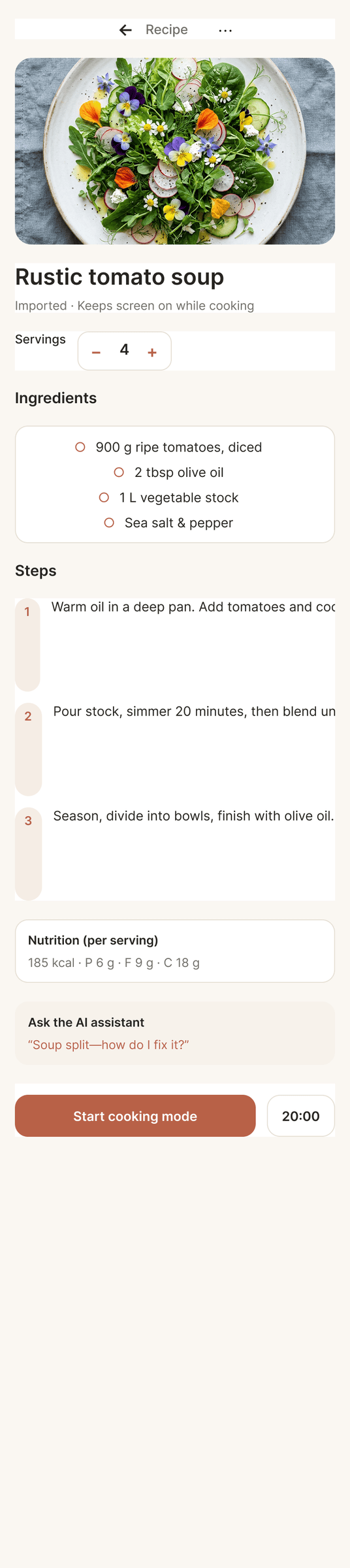
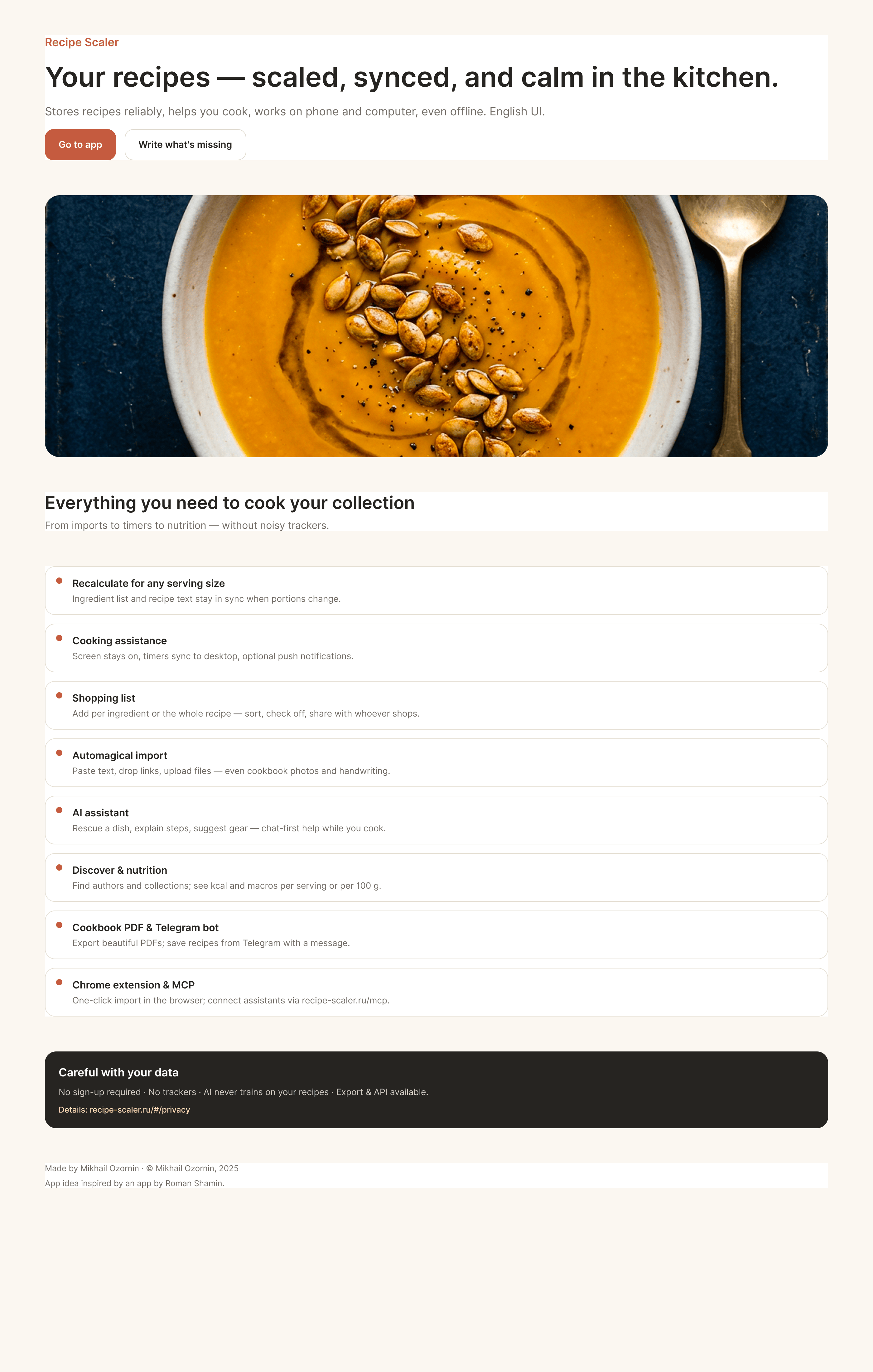
I gave the same task to 34 different agents + models. The task sounded like «make three screens for the same product»: a desktop screen, a mobile screen and a promo page. As the product I took my own recipe app and fed the agents the text from the about page.
I took all the popular agents and models that are currently of interest.
Agents:
- Agents from the main model vendors: Claude Code, Codex, even Antigravity
- The most popular independent closed agent on the market: Cursor
- The two most popular open agents (and the only ones at the moment that deserve attention): Opencode and Kilo Code.
Spoiler: in this task the agent wasn’t fundamentally important.
Models were used both via native providers and third-party ones through Openrouter. Models:
- Flagship models from American labs: Opus 4.7, Sonnet 4.6, Haiku 4.5, GPT 5.5 and 5.4, Gemini 3.1 Pro.
- Cursor Auto, Composer 2 and Composer 2.5 models, as well as niche players like Grok 4.3,
- All popular Chinese models: Qwen 3.7, Qwen 3.6 Max Preview (and the older Qwen 3.5 397B A17B), GLM 5.1, MiniMax 2.7, DeepSeek V4 Pro, Kimi 2.6.
All models received the task as a file on input, it was the same — only the file address differed — each model was given a fresh Paper file to exclude any influence from previous runs.
The full prompt for Paper is below (the Figma variant differed only in changing the tool and the link).
I am creating a design for a product.
# Task
Create new pages:
1. A desktop screen interface — choose the main screen and design it. Screen width: 1400px.
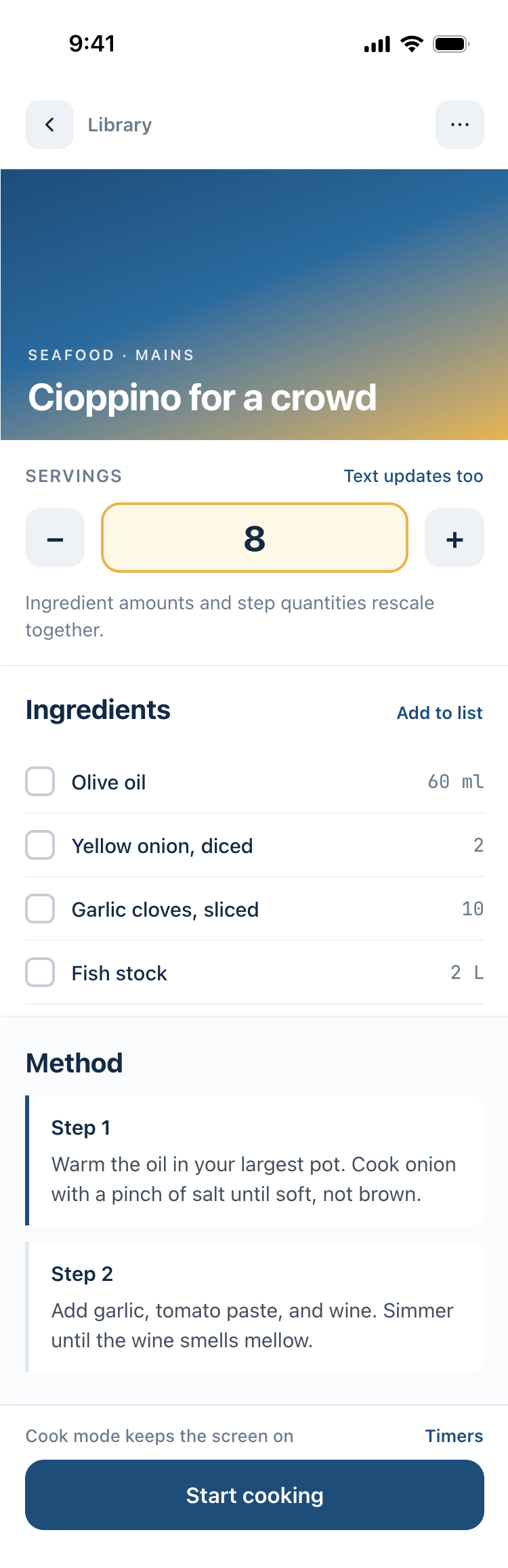
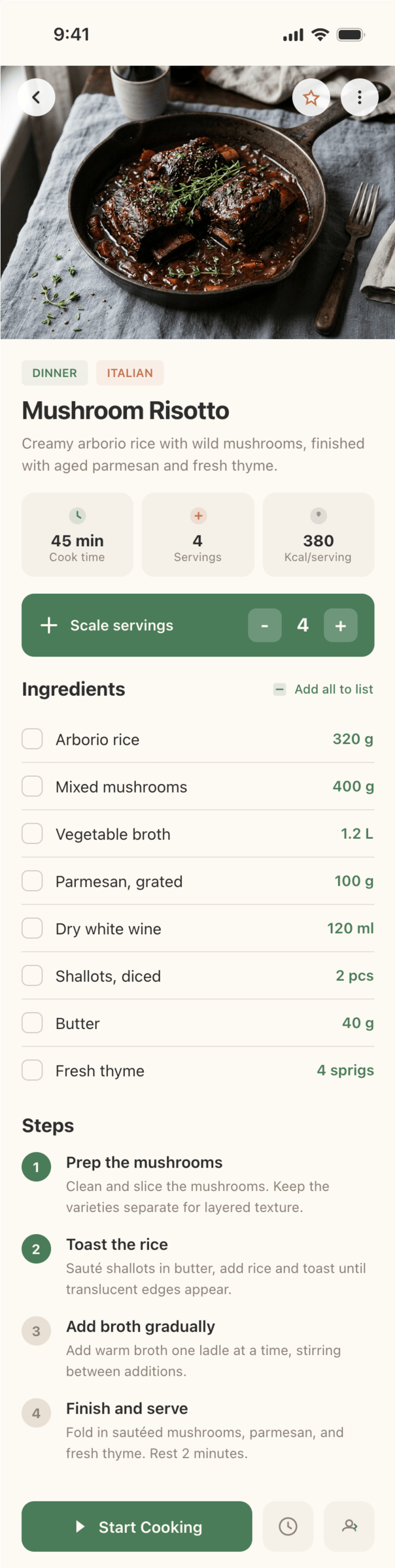
2. A recipe screen interface for mobile. You need to design a recipe screen. Screen width: 375px.
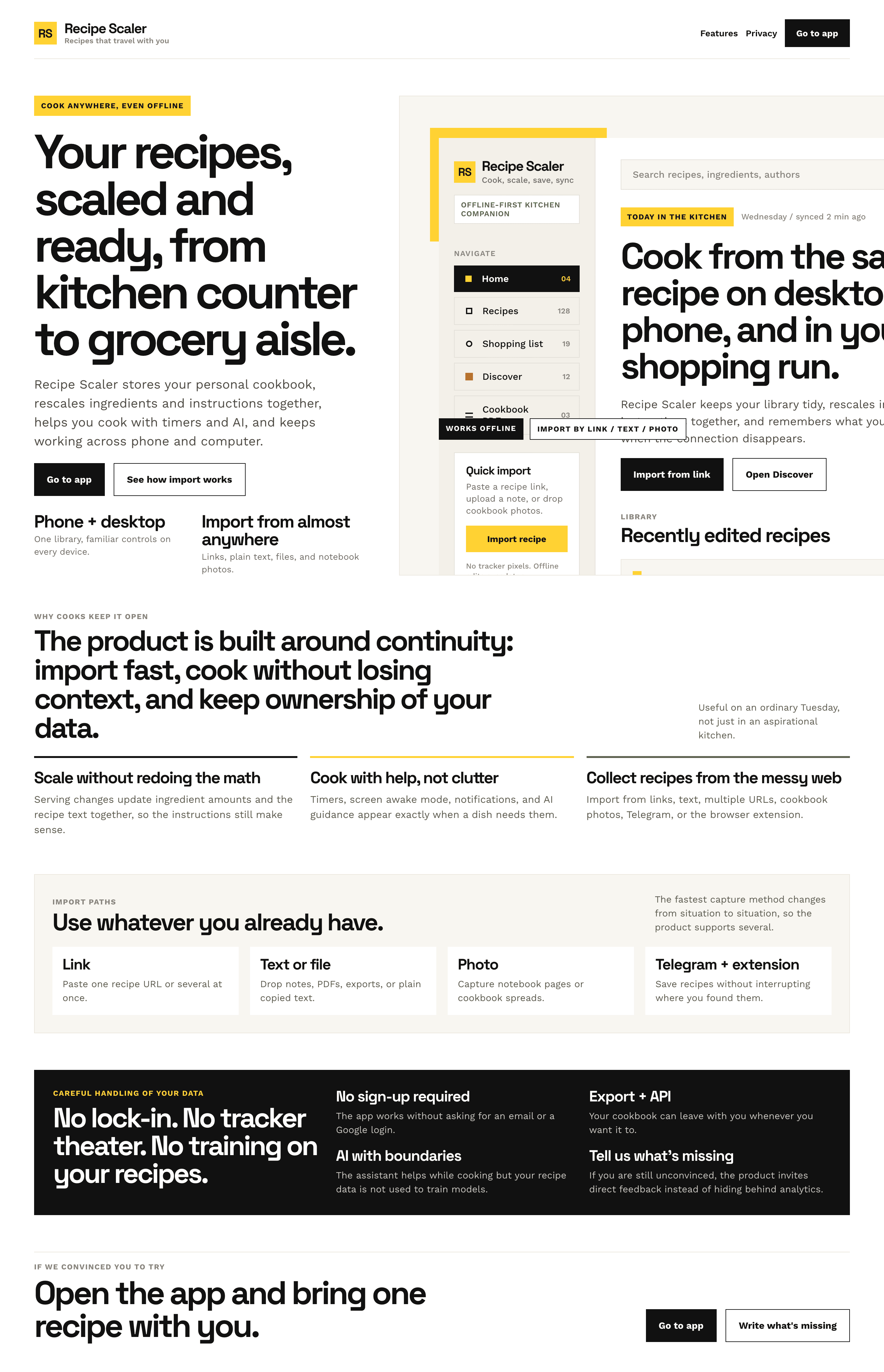
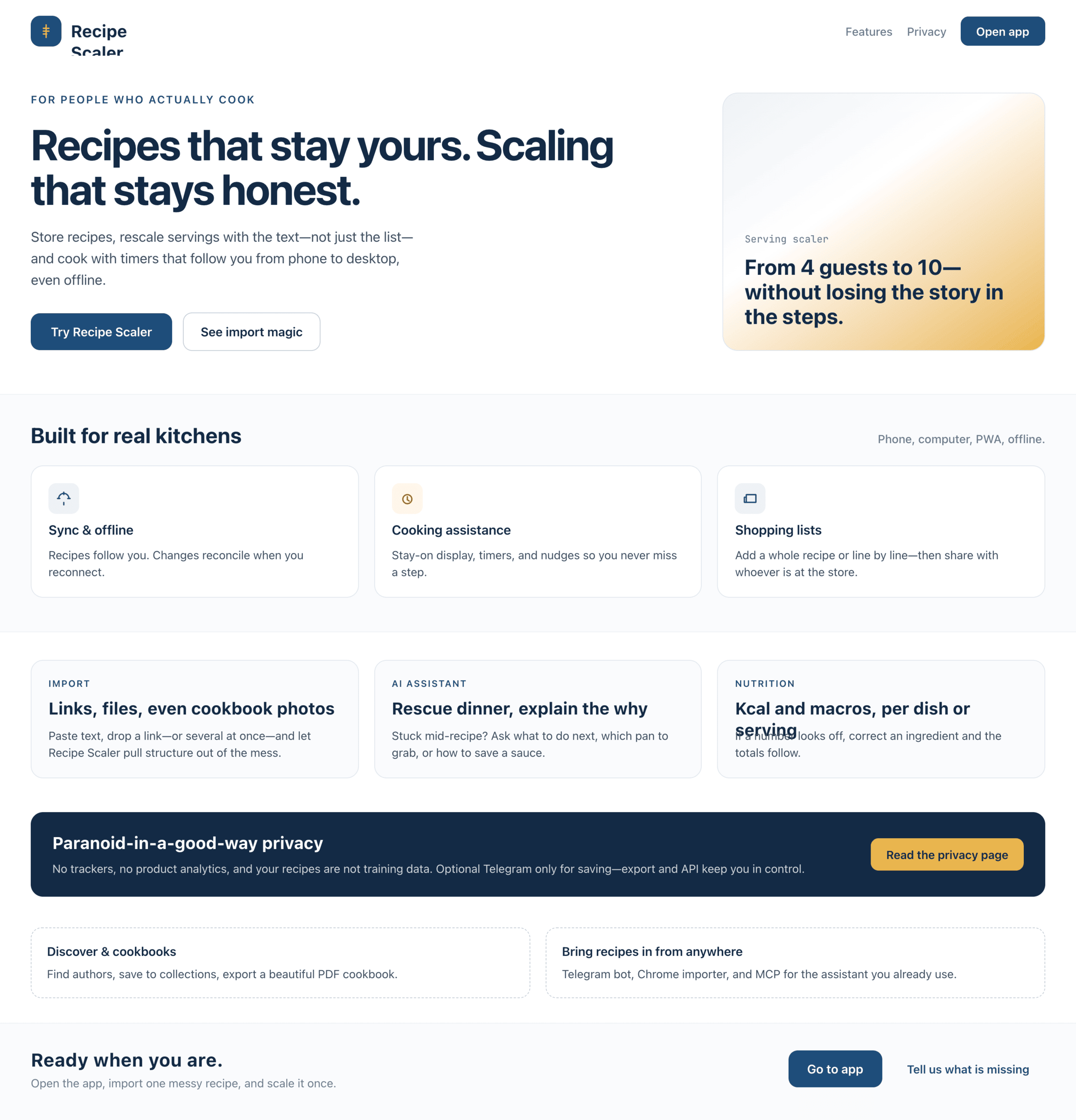
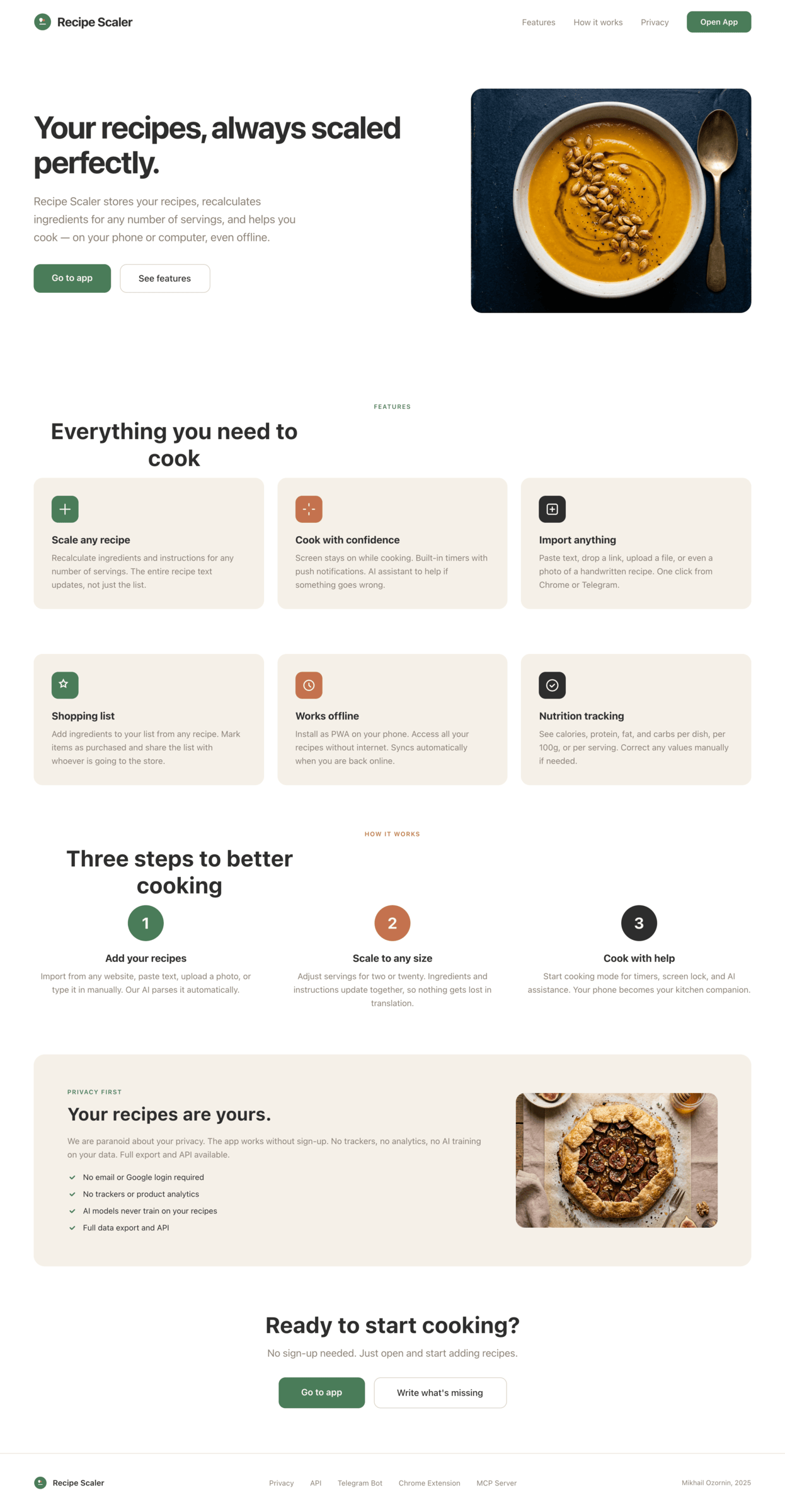
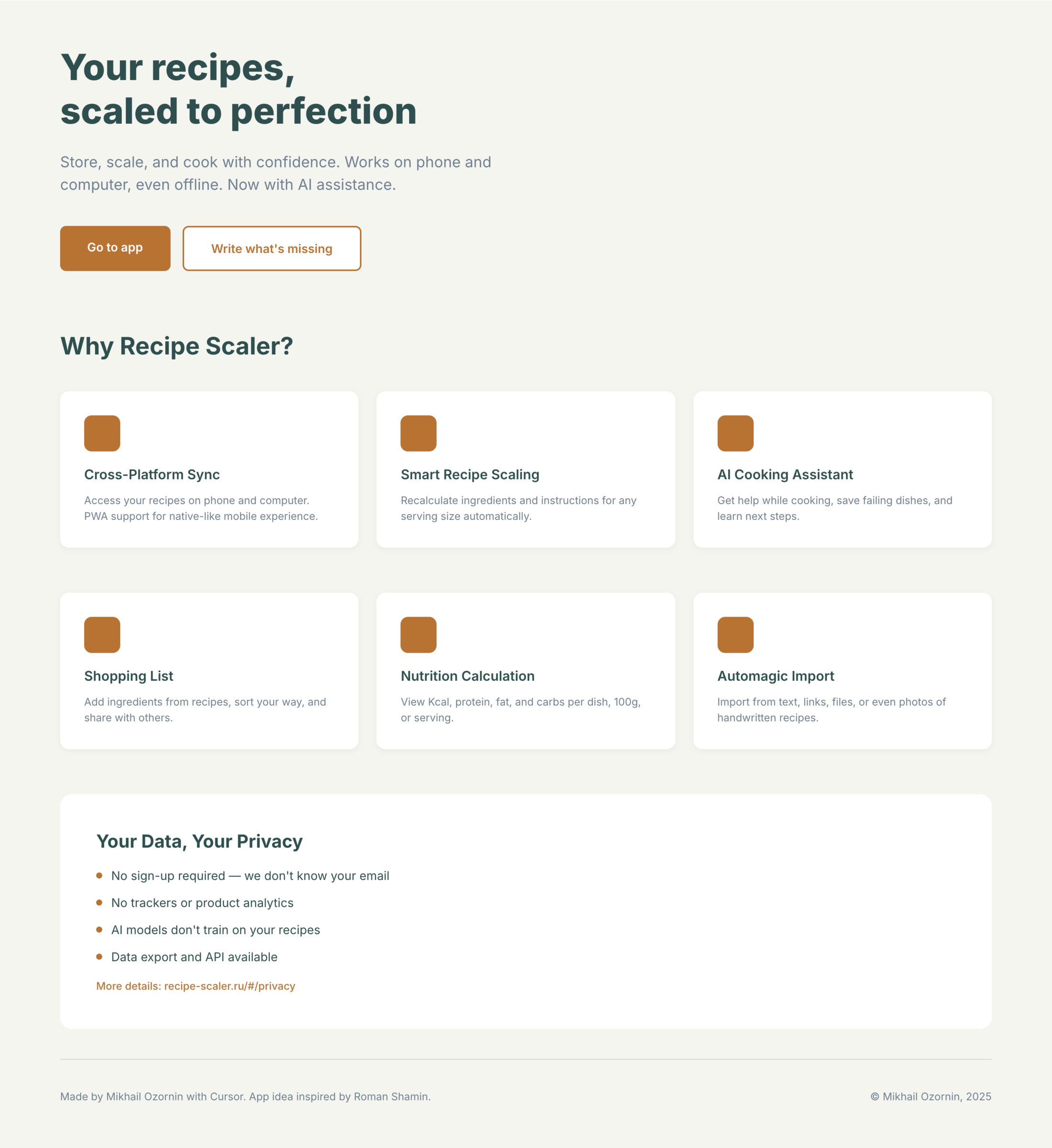
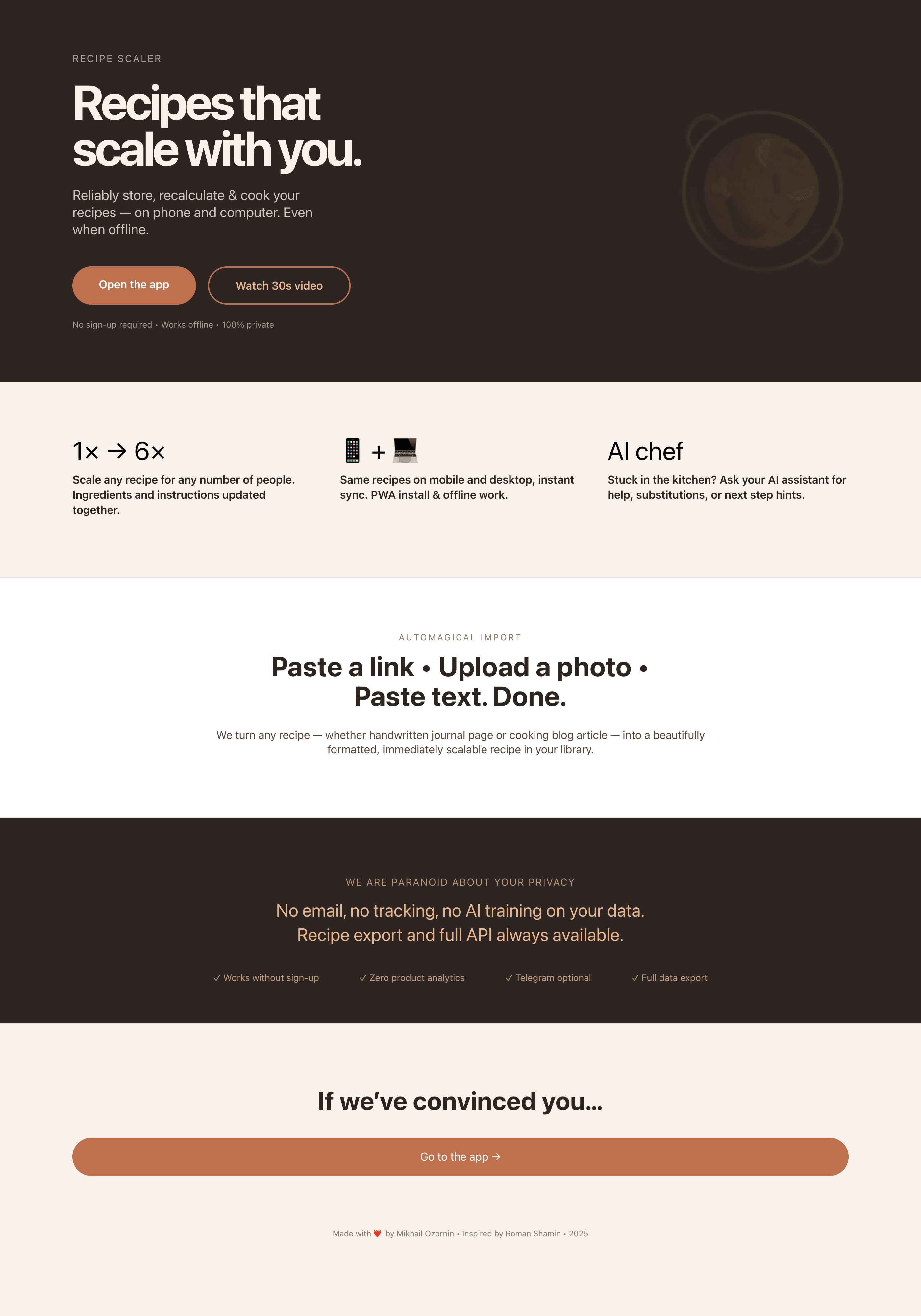
3. A promo page describing the product. Screen width: 1400px.
# Where to create it and expected result
Where to create: TODO
If the mockups are long, you can make a tall frame/artboard/layout. You do not have to fit standard screen proportions.
Use Paper MCP to create the design.
Use English for the content inside the mockups.
You can use pregenerated images for illustations: '/Users/mike/work/git-repos/projects/ai workshops/design with ai-tmp'. If you have built-in tools for drawing images, you can use them too.
Below is the product information, which also describes the product capabilities.
# Product information
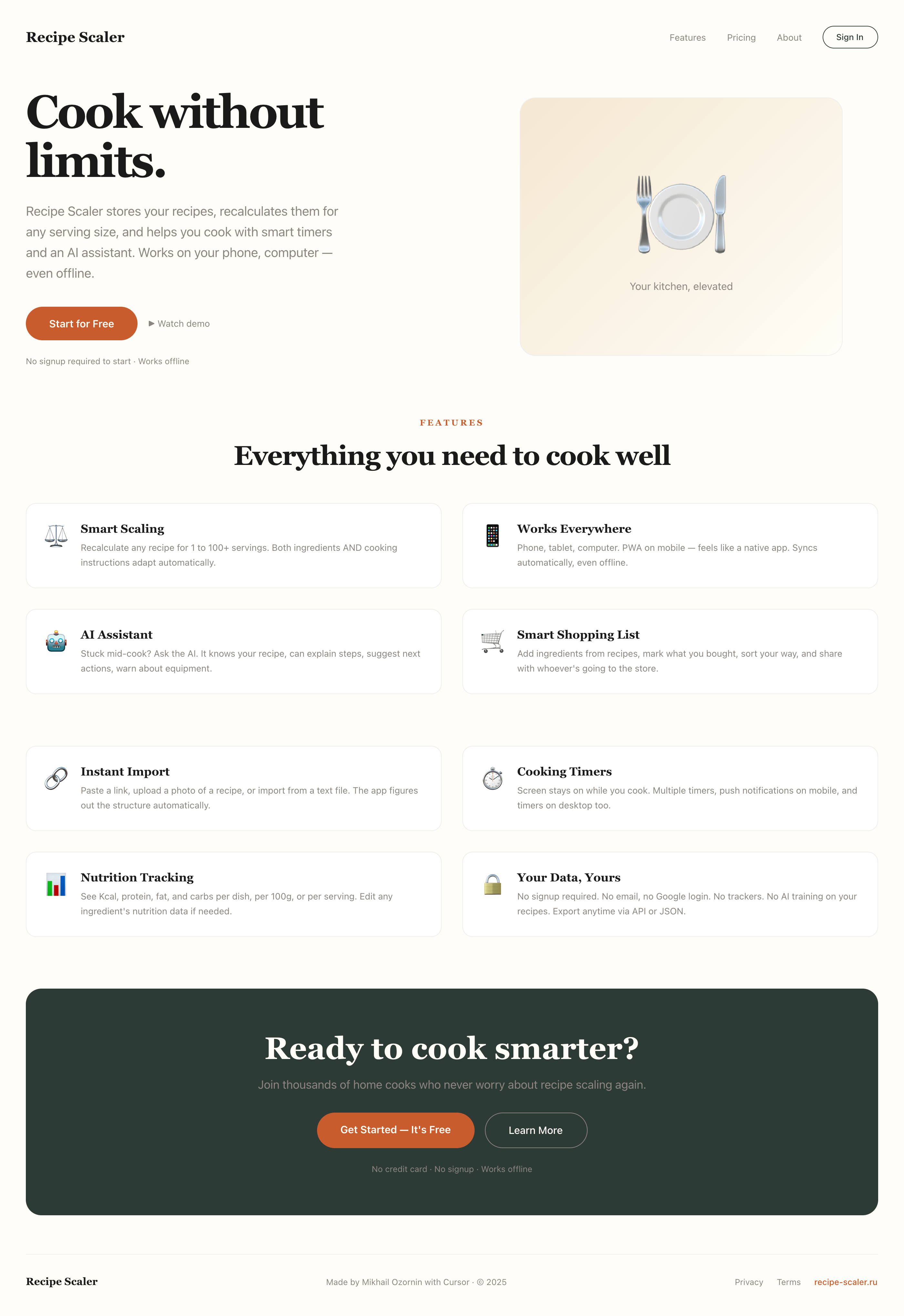
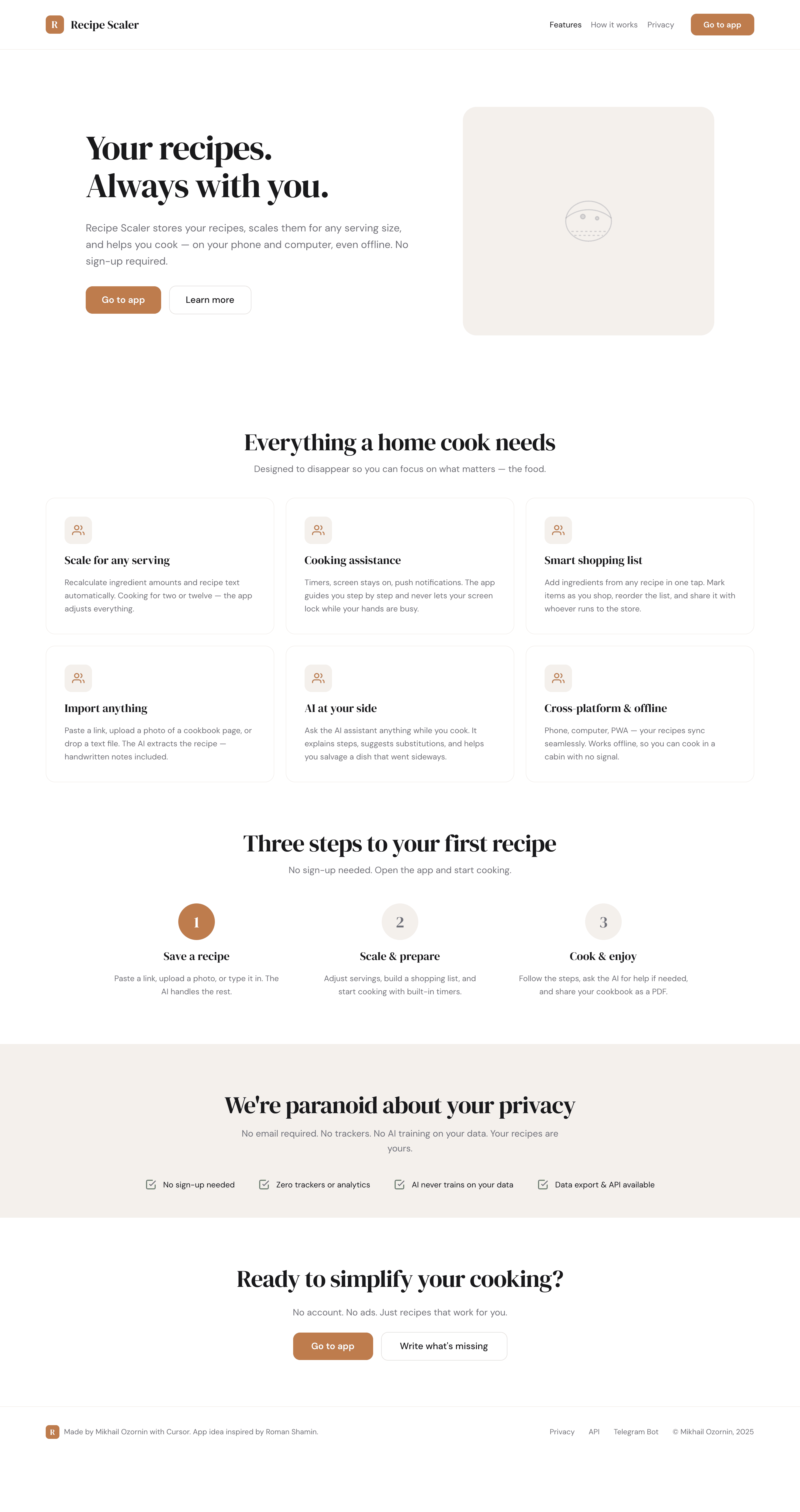
```
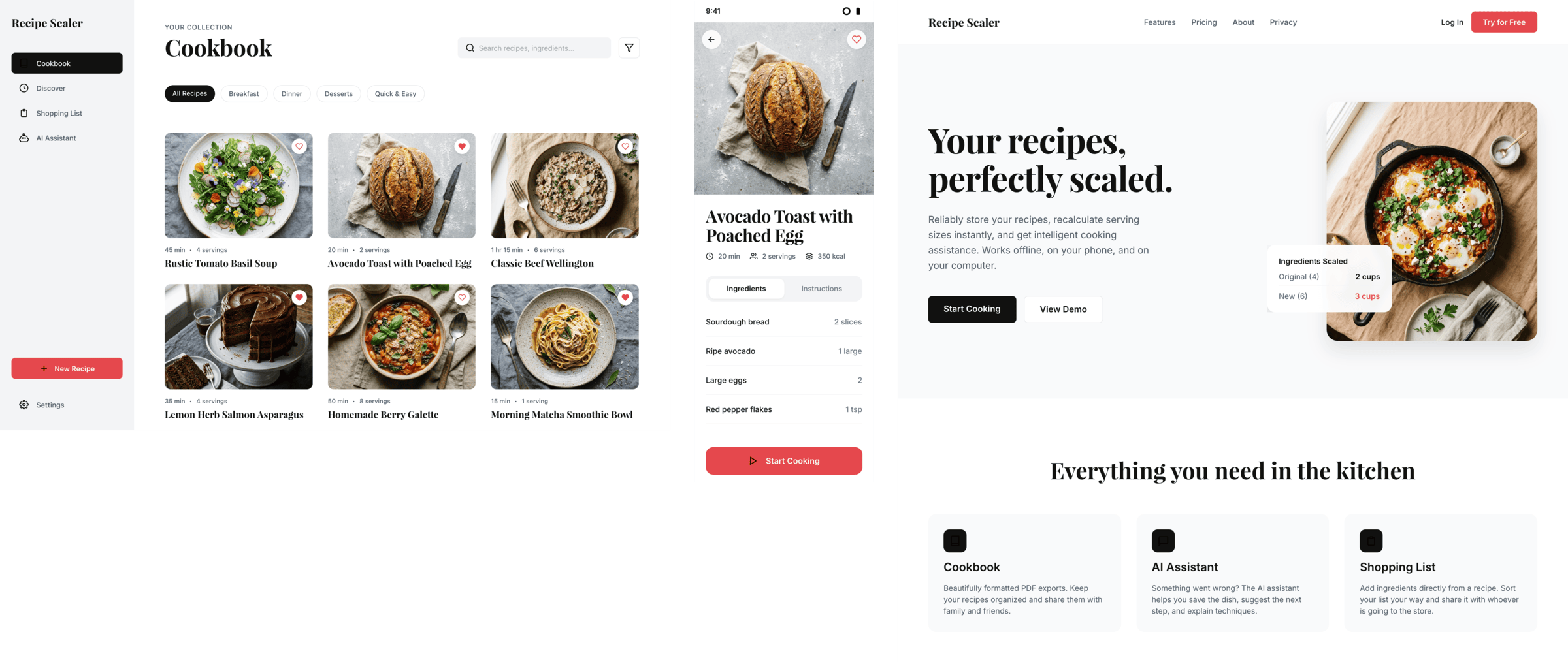
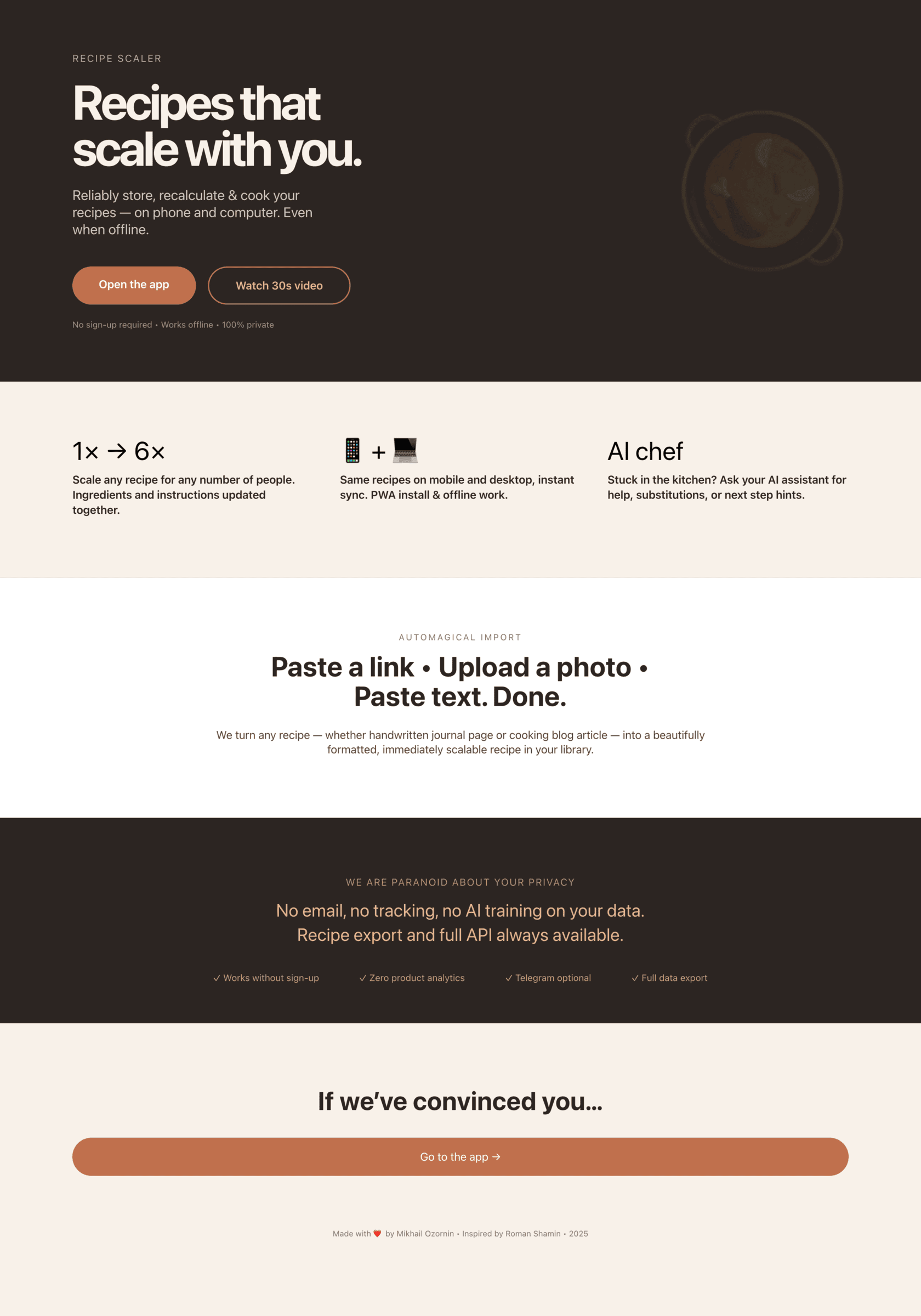
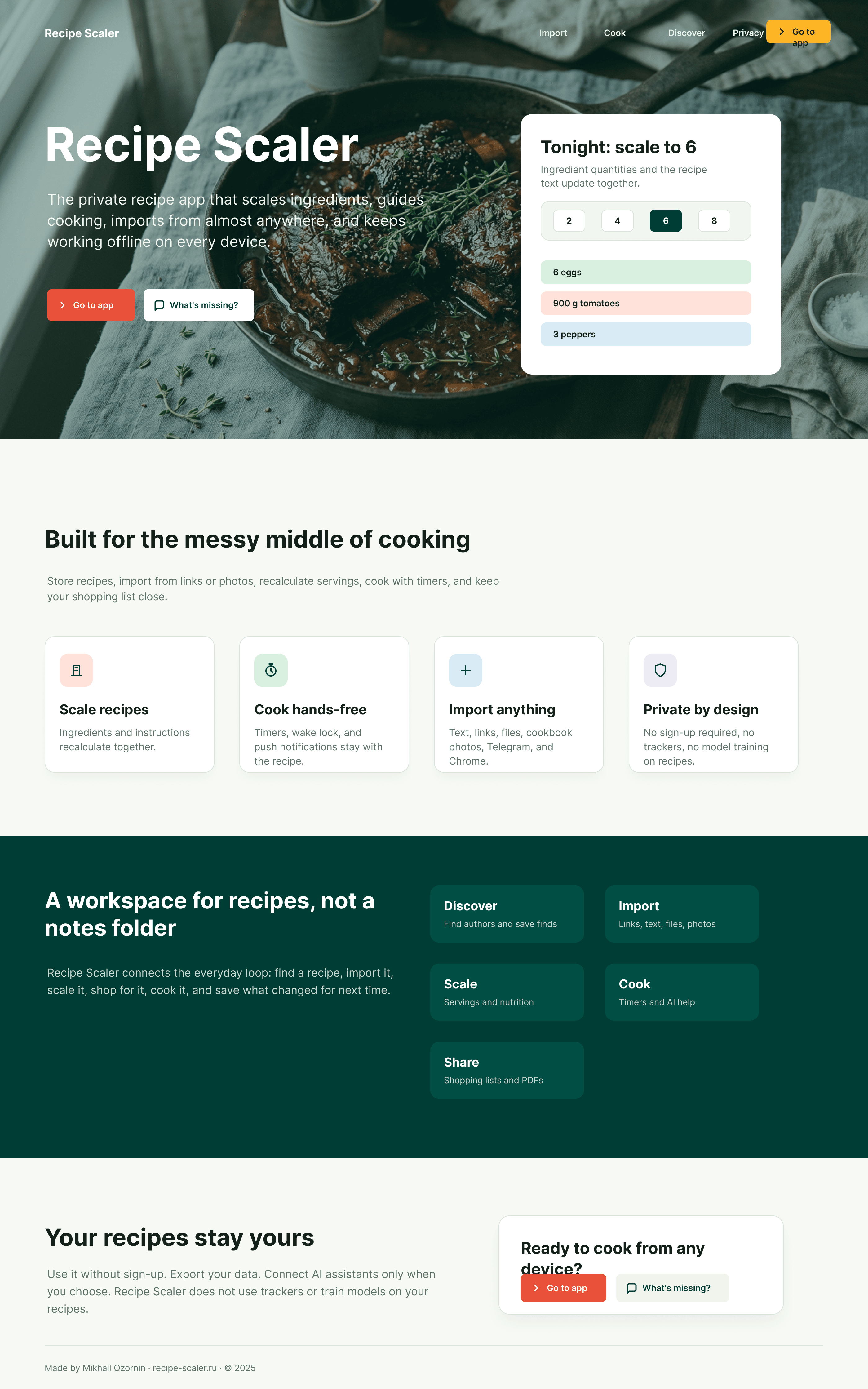
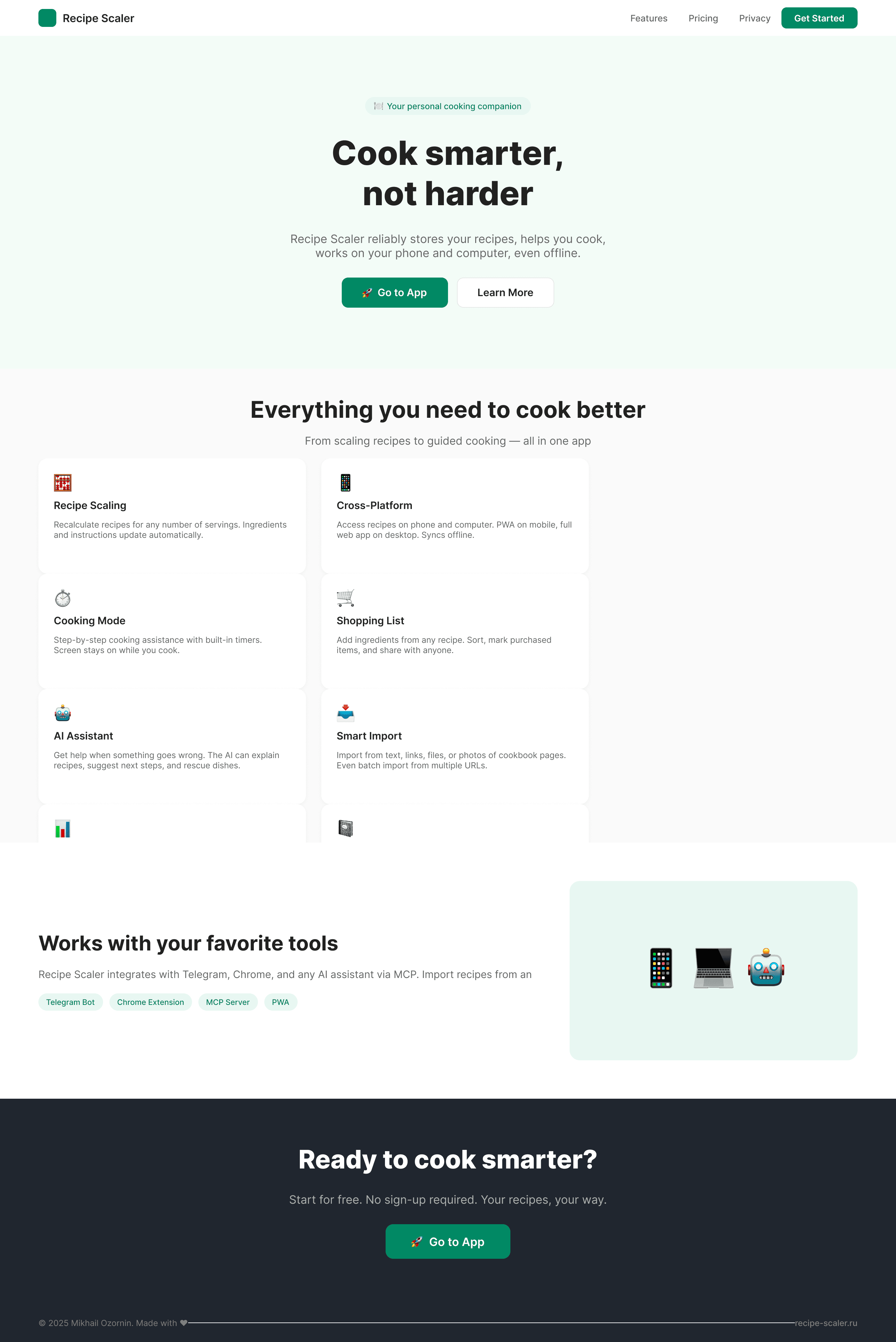
Recipe Scaler — app for those who cook
It reliably stores your recipes, helps you cook, works on your phone and computer, even offline.
Access from phone and computer
You will have access to your recipes both on your phone and computer. The apps will sync automatically, even from offline.
On each platform, the web application uses familiar ways of working: hotkeys on the computer, and standard gesture controls on the phone.
On the phone it works as PWA — install it on your home screen and you won't tell the difference from other apps.
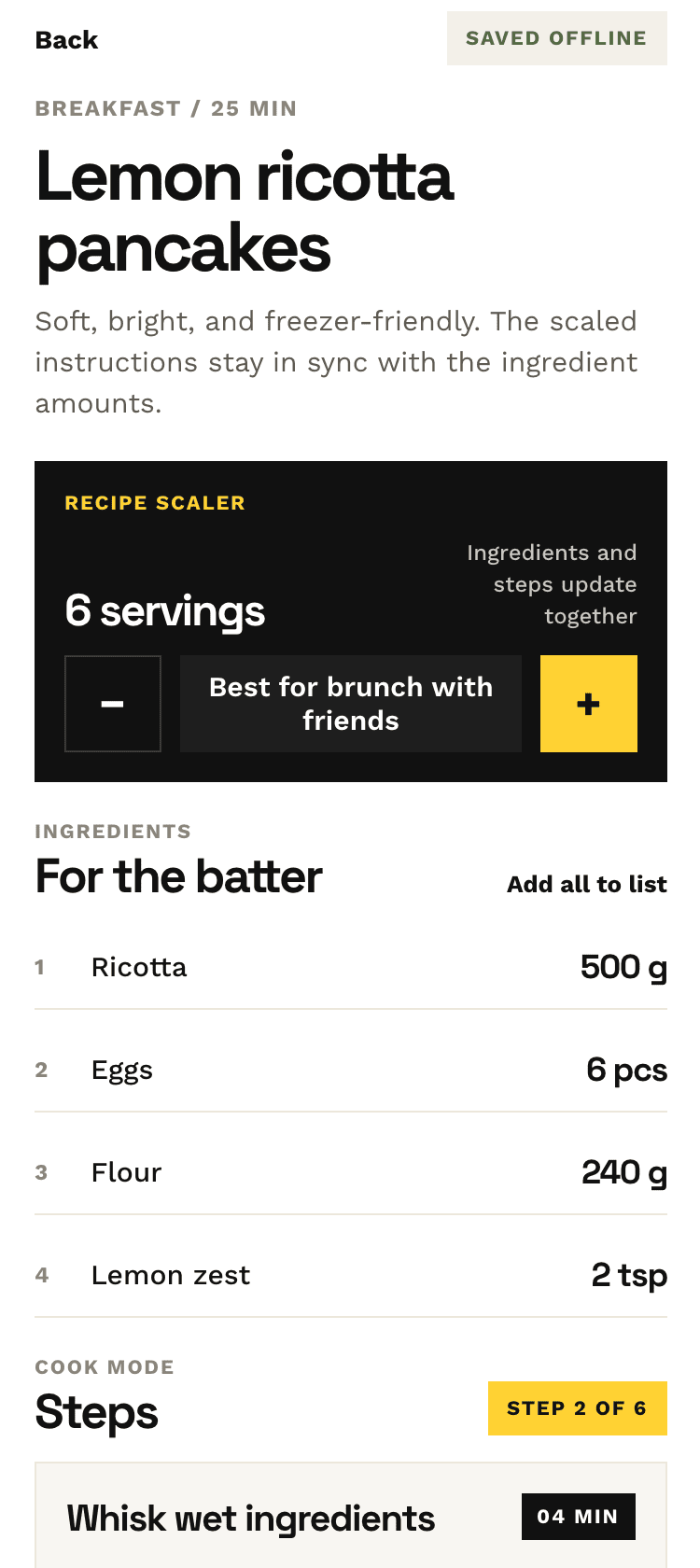
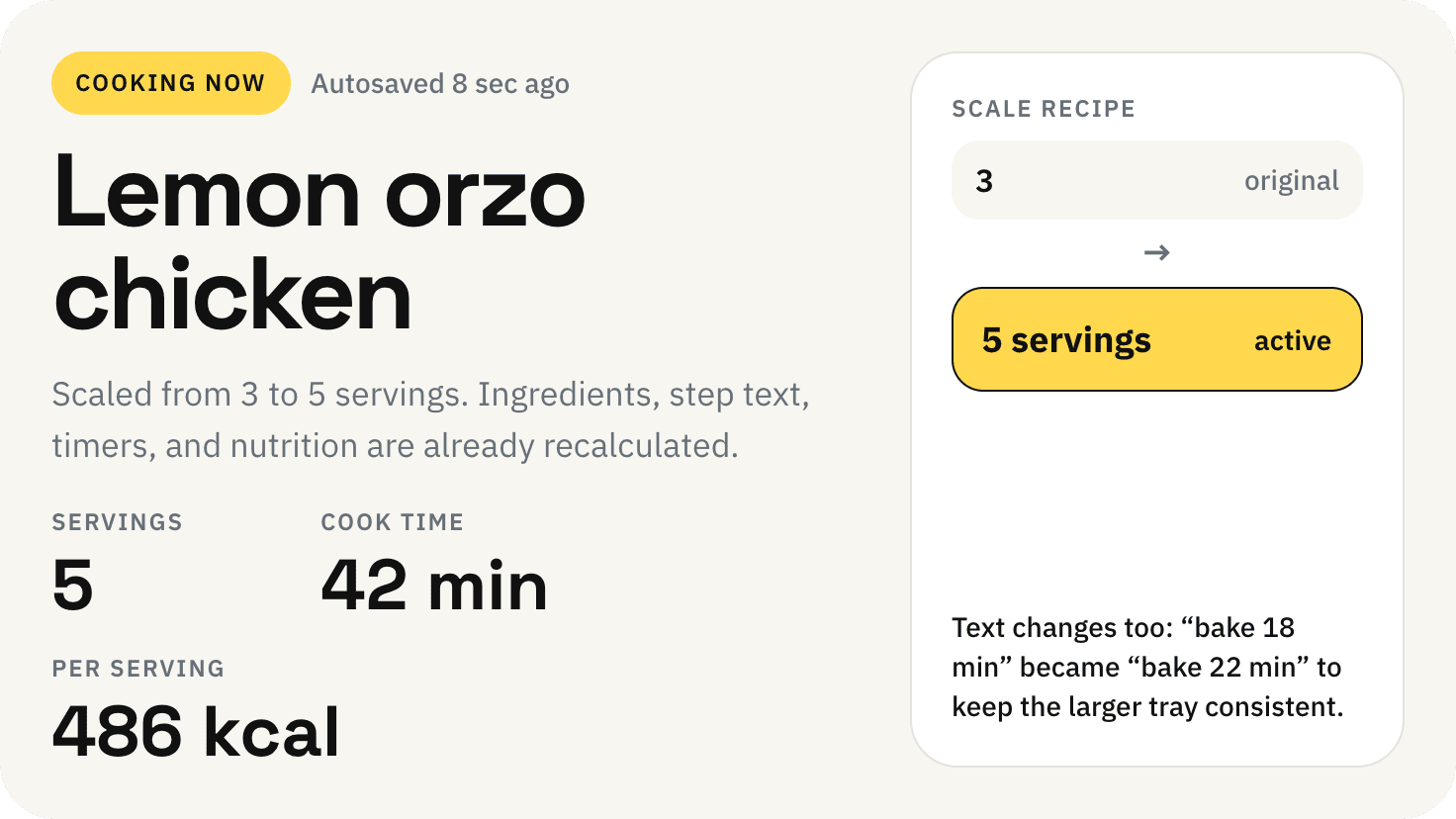
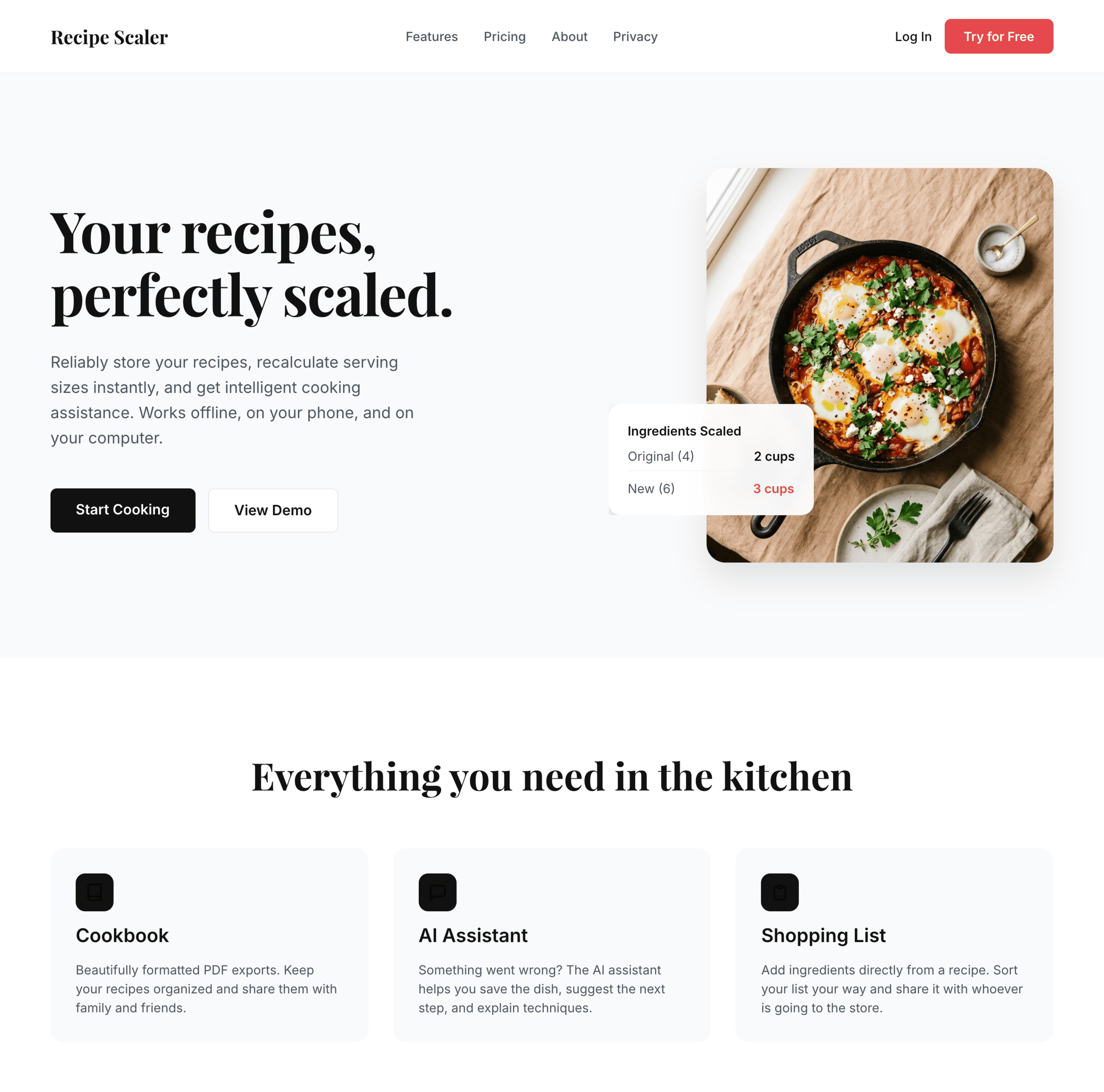
Recalculate recipes for different serving sizes
This is where the app started: recalculating recipes for different serving sizes.
When recalculating, not only the ingredient list is updated, but also the recipe text.
Cooking assistance
The app will help you cook: it won't turn off the screen while cooking, will track time and even send push notifications. Timers are, of course, available on the computer too.
Shopping list
Add ingredients to your shopping list one by one from a recipe, or add the whole recipe at once.
Mark purchased items, sort the list the way you like, and share the list with the person going to the store.
Automagical recipe import
Recipe Scaler can import a recipe from text, a single link, or multiple links at once.
You can also upload a file in almost any text format and even photos of pages from a cookbook, notebook, or handwritten recipe journal.
AI assistant for recipes
If something goes wrong while you cook, the AI assistant can help you save the dish and figure out what to do next.
It can also explain the recipe, suggest the next step, and point out the equipment you may need.
It's like having a chef always at your fingertips, ready to answer your questions.
Discover section
Find new recipes in Discover.
Explore interesting authors, save recipes to your collection, and build your own shortlist of the best finds.
Health-friendly: nutrition calculation
Recipe Scaler will calculate the nutritional value (Kcal, protein, fat, carbs) for a dish and let you view it conveniently: for the entire dish, per 100 grams, or per serving.
If artificial intelligence makes a mistake in the numbers, you can always correct the nutritional value of the needed ingredient.
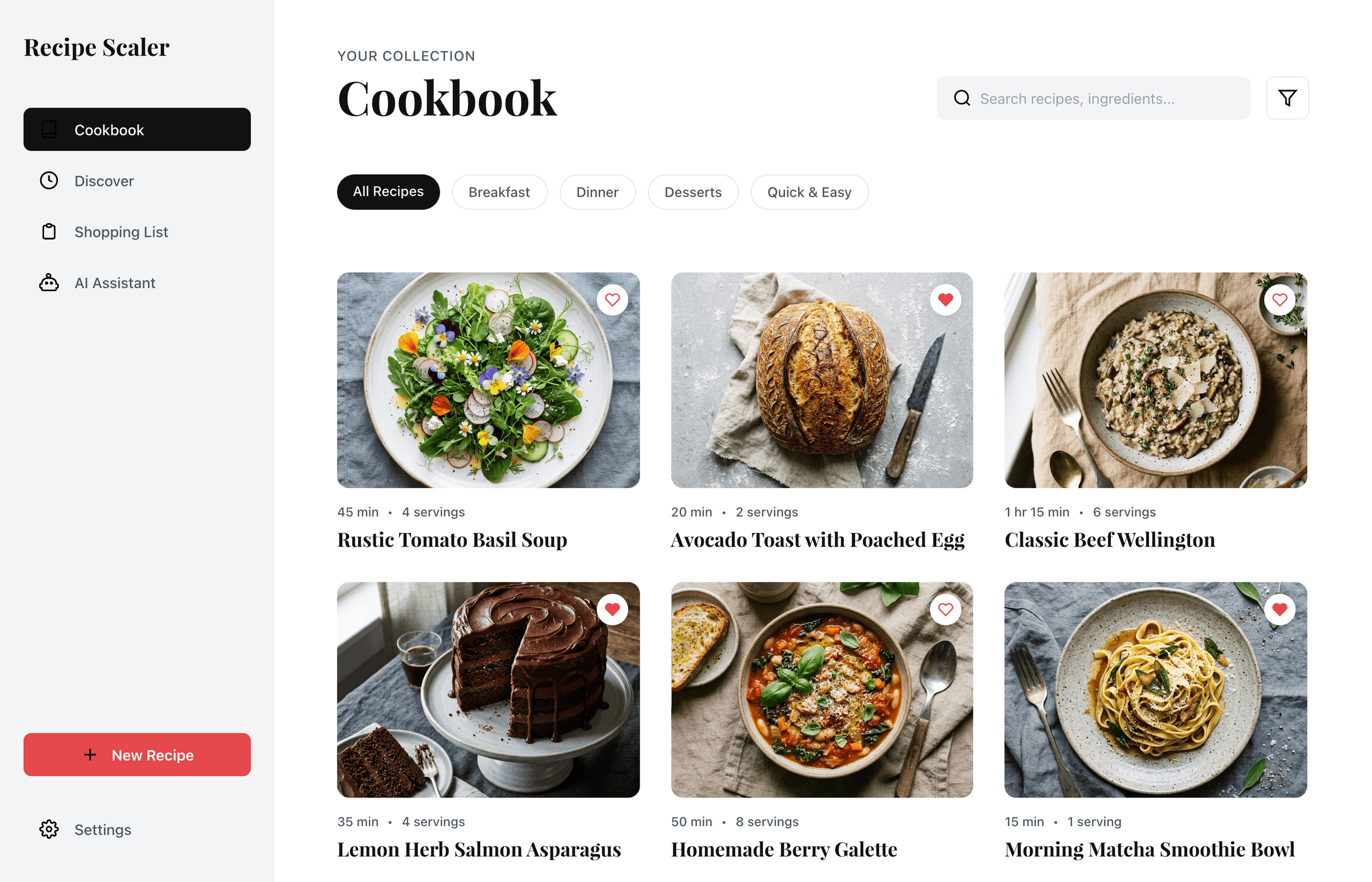
Cookbook
Download a public recipe collection (your own or someone else's) as a beautifully formatted PDF.
The cookbook includes recipes with photos, ingredients, and cooking instructions.
Telegram bot
Send the bot a recipe text or a link to it and the bot will save the recipe to your account.
Chrome extension for quick import
Install the Recipe Scaler Importer extension and import the recipe into your account in one click.
AI assistant integration
Connect your AI assistant to recipes. It can search recipes, add new ones, or help you cook the way you're used to: in chat, by voice. To connect, use the link: recipe-scaler.ru/mcp
For techies: yes, this is an MCP server.
Careful handling of your data
We are paranoid about your privacy.
The app works without sign-up: we don't know your email or your Google login. Even Telegram is only needed for saving recipes. Don't want it? Don't use it.
We don't use trackers or product analytics.
We don't allow AI models to train on your recipes.
Data export and an API are available, so we don't hold your data hostage.
More details: recipe-scaler.ru/#/privacy
If we've convinced you to try:
Go to app
If we haven't convinced you:
Write what's missing
Made by Mikhail Ozornin with Cursor. App idea inspired by app by Roman Shamin.
© Mikhail Ozornin, 20251.2 Particulars of the experiment
- The models were given basic limitations and instructions, there were no clarifications about style, design system and so on. I didn’t answer clarifying questions, I just skipped them. There was no intervention in the process — at most, if the agent was waiting for something, I asked it to start or continue.
- All models except Opus 4.7 worked on the maximum possible reasoning setting or its substitute parameter (effort for Claude Code).
- I deliberately didn’t give any preferences about style, didn’t attach any design system, didn’t describe more important and less important scenarios. I wanted to check not what I could design with an LLM, but what the agent itself could do.
- All texts were in English. This is a small cheat for the models — there are noticeably more good fonts for English than for Cyrillic. With Cyrillic it would be worse, I think. The font choice would be more primitive, and they would have boldly picked fonts that don’t have Cyrillic at all.
- For design I used Paper MCP, with Figma MCP as a backup option. Paper MCP works better, faster and is open to a larger number of agents. Figma doesn’t let the open agents Opencode and Kilo work with it. I also tested with Figma MCP, just launched fewer variants.
- To make the comparison fairer, I didn’t fix the mockups by hand — at most I occasionally stretched the frame if the agent made the artboard smaller than its own content. It was a shame to see that it was right there.
1.3 Formal goals
What I wanted to look at and check:
- The result: how close the produced mockups are to solving the task at all, how usable the result is at work, how beautiful, neat and overall good it is.
- The internals: how cleanly it’s laid out inside, whether you want to wash your hands after this.
- What about the cost of the solution.
- How much the result depends on the agent.
- How much the result depends on the reasoning level.
In general, I wanted to understand which models and agents make sense to use for something, and which don’t.
2 Results
The gap between the models is huge — some laid things out interestingly and beautifully. Others laid out neuro-slop in its worst sense, the third group couldn’t cope with the tools at all and produced a broken mockup.
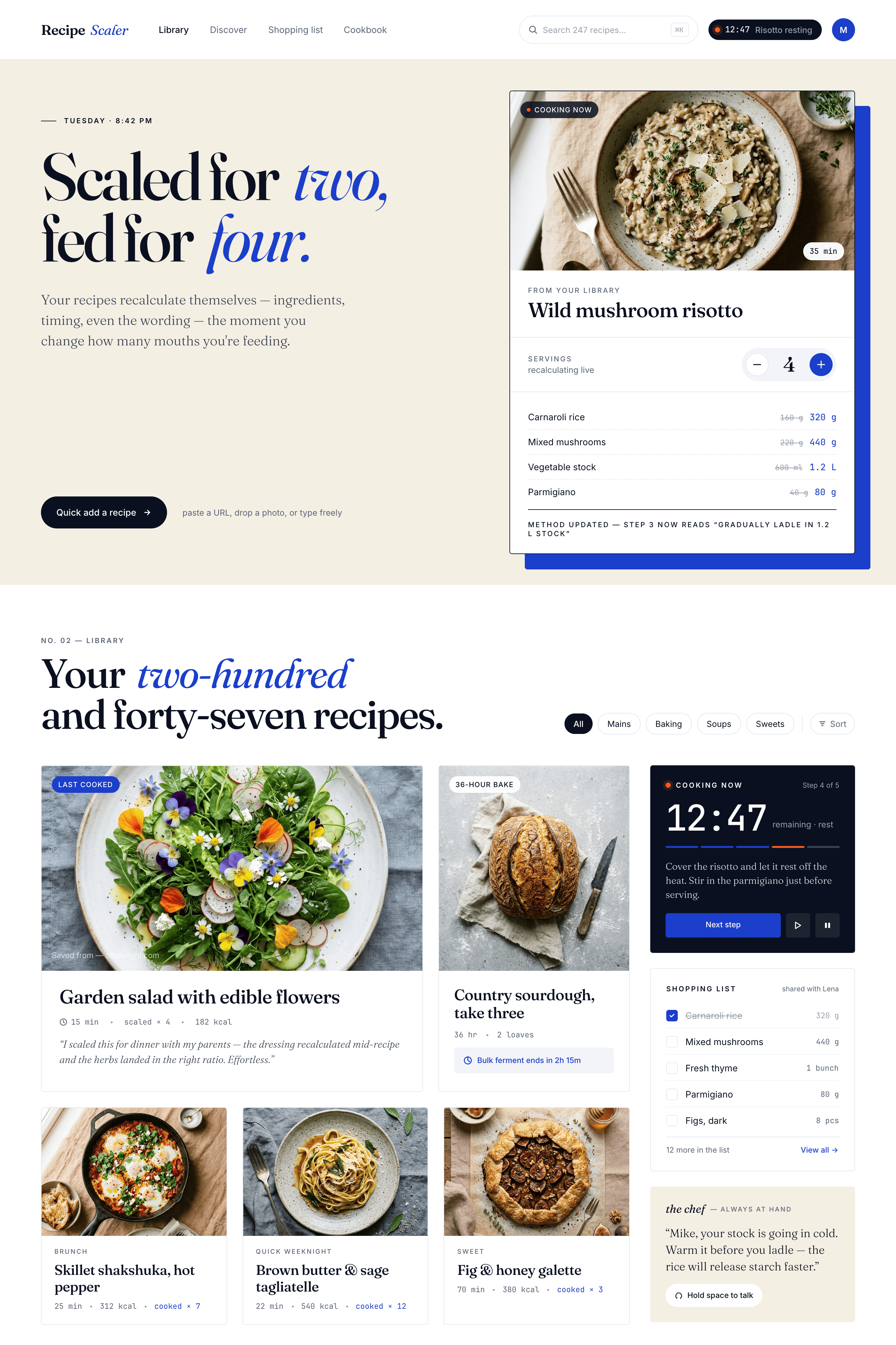
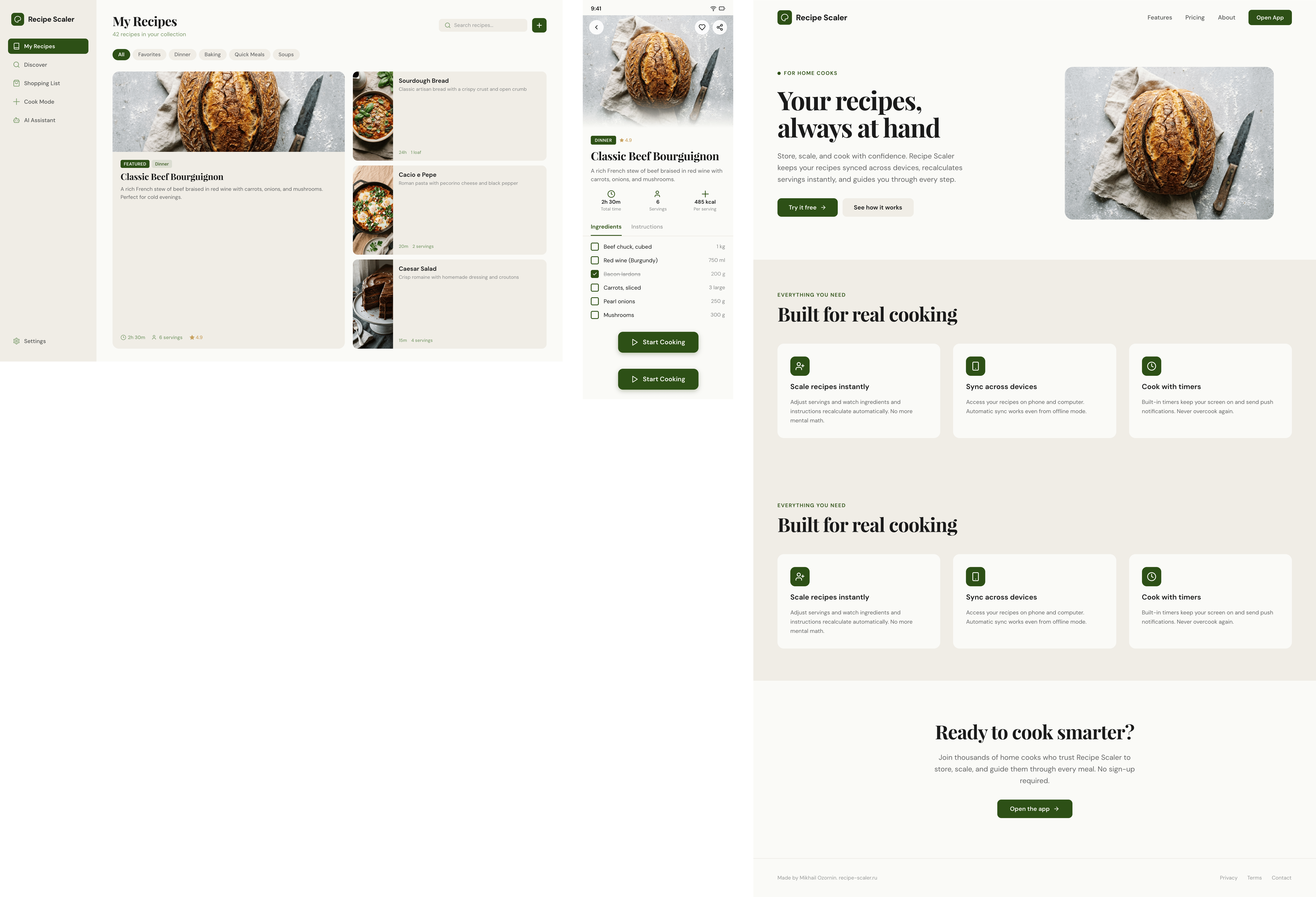
Best result (everything is Opus 4.7 xhigh):


Worst result (Haiku, Qwen 3.5 and one of the DeepSeek iterations)



The rest are somewhere in between. Below there will be a table with the results, but for now I’ll share my impressions.
2.1 Quality of the result
The models split into four categories:
Fancy design from which you can squeeze something interesting
There’s only one such model — Opus 4.7. You can see on every floor and micro-format that it’s showing off. The most interesting and complex promo pages. The only promo pages that aren’t laid out as a stretched mobile screen. Show such a design to a programmer from afar — they’ll think a designer was involved.
Examples of small details from there:
Mid-tier
Desktop and mobile interface are simple but understandable, the promo page is boring (literally like mine right now). You can immediately see it’s neuro-design, but at least it’s neat and clean. At the same time, there are no obvious mess-ups, you can quite use this when there’s no designer at hand. Opus 4.6, Sonnet 4.6, GPT 5.4, Cursor Auto, Qwen 3.6 and, with a stretch, GLM 5.1 (if it can handle the tools).
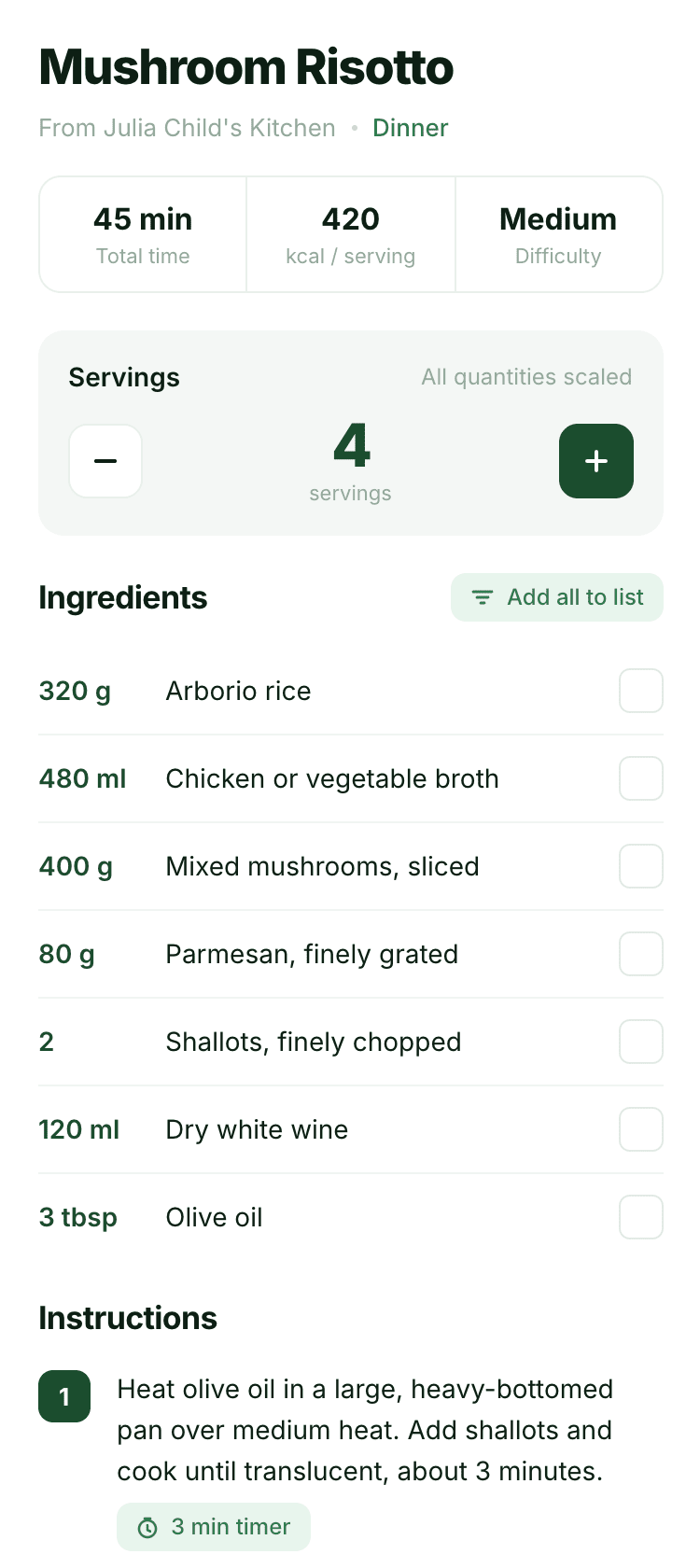
The completely typical neuro-slop design
Neuro-slop in its worst manifestations, most noticeable on the promo page. Literally nothing for your eyes to grab onto. For example, Minimax 2.7, Kimi 2.6 (slightly better, but still here), Cursor’s Composer 2 (a fine-tuned Kimi 2.5) is not far behind. Even the generally not-bad Gemini 3.1 Pro is here. Grok 4.3 also says «hi everyone in this chat».
The models that couldn’t handle the tools
These were Qwen 3.5 39, and in 50% of cases GLM 5.1 with DeepSeek V4 Pro — sometimes they managed, sometimes not. This category includes Anthropic’s Haiku 4.5, and it, by the way, is 1.5x more expensive than GLM 5.1 and 4x more expensive than Minimax 2.7, which performed better than it.


Many couldn’t grasp the concept of a desktop application, some made an editorial site. That would be fine in general for a recipe website, but not for a personal recipe manager app. I didn’t explicitly formulate this, but it’s like you could have guessed from context.
I think it would be inconvenient to use something like this daily. This gets amplified when you add a skill (will be below), there the model gets a serious case of grief from too much thinking.
In the weakest models, typical neuro-slop surfaces: frames on frames, gradients or colored blocks, junk everywhere, emoji, bad hierarchy and rhythm. The feeling that the screens were assembled from things that the better models didn’t need.


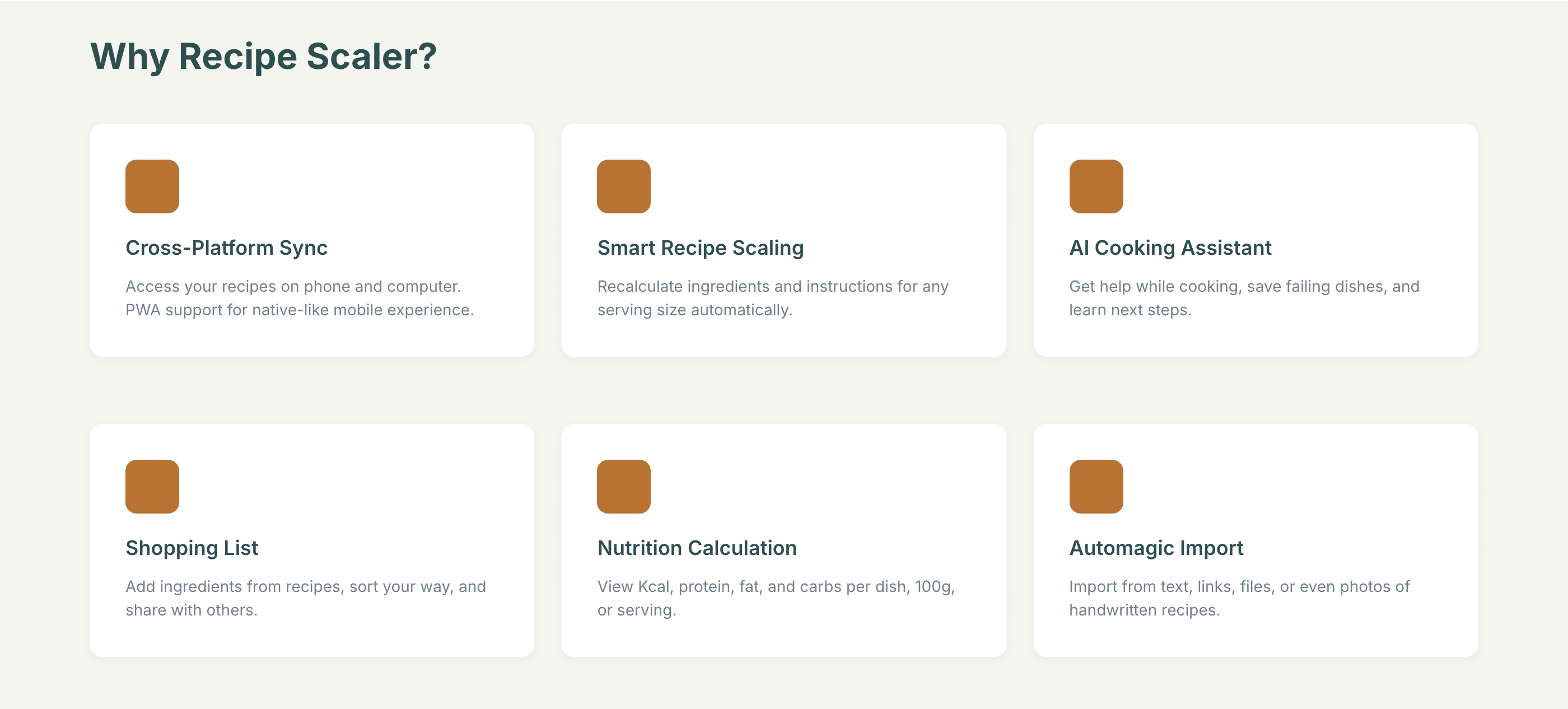
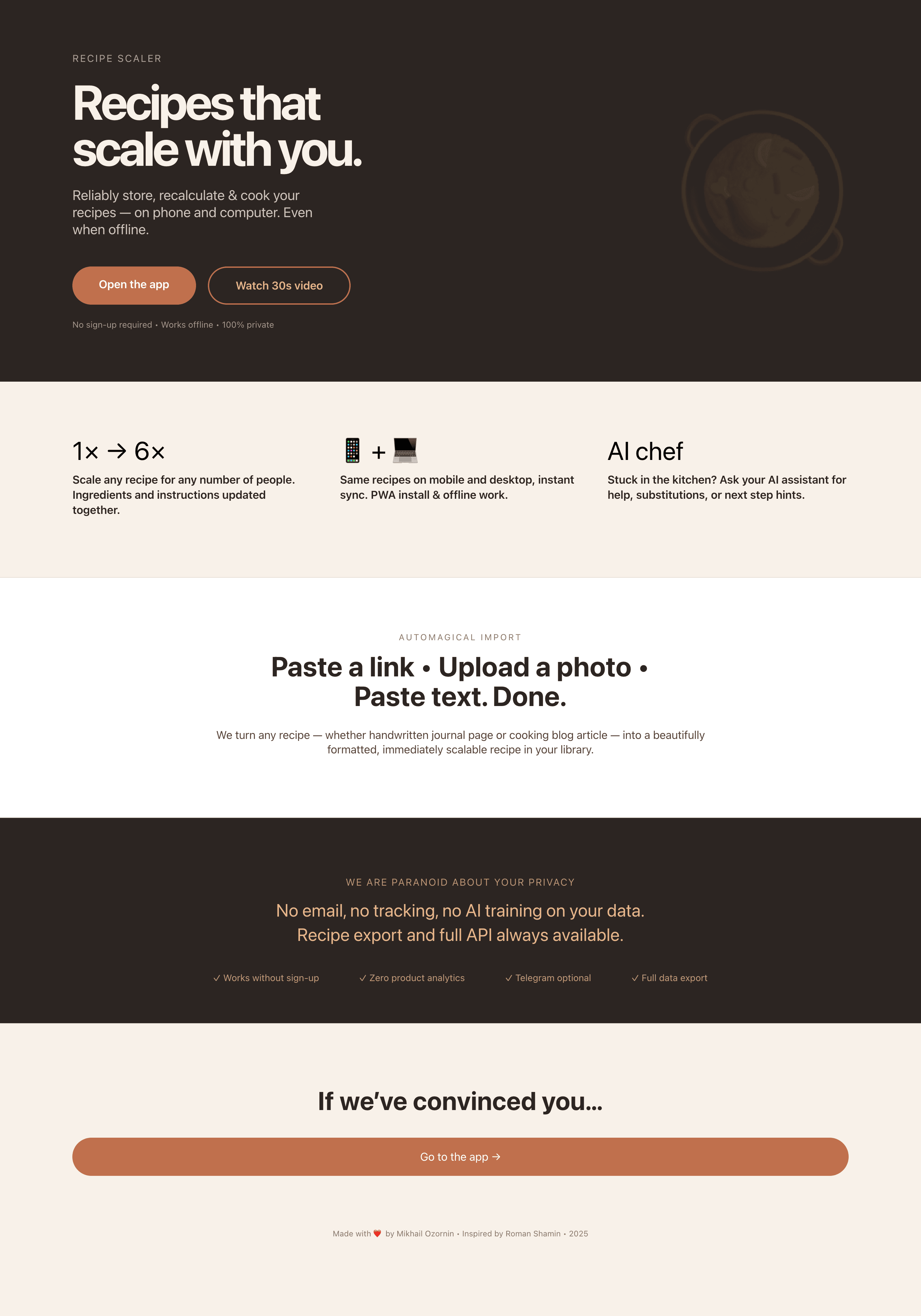
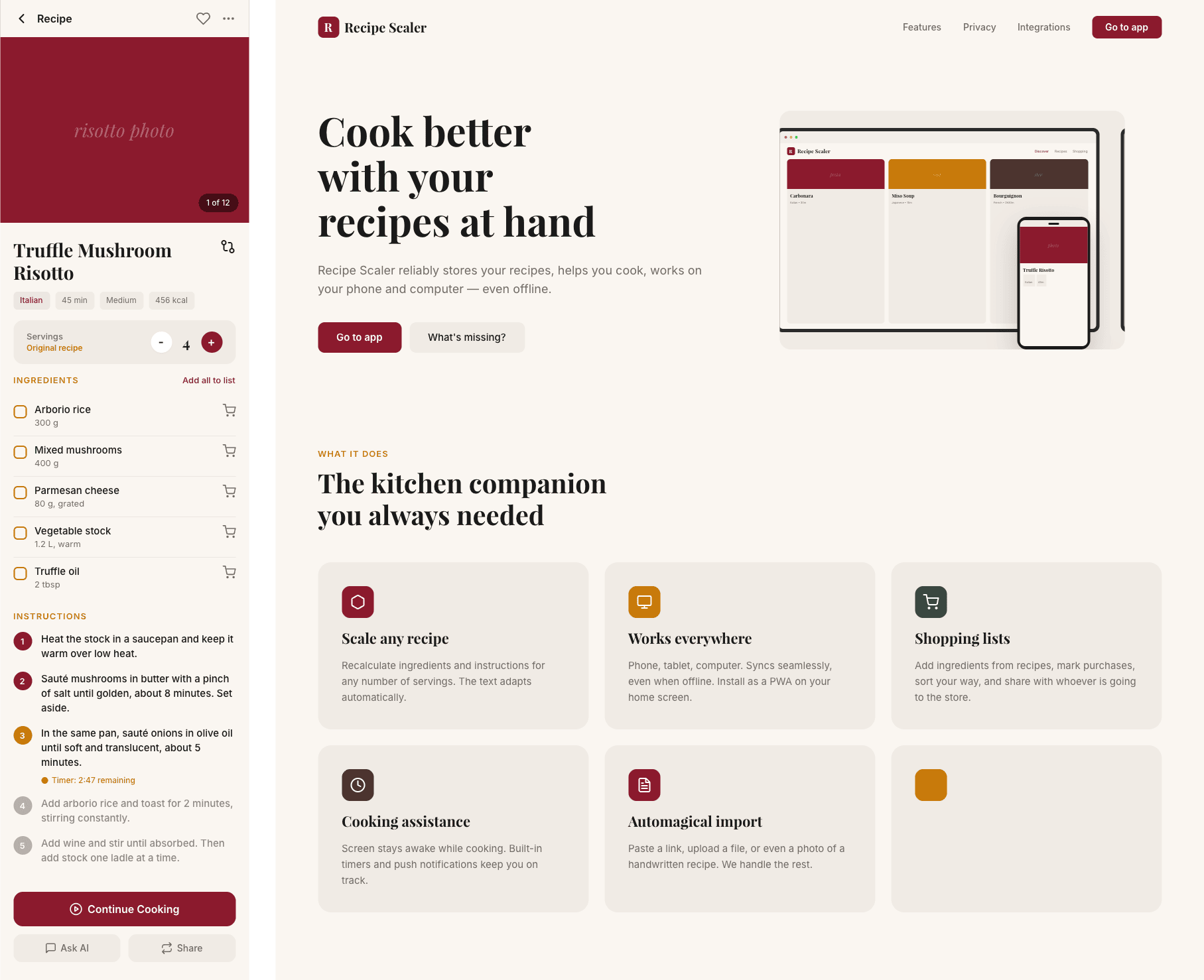
It’s noticeable that everyone does better with the mobile version than with the promo. There the layout is generally simpler, fewer elements, strong limitations (narrow column). As a result — the layout is better, more reliable, more solid. As soon as a wide page appears, many can’t do better than just stretching the mobile layout to width 375 → 1400.
Kimi 2.6 somehow handled the mobile, but couldn’t do anything at a similar level for the promo page. The desktop is also bad.
2.2 Quality of the layout
In Paper all models lay things out roughly the same way — normally, but in Figma GPT laid things out really badly. Everything in one frame, essentially — using absolutes. A human designer wouldn’t get praised on review for this. The same GPT in Paper laid things out normally, apparently Paper’s tools are simpler, better and more understandable.
Figma — everything is laid out in one frame, sizes are random, essentially as if on the web everyone laid things out with absolutes — this is GPT 5.5.
The same GPT 5.5 in Paper — in general everything is clean, the DOM structure is normal, some layers are even well named. A multifold difference.
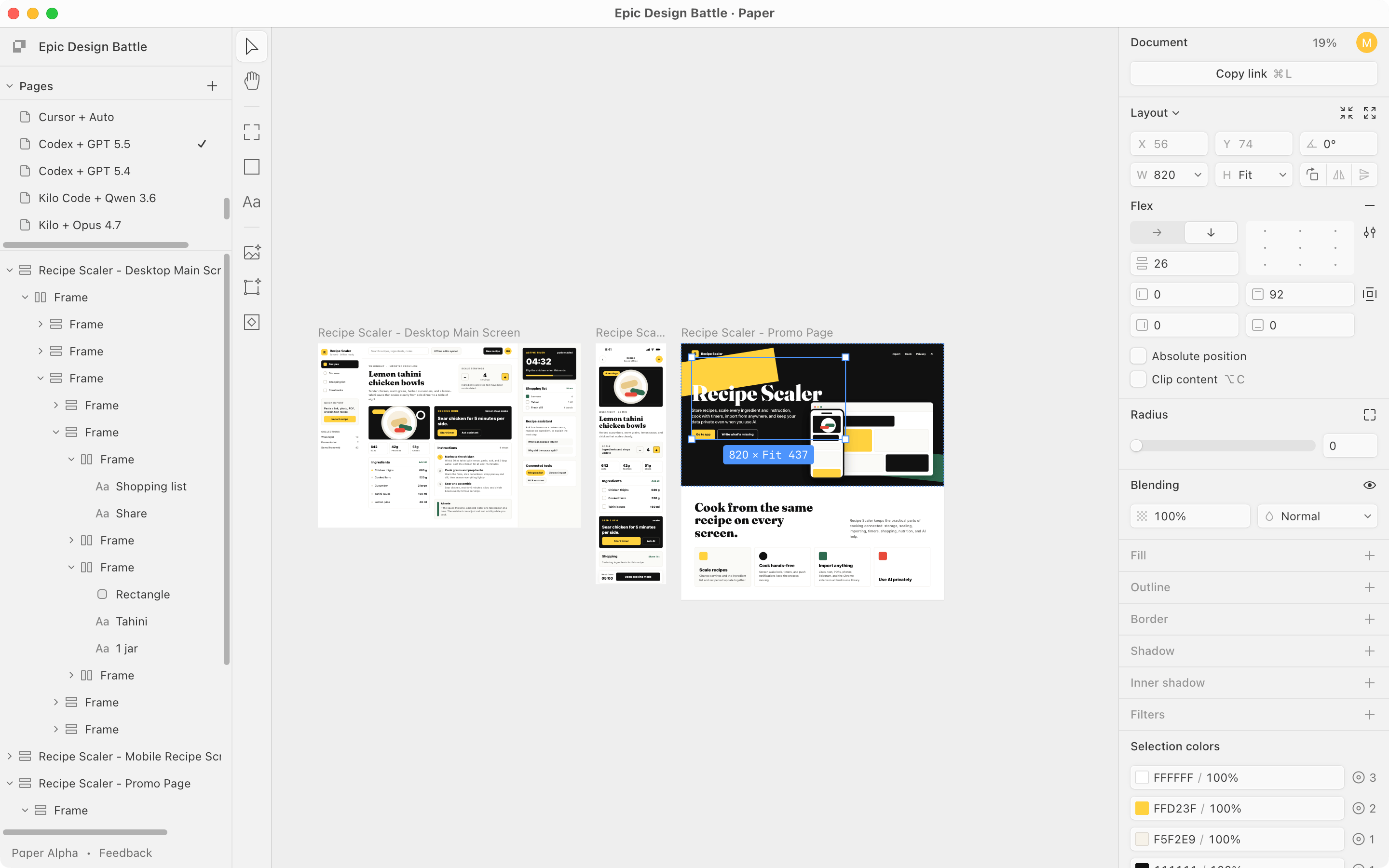
2.3 Thoughts and surprises during the experiment
- It’s amazing how bad GPT models are at design. As development models they’re generally fine and don’t cause rejection, but for design — horror. Moreover, in the one experiment I did, 5.5 turned out to be even worse than 5.4, even though it’s about twice as expensive. The only SOTA model (state of the art) that loses to many weaker ones, including the Chinese.
- Gemini 3.1 performed very badly. Both in Antigravity (their agent, a fork of Windsurf) and in Cursor. And if I can understand Antigravity, it’s very poorly made, but Cursor is a normal agent. Unacceptably bad for a model of this level.
- The agent in general doesn’t fundamentally affect the result, it can’t make an opus-result out of a non-opus model. That is, the result in this simple task is first determined by the model, and only then by the agent. At the same time, there’s still a difference. GPT 5.4 in Cursor showed itself even better than in its native Codex.
- Cursor + Opus 4.7 turned out to be twice as expensive as the same model in Kilo, Cursor was very actively collecting feedback and constantly screenshotting itself. I also like the result more overall. Such a thing should help especially.
- Models have a style. GPT is recognizable across all agents, Opus 4.7 is also recognizable across all of them. By the result I’d assume that Opus 4.7 and Opus 4.6 clearly gravitate to one model, the style is similar. Sonnet has a different style, this is not just a cut-down Opus, these are different models. But Opus gets worse from lowering the reasoning (xhigh → med), but remains the same Opus in style.
- Models that match in token prices don’t match in final price. Formally, GPT 5.5 and Opus 4.7 cost the same (GPT — 30 dollars, Opus 4.7 — 25). But that’s the price per million tokens, and they spend differently. I don’t have 5.5 specifically, but there was GPT 5.4 in Cursor — it has 4.5M tokens, and Opus (also in Cursor) — 15M.
- The difference between the most expensive and cheapest options is 410x. It’s clear that the difference between them in quality is also a lot, maybe even more than 410x.
- Visually Opus’s works are not bad, but they fall apart in the details. Starting from solving the wrong task, the wrong product, ending with layout. From afar it’s beautiful, but as soon as you start looking — you cringe. Probably approximately the same level of cringe that techies have when you bring them vibe-coded code. Almost all variants are easier to throw away than to try to refine.
- Another unpleasant result — my Openrouter account was banned from OpenAI, Claude and Gemini models. I can’t yet say why, trying to figure it out.
3 All the results in one place
Quotas for Claude Code are stated before the recent 2x increase of the five-hour quota. That is, you presumably need to divide by two. I didn’t always note the time or quota, and the quota wasn’t always understandable in general. Where it says tokens — those are both incoming and outgoing tokens, including cache, which is why so many.
The full results table is below.
3.1 Paper MCP
| Agent | Model + parameters | Time | Tokens | Cost | Comment |
| Antigravity | Gemini 3.1 Pro, high | 15 min | — | — | Very bad at using tools, monstrous integration into the tool |
| Antigravity | Gemini 3.5 Flash | — | — | — | Noticeably better than Gemini 3.1 Pro (but improving from its level is not hard). The only one who decided to do a dark mode. |
| Claude Code | Opus 4.7, xhigh | 10—15 min | — | 75%+ of pro · 5h quota | Quick. Expensive. Awesome. |
| Claude Code | Opus 4.8, xhigh | — | — | 53% of pro · 5h quota (already doubled) | Burns more; not necessarily better than 4.7. Three screens used half of the already-doubled 5h pro quota. |
| Claude Code | Opus 4.7, med | 5—10 min | — | 56% of pro · 5h quota | Keeps the Opus 4.7 style, simplifies the implementation |
| Claude Code | Opus 4.6, Max reasoning | — | — | 37% of pro · 5h quota | In general looks like a simplified Opus 4.7, much closer to Sonnet in overall layout |
| Claude Code | Sonnet 4.5, xhigh | 8 min | — | 25% of pro · 5h quota | Substantially closer to the Chinese models and the simpler ones. Neat, but completely neutral, completely simplified |
| Claude Code | Haiku 4.5 | 3 min | — | 6% of pro · 5h quota | Didn’t even cope with the tools. There’s not a single reason to use it |
| Codex | GPT 5.5, xhigh | 15 min | — | 26% of plus · 5h quota | Very cheap compared to opus, the result is accordingly. The worst result among SOTA models (state of the art, that is) |
| Codex | GPT 5.4, xhigh | 15 min | — | 17% of plus · 5h quota | Surprisingly, I like this variant even more than GPT 5.5 |
| Cursor | Auto | 25 min | 13.7M | $4.33 | A surprisingly good result for Auto mode. I don’t know who was doing it, maybe Opus on low-reasoning was doing the overall task, and the implementation was some GPT-nano. The style choice is like from Opus |
| Cursor | Opus 4.7 | 35 min | 15M | $12.30 | Twice as expensive as Opus 4.7 at Kilo. Checks itself a lot, screenshotted literally every stage and every block. The result is slightly better |
| Cursor | GPT 5.4, xhigh | 11 min | 4.5M | $2.20 | The agent is different, the model is recognizable, it’s the same GPT 5.4 that was in Codex. But here it turned out slightly better. |
| Cursor | Gemini 3.1 Pro | 8 min | 3.4M | $2.01 | Result comparable to Gemini in Antigravity. Very bad for a model of this level. |
| Cursor | Grok 4.3 | ~18 min | 3M | $1.65 | Mixed impressions from Grok. Mobile is generally fine, on the level of others. Promo is worse than ones to collect. I thought it’d be cheaper, Grok 4.1 was very cool precisely because it cost very little. |
| Cursor | GLM 5.1 (z.ai coding plan) | ~7 min | — | 37% of lite · 5h quota | GLM in Cursor for some reason couldn’t cope with the tools |
| Cursor | Composer 2 | 5 min | 1.3M | $0.33 | Very primitive, but also very cheap. Doesn’t match the level Cursor claims for its model, of course. But they honestly said they’re making a model for code first |
| Cursor | Composer 2.5 | — | 1.6M | $0.21 | Comparable in cost to Composer 2, quality has grown, but still very not great |
| Cursor | MiMo V2.5 Pro | — | 4.8M | 4.8M of 4.1B included tokens | Included Cursor model; very cheap in subscription terms, weak on design |
| Source Craft | Default | 7 min | — | 65 units of 4500 quota | Seems inexpensive, but no point in using it, neuro-slop neuro-slop |
| Source Craft | Default Thinking | 10 min | — | 74 units of 4500 quota | It’s like Default and Default Thinking models in Yandex Source Craft are not just different modes of one model, but different models: too different a result, with the reasoning model even worse. |
| Kilo Code | Opus 4.7 (Kilo cloud) | 27 min | 6.3M | $6.96 | Typical Opus 4.7. Clean in places, interesting, from afar it’s super-duper |
| Kilo Code | Hy3 preview (Kilo cloud) | — | 1.6M | $0.06 | The trendiest open-source model on Openrouter. Very so-so. |
| Kilo Code | Qwen 3.6 Max Preview (Kilo cloud) | 17 min | 2.2M | $0.42 | In general Qwen did decently for me. A bit dim, but pretty solid. Sagged in promo like everyone. 1/30 of Opus’s price. |
| Kilo Code | Qwen 3.5 397 | 6 min | — | — | Didn’t cope with the tools |
| Kilo Code | Grok Build 0.1 + Google Skill | — | — | $0.83 | Same prompt with Google’s design skill attached; compare with OpenCode Grok Build 0.1 without a skill |
| OpenCode | Opus 4.7, xhigh reasoning (OpenRouter) | — | 2.7M | $2.74 | Not bad, what would have been in mobile I don’t know because after this screen Openrouter banned me from American SOTA models |
| OpenCode | Kimi 2.6 (OpenRouter) | 42 min | 3.62M | $1.78 | Mobile is better than the rest, the rest is bad. The funny thing is everything was duplicated, but then through screenshots it discovered and erased it itself. Because of this it fussed for a very long time — 40+ minutes. |
| OpenCode | Grok 4.3 (OpenRouter) | — | 1.57M | $1.09 | Grok was already above, but unlike Cursor, Opencode couldn’t handle the model at all, the result is much worse than Cursor’s |
| OpenCode | Grok Build 0.1 (OpenRouter) | — | 3.7M | $1.24 | Fast, weak, expensive for this quality |
| OpenCode | DeepSeek V4 Pro (Deepseek Cloud), Max Reasoning | — | 4.1M | $0.09 | DeepSeek is very cheap, but managed only once. Mobile is watchable, the rest is bad |
| OpenCode | DeepSeek V4 Pro (Deepseek Cloud), Max Reasoning | — | 2.5M | $0.05 | DeepSeek is very cheap, but managed only once. Mobile is watchable, the rest is bad |
| OpenCode | GLM 5.1 (z.ai coding plan) | — | — | — | Unlike Cursor, Opencode managed to get something out of GLM, turned out generally OK for its price. It costs less than Haiku, which couldn’t do literally anything |
| OpenCode | Qwen 3.5 397 | — | — | — | Couldn’t do anything |
| OpenCode | MiniMax 2.7 (OpenRouter) | 3 min | 242K | $0.03 | Incredibly fast, incredibly cheap, the quality is accordingly |
| OpenCode | Qwen 3.7 | — | 3.13M | $7.95 | Expensive for its result, no improvement over 3.6 Max. Very bad at using tools (possibly an Opencode issue) |
3.2 Figma MCP
| Agent | Model + parameters | Time | Tokens | Cost | Comment |
| Claude Code | Opus 4.7, xhigh | ~19 min | — | 121% of pro · 5h quota | Opus in its style, especially from afar, but ate more than a full 5-hour quota |
| Codex | GPT 5.5, xhigh | 20 min | — | 16% of plus · 5h quota | In Figma it managed slightly better than in Paper. Lays things out monstrously simply |
| Cursor | GLM 5.1 (z.ai coding plan) | 25 min | — | 13% of lite · 5h quota | In general worse than in Paper. The desktop layout on the bottom is me dragging a layer to where it needs to go, GLM didn’t master a correct DOM |
| Cursor | Composer 2 | 6 min | 1.4M | $0.43 | Catastrophically bad, worse than in Paper |
Full list of all the images
Paper MCP
Antigravity + Gemini 3.1 Pro, high
Very bad at using tools, monstrous integration into the tool.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Antigravity + Gemini 3.5 Flash
Noticeably better than Gemini 3.1 Pro (but improving from its level is not hard). The only one who decided to do a dark mode.
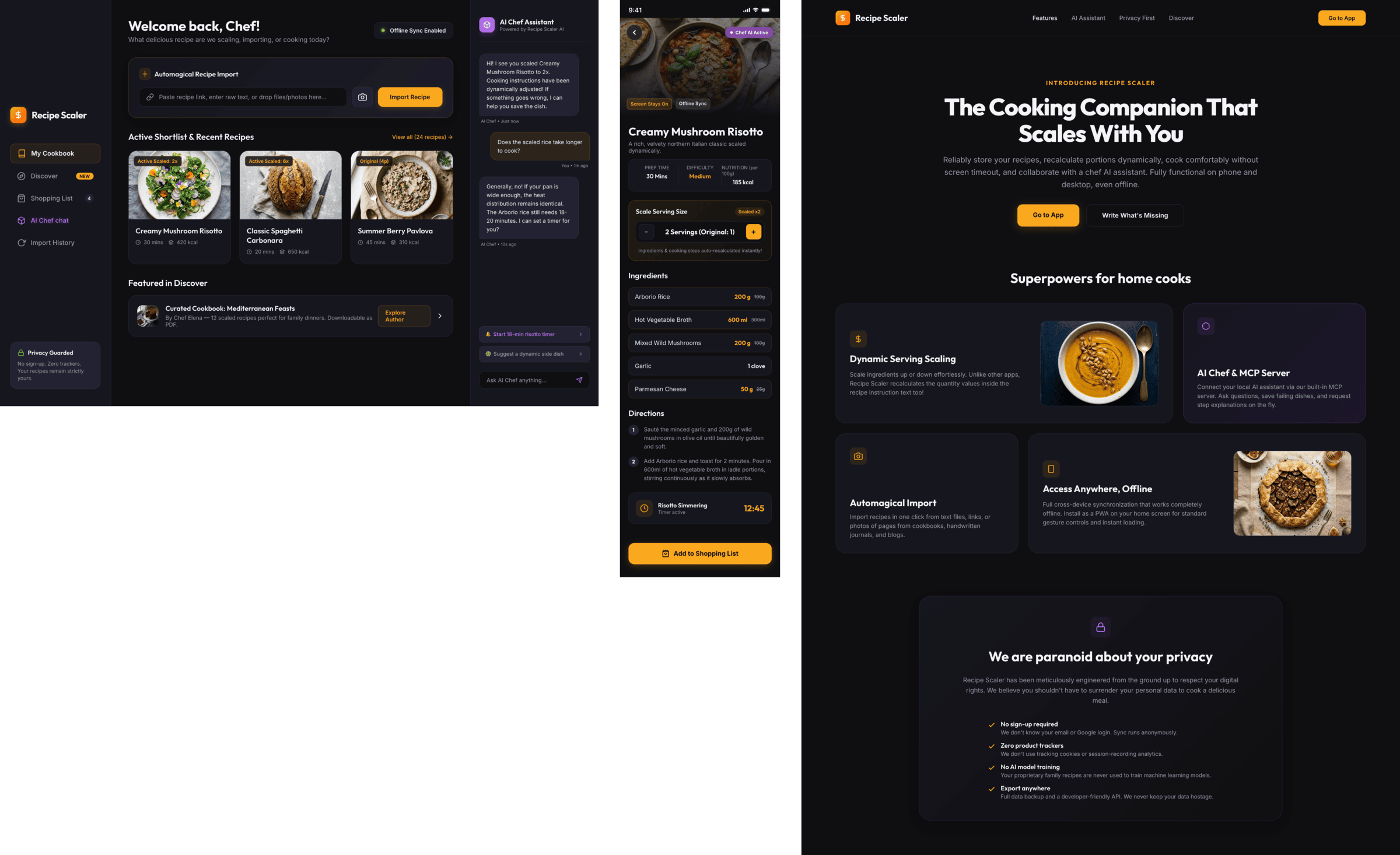
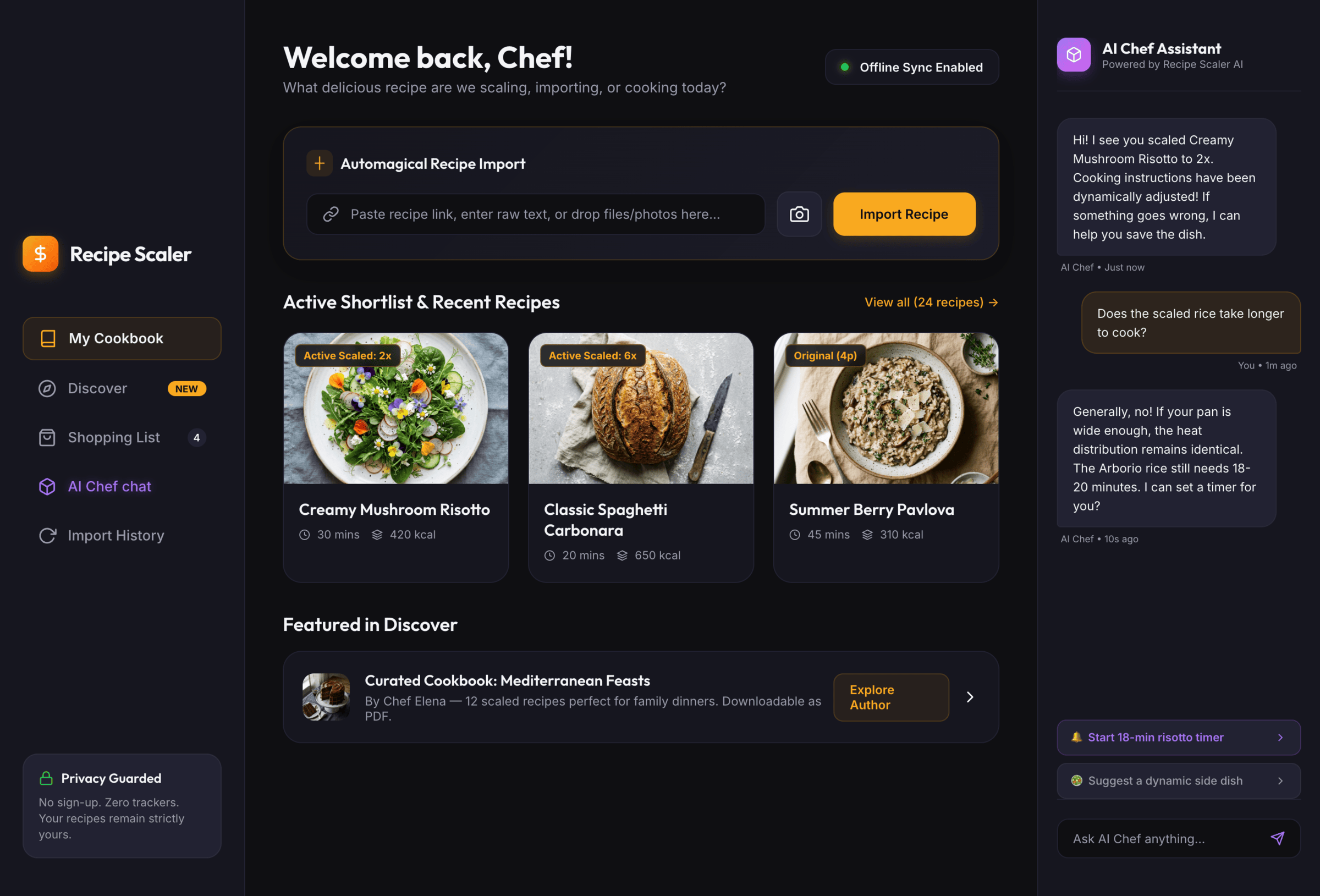
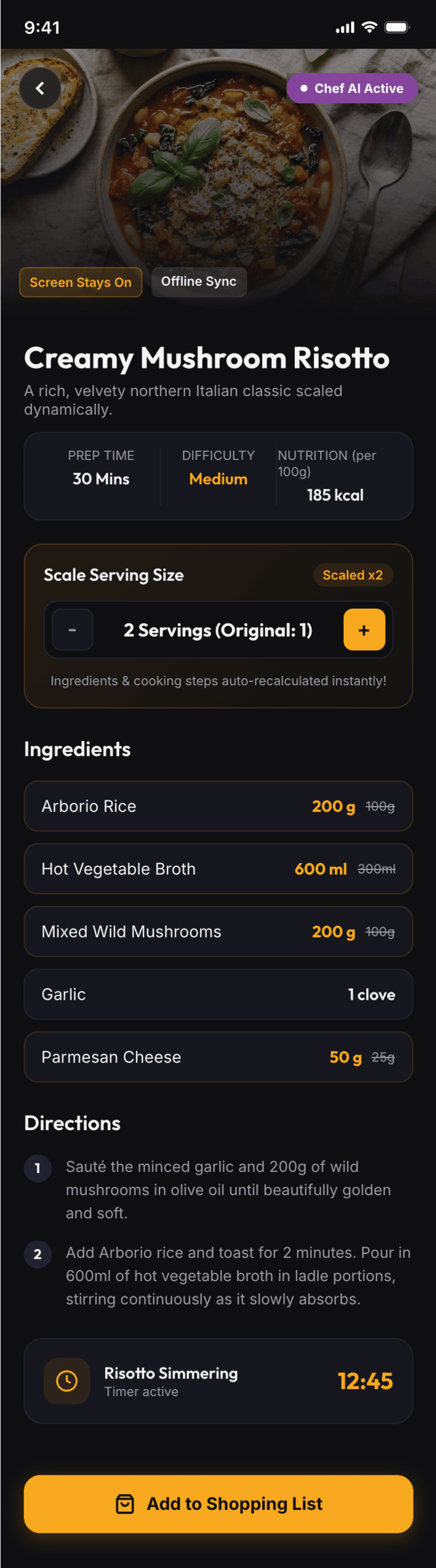
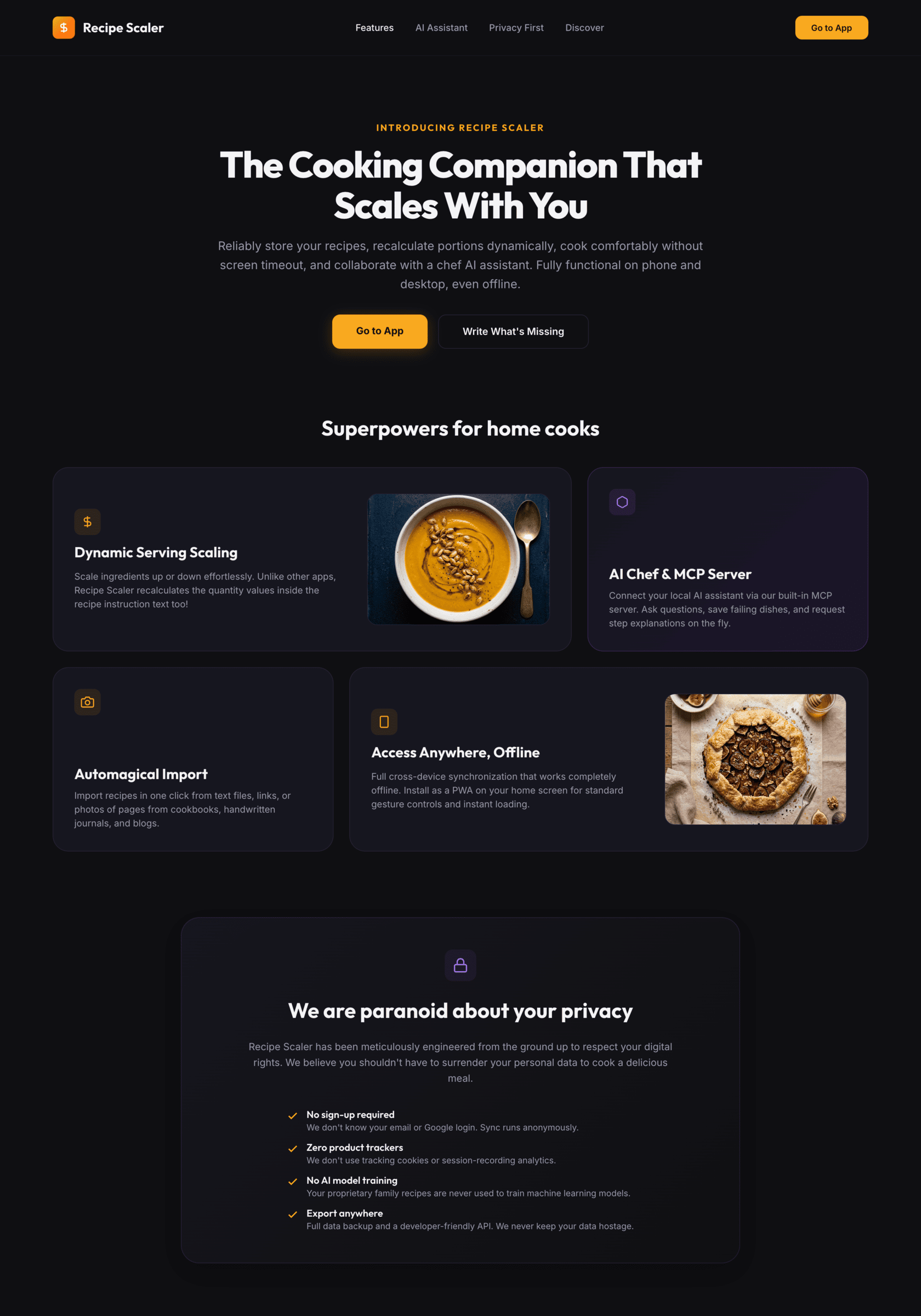
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Claude Code + Opus 4.7, xhigh
Quick. Expensive. Awesome.
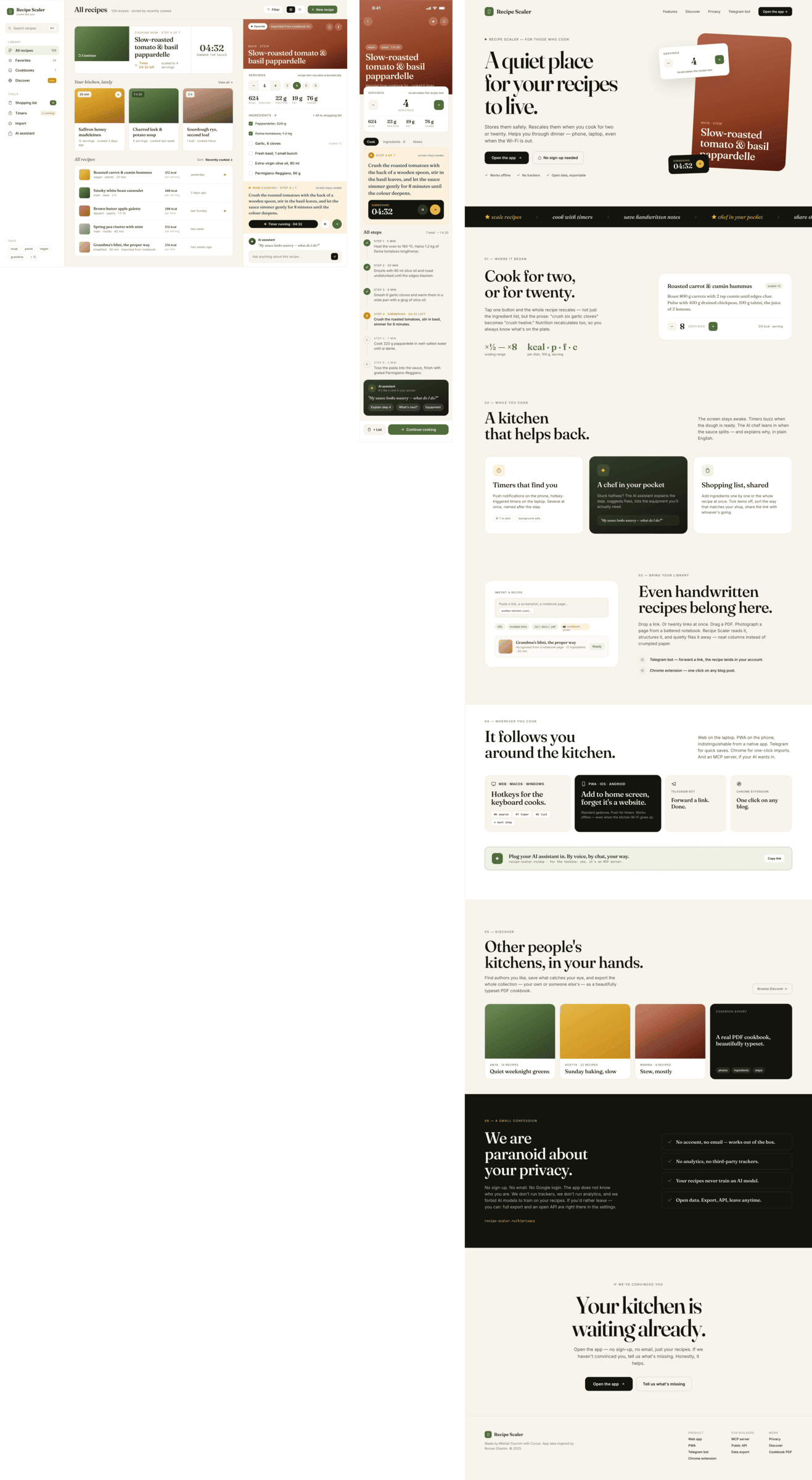
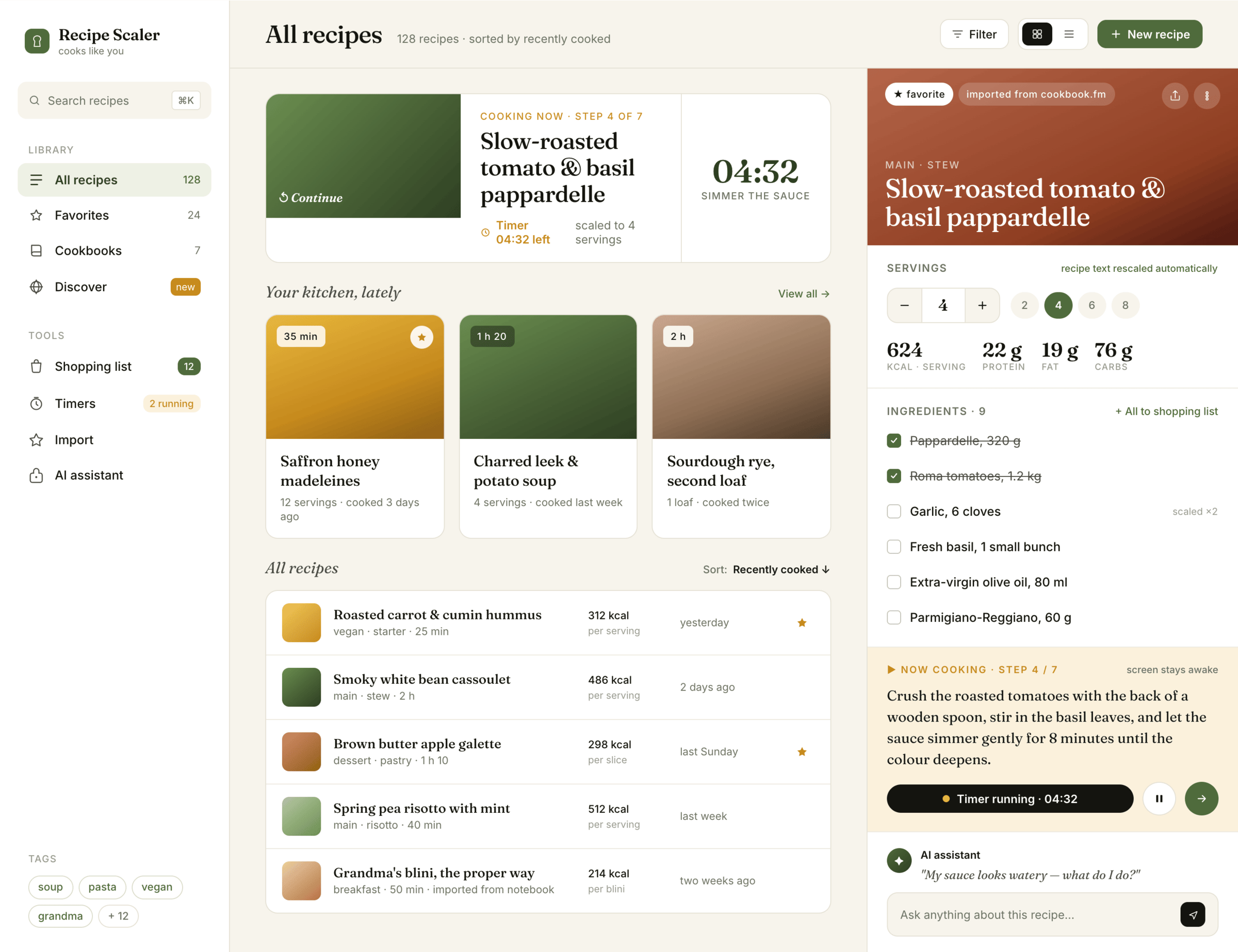
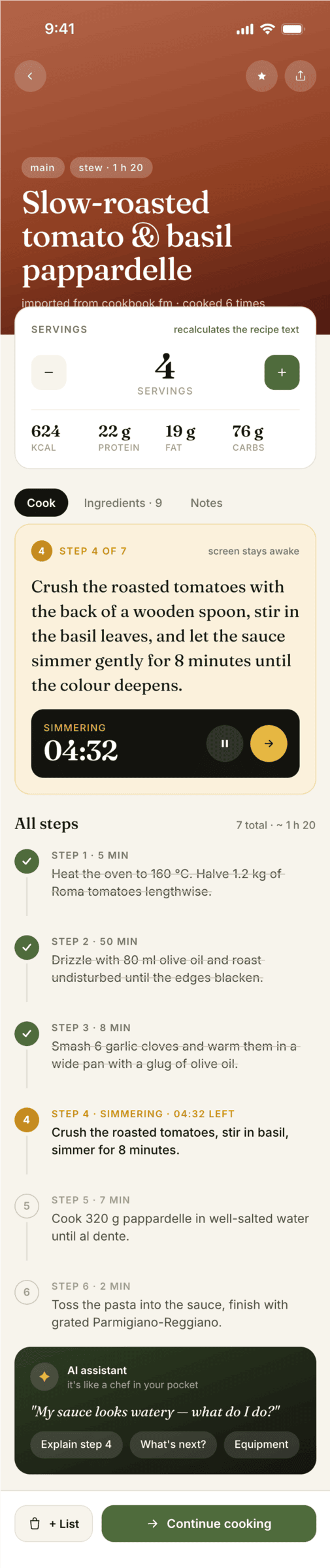
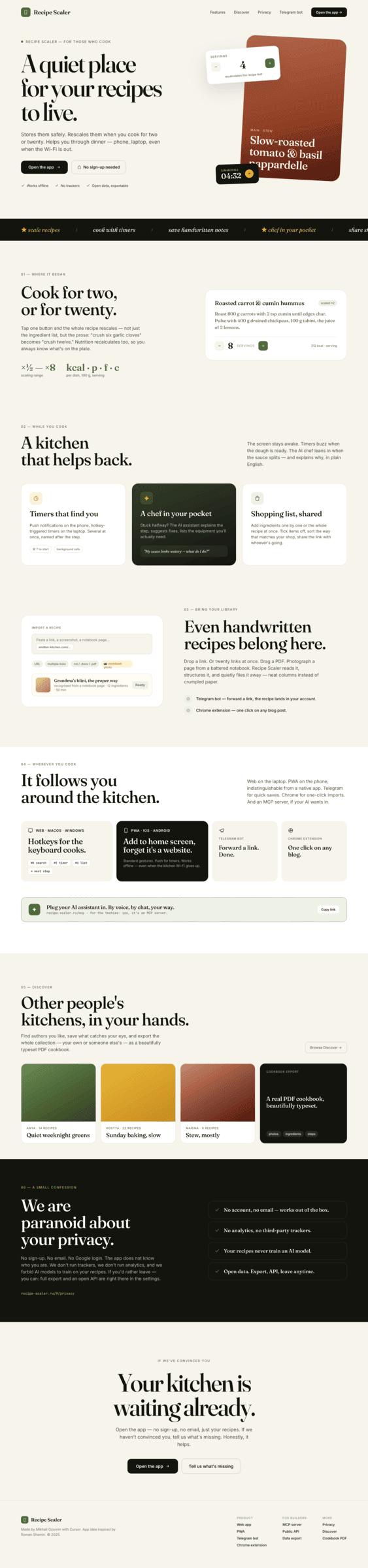
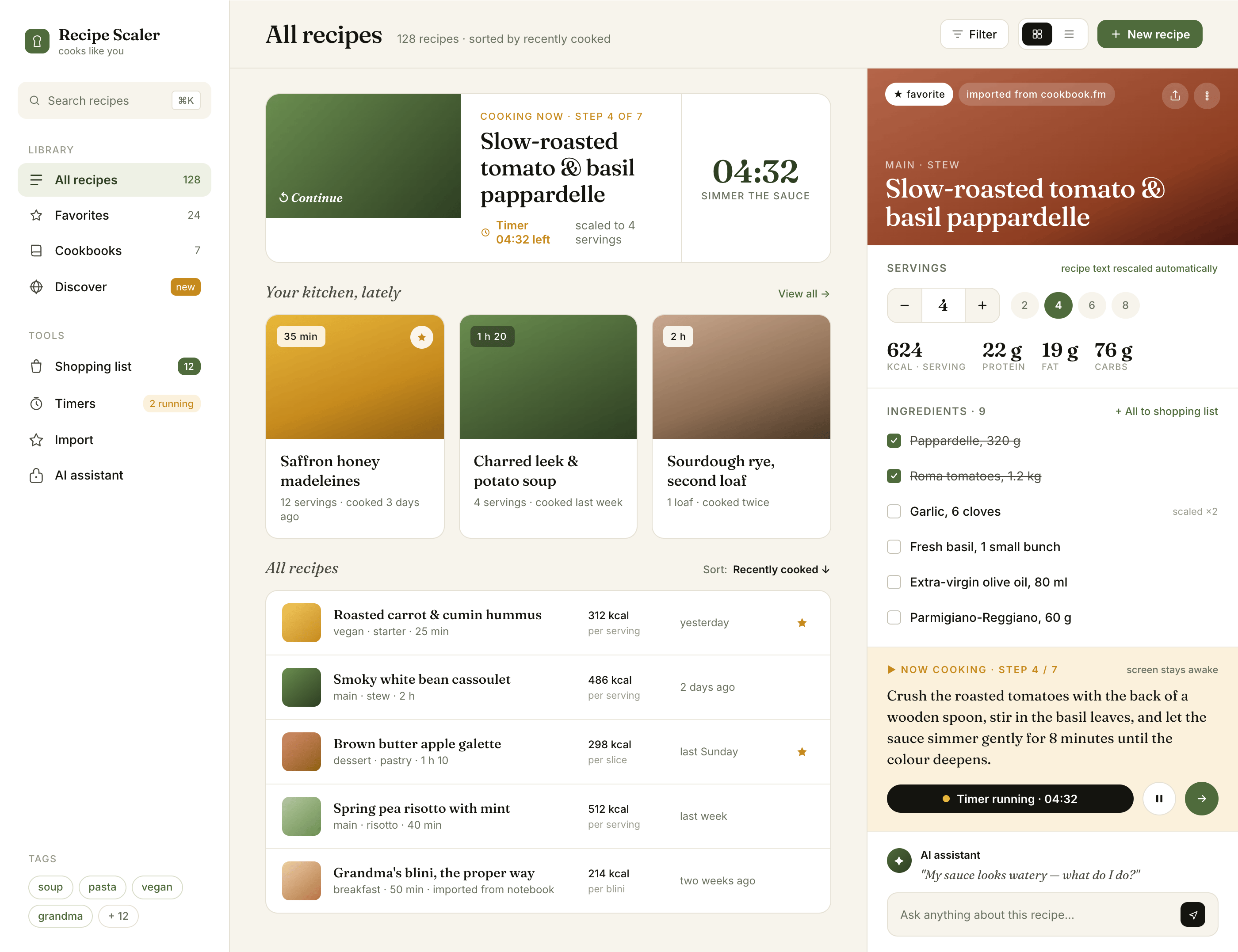{kind=link}
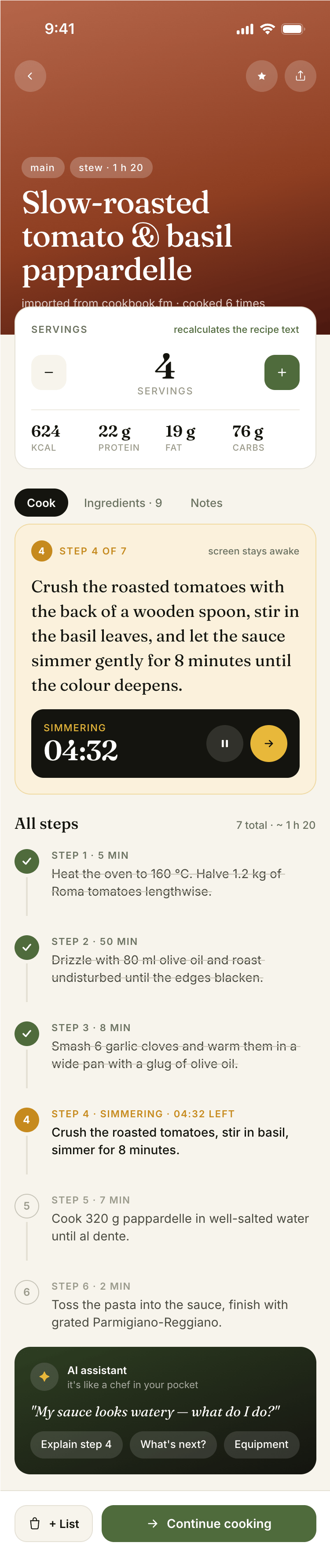{kind=link}
{kind=link}
Claude Code + Opus 4.8, xhigh
Still Opus-level; half the already-doubled 5h pro quota on a full three-screen run.
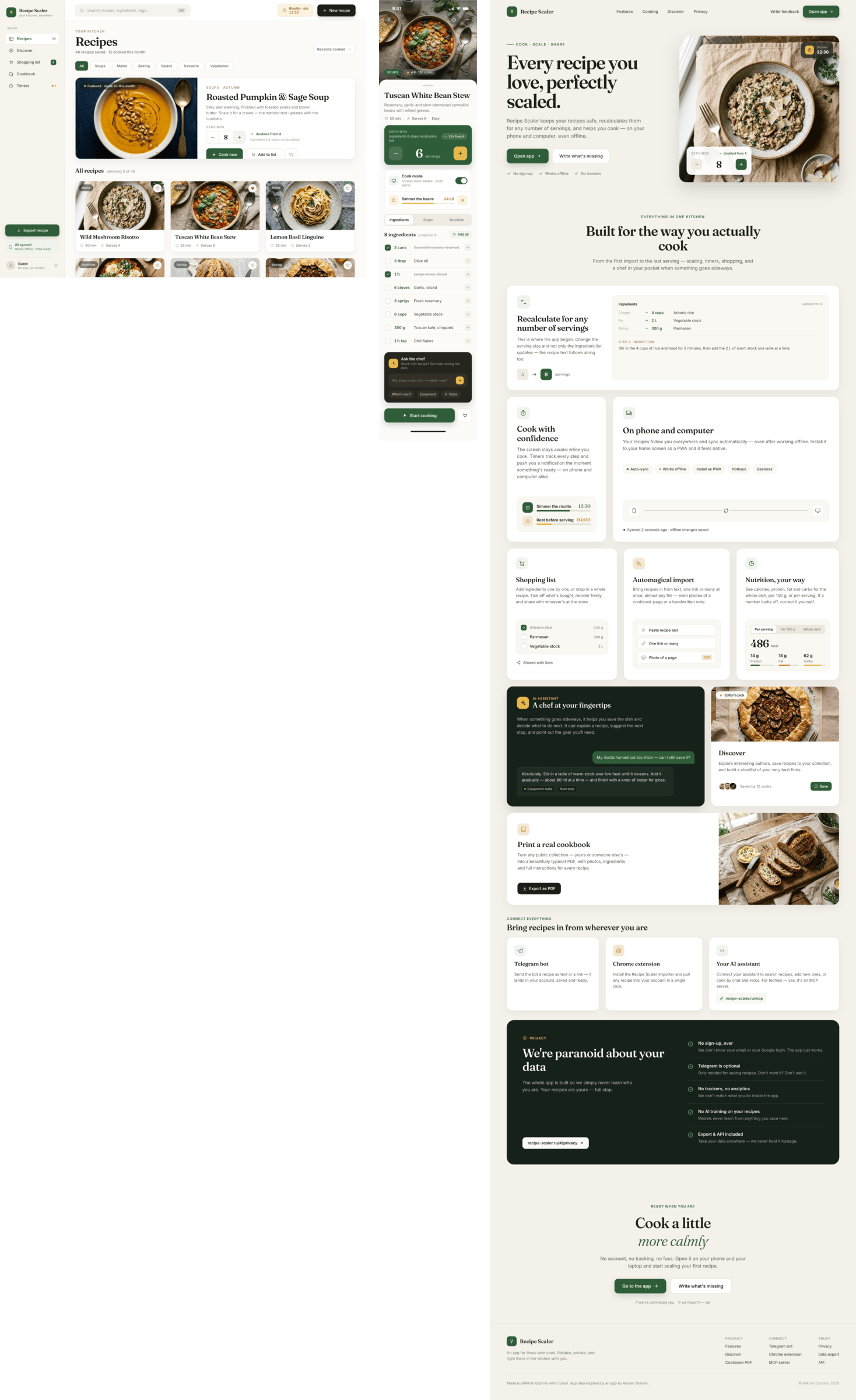
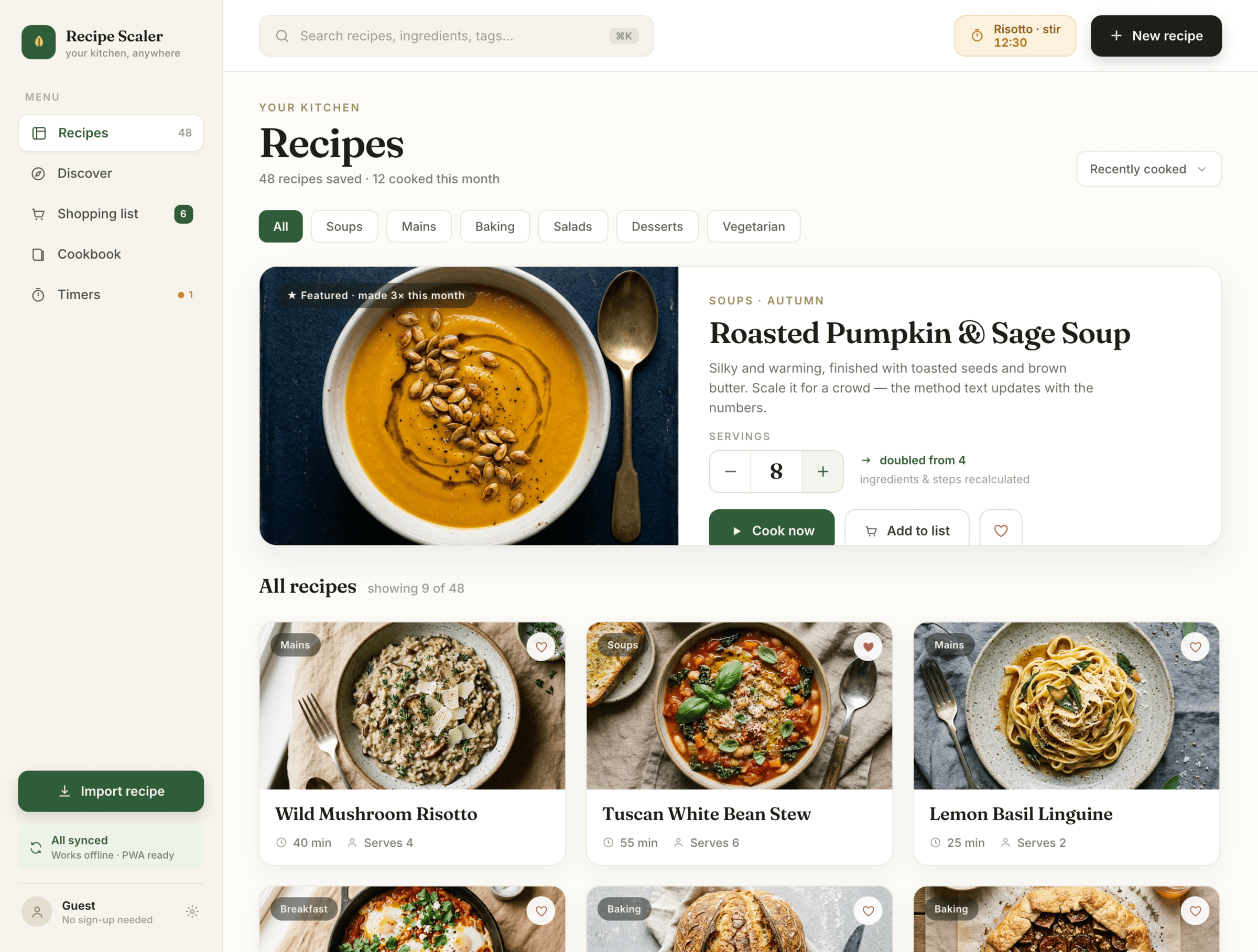
{kind=link}
{kind=link}
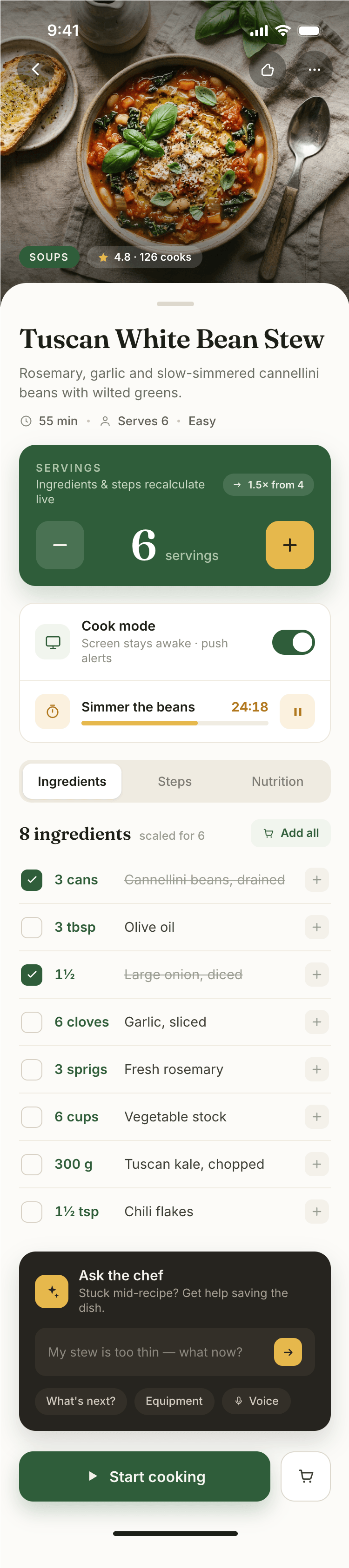{kind=link}
{kind=link}
Claude Code + Opus 4.7, med
Keeps the Opus 4.7 style, simplifies the implementation.
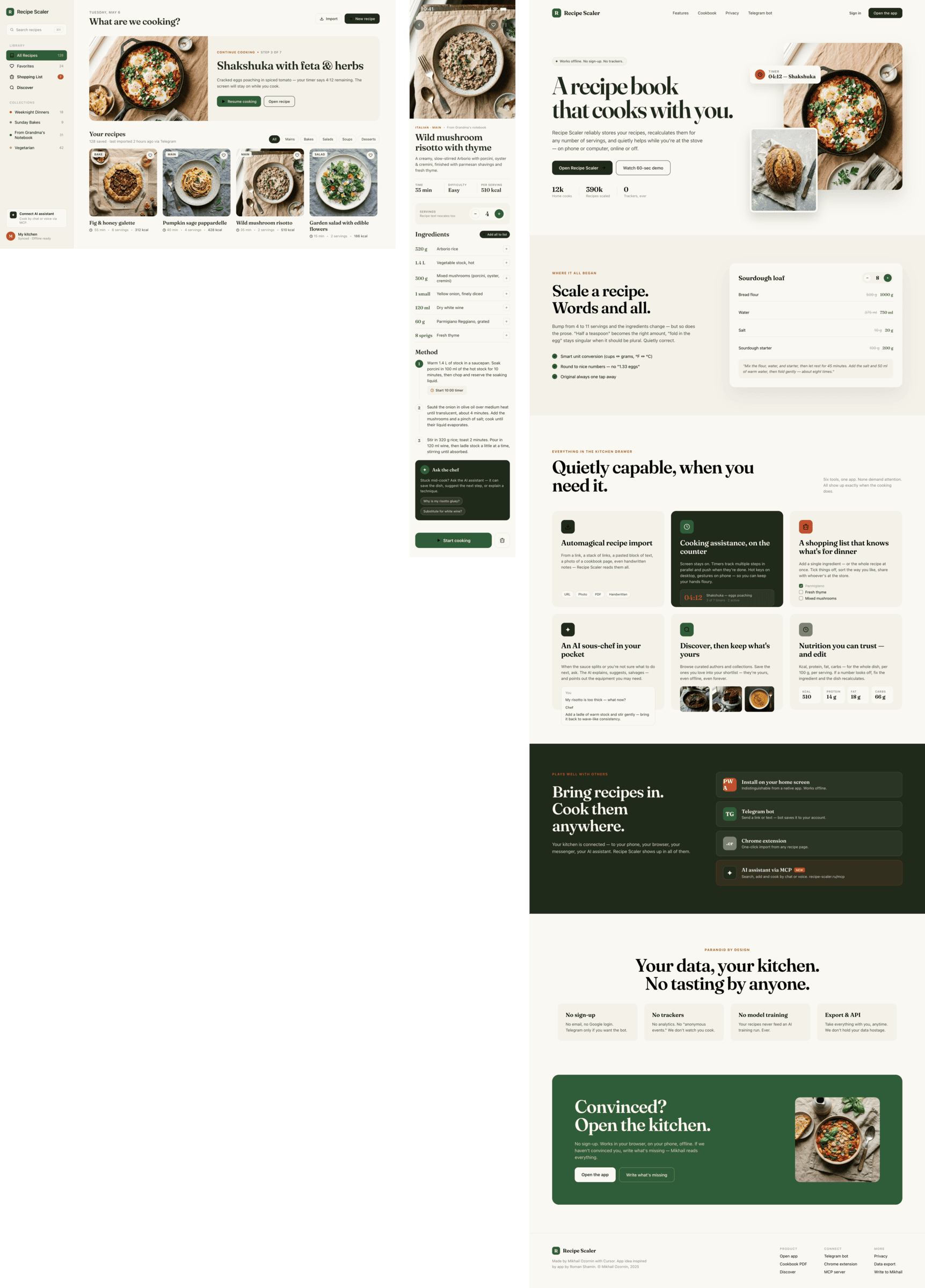
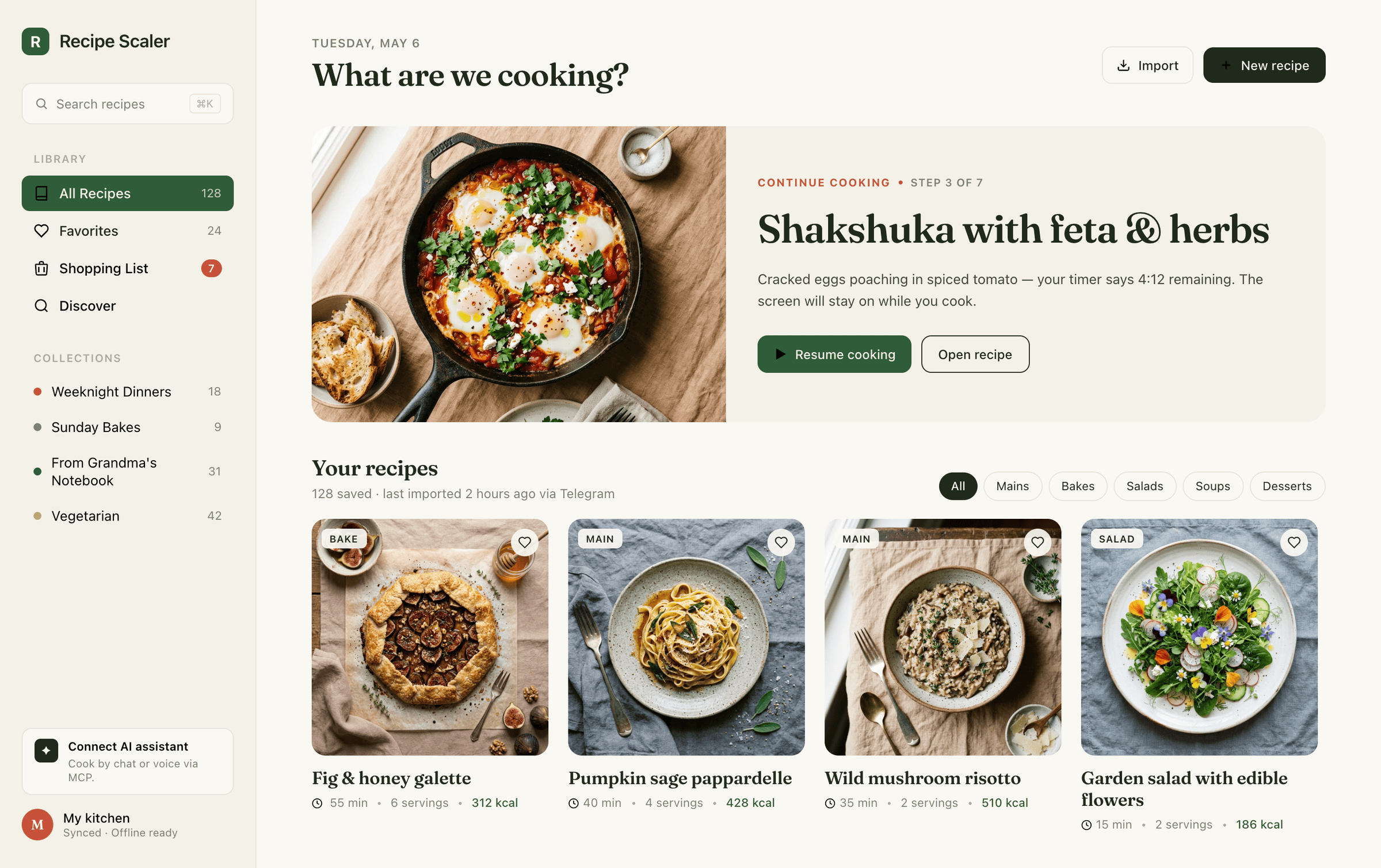

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Claude Code + Opus 4.6, max
In general looks like a simplified Opus 4.7, much closer to Sonnet in overall layout.
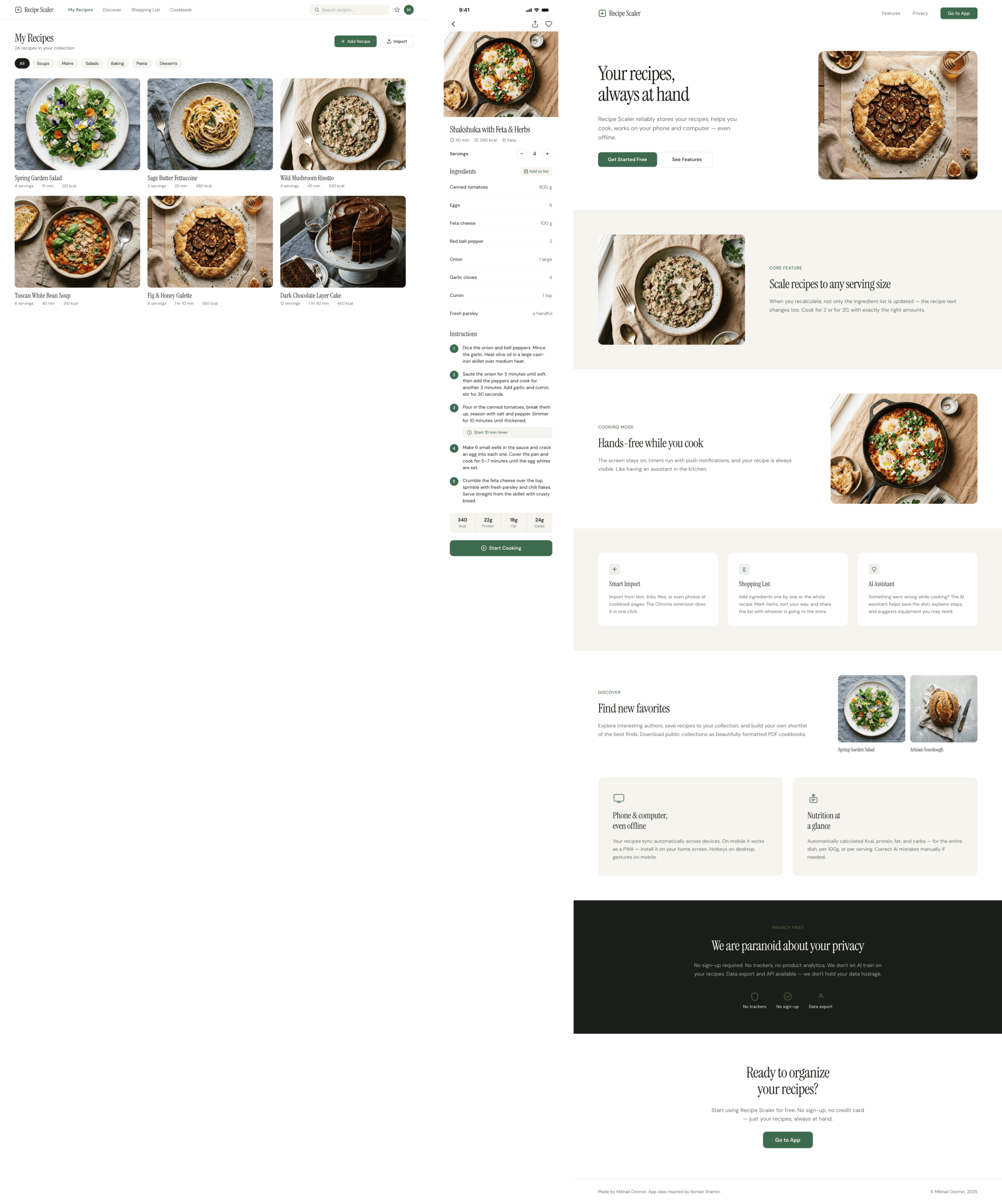
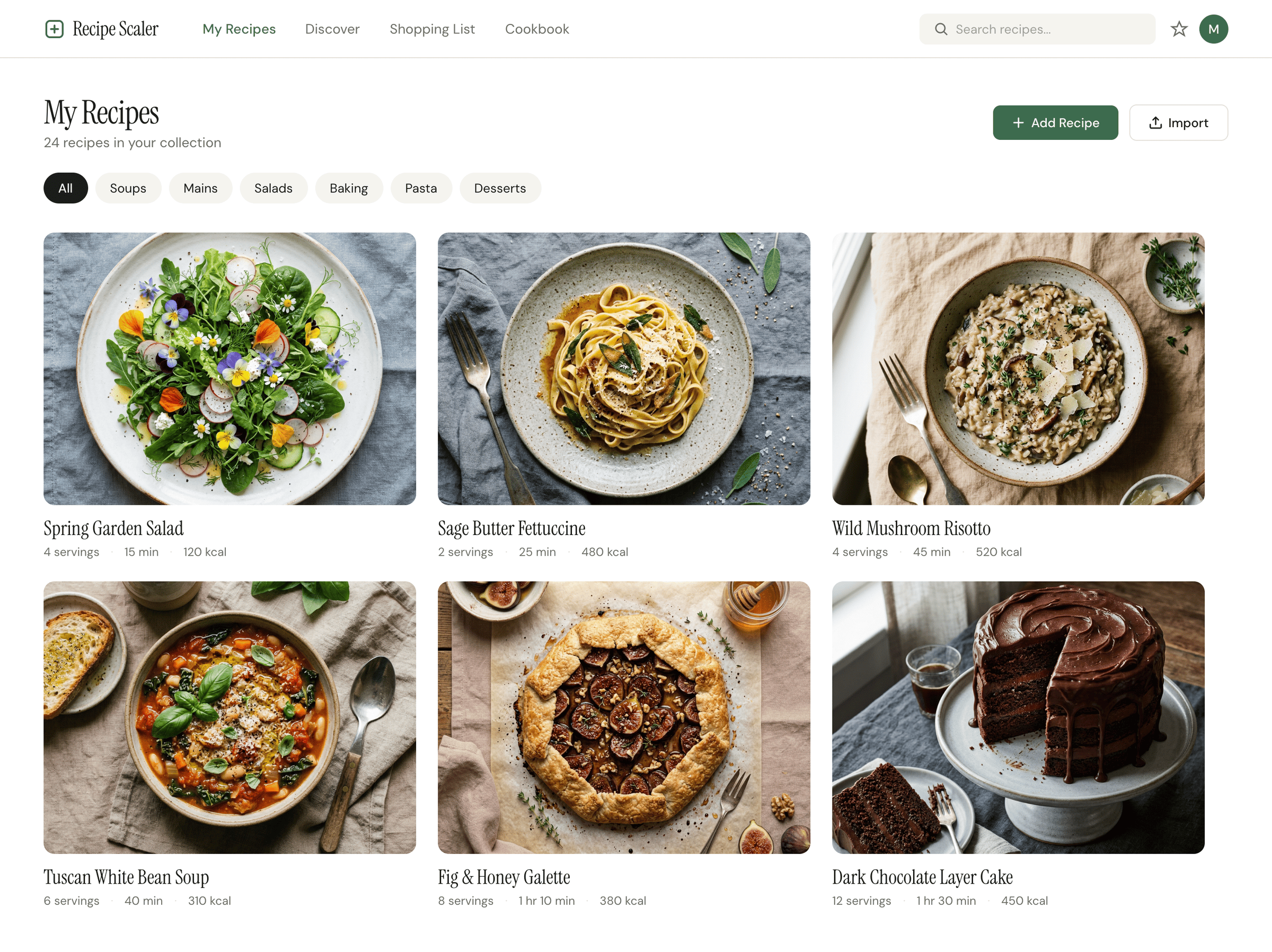
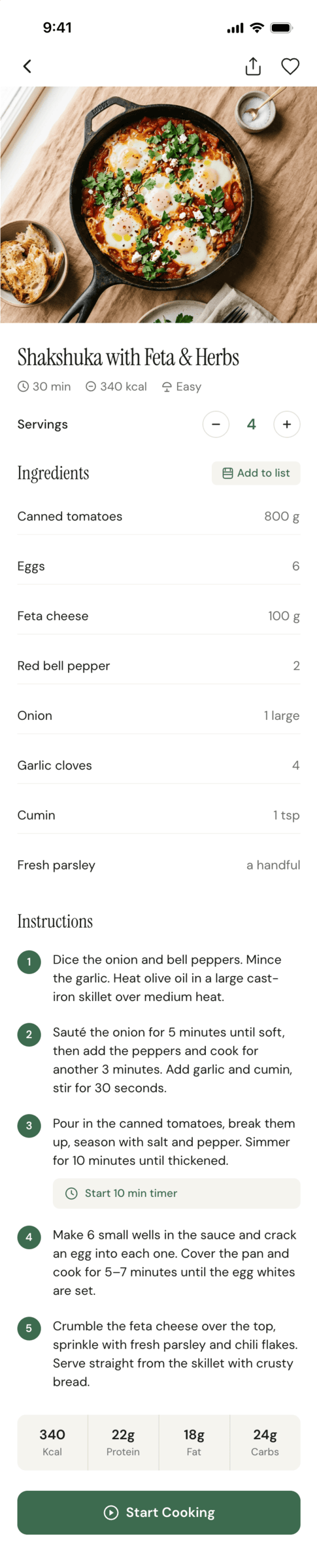
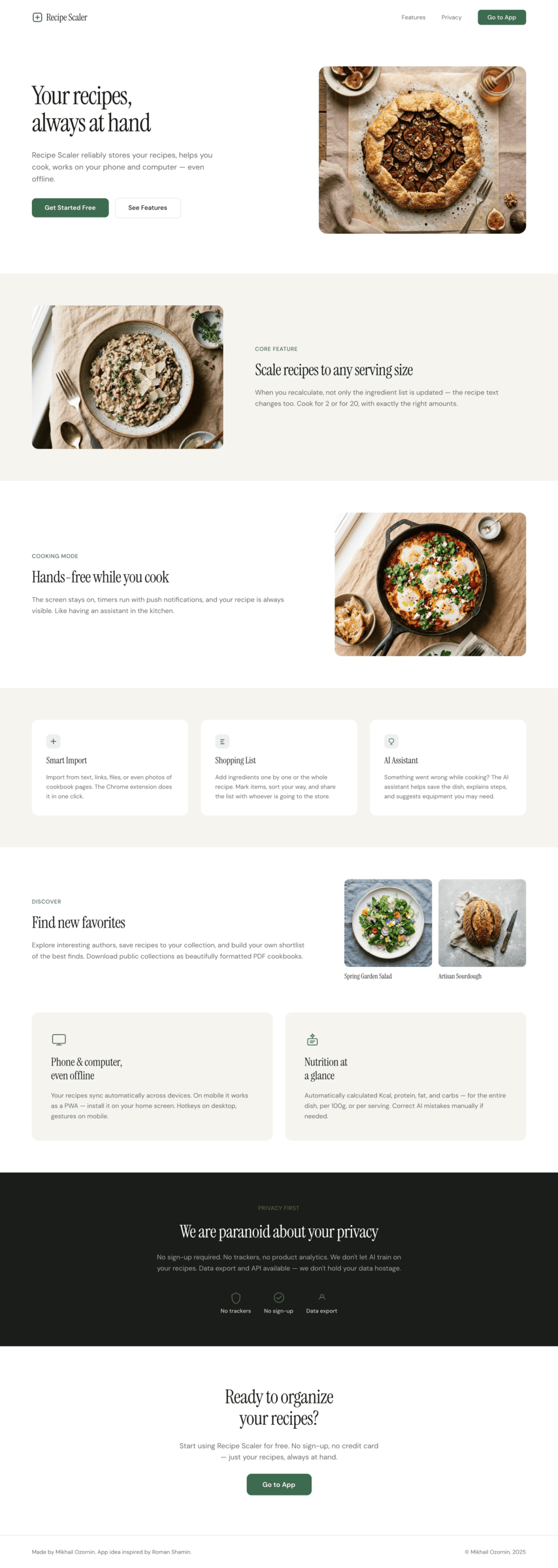
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Claude Code + Sonnet 4.5, xhigh
Substantially closer to the Chinese models and the simpler ones. Neat, but completely neutral, completely simplified.
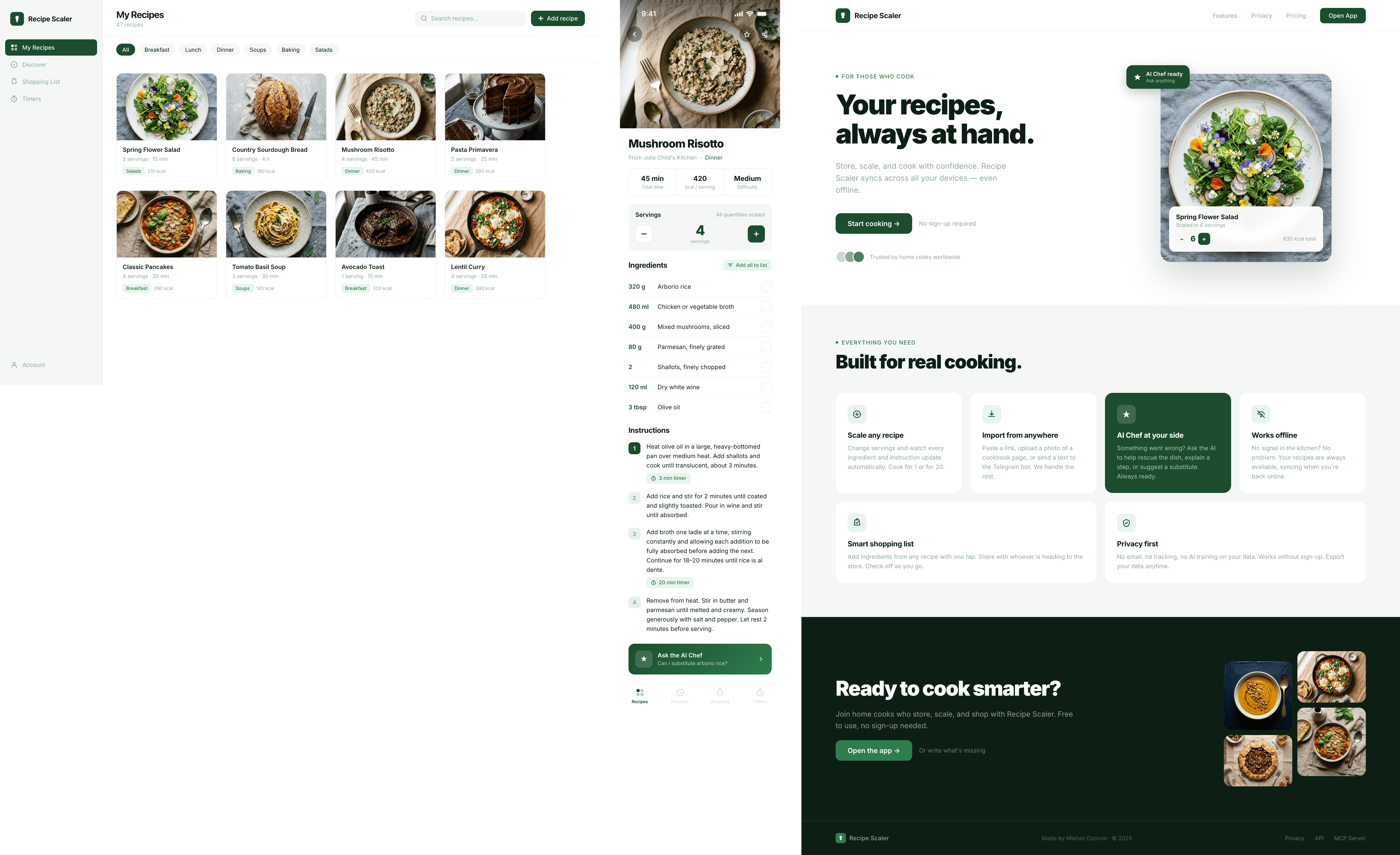{kind=link}
{kind=link}
{kind=link}
{kind=link}
Claude Code + Haiku 4.5
Didn’t even cope with the tools. There’s not a single reason to use it.




{kind=link}
{kind=link}
{kind=link}
Codex + GPT 5.5, xhigh
Very cheap compared to opus, the result is accordingly. The worst result among SOTA models (state of the art, that is).
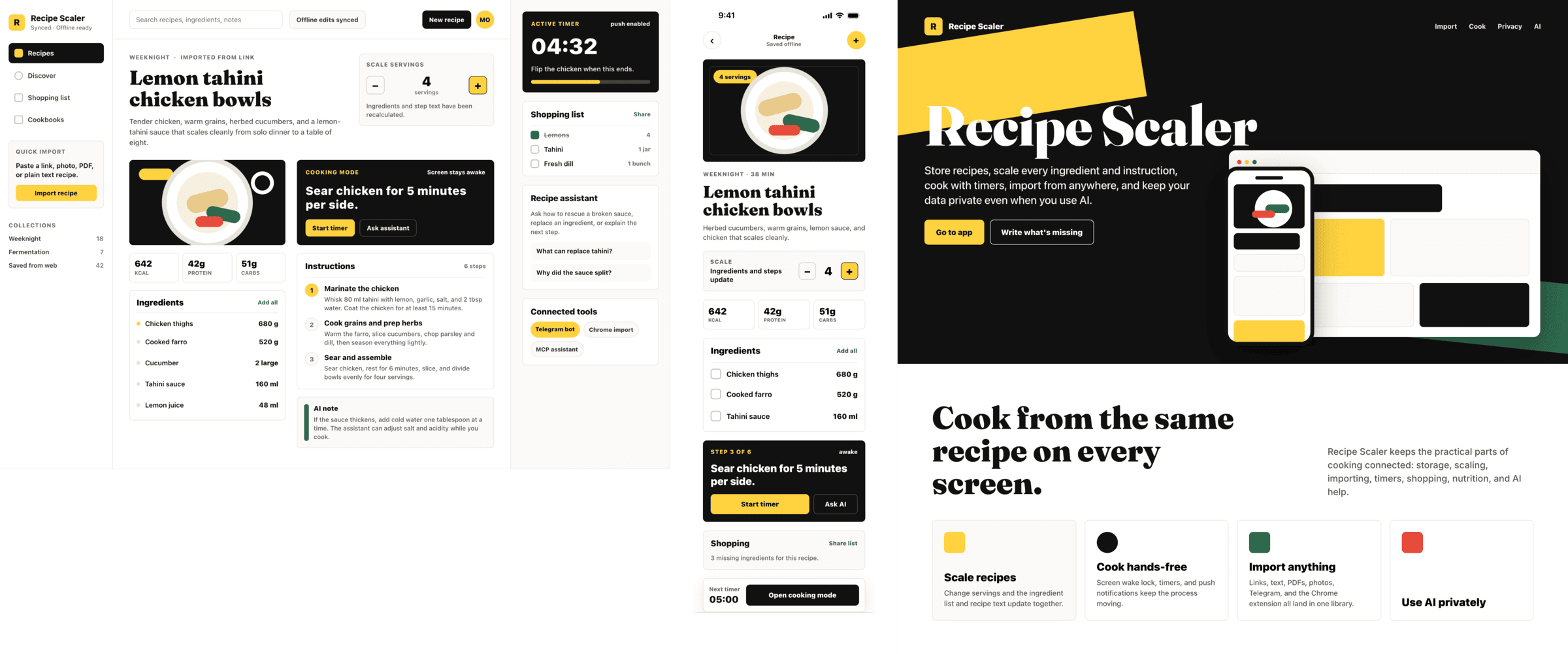
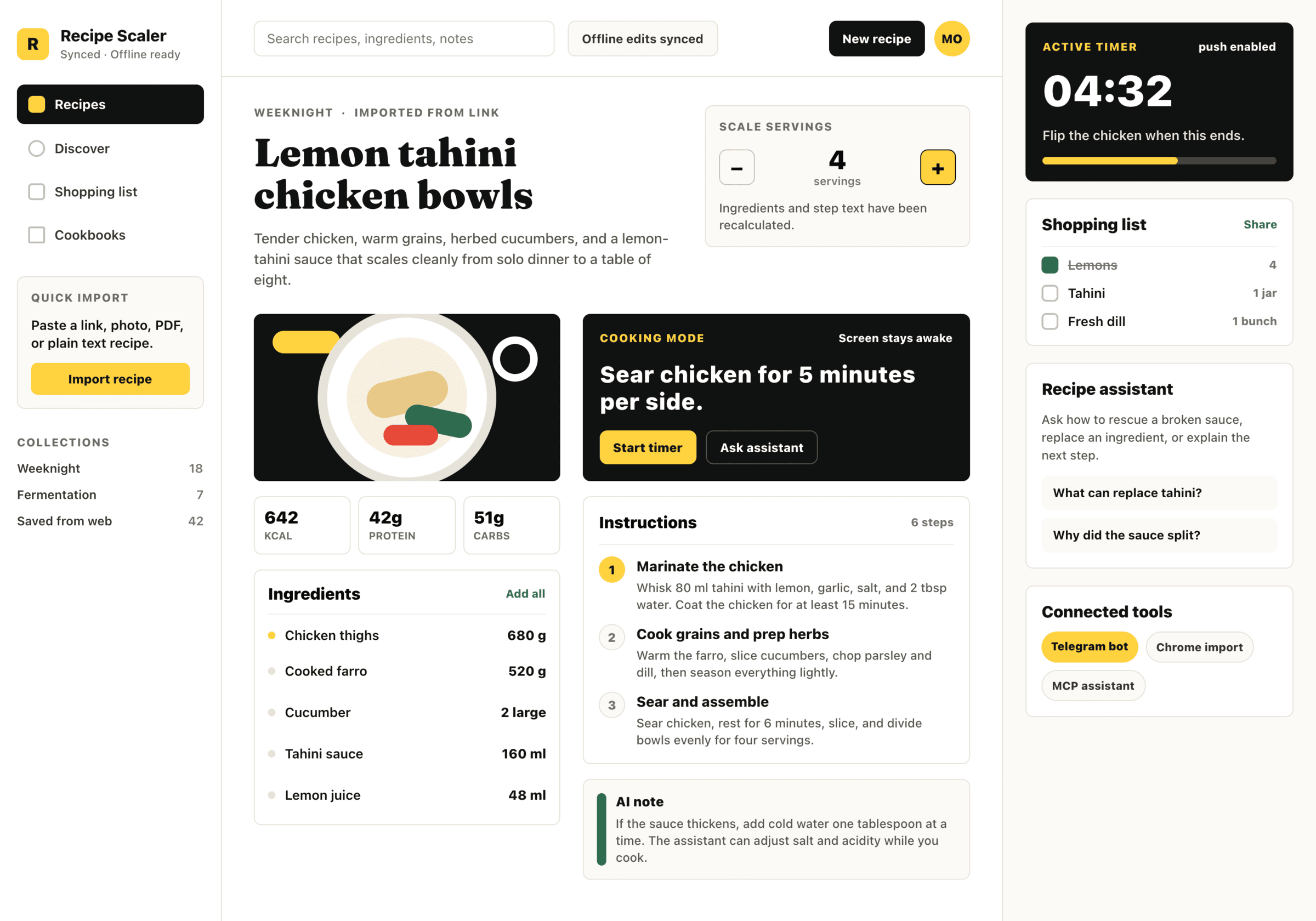
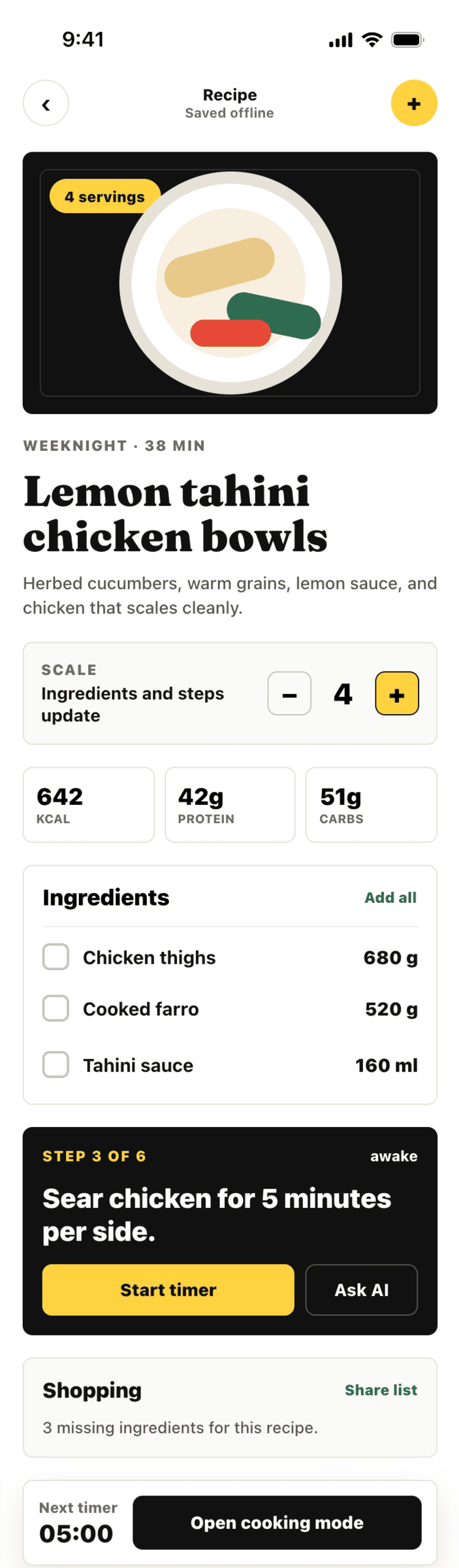
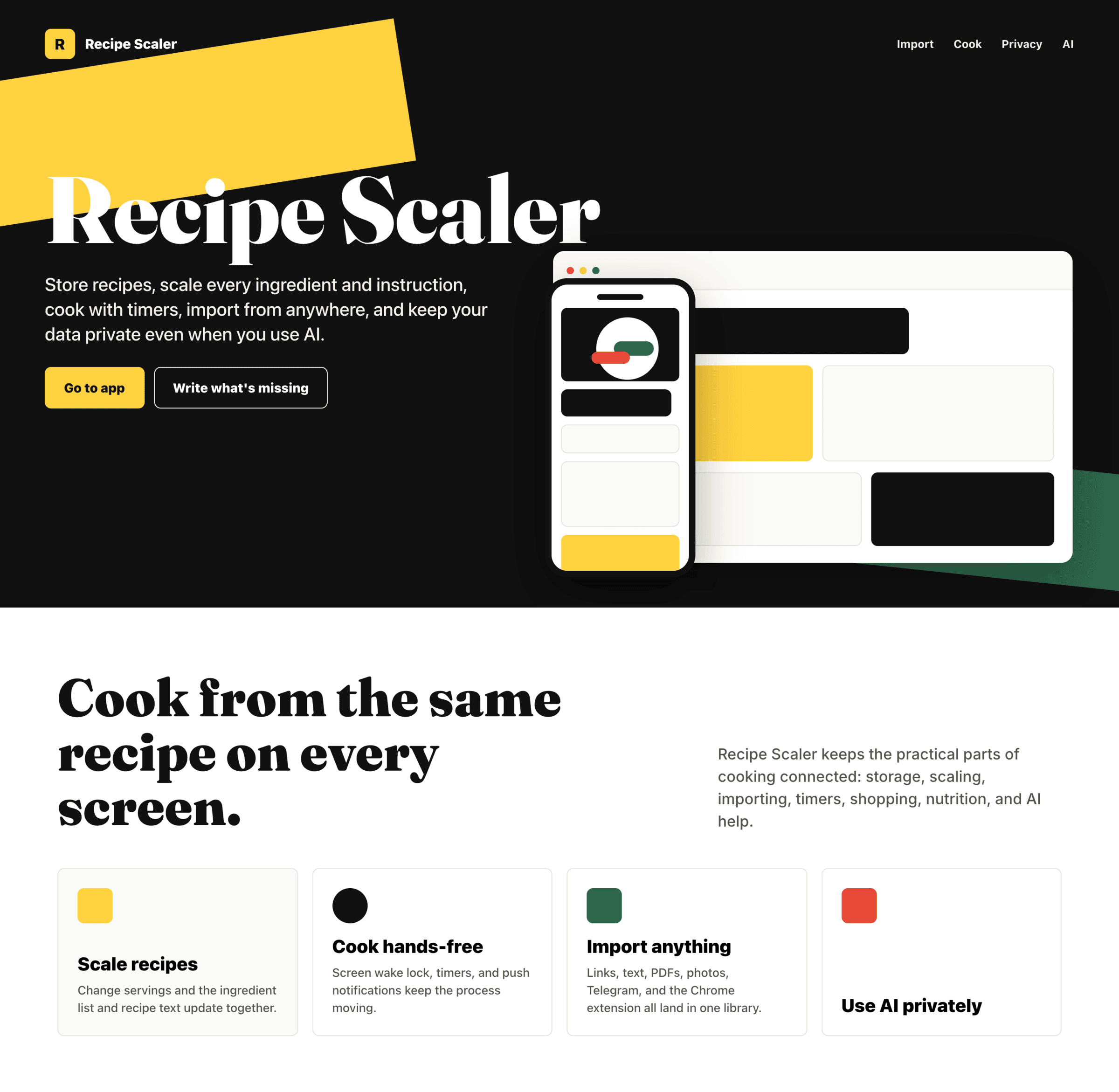
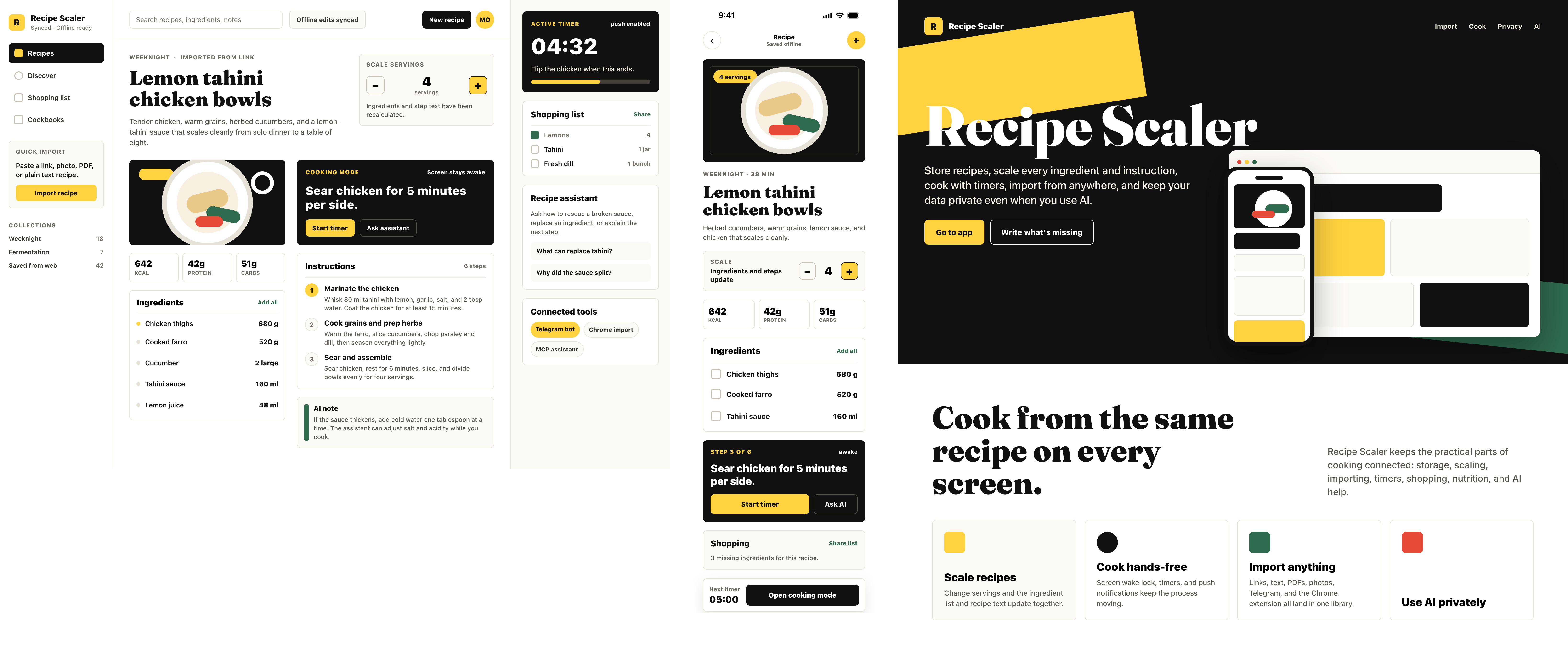{kind=link}
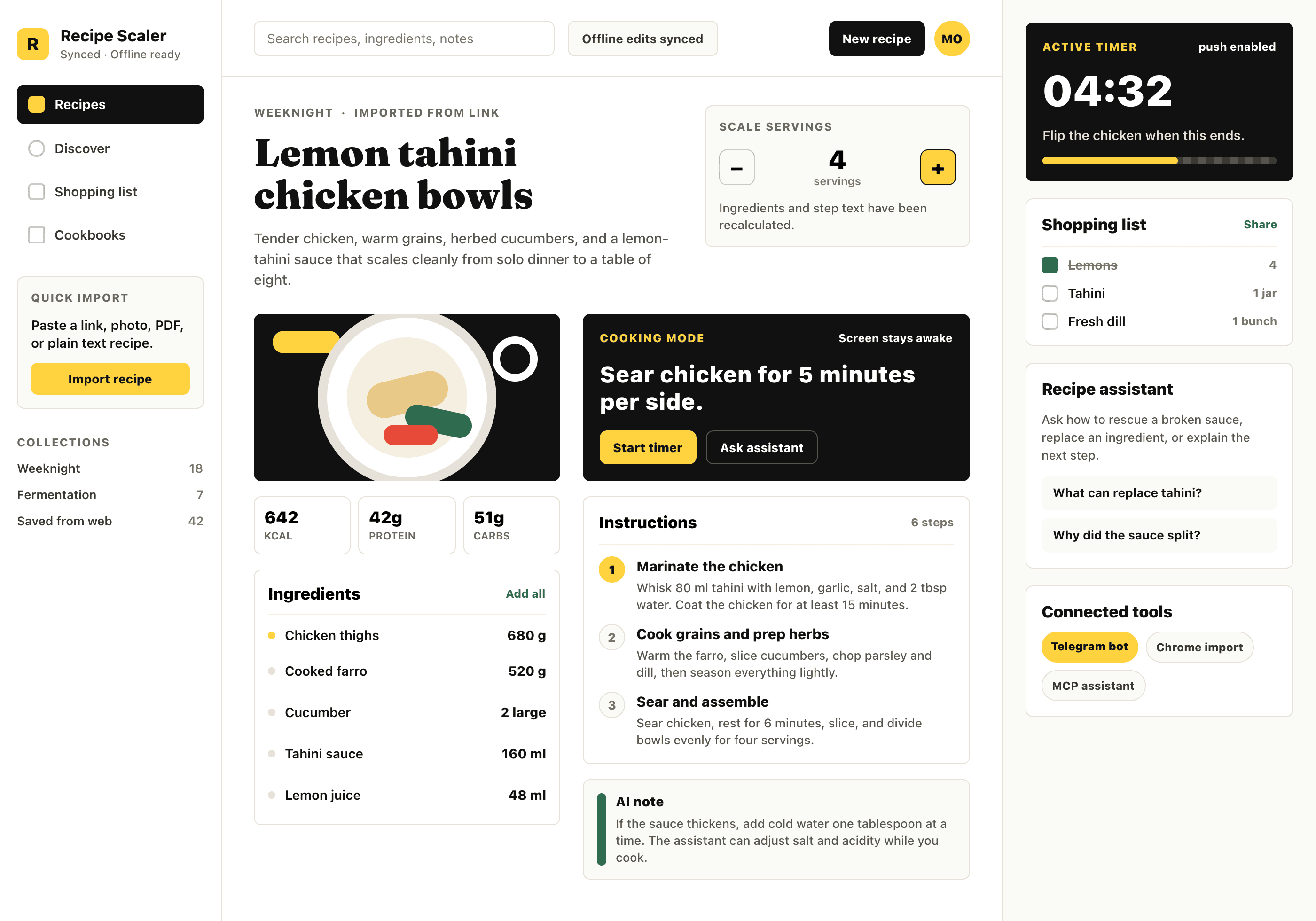{kind=link}
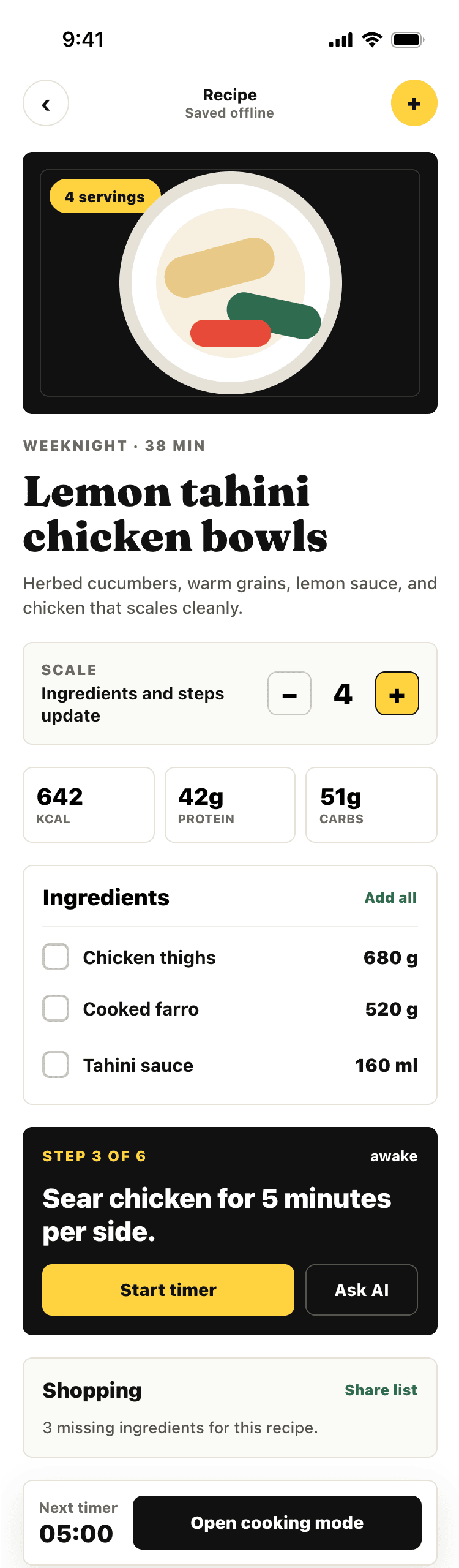{kind=link}
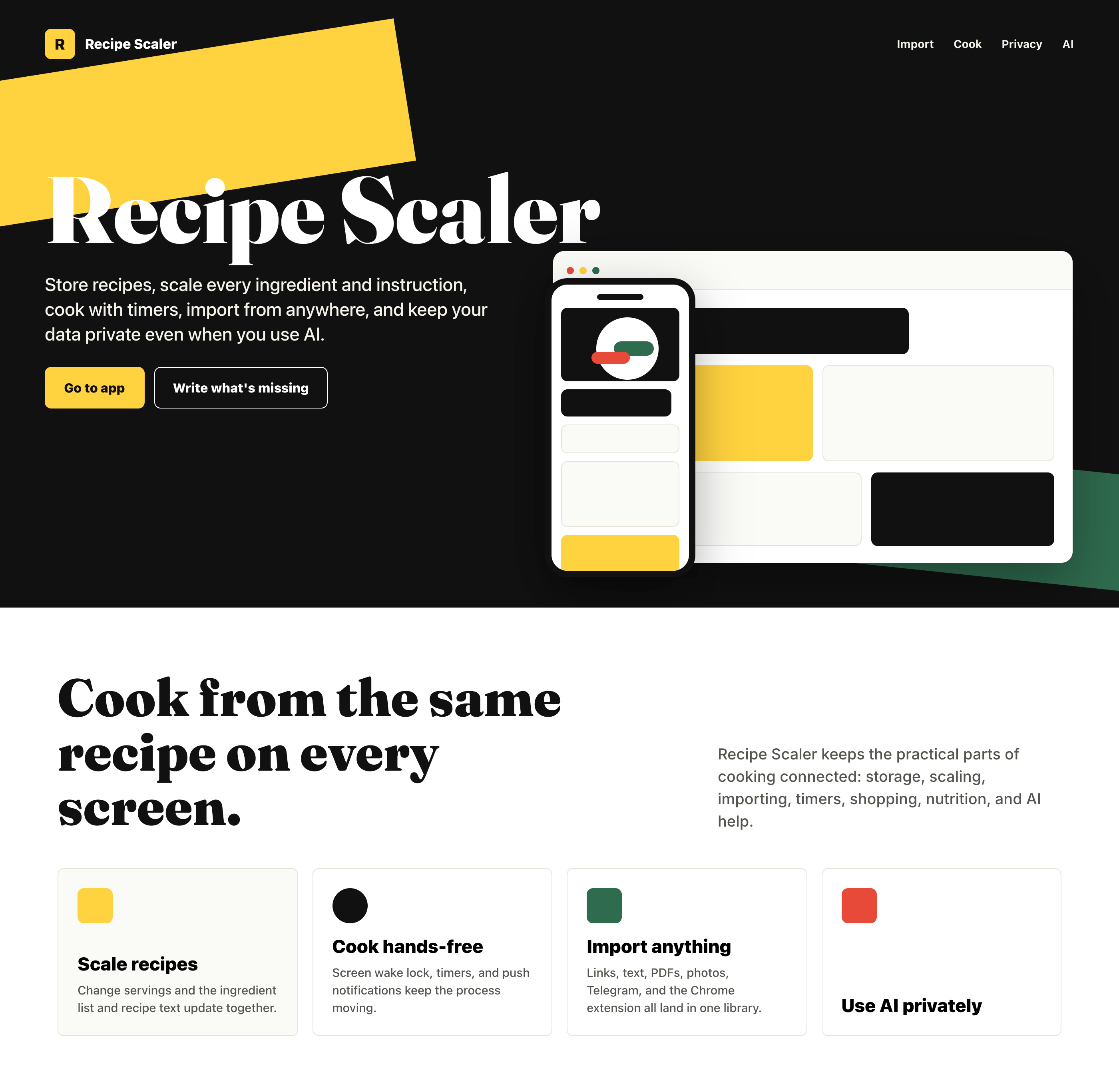{kind=link}
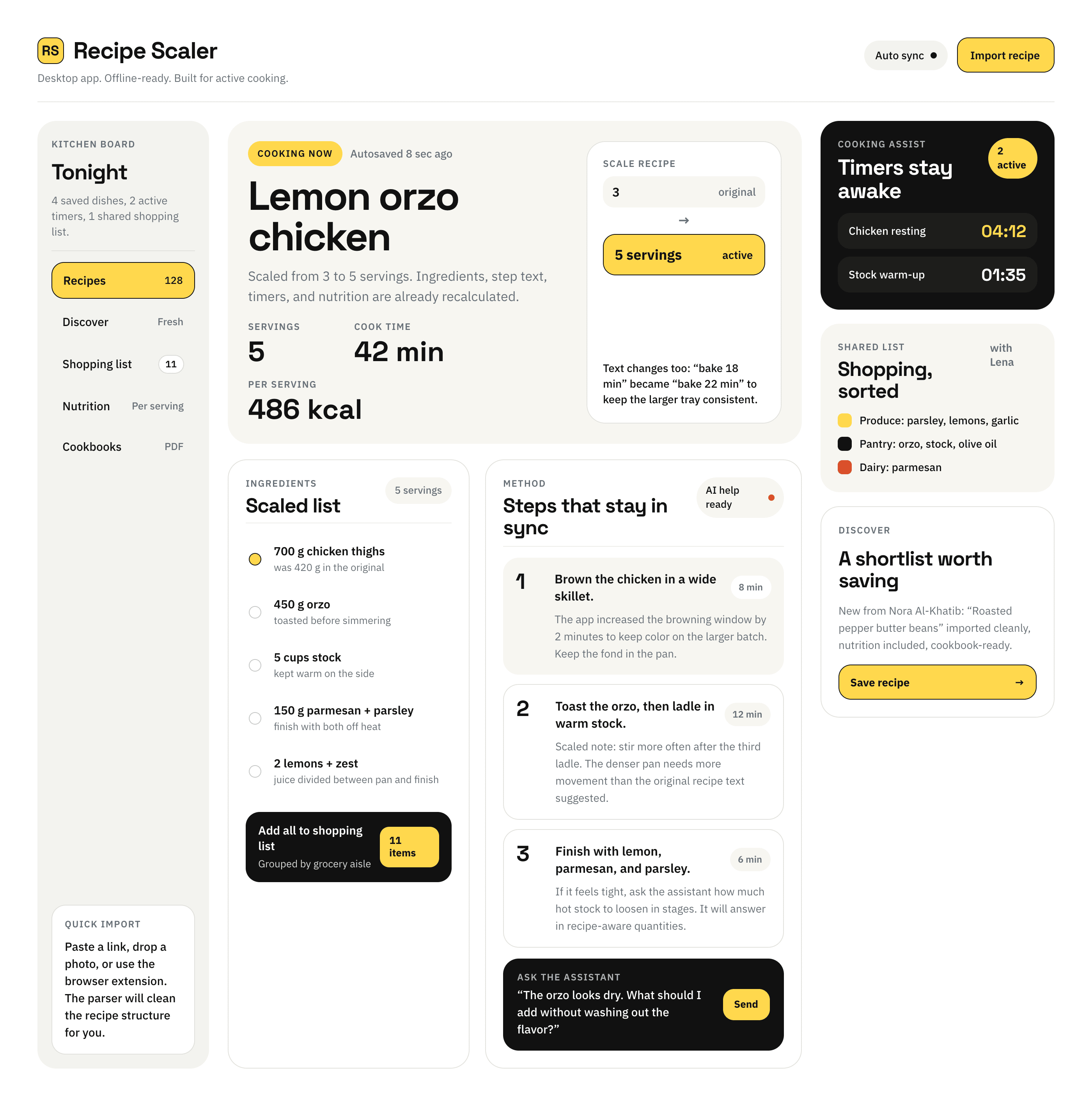
Codex + GPT 5.4, xhigh
Surprisingly, I like this variant even more than GPT 5.5.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
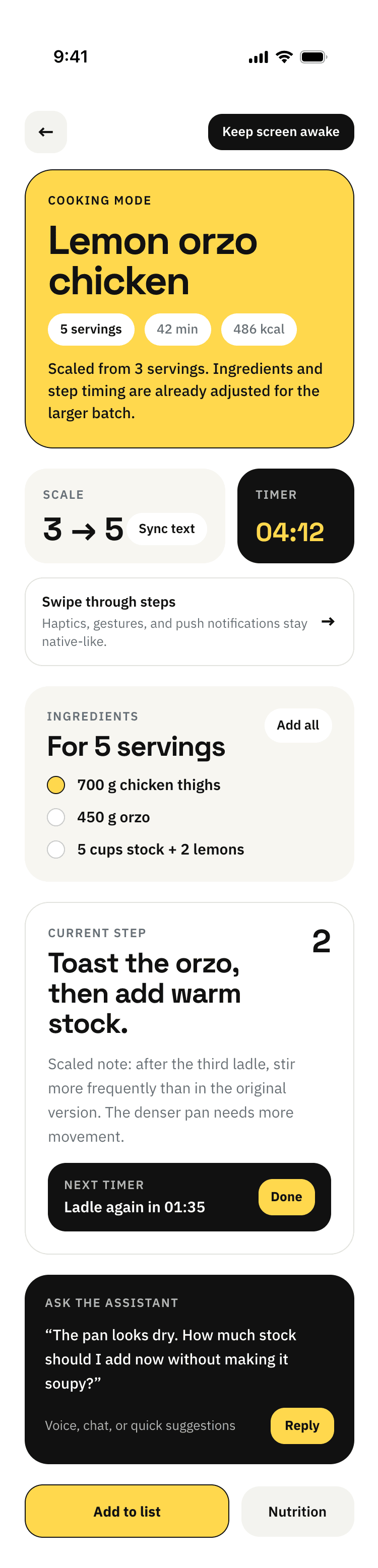
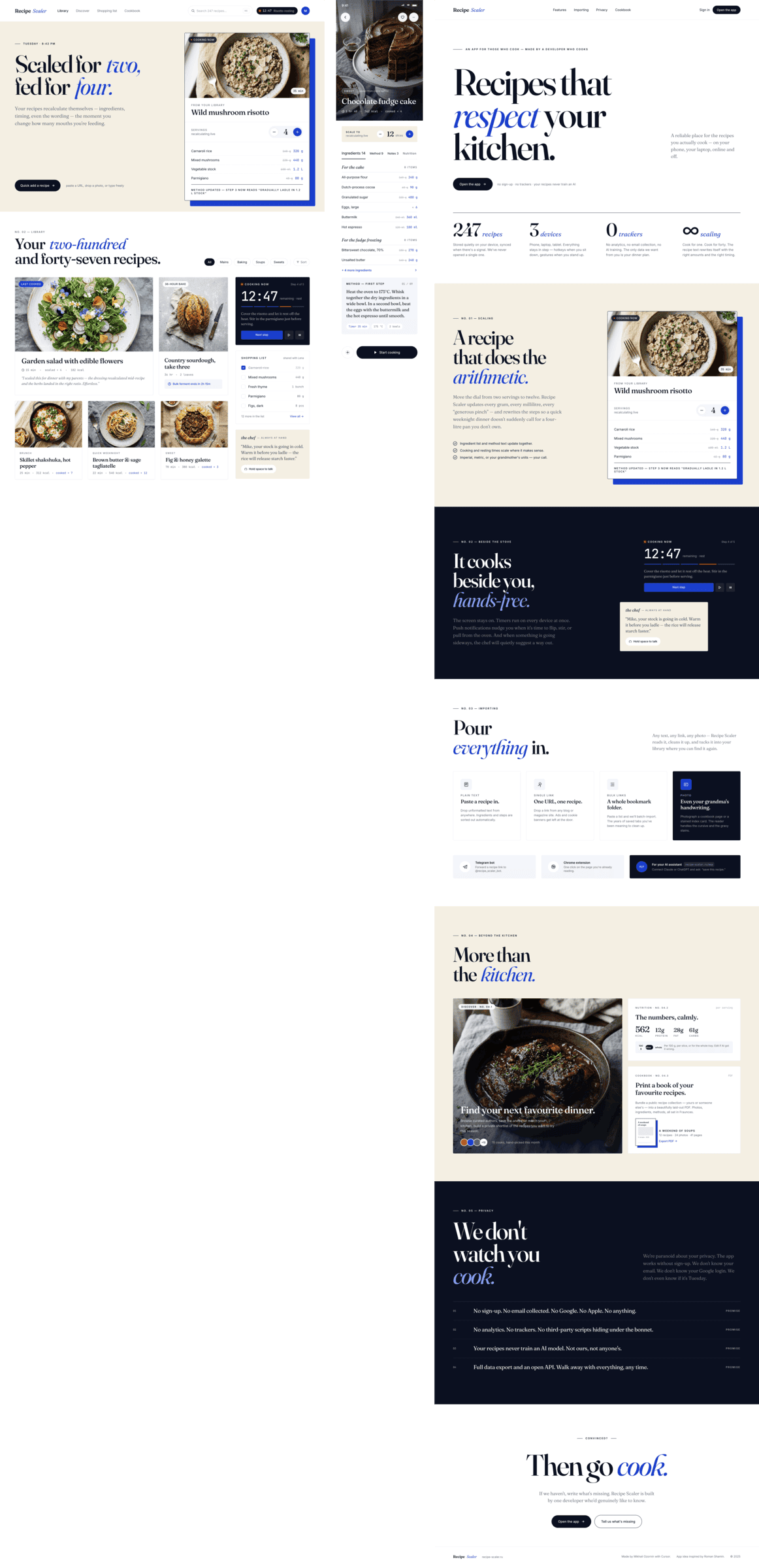
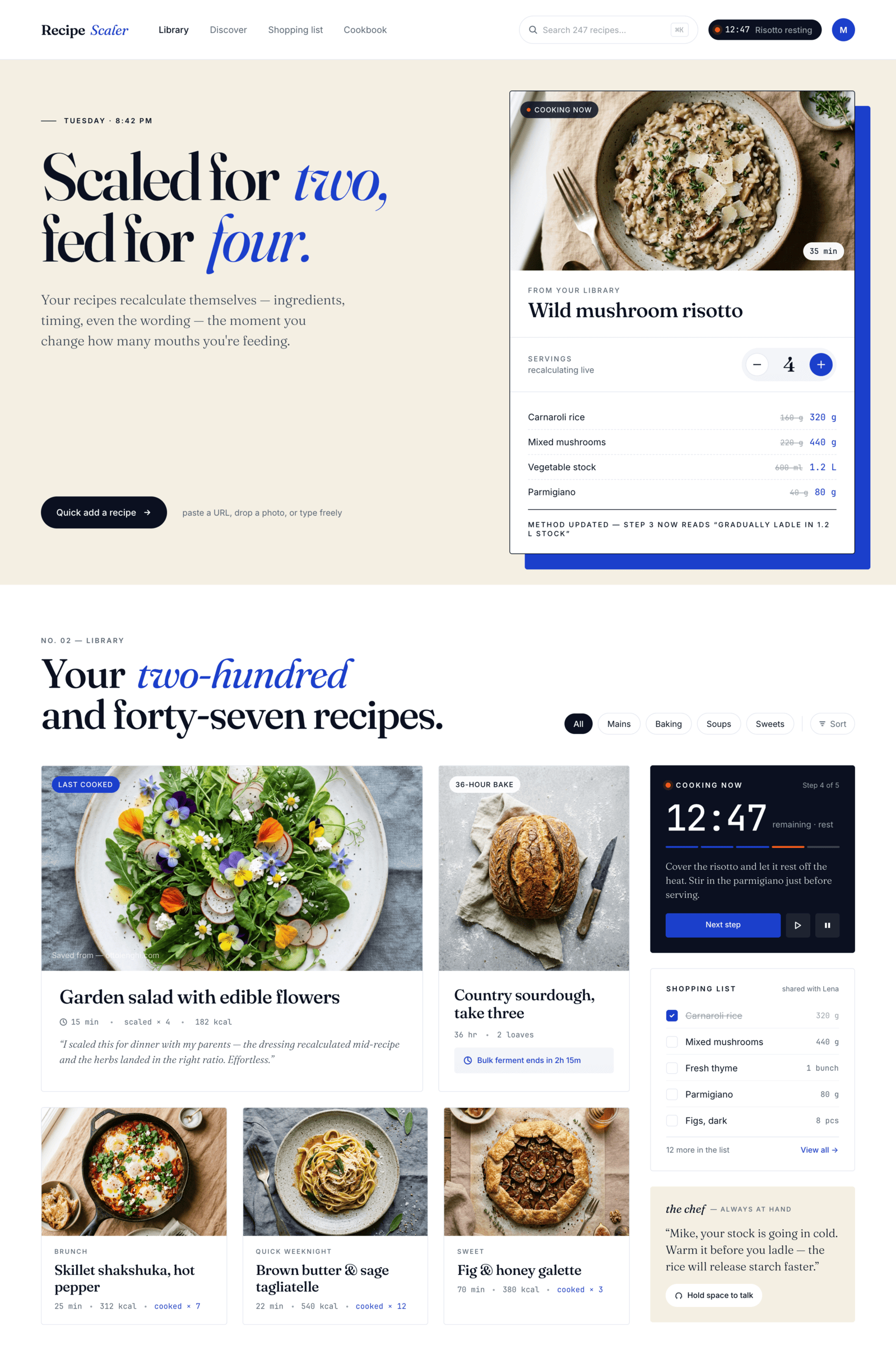
Cursor + Auto
A surprisingly good result for Auto mode. I don’t know who was doing it, maybe Opus on low-reasoning was doing the overall task, and the implementation was some GPT-nano. The style choice is like from Opus.
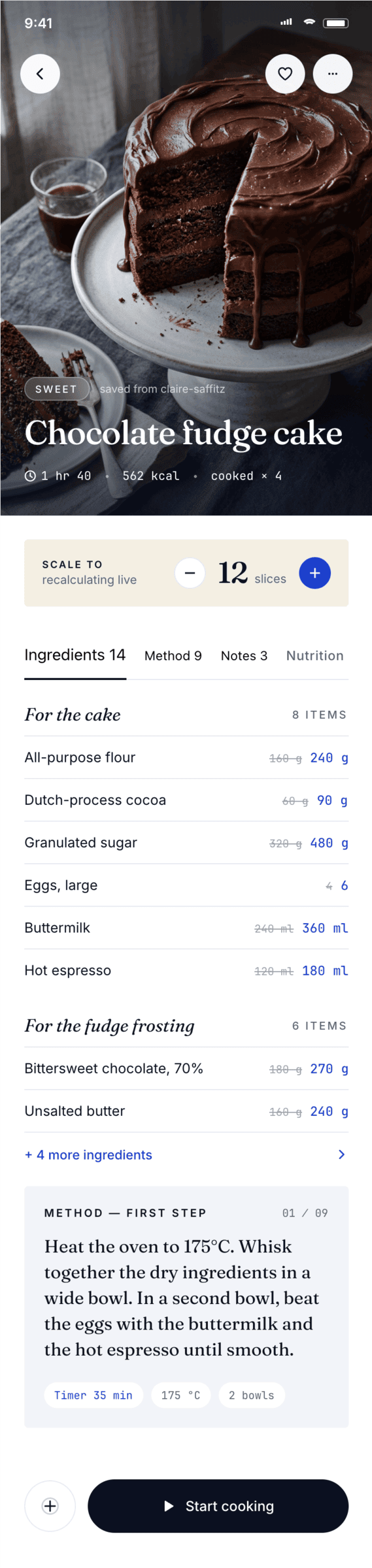
{kind=link}
{kind=link}
{kind=link}
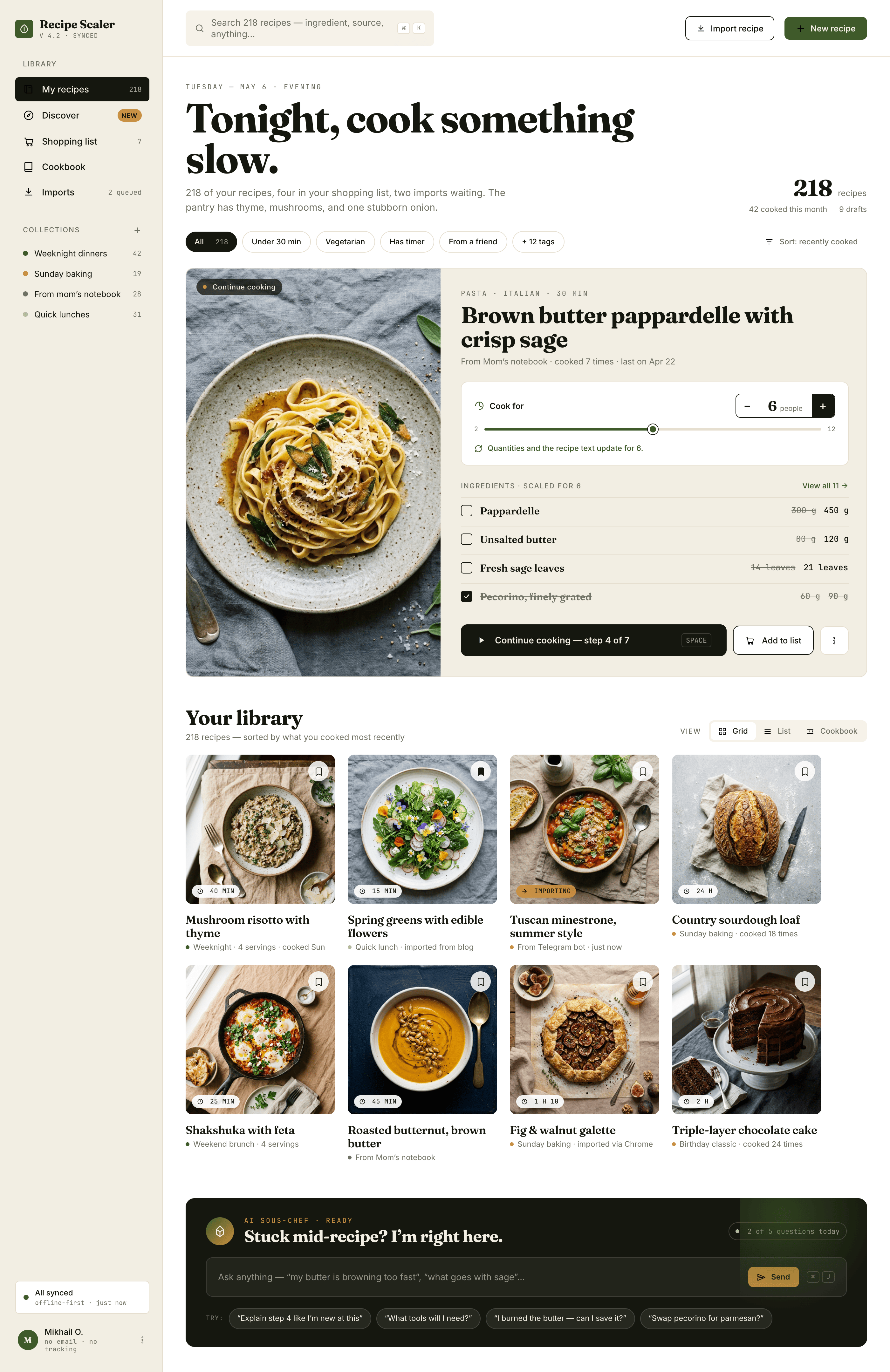
Cursor + Opus 4.7
Twice as expensive as Opus 4.7 at Kilo. Checks itself a lot, screenshotted literally every stage and every block. The result is slightly better.
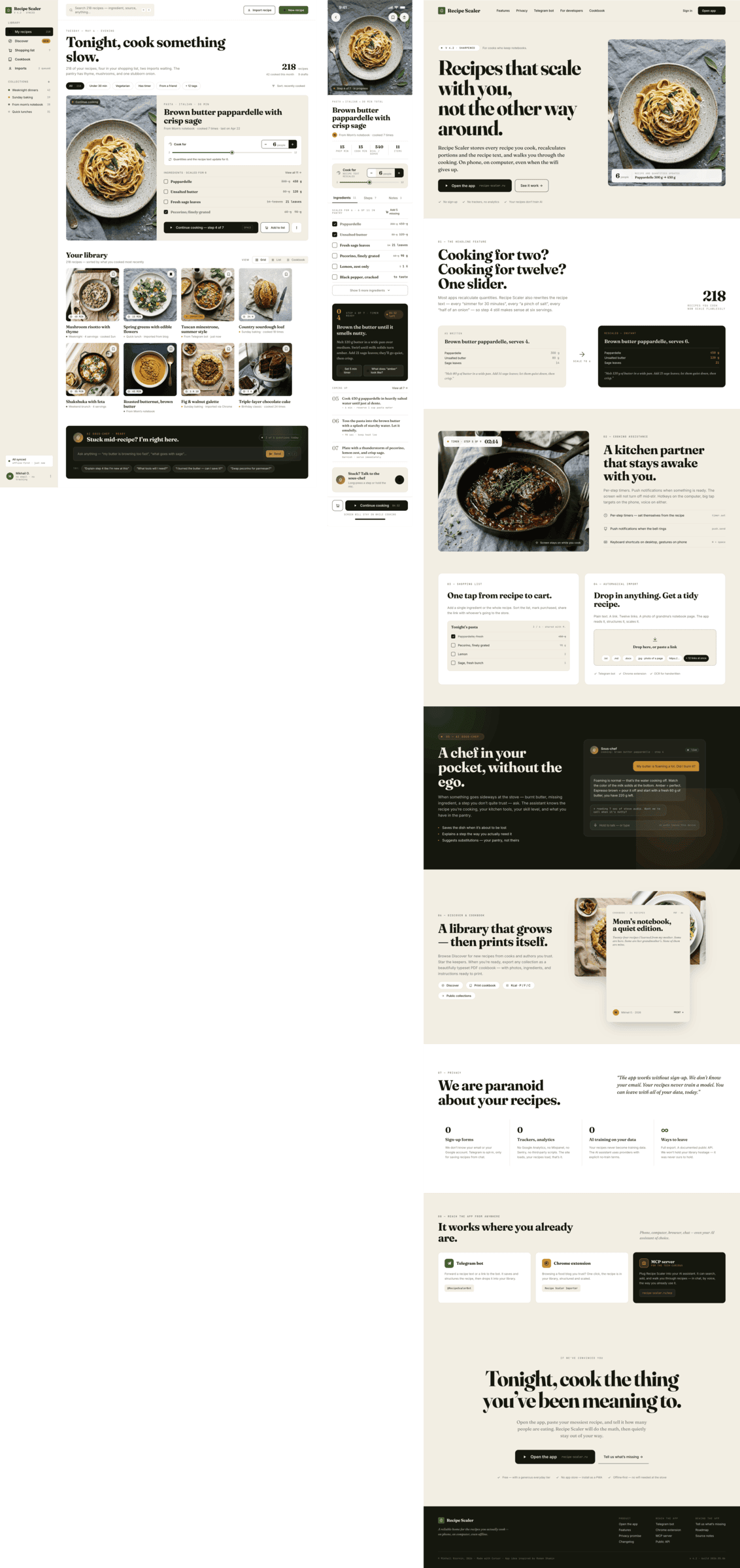
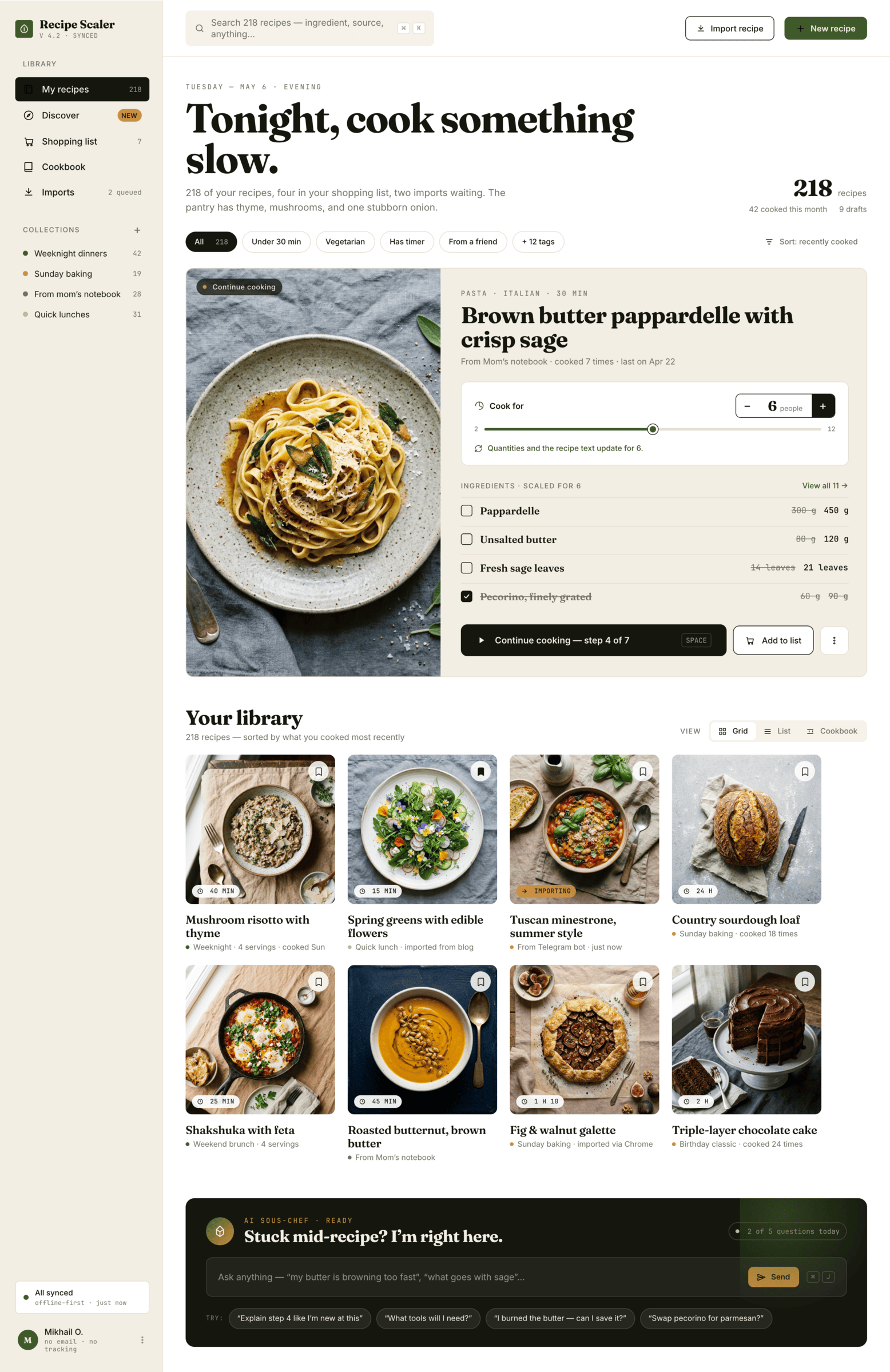

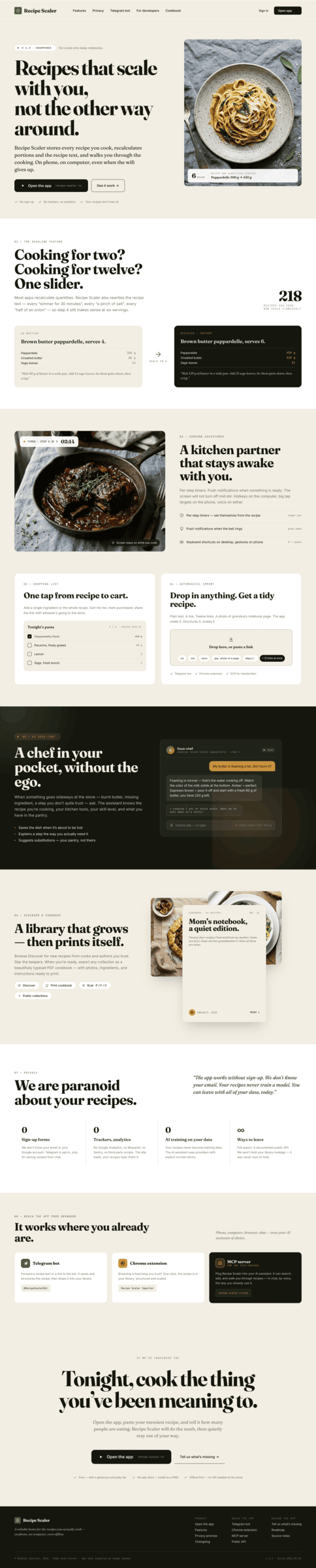
{kind=link}
{kind=link}
{kind=link}
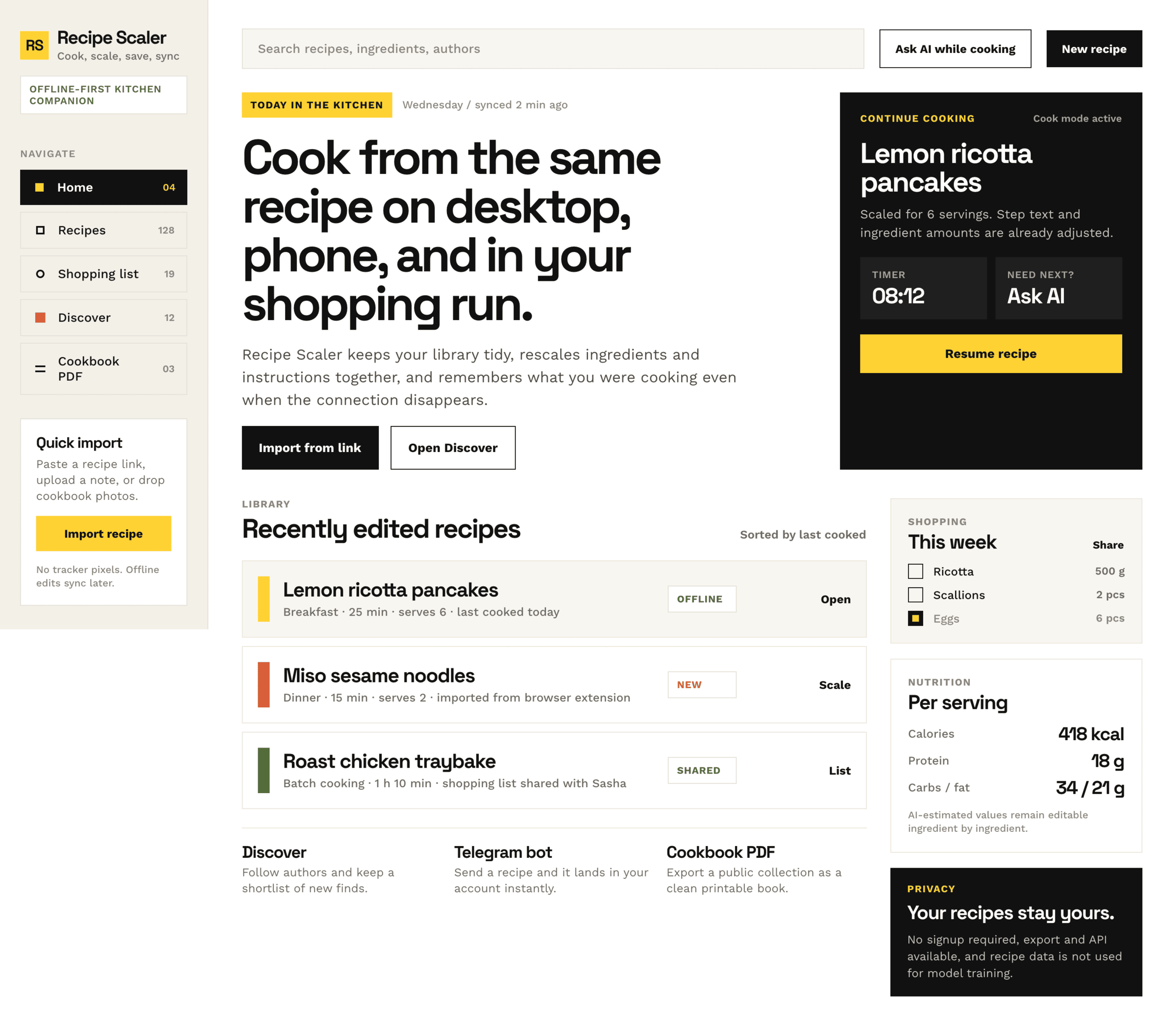
Cursor + GPT 5.4, xhigh
The agent is different, the model is recognizable, it’s the same GPT 5.4 that was in Codex. But here it turned out slightly better.
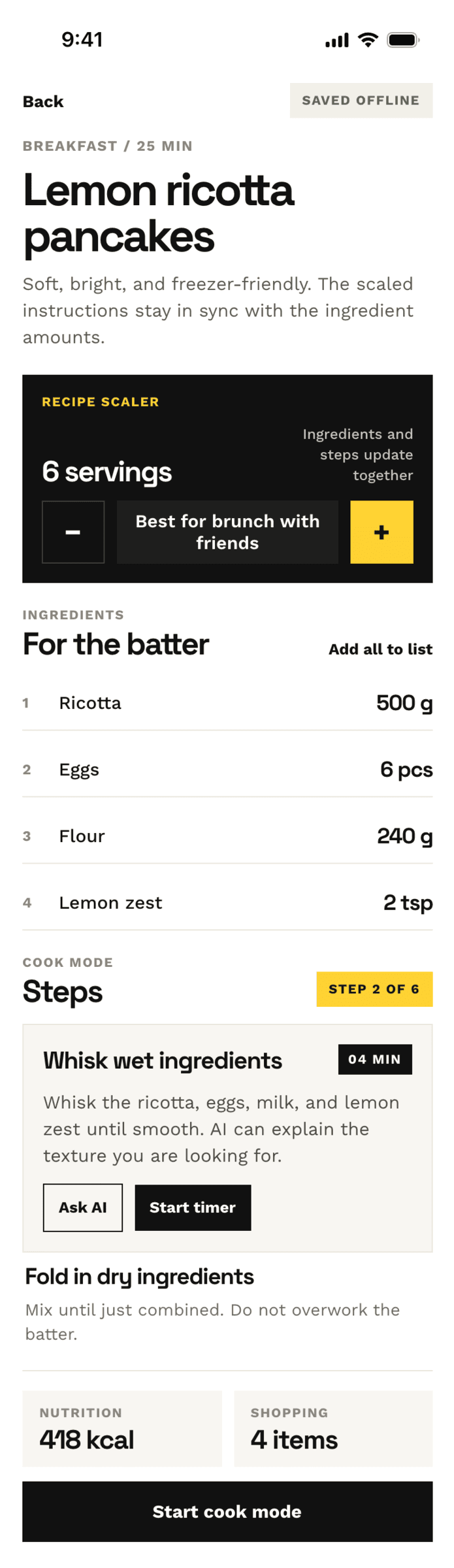
{kind=link}
{kind=link}
{kind=link}
{kind=link}
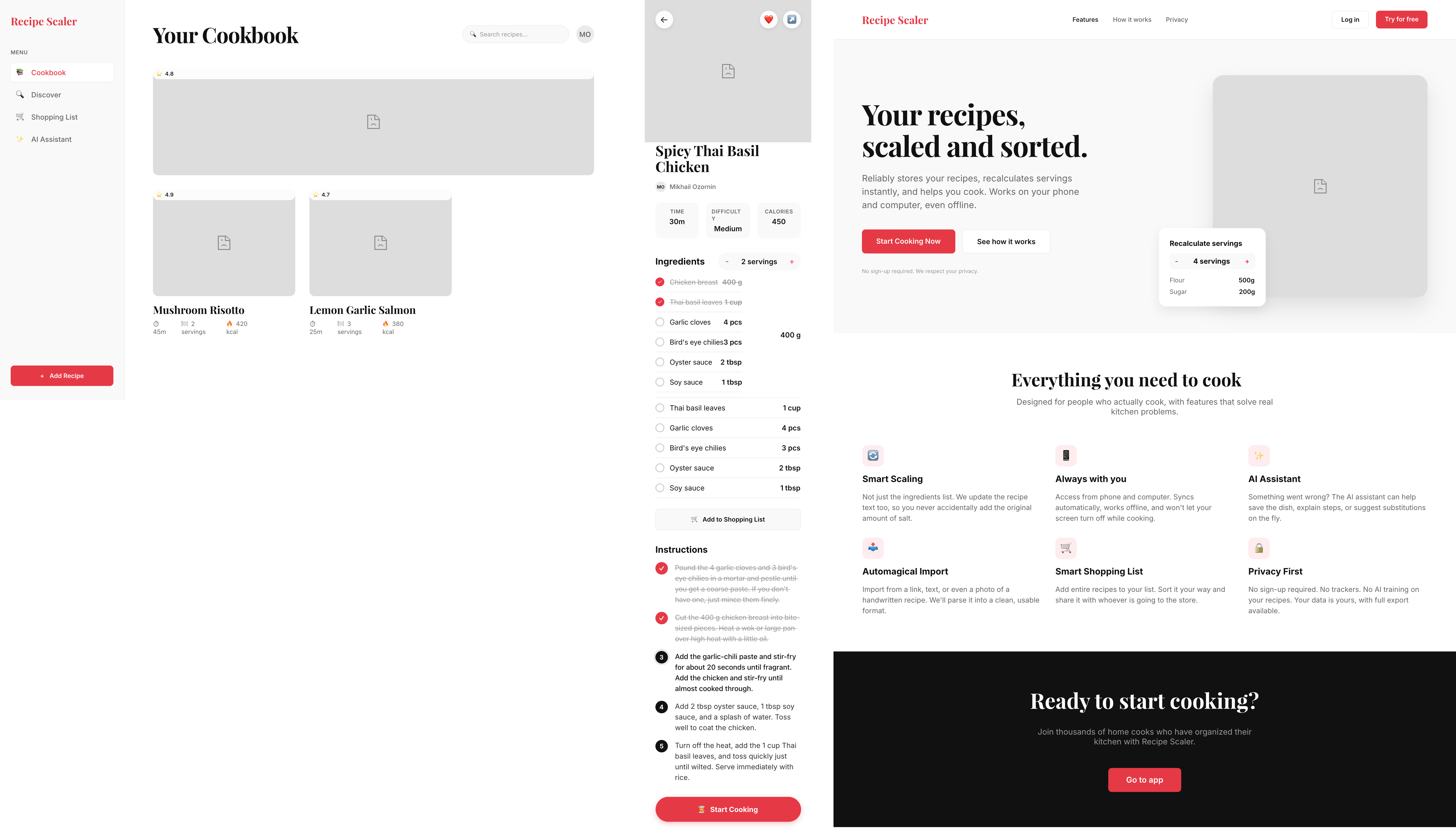
Cursor + Gemini 3.1 Pro
Result comparable to Gemini in Antigravity. Very bad for a model of this level.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cursor + Grok 4.3
Mixed impressions from Grok. Mobile is generally fine, on the level of others. Promo is worse than ones to collect. I thought it’d be cheaper, Grok 4.1 was very cool precisely because it cost very little.
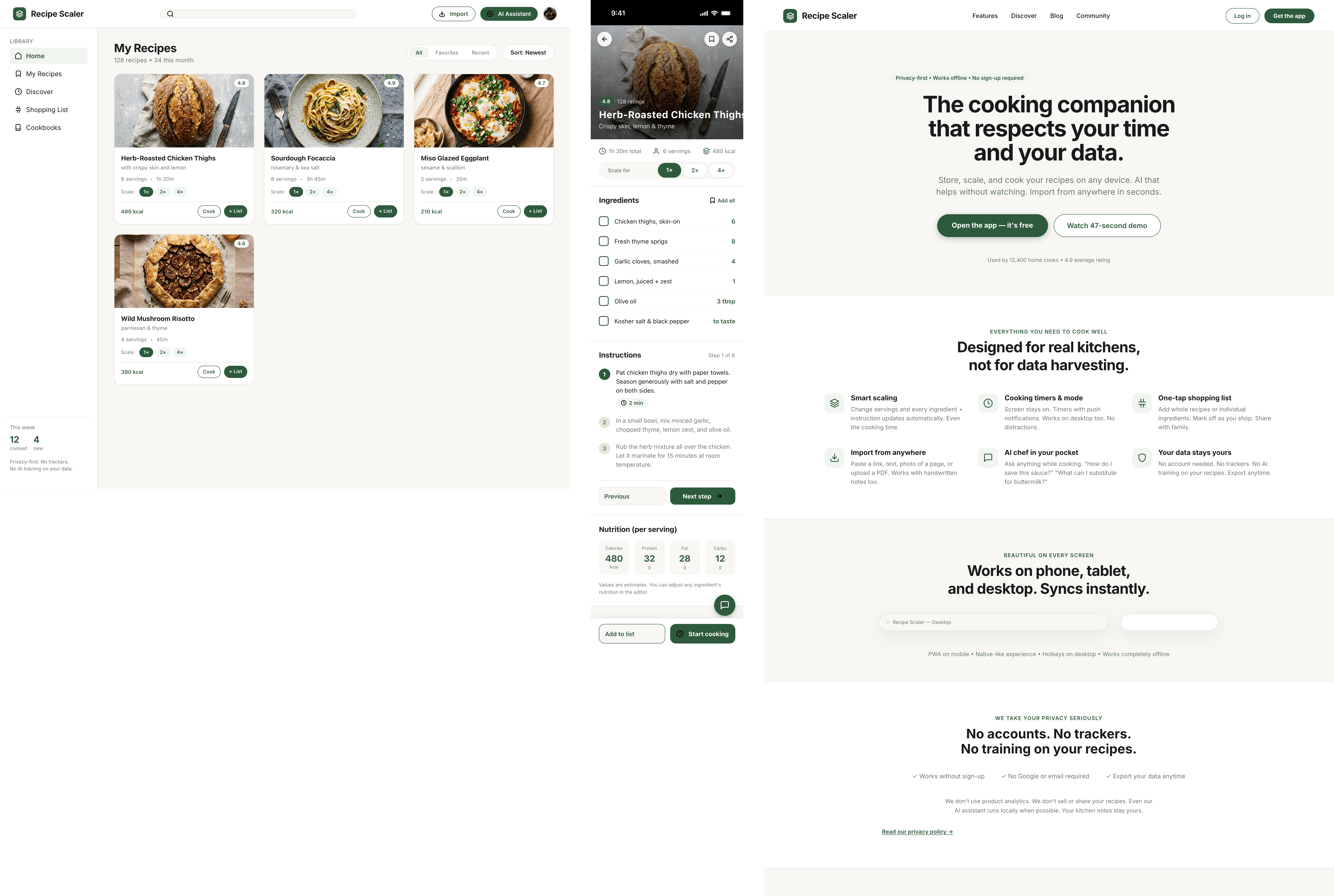{kind=link}
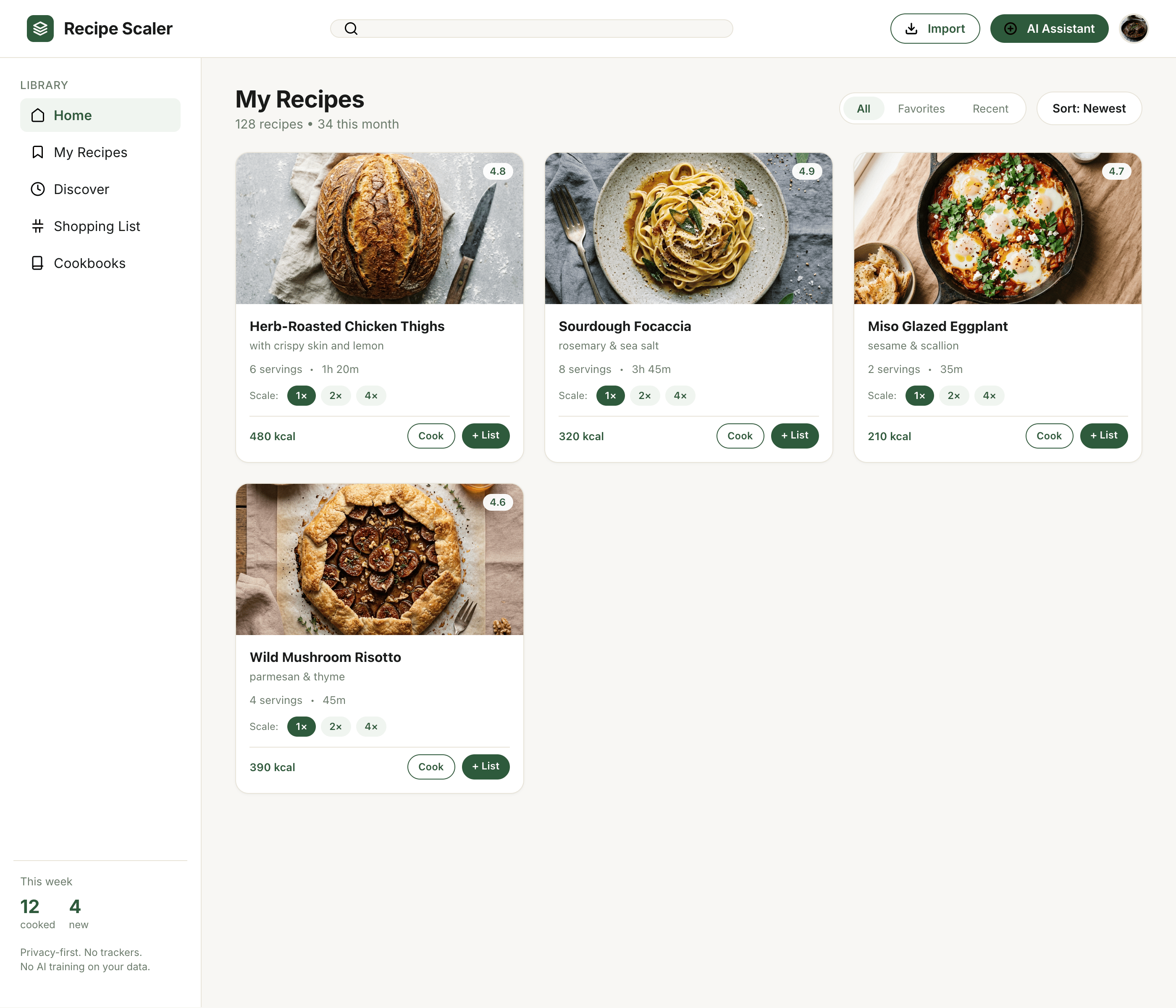{kind=link}
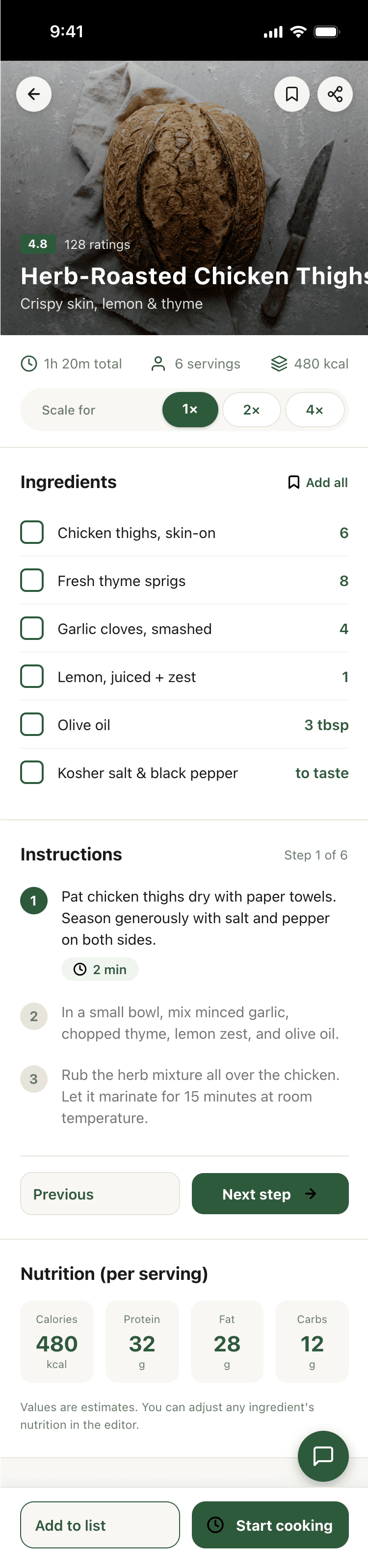{kind=link}
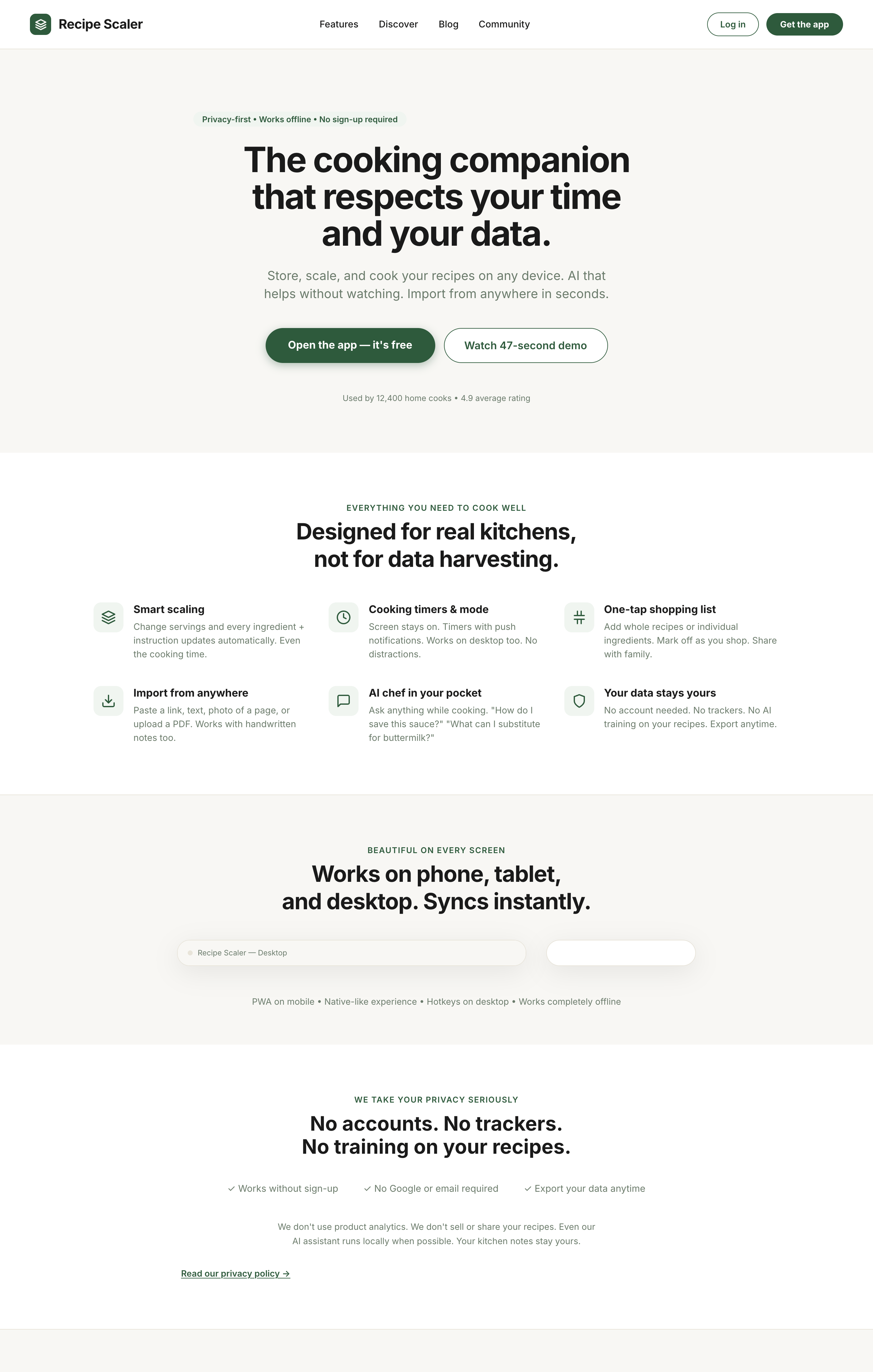{kind=link}
Cursor + GLM 5.1 (z.ai coding plan)
GLM in Cursor for some reason couldn’t cope with the tools.
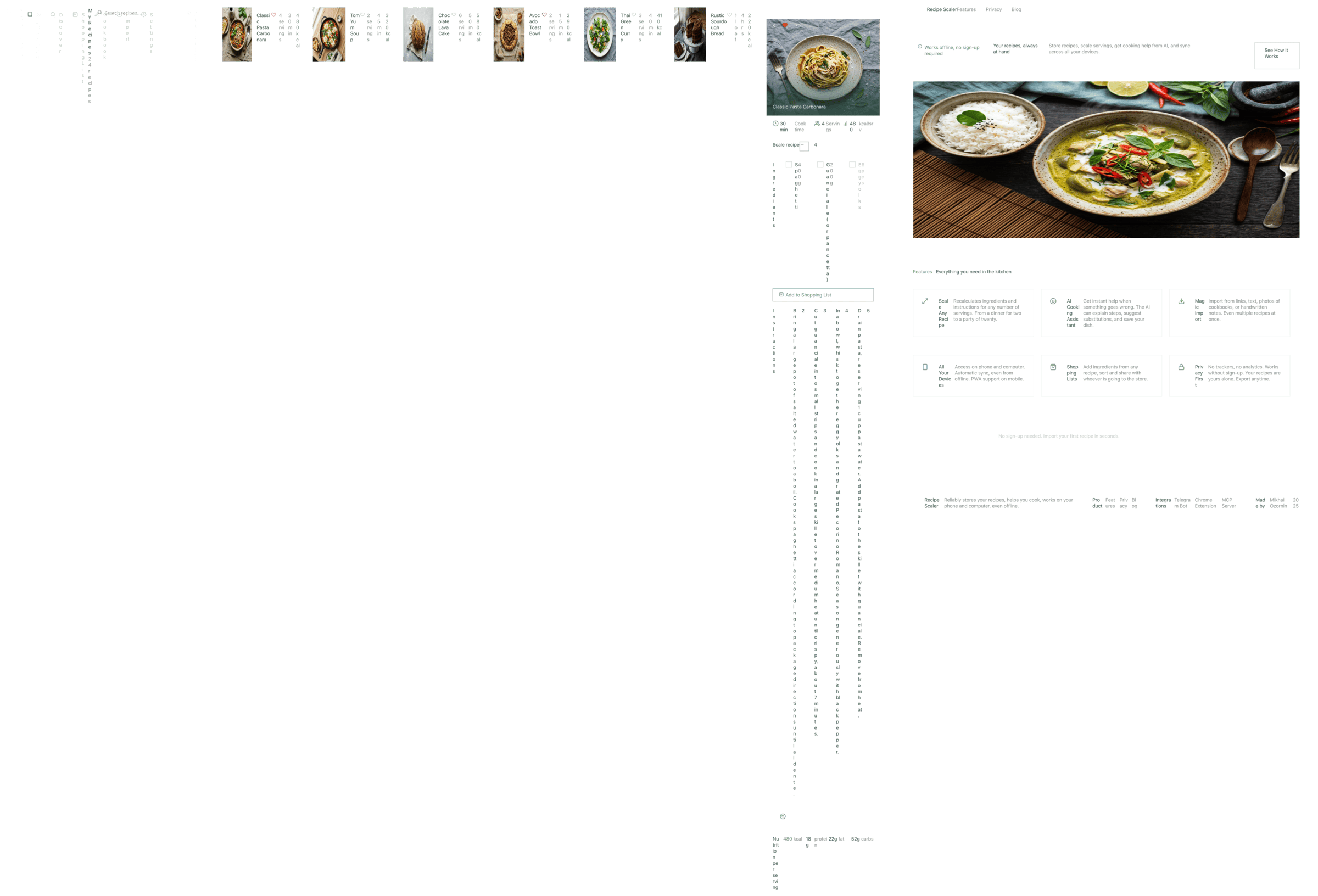


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cursor + Composer 2
Very primitive, but also very cheap. Doesn’t match the level Cursor claims for its model, of course. But they honestly said they’re making a model for code first.
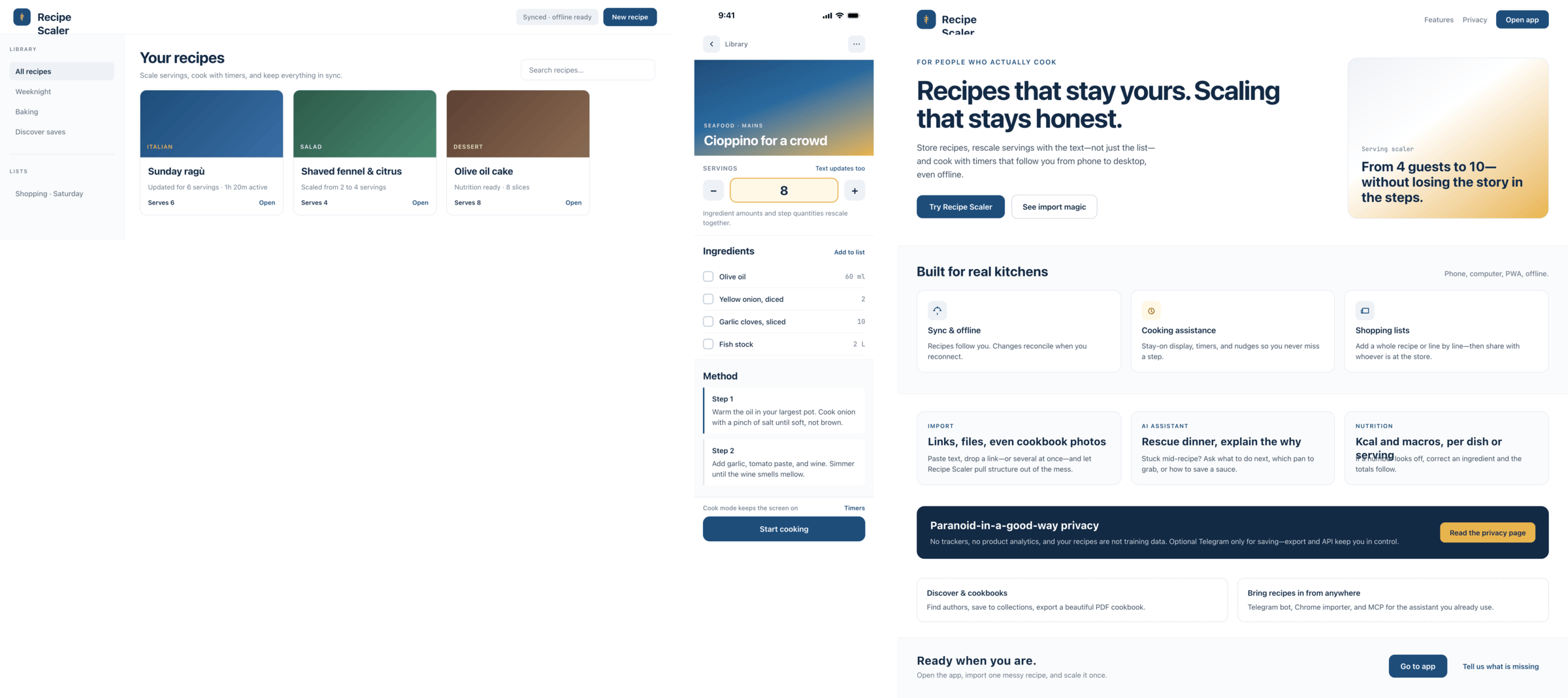
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cursor + Composer 2.5
Comparable in cost to Composer 2, quality has grown, but still very not great.
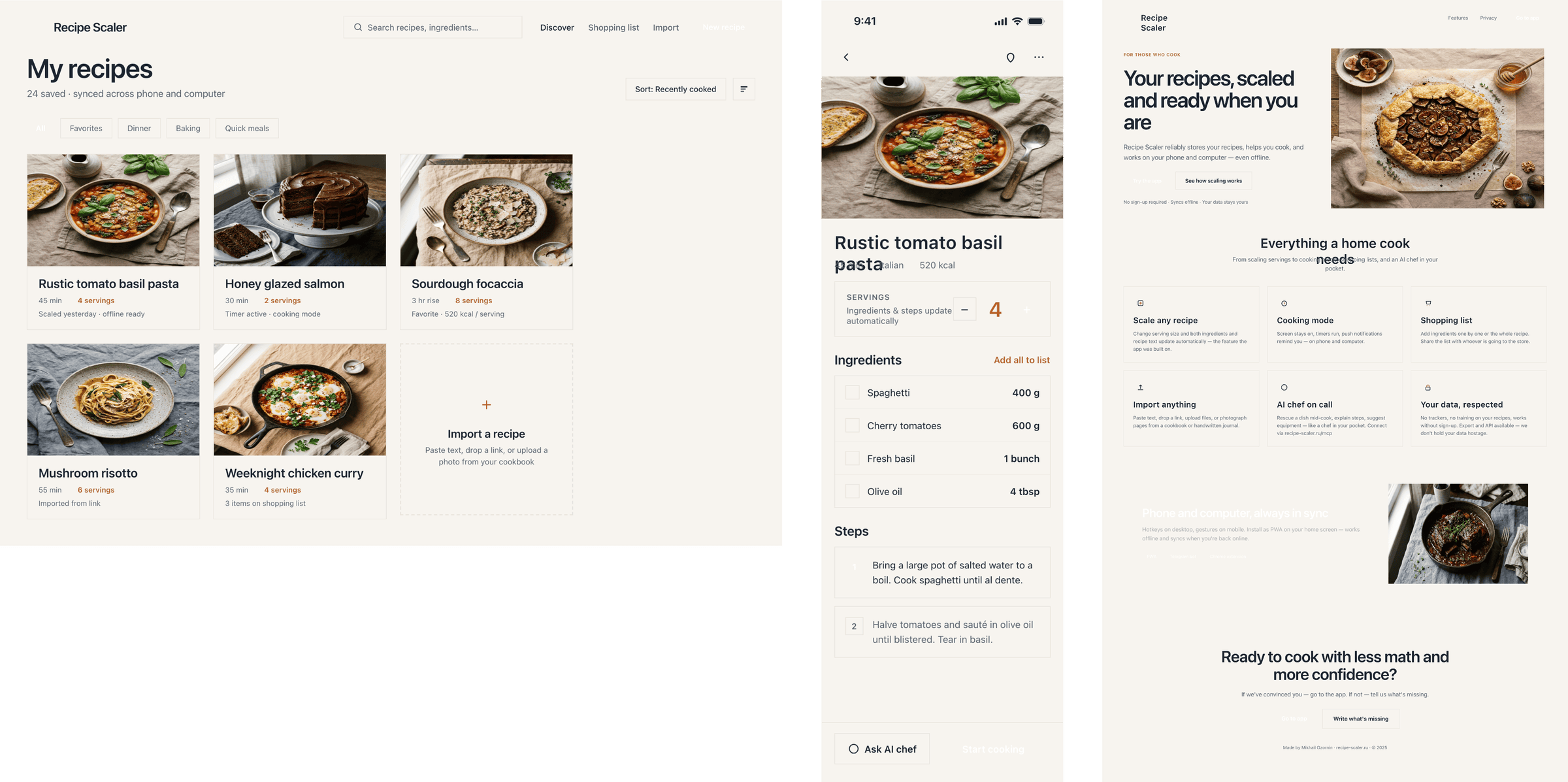
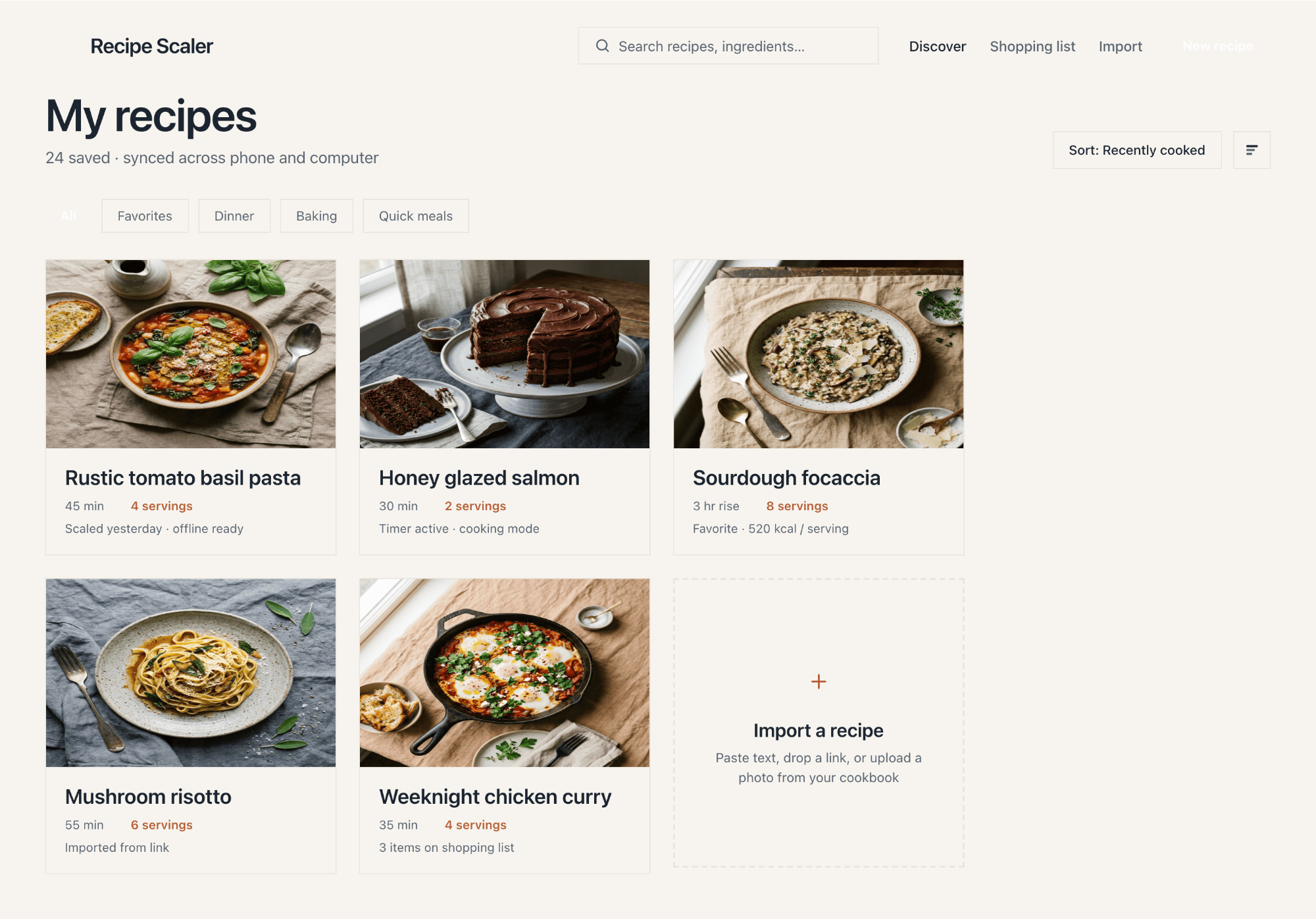
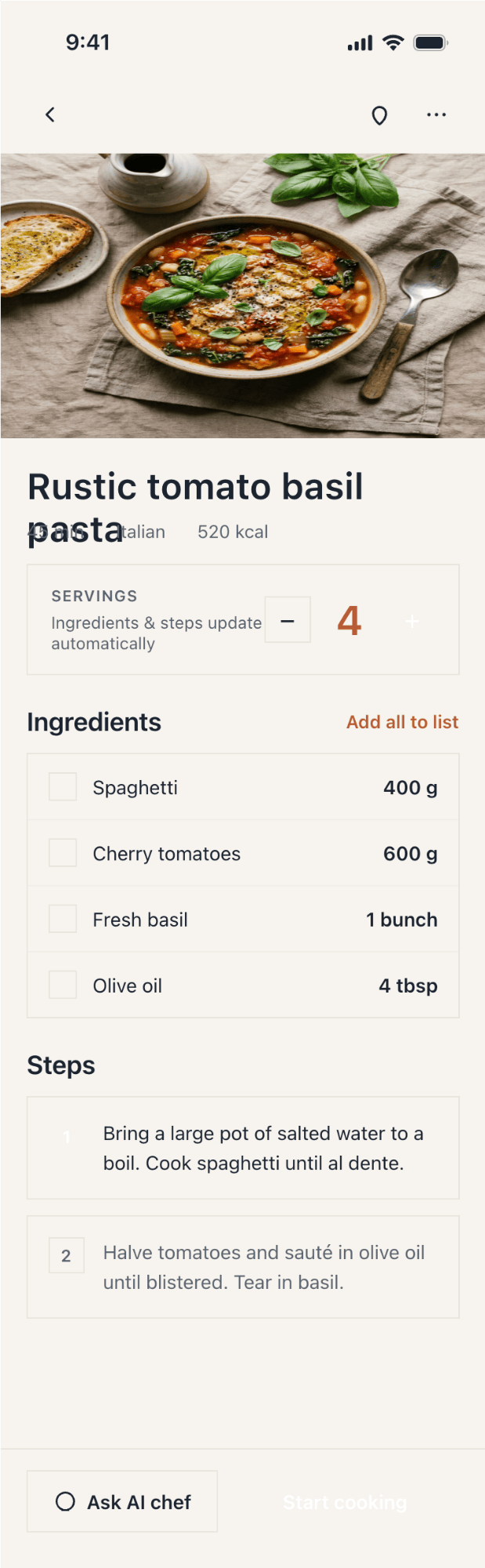
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cursor + MiMo V2.5 Pro
Included Cursor model; very cheap in subscription terms, weak on design.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Source Craft + Default
Seems inexpensive, but no point in using it, neuro-slop neuro-slop.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Source Craft + Default Thinking
It’s like Default and Default Thinking models in Yandex Source Craft are not just different modes of one model, but different models: too different a result, with the reasoning model even worse.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Kilo Code + Opus 4.7 (Kilo cloud)
Typical Opus 4.7. Clean in places, interesting, from afar it’s super-duper.
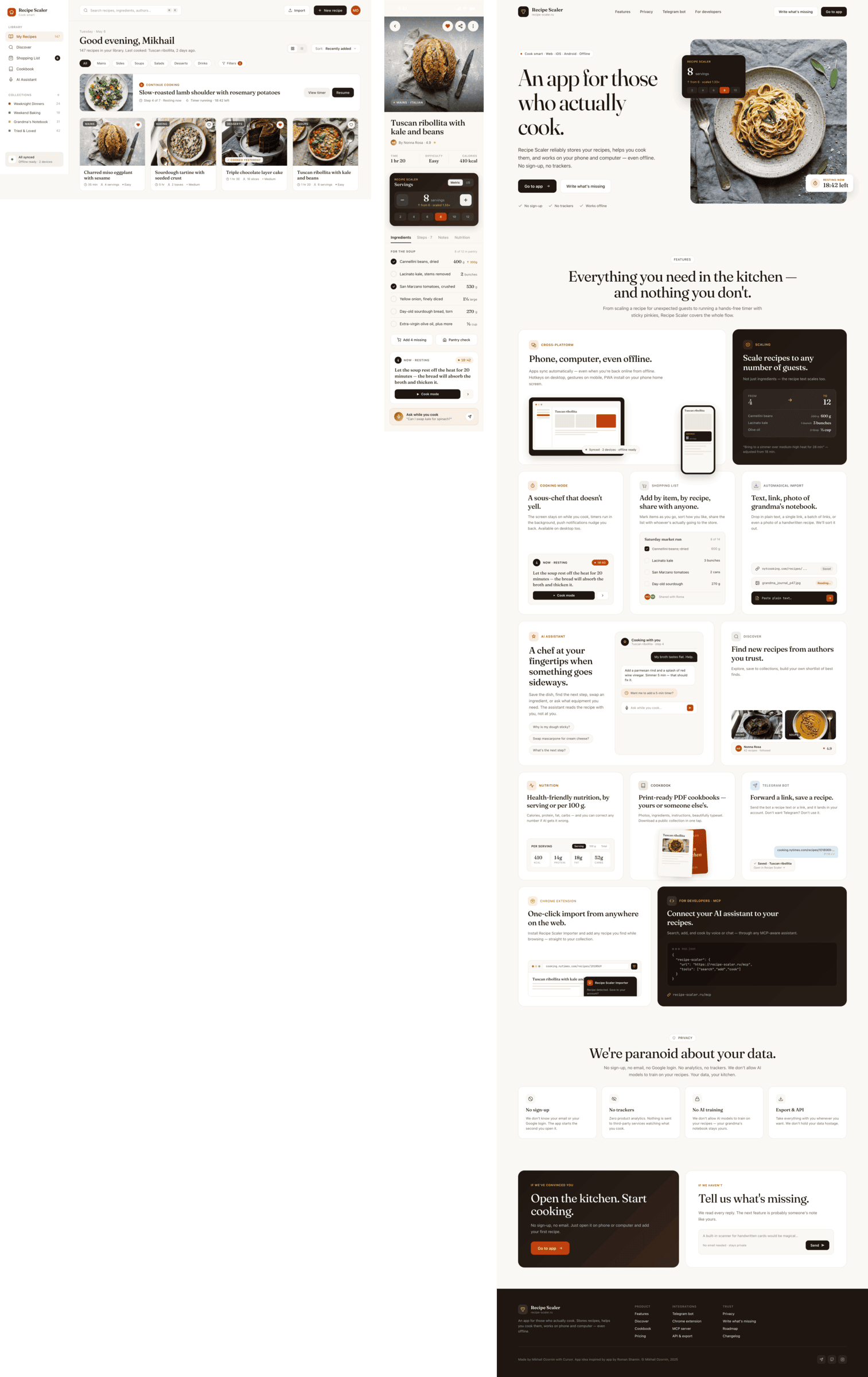
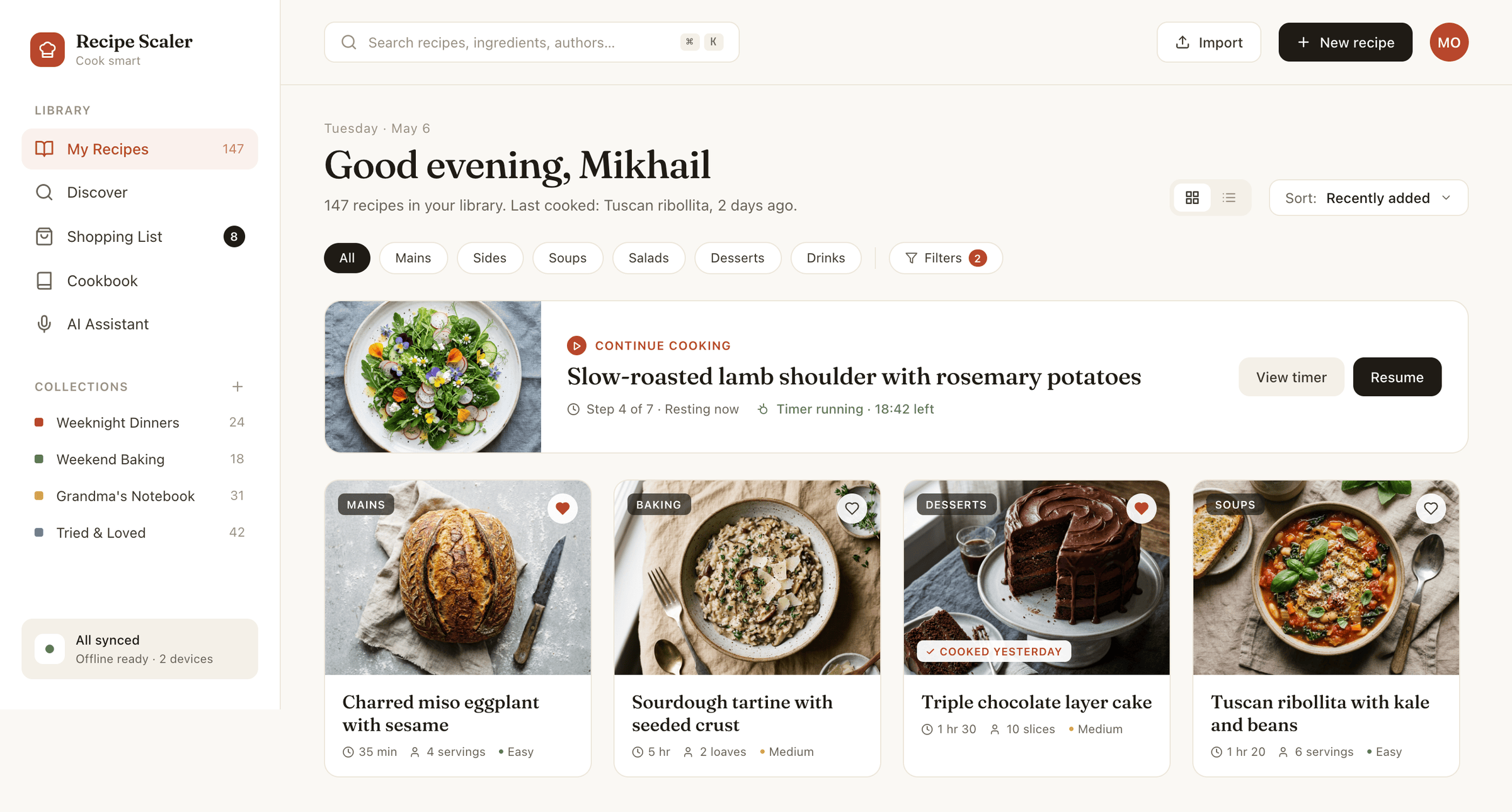
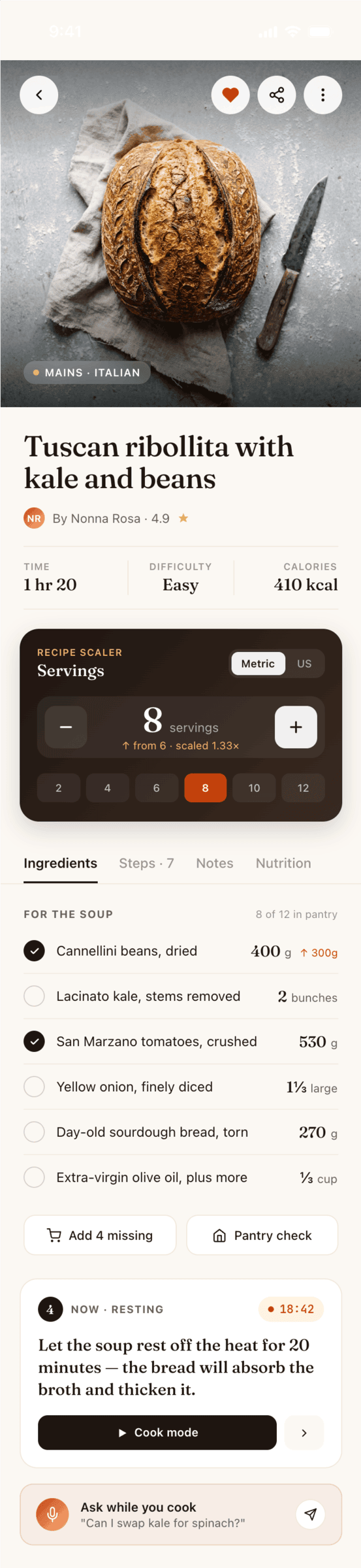
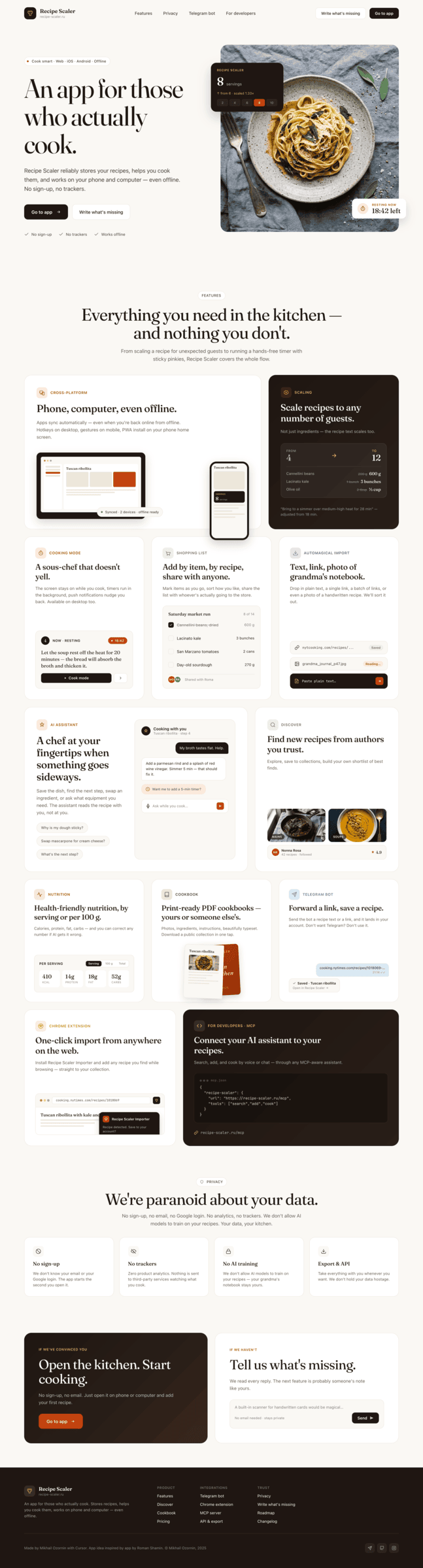
{kind=link}
{kind=link}
{kind=link}
Kilo Code + Hy3 preview (Kilo cloud)
The trendiest open-source model on Openrouter. Very so-so.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
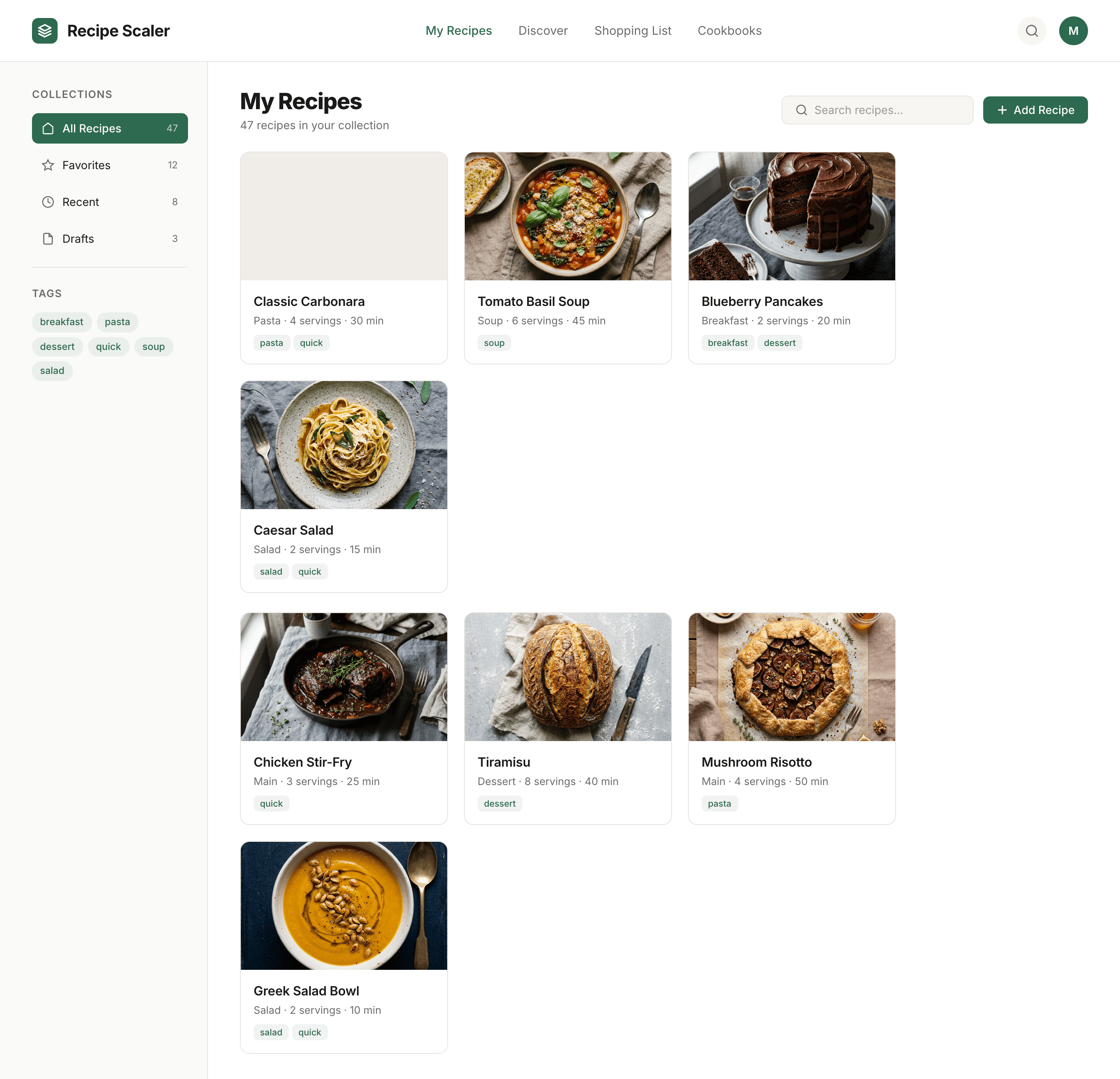
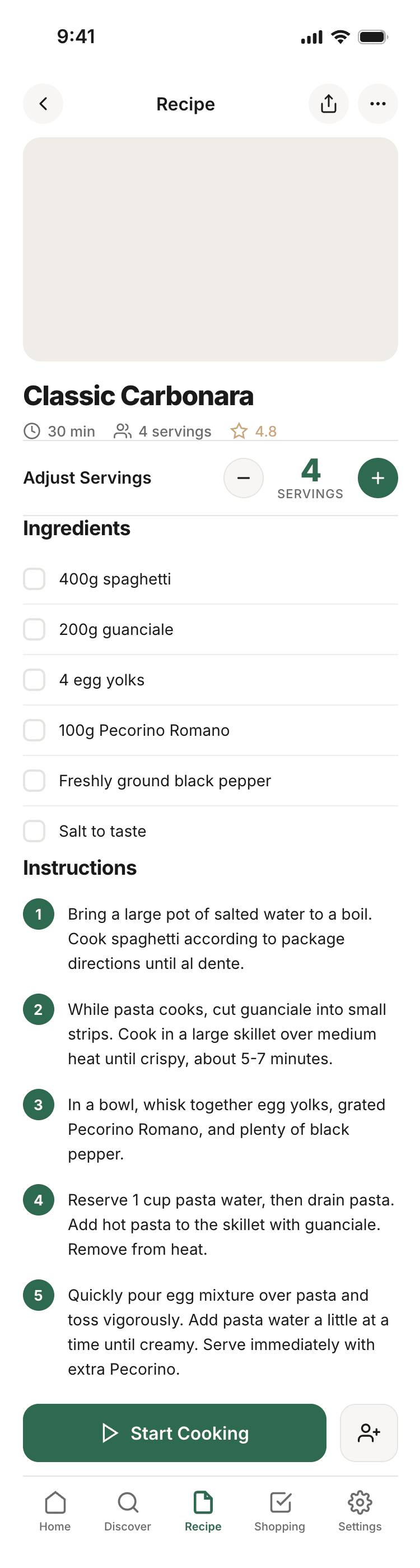
Kilo Code + Qwen 3.6 Max Preview (Kilo cloud)
In general Qwen did decently for me. A bit dim, but pretty solid. Sagged in promo like everyone. 1/30 of Opus’s price.
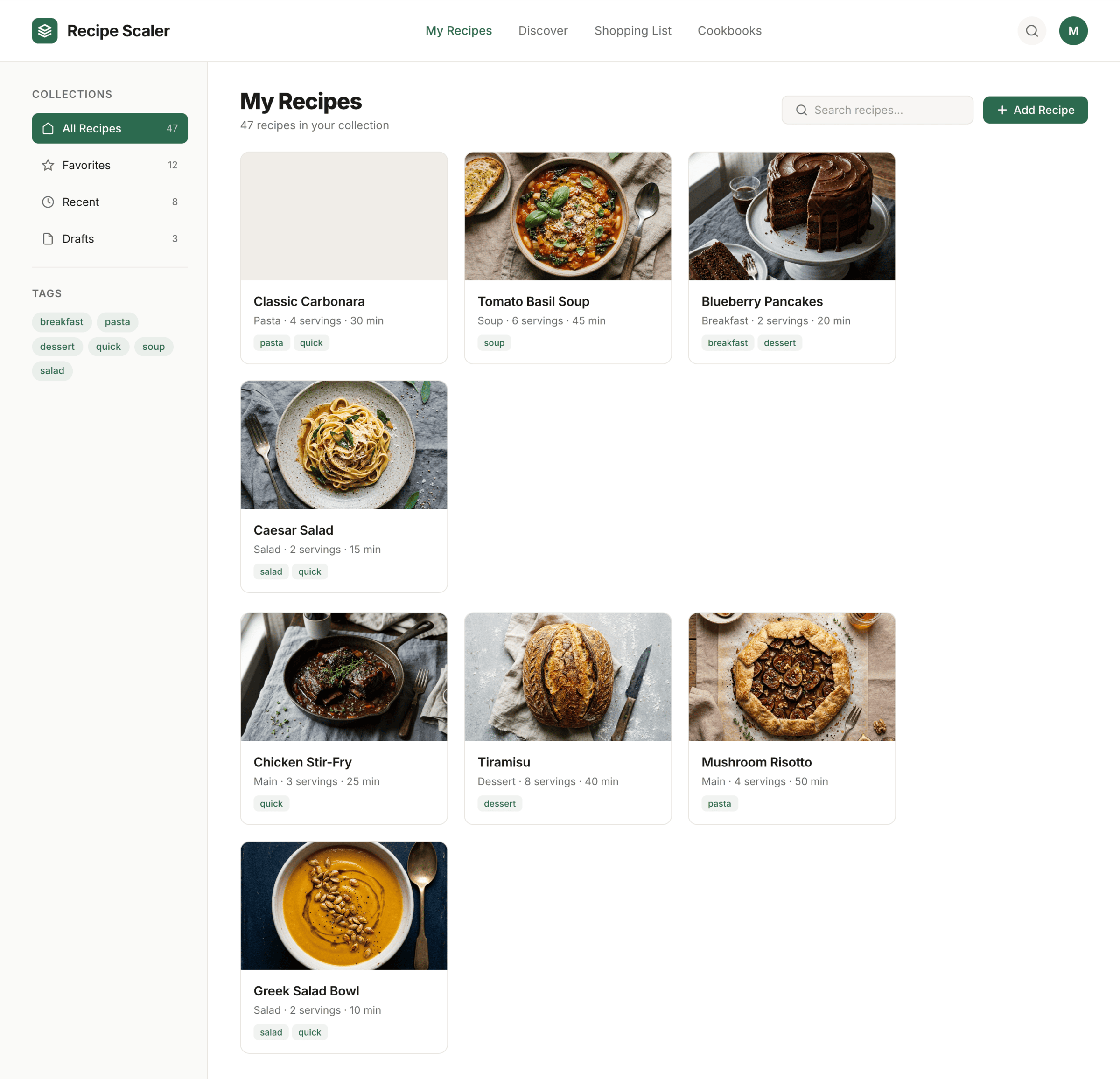
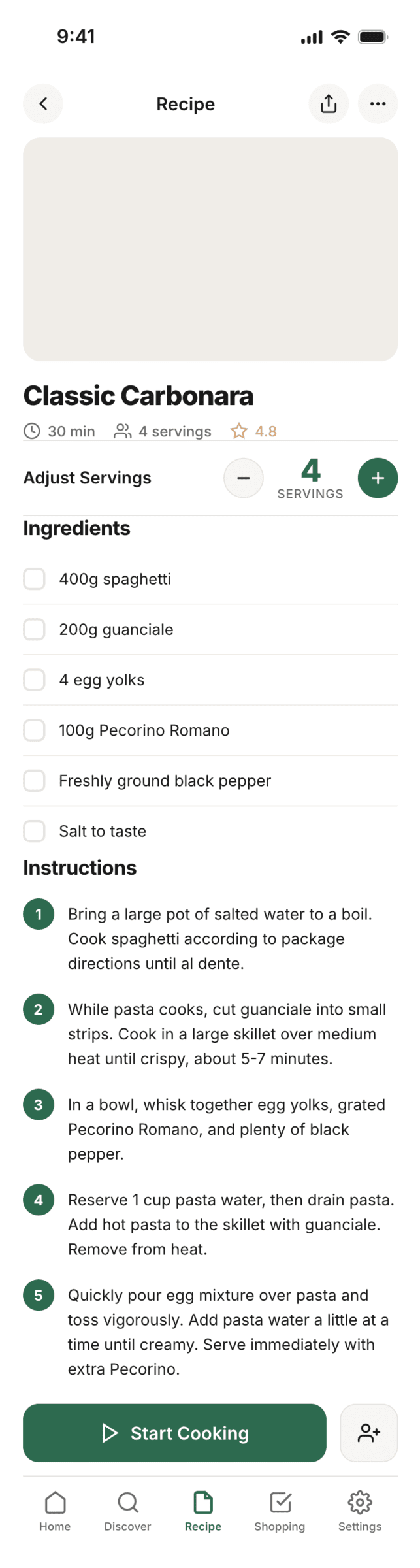
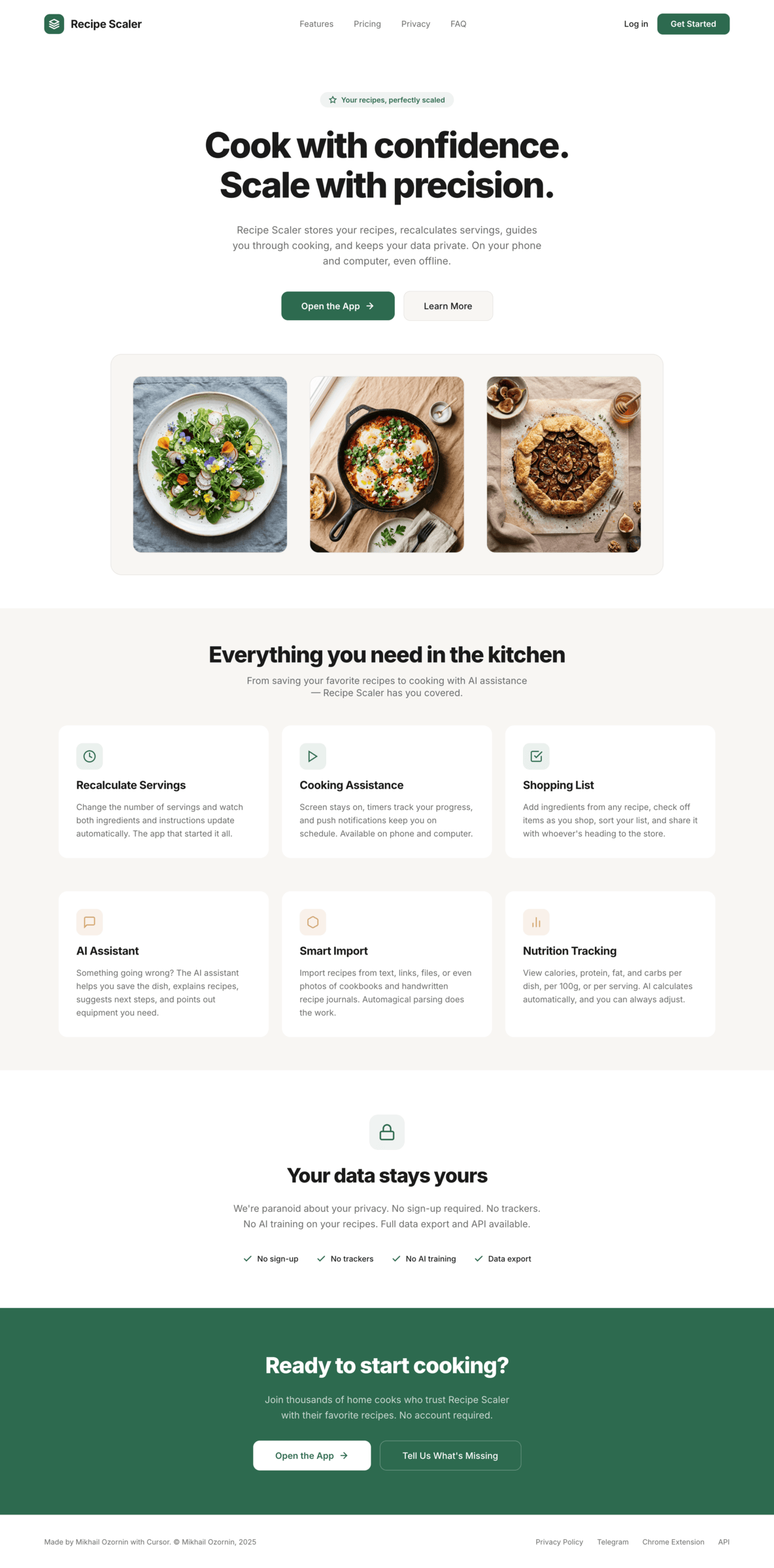
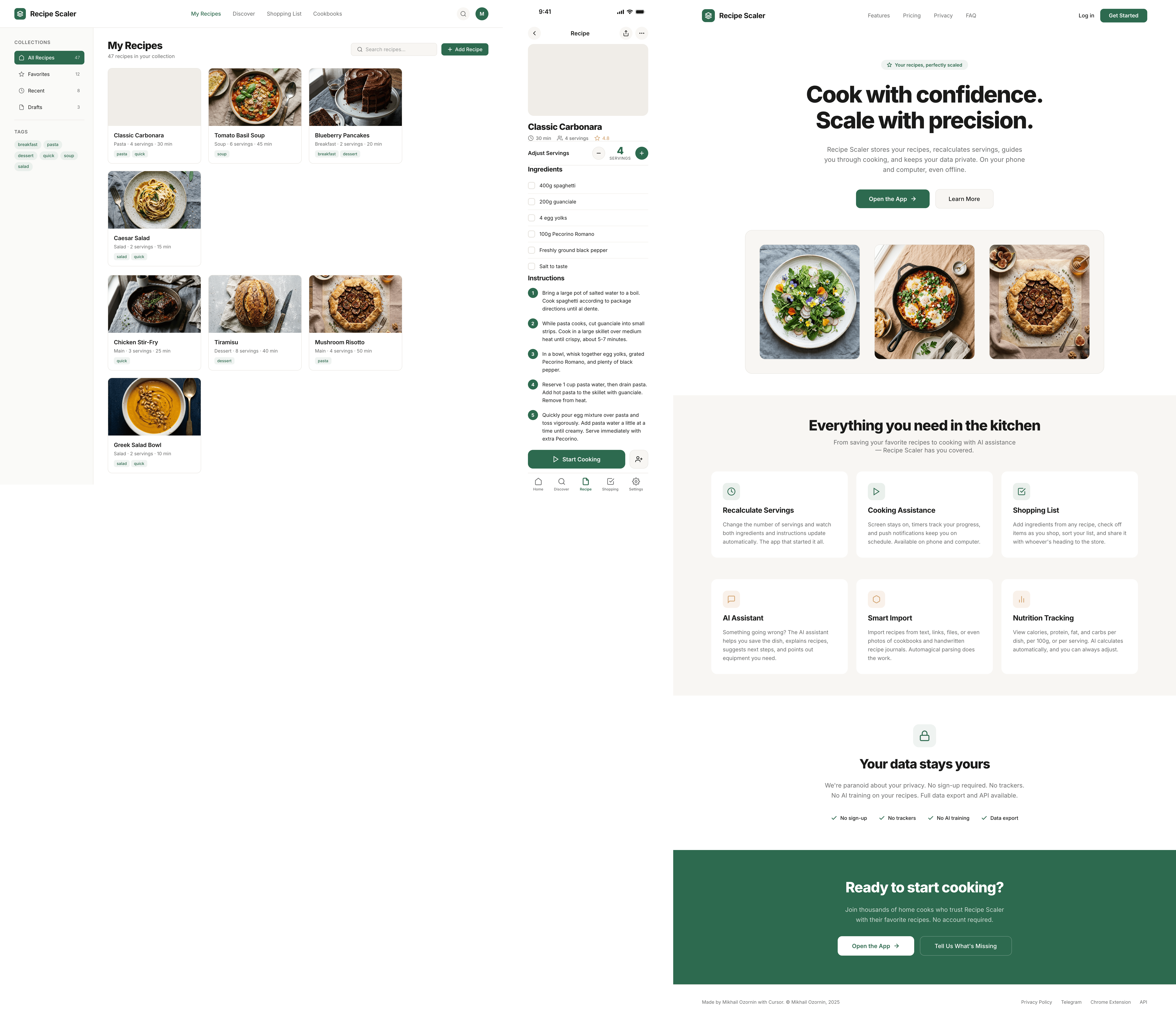{kind=link}
{kind=link}
{kind=link}
{kind=link}
Kilo Code + Qwen 3.5 397
Didn’t cope with the tools.



{kind=link}
{kind=link}
{kind=link}
Kilo Code + Grok Build 0.1 + Google Skill
Same prompt with Google’s design skill attached; compare with OpenCode Grok Build 0.1 without a skill.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + Opus 4.7, xhigh reasoning (OpenRouter)
Not bad, what would have been in mobile I don’t know, because after this screen Openrouter banned me from American SOTA models.
{kind=link}
OpenCode + Kimi 2.6 (OpenRouter)
Mobile is better than the rest, the rest is bad. The funny thing is everything was duplicated, but then through screenshots it discovered and erased it itself. Because of this it fussed for a very long time — 40+ minutes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + Grok 4.3 (OpenRouter)
Grok was already above, but unlike Cursor, Opencode couldn’t handle the model at all, the result is much worse than Cursor’s.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + Grok Build 0.1 (OpenRouter)
Fast, weak, expensive for this quality.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + DeepSeek V4 Pro (Deepseek Cloud), Max Reasoning
DeepSeek is very cheap, but managed only once. Mobile is watchable, the rest is bad.
{kind=link}
{kind=link}
{kind=link}
{kind=link}



{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + GLM 5.1 (z.ai coding plan)
Unlike Cursor, Opencode managed to get something out of GLM, turned out generally OK for its price. It costs less than Haiku, which couldn’t do literally anything.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + Qwen 3.5 397
Couldn’t do anything.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + MiniMax 2.7 (OpenRouter)
Incredibly fast, incredibly cheap, the quality is accordingly.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OpenCode + Qwen 3.7
Expensive for its result, no improvement over 3.6 Max. Very bad at using tools (possibly an Opencode issue).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figma: Claude Code + Opus 4.7, xhigh
Opus in its style, especially from afar, but ate more than a full 5-hour quota.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figma: Codex + GPT 5.5, xhigh
In Figma it managed slightly better than in Paper. Lays things out monstrously simply.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figma: Cursor + GLM 5.1 (z.ai coding plan)
In general worse than in Paper. The desktop layout on the bottom is me dragging a layer to where it needs to go, GLM didn’t master a correct DOM.
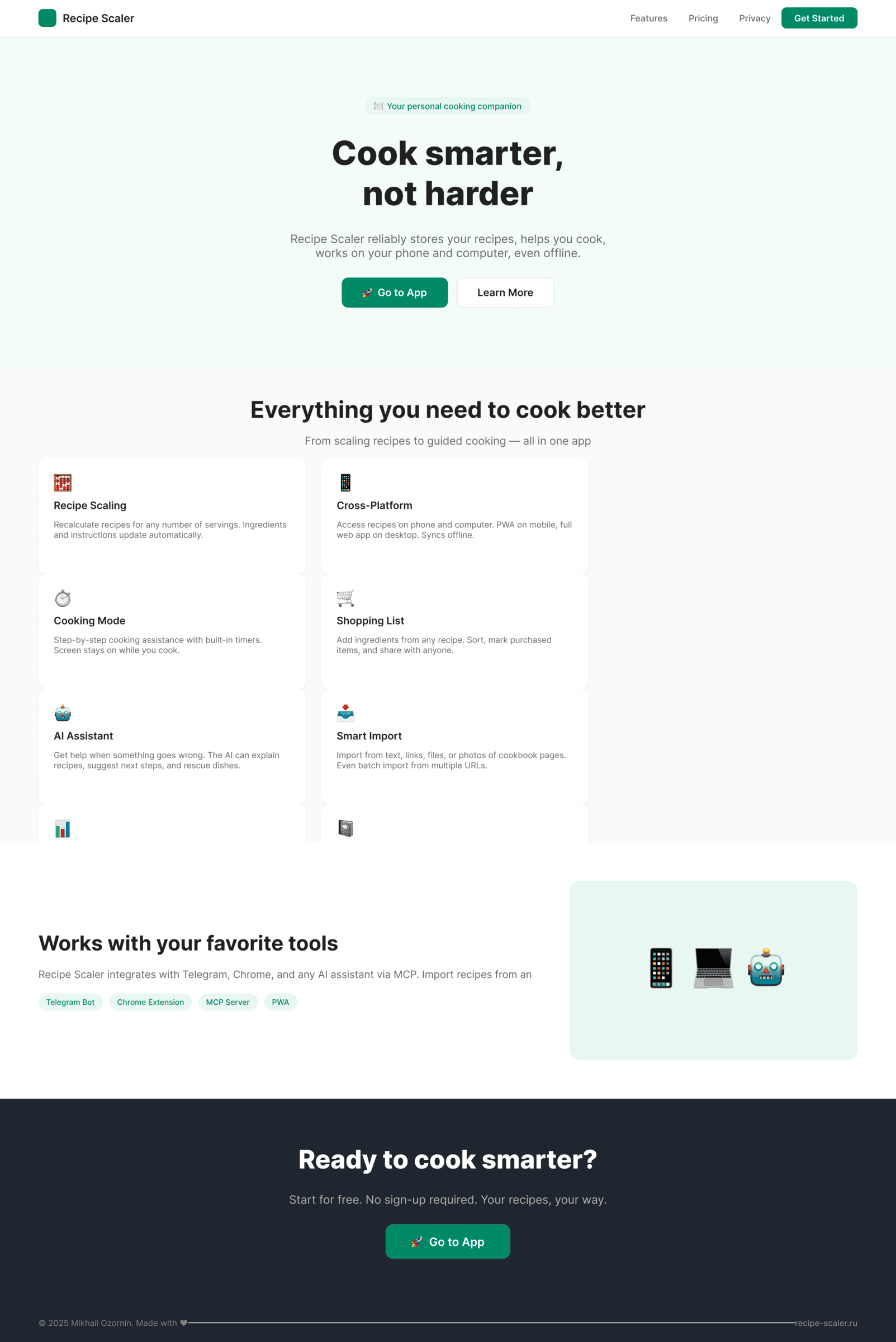
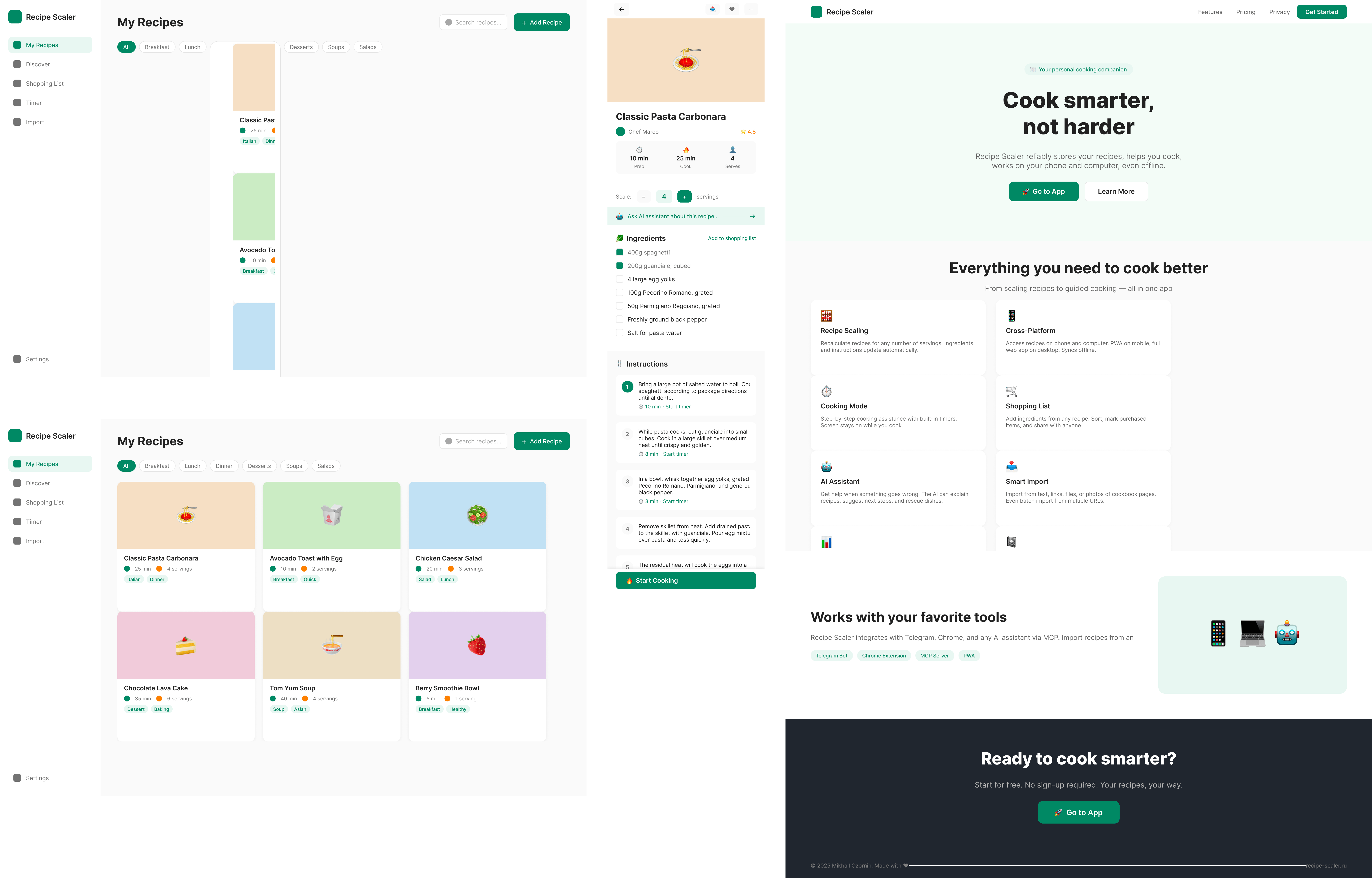{kind=link}
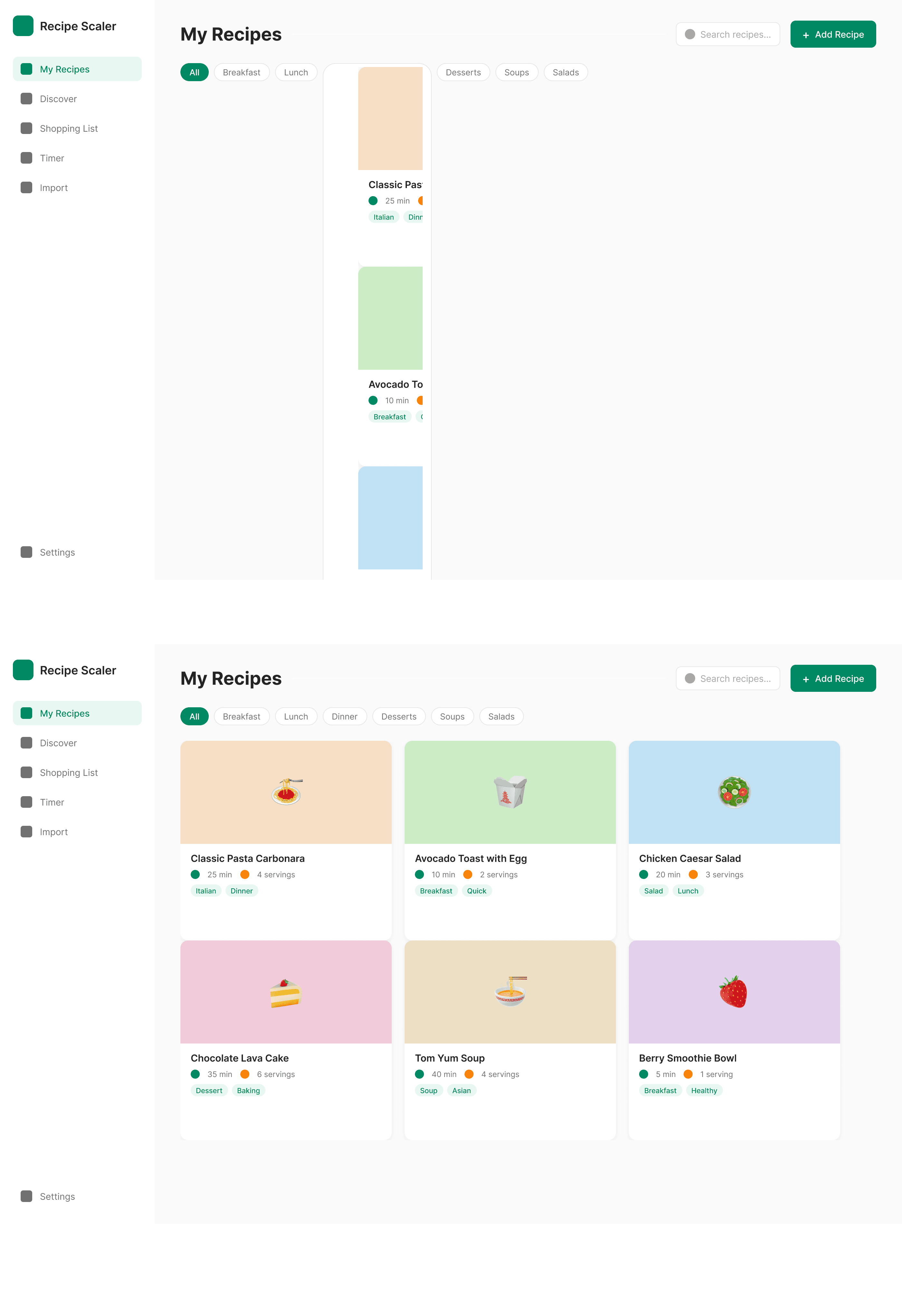{kind=link}
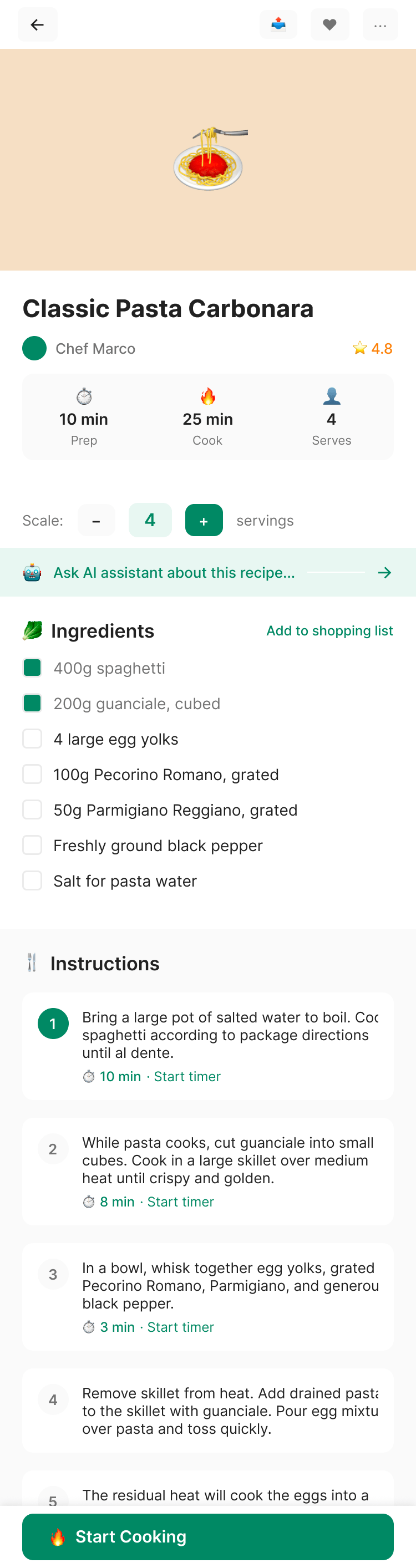{kind=link}
{kind=link}
Cursor + Composer 2
Catastrophically bad, worse than in Paper.
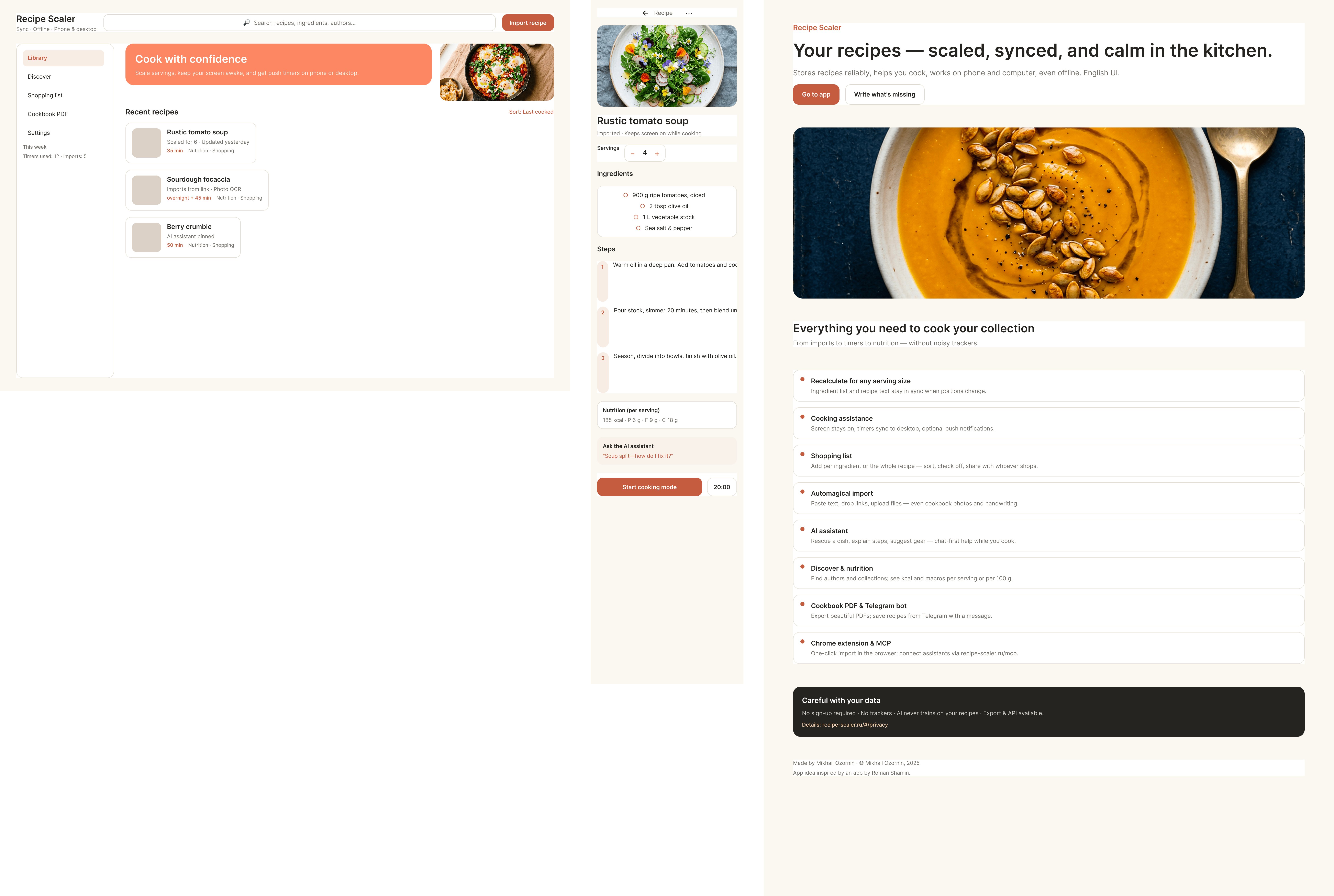{kind=link}
{kind=link}
{kind=link}
{kind=link}
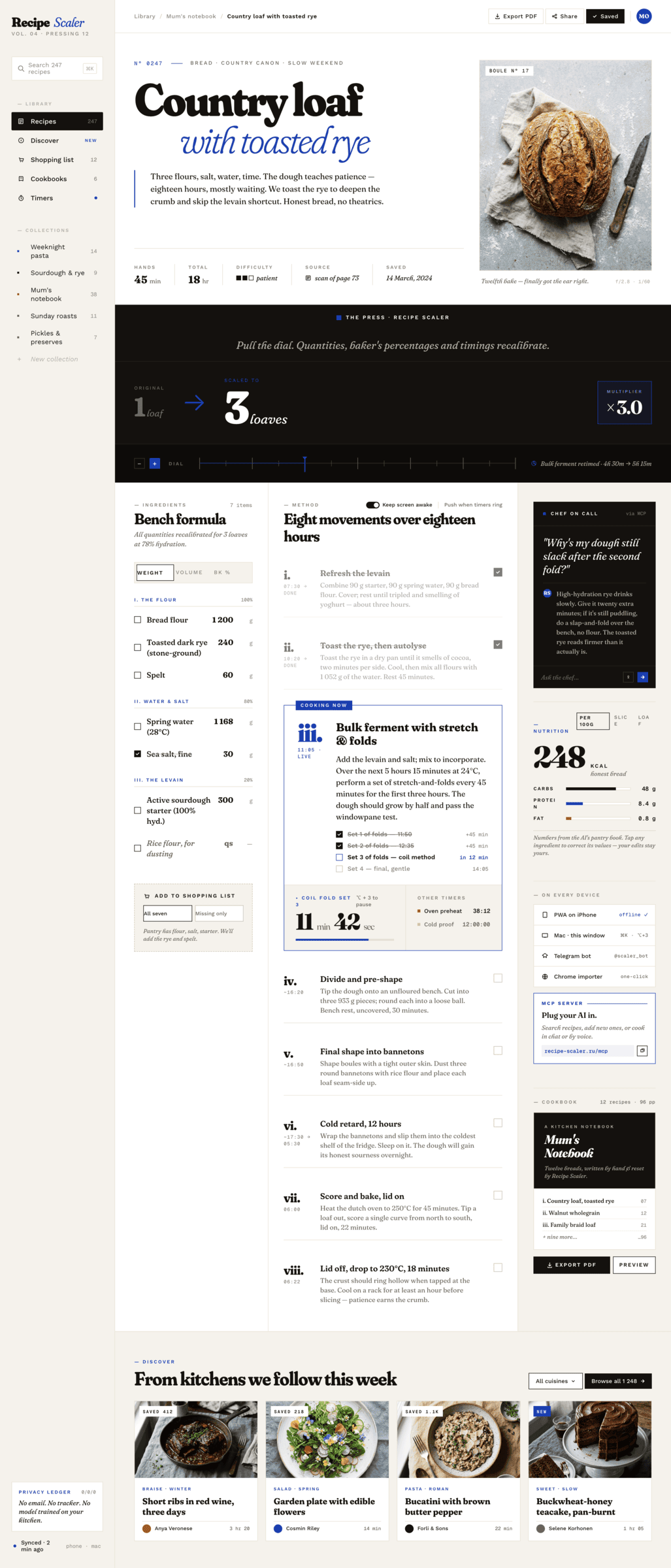
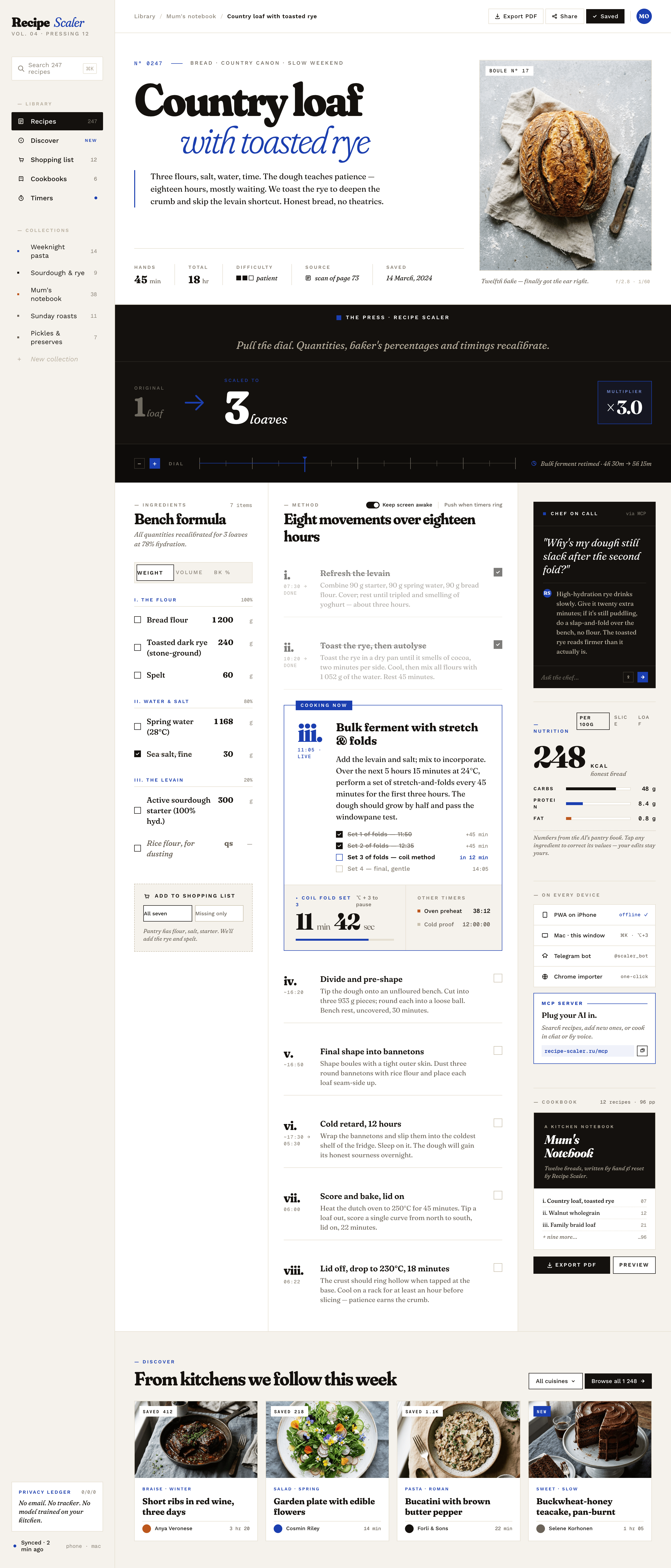
After the main experiment I decided to try giving it the Impeccable skill and see how it would influence things. The same prompt, but with the skill. Full config — Claude Code + Opus 4.7, xhigh + Frontend Design Skill
I only made one desktop screen, it eats a lot, even fancier than it was. One screen ate 44% of the 5h · pro quota in Claude Code. It’s like Opus became even more Opus-y and some kind of grief-from-too-much-design-thinking started. Every pixel shouts «look how beautiful I am». There are errors, but the design became even more designer-y.
{kind=link}
4 How much all this cost, you ask
In general there are prices in the table, dollars in Cursor are virtual (included in the subscription), the rest are real.
~$20 — the models
$16 — Paper Pro with a higher MCP limit.
3×$20 — subscriptions to Claude, Codex and Cursor, but they were already there.
The most expensive option would cost $12.30 (Cursor + Opus 4.7), the cheapest — $0.03 (Minimax 2.7), the difference — 410x. Opus wasn’t running at 100%, if I had turned on max-reasoning, it would have been about ×2.
5 Future experiments
What I would like to check, that didn’t make it into this series:
- Check with skills: how much this or that skill can improve the design.
- Check by giving styles, user scenarios and other context.
- Check by allowing it to ask clarifying questions: about tasks, product, style and user.
- Check what happens if you give it a rough sketch of the interface and bring it to a finished state.
- Give an existing screen and ask it to add style or improve only the interface without a complete redo of the structure.
- Let it read Gorbunov’s layout advice and check again.
6 Conclusions
- Opus is on top. Expensive and awesome. Surprisingly, the next one isn’t even GPT. Neither 5.4 nor even 5.5 come close. Chinese models, even Cursor’s auto mode, do it better. GPT 5.4 writes code well, explains and does analyses well. Design — a flop.
- Chinese models are overfitting on metrics and benchmarks. In general all models outside the big labs are like this. By SWE metrics they’ve already caught up with and overtaken Opus, but in real life they can’t do a simple task. Some can’t even cope with correctly calling tools. A typical example is Minimax 2.7 — by all metrics it’s very good, in design it can do nothing. In the end it’s only good in speed and price (those are really wow). Someone will say DeepSeek is overfitting too. I can’t say so unequivocally about it: first, DeepSeek made one of the mockups noticeably better, and second, it still has some kind of problems with calling tools, as was the case in version 3.2. The best result is from those Chinese models that do their work without particularly shouting — Qwen 3.6 (but 3.5 is so-so).
- A good model makes design by developers and product managers themselves quite pointless, unless they have an understanding of design. It’s rare, but such people exist. If not, the model will do it faster and better. There’s still work for designers, you can breathe out for a quarter.
P. S.
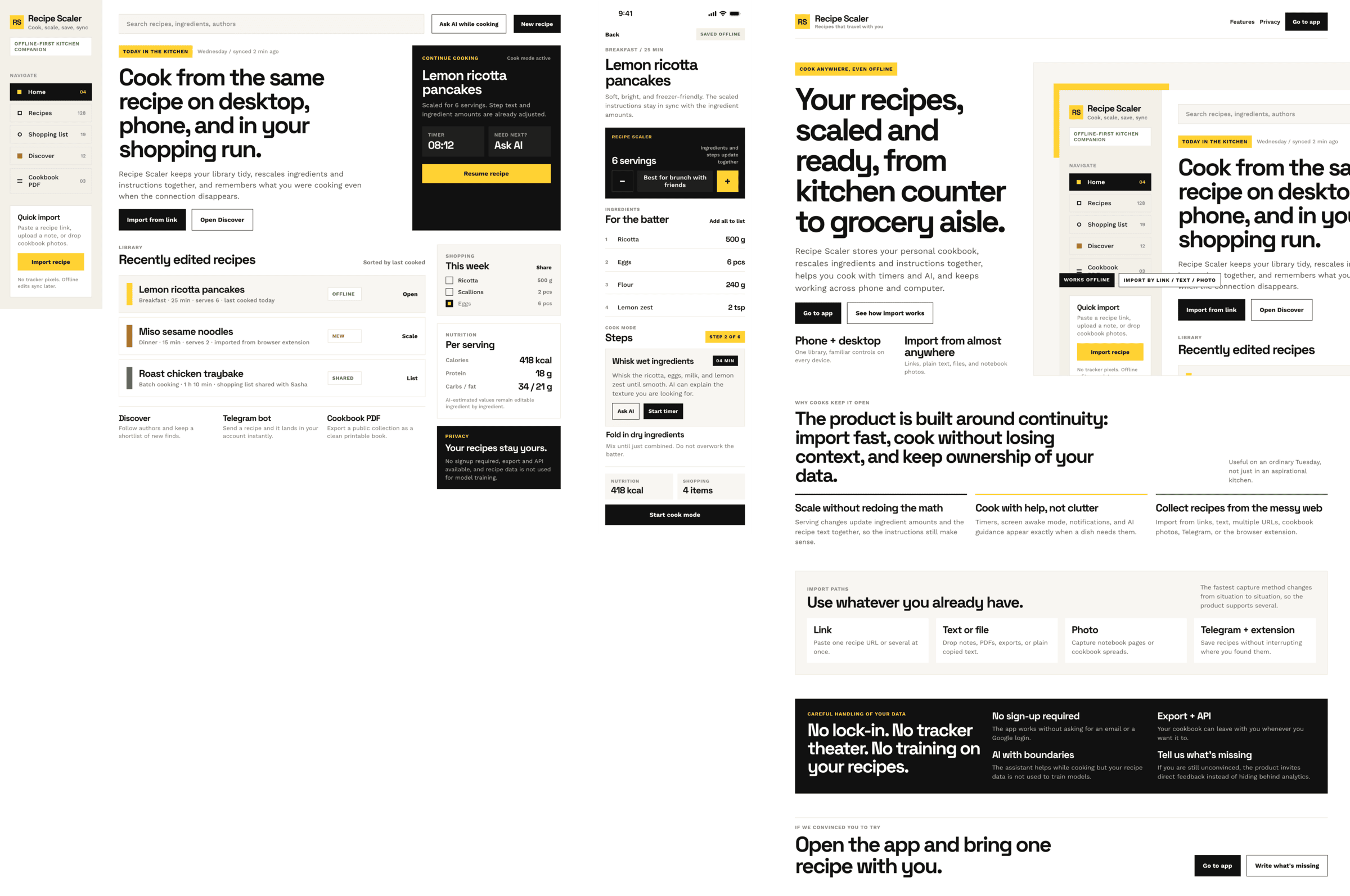
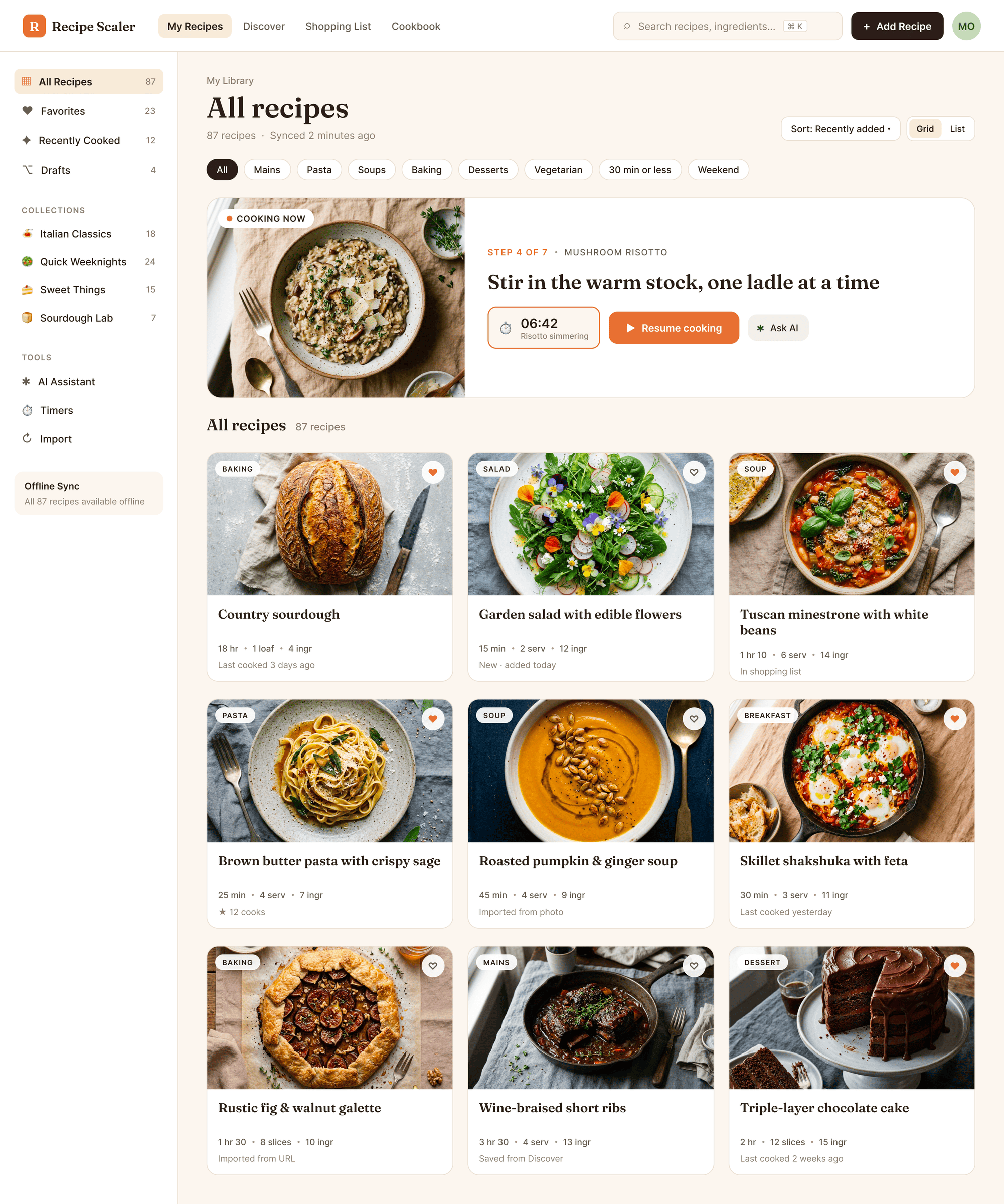
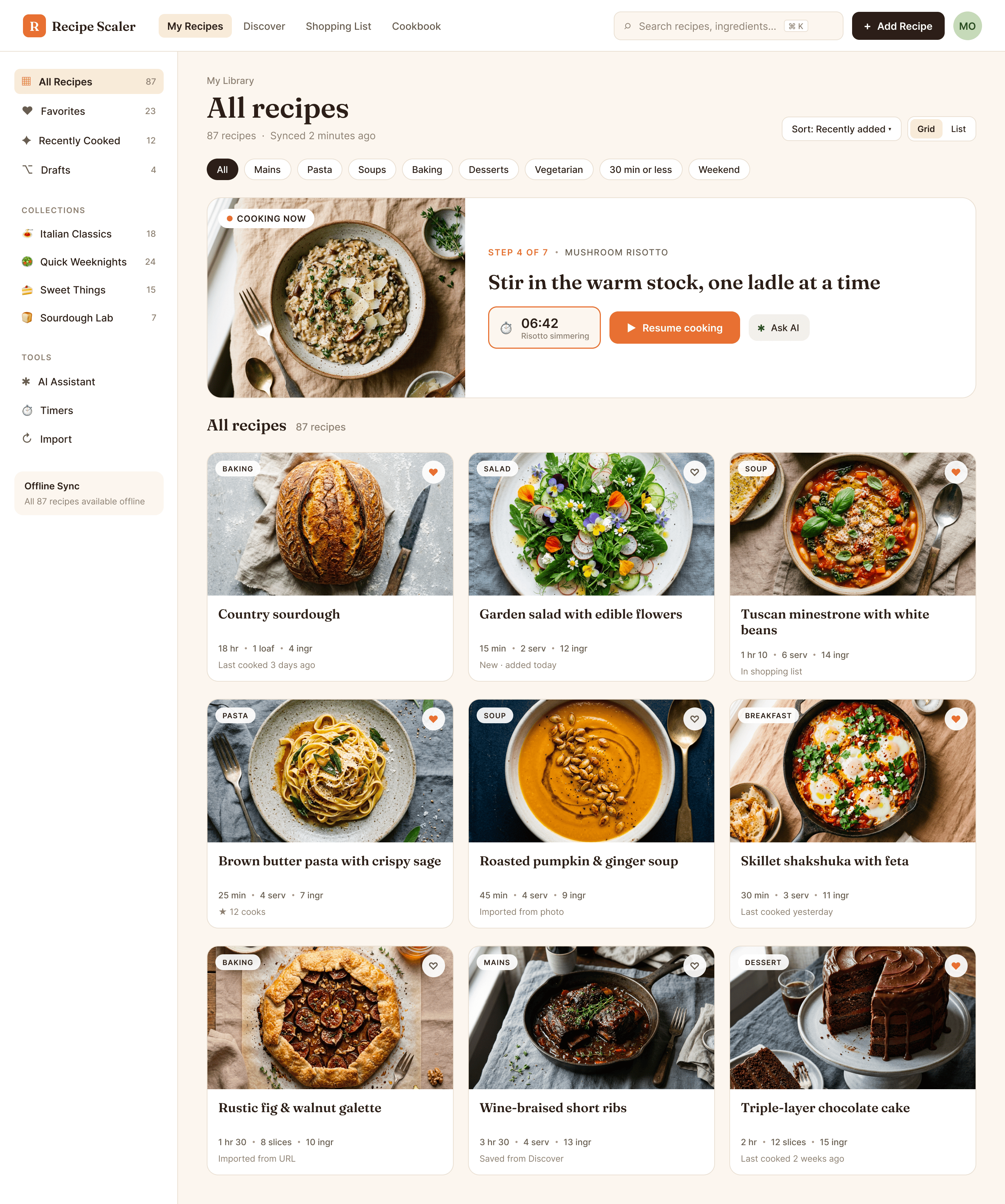
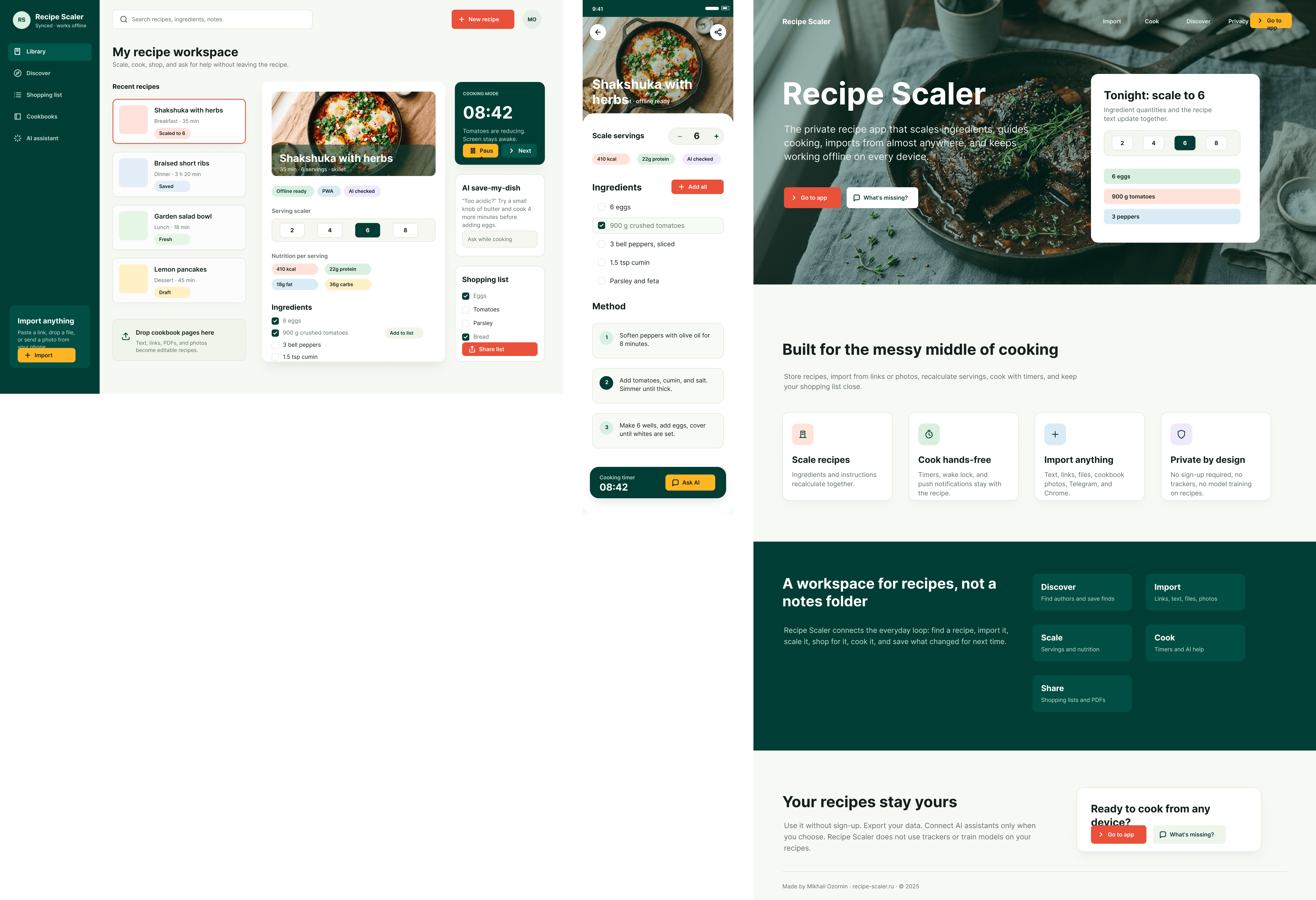
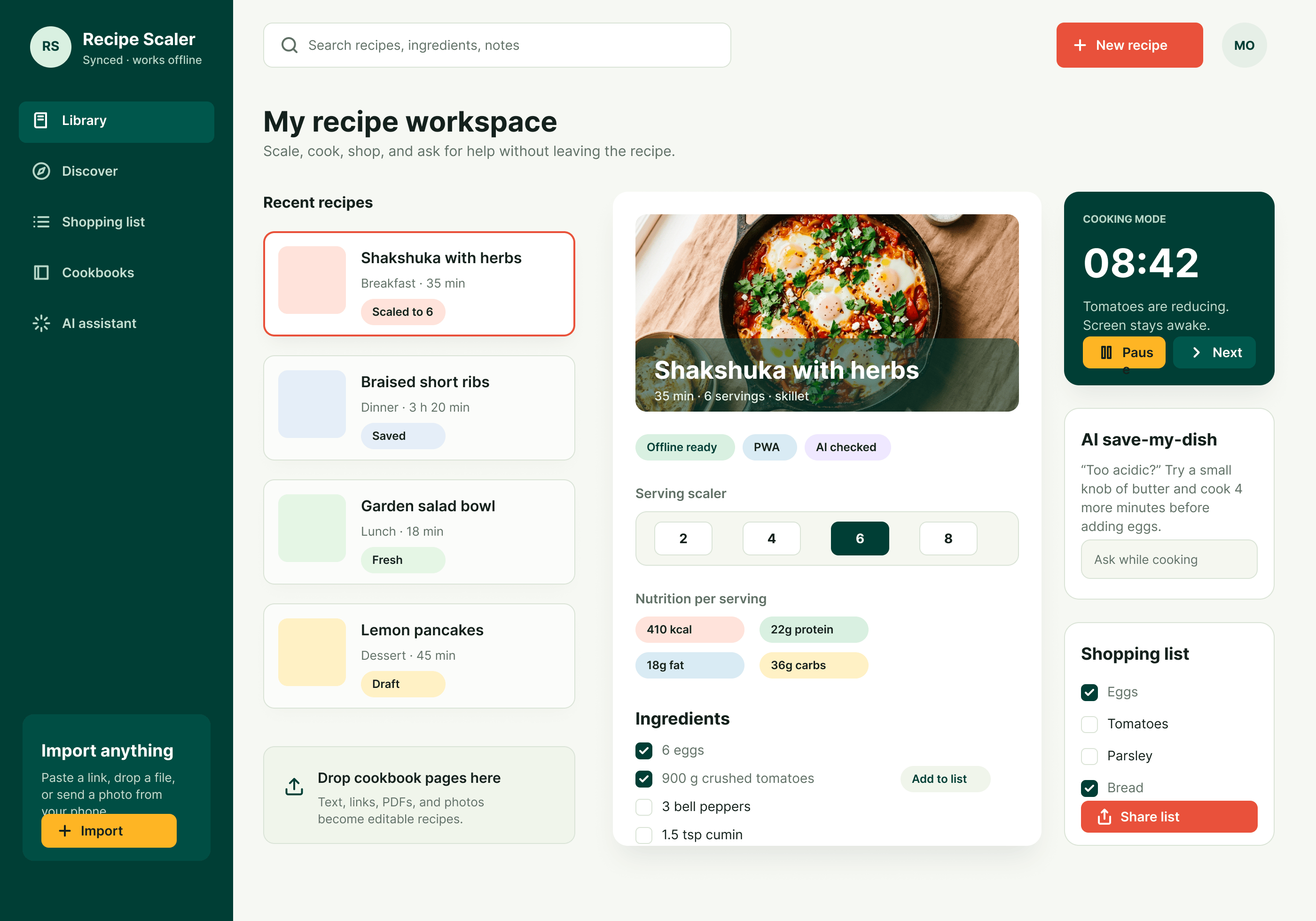
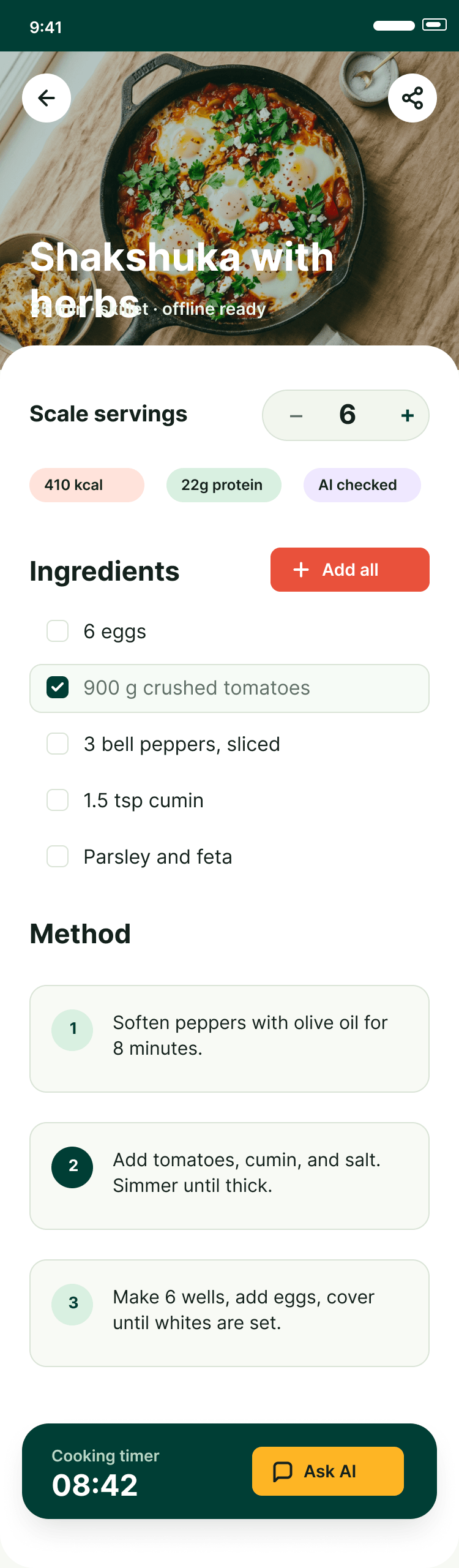
Since you’re here, try recipe-scaler.ru — the best recipe management app ever made. Wasn’t this all for nothing — so many design experiments? If every tenth person comes in, I’ll have +1000% users instantly.
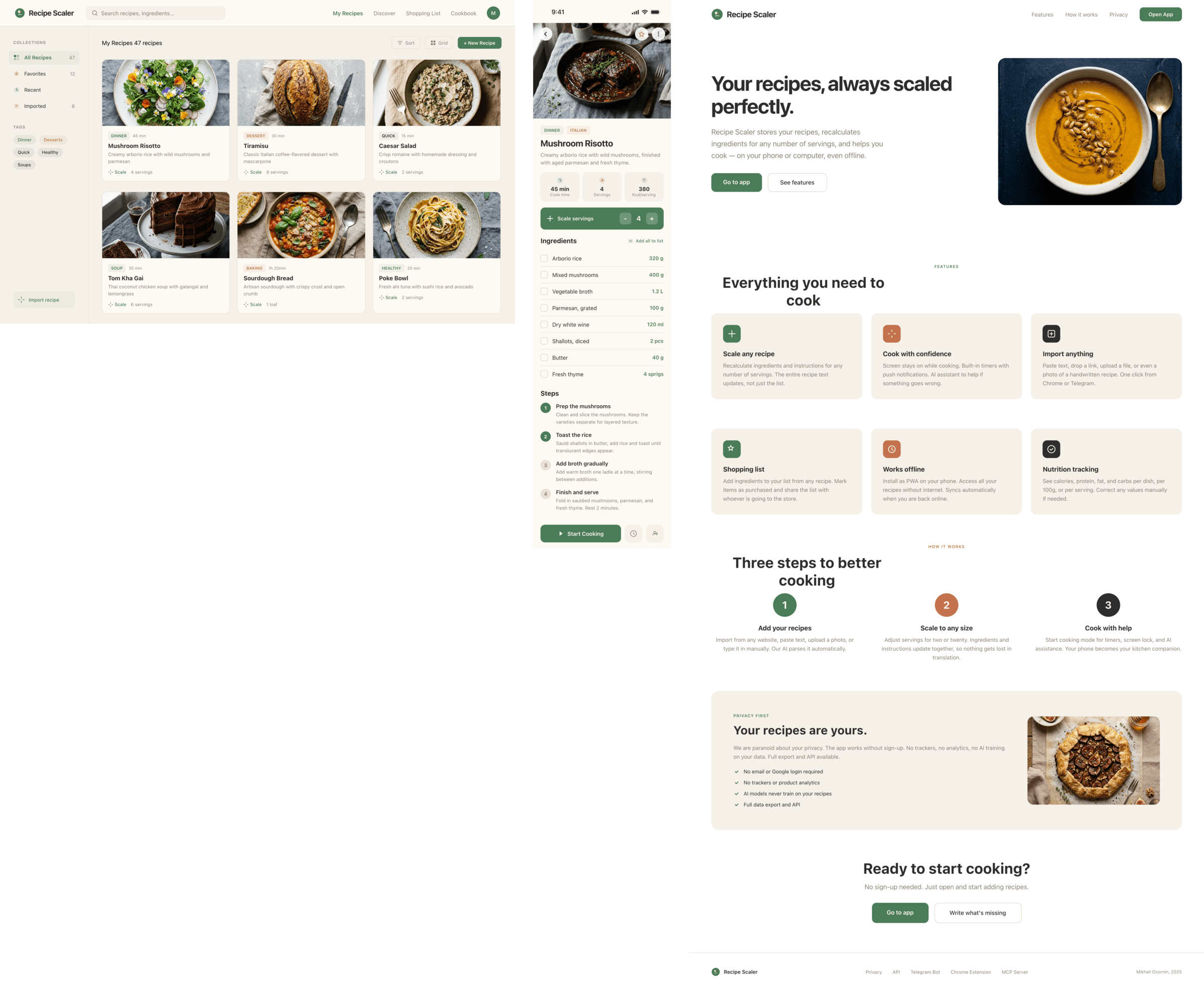
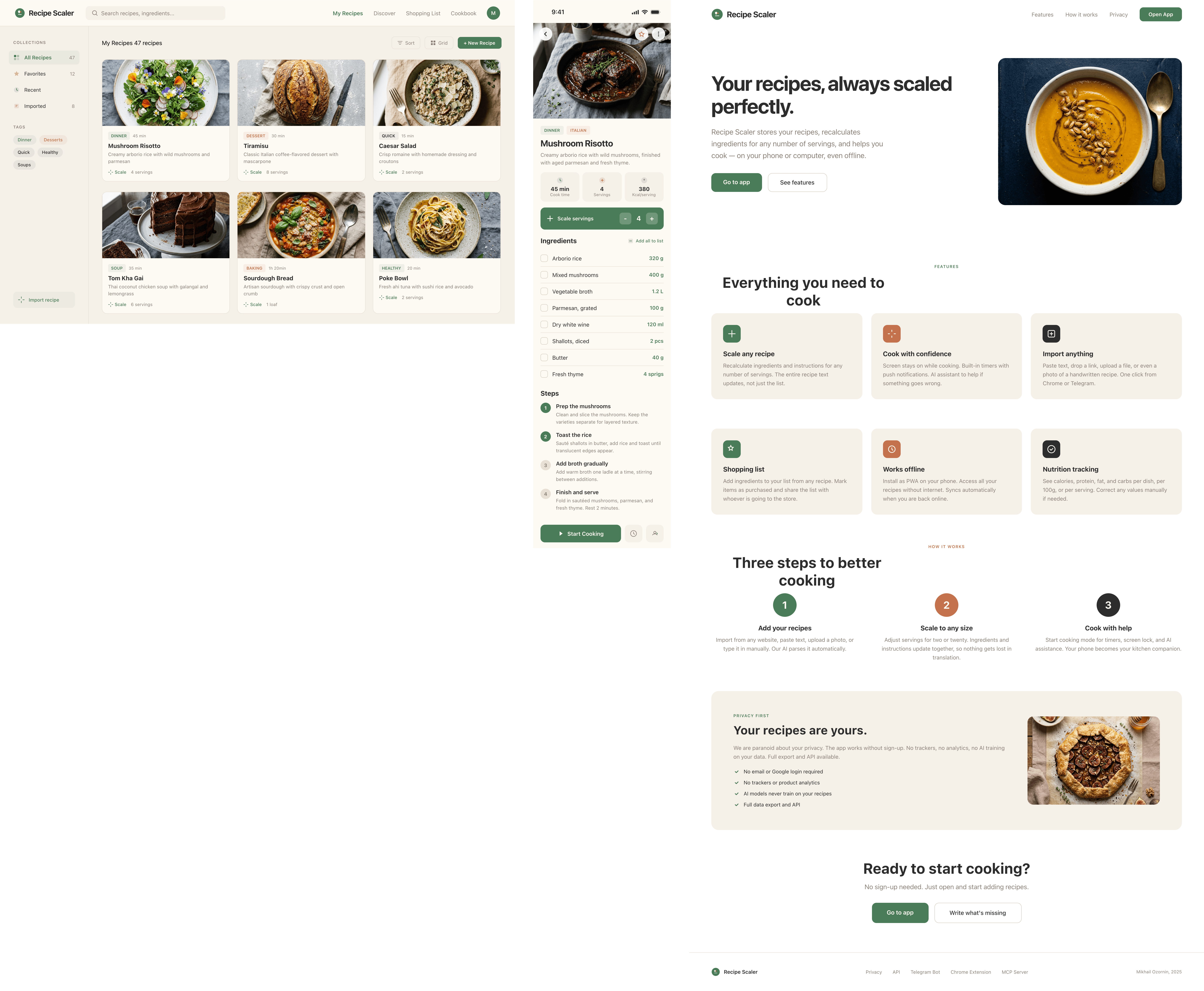
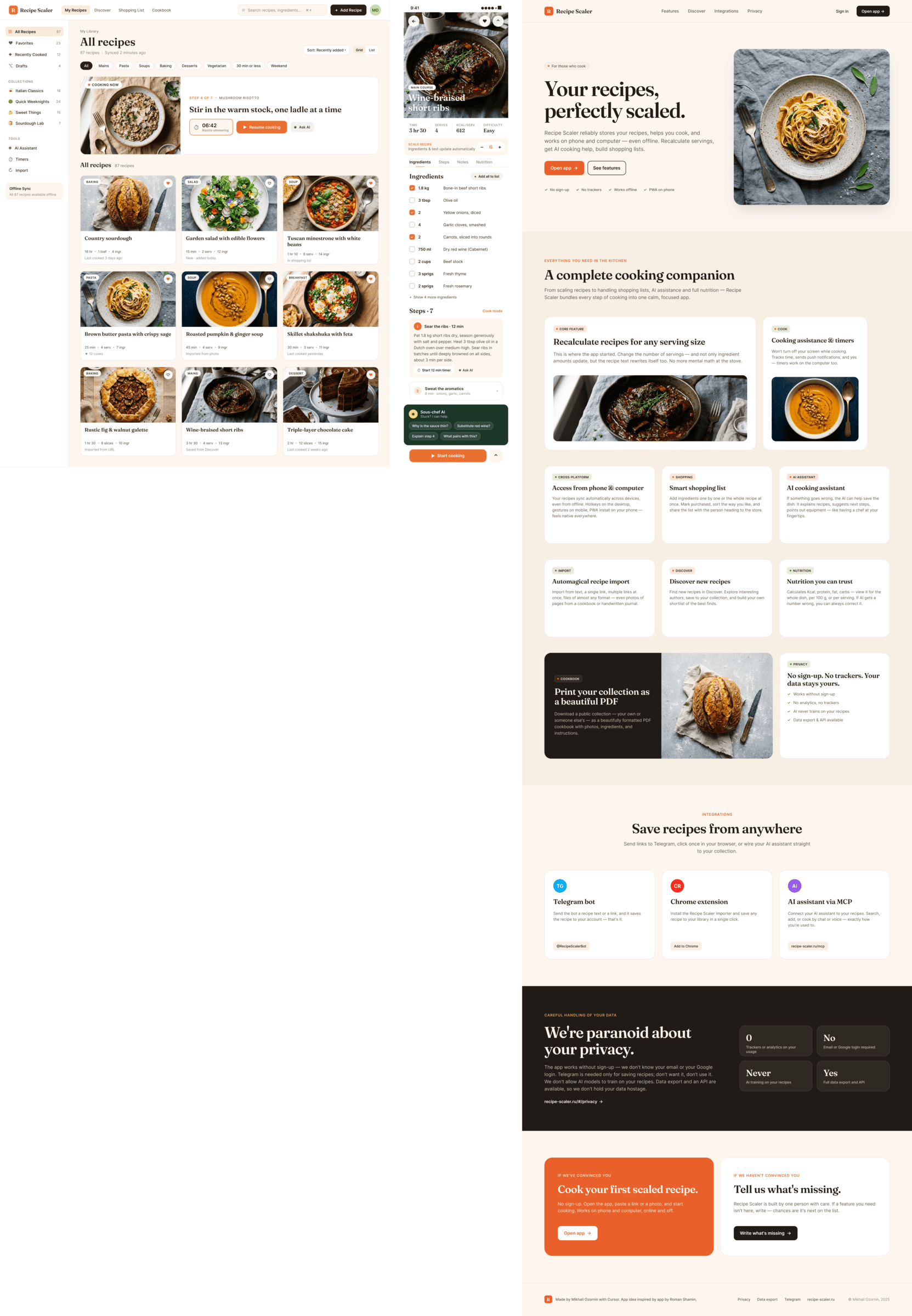
By the way, here’s what the post attachments block looks like:
upd. Added Gemini 3.5 Flash, Grok Build, MiMo 2.5, Opus 4.8